Welcome to Pigsty Doc
ZH Documentation
Pigsty (/ˈpɪɡˌstaɪ/) is the abbreviation of “PostgreSQL In Graphic STYle”

EN docs are translated by DeepL. And it will be calibrated later ….
Pigsty is a monitoring system that is specially designed for large scale PostgreSQL clusters. Along with a production-grade HA PostgreSQL cluster provisioning solution.
It brings the best observability for PostgreSQL and .
Pigsty bring users the ultimate observability and smooth experience with postgres. It is an open source software based on Apache License 2.0. Aiming to lower the threshold of enjoying PostgreSQL.

Pigsty has been evolved over time and has been tested in real production environments by some companies. The latest version of Pigsty is v0.8. It is available for production usage now.
Pigsty also has professional support.
1 - Overview
The problems Pigsty solves, the techniques Pigsty used, and the scenarios to which it applies.
What is Pigsty
- Pigsty delivers the best monitoring system for PostgreSQL
- Pigsty is a high-available postgres provisioning solution
- Pigsty is an open source software lower the threshold of enjoying postgres.
Monitoring
You can’t manage what you don’t measure.
Monitoring systems provide metrics on the state of the system and are the cornerstone of operations and maintenance management.
PostgreSQL is the best open source relational database in the world, but its ecosystem lacks a good enough monitoring system.
Pigsty aims to solve this: It delivers the best PostgreSQL monitoring system.
Pigsty is unrivaled in terms of metrics numbers and monitoring panel richness. Check comparsion for more detail.

Provisioning
Pigsty is a HA postgres cluster provisioning solution.
Provisioning solution is not a database, but a database factory. You submits a form to the factory, and it create corresponding postgres cluster you want based on the form content.
Pigsty use declarative configuration for defining postgres clusters. These clusters are created via idempotent playbooks. Which provides a kubernetes-like user experience.
The postgres clusters created by Pigsty are distributed, highly available postgres clusters. As long as any instance of the cluster still alive, the cluster can fully funtional. And each instance/node are idempotent . It will perform auto failover when failure occurs and self-heal within seconds without affecting read-only traffics.
If you wish to use Pigsty monitoring system alone without provisioning solution. Check monitor-only deployment for more information.
Open Source
Pigsty is l open source based on the Apache 2.0 License, which is free to use and also provides optional commercial support.
Pigsty’s monitoring system and provisioning solution are mostly based on open source components, and PostgreSQL itself is the world’s most advanced open source relational database. Based on the open source ecosystem and giving back to the open source community, Pigsty can greatly reduce the threshold of using and managing PostgreSQL, allowing more people to enjoy the convenience of PostgreSQL and experience the fun of the database.
The original intention of developing Pigsty was that the author needed to manage a large-scale PostgreSQL cluster, but after looking through all the open source and commercial monitoring system solutions on the market, he found that none of them were “good enough”. In the spirit of “I’ll do it, I’ll do it”, we developed and designed the Pigsty monitoring system. In order to distribute and demonstrate the monitoring system, there must first be monitored objects, so incidentally developed the Pigsty provisioning solution.
Pigsty packaged production-grade mature deployment solutions such as master-slave replication, failover, traffic proxy, connection pooling, service discovery, and basic permission system** into this project, and provided a **sandbox environment** for demonstration and testing. The sandbox configuration file can be applied to production deployments with only minor modifications, and users can fully explore and experience the features provided by Pigsty on their own laptops, truly **out-of-the-box**.

What’s Next?
Explore
- 监控界面:查阅监控系统提供的功能与界面
- 基本概念:关于Pigsty的基本概念与重要信息
- 公开示例:访问公开的Pigsty演示环境。
Get Started
- 上手沙箱:在本机上快速拉起Pigsty沙箱
- 探索实验:利用Pigsty体验数据库的乐趣
Deployment
2 -
Quick start with pigsty local sandbox with vagrant and virtualbox
TL;DR
To install pigsty, you have to prepare a node. Linux CentOS 7.8 x86_64 or equvilent. with sudo access.
curl -fsSL https://pigsty.cc/pigsty.tgz | gzip -d | tar -xC ~; cd ~/pigsty # download
make config # configure
make install # install
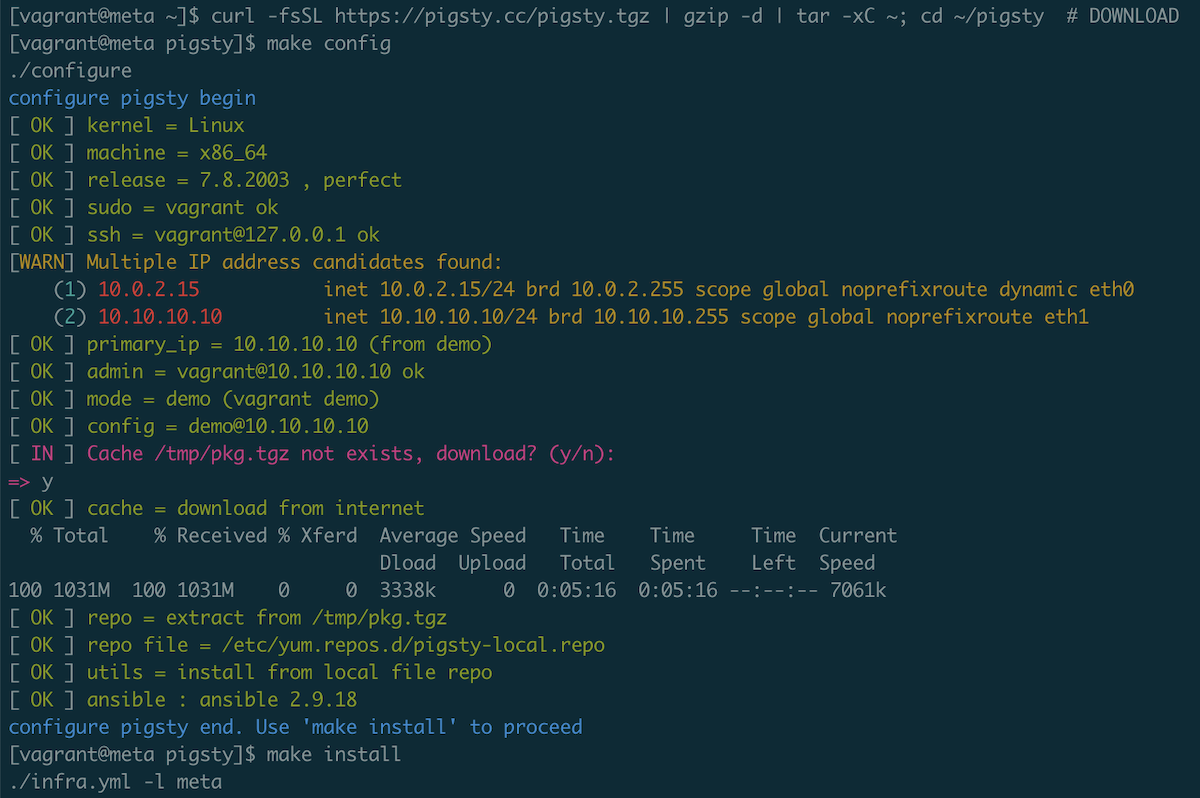
It may takes 10~15 minutes when using offline installation packages.
Sandbox
To run pigsty on your own laptop. Consider using Pigsty Sandbox. Which will create vm nodes for you based on virtualbox vm managed by vagrant.
make deps # (once) Install MacOS deps with homebrew
make dns # (once) Write static DNS
make start # (once) Pull-up vm nodes and setup ssh access
make demo # Boot meta node same as Quick-Start
While virtualbox & sandbox are cross-platform softwares. I could only guarentee it works on MacOS. But you can always create virtual machine to do this.
Usage
You can access via IP:ports directly to access Pigsty services.
For example. Pigsty monitoring system listen on 3000. with default username and password set to admin.
Domain name are written to /etc/hosts when executing make dns, you can also access these service via ip:port directly.
| service |
domain |
address |
description |
| Grafana |
http://pigsty |
10.10.10.10:3000 |
Pigsty Monitoring System Home |
| Consul |
http://c.pigsty |
10.10.10.10:8500 |
Consul admin UI, showing all nodes and services and their health status. |
| Prometheus |
http://p.pigsty |
10.10.10.10:9090 |
TSDB main page, querying metrics, defining rules, and handling alarms |
| Alertmanager |
http://a.pigsty |
10.10.10.10:9093 |
Browse, process, and block alarm messages |
| Haproxy |
http://h.pigsty |
10.10.10.10:80 |
Browse the status of load balancers for traffic management and control |
| Yum Repo |
http://yum.pigsty |
10.10.10.10:80 |
Local Yum repo |
Replace 10.10.10.10 here to your own IP address when install on your own nodes.
Deploy
After Pigsty installation is complete, this machine will act as a meta-node for Pigsty. Users can initiate control from the meta-node to deploy a new PG cluster. Deploying a new database cluster is a three-step process.
-
Bring the machine node used for deployment under management
The current user can password-free ssh login to the target node from the current node with password-free sudo privileges.
-
Define the database cluster (configuration file or GUI)
-
Execute the database cluster deployment script
If the user starts the sandbox with make start4`'' and make demo4`', just execute this command directly without configuration.
. /pgsql.yml -l pg-test # Initialize the pg-test database cluster
For more information, please refer to [deploy](. /deploy/) chapter
FAQ
For frequently asked questions during installation and use, please refer to FAQ.
What’s next?
3 - Concept
Some critical information about pigsty
Pigsty is logically composed of two parts: monitoring system and provisioning solution.
The monitoring system is responsible for monitoring the PostgreSQL database cluster, and the provisioning solution is responsible for creating the PostgreSQL database cluster. Before understanding Pigsty’s monitoring system and provisioning solution, it is helpful to read naming principles and overall architecture to get an intuitive picture of the overall design.
Pigsty’s monitoring system and provisioning solution can be used independently, and users can use Pigsty monitoring system to monitor existing PostgreSQL clusters and instances without using Pigsty provisioning solution, check Monitor-only deployment.
Monitoring System
You can’t manage what you don’t measure.
Pigsty delivers the best open source PostgreSQL monitoring system.
Pigsty’s monitoring system is physically divided into two parts.
- server: deployed on meta-node, including services such as Prometheus, a timing database, Grafana, a monitoring dashboard, Altermanager, and Consul, a service discovery.
- Client: deployed on [Database Node](arch/#Database Node), including NodeExporter, PgExporter, Haproxy. passively accept Prometheus pull, on.
The core concepts of the Pigsty monitoring system are as follows.
Provisioning Solution
It is better to teach a man how to fish rather than give him a fish
Provisioning Solution (Provisioning Solution) refers to a system that delivers database services and monitoring systems to users. The Provisioning Solution is not a database, but a database factory**, where the user submits a configuration to the provisioning system, and the provisioning system creates the required database cluster in the environment according to the user’s required specifications, similar to creating the various resources required by the system by submitting a YAML file to Kubernetes.
Pigsty’s provisioning solution is divided into two parts for deployment.
- Infrastructure (Infra) : Deployed on meta nodes to monitor key services such as infrastructure, DNS, NTP, DCS, local sources, etc.
- [Database Cluster](arch/# Database Cluster) (PgSQL) : Deployed on database nodes to provide database services to the outside world as a cluster.
Pigsty’s provisioning scheme is deployed to two types of objects.
- [meta node](arch/# meta node) (Meta): deployment infrastructure to perform control logic, each Pigsty deployment requires at least one meta node, which can be reused as a normal node.
- [Database Node](arch/#Database Node) (Node): used to deploy database clusters/instances, Pigsty uses exclusive deployment with one-to-one correspondence between nodes and database instances.
The relevant concepts of Pigsty provisioning solution are as follows.
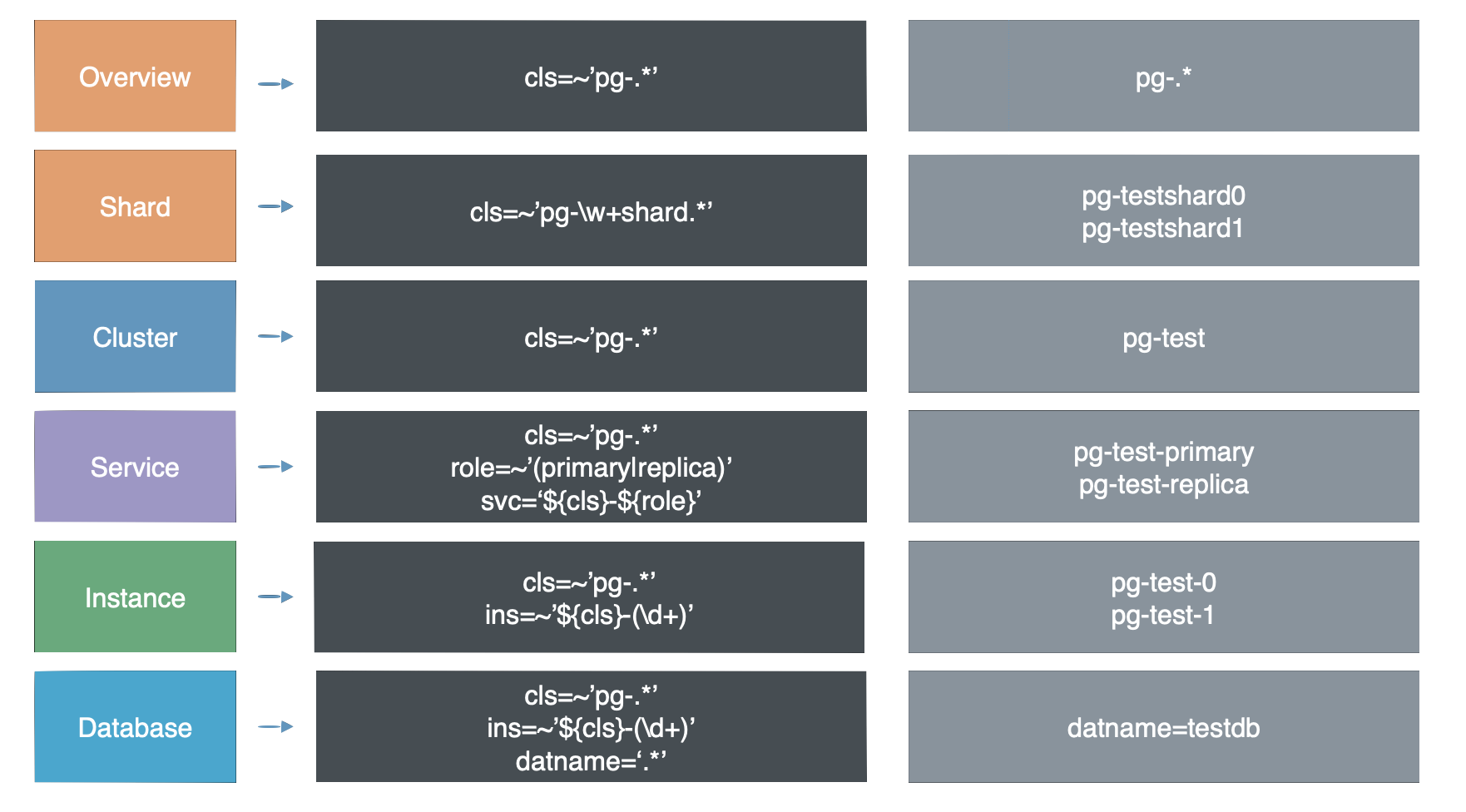
3.1 - Naming Rules
Introduction to pigsty naming rules
You can refer to those you can name. You can take action on those you can refer
Concepts and their naming are very important things, and the naming style reflects the engineer’s knowledge of the system architecture. Ill-defined concepts will lead to confusion in communication, and arbitrarily set names will create unexpected additional burden. Therefore it needs to be designed judiciously. This article introduces the relevant entities in Pigsty and the principles followed for their naming.
Conclusion
In Pigsty, the core four types of entities are: Cluster, Service, Instance, Node
- Cluster is the basic autonomous unit, which is assigned **uniquely by the user to express the business meaning and serve as the top-level namespace.
- Clusters contain a series of Nodes at the hardware level, i.e., physical machines, virtual machines (or Pods) that can be uniquely identified by IP.
- The cluster contains a series of Instance at the software level, i.e., software servers, which can be uniquely identified by IP:Port.
- The cluster contains a series of Services at the service level, i.e., accessible domains and endpoints that can be uniquely identified by domains.
- Cluster naming can use any name that satisfies the DNS domain name specification, not with a dot (
[a-zA-Z0-9-]+).
- Node naming uses the cluster name as a prefix, followed by
- and then an integer ordinal number (recommended to be assigned starting from 0, consistent with k8s)
- Because Pigsty uses exclusive deployment, nodes correspond to instances one by one. Then the instance naming can be consistent with the node naming, i.e.
${cluster}-${seq} way.
- Service naming also uses the cluster name as the prefix, followed by
- to connect the service specifics, such as primary, replica, offline, delayed, etc.
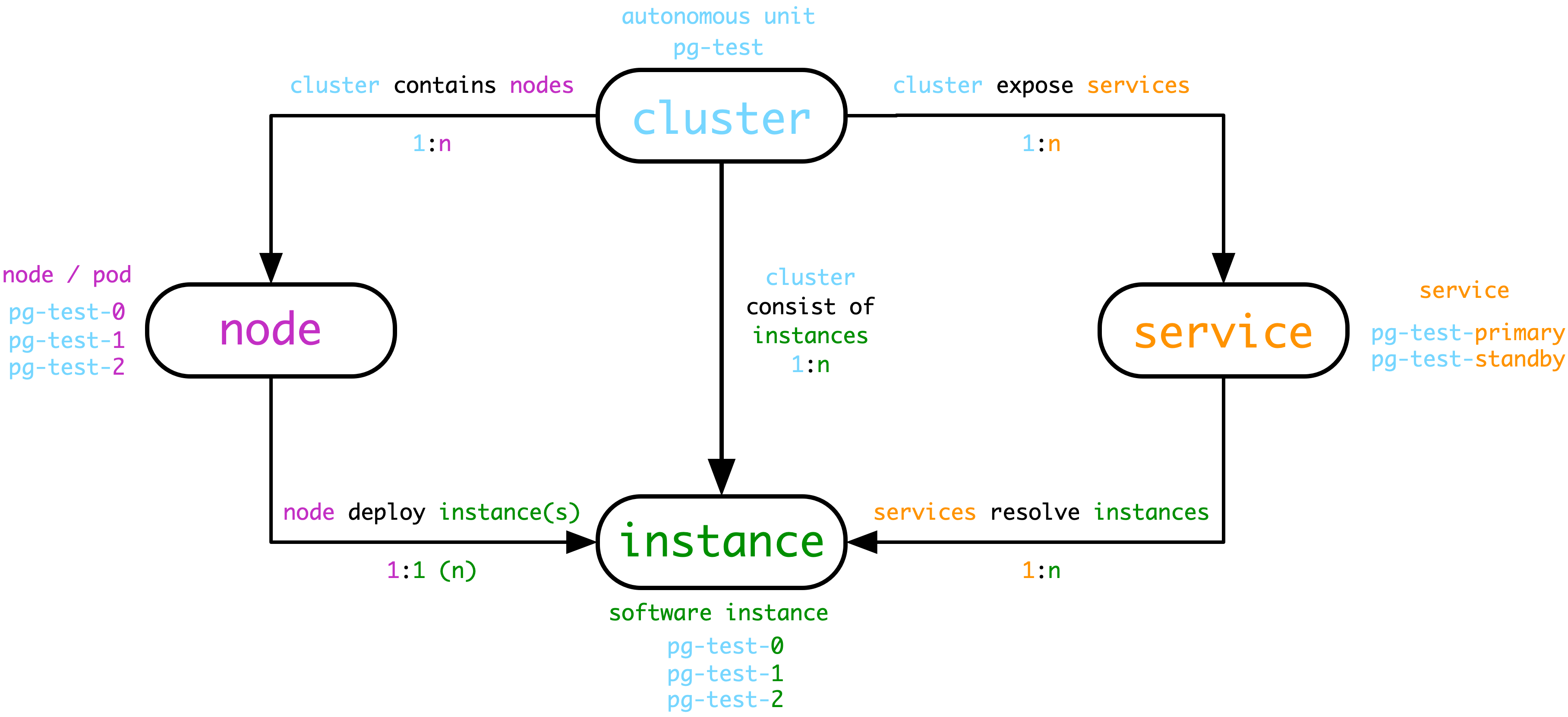
In the above figure, for example, the database cluster used for testing is named ``pg-test'', which consists of three database server instances, one master and two slaves, deployed on the three nodes belonging to the cluster. The pg-testcluster cluster provides two services to the outside world, the read-write servicepg-test-primaryand the read-only copy servicepg-test-replica`.
Entities
In Postgres cluster management, there are the following entity concepts.
Cluster (Cluster)
A cluster is the basic autonomous business unit, which means that the cluster can be organized as a whole to provide services to the outside world. Similar to the concept of Deployment in k8s. Note that Cluster here is a software level concept, not to be confused with PG Cluster (Database Set Cluster, i.e. a data directory containing multiple PG Databases with a single PG instance) or Node Cluster (Machine Cluster).
A cluster is one of the basic units of management, an organizational unit used to unify various resources. For example, a PG cluster may include.
- Three physical machine nodes
- One master instance, which provides database read and write services to the external world.
- Two slave instances, which provide read-only copies of the database to the public.
- Two externally exposed services: read-write service, read-only copy service.
Each cluster has a unique identifier defined by the user according to the business requirements. In this example, a database cluster named pg-test is defined.
Nodes (Node)
Node is an abstraction of a hardware resource, usually referring to a working machine, either a physical machine (bare metal) or a virtual machine (vm), or a Pod in k8s. note here that Node in k8s is an abstraction of a hardware resource, but in terms of actual management use, it is the Pod in k8s rather than the Node that is more similar to the Node concept here. In short, the key elements of a Node are.
- Node is an abstraction of a hardware resource that can run a range of software services
- Nodes can use IP addresses as unique identifiers
Although the lan_ip address can be used as the node unique identifier, for ease of management, the node should have a human-readable meaning-filled name as the node’s Hostname, as another common node unique identifier.
Service
A service is a named abstraction of a software service (e.g. Postgres, Redis). Services can be implemented in a variety of ways, but their key elements are.
- an addressable and accessible service name for providing access to the outside world, for example.
- A DNS domain name (
pg-test-primary)
- An Nginx/Haproxy Endpoint
- ** Service traffic routing resolution and load balancing mechanism** for deciding which instance is responsible for handling requests, e.g.
- DNS L7: DNS resolution records
- HTTP Proxy: Nginx/Ingress L7: Nginx Upstream configuration
- TCP Proxy: Haproxy L4: Haproxy Backend configuration
- Kubernetes: Ingress: Pod Selector Selector.
The same dataset cluster usually includes a master and a slave, both of which provide read and write services (primary) and read-only copy services (replica), respectively.
Instance
An instance refers to a specific database server**, which can be a single process, a group of processes sharing a common fate, or several closely related containers within a Pod. The key elements of an instance are.
- Can be uniquely identified by IP:Port
- Has the ability to process requests
For example, we can consider a Postgres process, the exclusive Pgbouncer connection pool that serves it, the PgExporter monitoring component, the high availability component, and the management Agent as a whole that provides services as a single database instance.
Instances are part of a cluster, and each instance has its own unique identifier to distinguish it within the cluster.
The instances are resolved by the Service, which provides the ability to be addressed, and the Service resolves the request traffic to a specific set of instances.
Naming Rules
An object can have many groups of Tags and Metadata/Annotation, but can usually have only one Name.
Managing databases and software is similar to managing pets in that it takes care of them. And naming is one of those very important tasks. Unbridled names (e.g. XÆA-12, NULL, Shi Zhenxiang) are likely to introduce unnecessary hassles (extra complexity), while properly designed names may have unexpected and surprising effects.
In general, object naming should follow some principles.
-
Simple and straightforward, human readable: the name is for people, so it should be memorable and easy to use.
-
Reflect the function, reflect the characteristics: the name needs to reflect the key features of the object
-
Unique, uniquely identifiable: the name should be unique in the namespace, under its own class, and can uniquely identify addressable.
-
Don’t cram too much extraneous stuff into the name: embedding a lot of important metadata in the name is an attractive idea, but can be very painful to maintain, e.g. counter example: pg:user:profile:10.11.12.13:5432:replica:13.
Cluster naming
The cluster name, in fact, is similar to the role of a namespace. All resources that are part of this cluster use this namespace.
For the form of cluster naming, it is recommended to use naming rules that conform to the DNS standard RFC1034 so as not to bury a hole for subsequent transformation. For example, if you want to move to the cloud one day and find that the name you used before is not supported, you will have to change the name again, which is costly.
I think a better approach would be to adopt a stricter restriction: cluster names should not include dots (dot). Only lowercase letters, numbers, and minus hyphens (hyphen)- should be used. This way, all objects in the cluster can use this name as a prefix for a wide variety of places without worrying about breaking certain constraints. That is, the cluster naming rule is
cluster_name := [a-z][a-z0-9-]*
The reason for emphasizing not to use dots in cluster names is that a naming convention used to be popular, such as com.foo.bar. That is, the hierarchical naming method split by points. Although this naming style is concise and quick, there is a problem that there may be arbitrarily many levels in the name given by the user, and the number is not controllable. Such names can cause trouble if the cluster needs to interact with an external system that has some constraints on naming. One of the most intuitive examples is Pod in K8s, where Pod naming rules do not allow . .
Connotation of cluster naming, -separated two-paragraph, three-paragraph names are recommended, e.g.
<cluster type>-<business>-<business line
For example: pg-test-tt would indicate a test cluster under the tt line of business, type pg. pg-user-fin indicates user service under the fin line of business.
Node naming
The recommended naming convention for nodes is the same as for k8s Pods, i.e.
<cluster_name>-<seq>
Node names are determined during the cluster resource allocation phase, and each node is assigned a serial number ${seq}, a self-incrementing integer starting at 0. This is consistent with the naming rules of StatefulSet in k8s, so it can be managed consistently on and off the cloud.
For example, the cluster pg-test has three nodes, so these three nodes can be named as
pg-test-1, pg-test-2 and pg-test-3.
The nodes are named in such a way that they remain the same throughout the life of the cluster for easy monitoring and management.
Instance naming
For databases, exclusive deployment is usually used, where one instance occupies the entire machine node. pg instances are in one-to-one correspondence with Nodes, so you can simply use the identifier of the Node as the identifier of the Instance. For example, the name of the PG instance on node pg-test-1 is: pg-test-1, and so on.
There is a great advantage in using exclusive deployment, where one node is one instance, which minimizes the management complexity. The need to mix parts usually comes from the pressure of resource utilization, but virtual machines or cloud platforms can effectively solve this problem. With vm or pod abstraction, even each redis (1 core 1G) instance can have an exclusive node environment.
As a convention, node 0 (Pod), in each cluster, will be used as the default primary library. This is because it is the first node allocated at initialization.
Service naming
Generally speaking, the database provides two basic services externally: primary read-write service, and replica read-only copy service.
Then the services can be named using a simple naming rule: ``primary`''
<cluster_name>-<service_name>
For example, here the pg-test cluster contains two services: the read-write service pg-test-primary and the read-only replica service pg-test-replica.
A popular instance/node naming rule: <cluster_name>-<service_role>-<sequence>, where the master-slave identity of the database is embedded in the instance name. This naming convention has both advantages and disadvantages. The advantage is that you can tell at a glance which instance/node is the master and which is the slave when managing it. The disadvantage is that once Failover occurs, the names of instances and nodes must be adjusted to maintain persistence, which creates additional maintenance work. In addition, service and node instances are relatively independent concepts, and this Embedding nomenclature distorts this relationship by uniquely affiliating instances to services. However, this assumption may not be satisfied in complex scenarios. For example, a cluster may have several different ways of dividing services, and there is likely to be overlap between the different divisions.
- Readable slave (resolves to all instances including the master)
- Synchronous slave (resolves to a backup library that uses synchronous commits)
- Deferred slave, backup instances (resolves to a specific specific instance)
So instead of embedding the service role in the instance name, maintain a list of target instances in the service. After all, names are not all-powerful, so don’t embed too much non-essential information into the object names.
3.2 - Architecture
Introduction to Pigsty Architecture
A Pigsty deployment is architecturally divided into two parts.
- Infrastructure : deployed on meta nodes, monitoring, DNS, NTP, DCS, Yum sources, etc. basic services.
- [Database Cluster](#Database Cluster) (PgSQL) : Deployed on database nodes to provide database services to the outside world as a cluster.
Also, the nodes (physical machines, virtual machines, Pods) used for deployment are divided into two types.
- Metanode (Meta): deploying infrastructure, executing control logic, at least one metanode is required for each Pigsty deployment.
- [Database Node](#Database Node) (Node): used to deploy database clusters/instances, nodes correspond to database instances one by one.
Sample sandbox
Using the four-node sandbox environment that comes with Pigsty as an example, the distribution of components on the nodes is shown in the following figure.
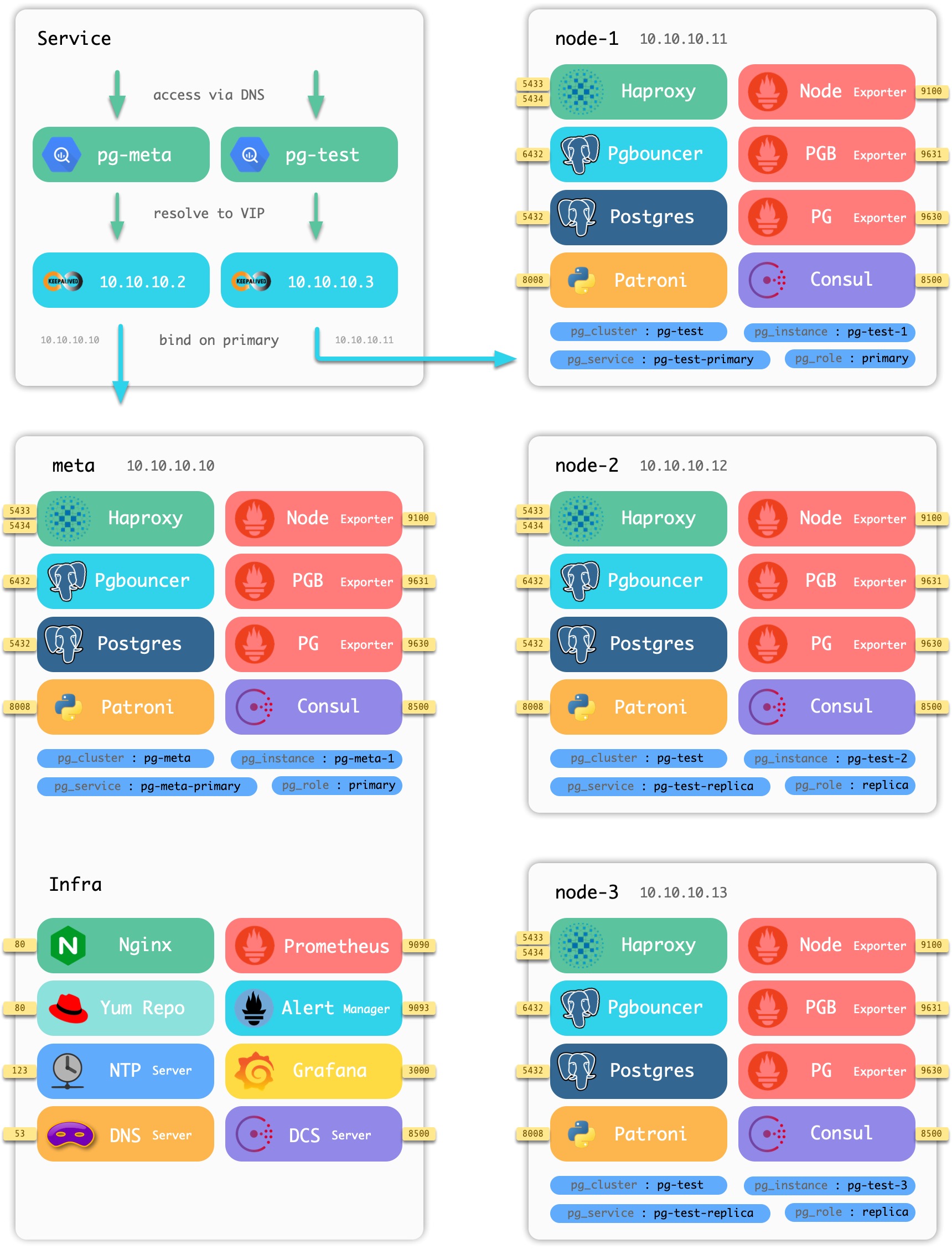
Figure : Nodes and components contained in the Pigsty sandbox
The sandbox consists of a [meta node](#meta node) and four [database nodes](#database nodes) (the meta node is also reused as a database node), deployed with one set of infrastructure and two sets of [database clusters](#database clusters). meta is a meta-node, deployed with infrastructure components, also multiplexed as a common database node, deployed with a single master database cluster pg-meta. node-1, node-2, node-3 are normal database nodes, deployed with database cluster pg-test.
Infrastructure
Each set of Pigsty [deployment](. /… /deploy/) (Deployment) requires some infrastructure to make the whole system work properly.
Infrastructure is usually handled by a professional Ops team or cloud vendor, but Pigsty, as an out-of-the-box product solution, integrates the basic infrastructure into the provisioning solution.
- Domain infrastructure: Dnsmasq (some requests are forwarded to Consul DNS for processing)
- Time infrastructure: NTP
- Monitoring infrastructure: Prometheus
- Alarm infrastructure: Altermanager
- Visualization infrastructure: Grafana
- Local source infrastructure: Yum/Nginx
- Distributed Configuration Storage: etcd/consul
- Pigsty infrastructure: MetaDB meta-database, management component Ansible, timed tasks, with other advanced feature components.
The infrastructure is deployed on meta nodes. A set of environments containing one or more meta-nodes for infrastructure deployment.
All infrastructure components are deployed replica-style except for Distributed Configuration Store (DCS); if there are multiple meta-nodes, the DCS (etcd/consul) on the meta-nodes act together as the DCS Server.
In each environment, Pigsty at a minimum requires a meta-node that will act as the control center for the entire environment. The meta-node is responsible for various administrative tasks: saving state, managing configuration, initiating tasks, collecting metrics, and so on. The infrastructure components of the entire environment, Nginx, Grafana, Prometheus, Alertmanager, NTP, DNS Nameserver, and DCS, will be deployed on the meta node.
The meta node will also be used to deploy the meta database (Consul or Etcd), and users can also use existing external DCS clusters. If deploying DCS to a meta-node, it is recommended that 3 meta-nodes be used in a production environment to fully guarantee the availability of DCS services. infrastructure components outside of DCS will be deployed as peer-to-peer copies on all meta-nodes. The number of meta-nodes requires a minimum of 1, recommends 3, and recommends no more than 5.
The services running on the meta-nodes are shown below.
| component |
port |
default domain |
description |
| Grafana |
3000 |
g.pigsty |
Pigsty Monitoring System GUI |
| Prometheus |
9090 |
p.pigsty |
Monitoring Timing Database |
| AlertManager |
9093 |
a.pigsty |
Alarm aggregation management component |
| Consul |
8500 |
c.pigsty |
Distributed Configuration Management, Service Discovery |
| Consul DNS |
8600 |
- |
Consul-provided DNS services |
| Nginx |
80 |
pigsty |
Entry proxy for all services |
| Yum Repo |
80 |
yum.pigsty |
Local Yum sources |
| Haproxy Index |
80 |
h.pigsty |
Access proxy for all Haproxy management interfaces |
| NTP |
123 |
n.pigsty |
The NTP time server used uniformly by the environment |
| Dnsmasq |
53 |
- |
The DNS name resolution server used by the environment |
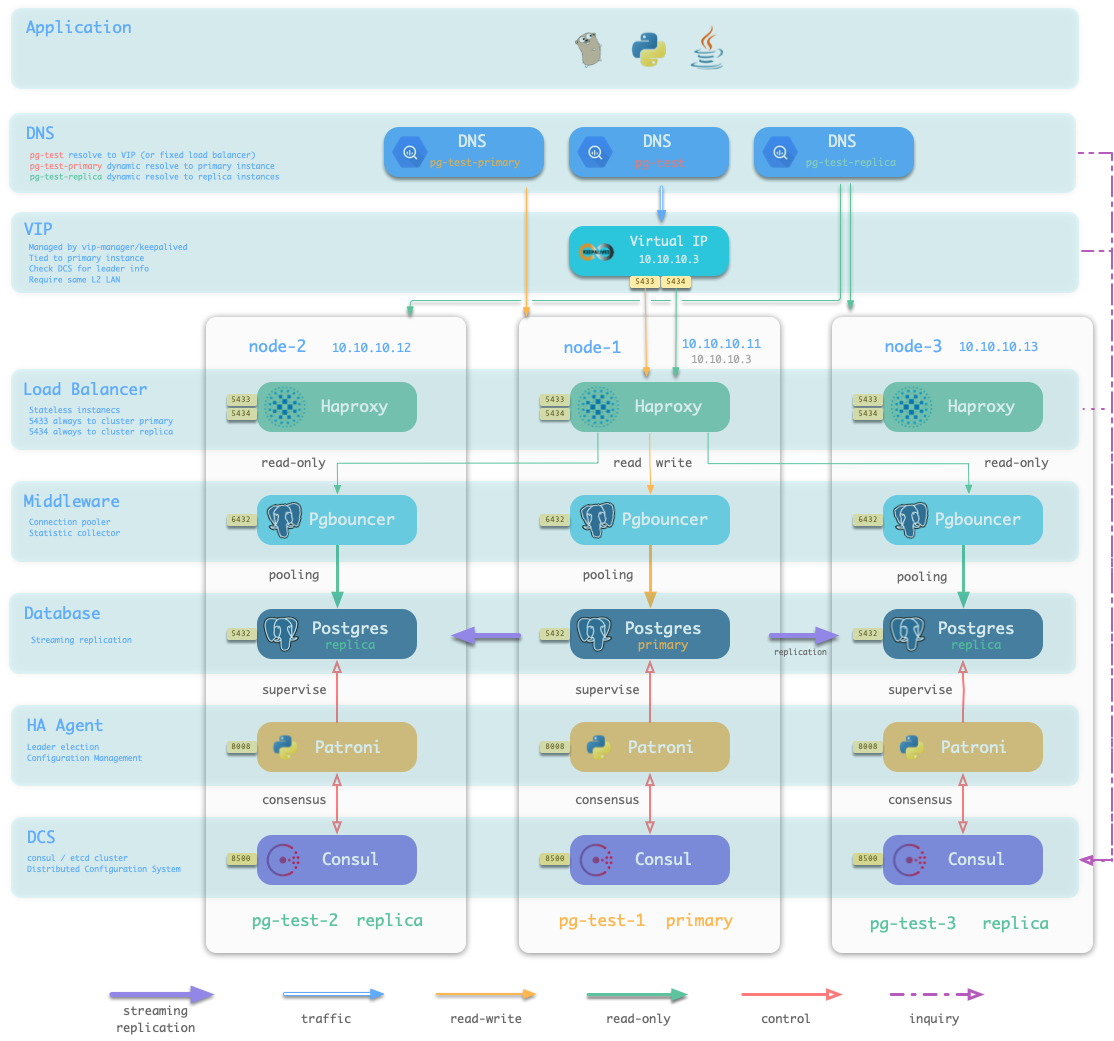
The base setup architecture deployed on the meta-node is shown in the following figure.
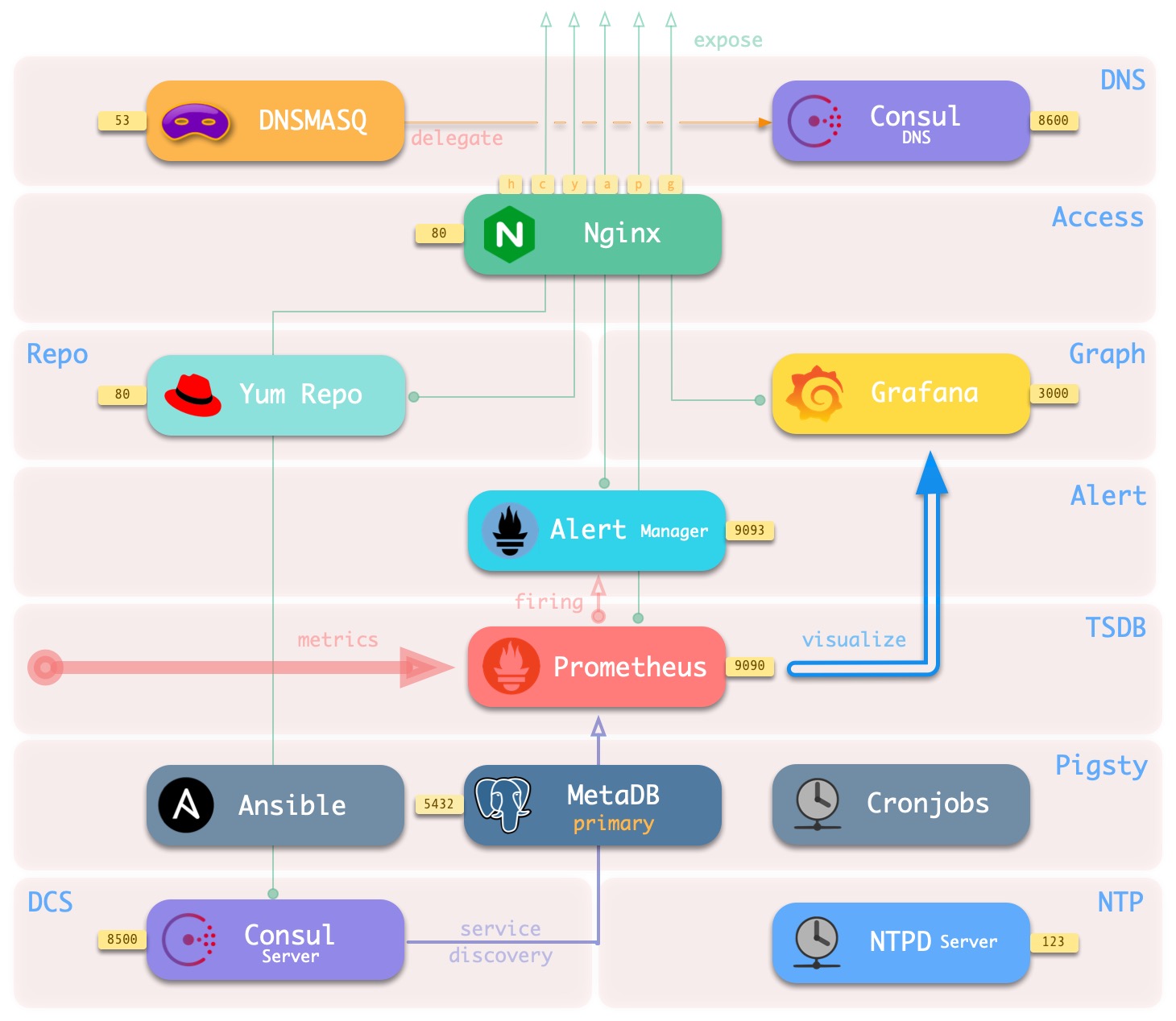
The main interactions are as follows.
-
Dnsmasq provides DNS resolution services within the environment (optional, can use existing Nameserver)
Some DNS resolution will ** be forwarded ** by Consul DNS
-
Nginx externally exposes all web services and forwards them differently by domain name.
-
Yum Repo is the default server for Nginx, providing the ability to install software from offline for all nodes in the environment.
-
Grafana is the carrier for the Pigsty monitoring system, used to visualize data in Prometheus and CMDB.
-
Prometheus is the timing database for monitoring.
- Prometheus fetches all Exporter to be crawled from Consul by default and associates identity information for them.
- Prometheus pulls monitoring metrics data from the Exporter, precomputes and processes it and stores it in its own TSDB.
- Prometheus calculates alarm rules and sends the alarm events to Alertmanager for processing.
-
Consul Server is used to save the status of DCS, reach consensus, and serve metadata queries.
-
NTP Service is used to synchronize the time of all nodes in the environment (external NTP service is optional)
-
Pigsty related components.
- Ansible for executing scripts, initiating control
- MetaDB for supporting various advanced features (also a standard database cluster)
- Timed task controller (backup, cleanup, statistics, patrol, advanced features not yet added)
Postgres clusters
Databases in production environments are organized in clusters, which clusters are a logical entity consisting of a set of database instances associated by master-slave replication. Each database cluster is a self-organizing business service unit consisting of at least one database instance.
Clusters are the basic business service units, and the following diagram shows the replication topology in a sandbox environment. Where pg-meta-1 alone constitutes a database cluster pg-meta, while pg-test-1, pg-test-2, and pg-test-3 together constitute another logical cluster pg-test.
pg-meta-1
(primary)
pg-test-1 -------------> pg-test-2
(primary) | (replica)
|pg-test-2
^ -------> pg-test-3
(replica)
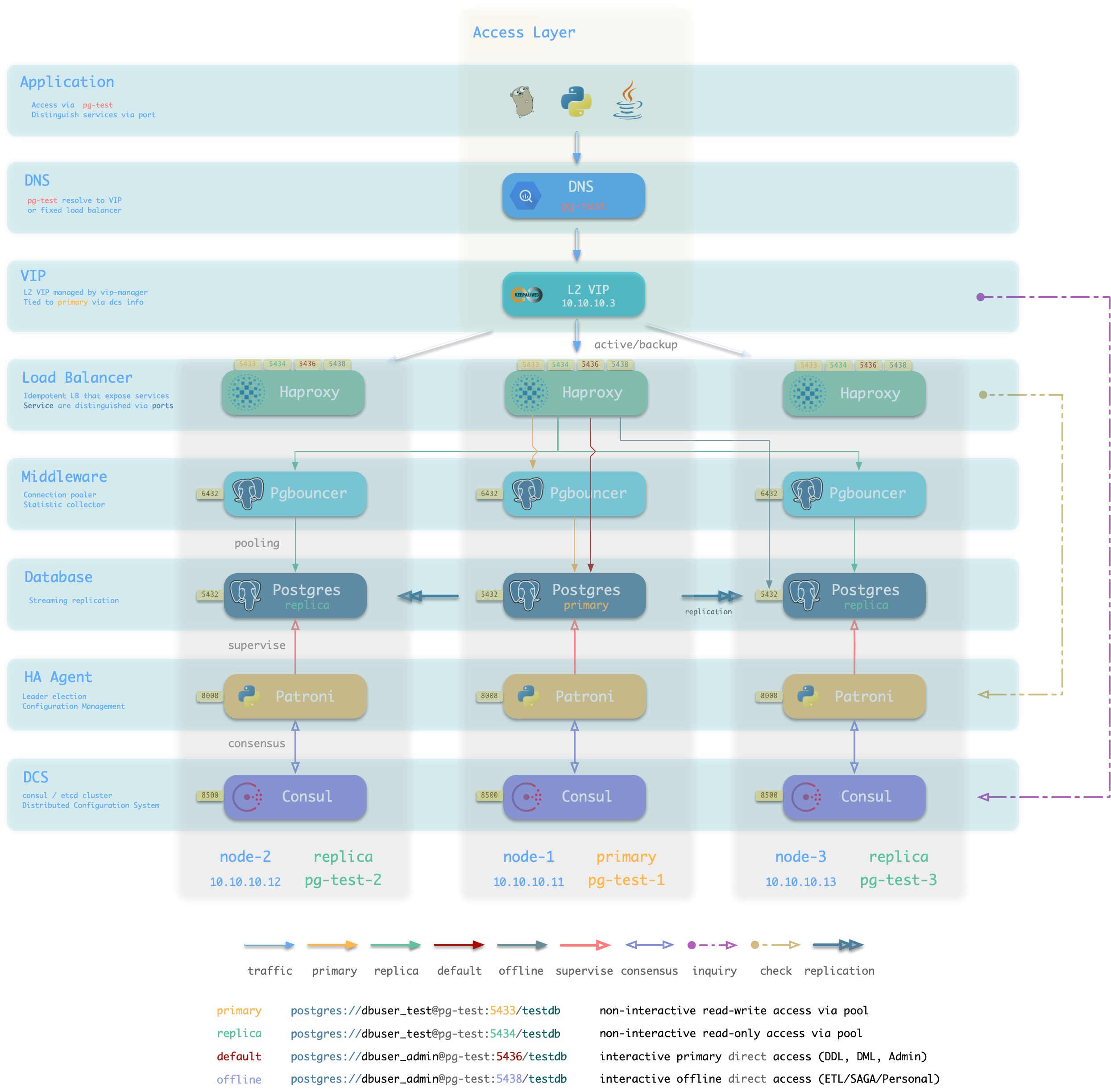
The following figure rearranges the location of related components in the pg-test cluster from the perspective of the database cluster.
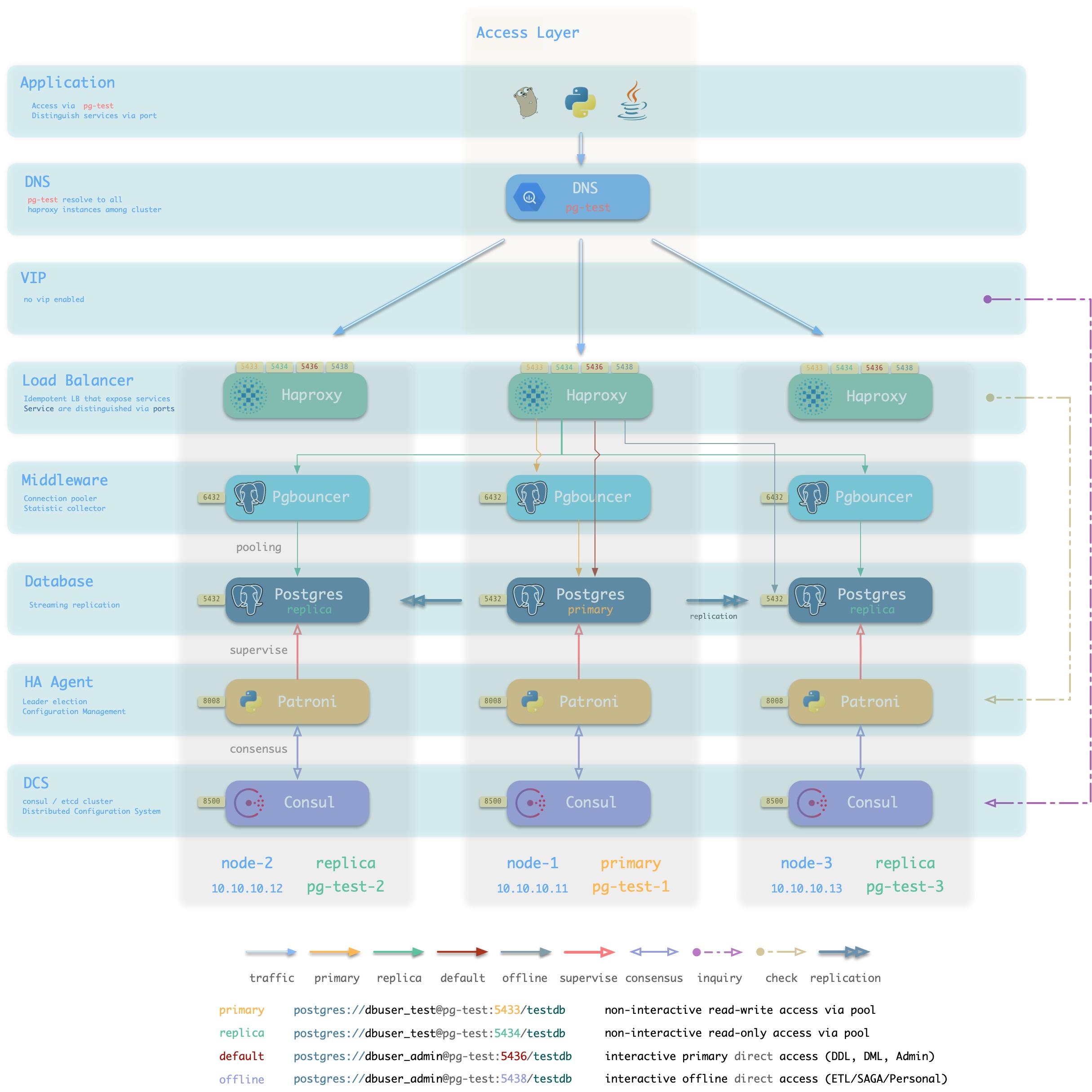
Figure : Looking at the architecture from the logical view of a database cluster ([standard access scenario](. /provision/access/#dns–haproxy))
Pigsty is a database provisioning solution that creates highly available database clusters on demand. Pigsty can automatically failover with business-side read-only traffic unaffected; the impact of read and write traffic is usually in the range of a few seconds to tens of seconds, depending on the specific configuration and load.
In Pigsty, each “database instance” is idempotent in use and is exposed to the public in a similar way to NodePort [database service](… /provision/service/). By default, access to port 5433 of any instance is sufficient to access the master database, and access to port 5434 of any instance is sufficient to access the slave database. Users also have the flexibility to use different ways to access the database at the same time, for details, please refer to: [Database Access](. /provision/access).
Database Nodes
A database node is responsible for running database instances. In Pigsty database instances are fixed using exclusive deployment, where there is one and only one database instance on a node, so nodes and database instances can be uniquely identified with each other (IP address and instance name).
A typical service running on a database node is shown below.
| component |
port |
description |
| Postgres |
5432 |
Postgres Database Service |
| Pgbouncer |
6432 |
Pgbouncer Connection Pooling Service |
| Patroni |
8008 |
Patroni High Availability Components |
| Consul |
8500 |
Distributed Configuration Management, Local Agent for Service Discovery Component Consul |
| Haproxy Primary |
5433 |
Cluster read and write service (primary connection pool) agent |
| Haproxy Replica |
5434 |
Cluster Read-Only Service (Slave Connection Pool) Agent |
| Haproxy Default |
5436 |
Cluster Master Direct Connect Service (for management, DDL/DML changes) |
| Haproxy Offline |
5438 |
Cluster Offline Read Service (directly connected offline instances, for ETL, interactive queries) |
| Haproxy <Service> |
543x |
Additional custom services provided by the cluster will be assigned ports in turn |
| Haproxy Admin |
9101 |
Haproxy Monitoring Metrics and Administration Page |
| PG Exporter |
9630 |
Postgres Monitoring Metrics Exporter |
| PGBouncer Exporter |
9631 |
Pgbouncer Monitoring Metrics Exporter |
| Node Exporter |
9100 |
Machine Node Monitoring Metrics Exporter |
| Consul DNS |
8600 |
DNS Services Provided by Consul |
| vip-manager |
x |
Bind VIPs to the cluster master |
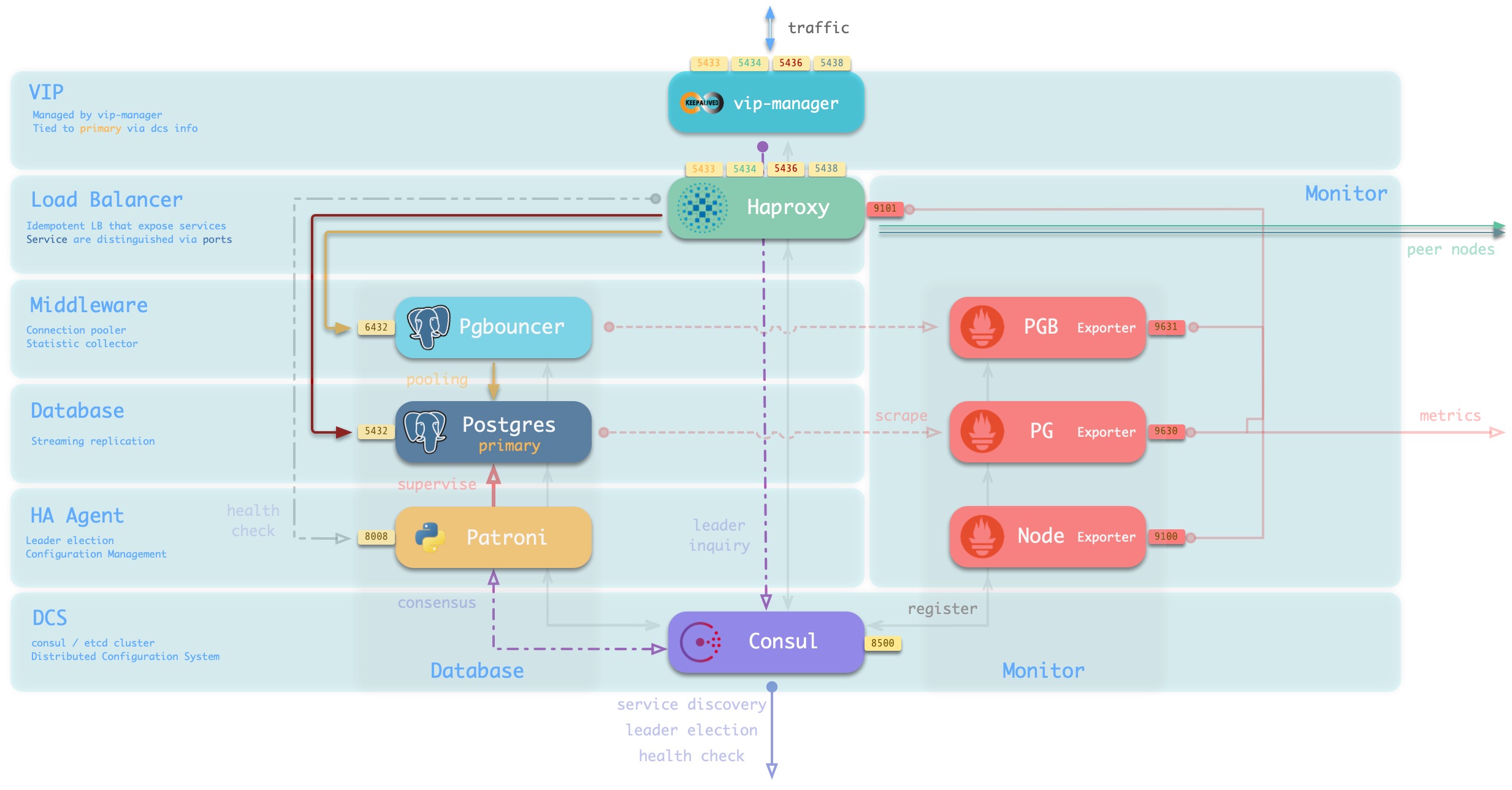
The main interactions are as follows.
-
vip-manager obtains cluster master information via query Consul and binds cluster-specific L2 VIPs to the master node (default access scheme).
-
Haproxy is the database traffic portal for exposing services to the outside world, using different ports (543x) to distinguish between different services.
- Haproxy port 9101 exposes Haproxy’s internal monitoring metrics, while providing an Admin interface to control traffic.
- Haproxy port 5433 points to the cluster master connection pool port 6432 by default
- Haproxy port 5434 points to the cluster slave connection pool port 6432 by default
- Haproxy 5436 port points directly to the cluster master 5432 port by default
- Haproxy 5438 port defaults to point directly to the cluster offline instance port 5432
-
Pgbouncer for pooling database connections, buffering failure shocks, and exposing additional metrics.
-
Production services (high frequency non-interactive, 5433/5434) must be accessed through Pgbouncer.
-
Directly connected services (management and ETL, 5436/5438) must bypass the Pgbouncer direct connection.
-
Postgres provides the actual database service, which constitutes a master-slave database cluster via stream replication.
-
Patroni is used to oversee the Postgres service and is responsible for master-slave election and switchover, health checks, and configuration management.
- Patroni uses Consul to reach consensus as the basis for cluster leader election.
-
Consul Agent is used to issue configurations, accept service registrations, service discovery, and provide DNS queries.
- All process services using the port are registered into Consul
-
PGB Exporter, PG Exporter, Node Exporter are used to ** expose ** database, connection pool, and node monitoring metrics respectively
As an example of an environment consisting of a single [meta-node](# meta-node) and a single [database node](# database node), the architecture is shown in the following figure.
Figure : Single meta-node and single database node (click for larger image)
The interaction between meta nodes and database nodes mainly includes.
-
Database cluster/node’s domain name relies on the meta-node’s Nameserver for resolution.
-
Database node software installation needs to use Yum Repo on the meta node.
-
Database cluster/node monitoring metrics are collected by Prometheus on the meta node.
-
Pigsty will initiate management of the database nodes from the meta node
Perform cluster creation, capacity expansion and contraction, user, service, HBA modification; log collection, garbage cleanup, backup, patrol, etc.
-
Consul of the database node will synchronize locally registered services to the DCS of the meta node and proxy state read and write operations.
-
Database node will synchronize time from meta node (or other NTP server)
3.3 - Monitoring
Concepts about pigsty monitoring system
3.3.1 - Hierarchy
Introduction to pigsty monitoring system hierarchy
As in Naming Principle, objects in Pigsty are divided into multiple levels: clusters, services, instances, and nodes.
Monitoring system hierarchy
Pigsty’s monitoring system has more layers. In addition to the two most common layers, Instance and Cluster, there are other layers of organization throughout the system. From the top down, there are 7 levels: **Overview, Slice, Cluster, Service, Instance, Database, Object. **

Figure : Pigsty’s monitoring panel is divided into 7 logical hierarchies and 5 implementation hierarchies
Logical levels
Databases in production environments are often organized in clusters, which are the basic business service units and the most important level of monitoring.
A cluster is a set of database instances associated by master-slave replication, and instance is the most basic level of monitoring.
Whereas multiple database clusters together form a real-world production environment, the Overview level of monitoring provides an overall description of the entire environment.
Multiple database clusters serving the same business in a horizontally split pattern are called Shards, and monitoring at the shard level is useful for locating data distribution, skew, and other issues.
Service is the layer sandwiched between the cluster and the instance, and the service is usually closely associated with resources such as DNS, domain names, VIPs, NodePort, etc.
Database is a sub-instance level object where a database cluster/instance may have multiple databases existing at the same time, and database level monitoring is concerned with activity within a single database.
Object are entities within a database, including tables, indexes, sequence numbers, functions, queries, connection pools, etc. Object-level monitoring focuses on the statistical metrics of these objects, which are closely related to the business.
Hierarchical Streamlining
As a streamlining, just as the OSI 7-layer model for networking was reduced in practice to a five-layer model for TCP/IP, these seven layers were also reduced to five layers bounded by Clusters and Instances: Overview , Clusters , Services , Instance , Databases .
This makes the final hierarchy very concise: all information above the cluster level is the Overview level, all monitoring below the instance level is counted as the Database level, and sandwiched between the Cluster and Instance is the Service level.
Naming Rules
After the hierarchy, the most important issue is naming.
-
there needs to be a way to identify and refer to the components within the different layers of the system.
-
the naming convention should reasonably reflect the hierarchical relationship of the entities in the system
-
the naming scheme should be automatically generated according to the rules, so that it can run maintenance-free and automatically when the cluster is scaled up and down and Failover.
Once we have clarified the hierarchy of the system, we can proceed to name each entity in the system.
For the basic naming rules followed by Pigsty, please refer to Naming Principles section.
Pigsty uses an independent name management mechanism and the naming of entities is self-contained.
If you need to interface with external systems, you can use this naming system directly, or adopt your own naming system by transferring the adaptation.
Cluster Naming
Pigsty’s cluster names are specified by the user and satisfy the regular expression of [a-z0-9][a-z0-9-]*, in the form of pg-test, pg-meta.
node naming
Pigsty’s nodes are subordinate to clusters. pigsty’s node names consist of two parts: [cluster name](#cluster naming) and node number, and are concatenated with -.
The form is ${pg_cluster}-${pg_seq}, e.g. pg-meta-1, pg-test-2.
Formally, node numbers are natural numbers of reasonable length (including 0), unique within the cluster, and each node has its own number.
Instance numbers can be explicitly specified and assigned by the user, usually using an assignment starting from 0 or 1, once assigned, they do not change again for the lifetime of the cluster.
Instance Naming
Pigsty’s instance is subordinate to the cluster and is deployed in an exclusive node style.
Since there is a one-to-one correspondence between instances and nodes, the instance name remains the same as the node life.
Service Naming
Pigsty’s Service is subordinate to the cluster. pigsty’s service name consists of two parts: [cluster name](#cluster naming) and Role, and is concatenated with -.
The form is ${pg_cluster}-${pg_role}, e.g. pg-meta-primary, pg-test-replica.
The options available for pg_role include: primary|replica|offline|delayed.
primary is a special role that each cluster must and can only define one instance of pg_role = primary as the primary library.
The other roles are largely user-defined, with replica|offline|delayed being a Pigsty predefined role.
What next?
After delineating the monitoring hierarchy, you need to [assign identity] to the monitoring object (../identity) to be able to manage them.
3.3.2 - Observability
From raw information to insight
对于系统管理来说,最重要到问题之一就是可观测性(Observability),下图展示了Postgres的可观测性。

原图地址:https://pgstats.dev/
PostgreSQL 提供了丰富的观测接口,包括系统目录,统计视图,辅助函数。 这些都是用户可以观测的信息。这里列出的信息全部为Pigsty所收录。Pigsty通过精心的设计,将晦涩的指标数据,转换成了人类可以轻松理解的洞察。
可观测性
经典的监控模型中,有三类重要信息:
- 指标(Metrics):可累加的,原子性的逻辑计量单元,可在时间段上进行更新与统计汇总。
- 日志(Log):离散事件的记录与描述
- 追踪(Trace):与单次请求绑定的相关元数据
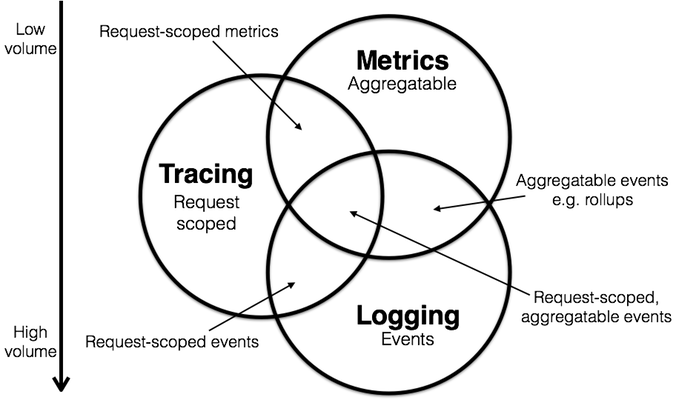
Pigsty重点关注 指标 信息,也会在后续加入对 日志 的采集、处理与展示,但Pigsty不会收集数据库的 追踪 信息。
指标
下面让以一个具体的例子来介绍指标的获取及其加工产物。
pg_stat_statements是Postgres官方提供的统计插件,可以暴露出数据库中执行的每一类查询的详细统计指标。
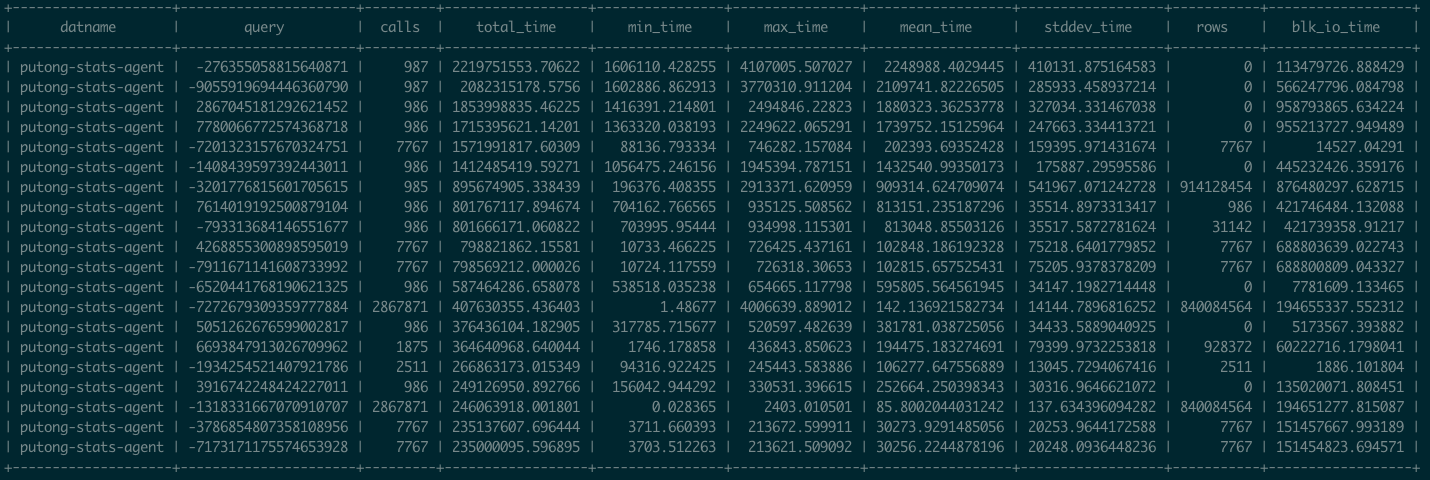
图:pg_stat_statements原始数据视图
这里pg_stat_statements提供的原始指标数据以表格的形式呈现。每一类查询都分配有一个查询ID,紧接着是调用次数,总耗时,最大、最小、平均单次耗时,响应时间都标准差,每次调用平均返回的行数,用于块IO的时间这些指标,(如果是PG13,还有更为细化的计划时间、执行时间、产生的WAL记录数量等新指标)。
这些系统视图与系统信息函数,就是Pigsty中指标数据的原始来源。直接查阅这种数据表很容易让人眼花缭乱,失去焦点。需要将这种指标转换为洞察,也就是以直观图表的方式呈现。
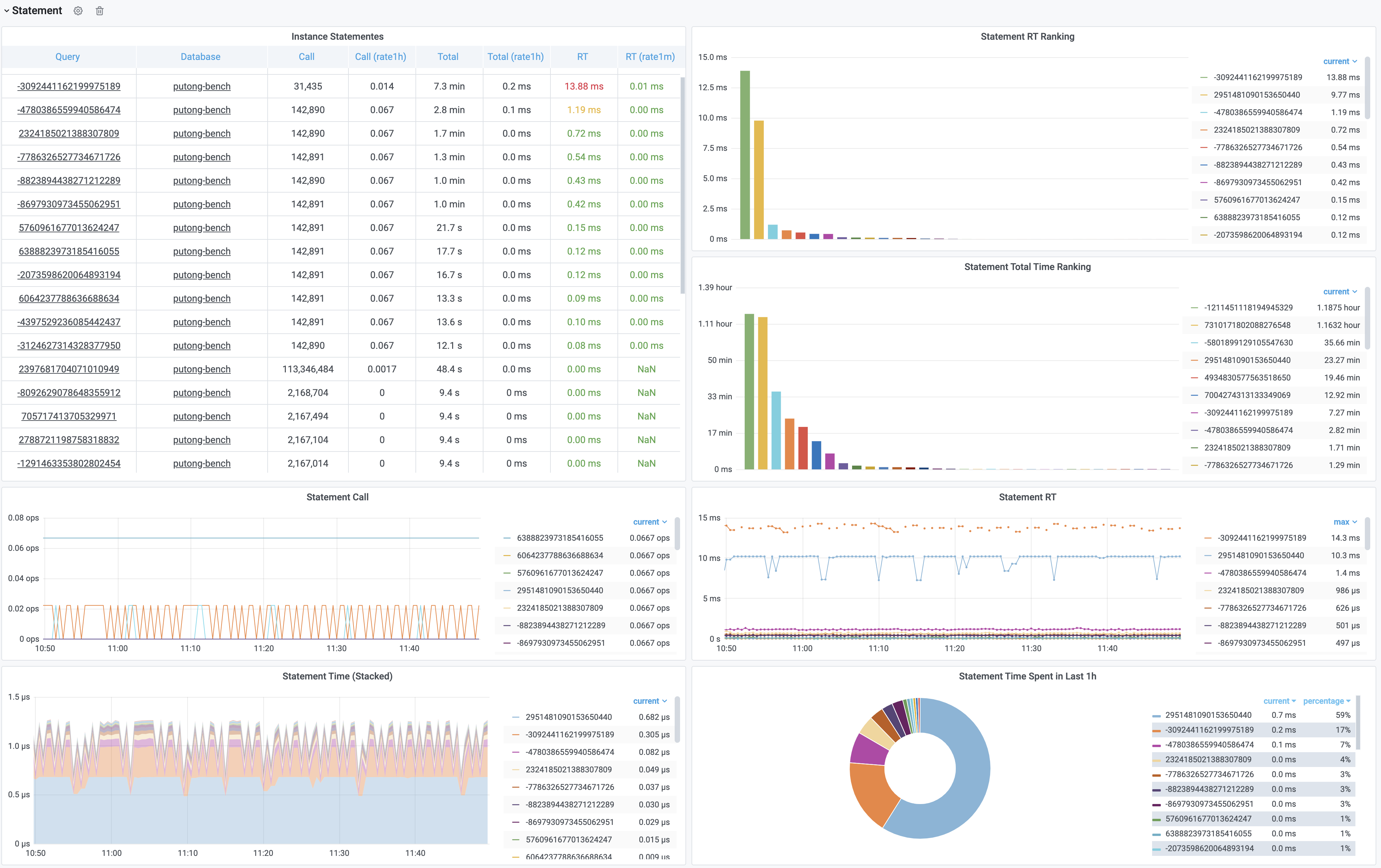
图:加工后的相关监控面板,PG Cluster Query看板部分截图
这里的表格数据经过一系列的加工处理,最终呈现为若干监控面板。最基本的数据加工是对表格中的原始数据进行标红上色,但也足以提供相当实用的改进:慢查询一览无余,但这不过是雕虫小技。重要的是,原始数据视图只能呈现当前时刻的快照;而通过Pigsty,用户可以回溯任意时刻或任意时间段。获取更深刻的性能洞察。
上图是集群视角下的查询看板 (PG Cluster Query),用户可以看到整个集群中所有查询的概览,包括每一类查询的QPS与RT,平均响应时间排名,以及耗费的总时间占比。
当用户对某一类具体查询感兴趣时,就可以点击查询ID,跳转到查询详情页(PG Query Detail)中。如下图所示。这里会显示查询的语句,以及一些核心指标。
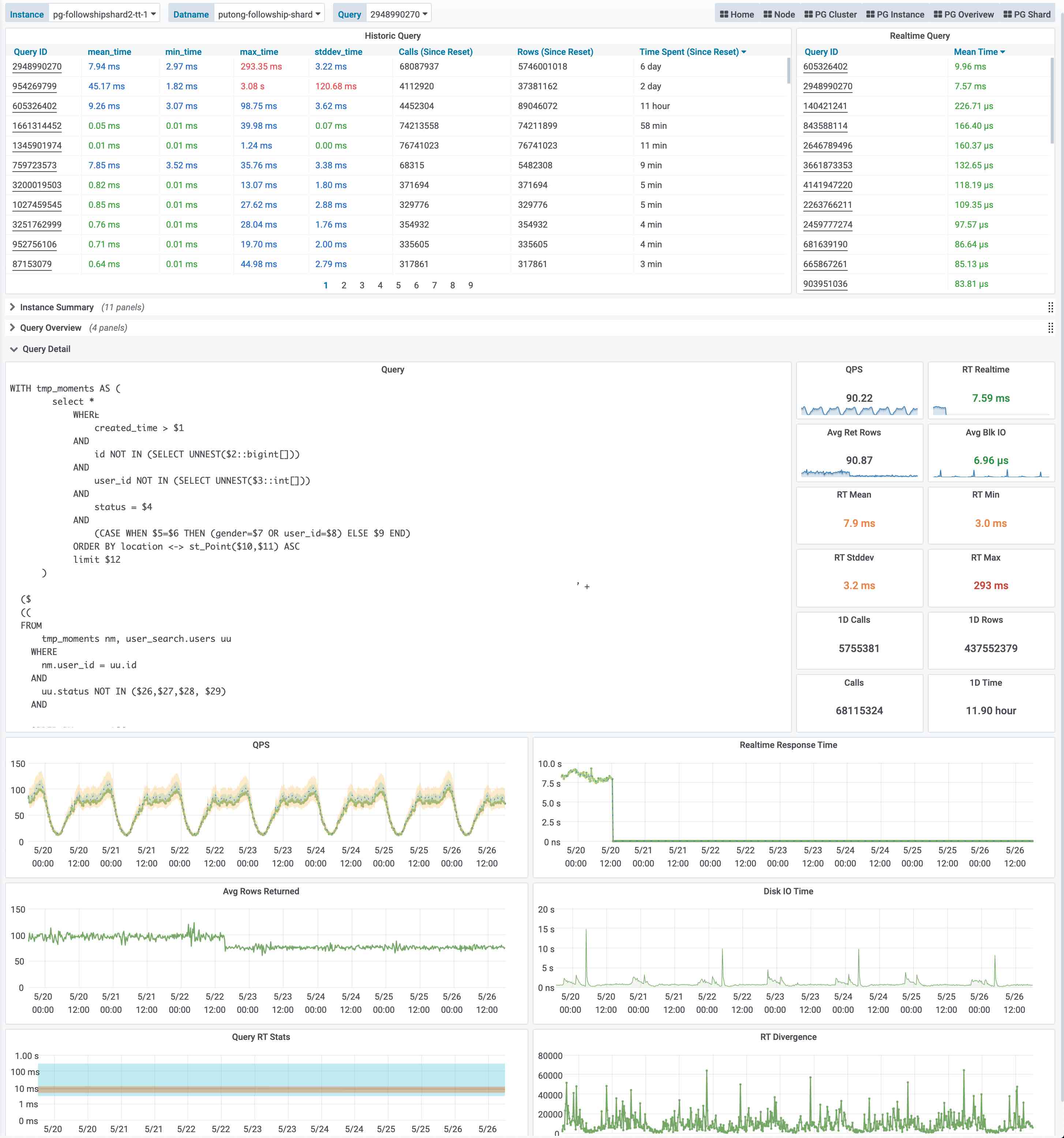
图:呈现单类查询的详细信息,PG Query Detail 看板截图
上图是实际生产环境中的一次慢查询优化记录,用户可以从右侧中间的Realtime Response Time 面板中发现一个突变。该查询的平均响应时间从七八秒突降到了七八毫秒。我们定位到了这个慢查询并添加了适当的索引,那么优化的效果就立刻在图表上以直观的形式展现出来,给出实时的反馈。
这就是Pigsty需要解决的核心问题:From observability to insight。
日志
除了指标外,还有一类重要的观测数据:日志(Log),日志是对离散事件的记录与描述。
如果说指标是对数据库系统的被动观测,那么日志就是数据库系统及其周边组件主动上报的信息。
Pigsty目前尚未对数据库日志进行挖掘,但在后续的版本中将集成pgbadger与mtail,引入日志统一收集、分析、处理的基础设施。并添加数据库日志相关的监控指标。
用户可以自行使用开源组件对PostgreSQL日志进行分析。
追踪
PostgreSQL提供了对DTrace的支持,用户也可以使用采样探针分析PostgreSQL查询执行时的性能瓶颈。但此类数据仅在某些特定场景会用到,实用性一般,因此Pigsty不会针对数据库收集Trace数据。
接下来?
只有指标并不够,我们还需要将这些信息组织起来,才能构建出体系来。阅读 监控层级 了解更多信息
3.3.3 - Identity Management
How does identity been managed in pigsty?
All instances have Identity, which is the metadata associated with the instance that identifies it.
!
Figure : Identity information with Postgres service when using Consul service discovery
Identity parameters
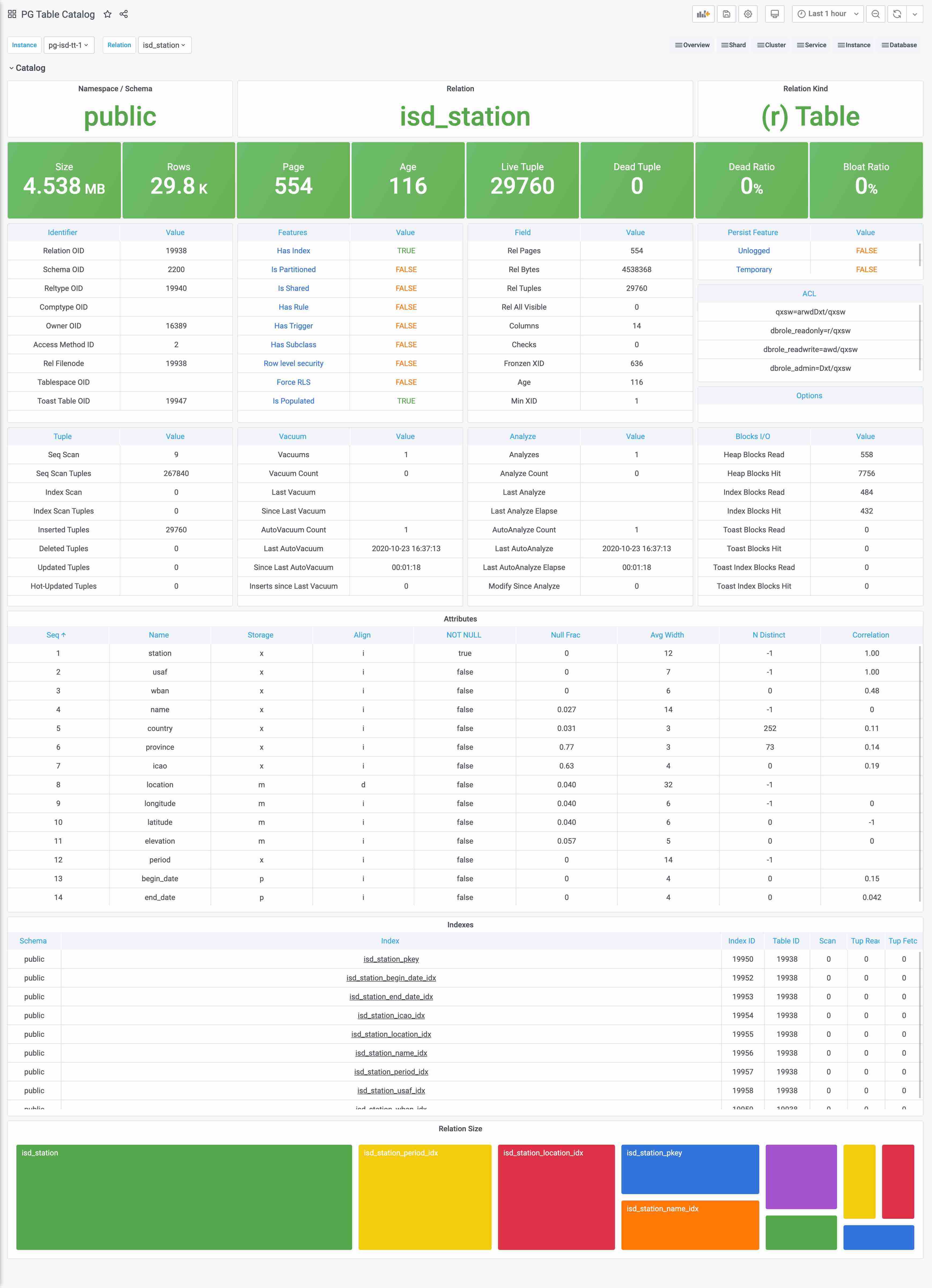
[identity-parameters](. /… /… /config/7-pg-provision/# identity-parameters) is a unique identifier that must be defined for any cluster and instance.
| name |
variables |
type |
description |
|
| cluster |
[pg_cluster](… /… /… /config/7-pg-provision/#pg_cluster) |
Core identity parameters |
Cluster name, top-level namespace for resources within the cluster |
|
| role |
[pg_role](. /… /… /config/7-pg-provision/#pg_role) |
Core identity parameters |
Instance role, primary, replica, offline, … |
|
| markers |
[pg_seq](… /… /… /config/7-pg-provision/#pg_seq) |
Core identity parameters |
Instance serial number, positive integer, unique within the cluster. |
|
| instance |
pg_instance |
derived identity parameter |
${pg_cluster}-${pg_seq} |
|
| service |
pg_service |
derived identity parameters |
${pg_cluster}-${pg_role} |
|
Identity association
After naming the objects in the system, you also need to associate identity information to specific instances.
Identity information is business-given metadata, and the database instance itself is not aware of this identity information; it does not know who it serves, which business it is subordinate to, or what number of instances it is in the cluster.
Identity assignment can take many forms, and the most rudimentary way to associate identities is Operator’s memory: the DBA remembers in his mind that the database instance on IP address 10.2.3.4 is the one used for payments, while the database instance on the other one is used for user management. A better way to manage the identity of cluster members is through profile, or by using service discovery.
Pigsty offers both ways of identity management: based on [Consul](. /identity/#consul service discovery), versus [Profile](. /identity/#static file service discovery)
Parameters [prometheus_sd_method (consul|static)](… /… /… /config/4-meta/#prometheus_sd_method) controls this behavior.
consul: service discovery based on Consul, default configurationstatic: service discovery based on local configuration files
Pigsty recommends using consul service discovery, where the monitoring system automatically corrects the identity registered by the target instance when a Failover occurs on the server.
Consul service discovery
Pigsty by default uses Consul service discovery to manage the services in your environment.
All services in Pigsty are automatically registered to the DCS, so metadata is automatically corrected when database clusters are created, destroyed, or modified, and the monitoring system can automatically discover monitoring targets without the need to manually maintain the configuration. The monitoring system can automatically discover the monitoring targets, eliminating the need for manual configuration maintenance.
Users can also use the DNS and service discovery mechanism provided by Consul to achieve automatic DNS-based traffic switching.
!
Consul uses a Client/Server architecture, and there are 1 to 5 Consul Servers ranging from 1 to 5 in the whole environment for the actual metadata storage. The Consul Agent is deployed on all nodes to proxy the communication between the native services and the Consul Server. pigsty registers the services by default by means of the local Consul configuration file.
Service Registration
On each node, there is a consul agent running, and services are registered to the DCS by the consul agent via JSON configuration files.
The default location of the JSON configuration file is /etc/consul.d/, using the naming convention of svc-<service>.json, using postgres as an example.
{
"service": {
"name": "postgres",
"port": {{ pg_port }},
"tags": [
"{{ pg_role }}",
"{{ pg_cluster }}"
],
"meta": {
"type": "postgres",
"role": "{{ pg_role }}",
"seq": "{{ pg_seq }}",
"instance": "{{ pg_instance }}",
"service": "{{ pg_service }}",
"cluster": "{{ pg_cluster }}",
"version": "{{ pg_version }}"
},
"check": {
"tcp": "127.0.0.1:{{ pg_port }}",
"interval": "15s",
"timeout": "1s"
}
}
}
其中meta与tags部分是服务的元数据,存储有实例的身份信息。
服务查询
用户可以通过Consul提供的DNS服务,或者直接调用Consul API发现注册到Consul中的服务
使用DNS API查阅consul服务的方式,请参阅Consul文档。
图:查询pg-bench-1上的 pg_exporter 服务。
服务发现
Prometheus会自动通过consul_sd_configs发现环境中的监控对象。同时带有pg和exporter标签的服务会自动被识别为抓取对象:
- job_name: pg
# https://prometheus.io/docs/prometheus/latest/configuration/configuration/#consul_sd_config
consul_sd_configs:
- server: localhost:8500
refresh_interval: 5s
tags:
- pg
- exporter
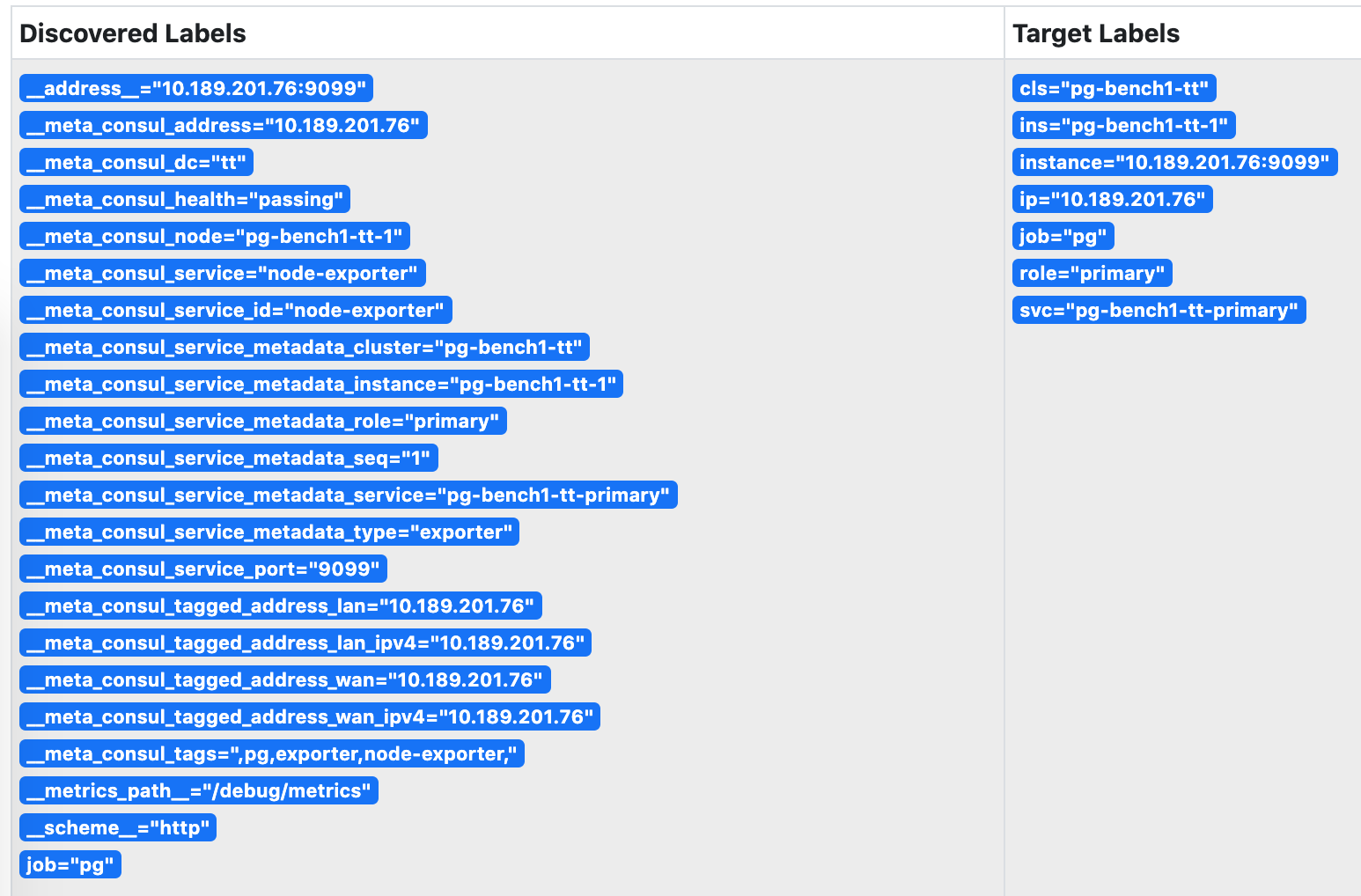
图:被Prometheus发现的服务,身份信息已关联至实例的指标维度上。
服务维护
有时候,因为数据库主从发生切换,导致注册的角色与数据库实例的实际角色出现偏差。这时候需要通过反熵过程处理这种异常。
基于Patroni的故障切换可以正常地通过回调逻辑修正注册的角色,但人工完成的角色切换则需要人工介入处理。
使用以下脚本可以自动检测并修复数据库的服务注册。建议在数据库实例上配置Crontab,或在元节点上设置定期巡检任务。
/pg/bin/pg-register $(pg-role)
静态文件服务发现
static服务发现依赖/etc/prometheus/targets/*.yml中的配置进行服务发现。采用这种方式的优势是不依赖Consul。
当Pigsty监控系统与外部管控方案集成时,这种模式对原系统的侵入性较小。但是缺点是,当集群内发生主从切换时,用户需要自行维护实例角色信息。手动维护时,可以根据以下命令从配置文件生成Prometheus所需的监控对象配置文件并载入生效。
详见 Prometheus服务发现。
./infra.yml --tags=prometheus_targtes,prometheus_reload
Pigsty默认生成的静态监控对象文件示例如下:
#==============================================================#
# File : targets/all.yml
# Ctime : 2021-02-18
# Mtime : 2021-02-18
# Desc : Prometheus Static Monitoring Targets Definition
# Path : /etc/prometheus/targets/all.yml
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
#======> pg-meta-1 [primary]
- labels: {cls: pg-meta, ins: pg-meta-1, ip: 10.10.10.10, role: primary, svc: pg-meta-primary}
targets: [10.10.10.10:9630, 10.10.10.10:9100, 10.10.10.10:9631, 10.10.10.10:9101]
#======> pg-test-1 [primary]
- labels: {cls: pg-test, ins: pg-test-1, ip: 10.10.10.11, role: primary, svc: pg-test-primary}
targets: [10.10.10.11:9630, 10.10.10.11:9100, 10.10.10.11:9631, 10.10.10.11:9101]
#======> pg-test-2 [replica]
- labels: {cls: pg-test, ins: pg-test-2, ip: 10.10.10.12, role: replica, svc: pg-test-replica}
targets: [10.10.10.12:9630, 10.10.10.12:9100, 10.10.10.12:9631, 10.10.10.12:9101]
#======> pg-test-3 [replica]
- labels: {cls: pg-test, ins: pg-test-3, ip: 10.10.10.13, role: replica, svc: pg-test-replica}
targets: [10.10.10.13:9630, 10.10.10.13:9100, 10.10.10.13:9631, 10.10.10.13:9101]
身份关联
无论是通过Consul服务发现,还是静态文件服务发现。最终的效果是实现身份信息与实例监控指标相互关联。
这一关联,是通过 监控指标 的维度标签实现的。
| 身份参数 |
维度标签 |
取值样例 |
pg_cluster |
cls |
pg-test |
pg_instance |
ins |
pg-test-1 |
pg_services |
svc |
pg-test-primary |
pg_role |
role |
primary |
node_ip |
ip |
10.10.10.11 |
阅读下一节 监控指标 ,了解这些指标是如何通过标签组织起来的。
3.3.4 - Metrics
Something about pigsty metrics: form, model, level, derived rules….
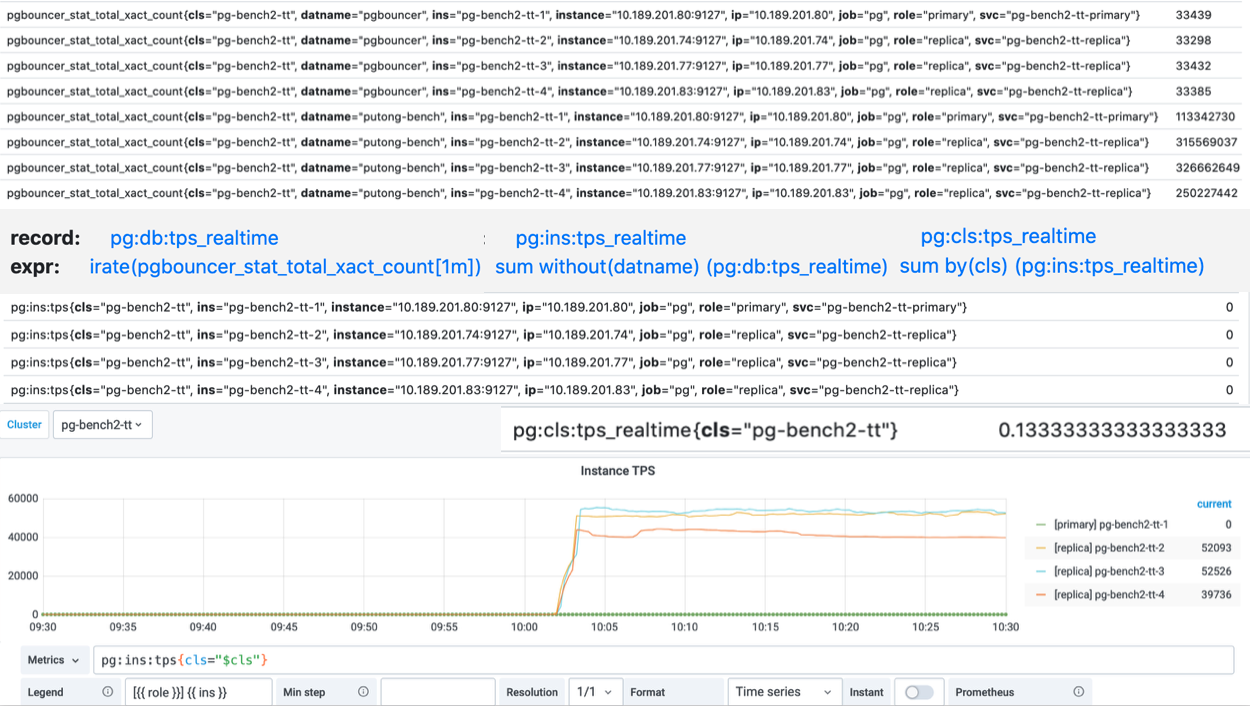
Metrics lies in the core part of pigsty monitoring system.
指标形式
指标在形式上是可累加的,原子性的逻辑计量单元,可在时间段上进行更新与统计汇总。
指标通常以 带有维度标签的时间序列 的形式存在。举个例子,Pigsty沙箱中的pg:ins:qps_realtime指展示了所有实例的实时QPS。
pg:ins:qps_realtime{cls="pg-meta", ins="pg-meta-1", ip="10.10.10.10", role="primary"} 0
pg:ins:qps_realtime{cls="pg-test", ins="pg-test-1", ip="10.10.10.11", role="primary"} 327.6
pg:ins:qps_realtime{cls="pg-test", ins="pg-test-2", ip="10.10.10.12", role="replica"} 517.0
pg:ins:qps_realtime{cls="pg-test", ins="pg-test-3", ip="10.10.10.13", role="replica"} 0
用户可以对指标进行运算:求和、求导,聚合,等等。例如:
$ sum(pg:ins:qps_realtime) by (cls) -- 查询按集群聚合的 实时实例QPS
{cls="pg-meta"} 0
{cls="pg-test"} 844.6
$ avg(pg:ins:qps_realtime) by (cls) -- 查询每个集群中 所有实例的平均 实时实例QPS
{cls="pg-meta"} 0
{cls="pg-test"} 280
$ avg_over_time(pg:ins:qps_realtime[30m]) -- 过去30分钟内实例的平均QPS
pg:ins:qps_realtime{cls="pg-meta", ins="pg-meta-1", ip="10.10.10.10", role="primary"} 0
pg:ins:qps_realtime{cls="pg-test", ins="pg-test-1", ip="10.10.10.11", role="primary"} 130
pg:ins:qps_realtime{cls="pg-test", ins="pg-test-2", ip="10.10.10.12", role="replica"} 100
pg:ins:qps_realtime{cls="pg-test", ins="pg-test-3", ip="10.10.10.13", role="replica"} 0
指标模型
每一个指标(Metric),都是一类数据,通常会对应多个时间序列(time series)。同一个指标对应的不同时间序列通过维度进行区分。
指标 + 维度,可以具体定位一个时间序列。每一个时间序列都是由 (时间戳,取值)二元组构成的数组。
Pigsty采用Prometheus的指标模型,其逻辑概念可以用以下的SQL DDL表示。
-- 指标表,指标与时间序列构成1:n关系
CREATE TABLE metrics (
id INT PRIMARY KEY, -- 指标标识
name TEXT UNIQUE -- 指标名称,[...其他指标元数据,例如类型]
);
-- 时间序列表,每个时间序列都对应一个指标。
CREATE TABLE series (
id BIGINT PRIMARY KEY, -- 时间序列标识
metric_id INTEGER REFERENCES metrics (id), -- 时间序列所属的指标
dimension JSONB DEFAULT '{}' -- 时间序列带有的维度信息,采用键值对的形式表示
);
-- 时许数据表,保存最终的采样数据点。每个采样点都属于一个时间序列
CREATE TABLE series_data (
series_id BIGINT REFERENCES series(id), -- 时间序列标识
ts TIMESTAMP, -- 采样点时间戳
value FLOAT, -- 采样点指标值
PRIMARY KEY (series_id, ts) -- 每个采样点可以通过 所属时间序列 与 时间戳 唯一标识
);
这里我们以pg:ins:qps指标为例:
-- 样例指标数据
INSERT INTO metrics VALUES(1, 'pg:ins:qps'); -- 该指标名为 pg:ins:qps ,是一个 GAUGE。
INSERT INTO series VALUES -- 该指标包含有四个时间序列,通过维度标签区分
(1001, 1, '{"cls": "pg-meta", "ins": "pg-meta-1", "role": "primary", "other": "..."}'),
(1002, 1, '{"cls": "pg-test", "ins": "pg-test-1", "role": "primary", "other": "..."}'),
(1003, 1, '{"cls": "pg-test", "ins": "pg-test-2", "role": "replica", "other": "..."}'),
(1004, 1, '{"cls": "pg-test", "ins": "pg-test-3", "role": "replica", "other": "..."}');
INSERT INTO series_data VALUES -- 每个时间序列底层的采样点
(1001, now(), 1000), -- 实例 pg-meta-1 在当前时刻QPS为1000
(1002, now(), 1000), -- 实例 pg-test-1 在当前时刻QPS为1000
(1003, now(), 5000), -- 实例 pg-test-2 在当前时刻QPS为1000
(1004, now(), 5001); -- 实例 pg-test-3 在当前时刻QPS为5001
pg_up 是一个指标,包含有4个时间序列。记录了整个环境中所有实例的存活状态。pg_up{ins": "pg-test-1", ...}是一个时间序列,记录了特定实例pg-test-1 的存活状态
指标来源
Pigsty的监控数据主要有四种主要来源: 数据库,连接池,操作系统,负载均衡器。通过相应的exporter对外暴露。
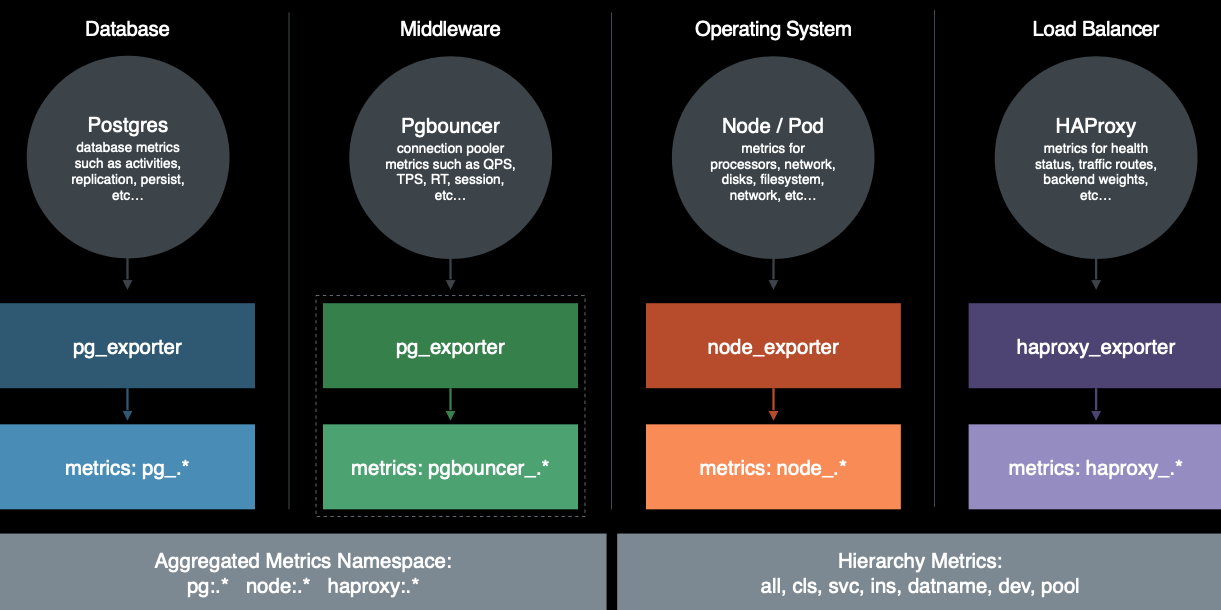
完整来源包括:
- PostgreSQL本身的监控指标
- PostgreSQL日志中的统计指标
- PostgreSQL系统目录信息
- Pgbouncer连接池中间价的指标
- PgExporter指标
- 数据库工作节点Node的指标
- 负载均衡器Haproxy指标
- DCS(Consul)工作指标
- 监控系统自身工作指标:Grafana,Prometheus,Nginx
- Blackbox探活指标
关于全部可用的指标清单,请查阅 参考-指标清单 一节
指标数量
那么,Pigsty总共包含了多少指标呢? 这里是一副各个指标来源占比的饼图。我们可以看到,右侧蓝绿黄对应的部分是数据库及数据库相关组件所暴露的指标,而左下方红橙色部分则对应着机器节点相关指标。左上方紫色部分则是负载均衡器的相关指标。
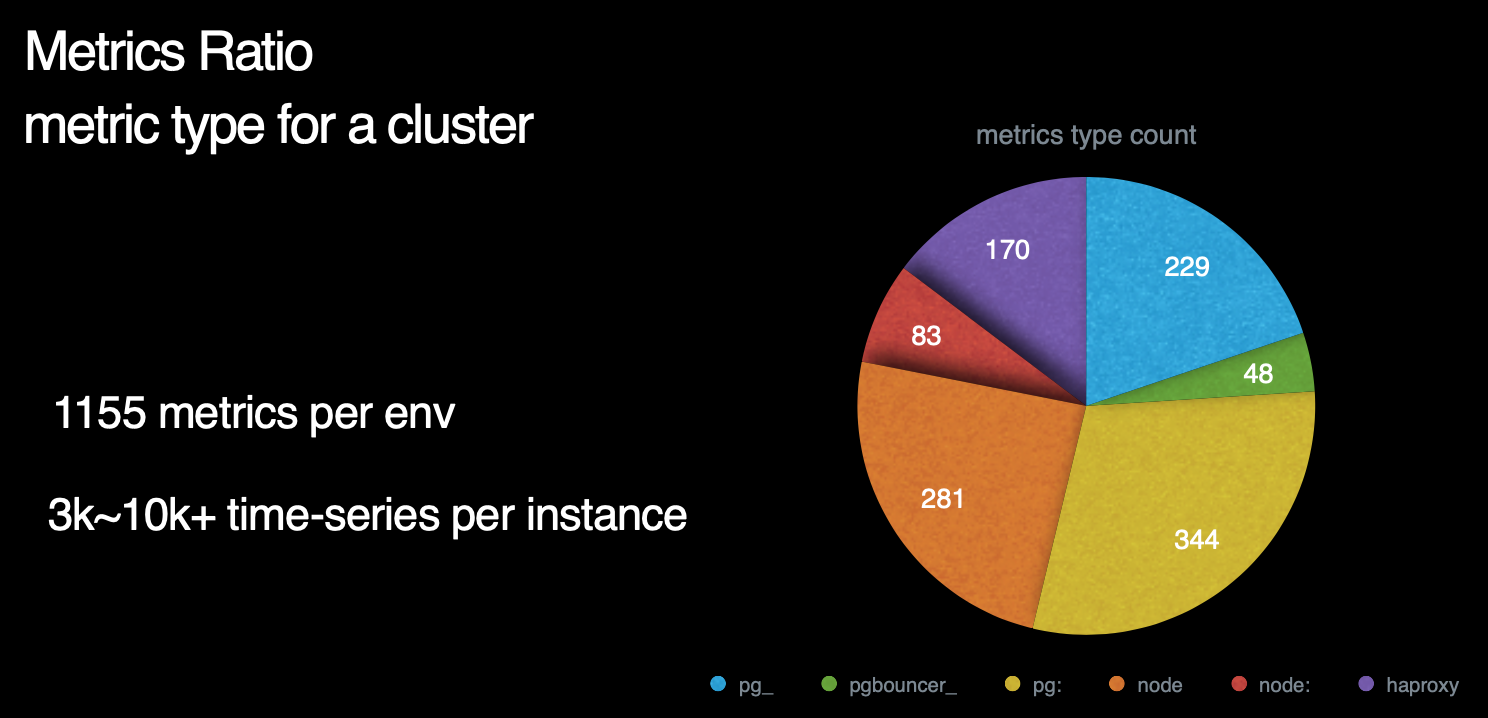
数据库指标中,与postgres本身有关的原始指标约230个,与中间件有关的原始指标约50个,基于这些原始指标,Pigsty又通过层次聚合与预计算,精心设计出约350个与DB相关的衍生指标。
因此,对于每个数据库集群来说,单纯针对数据库及其附件的监控指标就有621个。而机器原始指标281个,衍生指标83个一共364个。加上负载均衡器的170个指标,我们总共有接近1200类指标。
注意,这里我们必须辨析一下指标(metric)与时间序列( Time-series)的区别。
这里我们使用的量词是 类 而不是个 。 因为一个指标可能对应多个时间序列。例如一个数据库中有20张表,那么 pg_table_index_scan 这样的指标就会对应有20个对应的时间序列。
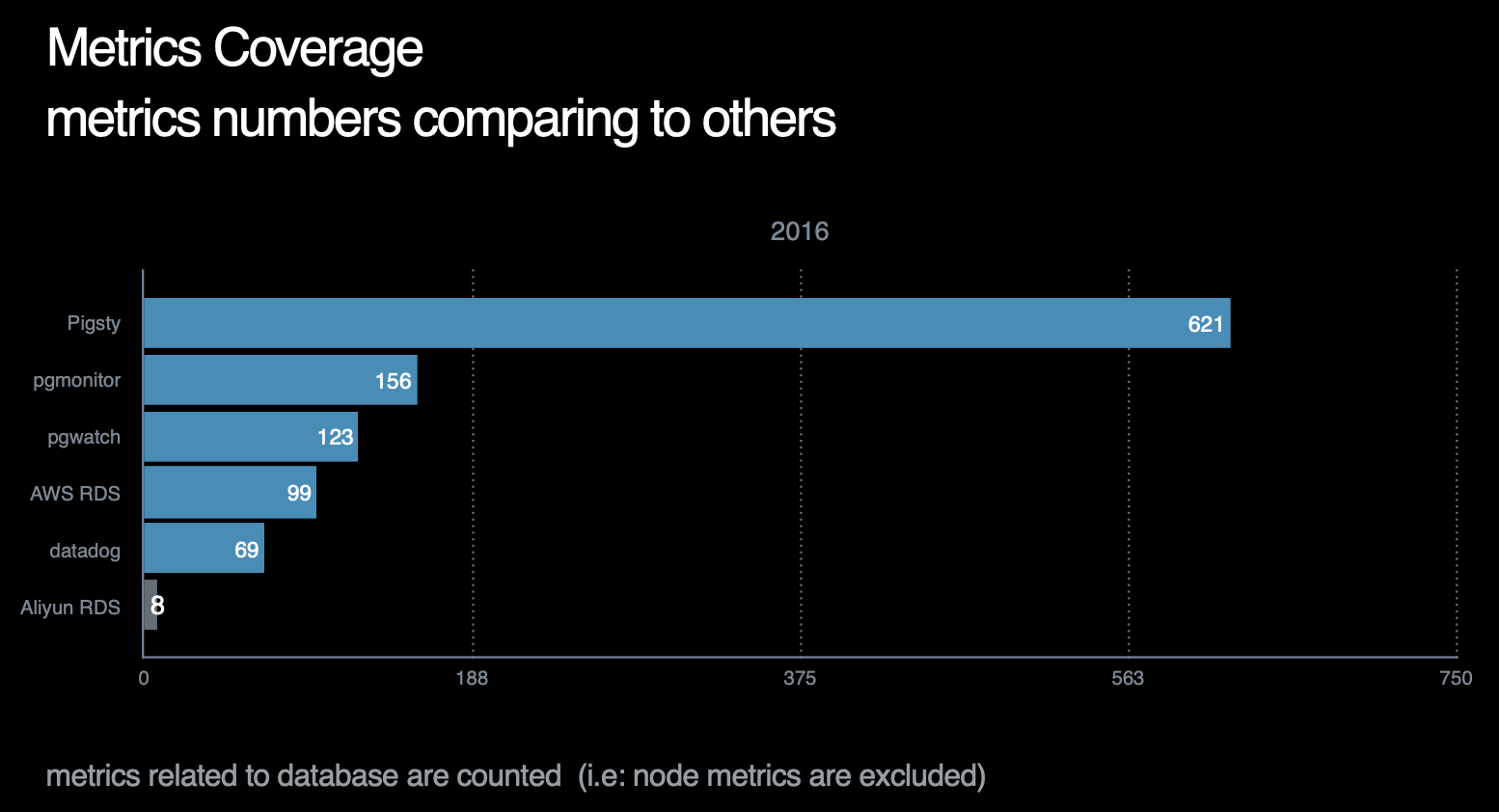
截止至2021年,Pigsty的指标覆盖率在所有作者已知的开源/商业监控系统中一骑绝尘,详情请参考横向对比。
指标层次
Pigsty还会基于现有指标进行加工处理,产出 衍生指标(Derived Metrics) 。
例如指标可以按照不同的层次进行聚合
从原始监控时间序列数据,到最终的成品图表,中间还有着若干道加工工序。
这里以TPS指标的衍生流程为例。
原始数据是从Pgbouncer抓取得到的事务计数器,集群中有四个实例,而每个实例上又有两个数据库,所以一个实例总共有8个DB层次的TPS指标。
而下面的图表,则是整个集群内每个实例的QPS横向对比,因此在这里,我们使用预定义的规则,首先对原始事务计数器求导获取8个DB层面的TPS指标,然后将8个DB层次的时间序列聚合为4个实例层次的TPS指标,最后再将这四个实例级别的TPS指标聚合为集群层次的TPS指标。
Pigsty共定义了360类衍生聚合指标,后续还会不断增加。衍生指标定义规则详见 参考-衍生指标
特殊指标
目录(Catalog) 是一种特殊的指标
Catalog与Metrics比较相似但又不完全相同,边界比较模糊。最简单的例子,一个表的页面数量和元组数量,应该算Catalog还是算Metrics?
跳过这种概念游戏,实践上Catalog和Metrics主要的区别是,Catalog里的信息通常是不怎么变化的,比如表的定义之类的,如果也像Metrics这样比如几秒抓一次,显然是一种浪费。所以我们会将这一类偏静态的信息划归Catalog。
Catalog主要由定时任务(例如巡检)负责抓取,而不由Prometheus采集。一些特别重要的Catalog信息,例如pg_class中的一些信息,也会转换为指标被Prometheus所采集。
小结
了解了Pigsty指标后,不妨了解一下Pigsty的 报警系统 是如何将这些指标数据用于实际生产用途的。
3.3.5 - Alert Rules
Introduction to built-in alert rules, and how to add new
Alerts are critical to daily fault response and to improve system availability.
Missed alarms lead to reduced availability and false alarms lead to reduced sensitivity, necessitating a prudent design of alarm rules.
- Reasonable definition of alarm levels and the corresponding processing flow
- Reasonable definition of alarm indicators, removal of duplicate alarm items, and supplementation of missing alarm items
- Scientific configuration of alarm thresholds based on historical monitoring data to reduce the false alarm rate.
- Reasonable sparse special case rules to eliminate false alarms caused by maintenance work, ETL, and offline query.
Alert taxonomy
**By Urgency **
-
P0: FATAL: Incidents that have significant off-site impact and require urgent intervention to handle. For example, main library down, replication outage. (Serious incident)
-
P1: ERROR: Incidents with minor off-site impact, or incidents with redundant processing, requiring response processing at the minute level. (Incident)
-
P2: WARNING: imminent impact, let loose may worsen at the hourly level, response is required at the hourly level. (Incident of concern)
-
P3: NOTICE: Needs attention, will not have an immediate impact, but needs to be responded to within the day level. (Deviation phenomena)
By Level
- DBA will only pay special attention to CPU and disk alarms, and the rest is the responsibility of operation and maintenance.
- Database level: Alarms of database itself, DBA focus on. This is generated by PG, PGB, and Exporter’s own monitoring metrics.
- Application level: Application alarms are the responsibility of the business side itself, but DBA will set alarms for business metrics such as QPS, TPS, Rollback, Seasonality, etc.
By Metric Type
- Errors: PG Down, PGB Down, Exporter Down, Stream Replication Outage, Single Set Cluster Multi-Master
- Traffic: QPS, TPS, Rollback, Seasonality
- Latency: Average Response Time, Replication Latency
- Saturation: Connection Stacking, Number of Idle Transactions, CPU, Disk, Age (Transaction Number), Buffers
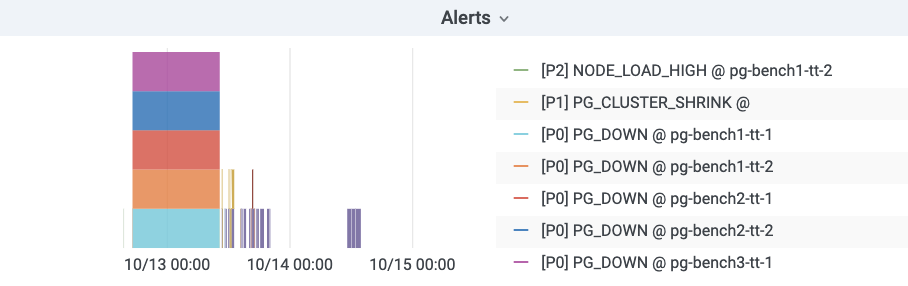
Alarm Visualization
Pigsty uses bar graphs to present alarm information. The horizontal axis represents the time period and a color bar represents the alarm event. Only alarms that are in the Firing state are displayed in the alarm chart.
Alarm rules in detail
Alarm rules can be roughly divided into four categories by type: error, delay, saturation, and flow. Among them.
- Errors: mainly concerned with the survivability (Aliveness) of each component, as well as network outages, brain fractures and other abnormalities, the level is usually higher (P0|P1).
- Latency: mainly concerned with query response time, replication latency, slow queries, and long transactions.
- Saturation: mainly focus on CPU, disk (these two belong to system monitoring but very important for DB so incorporate), connection pool queue, number of database back-end connections, age (essentially the saturation of available thing numbers), SSD life, etc.
- Traffic: QPS, TPS, Rollback (traffic is usually related to business metrics belongs to business monitoring, but incorporated because it is important for DB), seasonality of QPS, burst of TPS.
Error Alarm
Postgres instance downtime distinguishes between master and slave, master library downtime triggers P0 alarm, slave library downtime triggers P1 alarm. Both require immediate intervention, but slave libraries usually have multiple instances and can be downgraded to query on the master library, which has a higher processing margin, so slave library downtime is designated as P1.
# primary|master instance down for 1m triggers a P0 alert
- alert: PG_PRIMARY_DOWN
expr: pg_up{instance=~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Postgres Primary Instance Down: {{$labels.instance}}"
description: "pg_up = {{ $value }} {{$labels.instance}}"
# standby|slave instance down for 1m triggers a P1 alert
- alert: PG_STANDBY_DOWN
expr: pg_up{instance!~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres Standby Instance Down: {{$labels.instance}}"
description: "pg_up = {{ $value }} {{$labels.instance}}"
Pgbouncer实例因为与Postgres实例一一对应,其存活性报警规则与Postgres统一。
# primary pgbouncer down for 1m triggers a P0 alert
- alert: PGB_PRIMARY_DOWN
expr: pgbouncer_up{instance=~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Pgbouncer Primary Instance Down: {{$labels.instance}}"
description: "pgbouncer_up = {{ $value }} {{$labels.instance}}"
# standby pgbouncer down for 1m triggers a P1 alert
- alert: PGB_STANDBY_DOWN
expr: pgbouncer_up{instance!~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Pgbouncer Standby Instance Down: {{$labels.instance}}"
description: "pgbouncer_up = {{ $value }} {{$labels.instance}}"
Prometheus Exporter的存活性定级为P1,虽然Exporter宕机本身并不影响数据库服务,但这通常预示着一些不好的情况,而且监控数据的缺失也会产生某些相应的报警。Exporter的存活性是通过Prometheus自己的up指标检测的,需要注意某些单实例多DB的特例。
# exporter down for 1m triggers a P1 alert
- alert: PG_EXPORTER_DOWN
expr: up{port=~"(9185|9127)"} == 0
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Exporter Down: {{$labels.instance}} {{$labels.port}}"
description: "port = {{$labels.port}}, {{$labels.instance}}"
所有存活性检测的持续时间阈值设定为1分钟,对15s的默认采集周期而言是四个样本点。常规的重启操作通常不会触发存活性报警。
延迟报警
与复制延迟有关的报警有三个:复制中断,复制延迟高,复制延迟异常,分别定级为P1, P2, P3
-
其中复制中断是一种错误,使用指标:pg_repl_state_count{state="streaming"}进行判断,当前streaming状态的从库如果数量发生负向变动,则触发break报警。walsender会决定复制的状态,从库直接断开会产生此现象,缓冲区出现积压时会从streaming进入catchup状态也会触发此报警。此外,采用-Xs手工制作备份结束时也会产生此报警,此报警会在10分钟后自动Resolve。复制中断会导致客户端读到陈旧的数据,具有一定的场外影响,定级为P1。
-
复制延迟可以使用延迟时间或者延迟字节数判定。以延迟字节数为权威指标。常规状态下,复制延迟时间在百毫秒量级,复制延迟字节在百KB量级均属于正常。目前采用的是5s,15s的时间报警阈值。根据历史经验数据,这里采用了时间8秒与字节32MB的阈值,大致报警频率为每天个位数个。延迟时间更符合直觉,所以采用8s的P2报警,但并不是所有的从库都能有效取到该指标所以使用32MB的字节阈值触发P3报警补漏。
-
特例:antispam,stats,coredb均经常出现复制延迟。
# replication break for 1m triggers a P0 alert. auto-resolved after 10 minutes.
- alert: PG_REPLICATION_BREAK
expr: pg_repl_state_count{state="streaming"} - (pg_repl_state_count{state="streaming"} OFFSET 10m) < 0
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Postgres Streaming Replication Break: {{$labels.instance}}"
description: "delta = {{ $value }} {{$labels.instance}}"
# replication lag greater than 8 second for 3m triggers a P1 alert
- alert: PG_REPLICATION_LAG
expr: pg_repl_replay_lag{application_name="walreceiver"} > 8
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres Replication Lagged: {{$labels.instance}}"
description: "lag = {{ $value }} seconds, {{$labels.instance}}"
# replication diff greater than 32MB for 5m triggers a P3 alert
- alert: PG_REPLICATOIN_DIFF
expr: pg_repl_lsn{application_name="walreceiver"} - pg_repl_replay_lsn{application_name="walreceiver"} > 33554432
for: 5m
labels:
team: DBA
urgency: P3
annotations:
summary: "P3 Postgres Replication Diff Deviant: {{$labels.instance}}"
description: "delta = {{ $value }} {{$labels.instance}}"
饱和度报警
饱和度指标主要资源,包含很多系统级监控的指标。主要包括:CPU,磁盘(这两个属于系统监控但对于DB非常重要所以纳入),连接池排队,数据库后端连接数,年龄(本质是可用事物号的饱和度),SSD寿命等。
堆积检测
堆积主要包含两类指标,一方面是PG本身的后端连接数与活跃连接数,另一方面是连接池的排队情况。
PGB排队是决定性的指标,它代表用户端可感知的阻塞已经出现,因此,配置排队超过15持续1分钟触发P0报警。
# more than 8 client waiting in queue for 1 min triggers a P0 alert
- alert: PGB_QUEUING
expr: sum(pgbouncer_pool_waiting_clients{datname!="pgbouncer"}) by (instance,datname) > 8
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Pgbouncer {{ $value }} Clients Wait in Queue: {{$labels.instance}}"
description: "waiting clients = {{ $value }} {{$labels.instance}}"
后端连接数是一个重要的报警指标,如果后端连接持续达到最大连接数,往往也意味着雪崩。连接池的排队连接数也能反映这种情况,但不能覆盖应用直连数据库的情况。后端连接数的主要问题是它与连接池关系密切,连接池在短暂堵塞后会迅速打满后端连接,但堵塞恢复后这些连接必须在默认约10min的Timeout后才被释放。因此收到短暂堆积的影响较大。同时外晚上1点备份时也会出现这种情况,容易产生误报。
注意后端连接数与后端活跃连接数不同,目前报警使用的是活跃连接数。后端活跃连接数通常在0~1,一些慢库在十几左右,离线库可能会达到20~30。但后端连接/进程数(不管活跃不活跃),通常均值可达50。后端连接数更为直观准确。
对于后端连接数,这里使用两个等级的报警:超过90持续3分钟P1,以及超过80持续10分钟P2,考虑到通常数据库最大连接数为100。这样做可以以尽可能低的误报率检测到雪崩堆积。
# num of backend exceed 90 for 3m
- alert: PG_BACKEND_HIGH
expr: sum(pg_db_numbackends) by (node) > 90
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres Backend Number High: {{$labels.instance}}"
description: "numbackend = {{ $value }} {{$labels.instance}}"
# num of backend exceed 80 for 10m (avoid pgbouncer jam false alert)
- alert: PG_BACKEND_WARN
expr: sum(pg_db_numbackends) by (node) > 80
for: 10m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres Backend Number Warn: {{$labels.instance}}"
description: "numbackend = {{ $value }} {{$labels.instance}}"
空闲事务
目前监控使用IDEL In Xact的绝对数量作为报警条件,其实 Idle In Xact的最长持续时间可能会更有意义。因为这种现象其实已经被后端连接数覆盖了。长时间的空闲是我们真正关注的,因此这里使用所有空闲事务中最高的闲置时长作为报警指标。设置3分钟为P2报警阈值。经常出现IDLE的非Offline库有:moderation, location, stats,sms, device, moderationdevice
# max idle xact duration exceed 3m
- alert: PG_IDLE_XACT
expr: pg_activity_max_duration{instance!~".*offline.*", state=~"^idle in transaction.*"} > 180
for: 3m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres Long Idle Transaction: {{$labels.instance}}"
description: "duration = {{ $value }} {{$labels.instance}}"
资源报警
CPU, 磁盘,AGE
默认清理年龄为2亿,超过10Y报P1,既留下了充分的余量,又不至于让人忽视。
# age wrap around (progress in half 10Y) triggers a P1 alert
- alert: PG_XID_WRAP
expr: pg_database_age{} > 1000000000
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres XID Wrap Around: {{$labels.instance}}"
description: "age = {{ $value }} {{$labels.instance}}"
磁盘和CPU由运维配置,不变
流量
因为各个业务的负载情况不一,为流量指标设置绝对值是相对困难的。这里只对TPS和Rollback设置绝对值指标。而且较为宽松。
Rollback OPS超过4则发出P3警告,TPS超过24000发P2,超过30000发P1
# more than 30k TPS lasts for 1m triggers a P1 (pgbouncer bottleneck)
- alert: PG_TPS_HIGH
expr: rate(pg_db_xact_total{}[1m]) > 30000
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres TPS High: {{$labels.instance}} {{$labels.datname}}"
description: "TPS = {{ $value }} {{$labels.instance}}"
# more than 24k TPS lasts for 3m triggers a P2
- alert: PG_TPS_WARN
expr: rate(pg_db_xact_total{}[1m]) > 24000
for: 3m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres TPS Warning: {{$labels.instance}} {{$labels.datname}}"
description: "TPS = {{ $value }} {{$labels.instance}}"
# more than 4 rollback per seconds lasts for 5m
- alert: PG_ROLLBACK_WARN
expr: rate(pg_db_xact_rollback{}[1m]) > 4
for: 5m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres Rollback Warning: {{$labels.instance}}"
description: "rollback per sec = {{ $value }} {{$labels.instance}}"
QPS的指标与业务高度相关,因此不适合配置绝对值,可以为QPS突增配置一个报警项
短时间(和10分钟)前比突增30%会触发一个P2警报,同时避免小QPS下的突发流量,设置一个绝对阈值10k
# QPS > 10000 and have a 30% inc for 3m triggers P2 alert
- alert: PG_QPS_BURST
expr: sum by(datname,instance)(rate(pgbouncer_stat_total_query_count{datname!="pgbouncer"}[1m]))/sum by(datname,instance) (rate(pgbouncer_stat_total_query_count{datname!="pgbouncer"}[1m] offset 10m)) > 1.3 and sum by(datname,instance) (rate(pgbouncer_stat_total_query_count{datname!="pgbouncer"}[1m])) > 10000
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P2 Pgbouncer QPS Burst 30% and exceed 10000: {{$labels.instance}}"
description: "qps = {{ $value }} {{$labels.instance}}"
Prometheus报警规则
完整的报警规则详见:参考-报警规则
3.4 - Provisioning
Concepts about pigsty provisioning systems
By Provisioning Solution, we mean a system that delivers database services and monitoring systems to users.
Provisioning Solution is not a database, but a database factory.
The user submits a configuration to the provisioning system, and the provisioning system creates the required database cluster in the environment according to the user’s desired specifications.
This is more similar to submitting a YAML file to Kubernetes to create the various resources required.
Defining a database cluster
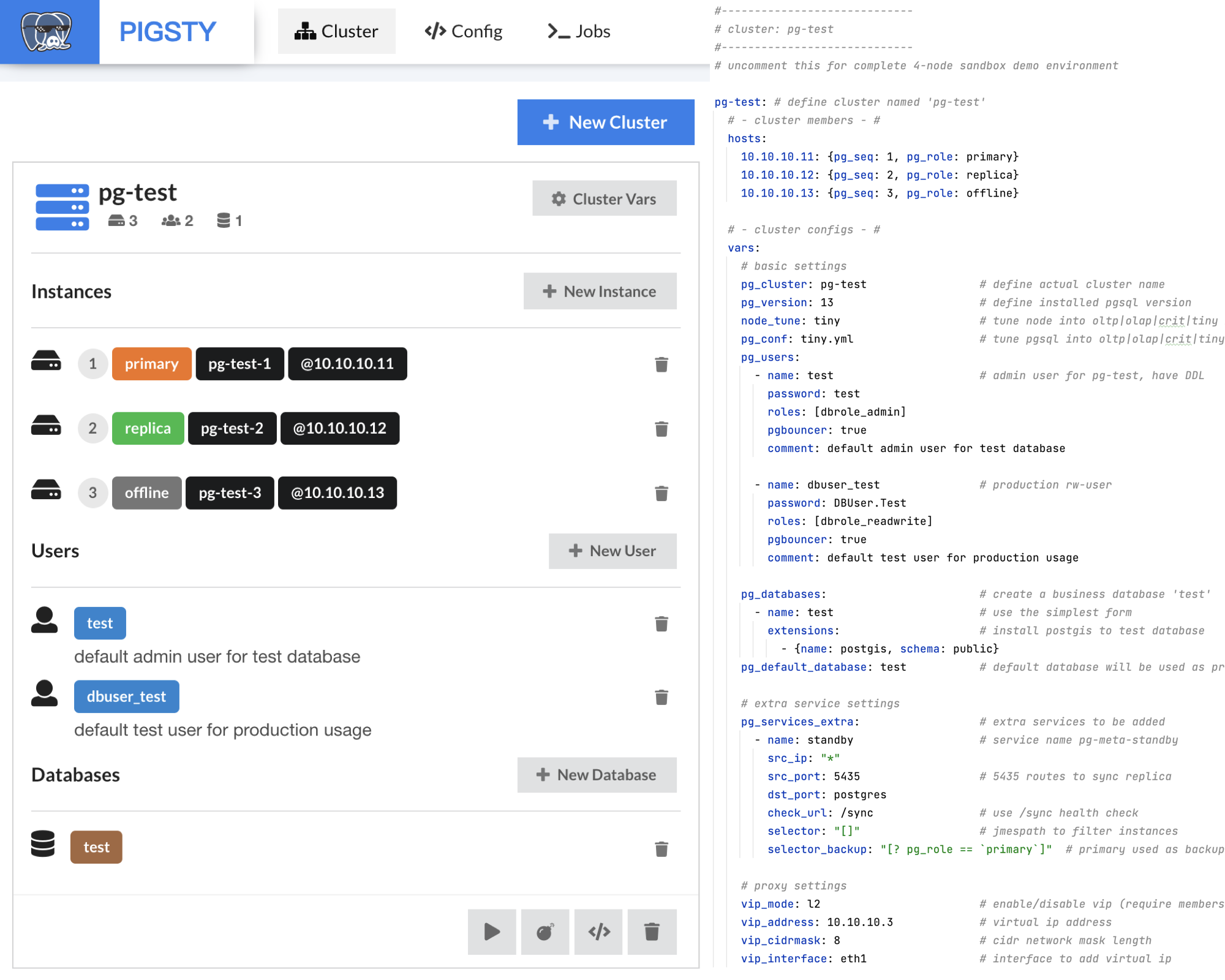
For example, the following configuration information declares a set of PostgreSQL database clusters named pg-test.
#-----------------------------
# cluster: pg-test
#-----------------------------
pg-test: # define cluster named 'pg-test'
# - cluster members - #
hosts:
10.10.10.11: {pg_seq: 1, pg_role: primary, ansible_host: node-1}
10.10.10.12: {pg_seq: 2, pg_role: replica, ansible_host: node-2}
10.10.10.13: {pg_seq: 3, pg_role: offline, ansible_host: node-3}
# - cluster configs - #
vars:
# basic settings
pg_cluster: pg-test # define actual cluster name
pg_version: 13 # define installed pgsql version
node_tune: tiny # tune node into oltp|olap|crit|tiny mode
pg_conf: tiny.yml # tune pgsql into oltp/olap/crit/tiny mode
# business users, adjust on your own needs
pg_users:
- name: test # example production user have read-write access
password: test # example user's password
roles: [dbrole_readwrite] # dborole_admin|dbrole_readwrite|dbrole_readonly|dbrole_offline
pgbouncer: true # production user that access via pgbouncer
comment: default test user for production usage
pg_databases: # create a business database 'test'
- name: test # use the simplest form
pg_default_database: test # default database will be used as primary monitor target
# proxy settings
vip_mode: l2 # enable/disable vip (require members in same LAN)
vip_address: 10.10.10.3 # virtual ip address
vip_cidrmask: 8 # cidr network mask length
vip_interface: eth1 # interface to add virtual ip
When executing database provisioning script . /pgsql.yml, the provisioning system will generate a one-master-two-slave PostgreSQL cluster pg-test on the three machines 10.10.10.11, 10.10.10.12, and 10.10.10.13, as defined in the manifest. And create a user and database named test. At the same time, Pigsty will also declare a 10.10.10.3 VIP binding on top of the cluster’s master library upon request. The structure is shown in the figure below.
Defining the infrastructure
The user is able to define not only the database cluster, but also the entire infrastructure.
Pigsty implements a complete representation of the database runtime environment with 154 variables.
For detailed configurable items, please refer to the Configuration Guide
Responsibilities of the provisioning scheme
The provisioning solution is usually only responsible for the creation of the cluster. Once the cluster is created, the day-to-day management should be the responsibility of the control platform.
However, Pigsty does not currently include a control platform component, so a simple resource recovery and destruction script is provided and can also be used for resource updates and management. However, it is not the job of the provisioning solution to do this.
3.4.1 - DB Access
How to access database?
Database access methods
Users can access the database services in several ways.
At the cluster level, users can access the [four default services] provided by the cluster via cluster domain + service port (. /service#default services), which Pigsty strongly recommends. Of course users can also bypass the domain name and access the database cluster directly using the cluster’s VIP (L2 or L4).
At the instance level, users can connect directly to the Postgres database via the node IP/domain name + port 5432, or they can use port 6432 to access the database via Pgbouncer. Services provided by the cluster to which the instance belongs can also be accessed via Haproxy via 5433~543x.
How the database is accessed ultimately depends on the traffic access scheme used by the database.
Typical access scheme
Pigsty recommends using a Haproxy-based access scheme (1/2), or in production environments with infrastructure support, an L4VIP (or equivalent load balancing service) based access scheme (3) can be used.
DNS + Haproxy
方案简介
标准高可用接入方案,系统无单点。灵活性,适用性,性能的最佳平衡点。
集群中的Haproxy采用Node Port的方式统一对外暴露 服务。每个Haproxy都是幂等的实例,提供完整的负载均衡与服务分发功能。Haproxy部署于每一个数据库节点上,因此整个集群的每一个成员在使用效果上都是幂等的。(例如访问任何一个成员的5433端口都会连接至主库连接池,访问任意成员的5434端口都会连接至某个从库的连接池)
Haproxy本身的可用性通过幂等副本实现,每一个Haproxy都可以作为访问入口,用户可以使用一个、两个、多个,所有Haproxy实例,每一个Haproxy提供的功能都是完全相同的。
用户需要自行确保应用能够访问到任意一个健康的Haproxy实例。作为最朴素的一种实现,用户可以将数据库集群的DNS域名解析至若干Haproxy实例,并启用DNS轮询响应。而客户端可以选择完全不缓存DNS,或者使用长连接并实现建立连接失败后重试的机制。又或者参考方案2,在架构侧通过额外的L2/L4 VIP确保Haproxy本身的高可用。
方案优越性
-
无单点,高可用
-
VIP固定绑定至主库,可以灵活访问
方案局限性
-
多一跳
-
Client IP地址丢失,部分HBA策略无法正常生效
-
Haproxy本身的高可用通过幂等副本,DNS轮询与客户端重连实现
DNS应有轮询机制,客户端应当使用长连接,并有建连失败重试机制。以便单Haproxy故障时可以自动漂移至集群中的其他Haproxy实例。如果无法做到这一点,可以考虑使用接入方案2,使用L2/L4 VIP确保Haproxy高可用。
方案示意
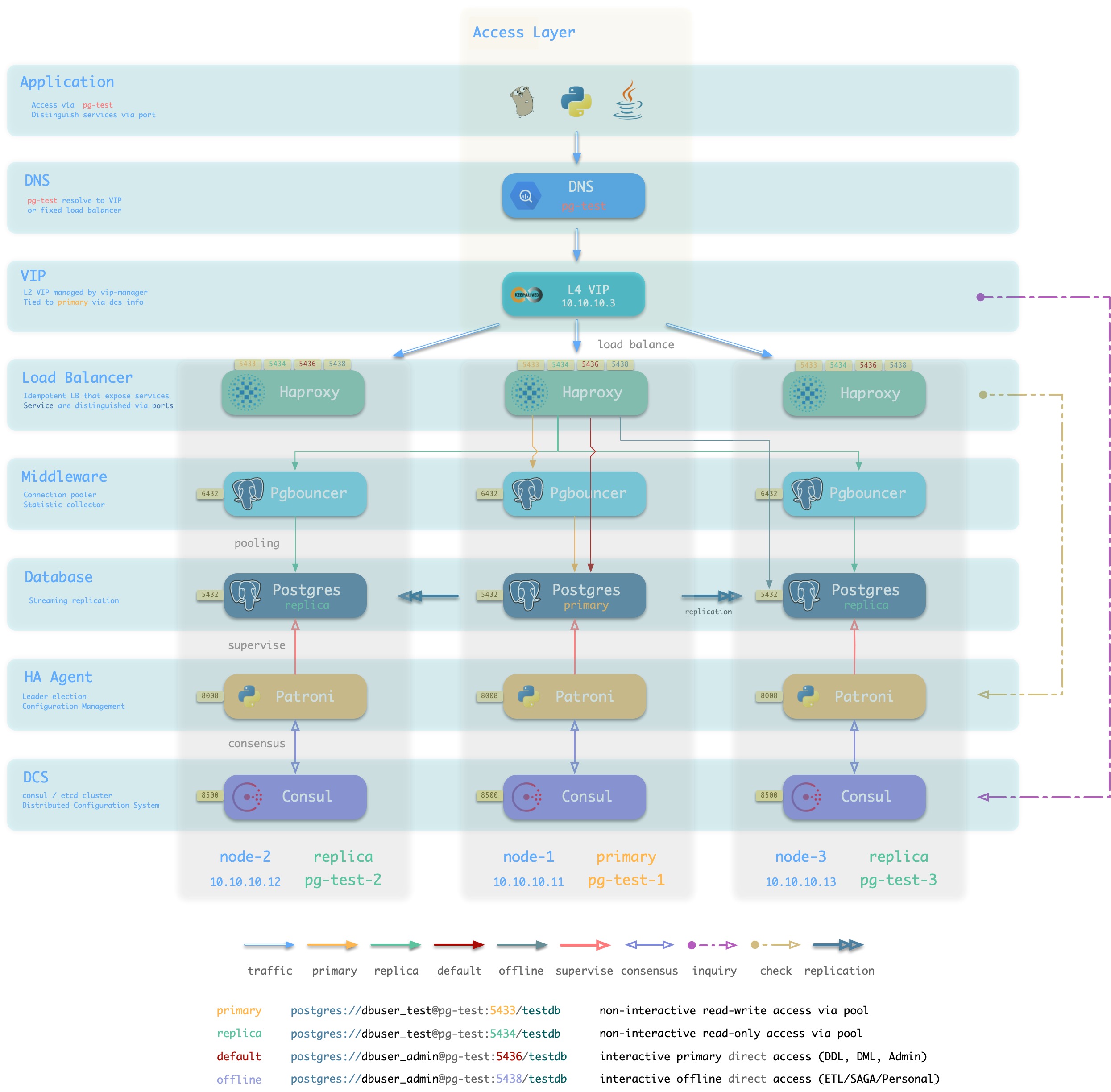
L2 VIP + Haproxy
方案简介
Pigsty沙箱使用的标准接入方案,采用单个域名绑定至单个L2 VIP,VIP指向集群中的HAProxy。
集群中的Haproxy采用Node Port的方式统一对外暴露 服务。每个Haproxy都是幂等的实例,提供完整的负载均衡与服务分发功能。而Haproxy本身的可用性则通过L2 VIP来保证。
每个集群都分配有一个L2 VIP,固定绑定至集群主库。当主库发生切换时,该L2 VIP也会随之漂移至新的主库上。这是通过vip-manager实现的:vip-manager会查询Consul获取集群当前主库信息,然后在主库上监听VIP地址。
集群的L2 VIP有与之对应的域名。域名固定解析至该L2 VIP,在生命周期中不发生变化。
方案优越性
-
无单点,高可用
-
VIP固定绑定至主库,可以灵活访问
方案局限性
方案示意
L4 VIP + Haproxy
方案简介
接入方案1/2的另一种变体,通过L4 VIP确保Haproxy的高可用
方案优越性
- 无单点,高可用
- 可以同时使用所有的Haproxy实例,均匀承载流量。
- 所有候选主库不需要位于同一二层网络。
- 可以操作单一VIP完成流量切换(如果同时使用了多个Haproxy,不需要逐个调整)
方案局限性
- 多两跳,较为浪费,如果有条件可以直接使用方案4: L4 VIP直接接入。
- Client IP地址丢失,部分HBA策略无法正常生效
方案示意
L4 VIP
方案简介
大规模高性能生产环境建议使用 L4 VIP接入(FullNAT,DPVS)
方案优越性
- 性能好,吞吐量大
- 可以通过
toa模块获取正确的客户端IP地址,HBA可以完整生效。
方案局限性
- 仍然多一条。
- 需要依赖外部基础设施,部署复杂。
- 未启用
toa内核模块时,仍然会丢失客户端IP地址。
- 没有Haproxy屏蔽主从差异,集群中的每个节点不再“幂等”。
方案示意

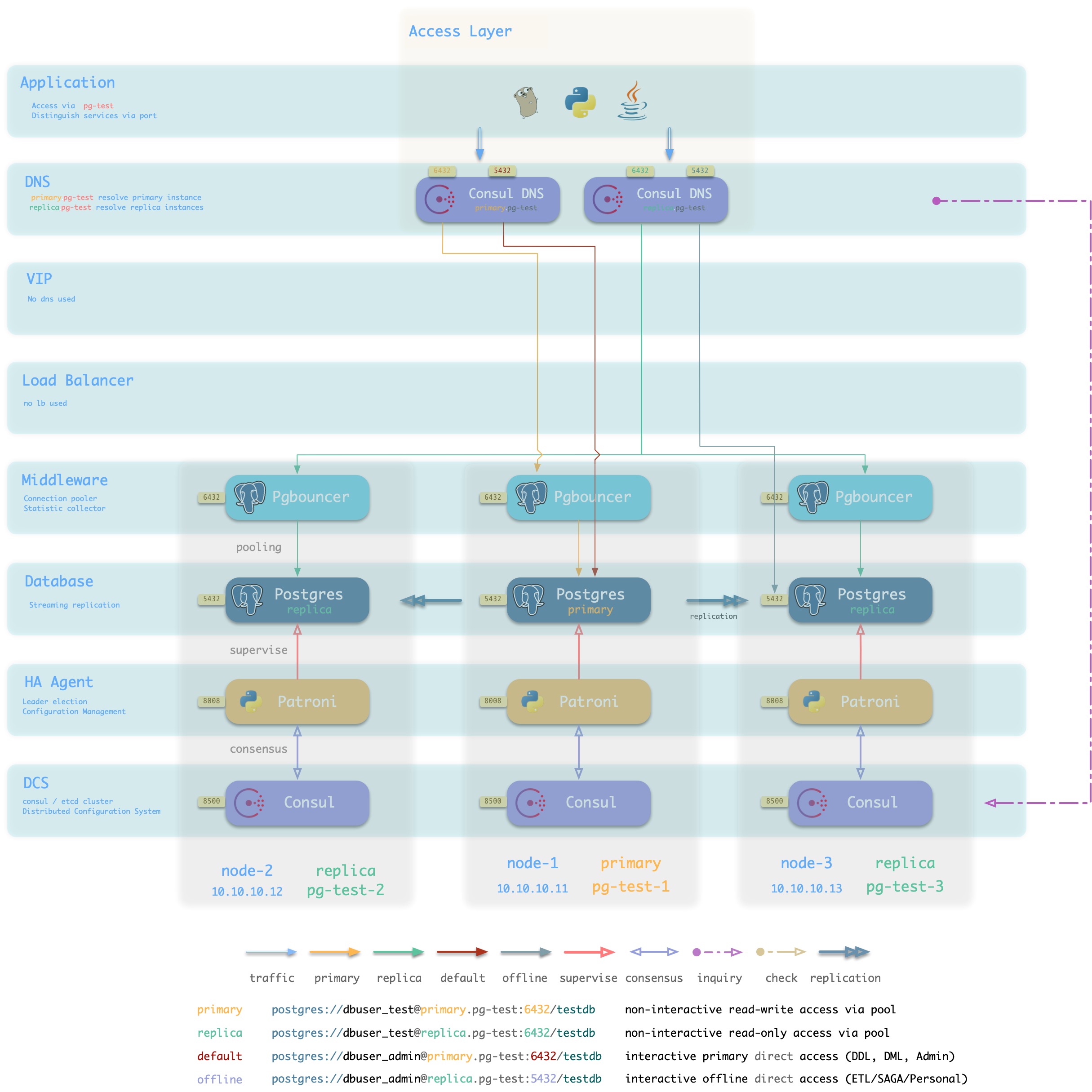
Consul DNS
方案简介
L2 VIP并非总是可用,特别是所有候选主库必须位于同一二层网络的要求可能不一定能满足。
在这种情况下,可以使用DNS解析代替L2 VIP,进行
方案优越性
方案局限性
- 依赖Consul DNS
- 用户需要合理配置DNS缓存策略
方案示意
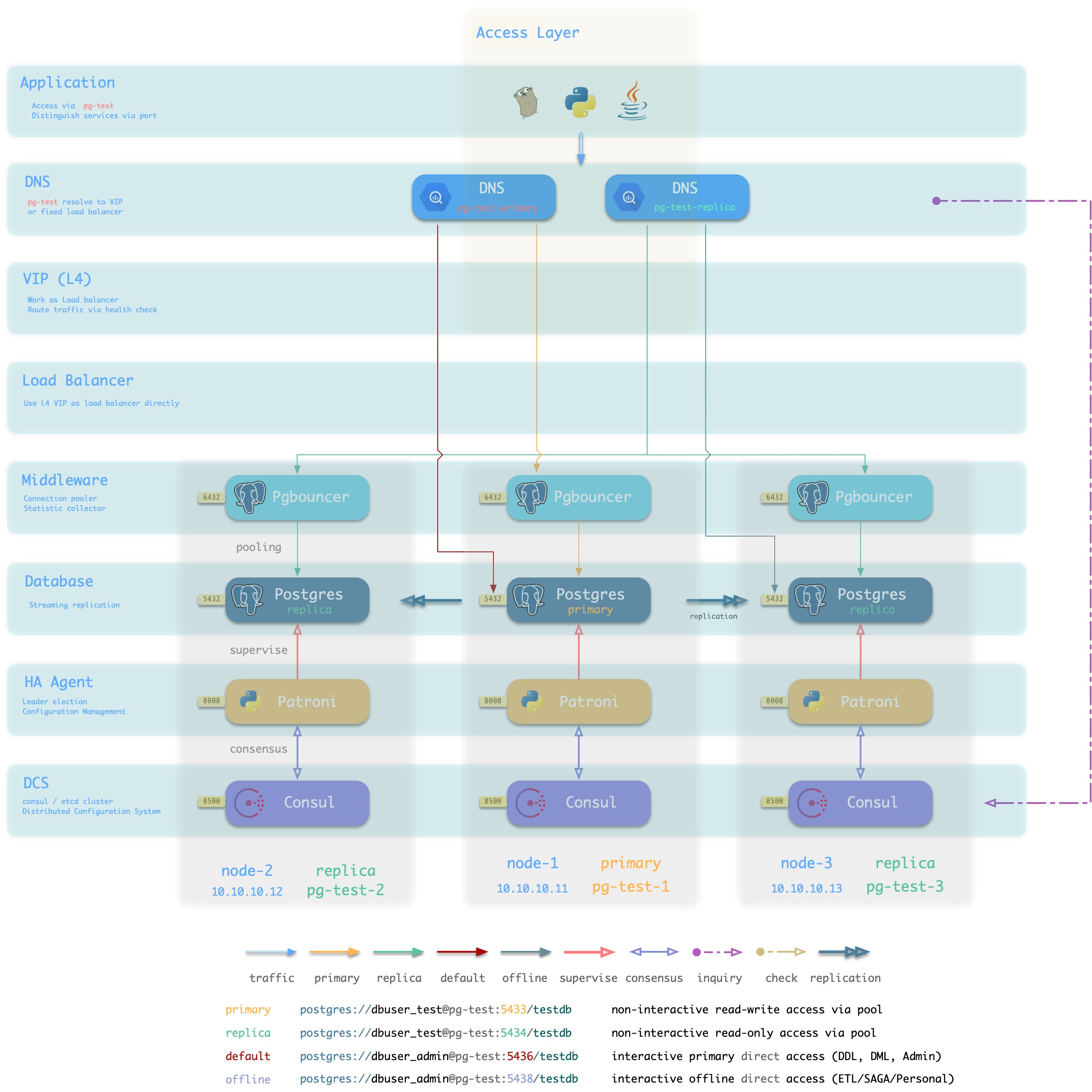
Static DNS
方案简介
传统静态DNS接入方式
方案优越性
方案局限性
方案示意
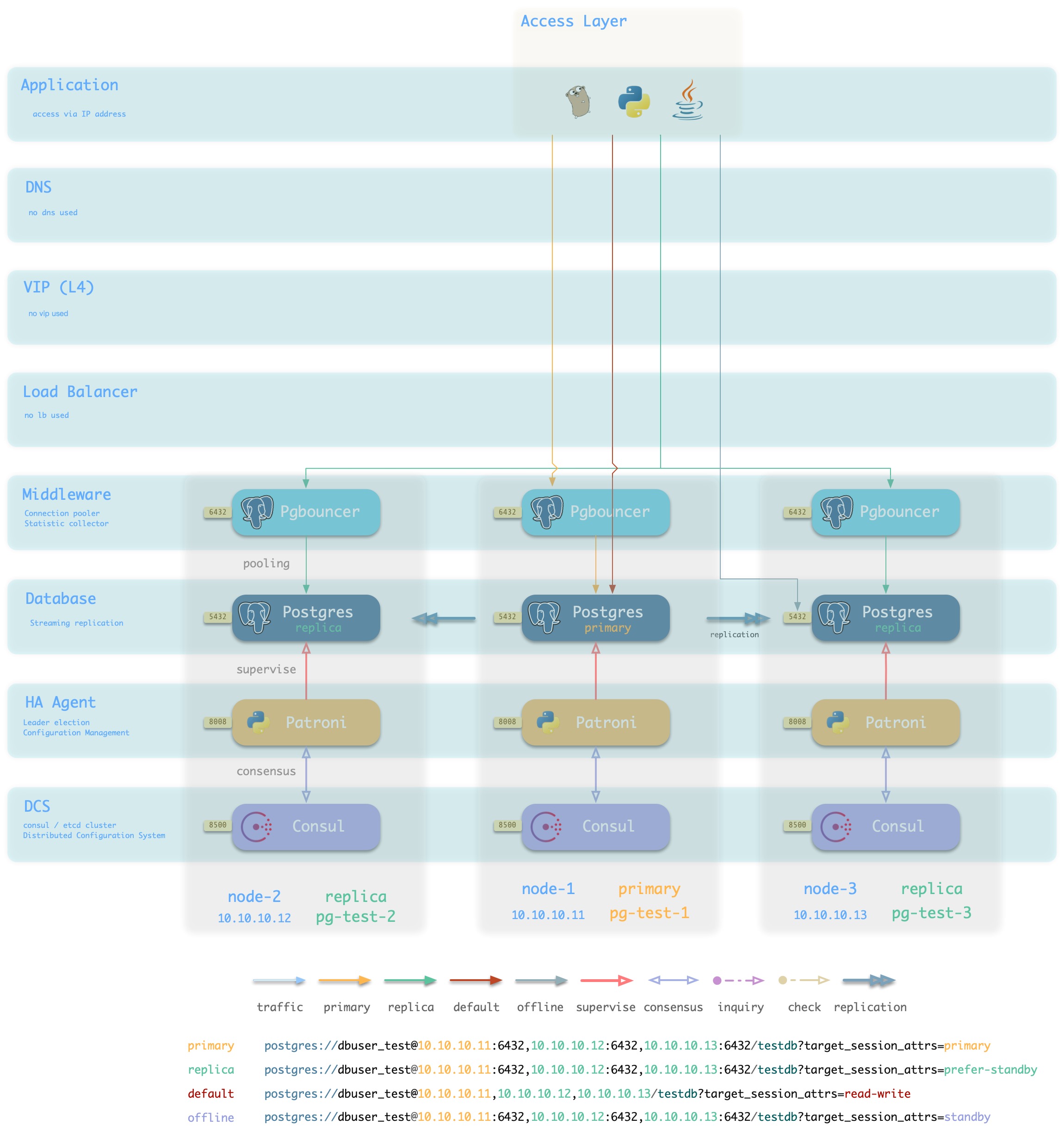
IP
方案简介
采用智能客户端直连数据库IP接入
方案优越性
- 直连数据库/连接池,少一条
- 不依赖额外组件进行主从区分,降低系统复杂性。
方案局限性
方案示意
3.4.2 - DB Service
How to access pigsty default service?
Service, the form of functionality that a database cluster provides to the outside world. In general, a database cluster** should provide at least two types of services**.
- read-write service (primary): users can write to the database
- read-only service (replica): users can access read-only copies
In addition, depending on the specific business scenario, there may be other services.
- offline replica service (offline): a dedicated slave that does not take on online read-only traffic, used for ETL and individual user queries.
- synchronous replica service (standby): read-only service with synchronous commit and no replication delay.
- delayed : Allows services to access old data before a fixed time interval.
- default : A service that allows (administrative) users to manage the database directly, bypassing the connection pool
Default Service
Pigsty provides four services outside the default queue: primary, replica, default, offline.
| service |
port |
purpose |
description |
| primary |
5433 |
production read/write |
connect to cluster primary via connection pool |
| replica |
5434 |
production read-only |
connection to cluster slave via connection pool |
| default |
5436 |
management |
direct connection to cluster master |
| offline |
5438 |
ETL/personal user |
connects directly to an available offline instance of the cluster |
| service |
port |
description |
sample |
| primary |
5433 |
Only production users can connect |
postgres://test@pg-test:5433/test |
| replica |
5434 |
Only production users can connect |
postgres://test@pg-test:5434/test |
| default |
5436 |
Administrator and DML executor can connect |
postgres://dbuser_admin@pg-test:5436/test |
| offline |
5438 |
ETL/STATS Individual users can connect |
postgres://dbuser_stats@pg-test-tt:5438/test
postgres://dbp_vonng@pg-test:5438/test |
Primary Service
The Primary service serves online production read and write access, which maps the cluster’s port 5433, to the primary connection pool (default 6432) port.
The Primary service selects all instances in the cluster as its members, but only those with a true health check /primary can actually take on traffic.
There is one and only one instance in the cluster that is the primary, and only its health check is true.
- name: primary # service name {{ pg_cluster }}_primary
src_ip: "*"
src_port: 5433
dst_port: pgbouncer # 5433 route to pgbouncer
check_url: /primary # primary health check, success when instance is primary
selector: "[]" # select all instance as primary service candidate
Replica Service
The Replica service serves online production read-only access, which maps the cluster’s port 5434, to the slave connection pool (default 6432) port.
The Replica service selects all instances in the cluster as its members, but only those with a true health check /read-only can actually take on traffic, and that health check returns success for all instances (including the master) that can take on read-only traffic. So any member of the cluster can carry read-only traffic.
But by default, only slave libraries carry read-only requests. The Replica service defines selector_backup, a selector that adds the cluster’s master library to the Replica service as a backup instance. The master will start taking read-only traffic** only when all other instances in the Replica service, i.e. **all slaves, are down.
# replica service will route {ip|name}:5434 to replica pgbouncer (5434->6432 ro)
- name: replica # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5434
dst_port: pgbouncer
check_url: /read-only # read-only health check. (including primary)
selector: "[]" # select all instance as replica service candidate
selector_backup: "[? pg_role == `primary`]" # primary are used as backup server in replica service
Default Service
The Default service serves the online primary direct connection, which maps the cluster’s port 5436, to the primary Postgres port (default 5432).
The Default service targets interactive read and write access, including: executing administrative commands, executing DDL changes, connecting to the primary library to execute DML, and executing CDC. interactive operations should not be accessed through connection pools, so the Default service forwards traffic directly to Postgres, bypassing the Pgbouncer.
The Default service is similar to the Primary service, using the same configuration options. The Default parameters are filled in explicitly for demonstration purposes.
# default service will route {ip|name}:5436 to primary postgres (5436->5432 primary)
- name: default # service's actual name is {{ pg_cluster }}-{{ service.name }}
src_ip: "*" # service bind ip address, * for all, vip for cluster virtual ip address
src_port: 5436 # bind port, mandatory
dst_port: postgres # target port: postgres|pgbouncer|port_number , pgbouncer(6432) by default
check_method: http # health check method: only http is available for now
check_port: patroni # health check port: patroni|pg_exporter|port_number , patroni by default
check_url: /primary # health check url path, / as default
check_code: 200 # health check http code, 200 as default
selector: "[]" # instance selector
haproxy: # haproxy specific fields
maxconn: 3000 # default front-end connection
balance: roundrobin # load balance algorithm (roundrobin by default)
default_server_options: 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
Offline Service
The Offline Service is used for offline access and personal queries. It maps the cluster’s 5438 port, to the offline instance Postgres port (default 5432).
The Offline Service is for interactive read-only access, including: ETL, offline large analytics queries, and individual user queries. Interactive operations should not be accessed through connection pools, so the Default service forwards traffic directly to the offline instance of Postgres, bypassing the Pgbouncer.
Offline instances are those with pg_role == offline or with the pg_offline_query flag. Other other slave libraries outside of the Offline instance will act as backup instances for Offline, so that when the Offline instance goes down, the Offline service can still get services from other slave libraries.
# offline service will route {ip|name}:5438 to offline postgres (5438->5432 offline)
- name: offline # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5438
dst_port: postgres
check_url: /replica # offline MUST be a replica
selector: "[? pg_role == `offline` || pg_offline_query ]" # instances with pg_role == 'offline' or instance marked with 'pg_offline_query == true'
selector_backup: "[? pg_role == `replica` && !pg_offline_query]" # replica are used as backup server in offline service
服务定义
Offline service is used for offline access and personal queries. It maps the cluster’s 5438 port, to the offline instance Postgres port (default 5432).
The Offline service is for interactive read-only access, including: ETL, offline large analytics queries, and individual user queries. Interactive operations should not be accessed through connection pools, so the Default service forwards traffic directly to the offline instance of Postgres, bypassing the Pgbouncer.
Offline instances are those with pg_role == offline or with the pg_offline_query flag. Other other slave libraries outside the Offline instance will act as backup instances for Offline, so that when the Offline instance goes down, the Offline service can still get services from other slave libraries.
# primary service will route {ip|name}:5433 to primary pgbouncer (5433->6432 rw)
- name: primary # service name {{ pg_cluster }}_primary
src_ip: "*"
src_port: 5433
dst_port: pgbouncer # 5433 route to pgbouncer
check_url: /primary # primary health check, success when instance is primary
selector: "[]" # select all instance as primary service candidate
# replica service will route {ip|name}:5434 to replica pgbouncer (5434->6432 ro)
- name: replica # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5434
dst_port: pgbouncer
check_url: /read-only # read-only health check. (including primary)
selector: "[]" # select all instance as replica service candidate
selector_backup: "[? pg_role == `primary`]" # primary are used as backup server in replica service
# default service will route {ip|name}:5436 to primary postgres (5436->5432 primary)
- name: default # service's actual name is {{ pg_cluster }}-{{ service.name }}
src_ip: "*" # service bind ip address, * for all, vip for cluster virtual ip address
src_port: 5436 # bind port, mandatory
dst_port: postgres # target port: postgres|pgbouncer|port_number , pgbouncer(6432) by default
check_method: http # health check method: only http is available for now
check_port: patroni # health check port: patroni|pg_exporter|port_number , patroni by default
check_url: /primary # health check url path, / as default
check_code: 200 # health check http code, 200 as default
selector: "[]" # instance selector
haproxy: # haproxy specific fields
maxconn: 3000 # default front-end connection
balance: roundrobin # load balance algorithm (roundrobin by default)
default_server_options: 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
# offline service will route {ip|name}:5438 to offline postgres (5438->5432 offline)
- name: offline # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5438
dst_port: postgres
check_url: /replica # offline MUST be a replica
selector: "[? pg_role == `offline` || pg_offline_query ]" # instances with pg_role == 'offline' or instance marked with 'pg_offline_query == true'
selector_backup: "[? pg_role == `replica` && !pg_offline_query]" # replica are used as backup server in offline service
Mandatory
-
Name (service.name).
service name, the full name of the service is prefixed by the database cluster name and suffixed by service.name, connected by -. For example, a service with name=primary in the pg-test cluster has the full service name pg-test-primary.
-
Port (service.port).
In Pigsty, services are exposed to the public by default in the form of NodePort, so exposing the port is mandatory. However, if you use an external load balancing service access scheme, you can also distinguish the services in other ways.
-
selector (service.selector).
The selector specifies the instance members of the service, in the form of a JMESPath that filters variables from all cluster instance members. The default [] selector will pick all cluster members.
Optional
-
backup selector (service.selector).
Optional backup selector service.selector_backup will select or mark the list of instances used for service backup, i.e. the backup instance takes over the service only when all other members of the cluster fail. For example, the primary instance can be added to the alternate set of the replica service, so that the master can still carry the read-only traffic of the cluster when all the slaves fail.
-
source_ip (service.src_ip).
Indicates the IP address used externally by the service. The default is *, which is all IP addresses on the local machine. Using vip will use the vip_address variable to take the value, or you can also fill in the specific IP address supported by the NIC.
-
Host port (service.dst_port).
Which port on the target instance will the service’s traffic be directed to? postgres will point to the port that the database listens on, pgbouncer will point to the port that the connection pool listens on, or you can fill in a fixed port number.
-
health check method (service.check_method):
How does the service check the health status of the instance? Currently only HTTP is supported
-
Health check port (service.check_port):
Which port does the service check the instance on to get the health status of the instance? patroni will get it from Patroni (default 8008), pg_exporter will get it from PG Exporter (default 9630), or user can fill in a custom port number.
-
Health check path (service.check_url):
The URL PATH used by the service to perform HTTP checks. / is used by default for health checks, and PG Exporter and Patroni provide a variety of health check methods that can be used to differentiate between master and slave traffic. For example, /primary will only return success for the master, and /replica will only return success for the slave. /read-only, on the other hand, will return success for any instance that supports read-only (including the master).
-
health check code (service.check_code):
The code expected for HTTP health checks, default is 200
-
Haproxy-specific configuration (service.haproxy) :
Proprietary configuration items about the service provisioning software (HAproxy)
3.4.3 - HA
Introduction to High Availability
The database cluster created by Pigsty is a distributed, highly available database cluster.
Effectively, as long as any instance in the cluster survives, the cluster can provide complete read and write services and read-only services to the outside world.
Each database instance in the database cluster is idempotent in use, and any instance can provide complete read and write services through the built-in load balancing components.
Database clusters can automatically perform fault detection and master-slave switching, and common failures can self-heal within seconds to tens of seconds, and read-only traffic is not affected during this period.
High Availability
Two core scenarios: Switchover, Failover
Four core issues: Fault detection, Fencing, master selection, traffic switching
For a walkthrough of the core scenarios of high availability, please refer to [High Availability Walkthrough](… /… /… /tasks/ha-drill/) section.
Patroni-based high availability scenarios
The Patroni based high availability solution is simple to deploy, does not require the use of special hardware, and has a large number of real production use cases to back it up.
Pigsty’s high availability solution is based on Patroni, vip-manager, haproxy
Patroni is based on DCS (etcd/consul/zookeeper) to reach a master selection consensus.
Patroni’s failure detection uses heartbeat packet to keep alive, DCS lease mechanism to achieve. The main repository holds the lease, and if Qin loses its deer, the world will fight it.
Patroni’s Fencing is based on the Linux kernel module watchdog.
Patroni provides master-slave health checks for easy integration with external load balancers.
Haproxy and VIP based access layer solutions
Pigsty sandboxes use by default L2 VIP and Haproxy based access layer solutions, Pigsty provides several optional [database access](… /… /… /concept/provision/access/) methods.
!
Haproxy idempotently is deployed on each instance of the cluster, and any one or more Haproxy instances can act as a load balancer for the cluster.
Haproxy uses a Node Port-like approach to expose its services to the public. By default, port 5433 provides read and write services to the cluster, while port 5434 provides read-only services to the cluster.
High availability of Haproxy itself can be achieved in several ways.
- Using a smart client that connects to the database using the DNS or service discovery mechanism provided by Consul.
- Using a smart client that uses the Multi-Host feature to populate all instances in the cluster.
- Use VIPs bound in front of Haproxy (Layer 2 or 4)
- Use external load balancers to guarantee
- Use DNS polling to resolve to multiple Haproxy, clients will re-execute DNS resolution and retry after a disconnect.
Patroni’s behavior in case of failure
| 场景 |
位置 |
Patroni的动作 |
| PG Down |
replica |
尝试重新拉起PG |
| Patroni Down |
replica |
PG随之关闭(维护模式下不变) |
| Patroni Crash |
replica |
PG不会随Patroni一并关闭 |
| DCS Network Partition |
replica |
无事 |
| Promote |
replica |
将PG降为从库并重新挂至主库。 |
| PG Down |
primary |
尝试重启PG
超过master_start_timeout后执行Failover |
| Patroni Down |
primary |
关闭PG并触发Failover |
| Patroni Crash |
primary |
触发Failover,可能触发脑裂。
可通过watchdog fencing避免。 |
| DCS Network Partition |
primary |
主库降级为从库,触发Failover |
| DCS Down |
DCS |
主库降级为从库,集群中没有主库,不可写入。 |
| 同步模式下无可用备选 |
|
临时切换为异步复制。
恢复为同步复制前不会Failover |
The proper configuration of Patroni can handle most failures. However, a scenario like DCS Down (Consul/Etcd down or network unreachable) will render all production database clusters unwritable and requires special attention. **Must ensure that DCS availability is higher than database availability. **
Known Issue
Please try to ensure that the server’s time synchronization service starts before Patroni.
3.4.4 - File Structure
Introduction to pigsty file structure hierarchy
The following parameters are related to the Pigsty directory structure
- pg_dbsu_home: home directory of the default user of Postgres, default is
/var/lib/pgsql
- pg_bin_dir: Postgres binary directory, defaults to
/usr/pgsql/bin/
- pg_data: Postgres database directory, defaults to
/pg/data
- pg_fs_main: Postgres main data disk mount point, default is
/export
- pg_fs_bkup: Postgres backup disk mount point, default is
/var/backups (optional, you can also choose to backup to the main data disk)
Overview
#------------------------------------------------------------------------------
# Create Directory
#------------------------------------------------------------------------------
# this assumes that
# /pg is shortcut for postgres home
# {{ pg_fs_main }} contains the main data (MUST ALREADY MOUNTED)
# {{ pg_fs_bkup }} contains archive and backup data (MUST ALREADY MOUNTED)
# cluster-version is the default parent folder for pgdata (e.g pg-test-12)
#------------------------------------------------------------------------------
# default variable:
# pg_fs_main = /export fast ssd
# pg_fs_bkup = /var/backups cheap hdd
#
# /pg -> /export/postgres/pg-test-12
# /pg/data -> /export/postgres/pg-test-12/data
#------------------------------------------------------------------------------
- name: Create postgresql directories
tags: pg_dir
become: yes
block:
- name: Make sure main and backup dir exists
file: path={{ item }} state=directory owner=root mode=0777
with_items:
- "{{ pg_fs_main }}"
- "{{ pg_fs_bkup }}"
# pg_cluster_dir: "{{ pg_fs_main }}/postgres/{{ pg_cluster }}-{{ pg_version }}"
- name: Create postgres directory structure
file: path={{ item }} state=directory owner={{ pg_dbsu }} group=postgres mode=0700
with_items:
- "{{ pg_fs_main }}/postgres"
- "{{ pg_cluster_dir }}"
- "{{ pg_cluster_dir }}/bin"
- "{{ pg_cluster_dir }}/log"
- "{{ pg_cluster_dir }}/tmp"
- "{{ pg_cluster_dir }}/conf"
- "{{ pg_cluster_dir }}/data"
- "{{ pg_cluster_dir }}/meta"
- "{{ pg_cluster_dir }}/stat"
- "{{ pg_cluster_dir }}/change"
- "{{ pg_backup_dir }}/postgres"
- "{{ pg_backup_dir }}/arcwal"
- "{{ pg_backup_dir }}/backup"
- "{{ pg_backup_dir }}/remote"
PG二进制目录结构
在RedHat/CentOS上,默认的Postgres发行版安装位置为
/usr/pgsql-${pg_version}/
安装剧本会自动创建指向当前安装版本的软连接,例如,如果安装了13版本的Postgres,则有:
/usr/pgsql -> /usr/pgsql-13
因此,默认的pg_bin_dir为/usr/pgsql/bin/,该路径会在/etc/profile.d/pgsql.sh中添加至所有用户的PATH环境变量中。
PG数据目录结构
Pigsty假设用于部署数据库实例的单个节点上至少有一块主数据盘(pg_fs_main),以及一块可选的备份数据盘(pg_fs_bkup)。通常主数据盘是高性能SSD,而备份盘是大容量廉价HDD。
#------------------------------------------------------------------------------
# Create Directory
#------------------------------------------------------------------------------
# this assumes that
# /pg is shortcut for postgres home
# {{ pg_fs_main }} contains the main data (MUST ALREADY MOUNTED)
# {{ pg_fs_bkup }} contains archive and backup data (MAYBE ALREADY MOUNTED)
# {{ pg_cluster }}-{{ pg_version }} is the default parent folder
# for pgdata (e.g pg-test-12)
#------------------------------------------------------------------------------
# default variable:
# pg_fs_main = /export fast ssd
# pg_fs_bkup = /var/backups cheap hdd
#
# /pg -> /export/postgres/pg-test-12
# /pg/data -> /export/postgres/pg-test-12/data
PG数据库集簇目录结构
# basic
{{ pg_fs_main }} /export # contains all business data (pg,consul,etc..)
{{ pg_dir_main }} /export/postgres # contains postgres main data
{{ pg_cluster_dir }} /export/postgres/pg-test-13 # contains cluster `pg-test` data (of version 13)
/export/postgres/pg-test-13/bin # binary scripts
/export/postgres/pg-test-13/log # misc logs
/export/postgres/pg-test-13/tmp # tmp, sql files, records
/export/postgres/pg-test-13/conf # configurations
/export/postgres/pg-test-13/data # main data directory
/export/postgres/pg-test-13/meta # identity information
/export/postgres/pg-test-13/stat # stats information
/export/postgres/pg-test-13/change # changing records
{{ pg_fs_bkup }} /var/backups # contains all backup data (pg,consul,etc..)
{{ pg_dir_bkup }} /var/backups/postgres # contains postgres backup data
{{ pg_backup_dir }} /var/backups/postgres/pg-test-13 # contains cluster `pg-test` backup (of version 13)
/var/backups/postgres/pg-test-13/backup # base backup
/var/backups/postgres/pg-test-13/arcwal # WAL archive
/var/backups/postgres/pg-test-13/remote # mount NFS/S3 remote resources here
# links
/pg -> /export/postgres/pg-test-12 # pg root link
/pg/data -> /export/postgres/pg-test-12/data # real data dir
/pg/backup -> /var/backups/postgres/pg-test-13/backup # base backup
/pg/arcwal -> /var/backups/postgres/pg-test-13/arcwal # WAL archive
/pg/remote -> /var/backups/postgres/pg-test-13/remote # mount NFS/S3 remote resources here
Pgbouncer配置文件结构
Pgbouncer使用Postgres用户运行,配置文件位于/etc/pgbouncer。配置文件包括:
pgbouncer.ini,主配置文件userlist.txt:列出连接池中的用户pgb_hba.conf:列出连接池用户的访问权限database.txt:列出连接池中的数据库
3.4.5 - Access Control
Introduction to Pigsty ACL models
PostgreSQL提供了两类访问控制机制:认证(Authentication) 与 权限(Privileges)
Pigsty带有基本的访问控制模型,足以覆盖绝大多数应用场景。
用户体系
Pigsty的默认权限系统包含四个默认用户与四类默认角色 。
用户可以通过修改 pg_default_roles 来修改默认用户的名字,但默认角色的名字不建议新用户自行修改。
默认角色
Pigsty带有四个默认角色:
- 只读角色(
dbrole_readonly):只读
- 读写角色(
dbrole_readwrite):读写,继承dbrole_readonly
- 管理角色(
dbrole_admin):�执行DDL变更,继承dbrole_readwrite
- 离线角色(
dbrole_offline):只读,用于执行慢查询/ETL/交互查询,仅允许在特定实例上访问。
默认用户
Pigsty带有四个默认用户:
- 超级用户(
postgres),数据库的拥有者与创建者,与操作系统用户一致
- 复制用户(
replicator),用于主从复制的用户。
- 监控用户(
dbuser_monitor),用于监控数据库指标的用户。
- 管理员(
dbuser_admin),执行日常管理操作与数据库变更。(通常供DBA使用)
| name |
attr |
roles |
desc |
| dbrole_readonly |
Cannot login |
|
role for global readonly access |
| dbrole_readwrite |
Cannot login |
dbrole_readonly |
role for global read-write access |
| dbrole_offline |
Cannot login |
|
role for restricted read-only access (offline instance) |
| dbrole_admin |
Cannot login
Bypass RLS |
pg_monitor
pg_signal_backend
dbrole_readwrite |
role for object creation |
| postgres |
Superuser
Create role
Create DB
Replication
Bypass RLS |
|
system superuser |
| replicator |
Replication
Bypass RLS |
pg_monitor
dbrole_readonly |
system replicator |
| dbuser_monitor |
16 connections |
pg_monitor
dbrole_readonly |
system monitor user |
| dbuser_admin |
Bypass RLS
Superuser |
dbrole_admin |
system admin user |
相关配置
以下是8个默认用户/角色的相关变量
默认用户有专用的用户名与密码配置选项,会覆盖 pg_default_roles中的选项。因此无需在其中为默认用户配置密码。
出于安全考虑,不建议为DBSU配置密码,故pg_dbsu没有专门的密码配置项。如有需要,用户可以在pg_default_roles中为超级用户指定密码。
# - system roles - #
pg_replication_username: replicator # system replication user
pg_replication_password: DBUser.Replicator # system replication password
pg_monitor_username: dbuser_monitor # system monitor user
pg_monitor_password: DBUser.Monitor # system monitor password
pg_admin_username: dbuser_admin # system admin user
pg_admin_password: DBUser.Admin # system admin password
# - default roles - #
# chekc http://pigsty.cc/zh/docs/concepts/provision/acl/ for more detail
pg_default_roles:
# common production readonly user
- name: dbrole_readonly # production read-only roles
login: false
comment: role for global readonly access
# common production read-write user
- name: dbrole_readwrite # production read-write roles
login: false
roles: [dbrole_readonly] # read-write includes read-only access
comment: role for global read-write access
# offline have same privileges as readonly, but with limited hba access on offline instance only
# for the purpose of running slow queries, interactive queries and perform ETL tasks
- name: dbrole_offline
login: false
comment: role for restricted read-only access (offline instance)
# admin have the privileges to issue DDL changes
- name: dbrole_admin
login: false
bypassrls: true
comment: role for object creation
roles: [dbrole_readwrite,pg_monitor,pg_signal_backend]
# dbsu, name is designated by `pg_dbsu`. It's not recommend to set password for dbsu
- name: postgres
superuser: true
comment: system superuser
# default replication user, name is designated by `pg_replication_username`, and password is set by `pg_replication_password`
- name: replicator
replication: true
roles: [pg_monitor, dbrole_readonly]
comment: system replicator
# default replication user, name is designated by `pg_monitor_username`, and password is set by `pg_monitor_password`
- name: dbuser_monitor
connlimit: 16
comment: system monitor user
roles: [pg_monitor, dbrole_readonly]
# default admin user, name is designated by `pg_admin_username`, and password is set by `pg_admin_password`
- name: dbuser_admin
bypassrls: true
comment: system admin user
roles: [dbrole_admin]
# default stats user, for ETL and slow queries
- name: dbuser_stats
password: DBUser.Stats
comment: business offline user for offline queries and ETL
roles: [dbrole_offline]
Pgbouncer用户
Pgbouncer的操作系统用户将与数据库超级用户保持一致,默认都使用postgres。
Pigsty默认会使用Postgres管理用户作为Pgbouncer的管理用户,使用Postgres的监控用户同时作为Pgbouncer的监控用户。
Pgbouncer的用户权限通过/etc/pgbouncer/pgb_hba.conf进行控制。
Pgbounce的用户列表通过/etc/pgbouncer/userlist.txt文件进行控制。
定义用户时,只有显式添加pgbouncer: true 的用户,才会被加入到Pgbouncer的用户列表中。
用户的定义
Pigsty中的用户可以通过以下两个参数进行声明,两者使用同样的形式:
用户的创建
Pigsty的用户可以通过 pgsql-createuser.yml 剧本完成创建
权限模型
默认情况下,角色拥有的权限如下所示:
GRANT USAGE ON SCHEMAS TO dbrole_readonly
GRANT SELECT ON TABLES TO dbrole_readonly
GRANT SELECT ON SEQUENCES TO dbrole_readonly
GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly
GRANT USAGE ON SCHEMAS TO dbrole_offline
GRANT SELECT ON TABLES TO dbrole_offline
GRANT SELECT ON SEQUENCES TO dbrole_offline
GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly
GRANT INSERT, UPDATE, DELETE ON TABLES TO dbrole_readwrite
GRANT USAGE, UPDATE ON SEQUENCES TO dbrole_readwrite
GRANT TRUNCATE, REFERENCES, TRIGGER ON TABLES TO dbrole_admin
GRANT CREATE ON SCHEMAS TO dbrole_admin
GRANT USAGE ON TYPES TO dbrole_admin
其他业务用户默认都应当属于四种默认角色之一:只读,读写,管理员,离线访问。
| Owner |
Schema |
Type |
Access privileges |
| username |
|
function |
=X/postgres |
|
|
|
postgres=X/postgres |
|
|
|
dbrole_readonly=X/postgres |
|
|
|
dbrole_offline=X/postgres |
| username |
|
schema |
postgres=UC/postgres |
|
|
|
dbrole_readonly=U/postgres |
|
|
|
dbrole_offline=U/postgres |
|
|
|
dbrole_admin=C/postgres |
| username |
|
sequence |
postgres=rwU/postgres |
|
|
|
dbrole_readonly=r/postgres |
|
|
|
dbrole_readwrite=wU/postgres |
|
|
|
dbrole_offline=r/postgres |
| username |
|
table |
postgres=arwdDxt/postgres |
|
|
|
dbrole_readonly=r/postgres |
|
|
|
dbrole_readwrite=awd/postgres |
|
|
|
dbrole_offline=r/postgres |
|
|
|
dbrole_admin=Dxt/postgres |
所有用户都可以访问所有模式,只读用户可以读取所有表,读写用户可以对所有表进行DML操作,管理员可以执行DDL变更操作。离线用户与只读用户类似,但只允许访问pg_role == 'offline' 或带有 pg_offline_query = true 的实例。
数据库权限
数据库有三种权限:CONNECT, CREATE, TEMP,以及特殊的属主OWNERSHIP。数据库的定义由参数 pg_database 控制。一个完整的数据库定义如下所示:
pg_databases:
- name: meta # name is the only required field for a database
owner: postgres # optional, database owner
template: template1 # optional, template1 by default
encoding: UTF8 # optional, UTF8 by default
locale: C # optional, C by default
allowconn: true # optional, true by default, false disable connect at all
revokeconn: false # optional, false by default, true revoke connect from public # (only default user and owner have connect privilege on database)
tablespace: pg_default # optional, 'pg_default' is the default tablespace
connlimit: -1 # optional, connection limit, -1 or none disable limit (default)
extensions: # optional, extension name and where to create
- {name: postgis, schema: public}
parameters: # optional, extra parameters with ALTER DATABASE
enable_partitionwise_join: true
pgbouncer: true # optional, add this database to pgbouncer list? true by default
comment: pigsty meta database # optional, comment string for database
默认情况下,如果数据库没有配置属主,那么数据库超级用户dbsu将会作为数据库的默认OWNER,否则将为指定用户。
默认情况下,所有用户都具有对新创建数据库的CONNECT 权限,如果希望回收该权限,设置 revokeconn == true,则该权限会被回收。只有默认用户(dbsu|admin|monitor|replicator)与数据库的属主才会被显式赋予CONNECT权限。同时,admin|owner将会具有CONNECT权限的GRANT OPTION,可以将CONNECT权限转授他人。
如果希望实现不同数据库之间的访问隔离,可以为每一个数据库创建一个相应的业务用户作为owner,并全部设置revokeconn选项。这种配置对于多租户实例尤为实用。
创建新对象
默认情况下,出于安全考虑,Pigsty会撤销PUBLIC用户在数据库下CREATE新模式的权限,同时也会撤销PUBLIC用户在public模式下创建新关系的权限。数据库超级用户与管理员不受此限制,他们总是可以在任何地方执行DDL变更。
Pigsty非常不建议使用业务用户执行DDL变更,因为PostgreSQL的ALTER DEFAULT PRIVILEGE仅针对“由特定用户创建的对象”生效,默认情况下超级用户postgres和dbuser_admin创建的对象拥有默认的权限配置,如果用户希望授予业务用户dbrole_admin,请在使用该业务管理员执行DDL变更时首先执行:
SET ROLE dbrole_admin; -- dbrole_admin 创建的对象具有正确的默认权限
在数据库中创建对象的权限与用户是否为数据库属主无关,这只取决于创建该用户时是否为该用户赋予管理员权限。
pg_users:
- {name: test1, password: xxx , groups: [dbrole_readwrite]} # 不能创建Schema与对象
- {name: test2, password: xxx , groups: [dbrole_admin]} # 可以创建Schema与对象
认证模型
HBA是Host Based Authentication的缩写,可以将其视作IP黑白名单。
HBA配置方式
在Pigsty中,所有实例的HBA都由配置文件生成而来,最终生成的HBA规则取决于实例的角色(pg_role)
Pigsty的HBA由下列变量控制:
pg_hba_rules: 环境统一的HBA规则pg_hba_rules_extra: 特定于实例或集群的HBA规则pgbouncer_hba_rules: 链接池使用的HBA规则pgbouncer_hba_rules_extra: 特定于实例或集群的链接池HBA规则
每个变量都是由下列样式的规则组成的数组:
- title: allow intranet admin password access
role: common
rules:
- host all +dbrole_admin 10.0.0.0/8 md5
- host all +dbrole_admin 172.16.0.0/12 md5
- host all +dbrole_admin 192.168.0.0/16 md5
基于角色的HBA
role = common的HBA规则组会安装到所有的实例上,而其他的取值,例如(role : primary)则只会安装至pg_role = primary的实例上。因此用户可以通过角色体系定义灵活的HBA规则。
作为一个特例,role: offline 的HBA规则,除了会安装至pg_role == 'offline'的实例,也会安装至pg_offline_query == true的实例上。
默认配置
在默认配置下,主库与从库会使用以下的HBA规则:
- 超级用户通过本地操作系统认证访问
- 其他用户可以从本地用密码访问
- 复制用户可以从局域网段通过密码访问
- 监控用户可以通过本地访问
- 所有人都可以在元节点上使用密码访问
- 管理员可以从局域网通过密码访问
- 所有人都可以从内网通过密码访问
- 读写用户(生产业务账号)可以通过本地(链接池)访问
(部分访问控制转交链接池处理)
- 在从库上:只读用户(个人)可以从本地(链接池)访问。
(意味主库上拒绝只读用户连接)
pg_role == 'offline' 或带有pg_offline_query == true的实例上,会添加允许dbrole_offline分组用户访问的HBA规则。
#==============================================================#
# Default HBA
#==============================================================#
# allow local su with ident"
local all postgres ident
local replication postgres ident
# allow local user password access
local all all md5
# allow local/intranet replication with password
local replication replicator md5
host replication replicator 127.0.0.1/32 md5
host all replicator 10.0.0.0/8 md5
host all replicator 172.16.0.0/12 md5
host all replicator 192.168.0.0/16 md5
host replication replicator 10.0.0.0/8 md5
host replication replicator 172.16.0.0/12 md5
host replication replicator 192.168.0.0/16 md5
# allow local role monitor with password
local all dbuser_monitor md5
host all dbuser_monitor 127.0.0.1/32 md5
#==============================================================#
# Extra HBA
#==============================================================#
# add extra hba rules here
#==============================================================#
# primary HBA
#==============================================================#
#==============================================================#
# special HBA for instance marked with 'pg_offline_query = true'
#==============================================================#
#==============================================================#
# Common HBA
#==============================================================#
# allow meta node password access
host all all 10.10.10.10/32 md5
# allow intranet admin password access
host all +dbrole_admin 10.0.0.0/8 md5
host all +dbrole_admin 172.16.0.0/12 md5
host all +dbrole_admin 192.168.0.0/16 md5
# allow intranet password access
host all all 10.0.0.0/8 md5
host all all 172.16.0.0/12 md5
host all all 192.168.0.0/16 md5
# allow local read/write (local production user via pgbouncer)
local all +dbrole_readonly md5
host all +dbrole_readonly 127.0.0.1/32 md5
#==============================================================#
# Ad Hoc HBA
#===========================================================
4 - Monitor
Learn about the Monitor GUI provided by Pigsty
Pigsty provides a professional and easy-to-use PostgreSQL monitoring system that distills the industry’s monitoring best practices. You can easily modify and customize it; reuse the monitoring infrastructure or integrate it with other monitoring systems. The following table provides quick navigation links to each monitoring panel’s introduction page.
Note: The bolded panels are the monitoring panels provided by Pigsty by default, while the others are additional features provided by the Enterprise Edition.
The default monitoring is sufficient to cover most scenarios, if you need more in-depth control and insight, please contact Business Support

4.1 - Index
Jump to specific dashboard with one click
Note: The bolded panels are the monitoring panels provided by Pigsty by default, while the others are additional features provided by the Enterprise Edition.
The default monitoring is sufficient to cover most scenarios, if you need more in-depth control and insight, please contact Business Support
4.2 - Overview
Introduction to overview dashboards
4.2.1 - Home
Introduction to Pigsty Home Dashboard
Home Dashboard is the default home page for Pigsty.
There are links to other internal systems
You can post announcements, add navigation to your business system, integrate other monitoring panels, etc. here.
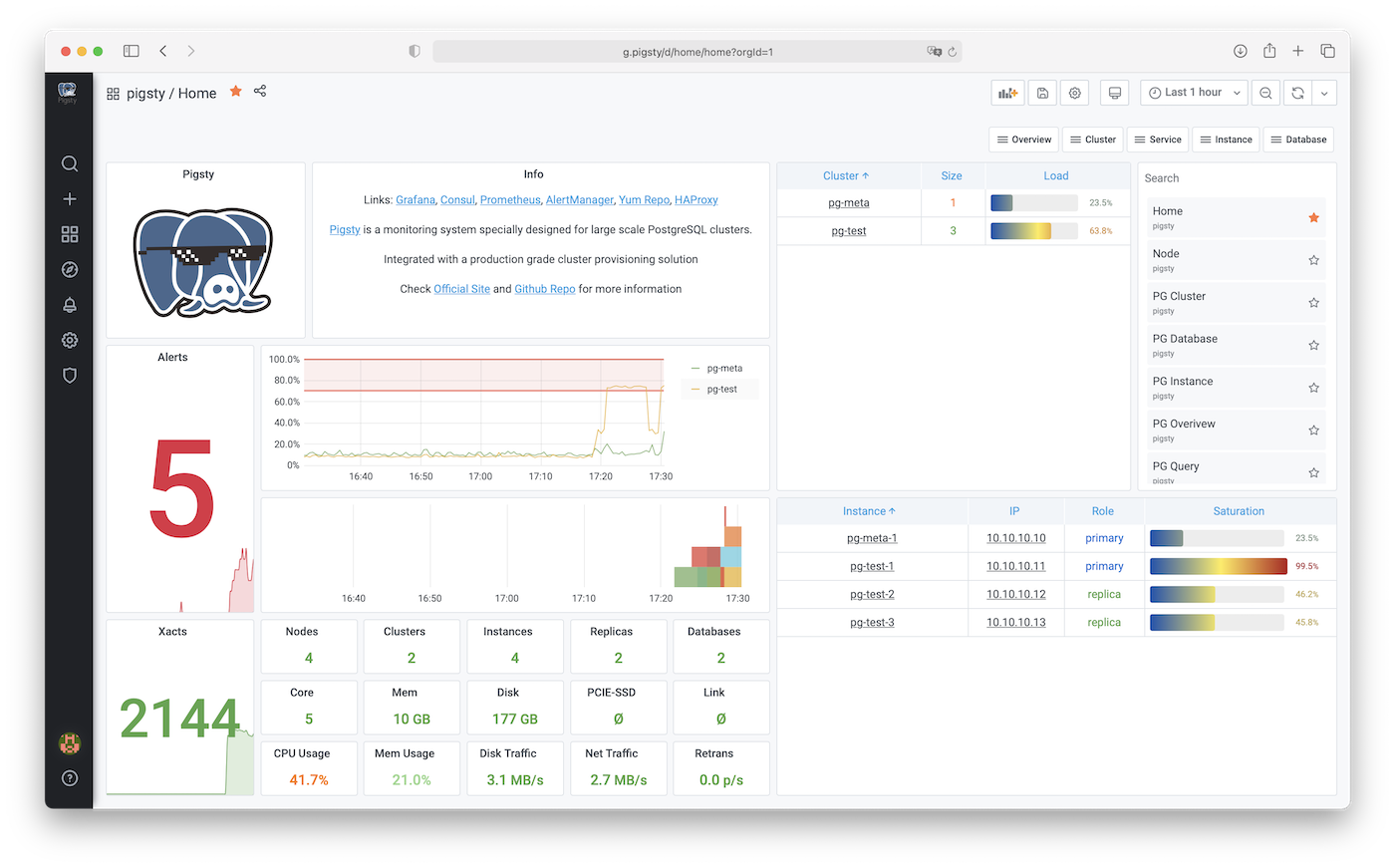
4.2.2 - PG Overview
PG Overview面板简介
PG Overview是总揽整个环境中所有数据库集群的地方。
这里提供了到所有数据库集群与数据库实例的快捷导航,并直观地呈现出整个环境的资源状态,异常事件,系统饱和度等等。
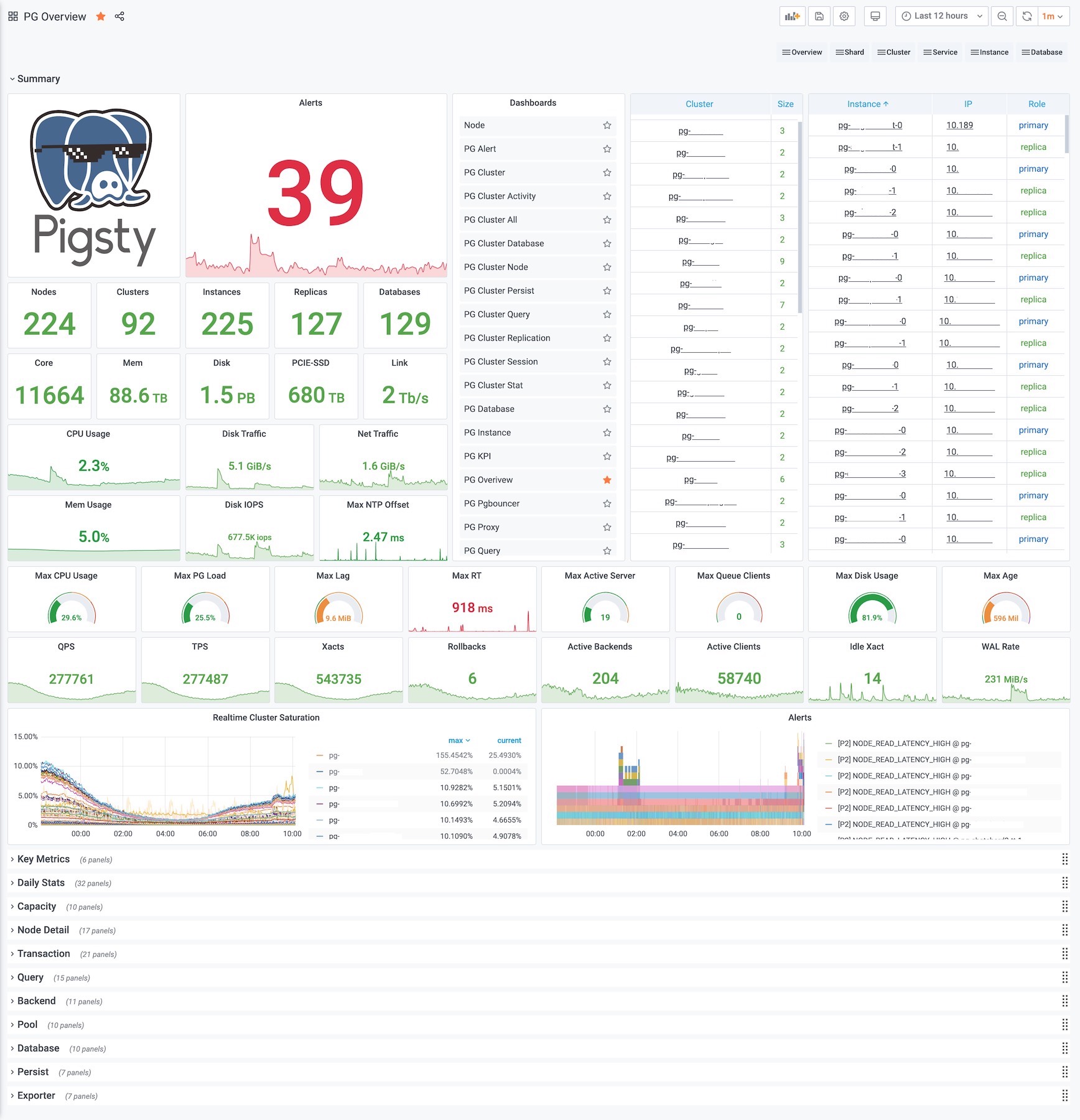
4.2.3 - PG Shard
PG Shard针对水平分片的并行集群而专门设计。
PG Shard针对水平分片的并行集群而专门设计。
水平分片是Pigsty企业版提供的高级特性,可以将较大(TB到PB)的业务数据拆分为多个水平的业务集群对外提供服务。
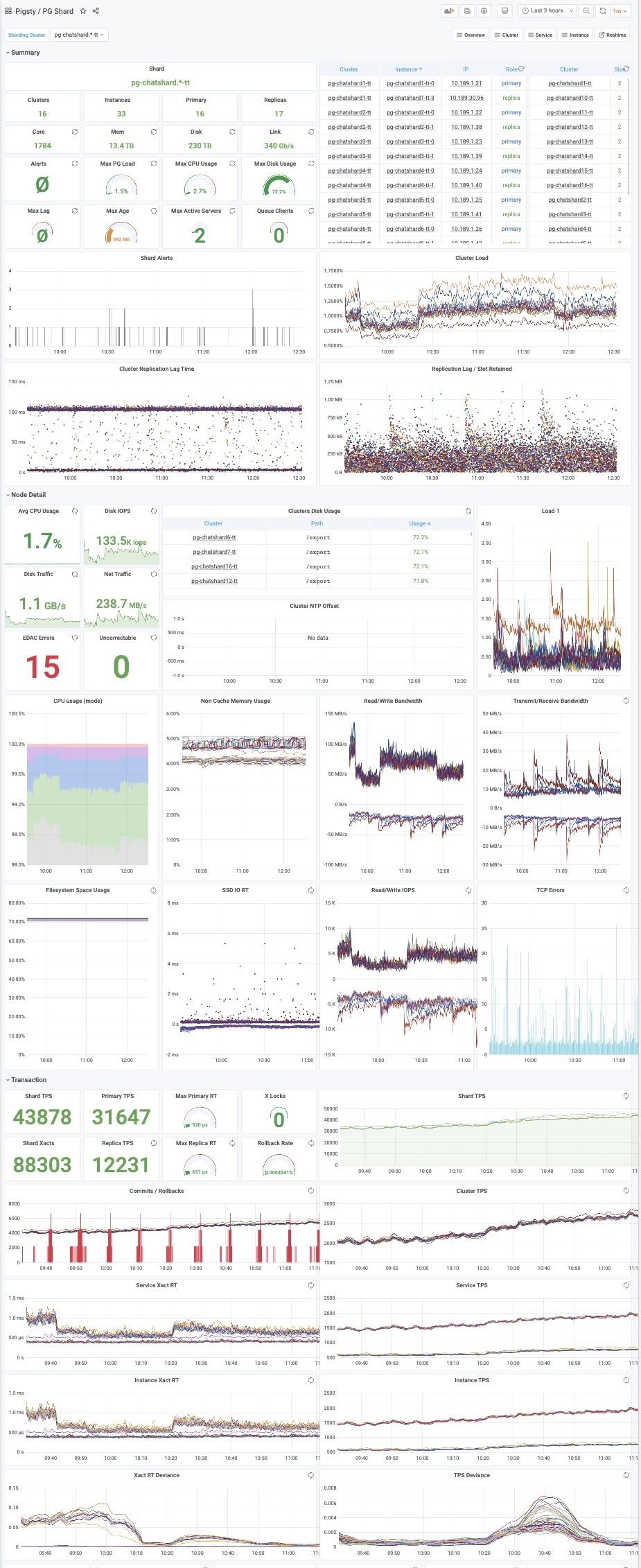
4.2.4 - PG Alert
PG Alert面板简介
PG Alert是总揽整个环境中所有报警信息的地方。包括所有与报警相关指标的快速面板。
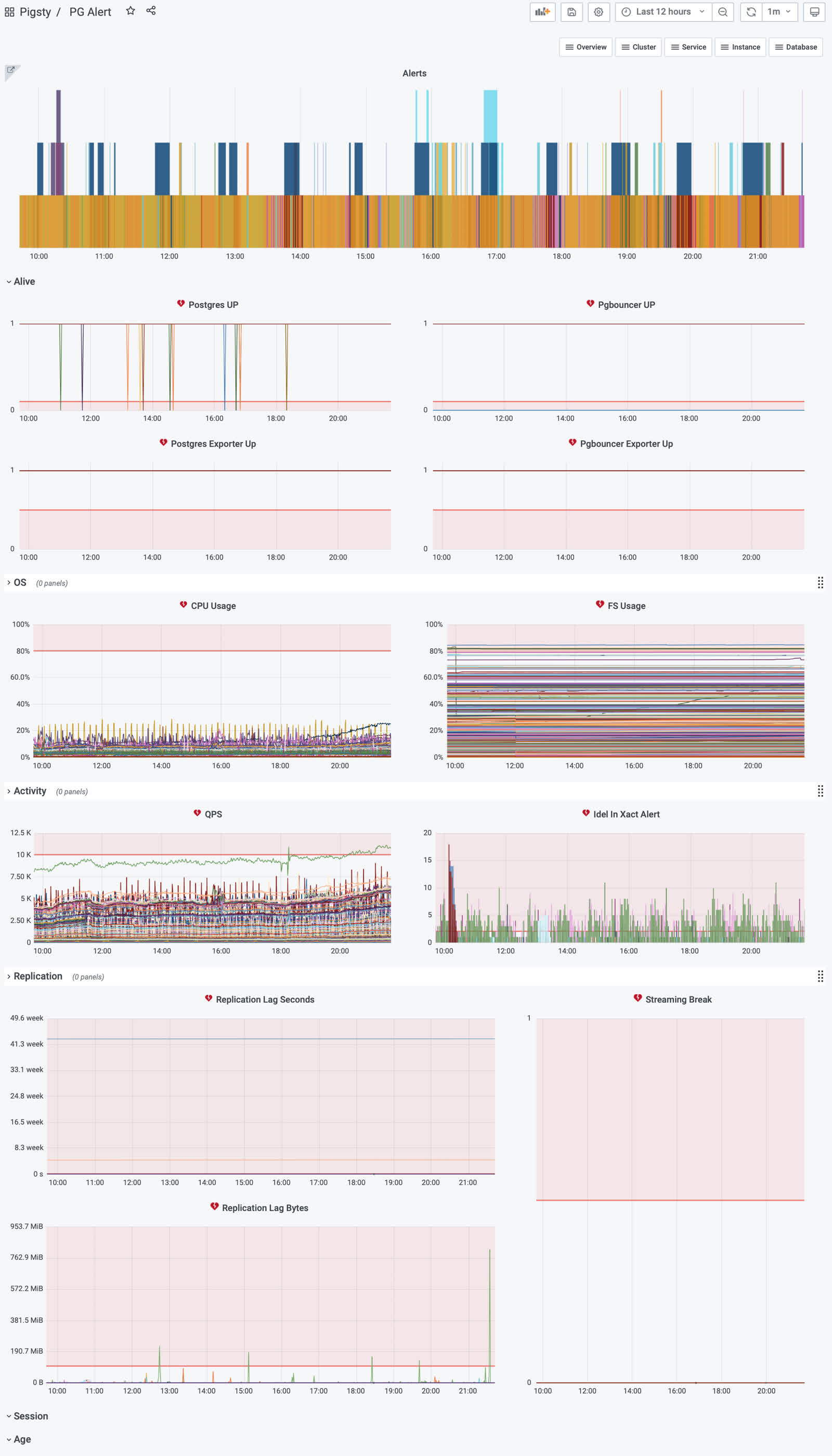
4.2.5 - PG KPI
PG KPI 展示了环境中关键指标的概览
PG KPI 展示了环境中关键指标的概览,您可以在这里快速定位整个环境中的异常。
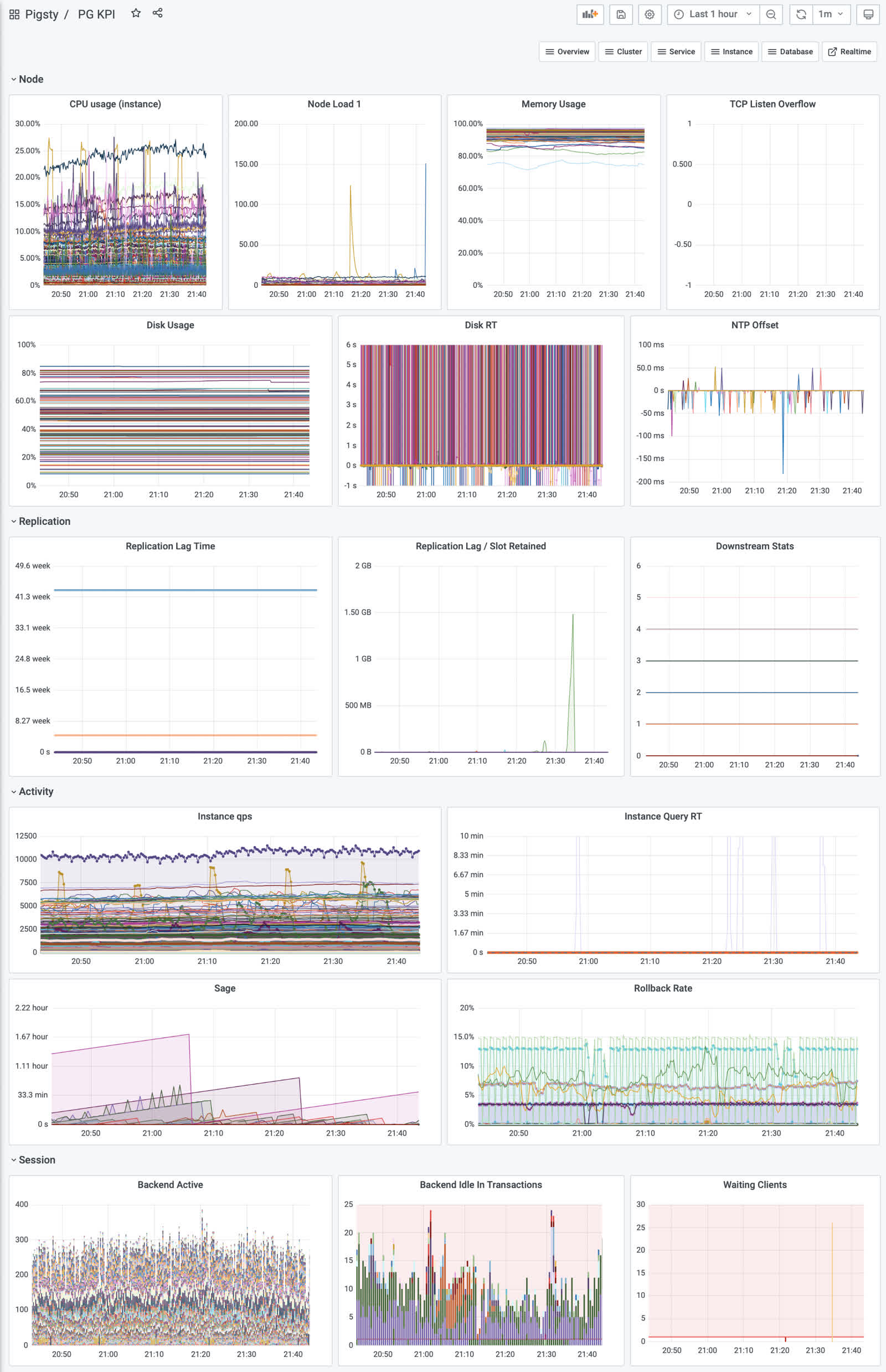
4.2.6 - PG Capacity
PG Capacity 展示了数据库的水位状态
PG Capacity 展示了数据库的水位状态,这是Pigsty企业版提供的面板。
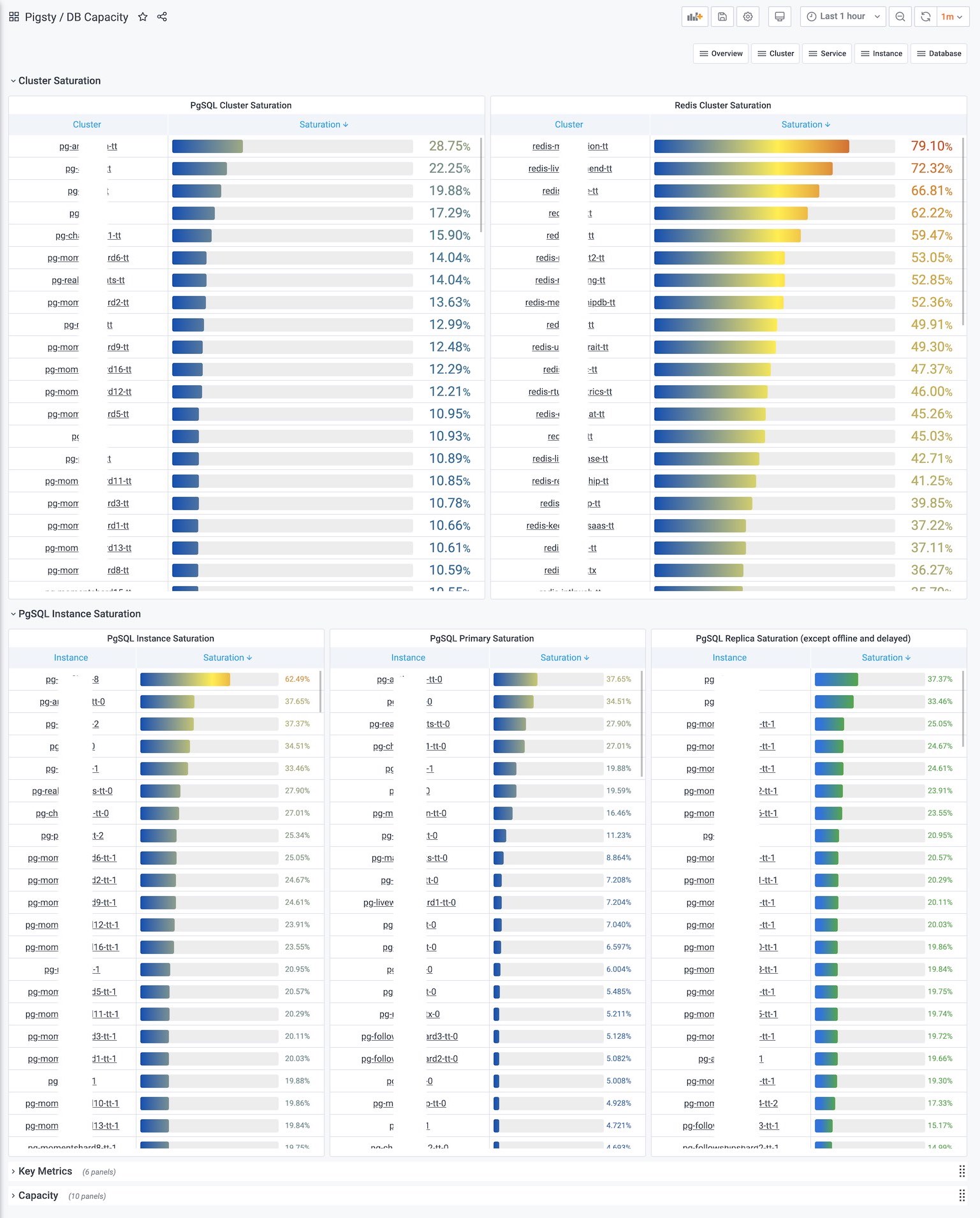
4.2.7 - PG Change
PG Change包含了整个环境中所发布的历史DDL变更。
PG Change包含了整个环境中所发布的历史DDL变更。
该面板必须与 Pigsty 企业版特性: DDL发布系统 共同使用
4.2.8 - PG Monitor
PG Monitor面板简介
PG Monitor是监控系统的自我监控,包括Grafana,Prometheus,Consul,Nginx的监控。
自我监控属于Pigsty企业版特性。
4.3 - Cluster
Cluster level dashboards
Cluster Level Monitoring
Cluster level montoring could be the most commonly used Dashboards because cluster is the basic business unit. so the most complete and comprehensive information is aggregated at the cluster level.
Most monitoring charts are generalizations and up-rolls of instance-level monitoring, i.e., they change from showing details within a single instance to showing information about each instance within the cluster and metrics aggregated at the cluster and service levels.
Cluster Overview
Cluster overview at Cluster level has a few more things compared to instance level.
- Timeline and leadership, when a Failover or Switchover occurs in the database, the timeline is stepped and the leadership changes.
- Cluster Topology, the cluster topology shows the replication topology in the cluster and the replication method used (synchronous/asynchronous).
- Cluster Load, which includes the load of the entire cluster in real time, 1 minute, 5 minutes, 15 minutes. and Load1 of each node in the cluster
- Cluster alarms and events.
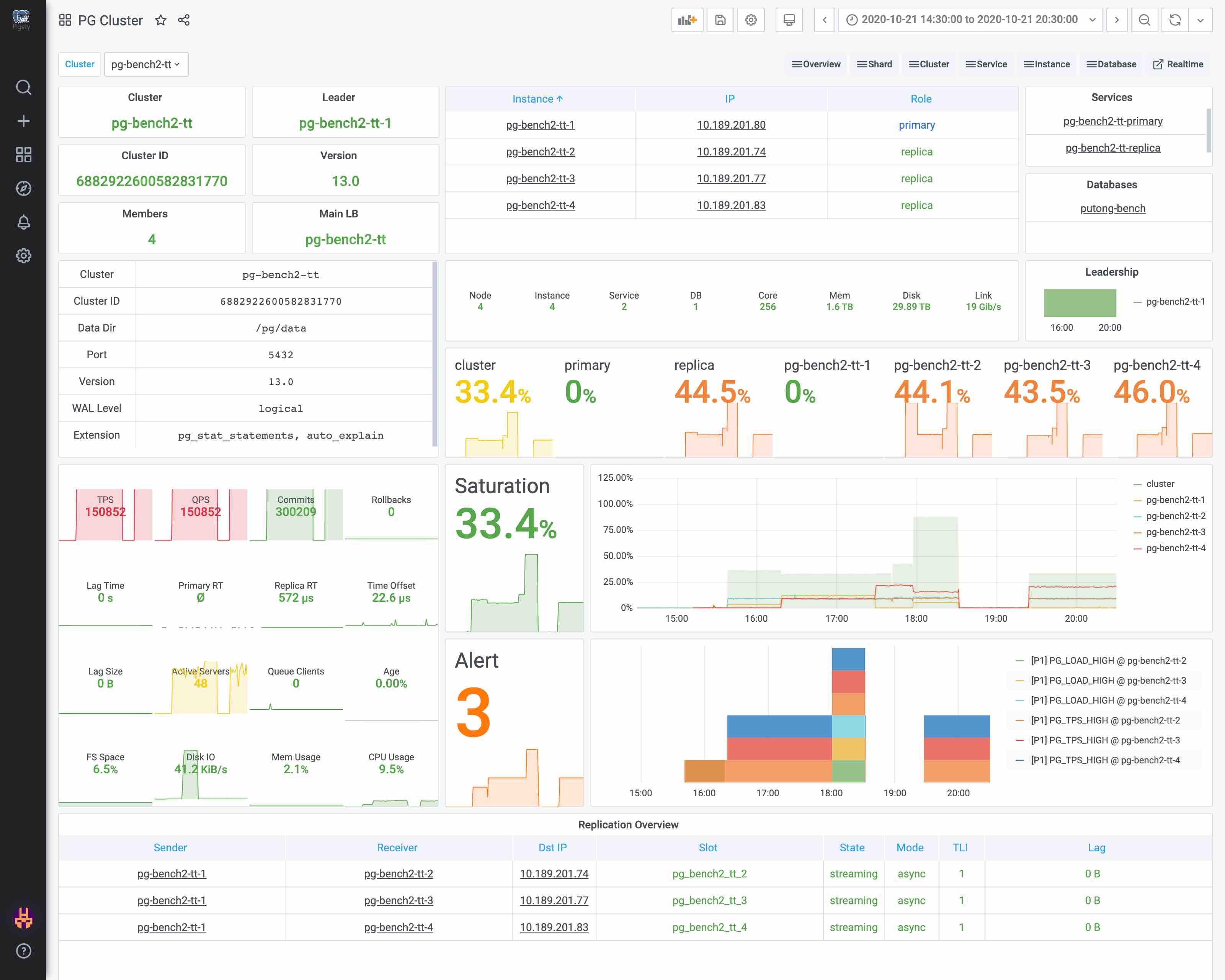
4.3.1 - PG Cluster
PG Cluster面板简介
PG Cluster 关注单个集群的整体情况,并提供到其他集群信息的导航。
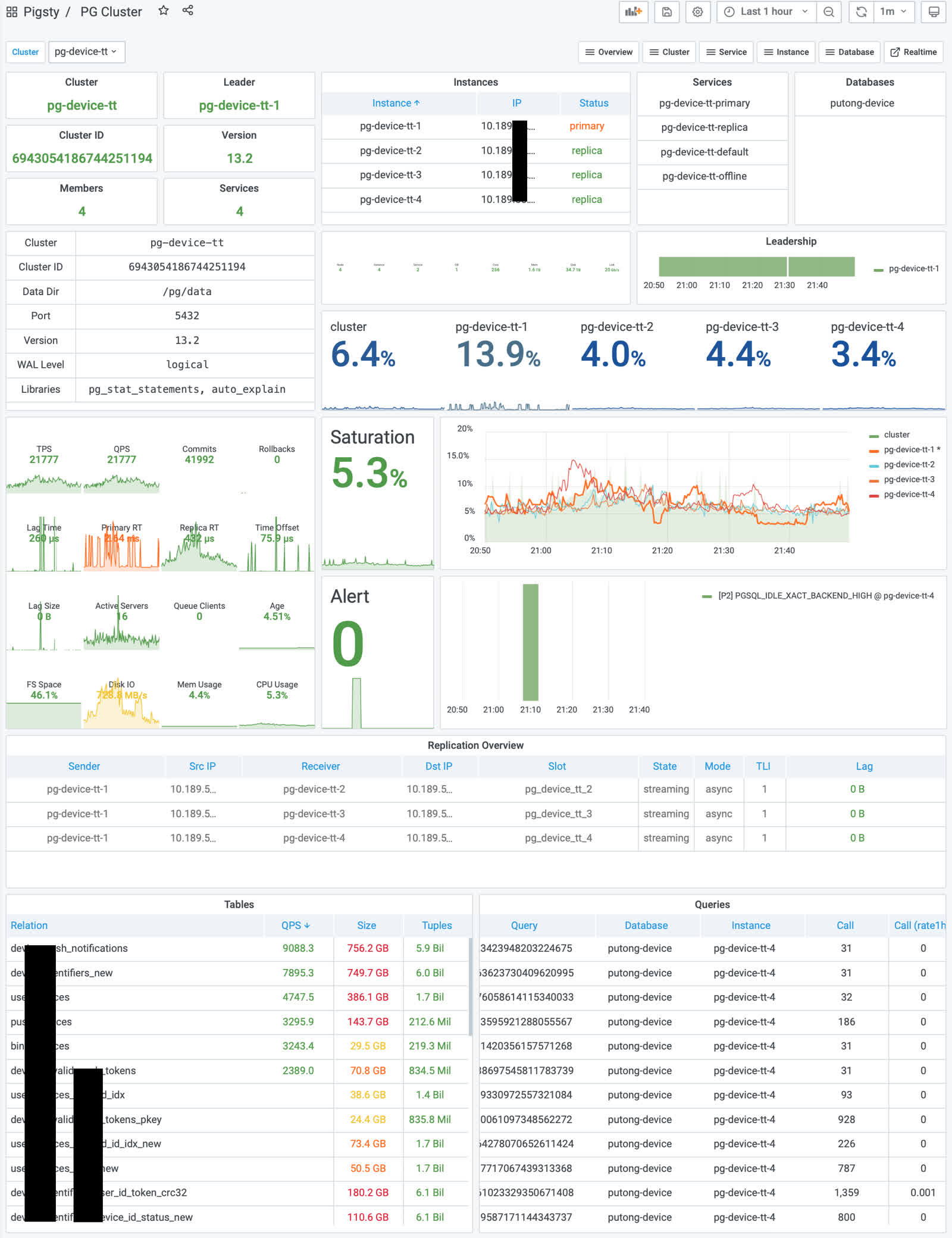
DB监控:PG集群
PG集群监控是最常用的Dashboard,因为PG以集群为单位提供服务,因此Cluster集合了最完整全面的信息。
大多数监控图都是实例级监控的泛化与上卷,即从展示单个实例内的细节,变为展现集群内每个实例的信息,以及集群和服务层次聚合后的指标。
集群概览
Cluster级别的集群概览相比实例级别多了一些东西:
- 时间线与领导权,当数据库发生Failover或Switchover时,时间线会步进,领导权会发生变化。
- 集群拓扑,集群拓扑展现了集群中的复制拓扑,以及采用的复制方式(同步/异步)。
- 集群负载,包括整个集群实时、1分钟、5分钟、15分钟的负载情况。以及集群中每个节点的Load1
- 集群报警与事件。

集群复制
Cluster级别的Dashboard与Instance级别Dashboard最重要的区别之一就是提供了整个集群的复制全景。包括:
-
集群中的主库与级联桥接库。集群是否启用同步提交,同步从库名称。桥接库与级联库数量,最大从库配置
-
成对出现的Walsender与Walreceiver列表,体现一对主从关系的复制状态
-
以秒和字节衡量的复制延迟(通常1秒的复制延迟对应10M~100M不等的字节延迟),复制槽堆积量。
-
从库视角的复制延迟
-
集群中从库的数量,备份或拉取从库时可以从这里看到异常。
-
集群的LSN进度,用于整体展示集群的复制状态与持久化状态。

节点指标
PG机器的相关指标,按照集群进行聚合。

事务与查询
与实例级别的类似,但添加了Service层次的聚合(一个集群通常提供primary与standby两种Service)。

其他指标与实例级别差别不大。
4.3.2 - PG Cluster Replication
PG Cluster Replication 关注单个集群内的复制活动。
PG Cluster Replication 关注单个集群内的复制活动。
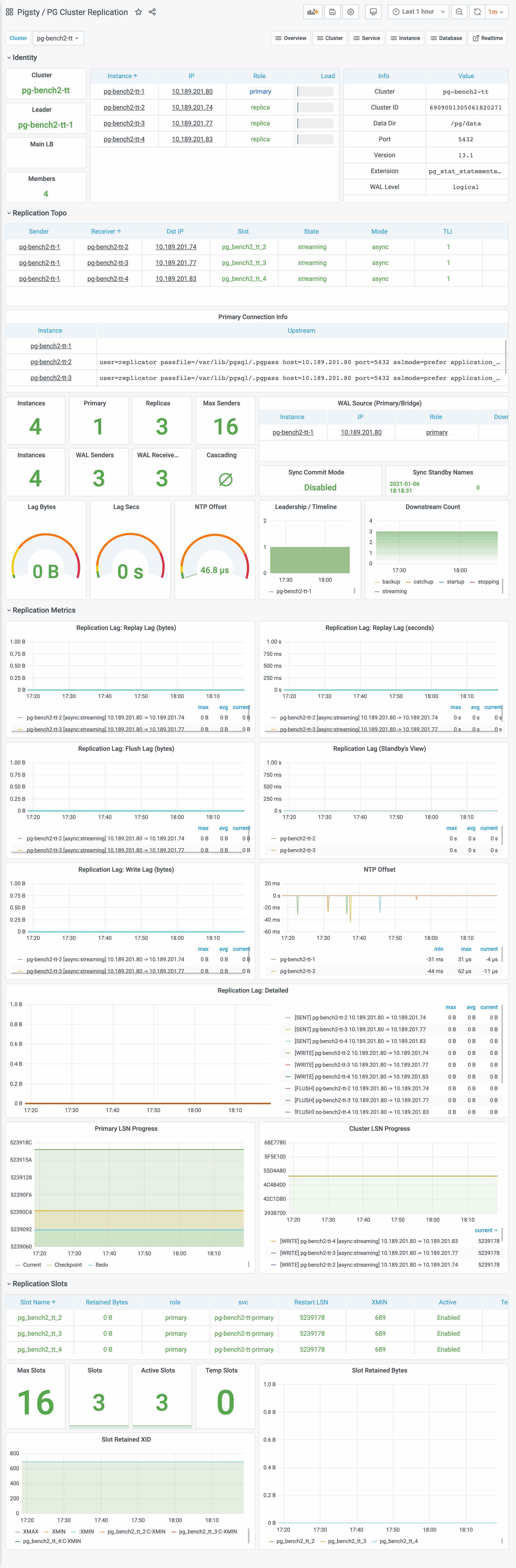
4.3.3 - PG Cluster Activity
PG Cluster Activity 关注特定集群的活动状态,包括事务,查询,锁,等等。
PG Cluster Activity 关注单个集群的活动,包括事务,查询,锁,等等。
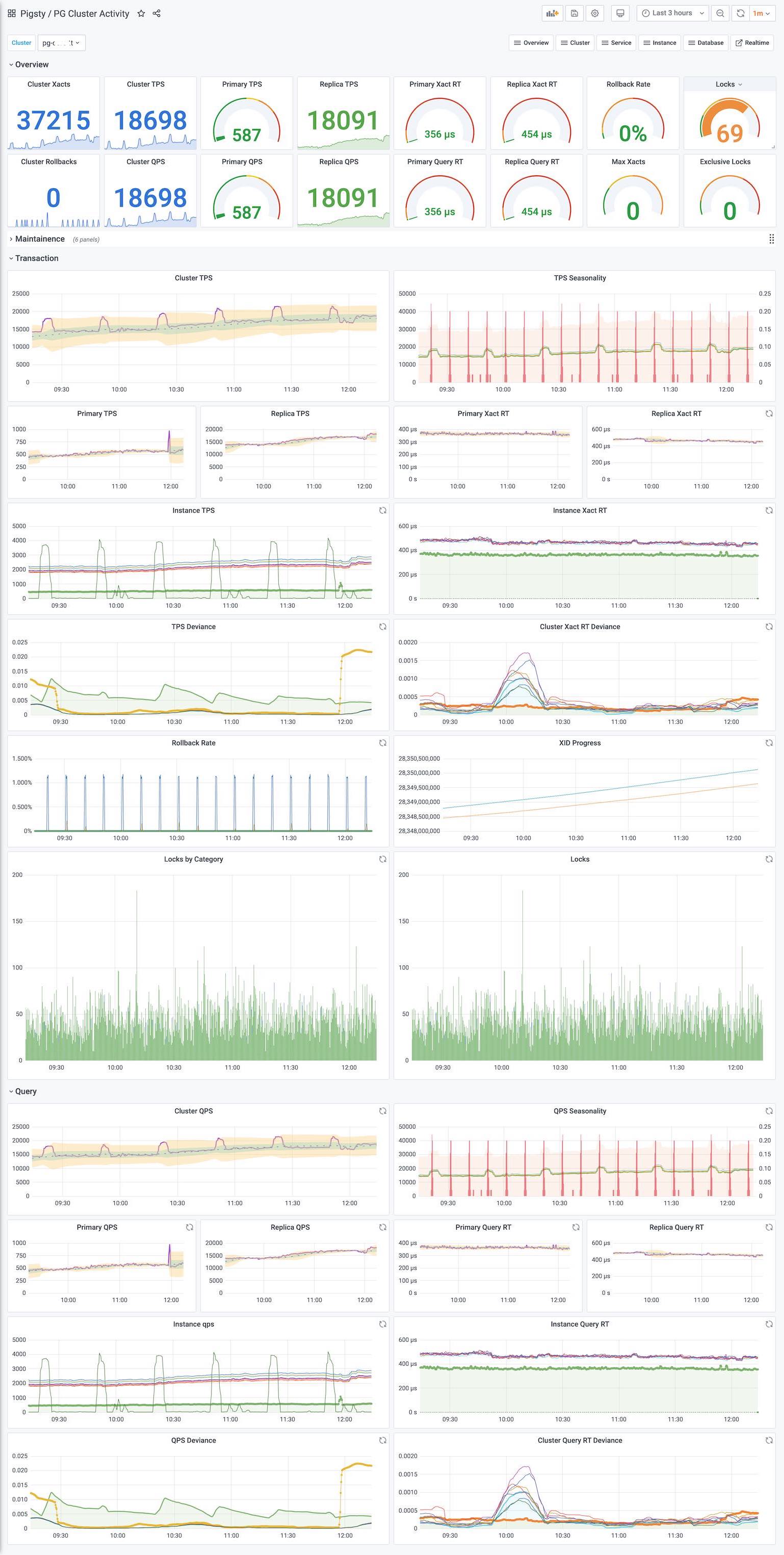
4.3.4 - PG Cluster Session
PG Cluster Session 关注特定集群中连接、连接池的工作状态。
PG Cluster Session 关注特定集群中连接、连接池的工作状态。

4.3.5 - PG Cluster Node
PG Cluster Node关注整个集群的机器资源使用情况
PG Cluster Node关注整个集群的机器资源使用情况
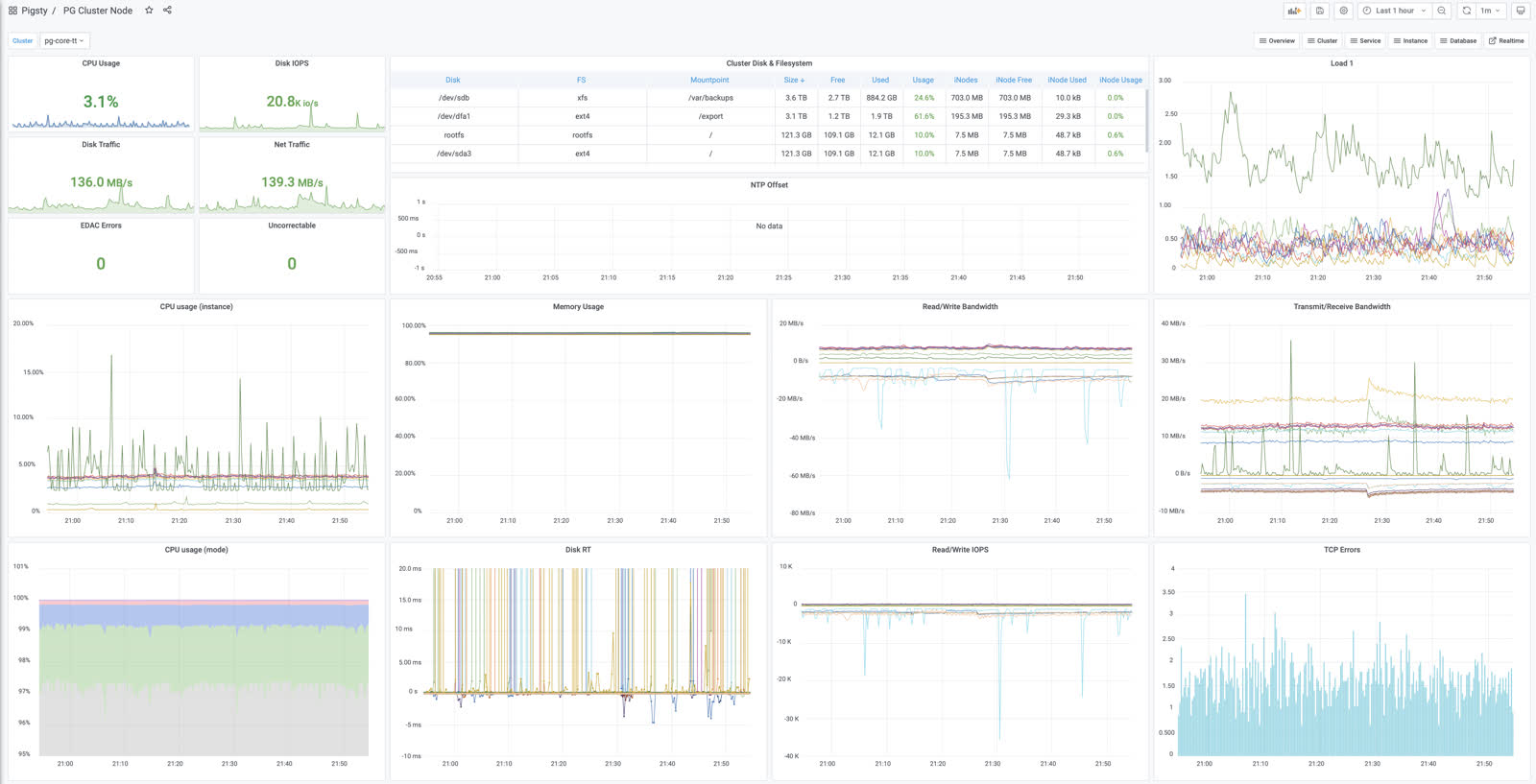
4.3.6 - PG Cluster Persist
PG Cluster Persist 关注集群的持久化,检查点与IO状态。
PG Cluster Persist 关注集群的持久化,检查点与IO状态。
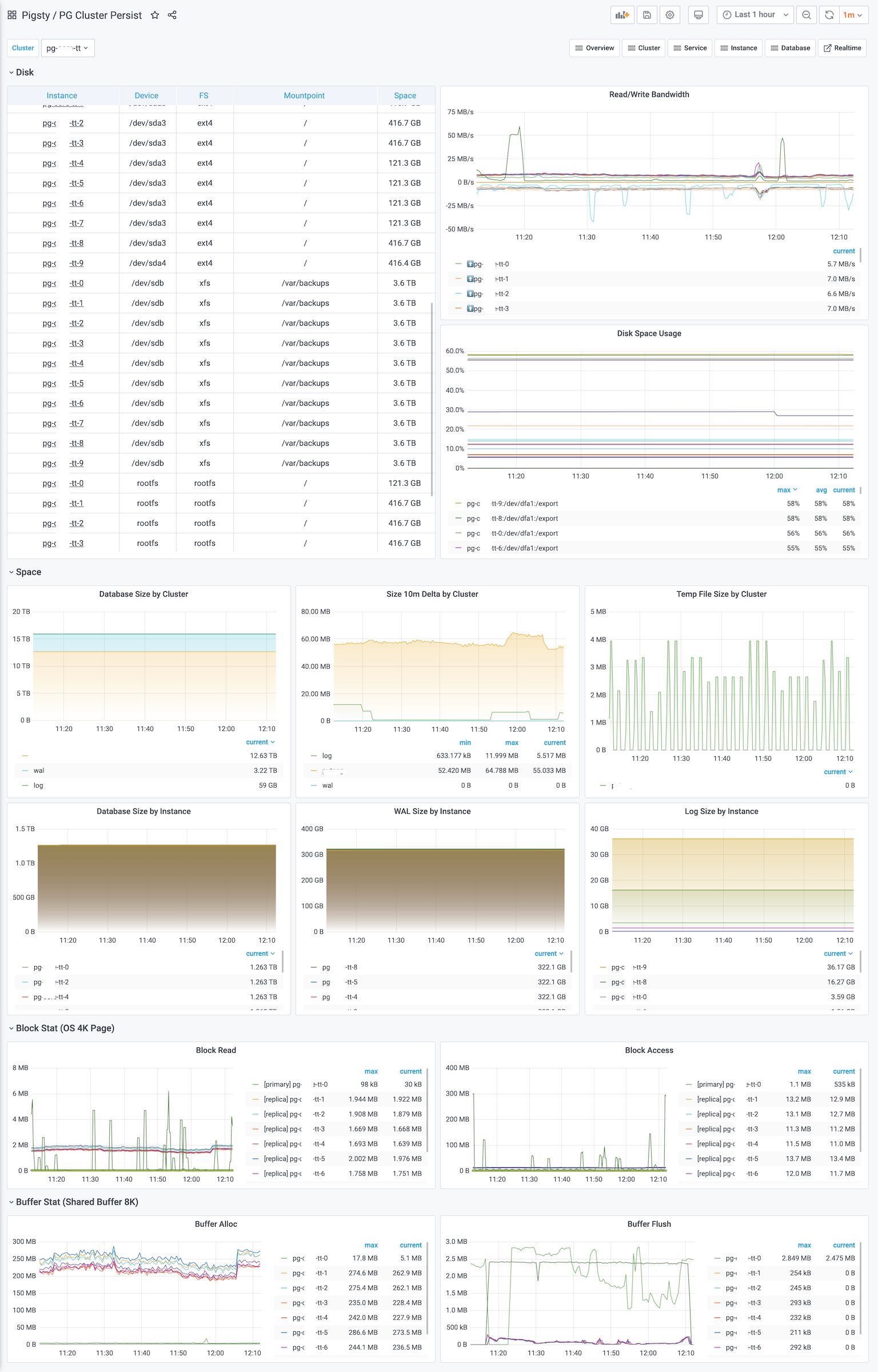
4.3.7 - PG Cluster Database
PG Cluster Database 关注特定集群中与数据库有关的指标:TPS,增删改查,年龄等。
PG Cluster Activity 关注单个集群的活动,包括事务,查询,锁,等等。
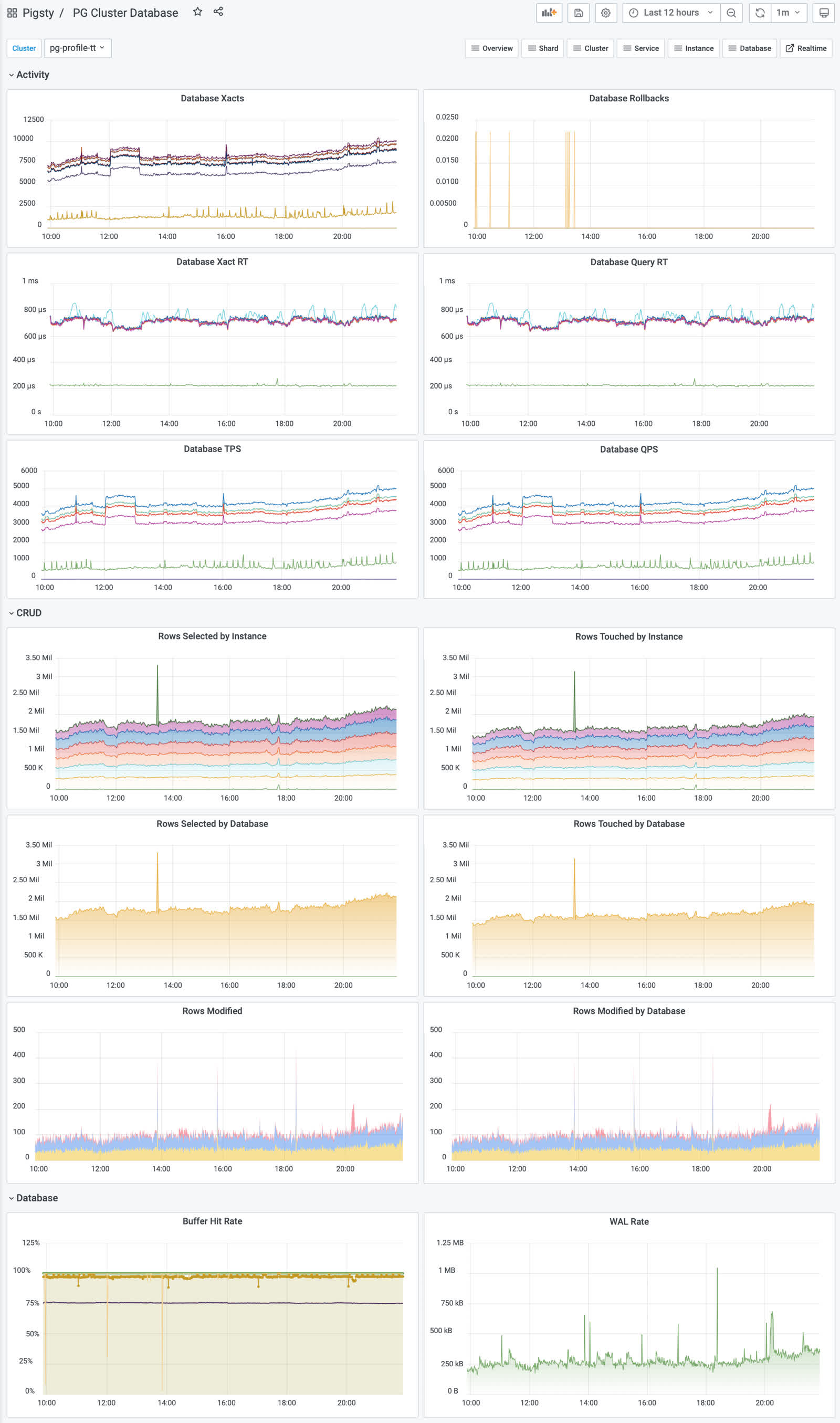
4.3.8 - PG Cluster Stat
PG Cluster Stat 用于展示集群在过去一段统计周期内的用量信息
PG Cluster Stat 用于展示集群在过去一段统计周期内的用量信息


4.3.9 - PG Cluster Table
PG Cluster Table 关注单个集群中所有表的增删改查情况
PG Cluster Table 关注单个集群中所有表的增删改查情况
4.3.10 - PG Cluster Table Detail
PG Cluster Table Detail关注单个集群中某张特定表的增删改查情况
PG Cluster Table Detail关注单个集群中某张特定表的增删改查情况
您可以从该面板跳转到
- PG Cluster Table: 上卷至集群中的所有表
- PG Instance Table Detail:查看这张表在集群中的单个特定实例上的详细状态。
4.3.11 - PG Cluster Query
PG Cluster Query 关注特定集群内所有的查询状况
PG Cluster Query 关注特定集群内所有的查询状况
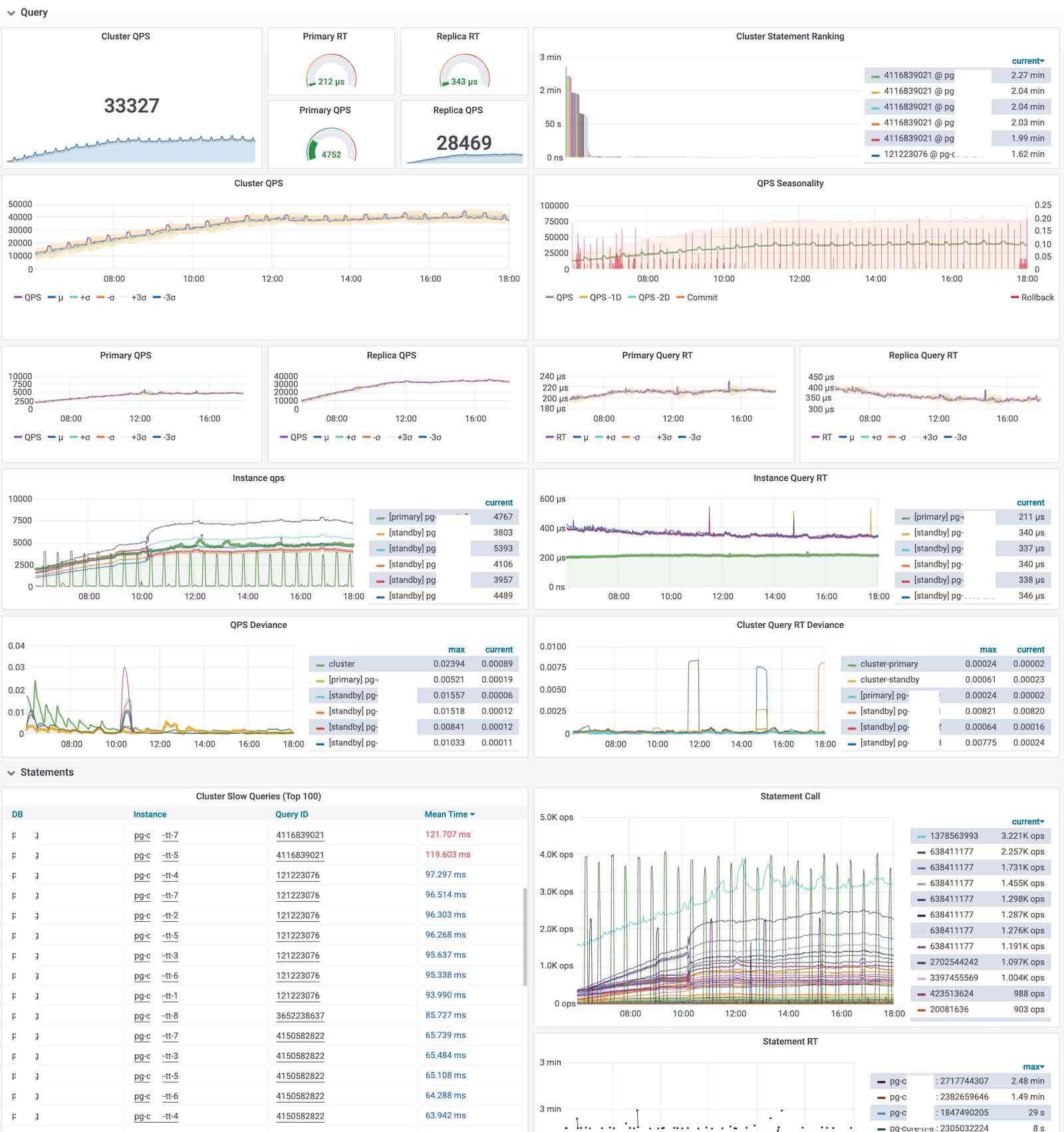
DB监控:PG慢查询平台
显示慢查询相关的指标,上方是本实例的查询总览。鼠标悬停查询ID可以看到查询语句,点击查询ID会跳转到对应的查询细分指标页(Query Detail)。
- 左侧是格式化后的查询语句,右侧是查询的主要指标,包括
- 每秒查询数量:QPS
- 实时的平均响应时间(RT Realtime)
- 每次查询平均返回的行数
- 每次查询平均用于BlockIO的时长
- 响应时间的均值,标准差,最小值,最大值(自从上一次统计周期以来)
- 查询最近一天的调用次数,返回行数,总耗时。以及自重置以来的总调用次数。
- 下方是指定时间段的查询指标图表,是概览指标的细化。
4.3.12 - PG Cluster Health
PG Cluster Health基于规则对集群进行健康度评分
PG Cluster Health基于规则对集群进行健康度评分。

4.3.13 - PG Cluster Log
PG Cluster Log面板简介
PG Cluster Log 关注单个集群内的所有日志事件。
该面板提供了到外部的日志摘要平台的连接,这是一个Pigsty高级特性,仅在企业版中提供。
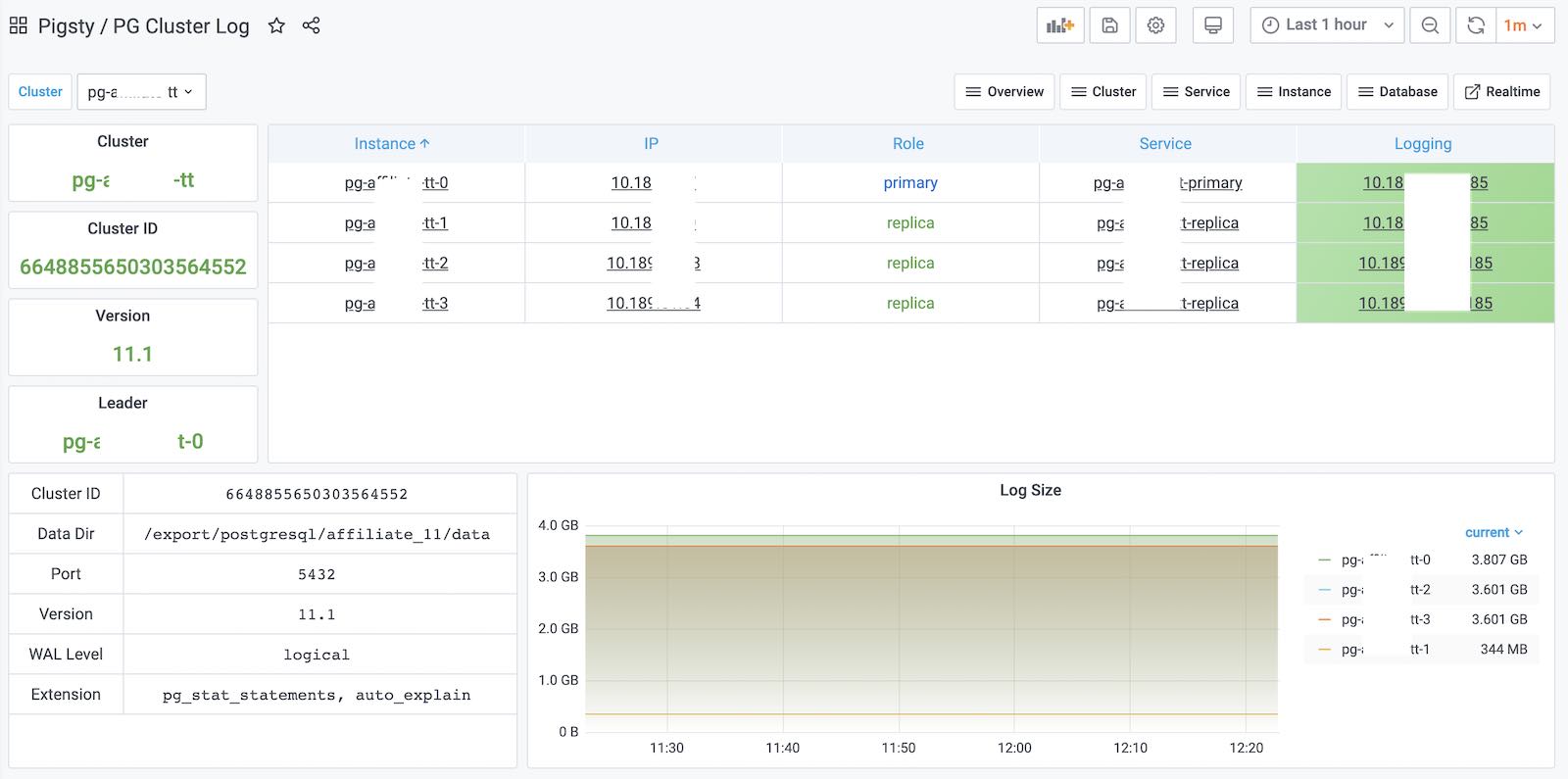
4.3.14 - PG Cluster All
PG Cluster All 包含了集群中所有的监控信息,用于细节对比与分析。
PG Cluster All 包含了集群中所有的监控信息,用于细节对比与分析。

4.4 - Service
Service level dashboards
服务级监控
一个典型的数据库集群提供两种服务
读写服务:主库
只读服务:从库
而服务往往与域名、解析、负载均衡,路由,流量分发紧密相关
服务级监控主要关注以下内容
-
主从流量分发与权重
-
后端服务器健康检测
-
负载均衡器统计信息
4.4.1 - PG Service
PG Service关注数据库角色层次的聚合信息,DNS解析,域名,代理流量权重等。
PG Service关注数据库角色层次的聚合信息,DNS解析,域名,代理流量权重等。
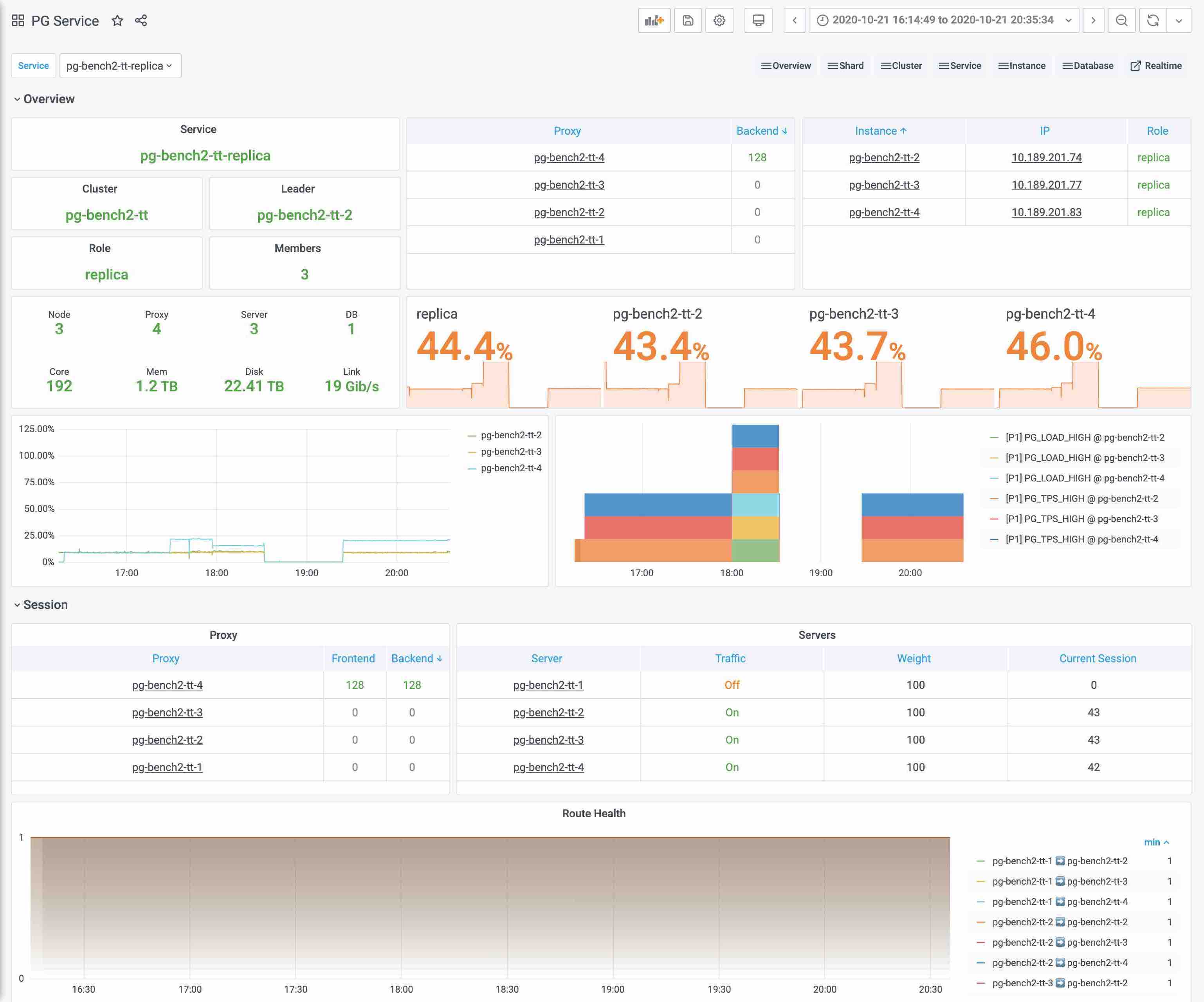
4.4.2 - PG DNS
PG DNS 关注服务域名的解析情况
PG DNS 关注服务域名的解析情况。以及与之绑定的VIP
但是鉴于各个用户定义与管理服务的方式不一,Pigsty不在公开发行版本提供更多关于服务级别的监控面板
4.5 - Instance
Instance level monitoring dashboards
实例级监控
实例级监控关注于单个实例,无论是一台机器,一个数据库实例,一个连接池实例,还是负载均衡器,指标导出器,都可以在实例级监控中找到最详细的信息。
4.5.1 - PG Instance
PG Instance 详细展示了单个数据库实例的完整指标信息
PG Instance 详细展示了单个数据库实例的完整指标信息

DB监控:PG实例
实例概览
- 实例身份信息:集群名,ID,所属节点,软件版本,所属集群其他成员等
- 实例配置信息:一些关键配置,目录,端口,配置路径等
- 实例健康信息,实例角色(Primary,Standby)等。
- 黄金指标:PG Load,复制延迟,活跃后端,排队连接,查询延迟,TPS,数据库年龄
- 数据库负载:实时(Load0),1分钟,5分钟,15分钟
- 数据库警报与提醒事件
节点概览
- 四大基本资源:CPU,内存,磁盘,网卡的配置规格,关键功能,与核心指标
- 右侧是网卡详情与磁盘详情
单日统计
以最近1日为周期的统计信息(从当前时刻算起的前24小时),比如最近一天的查询总数,返回的记录总数等。上面两行是节点级别的统计,下面两行是主要是PG相关的统计指标。
对于计量计费,水位评估特别有用。
复制
- 当前节点的Replication配置
- 复制延迟:以秒计,以字节计的复制延迟,复制槽堆积量
- 下游节点对应的Walsender统计
- 各种LSN进度,综合展示集群的复制状况与持久化状态。
- 下游节点数量统计,可以看出复制中断的问题
事务
事务部分用于洞悉实例中的活动情况,包括TPS,响应时间,锁等。
-
TPS概览信息:TPS,TPS与过去两天的DoD环比。DB事务数与回滚数
-
回滚事务数量与回滚率
-
TPS详情:绿色条带为±1σ,黄色条带为±3σ,以过去30分钟作为计算标准,通常超出黄色条带可认为TPS波动过大
-
Xact RT,事务平均响应时间,从连接池抓取。绿色条带为±1σ,黄色条带为±3σ。
-
TPS与RT的偏离程度,是一个无量纲的可横向比较的值,越大表示指标抖动越厉害。$(μ/σ)^2$
-
按照DB细分的TPS与事务响应时间,通常一个实例只有一个DB,但少量实例有多个DB。
-
事务数,回滚数(TPS来自连接池,而这两个指标直接来自DB本身)
-
锁的数量,按模式聚合(8种表锁),按大类聚合(读锁,写锁,排他锁)
查询
大多数指标与事务中的指标类似,不过统计单位从事务变成了查询语句。查询部分可用于分析实例上的慢查询,定位性能瓶颈。
- QPS 每秒查询数,与Query RT查询平均响应时间,以及这两者的波动程度,QPS的周期环比等
- 生产环境对查询平均响应时间有要求:1ms为黄线,100ms为红线
语句
语句展示了查询中按语句细分的指标。每条语句(查询语法树抽离常量变量后如果一致,则算同一条查询)都会有一个查询ID,可以在慢查询平台中获取到具体的语句与详细指标与统计。
- 左侧慢查询列表是按
pg_stat_statments中的平均响应时间从大到小排序的,点击查询ID会自动跳转到慢查询平台
- 这里列出的查询,是累计查询耗时最长的32个查询,但排除只有零星调用的长耗时单次查询与监控查询。
- 右侧包括了每个查询的实时QPS,平均响应时间。按照RT与总耗时的排名。
后端进程
后端进程用于显示与PG本身的连接,后端进程相关的统计指标。特别是按照各种维度进行聚合的结果,特别适合定位雪崩,慢查询,其他疑难杂症。
- 后端进程数按种类聚合,后端进程按状态聚合,后端进程按DB聚合,后端进程按等待事件类型聚合。
- 活跃状态的进程/连接,在事务中空闲的连接,长事务。
连接池
连接池部分与后端进程部分类似,但全都是从Pgbouncer中间件上获取的监控指标
- 连接池后端连接的状态:活跃,刚用过,空闲,测试过,登录状态。
- 分别按照User,按照DB,按照Pool(User:DB)聚合的前端连接,用于排查异常连接问题。
- 等待客户端数(重要),以及队首客户端等待的时长,用于定位连接堆积问题。
- 连接池可用连接使用比例。
数据库概览
Database部分主要来自pg_stat_database与pg_database,包含数据库相关的指标:
- WAL Rate,标识数据库的写入负载,每秒产生的WAL字节数量。
- Buffer Hit Rate,数据库 ShareBuffer 命中率,未命中的页面将从操作系统PageCache和磁盘获取。
- 每秒增删改查的记录条数
- 临时文件数量与临时文件大小,可以定位大型查询问题。
持久化
持久化主要包含数据落盘,Checkpoint,块访问相关的指标
- 重要的持久化参数,比如是否出现数据校验和验证失败(如果启用可以检测到数据腐坏)
- 数据库文件(DB,WAL,Log)的大小与增速。
- 检查点的数量与检查点耗时。
- 每秒分配的块,与每秒刷盘的块。每秒访问的块,以及每秒从磁盘中读取的块。(以字节计,注意一个Buffer Page是8192,一个Disk Block是4096)
监控Exporter
Exporter展示了监控系统组件本身的监控指标,包括:
- Exporter是否存活,Uptime,Exporter每分钟被抓取的次数
- 每个监控查询的耗时,产生的指标数量与错误数量。
4.5.2 - Node
Detailed metrics for single machine node
Node详细展示了单个机器节点的指标,该面板可用于任何安装有Node Exporter的节点
4.5.3 - PG Pgbouncer
PG Instance 详细展示了单个数据库实例的完整指标信息
PG Pgbouncer 详细展示了单个数据库连接池实例的完整指标信息
4.5.4 - PG Proxy
PG Proxy 详细展示了单个数据库代理 Haproxy 的状态信息
PG Proxy 详细展示了单个数据库代理 Haproxy 的状态信息
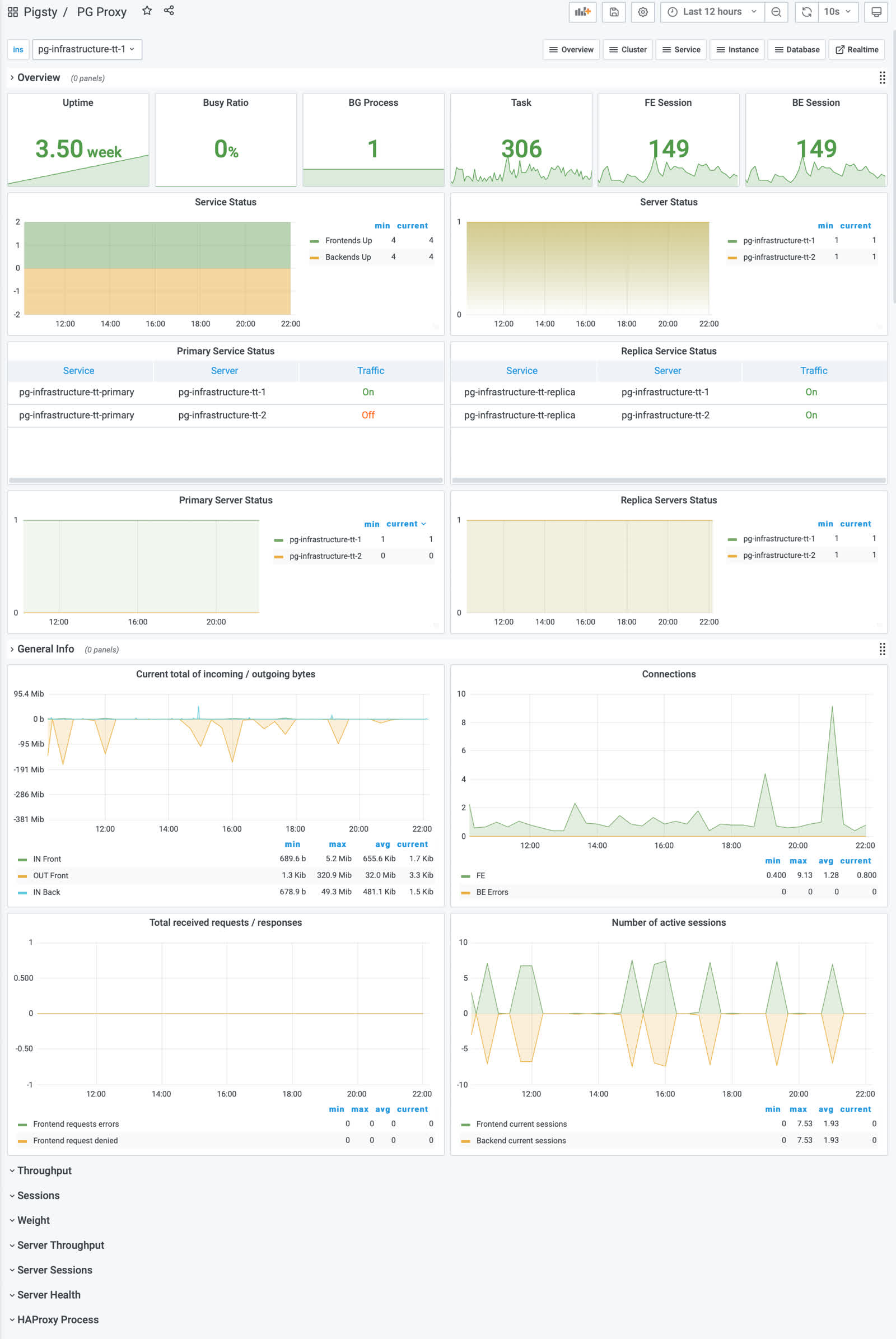
4.5.5 - PG Exporter
PG Exporter 详细展示了单个数据库实例的监控指标导出器本身的健康状态
PG Exporter 详细展示了单个数据库实例的监控指标导出器本身的健康状态
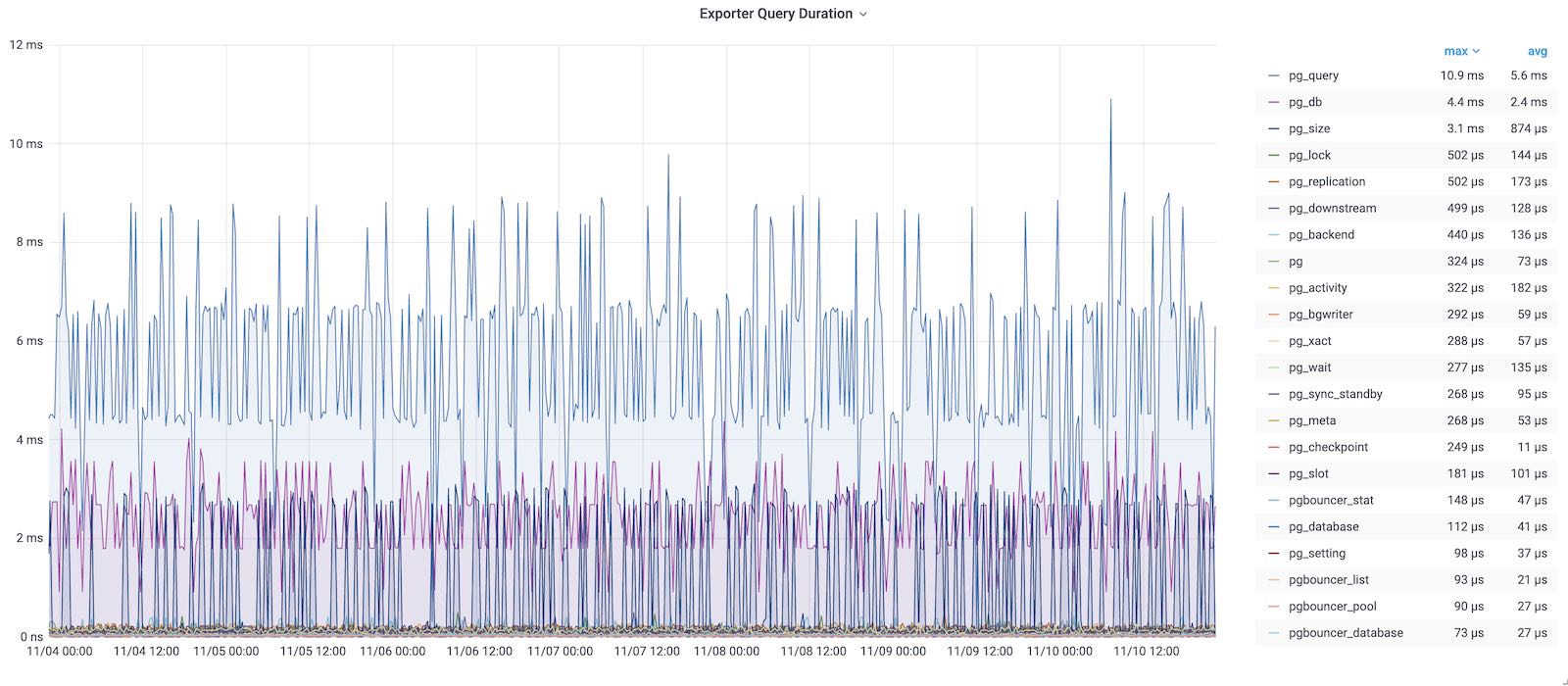
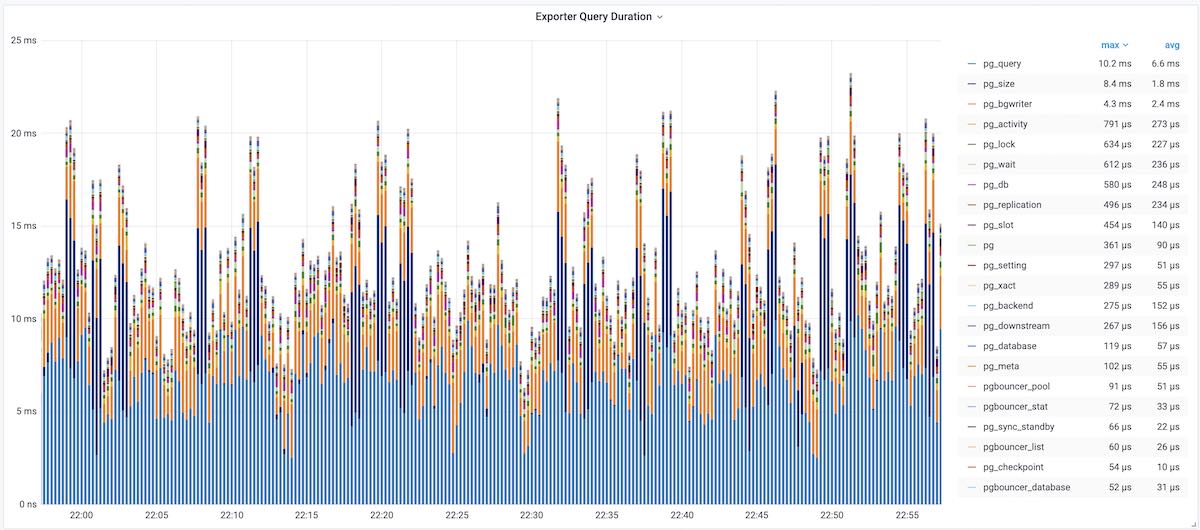
4.5.6 - PG Setting
PG Setting 详细展示了单个数据库实例的配置信息
PG Setting 详细展示了单个数据库实例的完整指标信息
4.5.7 - PG Stat Activity
PG Stat Activity 详细展示了单个数据库实例内的实时活动
PG Stat Activity 详细展示了单个数据库实例内的实时活动,注意这里的数据是从Catalog中实时获取,而非监控系统采集。

4.5.8 - PG Stat Statements
PG Stat Statements 详细展示了单个数据库实例内实时的查询状态统计
PG Stat Statements 详细展示了单个数据库实例内实时的查询状态统计

4.6 - Database
Database level monitoring dashboards
数据库级监控
数据库级监控更像是“业务级”监控,它会展现出系统中每一张表,每一个索引,每一个函数的详细使用情况。
对于业务优化与故障分析而言有着巨大的作用。
但是当心监控信息也可能透露出关键的业务数据,例如对用户表的更新QPS可能反映出业务的日活数。请在生产环境中对Grafana做好权限控制,避免不必要的风险。

4.6.1 - PG Database
PG Database 关注单个数据库内发生的细节
PG Database 关注单个数据库内发生的详细情况,对于单实例多DB的情况尤其实用。

4.6.2 - PG Pool
PG Pool关注连接池中的单个User-DB对
PG Pool关注连接池中的单个User-DB对,当您使用多租户特性时,这个面板对于连接池问题的排查会很有帮助。
4.6.3 - PG Query
PG Query 关注单个数据库内发生的查询细节
PG Query 关注单个数据库内发生的总体查询细节
您可以用本面板定位出实例内的具体异常查询,然后跳转到PG Query Detail面板查看具体查询的详细信息
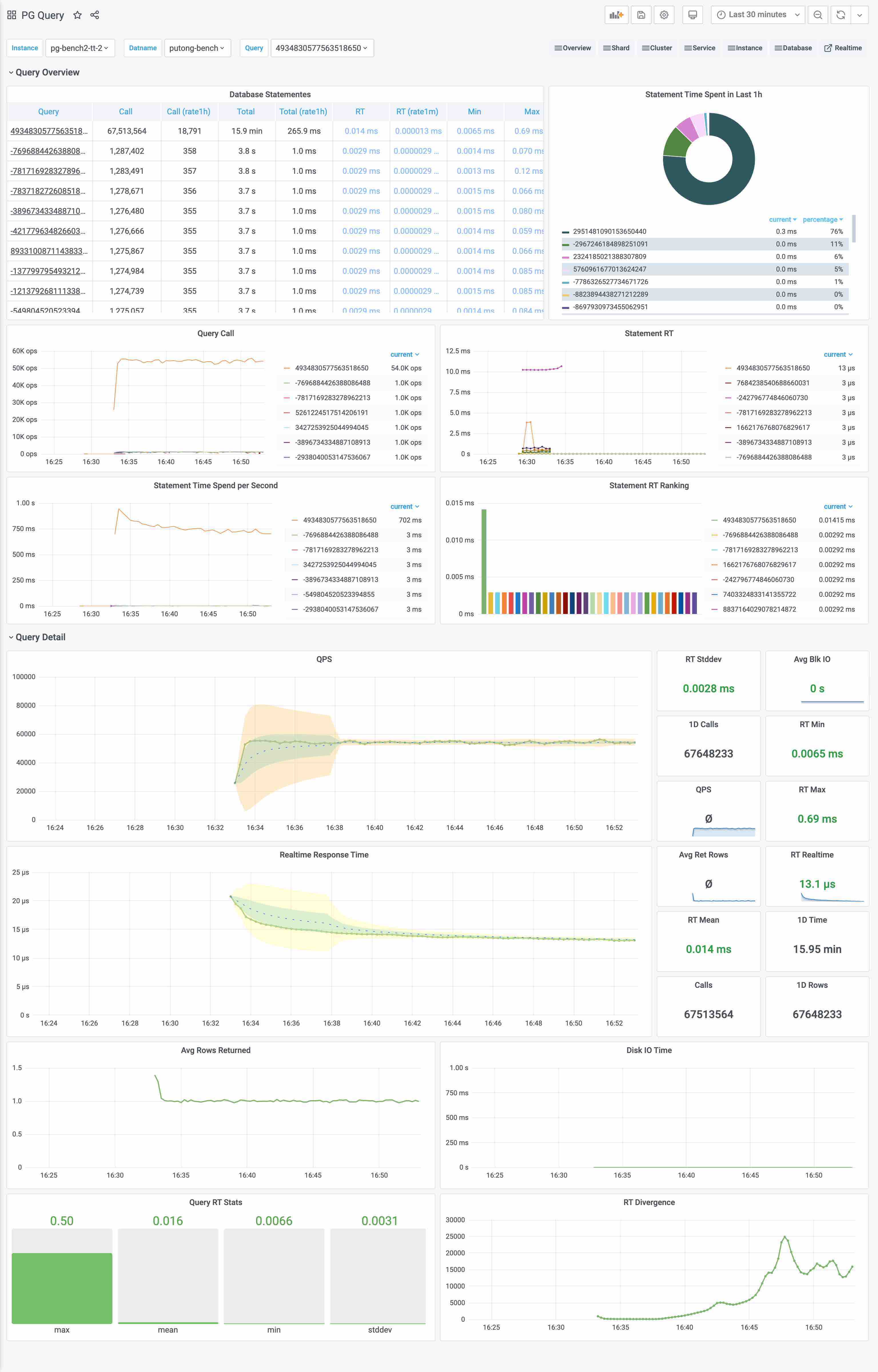
4.6.4 - PG Table Catalog
PG Catalog可以直接从数据库目录中获取并展示特定表的元数据
PG Catalog可以直接从数据库目录中获取并展示特定表的元数据
请注意,Catalog类型的信息是直接连接至数据库目录进行查询的,可能导致不必要的安全风险。
4.6.5 - PG Table
PG Table关注单个数据库中的所有表的增删改查等。
PG Table关注单个数据库中的所有表,增删改查,访问等。
您可以点击具体的表,跳转至PG Table Detail查阅这张表的详细指标。

4.6.6 - PG Table Detail
PG Table Detail关注单个数据库中的单张表
PG Table Detail关注单个数据库中的单张表
您可以在本面板中跳转至 PG Cluster Table Detail,来了解这张表在整个集群的不同实例上的工作状态。
4.6.7 - PG Query Detail
PG Query Detail关注单个数据库内发生的单个查询的细节
PG Query Detail关注单个数据库内发生的单个查询的细节。
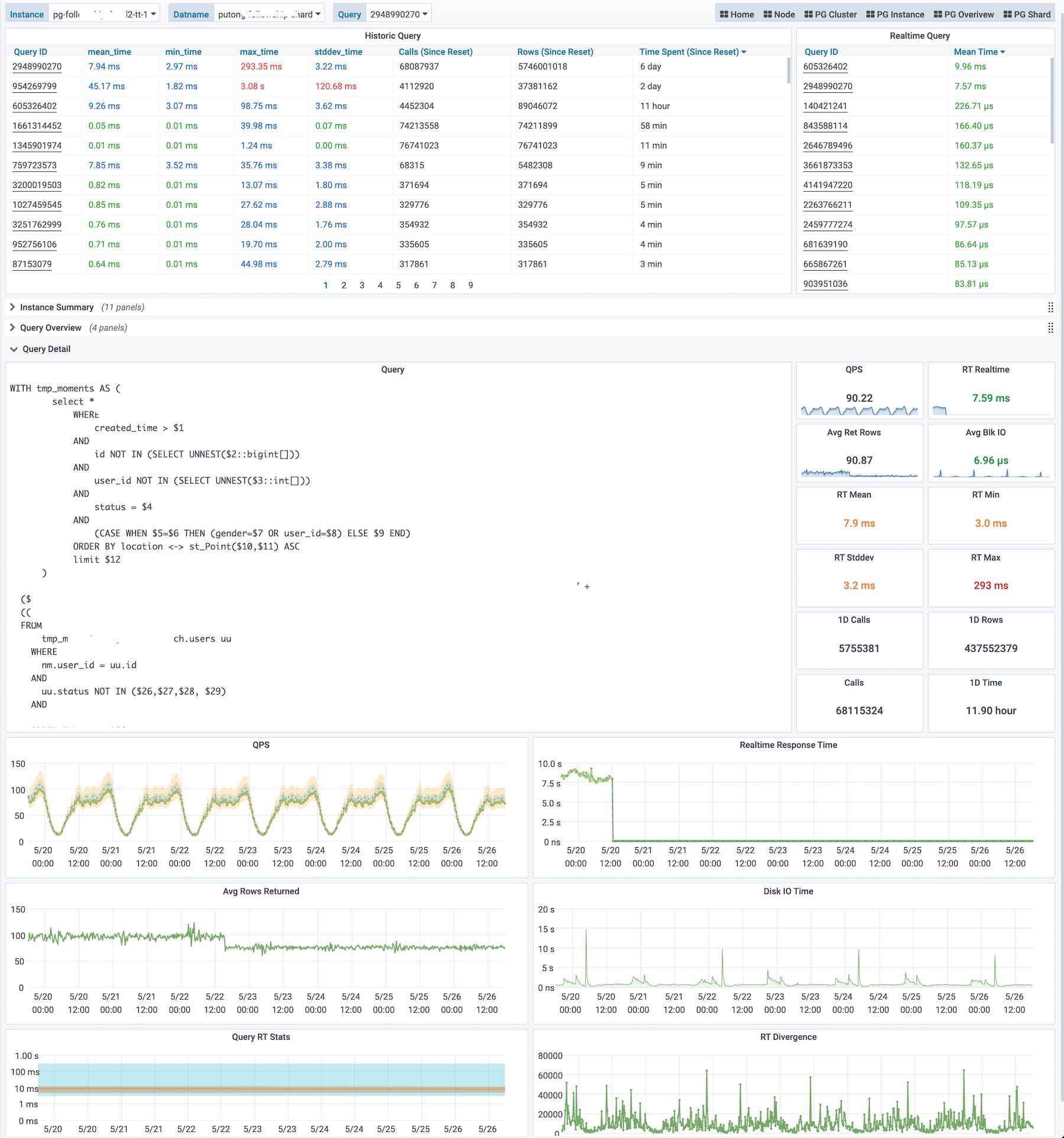
请注意,这里的查询都使用QueryID进行标识。
您可以使用PG Stat Statementes面板提供的实时查询接口获取查询对应的语句。
直接在面板中展示SQL语句可能会导致不必要的安全风险,但该特性会在Pigsty企业版中提供。
DB监控:PG慢查询平台
显示慢查询相关的指标,上方是本实例的查询总览。鼠标悬停查询ID可以看到查询语句,点击查询ID会跳转到对应的查询细分指标页(Query Detail)。
- 左侧是格式化后的查询语句,右侧是查询的主要指标,包括
- 每秒查询数量:QPS
- 实时的平均响应时间(RT Realtime)
- 每次查询平均返回的行数
- 每次查询平均用于BlockIO的时长
- 响应时间的均值,标准差,最小值,最大值(自从上一次统计周期以来)
- 查询最近一天的调用次数,返回行数,总耗时。以及自重置以来的总调用次数。
- 下方是指定时间段的查询指标图表,是概览指标的细化。
5 - Deployment
How to deploy pigsty to your production environment?
Whether it is a sandbox environment or a real production environment, Pigsty uses the same three-step deployment process: prepare resources, modify configuration, execute script
Pigsty requires some preparation before deployment: configure the node with the correct permissions configuration, download and install the relevant software. After configuration, users should [modify the configuration](… /config/) according to their needs. /config/). and execute the script to adjust the system to the state described in the configuration.
If users wish to use Pigsty to monitor an existing database cluster or wish to deploy only the Pigsty monitoring system part, please refer to monitoring deployment only .
- [node provisioning](prepare/#node provisioning)
- [meta-node provisioning](prepare/#meta-node provisioning)
- [software provisioning](prepare/#software provisioning)
- [identity information](config/#identity information)
- [Customize database cluster](config/#Customize database cluster)
- [Custom Business Users](config/#Custom Business Users)
- [Custom Business Database](config/#Custom Business Database)
Execution script
- [infrastructure initialization](playbook/#infrastructure initialization)
- [Database Cluster Initialization](playbook/#Database Cluster Initialization)
- [Database Cluster Scaling](playbook/#Database Cluster Scaling)
- [Managing business users and databases](playbook/#Managing business users and databases)
- [Managed Services](playbook/#Managed Services)
- [**Monitor-Only Deployment **](playbook/#Monitoring Deployment Only)
5.1 - Prepare
How to prepare resource for pigsty deployment?
Node provisioning
Before deploying Pigsty, users need to prepare machine node resources, including at least one meta node, with any number of database nodes.
[database nodes](… /… /concept/arch/#database nodes) can use any SSH reachable nodes: physical machines, virtual machines, containers, etc., but currently Pigsty only supports CentOS 7 operating system.
Pigsty recommends using physical and virtual machines for deployment. When using a local sandbox environment, Pigsty is based on Vagrant and Virtualbox to quickly pull up local VM resources, please refer to Vagrant tutorial for more details.
Pigsty requires [meta-node](. /… /concept/arch/# meta-node) as the control center for the entire environment and to provide [infrastructure](. /… /concept/arch/#infrastructure) services. The number of meta-nodes requires a minimum of 1, recommends 3, and suggests no more than 5. If deploying DCS to a meta-node, it is recommended that 3 meta-nodes be used in a production environment to fully ensure the availability of DCS services.
Users should ensure that they can login to the metanode and can [passwordless SSH login](users/#configure SSH passwordless access) other nodes from the metanode and [passwordless](users#configure passwordless SUDO) execute the sudo command.
Users should ensure that they have direct or indirect access to port 80 of the meta node to access the user interface provided by Pigsty.
Software Placement
The user should [download this project](software/# download pigsty source code) and [offline package](software/# download offline package) on the metanode (optional).
When pulling up Pigsty using the local sandbox, the user will also need to additionally install on the host.
5.1.1 - Vagrant
How to install, config, use vagrant
Often, in order to test a system such as a “database cluster”, users need to prepare several virtual machines in advance. Although cloud services are already very convenient, local virtual machine access is usually easier, more responsive and less expensive than cloud virtual machine access. Local VM configuration is relatively cumbersome, and Vagrant can solve this problem.
Pigsty users don’t need to understand how vagrant works, they just need to know that vagrant can simply and quickly pull up several virtual machines on a laptop, PC or Mac according to the user’s needs. All the user needs to accomplish is to express their virtual machine requirements in the form of a vagrant configuration file.
Vagrant Installation
Visit official website
https://www.vagrantup.com/downloads

Download Vagrant
最新版本为2.2.14

Vagrant Install
点击 vagrant.pkg 执行安装,安装过程需要输入密码。https://www.virtualbox.org/
Vagrantfile
�https://github.com/Vonng/pigsty/blob/master/vagrant/Vagrantfile 提供了一个Vagrantfile样例。
这是Pigsty沙箱所使用的Vagrantfile,定义了四台虚拟机,包括一台2核/4GB的中控机/元节点,和3台 1核/1GB 的数据库节点。
vagrant 二进制程序根据 Vagrantfile 中的定义,默认调用 Virtualbox 完成本地虚拟机的创建工作。
进入Pigsty根目录下的vagrant目录,执行vagrant up,即可拉起所有的四台虚拟机。
IMAGE_NAME = "centos/7"
N=3 # 数据库机器节点数量,可修改为0
Vagrant.configure("2") do |config|
config.vm.box = IMAGE_NAME
config.vm.box_check_update = false
config.ssh.insert_key = false
# 元节点
config.vm.define "meta", primary: true do |meta| # 元节点默认的ssh别名为`meta`
meta.vm.hostname = "meta"
meta.vm.network "private_network", ip: "10.10.10.10"
meta.vm.provider "virtualbox" do |v|
v.linked_clone = true
v.customize [
"modifyvm", :id,
"--memory", 4096, "--cpus", "2", # 元节点的内存与CPU核数:默认为2核/4GB
"--nictype1", "virtio", "--nictype2", "virtio",
"--hwv·irtex", "on", "--ioapic", "on", "--rtcuseutc", "on", "--vtxvpid", "on", "--largepages", "on"
]
end
meta.vm.provision "shell", path: "provision.sh"
end
# 初始化N个数据库节点
(1..N).each do |i|
config.vm.define "node-#{i}" do |node| # 数据库节点默认的ssh别名分别为`node-{1,2,3}`
node.vm.box = IMAGE_NAME
node.vm.network "private_network", ip: "10.10.10.#{i + 10}"
node.vm.hostname = "node-#{i}"
node.vm.provider "virtualbox" do |v|
v.linked_clone = true
v.customize [
"modifyvm", :id,
"--memory", 2048, "--cpus", "1", # 数据库节点的内存与CPU核数:默认为1核/2GB
"--nictype1", "virtio", "--nictype2", "virtio",
"--hwvirtex", "on", "--ioapic", "on", "--rtcuseutc", "on", "--vtxvpid", "on", "--largepages", "on"
]
end
node.vm.provision "shell", path: "provision.sh"
end
end
end
定制Vagrantfile
如果用户的机器配置不足,则可以考虑使用更小的N值,减少数据库节点的数量。如果只希望运行单个元节点,将其修改为0即可。
用户还可以修改每台机器的CPU核数和内存资源等,如配置文件中的注释所述,详情参阅Vagrant与Pigsty文档。
沙箱环境默认使用IMAGE_NAME = "centos/7",首次执行时会从vagrant官方下载centos 7.8 virtualbox 镜像,确保宿主机拥有合适的网络访问权限(科学上网)!
快捷方式
Pigsty已经提供了对常用vagrant命令的包装,用户可以在项目的Makefile中看到虚拟机管理的相关命令:
make # 启动集群
make new # 销毁并创建新集群
make dns # 将Pigsty域名记录写入本机/etc/hosts (需要sudo权限)
make ssh # 将虚拟机SSH配置信息写入 ~/.ssh/config
make clean # 销毁现有本地集群
make cache # 制作离线安装包,并拷贝至宿主机本地,加速后续集群创建
make upload # 将离线安装缓存包 pkg.tgz 上传并解压至默认目录 /www/pigsty
更多信息,请参考Makefile
###############################################################
# vm management
###############################################################
clean:
cd vagrant && vagrant destroy -f --parallel; exit 0
up:
cd vagrant && vagrant up
halt:
cd vagrant && vagrant halt
down: halt
status:
cd vagrant && vagrant status
suspend:
cd vagrant && vagrant suspend
resume:
cd vagrant && vagrant resume
provision:
cd vagrant && vagrant provision
# sync ntp time
sync:
echo meta node-1 node-2 node-3 | xargs -n1 -P4 -I{} ssh {} 'sudo ntpdate pool.ntp.org'; true
# echo meta node-1 node-2 node-3 | xargs -n1 -P4 -I{} ssh {} 'sudo chronyc -a makestep'; true
# show vagrant cluster status
st: status
start: up ssh sync
stop: halt
# only init partial of cluster
meta-up:
cd vagrant && vagrant up meta
node-up:
cd vagrant && vagrant up node-1 node-2 node-3
node-new:
cd vagrant && vagrant destroy -f node-1 node-2 node-3
cd vagrant && vagrant up node-1 node-2 node-3
5.1.2 - Virtualbox
How to install Virtualbox
It’s quite simple installing virtualbox on MacOS. And similar on other operating systems.
前往Virtualbox官网
https://www.virtualbox.org/

下载Virtualbox
最新版本为6.1.18

安装Virtualbox
点击 VirtualBox.pkg 执行安装,安装过程需要输入密码并重启。
如果安装失败,请检查您的 系统偏好设置 - 安全性与隐私 - 通用 - 允许以下位置的App中点击“允许”按钮。
就这?
没错,您已经成功安装完Oracle Virtualbox了!
5.1.3 - Ansible
How to install vagrant
Ansible is a popular and simple automated IT tool that is widely used for operations management and software deployment.
Ansible is the execution vehicle for Pigsty scripts, so if you don’t need to customize this project, users don’t need to know much about Ansible details, just think of it as an advanced Shell or Python interpreter.
How to install
Ansible can be installed via the package manager
brew install ansible # macos
yum install ansible # linux
Check installed version
$ echo $(ansible --version)
ansible 2.10.3
Ansible 2.9+ is recommended.
How to use
Pigsty项目根目录下提供了一系列Ansible剧本,在其开头的Hashbang中调用ansible-playbook来执行自己。
#!/usr/bin/env ansible-playbook
因此,您通常不需要关心Ansible如何使用,安装完成后,直接使用下面的方式执行Ansible剧本即可。
离线安装Ansible
Pigsty依赖Ansible进行环境初始化。但如果元节点本身没有安装Ansible,也没有互联网访问怎么办?
离线安装包中本身带有 Ansible,可以直接通过本地文件Yum源的方式使用,假设用户已经将离线安装包解压至默认位置:/www/pigsty。
那么将以下Repo文件写入/etc/yum.repos.d/pigsty-local.repo 中,就可以直接使用该源。
[pigsty-local]
name=Local Yum Repo pigsty
baseurl=file:///www/pigsty
skip_if_unavailable = 1
enabled = 1
priority = 1
gpgcheck = 0
执行以下命令,在元节点上离线安装Ansible :
yum clean all
yum makecache
yum install ansible
5.1.4 - Admin User
How to config ssh nopass and nopass sudo?
Pigsty requires an administrative user that can SSH password-free to other nodes from the meta-node and execute the sudo command password-free.
Admin user
Pigsty recommends that the creation of the administrative user, privilege configuration and key distribution be done during the Provisioning phase of the VM as part of the delivered content.
The default user for sandbox environments, vagrant, is already configured with password-free login and password-free sudo by default, and you can use vagrant to login to all database nodes from the host or sandbox meta-node. For production environments, i.e. when the machine is delivered, there should already be such a user configured with unencrypted remote SSH login and unencrypted sudo.
If not, the user will need to create it himself. If the user has root privileges, they can also perform the initialization directly with root identity, and Pigsty can complete the creation of the administrative user during the initialization process. The relevant configuration parameters include.
Whether to create an admin user on each node (password-free sudo with ssh), which will be created by default.
Pigsty by default creates an admin user named admin (uid=88) that can SSH-free access to other nodes in the environment from the meta-node and perform password-free sudo.
The uid of the administrator user, default is 88
Name of the admin user, default is admin
Does the SSH key for the admin user get exchanged between the machines currently executing the command?
The exchange is performed by default, so that the administrator can quickly jump between machines.
Key written to admin ~/.ssh/authorized_keys
Users with the corresponding private keys can log in as administrators.
By default, Pigsty will create the administrator user admin with uid=88 and exchange that user’s key cluster-wide.
node_admin_pks given in the public key will be installed to the authorized_keys of the admin account, and the user with the corresponding private key can directly log in remotely without encryption.
On the meta node, assume the username of the user executing the command is vagrant.
Generate the key
Execute the following command as user vagrant to generate a public-private key pair for vagrant to use for login.
- Default public key:
~/.ssh/id_rsa.pub
- Default private key:
~/.ssh/id_rsa
Install the key
Add the public key to the corresponding user on the machine you need to log in to: /home/vagrant/.ssh/authorized_keys
If you already have direct password access to the remote machine, you can copy the public key directly via ssh-copy-id.
# Enter the password to complete the public key copy
ssh-copy-id <ip>
# Embed the password directly into the command to avoid interactive password entry
sshpass -p <password> ssh-copy-id <ip>
Then you can log in to the remote machine via password-free SSH for that user.
Assuming the username is vagrant, add the following entry via the visudo command, or by creating the /etc/sudoers.d/vagrant file.
%vagrant ALL=(ALL) NOPASSWD: ALL
Then the vagrant user can execute all commands without sudo
5.1.5 - Prepare Software
How to prepare software resource for pigsty deployment
Users need to download the Pigsty project to the meta-node (in a sandbox environment, you can also use the host to initiate control)
Download Pigsty source code
Users can clone the project directly from Github using git, or download the latest version of the Pigsty source package from the Github Release page at.
git clone https://github.com/Vonng/pigsty
git clone git@github.com:Vonng/pigsty.git
You can also download the latest version of Pigsty from the Pigsty CDN: pigsty.tar.gz
http://pigsty-1304147732.cos.accelerate.myqcloud.com/latest/pigsty.tar.gz
Download the offline installer
Pigsty comes with a sandbox environment, and the offline installer for the sandbox environment is placed in the files directory by default, which can be downloaded from [Github Release](https://github. com/Vonng/pigsty/releases) page.
cd <pigsty>/files/
wget https://github.com/Vonng/pigsty/releases/download/v0.6.0/pkg.tgz
Pigsty’s official CDN also provides the latest version of pkg.tgz for download, just execute the following command.
make downlaod
curl http://pigsty-1304147732.cos.accelerate.myqcloud.com/pkg.tgz -o files/pkg.tgz
For details on how to use the offline installation package, please refer to the [offline installation](. /offline/) section.
Monitor-only mode resources
If you want to use a monitoring-only deployment, it is usually recommended to deploy the monitoring agent using a copy of the monitoring component binary, so you need to download and place the Linux Binary in the files directory beforehand.
files
^---- pg_exporter (linux amd64 binary)
^---- node_exporter (linux amd64 binary)
The self-contained script files/download-exporter.sh will automatically download the latest versions of node_exporter and pg_exporter from the Internet.
5.1.6 - Offline Installation
How to perform offline installation
Pigsty is a complex software system. To ensure the stability of the system, Pigsty downloads all dependent packages from the Internet during the initialization process and creates local repository (local Yum source).
The total size of all dependent software is about 1GB, and the download speed depends on the user’s network. Although Pigsty has tried to use mirror sources as much as possible to speed up the download, the download of a small number of packages may still be blocked by firewalls and may appear very slow. The user can download the packages via proxy_env configuration entry to set up a download proxy to complete the first download.
If you are using a different operating system than CentOS 7.8, it is usually recommended that users use the full online download and installation process. and cache the downloaded software after the first initialization is complete, see [Making an offline installer](#Making an offline installer).
If you wish to skip the long download process, or if the execution control meta-node does not have Internet access, consider downloading a pre-packaged offline installer.
Contents of the offline installer package
To quickly pull up Pigsty, it is recommended to use the offline download package and upload method to complete the installation.
The offline installer includes all packages from the local Yum repository. By default, Pigsty is installed at [infrastructure initialization](. /../playbook/infra/) when the local Yum repository is created.
{{ repo_home }}
|---- {{ repo_name }}.repo
^---- {{ repo_name}}/repo_complete
^---- {{ repo_name}}/**************.rpm
By default, {{ repo_home }} is the root directory of the Nginx static file server, which defaults to /www, and repo_name is a custom local source name, which defaults to pigsty.
By default, the /www/pigsty directory contains all RPM packages, and the offline installer is actually a zip archive of the /www/pigsty directory.
The principle of the offline installation package is that Pigsty checks if the local Yum source-related files already exist during the execution of the infrastructure initialization. If they already exist, the process of downloading the package and its dependencies is skipped.
The token file used for the check is {{ repo_home }}/{{ repo_name }}/repo_complete, by default /www/pigsty/repo_complete, if this token file exists, (usually set by Pigsty after the local source is created), then the local source has been created and can be used directly. Otherwise, Pigsty will perform the usual download logic. Once the download is complete, you can archive a compressed copy of the directory for accelerating the initialization of other environments.
沙箱环境
下载离线安装包
Pigsty自带了一个沙箱环境,沙箱环境的离线安装包默认放置于files目录中,可以从Github Release页面下载。
cd <pigsty>/files/
wget https://github.com/Vonng/pigsty/releases/download/v0.6.0/pkg.tgz
Pigsty的官方CDN也提供最新版本的pkg.tgz下载,只需要执行以下命令即可。
make downlaod
curl http://pigsty-1304147732.cos.accelerate.myqcloud.com/pkg.tgz -o files/pkg.tgz
上传离线安装包
使用Pigsty沙箱时,下载离线安装至本地files目录后,则可以直接使用 Makefile 提供的快捷指令make upload上传离线安装包至元节点上。
使用 make upload,也会将本地的离线安装包(Yum缓存)拷贝至元节点上。
# upload rpm cache to meta controller
upload:
ssh -t meta "sudo rm -rf /tmp/pkg.tgz"
scp -r files/pkg.tgz meta:/tmp/pkg.tgz
ssh -t meta "sudo mkdir -p /www/pigsty/; sudo rm -rf /www/pigsty/*; sudo tar -xf /tmp/pkg.tgz --strip-component=1 -C /www/pigsty/"
制作离线安装包
使用 Pigsty 沙箱时,可以通过 make cache 将沙箱中元节点的缓存制为离线安装包,并拷贝到本地。
# cache rpm packages from meta controller
cache:
rm -rf pkg/* && mkdir -p pkg;
ssh -t meta "sudo tar -zcf /tmp/pkg.tgz -C /www pigsty; sudo chmod a+r /tmp/pkg.tgz"
scp -r meta:/tmp/pkg.tgz files/pkg.tgz
ssh -t meta "sudo rm -rf /tmp/pkg.tgz"
在生产环境离线安装包
在生产环境使用离线安装包前,您必须确保生产环境的操作系统与制作该离线安装包的机器操作系统一致。Pigsty提供的离线安装包默认使用CentOS 7.8。
使用不同操作系统版本的离线安装包可能会出错,也可能不会,我们强烈建议不要这么做。
如果需要在其他版本的操作系统(例如CentOS7.3,7.7等)上运行Pigsty,建议用户在安装有同版本操作系统的沙箱中完整执行一遍初始化流程,不使用离线安装包,而是直接从上游源下载的方式进行初始化。对于没有网络访问的生产环境元节点而言,制作离线软件包是至关重要的。
常规初始化完成后,用户可以通过make cache或手工执行相关命令,将特定操作系统的软件缓存打为离线安装包。供生产环境使用。
从初始化完成的本地元节点构建离线安装包:
tar -zcf /tmp/pkg.tgz -C /www pigsty # 制作离线软件包
在生产环境使用离线安装包与沙箱环境类似,用户需要将pkg.tgz复制到元节点上,然后将离线安装包解压至目标地址。
这里以默认的 /www/pigsty 为例,将压缩包中的所有内容(RPM包,repo_complete标记文件,repodata 源的元数据库等)解压至目标目录/www/pigsty中,可以使用以下命令。
mkdir -p /www/pigsty/
sudo rm -rf /www/pigsty/*
sudo tar -xf /tmp/pkg.tgz --strip-component=1 -C /www/pigsty/
5.2 - Configure
How to configure pigsty according to your needs
Users can use the following configuration items to configure the infrastructure and database cluster.
In general, most parameters can be used directly with default values.
The infrastructure section requires very little modification, and the only modification usually involved is a textual substitution of the IP address of the meta-node.
In contrast, users need to focus on the definition and configuration of database clusters. The database cluster will be deployed on database nodes and the user must provide the [identity information](identity/#identity parameter) of the database cluster with the [connection information](identity/#connection information) of the database nodes. The identity information (e.g., cluster name, instance number) is used to describe the entities in the database cluster, while the connection information (e.g., IP address) is used to access the database node. Also, the user should define the default business user and business database together with the cluster creation.
In addition, users can also customize the default access control model, template database, external exposed services by modifying the parameters. /../concept/provision/service/# service definition).
Database customization
In Pigsty, database initialization is divided into five parts.
1. [Install database software](. /../config/6-pg-install/)
What version to install, which plugins to install, what user to use
Usually the parameters in this section can be used directly without modifying anything (adjustments need to be made when the PG version is upgraded).
2. [provisioning database cluster] (../../config/7-pg-provision/)
Where to create the directory, what purpose to create the cluster, which IP ports to listen on, what connection pooling mode to use
In this section, identity information is a mandatory parameter, other than that there are very few default parameters to change.
The default parameters are rarely changed other than by pg_conf you can use the default database cluster templates (Normal Transactional OLTP / Normal Analytical OLAP / Core Financial CRIT / Micro Virtual Machine TINY). If you wish to create custom templates, you can clone the default configuration in roles/postgres/templates and adopt it with your own modifications, see [Patroni template customization](. /../reference/patroni).
Which roles, users, databases, schemas to create, which extensions to enable, how to set permissions and whitelist
Needs to be focused, as this is where the business declares its desired database. Users can customize through database templates at.
- business user: (which users to use to access the database?) Attributes, restrictions, roles, permissions ……)
- business database: (What kind of database is needed? Extensions, schema, parameters, permissions ……)
- Default template database (template1) (schema, extensions, default permissions)
- access control system (roles, users, HBA)
- exposed services (which ports to use, which instances to direct traffic to, health checks, weights ……)
4. [pull up database monitoring](. /../config/9-monitor)
Deploy Pigsty monitoring system components
Normally no adjustment is needed, but in monitor deployment only mode it needs to be focused on. /monly) mode needs to be focused on and tuned.
5. [Expose database services](. /../config/10-services)
Expose database services externally via HAproxy/VIP
The configuration here does not need to be adjusted unless the user wishes to define additional services.
Configuration item reference
Most parameters are provided with reasonable default values, please refer to [configuration items](. /../config) manual to modify as needed.
| No | English | major class | function |
| :–: | :—————————————–: | :———: | ——————— —————– |
| 1 | connect | Infrastructure | Proxy server configuration, connection information for managed objects |
| 2 | repo | Infrastructure | Customize local Yum sources, install packages offline |
| 3 | node | Infrastructure | Configuring infrastructure on a normal node |
| 4 | meta | meta | Infrastructure |
| 5 | dcs | Infrastructure | Configure DCS services (consul/etcd) on all nodes |
| 6 | [pg-install](. /../config/6-pg-install) | Database-clustering | Installing PostgreSQL database |
| 7 | pg-provision | database-clustering | pulling up a PostgreSQL database cluster |
| 8 | [pg-template](. /../config/8-pg-template) | Database-template | Customize PostgreSQL database content |
| 9 | monitor | monitor | Database-Affiliate |
| 10 | service | service | Database-affiliated |
5.2.1 - Assign Identity
How to configure and assign identity to pgsql clusters and instances
Pigsty基于 身份标识(Identity) 管理数据库对象。
身份参数
身份参数是定义数据库集群时必须提供的信息,包括:
身份参数的内容遵循 Pigsty命名原则 。其中 pg_cluster ,pg_role,pg_seq 属于核心身份参数,是定义数据库集群所需的最小必须参数集。核心身份参数必须显式指定,手工分配。
pg_cluster 标识了集群的名称,在集群层面进行配置,作为集群资源的顶层命名空间。pg_role在实例层面进行配置,标识了实例在集群中扮演的角色。可选值包括:
primary:集群中的唯一主库,集群领导者,提供写入服务。replica:集群中的普通从库,承接常规生产只读流量。offline:集群中的离线从库,承接ETL/SAGA/个人用户/交互式/分析型查询。standby:集群中的同步从库,采用同步复制,没有复制延迟。delayed:集群中的延迟从库,显式指定复制延迟,用于执行回溯查询与数据抢救。
pg_seq 用于在集群内标识实例,通常采用从0或1开始递增的整数,一旦分配不再更改。pg_shard 用于标识集群所属的上层 分片集簇,只有当集群是水平分片集簇的一员时需要设置。pg_sindex 用于标识集群的分片集簇编号,只有当集群是水平分片集簇的一员时需要设置。
定义数据库集群
以下配置文件定义了一个名为pg-test的集群。集群中包含三个实例:pg-test-1, pg-test-2,pg-test-3,分别为主库,从库,离线库。该配置是一个集群定义所需的最小配置。
pg-test:
vars: { pg_cluster: pg-test }
hosts:
10.10.10.11: {pg_seq: 1, pg_role: primary}
10.10.10.12: {pg_seq: 2, pg_role: replica}
10.10.10.13: {pg_seq: 3, pg_role: offline}
pg_cluster,pg_role,pg_seq 属于 身份参数
除了IP地址外,这三个参数是定义一套新的数据库集群的最小必须参数集,如下面的配置所示。
其他参数都可以继承自全局配置或默认配置,但身份参数必须显式指定,手工分配。
pg_cluster 标识了集群的名称,在集群层面进行配置。pg_role 在实例层面进行配置,标识了实例的角色,只有primary角色会进行特殊处理,如果不填,默认为replica角色,此外,还有特殊的delayed与offline角色。pg_seq 用于在集群内标识实例,通常采用从0或1开始递增的整数,一旦分配不再更改。{{ pg_cluster }}-{{ pg_seq }} 被用于唯一标识实例,即pg_instance{{ pg_cluster }}-{{ pg_role }} 用于标识集群内的服务,即pg_service
定义水平分片数据库集簇
pg_shard 与 pg_sindex 用于定义特殊的分片数据库集簇,是可选的身份参数。
假设用户有一个水平分片的 分片数据库集簇(Shard) ,名称为test。这个集簇由四个独立的集群组成:pg-test1, pg-test2,pg-test3,pg-test-4。则用户可以将 pg_shard: test 的身份绑定至每一个数据库集群,将pg_sindex: 1|2|3|4 分别绑定至每一个数据库集群上。如下所示:
pg-test1:
vars: {pg_cluster: pg-test1, pg_shard: test, pg_sindex: 1}
hosts: {10.10.10.10: {pg_seq: 1, pg_role: primary}}
pg-test2:
vars: {pg_cluster: pg-test1, pg_shard: test, pg_sindex: 2}
hosts: {10.10.10.11: {pg_seq: 1, pg_role: primary}}
pg-test3:
vars: {pg_cluster: pg-test1, pg_shard: test, pg_sindex: 3}
hosts: {10.10.10.12: {pg_seq: 1, pg_role: primary}}
pg-test4:
vars: {pg_cluster: pg-test1, pg_shard: test, pg_sindex: 4}
hosts: {10.10.10.13: {pg_seq: 1, pg_role: primary}}
数据库节点与数据库实例
数据库集群需要部署在数据库节点上,Pigsty使用数据库节点与数据库实例一一对应的部署模式。
数据库节点使用IP地址作为标识符,数据库实例使用形如pg-test-1的标识符。 数据库节点(Node) 与 数据库实例(Instance) 的标识符可以相互对应,相互转换。
连接信息
如果说身份参数是数据库集群的标识,那么连接信息就是数据库节点的标识。
例如在 定义数据库集群 的例子中,数据库集群pg_cluster = pg-test 中 pg_seq = 1 的数据库实例(pg-test-1)部署在IP地址为10.10.10.11 的数据库节点上。这里的IP地址10.10.10.11就是连接信息。
Pigsty使用IP地址作为数据库节点的唯一标识,该IP地址必须是数据库实例监听并对外提供服务的IP地址。
这一点非常重要,即使您是通过跳板机或SSH代理访问该数据库节点,也应当在配置时保证这一点。
其他连接方式
如果您的目标机器藏在SSH跳板机之后,或者无法通过ssh ip的方式直接方案,则可以考虑使用Ansible提供的连接参数。
例如下面的例子中,ansible_host 通过SSH别名的方式告知Pigsty通过ssh node-1 的方式而不是ssh 10.10.10.11的方式访问目标数据库节点。
pg-test:
vars: { pg_cluster: pg-test }
hosts:
10.10.10.11: {pg_seq: 1, pg_role: primary, ansible_host: node-1}
10.10.10.12: {pg_seq: 2, pg_role: replica, ansible_host: node-2}
10.10.10.13: {pg_seq: 3, pg_role: offline, ansible_host: node-3}
通过这种方式,用户可以自由指定数据库节点的连接方式,并将连接配置保存在管理用户的~/.ssh/config中。
接下来
完成身份参数配置后,用户可以对数据库集群进行进一步定制。
5.2.2 - Customize business users
Cusomize business users and roles in pigsty
可以通过 pg_users 定制集群特定的业务用户。该配置项通常用于在数据库集群层面定义业务用户,与 pg_default_roles 采用相同的形式。
样例
一个完整的用户定义由一个JSON/YAML对象构成,如下所示:
# complete example of user/role definition for production user
- name: dbuser_meta # example production user have read-write access
password: DBUser.Meta # example user's password, can be encrypted
login: true # can login, true by default (should be false for role)
superuser: false # is superuser? false by default
createdb: false # can create database? false by default
createrole: false # can create role? false by default
inherit: true # can this role use inherited privileges?
replication: false # can this role do replication? false by default
bypassrls: false # can this role bypass row level security? false by default
connlimit: -1 # connection limit, -1 disable limit
expire_at: '2030-12-31' # 'timestamp' when this role is expired
expire_in: 365 # now + n days when this role is expired (OVERWRITE expire_at)
roles: [dbrole_readwrite] # dborole_admin|dbrole_readwrite|dbrole_readonly
pgbouncer: true # add this user to pgbouncer? false by default (true for production user)
parameters: # user's default search path
search_path: public
comment: test user
说明
一个用户对象由以下键值构成,只有用户名是必选项,其他参数均为可选,不添加相应键则会使用默认值。
-
name(string) : 用户名称,必选项
-
password(string) : 用户的密码,可以是以md5, sha开头的密文密码。
-
login(bool) :用户是否可以登录,默认为真;如果这里是业务角色,应当将其设置为假。
-
superuser(bool) : 用户是否具有超级用户权限,默认为假
-
createdb(bool) : 用户是否具有创建数据库的权限,默认没有
-
createrole(bool) : 用户是否具有创建新角色的权限,默认没有。
-
inherit(bool) : 用户是否继承其角色的权限?默认继承
-
replication(bool) : 用户是否具有复制权限?默认没有
-
bypassrls(bool) : 用户是否可以绕过行级安全策略?默认不行
-
connlimit(number) : 是否限制用户的连接数量?留空或-1不限,默认不限
-
expire_at(date) : 用户过期时间,默认不过期
-
expire_in(number) : 自创建n天后用户将过期,如果设置将覆盖expire_at
-
roles(string[]) : 用户所属的角色/用户组
-
pgbouncer(bool) : 是否将用户加入连接池用户列表中?默认不加入,通过连接池访问的生产用户应当显式设置此项为真,交互式个人用户/ETL用户应当设置未假或留空。
-
parameters(dict) : 针对用户修改配置参数,k-v结构
-
comment(string) : 用户备注说明信息
Pigsty建议采用dbuser_ 与 dbrole_ 的前缀区分用户与角色,用户的login选项应当设置为true以允许登录,角色的login选项应当设置为false以拒绝登录。
pg_users 与 pg_default_roles 都是 user 对象构成的数组,两者会依照定义顺序依次创建,因此后创建的用户可以属于先前创建的角色。
实现
pg_default_roles 中的用户会渲染为集群主库上的单个SQL文件:
/pg/tmp/pg-init-roles.sql
pg_users 中的用户会渲染为集群主库上的SQL文件,每个用户一个:
/pg/tmp/pg-db-{{ database.name }}.sql
并依次执行。一个实际渲染的例子如下所示:
----------------------------------------------------------------------
-- File : pg-user-dbuser_meta.sql
-- Path : /pg/tmp/pg-user-dbuser_meta.sql
-- Time : 2021-03-22 22:52
-- Note : managed by ansible, DO NOT CHANGE
-- Desc : creation sql script for user dbuser_meta
----------------------------------------------------------------------
--==================================================================--
-- EXECUTION --
--==================================================================--
-- run as dbsu (postgres by default)
-- createuser -w -p 5432 'dbuser_meta';
-- psql -p 5432 -AXtwqf /pg/tmp/pg-user-dbuser_meta.sql
--==================================================================--
-- CREATE USER --
--==================================================================--
CREATE USER "dbuser_meta" ;
--==================================================================--
-- ALTER USER --
--==================================================================--
-- options
ALTER USER "dbuser_meta" ;
-- password
ALTER USER "dbuser_meta" PASSWORD 'DBUser.Meta';
-- expire
-- expire at 2022-03-22 in 365 days since 2021-03-22
ALTER USER "dbuser_meta" VALID UNTIL '2022-03-22';
-- conn limit
-- remove conn limit
-- ALTER USER "dbuser_meta" CONNECTION LIMIT -1;
-- parameters
ALTER USER "dbuser_meta" SET search_path = public;
-- comment
COMMENT ON ROLE "dbuser_meta" IS 'test user';
--==================================================================--
-- GRANT ROLE --
--==================================================================--
GRANT "dbrole_readwrite" TO "dbuser_meta";
--==================================================================--
-- PGBOUNCER USER --
--==================================================================--
-- user will not be added to pgbouncer user list by default,
-- unless pgbouncer is explicitly set to 'true', which means production user
-- User 'dbuser_meta' will be added to /etc/pgbouncer/userlist.txt via
-- /pg/bin/pgbouncer-create-user 'dbuser_meta' 'DBUser.Meta'
--==================================================================--
连接池
Pgbouncer有自己的用户定义文件,通常是PG用户的一个子集。
在Pigsty中,Pgbouncer的用户定义文件位于:/etc/pgbouncer/userlist.txt
$ cat userlist.txt
"postgres" ""
"dbuser_monitor" "md57bbcca538453edba8be026725c530b05"
只有在该文件中出现的用户,才可以通过PGbouncer访问数据库。
只有pgbouncer选项显式配置为true的用户,会被添加至连接池用户列表中。
修改该配置文件需要reload Pgbouncer方可生效。
导出
以下SQL查询可以使用JSON格式导出数据库中的用户(但需要少量修正)
SELECT row_to_json(u) FROM
(SELECT r.rolname AS name,
a.rolpassword AS password,
r.rolcanlogin AS login,
r.rolsuper AS superuser,
r.rolcreatedb AS createdb,
r.rolcreaterole AS createrole,
r.rolinherit AS inherit,
r.rolreplication AS replication,
r.rolbypassrls AS bypassrls,
r.rolconnlimit AS connlimit,
r.rolvaliduntil AS expire_at,
setconfig AS parameters,
ARRAY(SELECT b.rolname FROM pg_catalog.pg_auth_members m JOIN pg_catalog.pg_roles b ON (m.roleid = b.oid) WHERE m.member = r.oid) as roles,
pg_catalog.shobj_description(r.oid, 'pg_authid') AS comment
FROM pg_catalog.pg_roles r
LEFT JOIN pg_db_role_setting rs ON r.oid = rs.setrole
LEFT JOIN pg_authid a ON r.oid = a.oid
WHERE r.rolname !~ '^pg_'
ORDER BY 1) u;
创建
请尽可能通过声明的方式创建业务用户与业务数据库,而不是在数据库中手工创建。因为业务用户与业务数据库需要同时在数据库与连接池中进行变更。详情请参考:创建业务用户
在运行中的数据库集群中创建新的业务用户,首先应在集群级配置中添加新用户的定义,例如在pg-test.vars.pg_users加入新的用户对象。然后可以使用pgsql-createuser剧本创建用户:
例如,在pg-test 集群中创建或修改名为dbuser_test的用户,可以执行以下命令。
./pgsql-createuser.yml -l <pg_cluster> -e pg_user=dbuser_test
如果dbuser_test的定义不存在,则会在检查阶段报错。
5.2.3 - Customize database
Configure business database
可以通过 pg_databases 定制集群特定的业务数据库。
样例
一个完整的数据库定义由一个JSON/YAML对象构成,如下所示:
- name: meta # name is the only required field for a database
owner: postgres # optional, database owner
template: template1 # optional, template1 by default
encoding: UTF8 # optional, UTF8 by default , must same as template database, leave blank to set to db default
locale: C # optional, C by default , must same as template database, leave blank to set to db default
lc_collate: C # optional, C by default , must same as template database, leave blank to set to db default
lc_ctype: C # optional, C by default , must same as template database, leave blank to set to db default
allowconn: true # optional, true by default, false disable connect at all
revokeconn: false # optional, false by default, true revoke connect from public # (only default user and owner have connect privilege on database)
tablespace: pg_default # optional, 'pg_default' is the default tablespace
connlimit: -1 # optional, connection limit, -1 or none disable limit (default)
schemas: [public,monitor] # create additional schema
extensions: # optional, extension name and where to create
- {name: postgis, schema: public}
parameters: # optional, extra parameters with ALTER DATABASE
enable_partitionwise_join: true
pgbouncer: true # optional, add this database to pgbouncer list? true by default
comment: pigsty meta database # optional, comment string for database
说明
一个数据库对象由以下键值构成,只有数据库名是必选项,其他参数均为可选,不添加相应键则会使用默认值。
-
name(string) : 数据库名称,必选项
-
owner(string) :数据库的属主,必须为已存在的用户(用户先于数据库创建)。
-
template(string):创建数据库时所使用的模板,默认为template1。
-
encoding(enum):数据库使用的字符集编码,默认为UTF8,必须与实例和模板数据库保持一致。
-
locale(enum):数据库使用的本地化规则,默认与实例和模板数据库保持一致,建议不要修改。
-
lc_collate(enum):数据库使用的本地化字符串排序规则,默认为与实例和模板数据库保持一致,建议不要修改。
-
lc_ctype(enum):数据库使用的本地化规则,默认与实例和模板数据库保持一致,建议不要修改。
-
allowconn(bool):是否允许连接至数据库,默认允许。
-
revokeconn(bool):是否回收PUBLIC默认连接至数据库的权限?默认不回收,建议在多DB实例上开启。
-
tablespace(string):数据库的默认表空间,默认为pg_default。
-
connlimit(number) : 是否限制数据库的连接数量?留空或-1不限,默认不限
-
schemas(string[]):需要在该数据库中额外创建的模式(默认会创建monitor模式)
-
extensions(extension[]):数据库中额外安装的扩展,每个扩展包括name与schema两个字段。
例如{name: postgis, schema: public} 指示Pigsty在该数据库的public模式下安装PostGIS扩展
-
pgbouncer(bool) : 是否将数据库加入连接池DB列表中?默认加入
-
parameters(dict) : 针对数据库额外修改配置参数,k-v结构
-
comment(string) : 数据库备注说明信息
实现
pg_databases 是数据库定义对象构成的数组,会依次渲染为主库上的SQL文件:
/pg/tmp/pg-db-{{ database.name }}.sql
并依次执行。一个实际渲染的例子如下所示:
----------------------------------------------------------------------
-- File : pg-db-meta.sql
-- Path : /pg/tmp/pg-db-meta.sql
-- Time : 2021-03-22 22:52
-- Note : managed by ansible, DO NOT CHANGE
-- Desc : creation sql script for database meta
----------------------------------------------------------------------
--==================================================================--
-- EXECUTION --
--==================================================================--
-- run as dbsu (postgres by default)
-- createdb -w -p 5432 'meta';
-- psql meta -p 5432 -AXtwqf /pg/tmp/pg-db-meta.sql
--==================================================================--
-- CREATE DATABASE --
--==================================================================--
-- create database with following commands
-- CREATE DATABASE "meta" ;
-- following commands are executed within database "meta"
--==================================================================--
-- ALTER DATABASE --
--==================================================================--
-- owner
-- tablespace
-- allow connection
ALTER DATABASE "meta" ALLOW_CONNECTIONS True;
-- connection limit
ALTER DATABASE "meta" CONNECTION LIMIT -1;
-- parameters
ALTER DATABASE "meta" SET enable_partitionwise_join = True;
-- comment
COMMENT ON DATABASE "meta" IS 'pigsty meta database';
--==================================================================--
-- REVOKE/GRANT CONNECT --
--==================================================================--
--==================================================================--
-- REVOKE/GRANT CREATE --
--==================================================================--
-- revoke create (schema) privilege from public
REVOKE CREATE ON DATABASE "meta" FROM PUBLIC;
-- only admin role have create privilege
GRANT CREATE ON DATABASE "meta" TO "dbrole_admin";
-- revoke public schema creation
REVOKE CREATE ON SCHEMA public FROM PUBLIC;
-- admin can create objects in public schema
GRANT CREATE ON SCHEMA public TO "dbrole_admin";
--==================================================================--
-- CREATE SCHEMAS --
--==================================================================--
-- create schemas
--==================================================================--
-- CREATE EXTENSIONS --
--==================================================================--
-- create extensions
CREATE EXTENSION IF NOT EXISTS "postgis" WITH SCHEMA "public";
--==================================================================--
-- PGBOUNCER DATABASE --
--==================================================================--
-- database will be added to pgbouncer database list by default,
-- unless pgbouncer is explicitly set to 'false', means hidden database
-- Database 'meta' will be added to /etc/pgbouncer/database.txt via
-- /pg/bin/pgbouncer-create-db 'meta'
--==================================================================--
连接池
Pgbouncer有自己的数据库定义文件,通常是PG数据库的一个子集。
在Pigsty中,Pgbouncer的数据库定义文件位于:/etc/pgbouncer/database.txt
$ cat database.txt
meta = host=/var/run/postgresql
只有在该文件中出现的数据库,才可以通过PGbouncer访问。pgbouncer选项显式配置为false的数据库不会被添加至连接池DB列表中。修改该配置文件需要reload Pgbouncer方可生效。
导出
以下SQL查询可以以JSON格式导出当前数据库的定义(需少量修正)
psql -AXtw <<-EOF
SELECT jsonb_pretty(row_to_json(final)::JSONB)
FROM (SELECT datname AS name,
datdba::RegRole::Text AS owner,
encoding,
datcollate AS lc_collate,
datctype AS lc_ctype,
datallowconn AS allowconn,
datconnlimit AS connlimit,
(SELECT json_agg(nspname) AS schemas FROM pg_namespace WHERE nspname !~ '^pg_' AND nspname NOT IN ('information_schema', 'monitor', 'repack')),
(SELECT json_agg(row_to_json(ex)) AS extensions FROM (SELECT extname, extnamespace::RegNamespace AS schema FROM pg_extension WHERE extnamespace::RegNamespace::TEXT NOT IN ('information_schema', 'monitor', 'repack', 'pg_catalog')) ex),
(SELECT json_object_agg(substring(cfg, 0 , strpos(cfg, '=')), substring(cfg, strpos(cfg, '=')+1)) AS value FROM
(SELECT unnest(setconfig) AS cfg FROM pg_db_role_setting s JOIN pg_database d ON d.oid = s.setdatabase WHERE d.datname = current_database()) cf
)
FROM pg_database WHERE datname = current_database()
) final;
EOF
创建
请尽可能通过声明的方式创建业务数据库,而不是在数据库中手工创建。因为业务用户与业务数据库需要同时在数据库与连接池中进行变更。
在运行中的数据库集群中创建新的业务数据库,首先应当在集群级配置中添加新数据库的定义,例如在pg-test.vars.pg_databases加入新的数据库对象。然后可以使用pgsql-createdb剧本创建数据库:
例如,在pg-test 集群中创建或修改名为test的数据库,可以执行以下命令。
./pgsql-createdb.yml -l <pg_cluster> -e pg_database=test
如果数据库test的定义不存在,则会在检查阶段报错。
5.2.4 - Customize Template
Customize template and other content in database clusters
相关参数
用户可以使用 PG模板 配置项,对集群中的模板数据库 template1 进行定制。
通过这种方式确保任何在该数据库集群中新创建的数据库都带有相同的默认配置:模式,扩展,默认权限。
^---/pg/bin/pg-init
|
^---(1)--- /pg/tmp/pg-init-roles.sql
^---(2)--- /pg/tmp/pg-init-template.sql
^---(3)--- <other customize logic in pg-init>
# 业务用户与数据库并不是在模版定制中创建的
^-------------(4)--- /pg/tmp/pg-user-{{ user.name }}.sql
^-------------(5)--- /pg/tmp/pg-db-{{ db.name }}.sql
pg-init是用于自定义初始化模板的Shell脚本路径,该脚本将以postgres用户身份,仅在主库上执行,执行时数据库集群主库已经被拉起,可以执行任意Shell命令,或通过psql执行任意SQL命令。
如果不指定该配置项,Pigsty会使用默认的pg-init Shell脚本,如下所示。
#!/usr/bin/env bash
set -uo pipefail
#==================================================================#
# Default Roles #
#==================================================================#
psql postgres -qAXwtf /pg/tmp/pg-init-roles.sql
#==================================================================#
# System Template #
#==================================================================#
# system default template
psql template1 -qAXwtf /pg/tmp/pg-init-template.sql
# make postgres same as templated database (optional)
psql postgres -qAXwtf /pg/tmp/pg-init-template.sql
#==================================================================#
# Customize Logic #
#==================================================================#
# add your template logic here
如果用户需要执行复杂的定制逻辑,可在该脚本的基础上进行追加。注意pg-init 用于定制数据库集群,通常这是通过修改 模板数据库 实现的。在该脚本执行时,数据库集群已经启动,但业务用户与业务数据库尚未创建。因此模板数据库的修改会反映在默认定义的业务数据库中。
pg-init-roles.sql
在 pg_default_roles 中可以自定义全局统一的角色体系。其中的定义会被渲染为/pg/tmp/pg-init-roles.sql,pg-test集群中的渲染样例如下所示:
```sql
----------------------------------------------------------------------
-- File : pg-init-roles.sql
-- Path : /pg/tmp/pg-init-roles
-- Time : 2021-03-16 21:24
-- Note : managed by ansible, DO NOT CHANGE
-- Desc : creation sql script for default roles
----------------------------------------------------------------------
–###################################################################–
– dbrole_readonly –
–###################################################################–
– run as dbsu (postgres by default)
– createuser -w -p 5432 –no-login’dbrole_readonly';
– psql -p 5432 -AXtwqf /pg/tmp/pg-user-dbrole_readonly.sql
–==================================================================–
– CREATE USER –
–==================================================================–
CREATE USER “dbrole_readonly” NOLOGIN;
–==================================================================–
– ALTER USER –
–==================================================================–
– options
ALTER USER “dbrole_readonly” NOLOGIN;
– password
– expire
– conn limit
– parameters
– comment
COMMENT ON ROLE “dbrole_readonly” IS ‘role for global readonly access’;
–==================================================================–
– GRANT ROLE –
–==================================================================–
–==================================================================–
– PGBOUNCER USER –
–==================================================================–
– user will not be added to pgbouncer user list by default,
– unless pgbouncer is explicitly set to ‘true’, which means production user
– User ‘dbrole_readonly’ will NOT be added to /etc/pgbouncer/userlist.txt
–==================================================================–
–###################################################################–
– dbrole_readwrite –
–###################################################################–
– run as dbsu (postgres by default)
– createuser -w -p 5432 –no-login’dbrole_readwrite';
– psql -p 5432 -AXtwqf /pg/tmp/pg-user-dbrole_readwrite.sql
–==================================================================–
– CREATE USER –
–==================================================================–
CREATE USER “dbrole_readwrite” NOLOGIN;
–==================================================================–
– ALTER USER –
–==================================================================–
– options
ALTER USER “dbrole_readwrite” NOLOGIN;
– password
– expire
– conn limit
– parameters
– comment
COMMENT ON ROLE “dbrole_readwrite” IS ‘role for global read-write access’;
–==================================================================–
– GRANT ROLE –
–==================================================================–
GRANT “dbrole_readonly” TO “dbrole_readwrite”;
–==================================================================–
– PGBOUNCER USER –
–==================================================================–
– user will not be added to pgbouncer user list by default,
– unless pgbouncer is explicitly set to ‘true’, which means production user
– User ‘dbrole_readwrite’ will NOT be added to /etc/pgbouncer/userlist.txt
–==================================================================–
–###################################################################–
– dbrole_offline –
–###################################################################–
– run as dbsu (postgres by default)
– createuser -w -p 5432 –no-login’dbrole_offline';
– psql -p 5432 -AXtwqf /pg/tmp/pg-user-dbrole_offline.sql
–==================================================================–
– CREATE USER –
–==================================================================–
CREATE USER “dbrole_offline” NOLOGIN;
–==================================================================–
– ALTER USER –
–==================================================================–
– options
ALTER USER “dbrole_offline” NOLOGIN;
– password
– expire
– conn limit
– parameters
– comment
COMMENT ON ROLE “dbrole_offline” IS ‘role for restricted read-only access (offline instance)';
–==================================================================–
– GRANT ROLE –
–==================================================================–
–==================================================================–
– PGBOUNCER USER –
–==================================================================–
– user will not be added to pgbouncer user list by default,
– unless pgbouncer is explicitly set to ‘true’, which means production user
– User ‘dbrole_offline’ will NOT be added to /etc/pgbouncer/userlist.txt
–==================================================================–
–###################################################################–
– dbrole_admin –
–###################################################################–
– run as dbsu (postgres by default)
– createuser -w -p 5432 –no-login’dbrole_admin’;
– psql -p 5432 -AXtwqf /pg/tmp/pg-user-dbrole_admin.sql
–==================================================================–
– CREATE USER –
–==================================================================–
CREATE USER “dbrole_admin” NOLOGIN BYPASSRLS;
–==================================================================–
– ALTER USER –
–==================================================================–
– options
ALTER USER “dbrole_admin” NOLOGIN BYPASSRLS;
– password
– expire
– conn limit
– parameters
– comment
COMMENT ON ROLE “dbrole_admin” IS ‘role for object creation’;
–==================================================================–
– GRANT ROLE –
–==================================================================–
GRANT “dbrole_readwrite” TO “dbrole_admin”;
GRANT “pg_monitor” TO “dbrole_admin”;
GRANT “pg_signal_backend” TO “dbrole_admin”;
–==================================================================–
– PGBOUNCER USER –
–==================================================================–
– user will not be added to pgbouncer user list by default,
– unless pgbouncer is explicitly set to ‘true’, which means production user
– User ‘dbrole_admin’ will NOT be added to /etc/pgbouncer/userlist.txt
–==================================================================–
–###################################################################–
– postgres –
–###################################################################–
– run as dbsu (postgres by default)
– createuser -w -p 5432 –superuser’postgres';
– psql -p 5432 -AXtwqf /pg/tmp/pg-user-postgres.sql
–==================================================================–
– CREATE USER –
–==================================================================–
CREATE USER “postgres” SUPERUSER;
–==================================================================–
– ALTER USER –
–==================================================================–
– options
ALTER USER “postgres” SUPERUSER;
– password
– expire
– conn limit
– parameters
– comment
COMMENT ON ROLE “postgres” IS ‘system superuser’;
–==================================================================–
– GRANT ROLE –
–==================================================================–
–==================================================================–
– PGBOUNCER USER –
–==================================================================–
– user will not be added to pgbouncer user list by default,
– unless pgbouncer is explicitly set to ‘true’, which means production user
– User ‘postgres’ will NOT be added to /etc/pgbouncer/userlist.txt
–==================================================================–
–###################################################################–
– replicator –
–###################################################################–
– run as dbsu (postgres by default)
– createuser -w -p 5432 –replication’replicator';
– psql -p 5432 -AXtwqf /pg/tmp/pg-user-replicator.sql
–==================================================================–
– CREATE USER –
–==================================================================–
CREATE USER “replicator” REPLICATION BYPASSRLS;
–==================================================================–
– ALTER USER –
–==================================================================–
– options
ALTER USER “replicator” REPLICATION BYPASSRLS;
– password
– expire
– conn limit
– parameters
– comment
COMMENT ON ROLE “replicator” IS ‘system replicator’;
–==================================================================–
– GRANT ROLE –
–==================================================================–
GRANT “pg_monitor” TO “replicator”;
GRANT “dbrole_readonly” TO “replicator”;
–==================================================================–
– PGBOUNCER USER –
–==================================================================–
– user will not be added to pgbouncer user list by default,
– unless pgbouncer is explicitly set to ‘true’, which means production user
– User ‘replicator’ will NOT be added to /etc/pgbouncer/userlist.txt
–==================================================================–
–###################################################################–
– dbuser_monitor –
–###################################################################–
– run as dbsu (postgres by default)
– createuser -w -p 5432 ‘dbuser_monitor’;
– psql -p 5432 -AXtwqf /pg/tmp/pg-user-dbuser_monitor.sql
–==================================================================–
– CREATE USER –
–==================================================================–
CREATE USER “dbuser_monitor” ;
–==================================================================–
– ALTER USER –
–==================================================================–
– options
ALTER USER “dbuser_monitor” ;
– password
– expire
– conn limit
ALTER USER “dbuser_monitor” CONNECTION LIMIT 16;
– parameters
– comment
COMMENT ON ROLE “dbuser_monitor” IS ‘system monitor user’;
–==================================================================–
– GRANT ROLE –
–==================================================================–
GRANT “pg_monitor” TO “dbuser_monitor”;
GRANT “dbrole_readonly” TO “dbuser_monitor”;
–==================================================================–
– PGBOUNCER USER –
–==================================================================–
– user will not be added to pgbouncer user list by default,
– unless pgbouncer is explicitly set to ‘true’, which means production user
– User ‘dbuser_monitor’ will NOT be added to /etc/pgbouncer/userlist.txt
–==================================================================–
–###################################################################–
– dbuser_admin –
–###################################################################–
– run as dbsu (postgres by default)
– createuser -w -p 5432 –superuser’dbuser_admin';
– psql -p 5432 -AXtwqf /pg/tmp/pg-user-dbuser_admin.sql
–==================================================================–
– CREATE USER –
–==================================================================–
CREATE USER “dbuser_admin” SUPERUSER BYPASSRLS;
–==================================================================–
– ALTER USER –
–==================================================================–
– options
ALTER USER “dbuser_admin” SUPERUSER BYPASSRLS;
– password
– expire
– conn limit
– parameters
– comment
COMMENT ON ROLE “dbuser_admin” IS ‘system admin user’;
–==================================================================–
– GRANT ROLE –
–==================================================================–
GRANT “dbrole_admin” TO “dbuser_admin”;
–==================================================================–
– PGBOUNCER USER –
–==================================================================–
– user will not be added to pgbouncer user list by default,
– unless pgbouncer is explicitly set to ‘true’, which means production user
– User ‘dbuser_admin’ will NOT be added to /etc/pgbouncer/userlist.txt
–==================================================================–
–###################################################################–
– dbuser_stats –
–###################################################################–
– run as dbsu (postgres by default)
– createuser -w -p 5432 ‘dbuser_stats’;
– psql -p 5432 -AXtwqf /pg/tmp/pg-user-dbuser_stats.sql
–==================================================================–
– CREATE USER –
–==================================================================–
CREATE USER “dbuser_stats” ;
–==================================================================–
– ALTER USER –
–==================================================================–
– options
ALTER USER “dbuser_stats” ;
– password
ALTER USER “dbuser_stats” PASSWORD ‘DBUser.Stats’;
– expire
– conn limit
– parameters
– comment
COMMENT ON ROLE “dbuser_stats” IS ‘business offline user for offline queries and ETL’;
–==================================================================–
– GRANT ROLE –
–==================================================================–
GRANT “dbrole_offline” TO “dbuser_stats”;
–==================================================================–
– PGBOUNCER USER –
–==================================================================–
– user will not be added to pgbouncer user list by default,
– unless pgbouncer is explicitly set to ‘true’, which means production user
– User ‘dbuser_stats’ will NOT be added to /etc/pgbouncer/userlist.txt
–==================================================================–
–==================================================================–
– PASSWORD OVERWRITE –
–==================================================================–
ALTER ROLE “replicator” PASSWORD ‘DBUser.Replicator’;
ALTER ROLE “dbuser_monitor” PASSWORD ‘DBUser.Monitor’;
ALTER ROLE “dbuser_admin” PASSWORD ‘DBUser.Admin’;
–==================================================================–
</details>
## pg-init-template.sql
[`pg-init-template.sql`](https://github.com/Vonng/pigsty/blob/master/roles/postgres/templates/pg-init-template.sql) 是用于初始化 `template1` 数据的脚本模板。PG模板中的变量,大抵都是通过该SQL模板渲染为最终执行的SQL命令。该模板会被渲染至集群主库的`/pg/tmp/pg-init-template.sql`并执行。
Pigsty强烈建议通过提供自定义的`pg-init`脚本完成复杂的定制。如无必要,尽量不要改动`pg-init-template.sql`中的原有逻辑。
```sql
--==================================================================--
-- Executions --
--==================================================================--
-- psql template1 -AXtwqf /pg/tmp/pg-init-template.sql
-- this sql scripts is responsible for post-init procedure
-- it will
-- * create system users such as replicator, monitor user, admin user
-- * create system default roles
-- * create schema, extensions in template1 & postgres
-- * create monitor views in template1 & postgres
--==================================================================--
-- Default Privileges --
--==================================================================--
{% for priv in pg_default_privileges %}
ALTER DEFAULT PRIVILEGES FOR ROLE {{ pg_dbsu }} {{ priv }};
{% endfor %}
{% for priv in pg_default_privileges %}
ALTER DEFAULT PRIVILEGES FOR ROLE {{ pg_admin_username }} {{ priv }};
{% endfor %}
-- for additional business admin, they can SET ROLE to dbrole_admin
{% for priv in pg_default_privileges %}
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" {{ priv }};
{% endfor %}
--==================================================================--
-- Schemas --
--==================================================================--
{% for schema_name in pg_default_schemas %}
CREATE SCHEMA IF NOT EXISTS "{{ schema_name }}";
{% endfor %}
-- revoke public creation
REVOKE CREATE ON SCHEMA public FROM PUBLIC;
--==================================================================--
-- Extensions --
--==================================================================--
{% for extension in pg_default_extensions %}
CREATE EXTENSION IF NOT EXISTS "{{ extension.name }}"{% if 'schema' in extension %} WITH SCHEMA "{{ extension.schema }}"{% endif %};
{% endfor %}
默认的模板初始化逻辑还会创建监控模式,扩展与相关视图。
```sql
--==================================================================--
-- Monitor Views --
--==================================================================--
– cleanse
CREATE SCHEMA IF NOT EXISTS monitor;
GRANT USAGE ON SCHEMA monitor TO “{{ pg_monitor_username }}";
GRANT USAGE ON SCHEMA monitor TO “{{ pg_admin_username }}";
GRANT USAGE ON SCHEMA monitor TO “{{ pg_replication_username }}";
DROP VIEW IF EXISTS monitor.pg_table_bloat_human;
DROP VIEW IF EXISTS monitor.pg_index_bloat_human;
DROP VIEW IF EXISTS monitor.pg_table_bloat;
DROP VIEW IF EXISTS monitor.pg_index_bloat;
DROP VIEW IF EXISTS monitor.pg_session;
DROP VIEW IF EXISTS monitor.pg_kill;
DROP VIEW IF EXISTS monitor.pg_cancel;
DROP VIEW IF EXISTS monitor.pg_seq_scan;
– Table bloat estimate
CREATE OR REPLACE VIEW monitor.pg_table_bloat AS
SELECT CURRENT_CATALOG AS datname, nspname, relname , bs * tblpages AS size,
CASE WHEN tblpages - est_tblpages_ff > 0 THEN (tblpages - est_tblpages_ff)/tblpages::FLOAT ELSE 0 END AS ratio
FROM (
SELECT ceil( reltuples / ( (bs-page_hdr)fillfactor/(tpl_size100) ) ) + ceil( toasttuples / 4 ) AS est_tblpages_ff,
tblpages, fillfactor, bs, tblid, nspname, relname, is_na
FROM (
SELECT
( 4 + tpl_hdr_size + tpl_data_size + (2 * ma)
- CASE WHEN tpl_hdr_size % ma = 0 THEN ma ELSE tpl_hdr_size % ma END
- CASE WHEN ceil(tpl_data_size)::INT % ma = 0 THEN ma ELSE ceil(tpl_data_size)::INT % ma END
) AS tpl_size, (heappages + toastpages) AS tblpages, heappages,
toastpages, reltuples, toasttuples, bs, page_hdr, tblid, nspname, relname, fillfactor, is_na
FROM (
SELECT
tbl.oid AS tblid, ns.nspname , tbl.relname, tbl.reltuples,
tbl.relpages AS heappages, coalesce(toast.relpages, 0) AS toastpages,
coalesce(toast.reltuples, 0) AS toasttuples,
coalesce(substring(array_to_string(tbl.reloptions, ' ‘) FROM ‘fillfactor=([0-9]+)')::smallint, 100) AS fillfactor,
current_setting(‘block_size’)::numeric AS bs,
CASE WHEN version()~‘mingw32’ OR version()~‘64-bit|x86_64|ppc64|ia64|amd64’ THEN 8 ELSE 4 END AS ma,
24 AS page_hdr,
23 + CASE WHEN MAX(coalesce(s.null_frac,0)) > 0 THEN ( 7 + count(s.attname) ) / 8 ELSE 0::int END
+ CASE WHEN bool_or(att.attname = ‘oid’ and att.attnum < 0) THEN 4 ELSE 0 END AS tpl_hdr_size,
sum( (1-coalesce(s.null_frac, 0)) * coalesce(s.avg_width, 0) ) AS tpl_data_size,
bool_or(att.atttypid = ‘pg_catalog.name’::regtype)
OR sum(CASE WHEN att.attnum > 0 THEN 1 ELSE 0 END) <> count(s.attname) AS is_na
FROM pg_attribute AS att
JOIN pg_class AS tbl ON att.attrelid = tbl.oid
JOIN pg_namespace AS ns ON ns.oid = tbl.relnamespace
LEFT JOIN pg_stats AS s ON s.schemaname=ns.nspname AND s.tablename = tbl.relname AND s.inherited=false AND s.attname=att.attname
LEFT JOIN pg_class AS toast ON tbl.reltoastrelid = toast.oid
WHERE NOT att.attisdropped AND tbl.relkind = ‘r’ AND nspname NOT IN (‘pg_catalog’,‘information_schema’)
GROUP BY 1,2,3,4,5,6,7,8,9,10
) AS s
) AS s2
) AS s3
WHERE NOT is_na;
COMMENT ON VIEW monitor.pg_table_bloat IS ‘postgres table bloat estimate’;
– Index bloat estimate
CREATE OR REPLACE VIEW monitor.pg_index_bloat AS
SELECT CURRENT_CATALOG AS datname, nspname, idxname AS relname, relpages::BIGINT * bs AS size,
COALESCE((relpages - ( reltuples * (6 + ma - (CASE WHEN index_tuple_hdr % ma = 0 THEN ma ELSE index_tuple_hdr % ma END)
+ nulldatawidth + ma - (CASE WHEN nulldatawidth % ma = 0 THEN ma ELSE nulldatawidth % ma END))
/ (bs - pagehdr)::FLOAT + 1 )), 0) / relpages::FLOAT AS ratio
FROM (
SELECT nspname,
idxname,
reltuples,
relpages,
current_setting(‘block_size’)::INTEGER AS bs,
(CASE WHEN version() ~ ‘mingw32’ OR version() ~ ‘64-bit|x86_64|ppc64|ia64|amd64’ THEN 8 ELSE 4 END) AS ma,
24 AS pagehdr,
(CASE WHEN max(COALESCE(pg_stats.null_frac, 0)) = 0 THEN 2 ELSE 6 END) AS index_tuple_hdr,
sum((1.0 - COALESCE(pg_stats.null_frac, 0.0)) *
COALESCE(pg_stats.avg_width, 1024))::INTEGER AS nulldatawidth
FROM pg_attribute
JOIN (
SELECT pg_namespace.nspname,
ic.relname AS idxname,
ic.reltuples,
ic.relpages,
pg_index.indrelid,
pg_index.indexrelid,
tc.relname AS tablename,
regexp_split_to_table(pg_index.indkey::TEXT, ' ‘) :: INTEGER AS attnum,
pg_index.indexrelid AS index_oid
FROM pg_index
JOIN pg_class ic ON pg_index.indexrelid = ic.oid
JOIN pg_class tc ON pg_index.indrelid = tc.oid
JOIN pg_namespace ON pg_namespace.oid = ic.relnamespace
JOIN pg_am ON ic.relam = pg_am.oid
WHERE pg_am.amname = ‘btree’ AND ic.relpages > 0 AND nspname NOT IN (‘pg_catalog’, ‘information_schema’)
) ind_atts ON pg_attribute.attrelid = ind_atts.indexrelid AND pg_attribute.attnum = ind_atts.attnum
JOIN pg_stats ON pg_stats.schemaname = ind_atts.nspname
AND ((pg_stats.tablename = ind_atts.tablename AND pg_stats.attname = pg_get_indexdef(pg_attribute.attrelid, pg_attribute.attnum, TRUE))
OR (pg_stats.tablename = ind_atts.idxname AND pg_stats.attname = pg_attribute.attname))
WHERE pg_attribute.attnum > 0
GROUP BY 1, 2, 3, 4, 5, 6
) est
LIMIT 512;
COMMENT ON VIEW monitor.pg_index_bloat IS ‘postgres index bloat estimate (btree-only)';
– table bloat pretty
CREATE OR REPLACE VIEW monitor.pg_table_bloat_human AS
SELECT nspname || ‘.’ || relname AS name,
pg_size_pretty(size) AS size,
pg_size_pretty((size * ratio)::BIGINT) AS wasted,
round(100 * ratio::NUMERIC, 2) as ratio
FROM monitor.pg_table_bloat ORDER BY wasted DESC NULLS LAST;
COMMENT ON VIEW monitor.pg_table_bloat_human IS ‘postgres table bloat pretty’;
– index bloat pretty
CREATE OR REPLACE VIEW monitor.pg_index_bloat_human AS
SELECT nspname || ‘.’ || relname AS name,
pg_size_pretty(size) AS size,
pg_size_pretty((size * ratio)::BIGINT) AS wasted,
round(100 * ratio::NUMERIC, 2) as ratio
FROM monitor.pg_index_bloat;
COMMENT ON VIEW monitor.pg_index_bloat_human IS ‘postgres index bloat pretty’;
– pg session
CREATE OR REPLACE VIEW monitor.pg_session AS
SELECT coalesce(datname, ‘all’) AS datname,
numbackends,
active,
idle,
ixact,
max_duration,
max_tx_duration,
max_conn_duration
FROM (
SELECT datname,
count() AS numbackends,
count() FILTER ( WHERE state = ‘active’ ) AS active,
count() FILTER ( WHERE state = ‘idle’ ) AS idle,
count() FILTER ( WHERE state = ‘idle in transaction’
OR state = ‘idle in transaction (aborted)’ ) AS ixact,
max(extract(epoch from now() - state_change))
FILTER ( WHERE state = ‘active’ ) AS max_duration,
max(extract(epoch from now() - xact_start)) AS max_tx_duration,
max(extract(epoch from now() - backend_start)) AS max_conn_duration
FROM pg_stat_activity
WHERE backend_type = ‘client backend’
AND pid <> pg_backend_pid()
GROUP BY ROLLUP (1)
ORDER BY 1 NULLS FIRST
) t;
COMMENT ON VIEW monitor.pg_session IS ‘postgres session stats’;
– pg kill
CREATE OR REPLACE VIEW monitor.pg_kill AS
SELECT pid,
pg_terminate_backend(pid) AS killed,
datname AS dat,
usename AS usr,
application_name AS app,
client_addr AS addr,
state,
extract(epoch from now() - state_change) AS query_time,
extract(epoch from now() - xact_start) AS xact_time,
extract(epoch from now() - backend_start) AS conn_time,
substring(query, 1, 40) AS query
FROM pg_stat_activity
WHERE backend_type = ‘client backend’
AND pid <> pg_backend_pid();
COMMENT ON VIEW monitor.pg_kill IS ‘kill all backend session’;
– quick cancel view
DROP VIEW IF EXISTS monitor.pg_cancel;
CREATE OR REPLACE VIEW monitor.pg_cancel AS
SELECT pid,
pg_cancel_backend(pid) AS cancel,
datname AS dat,
usename AS usr,
application_name AS app,
client_addr AS addr,
state,
extract(epoch from now() - state_change) AS query_time,
extract(epoch from now() - xact_start) AS xact_time,
extract(epoch from now() - backend_start) AS conn_time,
substring(query, 1, 40)
FROM pg_stat_activity
WHERE state = ‘active’
AND backend_type = ‘client backend’
and pid <> pg_backend_pid();
COMMENT ON VIEW monitor.pg_cancel IS ‘cancel backend queries’;
– seq scan
DROP VIEW IF EXISTS monitor.pg_seq_scan;
CREATE OR REPLACE VIEW monitor.pg_seq_scan AS
SELECT schemaname AS nspname,
relname,
seq_scan,
seq_tup_read,
seq_tup_read / seq_scan AS seq_tup_avg,
idx_scan,
n_live_tup + n_dead_tup AS tuples,
n_live_tup / (n_live_tup + n_dead_tup) AS dead_ratio
FROM pg_stat_user_tables
WHERE seq_scan > 0
and (n_live_tup + n_dead_tup) > 0
ORDER BY seq_tup_read DESC
LIMIT 50;
COMMENT ON VIEW monitor.pg_seq_scan IS ‘table that have seq scan’;
{% if pg_version >= 13 %}
– pg_shmem auxiliary function
– PG 13 ONLY!
CREATE OR REPLACE FUNCTION monitor.pg_shmem() RETURNS SETOF
pg_shmem_allocations AS $$ SELECT * FROM pg_shmem_allocations;$$ LANGUAGE SQL SECURITY DEFINER;
COMMENT ON FUNCTION monitor.pg_shmem() IS ‘security wrapper for pg_shmem’;
{% endif %}
–==================================================================–
– Customize Logic –
–==================================================================–
– This script will be execute on primary instance among a newly created
– postgres cluster. it will be executed as dbsu on template1 database
– put your own customize logic here
– make sure they are idempotent
</details>
一个实际的渲染样例(`pg-test`)如下所示:
<details>
```sql
----------------------------------------------------------------------
-- File : pg-init-template.sql
-- Ctime : 2018-10-30
-- Mtime : 2021-02-27
-- Desc : init postgres cluster template
-- Path : /pg/tmp/pg-init-template.sql
-- Author : Vonng(fengruohang@outlook.com)
-- Copyright (C) 2018-2021 Ruohang Feng
----------------------------------------------------------------------
--==================================================================--
-- Executions --
--==================================================================--
-- psql template1 -AXtwqf /pg/tmp/pg-init-template.sql
-- this sql scripts is responsible for post-init procedure
-- it will
-- * create system users such as replicator, monitor user, admin user
-- * create system default roles
-- * create schema, extensions in template1 & postgres
-- * create monitor views in template1 & postgres
--==================================================================--
-- Default Privileges --
--==================================================================--
ALTER DEFAULT PRIVILEGES FOR ROLE postgres GRANT USAGE ON SCHEMAS TO dbrole_readonly;
ALTER DEFAULT PRIVILEGES FOR ROLE postgres GRANT SELECT ON TABLES TO dbrole_readonly;
ALTER DEFAULT PRIVILEGES FOR ROLE postgres GRANT SELECT ON SEQUENCES TO dbrole_readonly;
ALTER DEFAULT PRIVILEGES FOR ROLE postgres GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly;
ALTER DEFAULT PRIVILEGES FOR ROLE postgres GRANT USAGE ON SCHEMAS TO dbrole_offline;
ALTER DEFAULT PRIVILEGES FOR ROLE postgres GRANT SELECT ON TABLES TO dbrole_offline;
ALTER DEFAULT PRIVILEGES FOR ROLE postgres GRANT SELECT ON SEQUENCES TO dbrole_offline;
ALTER DEFAULT PRIVILEGES FOR ROLE postgres GRANT EXECUTE ON FUNCTIONS TO dbrole_offline;
ALTER DEFAULT PRIVILEGES FOR ROLE postgres GRANT INSERT, UPDATE, DELETE ON TABLES TO dbrole_readwrite;
ALTER DEFAULT PRIVILEGES FOR ROLE postgres GRANT USAGE, UPDATE ON SEQUENCES TO dbrole_readwrite;
ALTER DEFAULT PRIVILEGES FOR ROLE postgres GRANT TRUNCATE, REFERENCES, TRIGGER ON TABLES TO dbrole_admin;
ALTER DEFAULT PRIVILEGES FOR ROLE postgres GRANT CREATE ON SCHEMAS TO dbrole_admin;
ALTER DEFAULT PRIVILEGES FOR ROLE dbuser_admin GRANT USAGE ON SCHEMAS TO dbrole_readonly;
ALTER DEFAULT PRIVILEGES FOR ROLE dbuser_admin GRANT SELECT ON TABLES TO dbrole_readonly;
ALTER DEFAULT PRIVILEGES FOR ROLE dbuser_admin GRANT SELECT ON SEQUENCES TO dbrole_readonly;
ALTER DEFAULT PRIVILEGES FOR ROLE dbuser_admin GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly;
ALTER DEFAULT PRIVILEGES FOR ROLE dbuser_admin GRANT USAGE ON SCHEMAS TO dbrole_offline;
ALTER DEFAULT PRIVILEGES FOR ROLE dbuser_admin GRANT SELECT ON TABLES TO dbrole_offline;
ALTER DEFAULT PRIVILEGES FOR ROLE dbuser_admin GRANT SELECT ON SEQUENCES TO dbrole_offline;
ALTER DEFAULT PRIVILEGES FOR ROLE dbuser_admin GRANT EXECUTE ON FUNCTIONS TO dbrole_offline;
ALTER DEFAULT PRIVILEGES FOR ROLE dbuser_admin GRANT INSERT, UPDATE, DELETE ON TABLES TO dbrole_readwrite;
ALTER DEFAULT PRIVILEGES FOR ROLE dbuser_admin GRANT USAGE, UPDATE ON SEQUENCES TO dbrole_readwrite;
ALTER DEFAULT PRIVILEGES FOR ROLE dbuser_admin GRANT TRUNCATE, REFERENCES, TRIGGER ON TABLES TO dbrole_admin;
ALTER DEFAULT PRIVILEGES FOR ROLE dbuser_admin GRANT CREATE ON SCHEMAS TO dbrole_admin;
-- for additional business admin, they can SET ROLE to dbrole_admin
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" GRANT USAGE ON SCHEMAS TO dbrole_readonly;
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" GRANT SELECT ON TABLES TO dbrole_readonly;
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" GRANT SELECT ON SEQUENCES TO dbrole_readonly;
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly;
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" GRANT USAGE ON SCHEMAS TO dbrole_offline;
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" GRANT SELECT ON TABLES TO dbrole_offline;
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" GRANT SELECT ON SEQUENCES TO dbrole_offline;
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" GRANT EXECUTE ON FUNCTIONS TO dbrole_offline;
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" GRANT INSERT, UPDATE, DELETE ON TABLES TO dbrole_readwrite;
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" GRANT USAGE, UPDATE ON SEQUENCES TO dbrole_readwrite;
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" GRANT TRUNCATE, REFERENCES, TRIGGER ON TABLES TO dbrole_admin;
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" GRANT CREATE ON SCHEMAS TO dbrole_admin;
--==================================================================--
-- Schemas --
--==================================================================--
CREATE SCHEMA IF NOT EXISTS "monitor";
-- revoke public creation
REVOKE CREATE ON SCHEMA public FROM PUBLIC;
--==================================================================--
-- Extensions --
--==================================================================--
CREATE EXTENSION IF NOT EXISTS "pg_stat_statements" WITH SCHEMA "monitor";
CREATE EXTENSION IF NOT EXISTS "pgstattuple" WITH SCHEMA "monitor";
CREATE EXTENSION IF NOT EXISTS "pg_qualstats" WITH SCHEMA "monitor";
CREATE EXTENSION IF NOT EXISTS "pg_buffercache" WITH SCHEMA "monitor";
CREATE EXTENSION IF NOT EXISTS "pageinspect" WITH SCHEMA "monitor";
CREATE EXTENSION IF NOT EXISTS "pg_prewarm" WITH SCHEMA "monitor";
CREATE EXTENSION IF NOT EXISTS "pg_visibility" WITH SCHEMA "monitor";
CREATE EXTENSION IF NOT EXISTS "pg_freespacemap" WITH SCHEMA "monitor";
CREATE EXTENSION IF NOT EXISTS "pg_repack" WITH SCHEMA "monitor";
CREATE EXTENSION IF NOT EXISTS "postgres_fdw";
CREATE EXTENSION IF NOT EXISTS "file_fdw";
CREATE EXTENSION IF NOT EXISTS "btree_gist";
CREATE EXTENSION IF NOT EXISTS "btree_gin";
CREATE EXTENSION IF NOT EXISTS "pg_trgm";
CREATE EXTENSION IF NOT EXISTS "intagg";
CREATE EXTENSION IF NOT EXISTS "intarray";
--==================================================================--
-- Monitor Views --
--==================================================================--
----------------------------------------------------------------------
-- cleanse
----------------------------------------------------------------------
CREATE SCHEMA IF NOT EXISTS monitor;
GRANT USAGE ON SCHEMA monitor TO "dbuser_monitor";
GRANT USAGE ON SCHEMA monitor TO "dbuser_admin";
GRANT USAGE ON SCHEMA monitor TO "replicator";
DROP VIEW IF EXISTS monitor.pg_table_bloat_human;
DROP VIEW IF EXISTS monitor.pg_index_bloat_human;
DROP VIEW IF EXISTS monitor.pg_table_bloat;
DROP VIEW IF EXISTS monitor.pg_index_bloat;
DROP VIEW IF EXISTS monitor.pg_session;
DROP VIEW IF EXISTS monitor.pg_kill;
DROP VIEW IF EXISTS monitor.pg_cancel;
DROP VIEW IF EXISTS monitor.pg_seq_scan;
----------------------------------------------------------------------
-- Table bloat estimate
----------------------------------------------------------------------
CREATE OR REPLACE VIEW monitor.pg_table_bloat AS
SELECT CURRENT_CATALOG AS datname, nspname, relname , bs * tblpages AS size,
CASE WHEN tblpages - est_tblpages_ff > 0 THEN (tblpages - est_tblpages_ff)/tblpages::FLOAT ELSE 0 END AS ratio
FROM (
SELECT ceil( reltuples / ( (bs-page_hdr)*fillfactor/(tpl_size*100) ) ) + ceil( toasttuples / 4 ) AS est_tblpages_ff,
tblpages, fillfactor, bs, tblid, nspname, relname, is_na
FROM (
SELECT
( 4 + tpl_hdr_size + tpl_data_size + (2 * ma)
- CASE WHEN tpl_hdr_size % ma = 0 THEN ma ELSE tpl_hdr_size % ma END
- CASE WHEN ceil(tpl_data_size)::INT % ma = 0 THEN ma ELSE ceil(tpl_data_size)::INT % ma END
) AS tpl_size, (heappages + toastpages) AS tblpages, heappages,
toastpages, reltuples, toasttuples, bs, page_hdr, tblid, nspname, relname, fillfactor, is_na
FROM (
SELECT
tbl.oid AS tblid, ns.nspname , tbl.relname, tbl.reltuples,
tbl.relpages AS heappages, coalesce(toast.relpages, 0) AS toastpages,
coalesce(toast.reltuples, 0) AS toasttuples,
coalesce(substring(array_to_string(tbl.reloptions, ' ') FROM 'fillfactor=([0-9]+)')::smallint, 100) AS fillfactor,
current_setting('block_size')::numeric AS bs,
CASE WHEN version()~'mingw32' OR version()~'64-bit|x86_64|ppc64|ia64|amd64' THEN 8 ELSE 4 END AS ma,
24 AS page_hdr,
23 + CASE WHEN MAX(coalesce(s.null_frac,0)) > 0 THEN ( 7 + count(s.attname) ) / 8 ELSE 0::int END
+ CASE WHEN bool_or(att.attname = 'oid' and att.attnum < 0) THEN 4 ELSE 0 END AS tpl_hdr_size,
sum( (1-coalesce(s.null_frac, 0)) * coalesce(s.avg_width, 0) ) AS tpl_data_size,
bool_or(att.atttypid = 'pg_catalog.name'::regtype)
OR sum(CASE WHEN att.attnum > 0 THEN 1 ELSE 0 END) <> count(s.attname) AS is_na
FROM pg_attribute AS att
JOIN pg_class AS tbl ON att.attrelid = tbl.oid
JOIN pg_namespace AS ns ON ns.oid = tbl.relnamespace
LEFT JOIN pg_stats AS s ON s.schemaname=ns.nspname AND s.tablename = tbl.relname AND s.inherited=false AND s.attname=att.attname
LEFT JOIN pg_class AS toast ON tbl.reltoastrelid = toast.oid
WHERE NOT att.attisdropped AND tbl.relkind = 'r' AND nspname NOT IN ('pg_catalog','information_schema')
GROUP BY 1,2,3,4,5,6,7,8,9,10
) AS s
) AS s2
) AS s3
WHERE NOT is_na;
COMMENT ON VIEW monitor.pg_table_bloat IS 'postgres table bloat estimate';
----------------------------------------------------------------------
-- Index bloat estimate
----------------------------------------------------------------------
CREATE OR REPLACE VIEW monitor.pg_index_bloat AS
SELECT CURRENT_CATALOG AS datname, nspname, idxname AS relname, relpages::BIGINT * bs AS size,
COALESCE((relpages - ( reltuples * (6 + ma - (CASE WHEN index_tuple_hdr % ma = 0 THEN ma ELSE index_tuple_hdr % ma END)
+ nulldatawidth + ma - (CASE WHEN nulldatawidth % ma = 0 THEN ma ELSE nulldatawidth % ma END))
/ (bs - pagehdr)::FLOAT + 1 )), 0) / relpages::FLOAT AS ratio
FROM (
SELECT nspname,
idxname,
reltuples,
relpages,
current_setting('block_size')::INTEGER AS bs,
(CASE WHEN version() ~ 'mingw32' OR version() ~ '64-bit|x86_64|ppc64|ia64|amd64' THEN 8 ELSE 4 END) AS ma,
24 AS pagehdr,
(CASE WHEN max(COALESCE(pg_stats.null_frac, 0)) = 0 THEN 2 ELSE 6 END) AS index_tuple_hdr,
sum((1.0 - COALESCE(pg_stats.null_frac, 0.0)) *
COALESCE(pg_stats.avg_width, 1024))::INTEGER AS nulldatawidth
FROM pg_attribute
JOIN (
SELECT pg_namespace.nspname,
ic.relname AS idxname,
ic.reltuples,
ic.relpages,
pg_index.indrelid,
pg_index.indexrelid,
tc.relname AS tablename,
regexp_split_to_table(pg_index.indkey::TEXT, ' ') :: INTEGER AS attnum,
pg_index.indexrelid AS index_oid
FROM pg_index
JOIN pg_class ic ON pg_index.indexrelid = ic.oid
JOIN pg_class tc ON pg_index.indrelid = tc.oid
JOIN pg_namespace ON pg_namespace.oid = ic.relnamespace
JOIN pg_am ON ic.relam = pg_am.oid
WHERE pg_am.amname = 'btree' AND ic.relpages > 0 AND nspname NOT IN ('pg_catalog', 'information_schema')
) ind_atts ON pg_attribute.attrelid = ind_atts.indexrelid AND pg_attribute.attnum = ind_atts.attnum
JOIN pg_stats ON pg_stats.schemaname = ind_atts.nspname
AND ((pg_stats.tablename = ind_atts.tablename AND pg_stats.attname = pg_get_indexdef(pg_attribute.attrelid, pg_attribute.attnum, TRUE))
OR (pg_stats.tablename = ind_atts.idxname AND pg_stats.attname = pg_attribute.attname))
WHERE pg_attribute.attnum > 0
GROUP BY 1, 2, 3, 4, 5, 6
) est
LIMIT 512;
COMMENT ON VIEW monitor.pg_index_bloat IS 'postgres index bloat estimate (btree-only)';
----------------------------------------------------------------------
-- table bloat pretty
----------------------------------------------------------------------
CREATE OR REPLACE VIEW monitor.pg_table_bloat_human AS
SELECT nspname || '.' || relname AS name,
pg_size_pretty(size) AS size,
pg_size_pretty((size * ratio)::BIGINT) AS wasted,
round(100 * ratio::NUMERIC, 2) as ratio
FROM monitor.pg_table_bloat ORDER BY wasted DESC NULLS LAST;
COMMENT ON VIEW monitor.pg_table_bloat_human IS 'postgres table bloat pretty';
----------------------------------------------------------------------
-- index bloat pretty
----------------------------------------------------------------------
CREATE OR REPLACE VIEW monitor.pg_index_bloat_human AS
SELECT nspname || '.' || relname AS name,
pg_size_pretty(size) AS size,
pg_size_pretty((size * ratio)::BIGINT) AS wasted,
round(100 * ratio::NUMERIC, 2) as ratio
FROM monitor.pg_index_bloat;
COMMENT ON VIEW monitor.pg_index_bloat_human IS 'postgres index bloat pretty';
----------------------------------------------------------------------
-- pg session
----------------------------------------------------------------------
CREATE OR REPLACE VIEW monitor.pg_session AS
SELECT coalesce(datname, 'all') AS datname,
numbackends,
active,
idle,
ixact,
max_duration,
max_tx_duration,
max_conn_duration
FROM (
SELECT datname,
count(*) AS numbackends,
count(*) FILTER ( WHERE state = 'active' ) AS active,
count(*) FILTER ( WHERE state = 'idle' ) AS idle,
count(*) FILTER ( WHERE state = 'idle in transaction'
OR state = 'idle in transaction (aborted)' ) AS ixact,
max(extract(epoch from now() - state_change))
FILTER ( WHERE state = 'active' ) AS max_duration,
max(extract(epoch from now() - xact_start)) AS max_tx_duration,
max(extract(epoch from now() - backend_start)) AS max_conn_duration
FROM pg_stat_activity
WHERE backend_type = 'client backend'
AND pid <> pg_backend_pid()
GROUP BY ROLLUP (1)
ORDER BY 1 NULLS FIRST
) t;
COMMENT ON VIEW monitor.pg_session IS 'postgres session stats';
----------------------------------------------------------------------
-- pg kill
----------------------------------------------------------------------
CREATE OR REPLACE VIEW monitor.pg_kill AS
SELECT pid,
pg_terminate_backend(pid) AS killed,
datname AS dat,
usename AS usr,
application_name AS app,
client_addr AS addr,
state,
extract(epoch from now() - state_change) AS query_time,
extract(epoch from now() - xact_start) AS xact_time,
extract(epoch from now() - backend_start) AS conn_time,
substring(query, 1, 40) AS query
FROM pg_stat_activity
WHERE backend_type = 'client backend'
AND pid <> pg_backend_pid();
COMMENT ON VIEW monitor.pg_kill IS 'kill all backend session';
----------------------------------------------------------------------
-- quick cancel view
----------------------------------------------------------------------
DROP VIEW IF EXISTS monitor.pg_cancel;
CREATE OR REPLACE VIEW monitor.pg_cancel AS
SELECT pid,
pg_cancel_backend(pid) AS cancel,
datname AS dat,
usename AS usr,
application_name AS app,
client_addr AS addr,
state,
extract(epoch from now() - state_change) AS query_time,
extract(epoch from now() - xact_start) AS xact_time,
extract(epoch from now() - backend_start) AS conn_time,
substring(query, 1, 40)
FROM pg_stat_activity
WHERE state = 'active'
AND backend_type = 'client backend'
and pid <> pg_backend_pid();
COMMENT ON VIEW monitor.pg_cancel IS 'cancel backend queries';
----------------------------------------------------------------------
-- seq scan
----------------------------------------------------------------------
DROP VIEW IF EXISTS monitor.pg_seq_scan;
CREATE OR REPLACE VIEW monitor.pg_seq_scan AS
SELECT schemaname AS nspname,
relname,
seq_scan,
seq_tup_read,
seq_tup_read / seq_scan AS seq_tup_avg,
idx_scan,
n_live_tup + n_dead_tup AS tuples,
n_live_tup / (n_live_tup + n_dead_tup) AS dead_ratio
FROM pg_stat_user_tables
WHERE seq_scan > 0
and (n_live_tup + n_dead_tup) > 0
ORDER BY seq_tup_read DESC
LIMIT 50;
COMMENT ON VIEW monitor.pg_seq_scan IS 'table that have seq scan';
----------------------------------------------------------------------
-- pg_shmem auxiliary function
-- PG 13 ONLY!
----------------------------------------------------------------------
CREATE OR REPLACE FUNCTION monitor.pg_shmem() RETURNS SETOF
pg_shmem_allocations AS $$ SELECT * FROM pg_shmem_allocations;$$ LANGUAGE SQL SECURITY DEFINER;
COMMENT ON FUNCTION monitor.pg_shmem() IS 'security wrapper for pg_shmem';
--==================================================================--
-- Customize Logic --
--==================================================================--
-- This script will be execute on primary instance among a newly created
-- postgres cluster. it will be executed as dbsu on template1 database
-- put your own customize logic here
-- make sure they are idempotent
5.2.5 - Customize ACL
Configure access control in Pigsty
PostgreSQL中的ACL包括两部分,用户权限体系(Privileges) 与 Host Based Authentication (HBA)
Pigsty提供了默认访问控制系统,用户可在此基础上进一步定制,与ACL相关的配置项包括:
HBA规则
用户可以通过 pg_hba_rules 与 pg_hba_rules_extra 定制 Postgres的HBA规则,通过 pgbouncer_hba_rules 与 pgbouncer_hba_rules_extra 定制Pgbouncer的HBA规则。
一条HBA规则是一个对象,包含3个必选字段:title,role,rules。
title: intranet password access
role: common
rules:
- host all all 10.0.0.0/8 md5
- host all all 172.16.0.0/12 md5
- host all all 192.168.0.0/16 md5
title 是这条规则的说明,会被渲染为注释信息。role 是这条规则的应用范围,rules 是具体的HBA规则数组,每一个元素都是一条规则五元组,请参考PG官方文档。
这样的一条规则,会被渲染至/pg/data/pg_hba.conf文件中。
# allow intranet password access
host all all 10.0.0.0/8 md5
host all all 172.16.0.0/12 md5
host all all 192.168.0.0/16 md5
规则的应用范围
规则的 role 用于控制规则安装的位置。
role = common的HBA规则组会安装到所有的实例上,而其他的取值,例如(role : primary)则只会安装至pg_role = primary的实例上。因此用户可以通过角色体系定义灵活的HBA规则。
作为一个特例,role: offline 的HBA规则,除了会安装至pg_role == 'offline'的实例,也会安装至pg_offline_query == true的实例上,允许离线用户访问。
规则的应用顺序
定义的HBA规则按照以下顺序生效:
特别注意
请注意,因为在实际生产应用中,通常会基于实例的角色,对HBA进行区分与细化管理。Pigsty不建议通过Patroni管理HBA配置。如果配置了Patroni中的HBA规则,数据库的HBA会在重启时被Patroni所覆盖。
5.3 - Playbooks
Built-in playbooks to perform various tasks
Pigsty uses a declarative interface, [configuration](. /config/) is done, just run the fixed Playbook and you’re done deploying
Basic Deployment
Sandbox Deployment
Monitor-only deployments
Day-to-day management
Pigsty also provides a number of pre-built scripts for daily operations and maintenance management.
5.3.1 - Infra Provision
How to pull up infrasturcture on meta node
Overview
Infrastructure initialization is done via infra.yml. The script completes the installation and deployment of infrastructure on the meta node.
``infra.ymltakes the metanode (default group namemeta`) as the deployment target.
!
Caution
❗️ The initialization of the meta node must be completed before the initialization of the database node can be executed properly
infra.yml is fixed to work on the group named meta in the configuration file
meta nodes can be reused as normal nodes, i.e. PostgreSQL databases can be defined and created on meta nodes as well.
Pigsty recommends using the default configuration and creating a cluster of pg-meta meta-databases on the meta-nodes for hosting Pigsty advanced features.
A complete execution of the initialization process can take 2 to 8 minutes, depending on the machine configuration.
Selective execution
Users can selectively execute a subset of scripts through ansible’s tagging mechanism.
For example, if you want to execute only the local source initialization part, you can do so with the following command.
Please refer to [task details](#task details) for specific tags
Some common subsets of tasks include.
. /infra.yml --tags=repo -e repo_rebuild=true # Force a local source to be recreated
. /infra.yml --tags=prometheus_reload # Reload Prometheus configuration
. /infra.yml --tags=nginx_haproxy # Regenerate the Nginx Haproxy index page
. /infra.yml --tags=prometheus_targets,prometheus_reload # Regenerate the Prometheus static monitoring object file and apply
script description
infra.yml does the following stuff:
- Deploy and enable local sources
- Complete metanode initialization
- Complete meta-node infrastructure initialization
- CA infrastructure
- DNS Nameserver
- Nginx
- Prometheus & Alertmanger
- Grafana
- Copy the Pigsty ontology to the meta node
- Complete database initialization on the meta node (optional, users can reuse the meta node through the standard database cluster initialization process)
Content
#!/usr/bin/env ansible-playbook
---
#==============================================================#
# File : infra.yml
# Ctime : 2020-04-13
# Mtime : 2020-07-23
# Desc : init infrastructure on meta nodes
# Path : infra.yml
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
#------------------------------------------------------------------------------
# init local yum repo (only run on meta nodes)
#------------------------------------------------------------------------------
- name: Init local repo
become: yes
hosts: meta
gather_facts: no
tags: repo
roles:
- repo
#------------------------------------------------------------------------------
# provision nodes
#------------------------------------------------------------------------------
- name: Provision Node
become: yes
hosts: meta
gather_facts: no
tags: node
roles:
- node
#------------------------------------------------------------------------------
# init meta service (only run on meta nodes)
#------------------------------------------------------------------------------
- name: Init meta service
become: yes
hosts: meta
gather_facts: no
tags: meta
roles:
- role: ca
tags: ca
- role: nameserver
tags: nameserver
- role: nginx
tags: nginx
- role: prometheus
tags: prometheus
- role: grafana
tags: grafana
#------------------------------------------------------------------------------
# init dcs on nodes
#------------------------------------------------------------------------------
- name: Init dcs
become: yes
hosts: meta
gather_facts: no
roles:
- role: consul
tags: dcs
#------------------------------------------------------------------------------
# copy scripts to meta node
#------------------------------------------------------------------------------
- name: Copy ansible scripts
become: yes
hosts: meta
gather_facts: no
ignore_errors: yes
tags: ansible
tasks:
- name: Copy ansible scritps
when: node_admin_setup is defined and node_admin_setup|bool and node_admin_username != ''
block:
# create copy of this repo
- name: Create ansible tarball
become: no
connection: local
run_once: true
command:
cmd: tar -cf files/meta.tgz roles templates ansible.cfg infra.yml pgsql.yml pgsql-remove.yml pgsql-createdb.yml pgsql-createuser.yml pgsql-service.yml pgsql-monitor.yml pigsty.yml Makefile
chdir: "{{ playbook_dir }}"
- name: Create ansible directory
file: path="/home/{{ node_admin_username }}/meta" state=directory owner={{ node_admin_username }}
- name: Copy ansible tarball
copy: src="meta.tgz" dest="/home/{{ node_admin_username }}/meta/meta.tgz" owner={{ node_admin_username }}
- name: Extract tarball
shell: |
cd /home/{{ node_admin_username }}/meta/
tar -xf meta.tgz
chown -R {{ node_admin_username }} /home/{{ node_admin_username }}
rm -rf meta.tgz
chmod a+x *.yml
#------------------------------------------------------------------------------
# meta node database (optional)
#------------------------------------------------------------------------------
# this play will create database clusters on meta nodes.
# it's good to reuse meta node as normal database nodes too
# but it's always better to leave it be.
#------------------------------------------------------------------------------
#- name: Pgsql Initialization
# become: yes
# hosts: meta
# gather_facts: no
# roles:
# - role: postgres # init postgres
# tags: [pgsql, postgres]
#
# - role: monitor # init monitor system
# tags: [pgsql, monitor]
#
# - role: service # init haproxy
# tags: [service]
...
任务详情
使用以下命令可以列出所有基础设施初始化会执行的任务,以及可以使用的标签:
默认任务如下:
playbook: ./infra.yml
play #1 (meta): Init local repo TAGS: [repo]
tasks:
repo : Create local repo directory TAGS: [repo, repo_dir]
repo : Backup & remove existing repos TAGS: [repo, repo_upstream]
repo : Add required upstream repos TAGS: [repo, repo_upstream]
repo : Check repo pkgs cache exists TAGS: [repo, repo_prepare]
repo : Set fact whether repo_exists TAGS: [repo, repo_prepare]
repo : Move upstream repo to backup TAGS: [repo, repo_prepare]
repo : Add local file system repos TAGS: [repo, repo_prepare]
repo : Remake yum cache if not exists TAGS: [repo, repo_prepare]
repo : Install repo bootstrap packages TAGS: [repo, repo_boot]
repo : Render repo nginx server files TAGS: [repo, repo_nginx]
repo : Disable selinux for repo server TAGS: [repo, repo_nginx]
repo : Launch repo nginx server TAGS: [repo, repo_nginx]
repo : Waits repo server online TAGS: [repo, repo_nginx]
repo : Download web url packages TAGS: [repo, repo_download]
repo : Download repo packages TAGS: [repo, repo_download]
repo : Download repo pkg deps TAGS: [repo, repo_download]
repo : Create local repo index TAGS: [repo, repo_download]
repo : Copy bootstrap scripts TAGS: [repo, repo_download, repo_script]
repo : Mark repo cache as valid TAGS: [repo, repo_download]
play #2 (meta): Provision Node TAGS: [node]
tasks:
node : Update node hostname TAGS: [node, node_name]
node : Add new hostname to /etc/hosts TAGS: [node, node_name]
node : Write static dns records TAGS: [node, node_dns]
node : Get old nameservers TAGS: [node, node_resolv]
node : Truncate resolv file TAGS: [node, node_resolv]
node : Write resolv options TAGS: [node, node_resolv]
node : Add new nameservers TAGS: [node, node_resolv]
node : Append old nameservers TAGS: [node, node_resolv]
node : Node configure disable firewall TAGS: [node, node_firewall]
node : Node disable selinux by default TAGS: [node, node_firewall]
node : Backup existing repos TAGS: [node, node_repo]
node : Install upstream repo TAGS: [node, node_repo]
node : Install local repo TAGS: [node, node_repo]
node : Install node basic packages TAGS: [node, node_pkgs]
node : Install node extra packages TAGS: [node, node_pkgs]
node : Install meta specific packages TAGS: [node, node_pkgs]
node : Install node basic packages TAGS: [node, node_pkgs]
node : Install node extra packages TAGS: [node, node_pkgs]
node : Install meta specific packages TAGS: [node, node_pkgs]
node : Node configure disable numa TAGS: [node, node_feature]
node : Node configure disable swap TAGS: [node, node_feature]
node : Node configure unmount swap TAGS: [node, node_feature]
node : Node setup static network TAGS: [node, node_feature]
node : Node configure disable firewall TAGS: [node, node_feature]
node : Node configure disk prefetch TAGS: [node, node_feature]
node : Enable linux kernel modules TAGS: [node, node_kernel]
node : Enable kernel module on reboot TAGS: [node, node_kernel]
node : Get config parameter page count TAGS: [node, node_tuned]
node : Get config parameter page size TAGS: [node, node_tuned]
node : Tune shmmax and shmall via mem TAGS: [node, node_tuned]
node : Create tuned profiles TAGS: [node, node_tuned]
node : Render tuned profiles TAGS: [node, node_tuned]
node : Active tuned profile TAGS: [node, node_tuned]
node : Change additional sysctl params TAGS: [node, node_tuned]
node : Copy default user bash profile TAGS: [node, node_profile]
node : Setup node default pam ulimits TAGS: [node, node_ulimit]
node : Create os user group admin TAGS: [node, node_admin]
node : Create os user admin TAGS: [node, node_admin]
node : Grant admin group nopass sudo TAGS: [node, node_admin]
node : Add no host checking to ssh config TAGS: [node, node_admin]
node : Add admin ssh no host checking TAGS: [node, node_admin]
node : Fetch all admin public keys TAGS: [node, node_admin]
node : Exchange all admin ssh keys TAGS: [node, node_admin]
node : Install public keys TAGS: [node, node_admin]
node : Install ntp package TAGS: [node, ntp_install]
node : Install chrony package TAGS: [node, ntp_install]
node : Setup default node timezone TAGS: [node, ntp_config]
node : Copy the ntp.conf file TAGS: [node, ntp_config]
node : Copy the chrony.conf template TAGS: [node, ntp_config]
node : Launch ntpd service TAGS: [node, ntp_launch]
node : Launch chronyd service TAGS: [node, ntp_launch]
play #3 (meta): Init meta service TAGS: [meta]
tasks:
ca : Create local ca directory TAGS: [ca, ca_dir, meta]
ca : Copy ca cert from local files TAGS: [ca, ca_copy, meta]
ca : Check ca key cert exists TAGS: [ca, ca_create, meta]
ca : Create self-signed CA key-cert TAGS: [ca, ca_create, meta]
nameserver : Make sure dnsmasq package installed TAGS: [meta, nameserver]
nameserver : Copy dnsmasq /etc/dnsmasq.d/config TAGS: [meta, nameserver]
nameserver : Add dynamic dns records to meta TAGS: [meta, nameserver]
nameserver : Launch meta dnsmasq service TAGS: [meta, nameserver]
nameserver : Wait for meta dnsmasq online TAGS: [meta, nameserver]
nameserver : Register consul dnsmasq service TAGS: [meta, nameserver]
nameserver : Reload consul TAGS: [meta, nameserver]
nginx : Make sure nginx installed TAGS: [meta, nginx, nginx_install]
nginx : Create local html directory TAGS: [meta, nginx, nginx_content]
nginx : Create nginx config directory TAGS: [meta, nginx, nginx_content]
nginx : Update default nginx index page TAGS: [meta, nginx, nginx_content]
nginx : Copy nginx default config TAGS: [meta, nginx, nginx_config]
nginx : Copy nginx upstream conf TAGS: [meta, nginx, nginx_config]
nginx : Templating /etc/nginx/haproxy.conf TAGS: [meta, nginx, nginx_haproxy]
nginx : Render haproxy upstream in cluster mode TAGS: [meta, nginx, nginx_haproxy]
nginx : Render haproxy location in cluster mode TAGS: [meta, nginx, nginx_haproxy]
nginx : Templating haproxy cluster index TAGS: [meta, nginx, nginx_haproxy]
nginx : Templating haproxy cluster index TAGS: [meta, nginx, nginx_haproxy]
nginx : Restart meta nginx service TAGS: [meta, nginx, nginx_restart]
nginx : Wait for nginx service online TAGS: [meta, nginx, nginx_restart]
nginx : Make sure nginx exporter installed TAGS: [meta, nginx, nginx_exporter]
nginx : Config nginx_exporter options TAGS: [meta, nginx, nginx_exporter]
nginx : Restart nginx_exporter service TAGS: [meta, nginx, nginx_exporter]
nginx : Wait for nginx exporter online TAGS: [meta, nginx, nginx_exporter]
nginx : Register cosnul nginx service TAGS: [meta, nginx, nginx_register]
nginx : Register consul nginx-exporter service TAGS: [meta, nginx, nginx_register]
nginx : Reload consul TAGS: [meta, nginx, nginx_register]
prometheus : Install prometheus and alertmanager TAGS: [meta, prometheus]
prometheus : Wipe out prometheus config dir TAGS: [meta, prometheus, prometheus_clean]
prometheus : Wipe out existing prometheus data TAGS: [meta, prometheus, prometheus_clean]
prometheus : Create postgres directory structure TAGS: [meta, prometheus, prometheus_config]
prometheus : Copy prometheus bin scripts TAGS: [meta, prometheus, prometheus_config]
prometheus : Copy prometheus rules scripts TAGS: [meta, prometheus, prometheus_config]
prometheus : Copy altermanager config TAGS: [meta, prometheus, prometheus_config]
prometheus : Render prometheus config TAGS: [meta, prometheus, prometheus_config]
prometheus : Config /etc/prometheus opts TAGS: [meta, prometheus, prometheus_config]
prometheus : Launch prometheus service TAGS: [meta, prometheus, prometheus_launch]
prometheus : Launch alertmanager service TAGS: [meta, prometheus, prometheus_launch]
prometheus : Wait for prometheus online TAGS: [meta, prometheus, prometheus_launch]
prometheus : Wait for alertmanager online TAGS: [meta, prometheus, prometheus_launch]
prometheus : Render prometheus targets in cluster mode TAGS: [meta, prometheus, prometheus_targets]
prometheus : Reload prometheus service TAGS: [meta, prometheus, prometheus_reload]
prometheus : Copy prometheus service definition TAGS: [meta, prometheus, prometheus_register]
prometheus : Copy alertmanager service definition TAGS: [meta, prometheus, prometheus_register]
prometheus : Reload consul to register prometheus TAGS: [meta, prometheus, prometheus_register]
grafana : Make sure grafana is installed TAGS: [grafana, grafana_install, meta]
grafana : Check grafana plugin cache exists TAGS: [grafana, grafana_plugin, meta]
grafana : Provision grafana plugins via cache TAGS: [grafana, grafana_plugin, meta]
grafana : Download grafana plugins from web TAGS: [grafana, grafana_plugin, meta]
grafana : Download grafana plugins from web TAGS: [grafana, grafana_plugin, meta]
grafana : Create grafana plugins cache TAGS: [grafana, grafana_plugin, meta]
grafana : Copy /etc/grafana/grafana.ini TAGS: [grafana, grafana_config, meta]
grafana : Remove grafana provision dir TAGS: [grafana, grafana_config, meta]
grafana : Copy provisioning content TAGS: [grafana, grafana_config, meta]
grafana : Copy pigsty dashboards TAGS: [grafana, grafana_config, meta]
grafana : Copy pigsty icon image TAGS: [grafana, grafana_config, meta]
grafana : Replace grafana icon with pigsty TAGS: [grafana, grafana_config, grafana_customize, meta]
grafana : Launch grafana service TAGS: [grafana, grafana_launch, meta]
grafana : Wait for grafana online TAGS: [grafana, grafana_launch, meta]
grafana : Update grafana default preferences TAGS: [grafana, grafana_provision, meta]
grafana : Register consul grafana service TAGS: [grafana, grafana_register, meta]
grafana : Reload consul TAGS: [grafana, grafana_register, meta]
play #4 (meta): Init dcs TAGS: []
tasks:
consul : Check for existing consul TAGS: [consul_check, dcs]
consul : Consul exists flag fact set TAGS: [consul_check, dcs]
consul : Abort due to consul exists TAGS: [consul_check, dcs]
consul : Clean existing consul instance TAGS: [consul_clean, dcs]
consul : Stop any running consul instance TAGS: [consul_clean, dcs]
consul : Remove existing consul dir TAGS: [consul_clean, dcs]
consul : Recreate consul dir TAGS: [consul_clean, dcs]
consul : Make sure consul is installed TAGS: [consul_install, dcs]
consul : Make sure consul dir exists TAGS: [consul_config, dcs]
consul : Get dcs server node names TAGS: [consul_config, dcs]
consul : Get dcs node name from var TAGS: [consul_config, dcs]
consul : Get dcs node name from var TAGS: [consul_config, dcs]
consul : Fetch hostname as dcs node name TAGS: [consul_config, dcs]
consul : Get dcs name from hostname TAGS: [consul_config, dcs]
consul : Copy /etc/consul.d/consul.json TAGS: [consul_config, dcs]
consul : Copy consul agent service TAGS: [consul_config, dcs]
consul : Get dcs bootstrap expect quroum TAGS: [consul_server, dcs]
consul : Copy consul server service unit TAGS: [consul_server, dcs]
consul : Launch consul server service TAGS: [consul_server, dcs]
consul : Wait for consul server online TAGS: [consul_server, dcs]
consul : Launch consul agent service TAGS: [consul_agent, dcs]
consul : Wait for consul agent online TAGS: [consul_agent, dcs]
play #5 (meta): Copy ansible scripts TAGS: [ansible]
tasks:
Create ansible tarball TAGS: [ansible]
Create ansible directory TAGS: [ansible]
Copy ansible tarball TAGS: [ansible]
Extract tarball TAGS: [ansible]

5.3.2 - Pgsql Provision
How to define and create postgres clusters?
Playbook Overview
After completing the [infrastructure initialization](. /infra-provision/), users can pgsql.yml to complete the initialization of the database cluster.
First in [Pigsty configuration file](… /… //config/pgsql/) and then apply the changes to the real environment by executing pgsql.yml.
. /pgsql.yml # Execute the database cluster initialization operation on all the machines in the manifest (danger!)
. /pgsql.yml -l pg-test # Perform database cluster initialization on the machines under the pg-test manifest (recommended!)
. /pgsql.yml -l pg-meta,pg-test # Initialize both pg-meta and pg-test clusters at the same time
. /pgsql.yml -l 10.10.10.11 # Initialize the database instance on the machine 10.10.10.11

Caution
-
Using pgsql.yml without parameters is convenient, but it is a high-risk operation in production environments
It is strongly recommended that you add the -l parameter to the execution to limit the range of objects for which the command can be executed.
-
Users can treat metanodes as normal nodes reuse, i.e. define and create PostgreSQL databases on metanodes.
In the default sandbox environment, executing . /pgsql.yml will complete the initialization of pg-meta and pg-test at the same time.
-
Separately When performing initialization for a cluster slave, the user must make sure that the master library has been initialized, but not the master and its slaves at the same time.
Protection mechanism
pgsql.yml provides a protection mechanism determined by the configuration parameter pg_exists_action. When there is a running instance of PostgreSQL on the target machine before executing the script, Pigsty will act according to the configuration abort|clean|skip of pg_exists_action.
abort: recommended to be set as the default configuration to abort script execution if an existing instance is encountered to avoid accidental library deletion.clean: recommended to be used in local sandbox environment, to clear existing database in case of existing instances.skip: Execute subsequent logic directly on the existing database cluster.- You can use
. /pgsql.yml -e pg_exists_action=clean to override the configuration file option and force wipe the existing instance
The pg_disable_purge`'' option provides double protection; if enabled, pg_exists_action'' is forced to be set to ``abort' and will not wipe out running database instances under any circumstances.
dcs_exists_action` and dcs_disable_purge` have the same effect as the above two options, but for DCS (Consul Agent) instances.
Selective execution
Users have the option to execute a subset of scripts through ansible’s tagging mechanism.
As an example, if you want to execute only the service initialization part, you can do so with the following command
./pgsql.yml --tags=service
Frequently used subsets
./pgsql.yml --tags=infra # 完成基础设施的初始化,包括机器节点初始化与DCS部署
./pgsql.yml --tags=node # 完成机器节点的初始化
./pgsql.yml --tags=dcs # 完成DCS:consul/etcd的初始化
./pgsql.yml --tags=dcs -e dcs_exists_action # 完成consul/etcd的初始化,抹除已有的consul agent
./pgsql.yml --tags=pgsql # 完成数据库与监控的部署
./pgsql.yml --tags=postgres # 完成数据库部署
./pgsql.yml --tags=monitor # 完成监控的部署
./pgsql.yml --tags=service # 完成负载均衡的部署,包括Haproxy与VIP
./pgsql.yml --tags=haproxy_config,haproxy_reload # 修改Haproxy配置并应用。
Description
pgsql.yml does the following, among others.
- Initialize the database node infrastructure (
node)
- Initialize the DCS Agent (or DCS Server if it is a meta-node) service (
consul)
- Install, deploy, and initialize PostgreSQL, Pgbouncer, Patroni (
postgres)
- Installation of PostgreSQL monitoring system (
monitor)
- Installing and deploying Haproxy and VIP, exposing services to the outside world (
service)
Please refer to Tasks for the precise label about tasks
#!/usr/bin/env ansible-playbook
---
#==============================================================#
# File : pgsql.yml
# Mtime : 2020-05-12
# Mtime : 2021-03-15
# Desc : initialize pigsty cluster
# Path : pgsql.yml
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
#------------------------------------------------------------------------------
# init node and database
#------------------------------------------------------------------------------
- name: Pgsql Initialization
become: yes
hosts: all
gather_facts: no
roles:
- role: node # init node
tags: [infra, node]
- role: consul # init consul
tags: [infra, dcs]
- role: postgres # init postgres
tags: [pgsql, postgres]
- role: monitor # init monitor system
tags: [pgsql, monitor]
- role: service # init service
tags: [service]
...
Tasks
list all available tasks with following commands
默认任务如下:
playbook: ./pgsql.yml
play #1 (all): Pgsql Initialization TAGS: []
tasks:
node : Update node hostname TAGS: [infra, node, node_name]
node : Add new hostname to /etc/hosts TAGS: [infra, node, node_name]
node : Write static dns records TAGS: [infra, node, node_dns]
node : Get old nameservers TAGS: [infra, node, node_resolv]
node : Truncate resolv file TAGS: [infra, node, node_resolv]
node : Write resolv options TAGS: [infra, node, node_resolv]
node : Add new nameservers TAGS: [infra, node, node_resolv]
node : Append old nameservers TAGS: [infra, node, node_resolv]
node : Node configure disable firewall TAGS: [infra, node, node_firewall]
node : Node disable selinux by default TAGS: [infra, node, node_firewall]
node : Backup existing repos TAGS: [infra, node, node_repo]
node : Install upstream repo TAGS: [infra, node, node_repo]
node : Install local repo TAGS: [infra, node, node_repo]
node : Install node basic packages TAGS: [infra, node, node_pkgs]
node : Install node extra packages TAGS: [infra, node, node_pkgs]
node : Install meta specific packages TAGS: [infra, node, node_pkgs]
node : Install node basic packages TAGS: [infra, node, node_pkgs]
node : Install node extra packages TAGS: [infra, node, node_pkgs]
node : Install meta specific packages TAGS: [infra, node, node_pkgs]
node : Node configure disable numa TAGS: [infra, node, node_feature]
node : Node configure disable swap TAGS: [infra, node, node_feature]
node : Node configure unmount swap TAGS: [infra, node, node_feature]
node : Node setup static network TAGS: [infra, node, node_feature]
node : Node configure disable firewall TAGS: [infra, node, node_feature]
node : Node configure disk prefetch TAGS: [infra, node, node_feature]
node : Enable linux kernel modules TAGS: [infra, node, node_kernel]
node : Enable kernel module on reboot TAGS: [infra, node, node_kernel]
node : Get config parameter page count TAGS: [infra, node, node_tuned]
node : Get config parameter page size TAGS: [infra, node, node_tuned]
node : Tune shmmax and shmall via mem TAGS: [infra, node, node_tuned]
node : Create tuned profiles TAGS: [infra, node, node_tuned]
node : Render tuned profiles TAGS: [infra, node, node_tuned]
node : Active tuned profile TAGS: [infra, node, node_tuned]
node : Change additional sysctl params TAGS: [infra, node, node_tuned]
node : Copy default user bash profile TAGS: [infra, node, node_profile]
node : Setup node default pam ulimits TAGS: [infra, node, node_ulimit]
node : Create os user group admin TAGS: [infra, node, node_admin]
node : Create os user admin TAGS: [infra, node, node_admin]
node : Grant admin group nopass sudo TAGS: [infra, node, node_admin]
node : Add no host checking to ssh config TAGS: [infra, node, node_admin]
node : Add admin ssh no host checking TAGS: [infra, node, node_admin]
node : Fetch all admin public keys TAGS: [infra, node, node_admin]
node : Exchange all admin ssh keys TAGS: [infra, node, node_admin]
node : Install public keys TAGS: [infra, node, node_admin]
node : Install ntp package TAGS: [infra, node, ntp_install]
node : Install chrony package TAGS: [infra, node, ntp_install]
node : Setup default node timezone TAGS: [infra, node, ntp_config]
node : Copy the ntp.conf file TAGS: [infra, node, ntp_config]
node : Copy the chrony.conf template TAGS: [infra, node, ntp_config]
node : Launch ntpd service TAGS: [infra, node, ntp_launch]
node : Launch chronyd service TAGS: [infra, node, ntp_launch]
consul : Check for existing consul TAGS: [consul_check, dcs, infra]
consul : Consul exists flag fact set TAGS: [consul_check, dcs, infra]
consul : Abort due to consul exists TAGS: [consul_check, dcs, infra]
consul : Clean existing consul instance TAGS: [consul_clean, dcs, infra]
consul : Stop any running consul instance TAGS: [consul_clean, dcs, infra]
consul : Remove existing consul dir TAGS: [consul_clean, dcs, infra]
consul : Recreate consul dir TAGS: [consul_clean, dcs, infra]
consul : Make sure consul is installed TAGS: [consul_install, dcs, infra]
consul : Make sure consul dir exists TAGS: [consul_config, dcs, infra]
consul : Get dcs server node names TAGS: [consul_config, dcs, infra]
consul : Get dcs node name from var TAGS: [consul_config, dcs, infra]
consul : Get dcs node name from var TAGS: [consul_config, dcs, infra]
consul : Fetch hostname as dcs node name TAGS: [consul_config, dcs, infra]
consul : Get dcs name from hostname TAGS: [consul_config, dcs, infra]
consul : Copy /etc/consul.d/consul.json TAGS: [consul_config, dcs, infra]
consul : Copy consul agent service TAGS: [consul_config, dcs, infra]
consul : Get dcs bootstrap expect quroum TAGS: [consul_server, dcs, infra]
consul : Copy consul server service unit TAGS: [consul_server, dcs, infra]
consul : Launch consul server service TAGS: [consul_server, dcs, infra]
consul : Wait for consul server online TAGS: [consul_server, dcs, infra]
consul : Launch consul agent service TAGS: [consul_agent, dcs, infra]
consul : Wait for consul agent online TAGS: [consul_agent, dcs, infra]
postgres : Create os group postgres TAGS: [instal, pg_dbsu, pgsql, postgres]
postgres : Make sure dcs group exists TAGS: [instal, pg_dbsu, pgsql, postgres]
postgres : Create dbsu {{ pg_dbsu }} TAGS: [instal, pg_dbsu, pgsql, postgres]
postgres : Grant dbsu nopass sudo TAGS: [instal, pg_dbsu, pgsql, postgres]
postgres : Grant dbsu all sudo TAGS: [instal, pg_dbsu, pgsql, postgres]
postgres : Grant dbsu limited sudo TAGS: [instal, pg_dbsu, pgsql, postgres]
postgres : Config patroni watchdog support TAGS: [instal, pg_dbsu, pgsql, postgres]
postgres : Add dbsu ssh no host checking TAGS: [instal, pg_dbsu, pgsql, postgres]
postgres : Fetch dbsu public keys TAGS: [instal, pg_dbsu, pgsql, postgres]
postgres : Exchange dbsu ssh keys TAGS: [instal, pg_dbsu, pgsql, postgres]
postgres : Install offical pgdg yum repo TAGS: [instal, pg_install, pgsql, postgres]
postgres : Install pg packages TAGS: [instal, pg_install, pgsql, postgres]
postgres : Install pg extensions TAGS: [instal, pg_install, pgsql, postgres]
postgres : Link /usr/pgsql to current version TAGS: [instal, pg_install, pgsql, postgres]
postgres : Add pg bin dir to profile path TAGS: [instal, pg_install, pgsql, postgres]
postgres : Fix directory ownership TAGS: [instal, pg_install, pgsql, postgres]
postgres : Remove default postgres service TAGS: [instal, pg_install, pgsql, postgres]
postgres : Check necessary variables exists TAGS: [always, pg_preflight, pgsql, postgres, preflight]
postgres : Fetch variables via pg_cluster TAGS: [always, pg_preflight, pgsql, postgres, preflight]
postgres : Set cluster basic facts for hosts TAGS: [always, pg_preflight, pgsql, postgres, preflight]
postgres : Assert cluster primary singleton TAGS: [always, pg_preflight, pgsql, postgres, preflight]
postgres : Setup cluster primary ip address TAGS: [always, pg_preflight, pgsql, postgres, preflight]
postgres : Setup repl upstream for primary TAGS: [always, pg_preflight, pgsql, postgres, preflight]
postgres : Setup repl upstream for replicas TAGS: [always, pg_preflight, pgsql, postgres, preflight]
postgres : Debug print instance summary TAGS: [always, pg_preflight, pgsql, postgres, preflight]
postgres : Check for existing postgres instance TAGS: [pg_check, pgsql, postgres, prepare]
postgres : Set fact whether pg port is open TAGS: [pg_check, pgsql, postgres, prepare]
postgres : Abort due to existing postgres instance TAGS: [pg_check, pgsql, postgres, prepare]
postgres : Clean existing postgres instance TAGS: [pg_check, pgsql, postgres, prepare]
postgres : Shutdown existing postgres service TAGS: [pg_clean, pgsql, postgres, prepare]
postgres : Remove registerd consul service TAGS: [pg_clean, pgsql, postgres, prepare]
postgres : Remove postgres metadata in consul TAGS: [pg_clean, pgsql, postgres, prepare]
postgres : Remove existing postgres data TAGS: [pg_clean, pgsql, postgres, prepare]
postgres : Make sure main and backup dir exists TAGS: [pg_dir, pgsql, postgres, prepare]
postgres : Create postgres directory structure TAGS: [pg_dir, pgsql, postgres, prepare]
postgres : Create pgbouncer directory structure TAGS: [pg_dir, pgsql, postgres, prepare]
postgres : Create links from pgbkup to pgroot TAGS: [pg_dir, pgsql, postgres, prepare]
postgres : Create links from current cluster TAGS: [pg_dir, pgsql, postgres, prepare]
postgres : Copy pg_cluster to /pg/meta/cluster TAGS: [pg_meta, pgsql, postgres, prepare]
postgres : Copy pg_version to /pg/meta/version TAGS: [pg_meta, pgsql, postgres, prepare]
postgres : Copy pg_instance to /pg/meta/instance TAGS: [pg_meta, pgsql, postgres, prepare]
postgres : Copy pg_seq to /pg/meta/sequence TAGS: [pg_meta, pgsql, postgres, prepare]
postgres : Copy pg_role to /pg/meta/role TAGS: [pg_meta, pgsql, postgres, prepare]
postgres : Copy postgres scripts to /pg/bin/ TAGS: [pg_scripts, pgsql, postgres, prepare]
postgres : Copy alias profile to /etc/profile.d TAGS: [pg_scripts, pgsql, postgres, prepare]
postgres : Copy psqlrc to postgres home TAGS: [pg_scripts, pgsql, postgres, prepare]
postgres : Setup hostname to pg instance name TAGS: [pg_hostname, pgsql, postgres, prepare]
postgres : Copy consul node-meta definition TAGS: [pg_nodemeta, pgsql, postgres, prepare]
postgres : Restart consul to load new node-meta TAGS: [pg_nodemeta, pgsql, postgres, prepare]
postgres : Config patroni watchdog support TAGS: [pg_watchdog, pgsql, postgres, prepare]
postgres : Get config parameter page count TAGS: [pg_config, pgsql, postgres]
postgres : Get config parameter page size TAGS: [pg_config, pgsql, postgres]
postgres : Tune shared buffer and work mem TAGS: [pg_config, pgsql, postgres]
postgres : Hanlde small size mem occasion TAGS: [pg_config, pgsql, postgres]
postgres : Calculate postgres mem params TAGS: [pg_config, pgsql, postgres]
postgres : create patroni config dir TAGS: [pg_config, pgsql, postgres]
postgres : use predefined patroni template TAGS: [pg_config, pgsql, postgres]
postgres : Render default /pg/conf/patroni.yml TAGS: [pg_config, pgsql, postgres]
postgres : Link /pg/conf/patroni to /pg/bin/ TAGS: [pg_config, pgsql, postgres]
postgres : Link /pg/bin/patroni.yml to /etc/patroni/ TAGS: [pg_config, pgsql, postgres]
postgres : Config patroni watchdog support TAGS: [pg_config, pgsql, postgres]
postgres : Copy patroni systemd service file TAGS: [pg_config, pgsql, postgres]
postgres : create patroni systemd drop-in dir TAGS: [pg_config, pgsql, postgres]
postgres : Copy postgres systemd service file TAGS: [pg_config, pgsql, postgres]
postgres : Drop-In consul dependency for patroni TAGS: [pg_config, pgsql, postgres]
postgres : Render default initdb scripts TAGS: [pg_config, pgsql, postgres]
postgres : Launch patroni on primary instance TAGS: [pg_primary, pgsql, postgres]
postgres : Wait for patroni primary online TAGS: [pg_primary, pgsql, postgres]
postgres : Wait for postgres primary online TAGS: [pg_primary, pgsql, postgres]
postgres : Check primary postgres service ready TAGS: [pg_primary, pgsql, postgres]
postgres : Check replication connectivity to primary TAGS: [pg_primary, pgsql, postgres]
postgres : Render init roles sql TAGS: [pg_init, pg_init_role, pgsql, postgres]
postgres : Render init template sql TAGS: [pg_init, pg_init_tmpl, pgsql, postgres]
postgres : Render default pg-init scripts TAGS: [pg_init, pg_init_main, pgsql, postgres]
postgres : Execute initialization scripts TAGS: [pg_init, pg_init_exec, pgsql, postgres]
postgres : Check primary instance ready TAGS: [pg_init, pg_init_exec, pgsql, postgres]
postgres : Add dbsu password to pgpass if exists TAGS: [pg_pass, pgsql, postgres]
postgres : Add system user to pgpass TAGS: [pg_pass, pgsql, postgres]
postgres : Check replication connectivity to primary TAGS: [pg_replica, pgsql, postgres]
postgres : Launch patroni on replica instances TAGS: [pg_replica, pgsql, postgres]
postgres : Wait for patroni replica online TAGS: [pg_replica, pgsql, postgres]
postgres : Wait for postgres replica online TAGS: [pg_replica, pgsql, postgres]
postgres : Check replica postgres service ready TAGS: [pg_replica, pgsql, postgres]
postgres : Render hba rules TAGS: [pg_hba, pgsql, postgres]
postgres : Reload hba rules TAGS: [pg_hba, pgsql, postgres]
postgres : Pause patroni TAGS: [pg_patroni, pgsql, postgres]
postgres : Stop patroni on replica instance TAGS: [pg_patroni, pgsql, postgres]
postgres : Stop patroni on primary instance TAGS: [pg_patroni, pgsql, postgres]
postgres : Launch raw postgres on primary TAGS: [pg_patroni, pgsql, postgres]
postgres : Launch raw postgres on primary TAGS: [pg_patroni, pgsql, postgres]
postgres : Wait for postgres online TAGS: [pg_patroni, pgsql, postgres]
postgres : Check pgbouncer is installed TAGS: [pgbouncer, pgbouncer_check, pgsql, postgres]
postgres : Stop existing pgbouncer service TAGS: [pgbouncer, pgbouncer_clean, pgsql, postgres]
postgres : Remove existing pgbouncer dirs TAGS: [pgbouncer, pgbouncer_clean, pgsql, postgres]
postgres : Recreate dirs with owner postgres TAGS: [pgbouncer, pgbouncer_clean, pgsql, postgres]
postgres : Copy /etc/pgbouncer/pgbouncer.ini TAGS: [pgbouncer, pgbouncer_config, pgbouncer_ini, pgsql, postgres]
postgres : Copy /etc/pgbouncer/pgb_hba.conf TAGS: [pgbouncer, pgbouncer_config, pgbouncer_hba, pgsql, postgres]
postgres : Touch userlist and database list TAGS: [pgbouncer, pgbouncer_config, pgsql, postgres]
postgres : Add default users to pgbouncer TAGS: [pgbouncer, pgbouncer_config, pgsql, postgres]
postgres : Copy pgbouncer systemd service TAGS: [pgbouncer, pgbouncer_launch, pgsql, postgres]
postgres : Launch pgbouncer pool service TAGS: [pgbouncer, pgbouncer_launch, pgsql, postgres]
postgres : Wait for pgbouncer service online TAGS: [pgbouncer, pgbouncer_launch, pgsql, postgres]
postgres : Check pgbouncer service is ready TAGS: [pgbouncer, pgbouncer_launch, pgsql, postgres]
include_tasks TAGS: [pg_user, pgsql, postgres]
include_tasks TAGS: [pg_db, pgsql, postgres]
postgres : Reload pgbouncer to add db and users TAGS: [pgbouncer_reload, pgsql, postgres]
postgres : Copy pg service definition to consul TAGS: [pg_register, pgsql, postgres, register]
postgres : Reload postgres consul service TAGS: [pg_register, pgsql, postgres, register]
postgres : Render grafana datasource definition TAGS: [pg_grafana, pgsql, postgres, register]
postgres : Register datasource to grafana TAGS: [pg_grafana, pgsql, postgres, register]
monitor : Install exporter yum repo TAGS: [exporter_install, exporter_yum_install, monitor, pgsql]
monitor : Install node_exporter and pg_exporter TAGS: [exporter_install, exporter_yum_install, monitor, pgsql]
monitor : Copy node_exporter binary TAGS: [exporter_binary_install, exporter_install, monitor, pgsql]
monitor : Copy pg_exporter binary TAGS: [exporter_binary_install, exporter_install, monitor, pgsql]
monitor : Create /etc/pg_exporter conf dir TAGS: [monitor, pg_exporter, pgsql]
monitor : Copy default pg_exporter.yaml TAGS: [monitor, pg_exporter, pgsql]
monitor : Config /etc/default/pg_exporter TAGS: [monitor, pg_exporter, pgsql]
monitor : Config pg_exporter service unit TAGS: [monitor, pg_exporter, pgsql]
monitor : Launch pg_exporter systemd service TAGS: [monitor, pg_exporter, pgsql]
monitor : Wait for pg_exporter service online TAGS: [monitor, pg_exporter, pgsql]
monitor : Register pg-exporter consul service TAGS: [monitor, pg_exporter_register, pgsql]
monitor : Reload pg-exporter consul service TAGS: [monitor, pg_exporter_register, pgsql]
monitor : Config pgbouncer_exporter opts TAGS: [monitor, pgbouncer_exporter, pgsql]
monitor : Config pgbouncer_exporter service TAGS: [monitor, pgbouncer_exporter, pgsql]
monitor : Launch pgbouncer_exporter service TAGS: [monitor, pgbouncer_exporter, pgsql]
monitor : Wait for pgbouncer_exporter online TAGS: [monitor, pgbouncer_exporter, pgsql]
monitor : Register pgb-exporter consul service TAGS: [monitor, node_exporter_register, pgsql]
monitor : Reload pgb-exporter consul service TAGS: [monitor, node_exporter_register, pgsql]
monitor : Copy node_exporter systemd service TAGS: [monitor, node_exporter, pgsql]
monitor : Config default node_exporter options TAGS: [monitor, node_exporter, pgsql]
monitor : Launch node_exporter service unit TAGS: [monitor, node_exporter, pgsql]
monitor : Wait for node_exporter online TAGS: [monitor, node_exporter, pgsql]
monitor : Register node-exporter service to consul TAGS: [monitor, node_exporter_register, pgsql]
monitor : Reload node-exporter consul service TAGS: [monitor, node_exporter_register, pgsql]
service : Make sure haproxy is installed TAGS: [haproxy_install, service]
service : Create haproxy directory TAGS: [haproxy_install, service]
service : Copy haproxy systemd service file TAGS: [haproxy_install, haproxy_unit, service]
service : Fetch postgres cluster memberships TAGS: [haproxy_config, service]
service : Templating /etc/haproxy/haproxy.cfg TAGS: [haproxy_config, service]
service : Launch haproxy load balancer service TAGS: [haproxy_launch, haproxy_restart, service]
service : Wait for haproxy load balancer online TAGS: [haproxy_launch, service]
service : Reload haproxy load balancer service TAGS: [haproxy_reload, service]
service : Copy haproxy exporter definition TAGS: [haproxy_register, service]
service : Copy haproxy service definition TAGS: [haproxy_register, service]
service : Reload haproxy consul service TAGS: [haproxy_register, service]
service : Make sure vip-manager is installed TAGS: [service, vip_l2_install]
service : Copy vip-manager systemd service file TAGS: [service, vip_l2_install]
service : create vip-manager systemd drop-in dir TAGS: [service, vip_l2_install]
service : create vip-manager systemd drop-in file TAGS: [service, vip_l2_install]
service : Templating /etc/default/vip-manager.yml TAGS: [service, vip_l2_config, vip_manager_config]
service : Launch vip-manager TAGS: [service, vip_l2_reload]
service : Fetch postgres cluster memberships TAGS: [service, vip_l4_config]
service : Render L4 VIP configs TAGS: [service, vip_l4_config]
include_tasks TAGS: [service, vip_l4_reload]

5.3.3 - Sandbox Provision
How to perform one-pass bootstrap for sandbox?
The regular initialization process needs to complete the initialization of the meta-node/infrastructure first, and then the initialization of the other database nodes.
To speed up the initialization of the sandbox environment, Pigsty provides a sandbox-specific initialization script sandbox.yml, which can be used in an interleaved manner to complete the initialization of both the infrastructure meta nodes and normal nodes at once using an interleaved approach. This initialization method is fast, but is not recommended for production environments.
Script overview
Users can directly call sandbox.yml or complete the one-click initialization of the sandbox environment via the ``make init`' shortcut.

Cautions
The specific notes for sandbox initialization are the same as infrastructure deployment and PG cluster deployment.
script description
sandbox.yml will be [infra.yml](https://github.com/Vonng/pigsty/blob/master/ infra.yml) and pgsql.yml work interwoven together as follows.
#------------------------------------------------------------------------------
# init local yum repo on meta node
#------------------------------------------------------------------------------
- name: Init local repo
become: yes
hosts: meta
gather_facts: no
tags: repo
roles:
- repo
#------------------------------------------------------------------------------
# provision all nodes
#------------------------------------------------------------------------------
# node provision depends on existing repo on meta node
- name: Provision Node
become: yes
hosts: all
gather_facts: no
tags: node
roles:
- node
#------------------------------------------------------------------------------
# init meta service on meta node
#------------------------------------------------------------------------------
# meta provision depends on node provision. You'll have to provision node on meta node
# then provision meta infrastructure on meta node
- name: Init meta service
become: yes
hosts: meta
gather_facts: no
tags: meta
roles:
- role: ca
tags: ca
- role: nameserver
tags: nameserver
- role: nginx
tags: nginx
- role: prometheus
tags: prometheus
- role: grafana
tags: grafana
#------------------------------------------------------------------------------
# init dcs on nodes
#------------------------------------------------------------------------------
# typically you'll have to bootstrap dcs on meta node first (or use external dcs)
# but pigsty allows you to setup server and agent at the same time.
- name: Init dcs
become: yes
hosts: all # provision all nodes or just meta nodes
gather_facts: no
roles:
- role: consul
tags: dcs
#------------------------------------------------------------------------------
# create or recreate postgres database clusters
#------------------------------------------------------------------------------
- name: Init database cluster
become: yes
hosts: all
gather_facts: false
roles:
- role: postgres # init postgres
tags: postgres
- role: monitor # init monitor system
tags: monitor
- role: haproxy # init haproxy
tags: haproxy
- role: vip # init vip-manager
tags: vip
默认任务
使用以下命令可以列出所有沙箱初始化会执行的任务,以及可以使用的标签:
./sandbox.yml --list-tasks
任务列表如下:
playbook: ./sandbox.yml
play #1 (meta): Init local repo TAGS: [repo]
tasks:
repo : Create local repo directory TAGS: [repo, repo_dir]
repo : Backup & remove existing repos TAGS: [repo, repo_upstream]
repo : Add required upstream repos TAGS: [repo, repo_upstream]
repo : Check repo pkgs cache exists TAGS: [repo, repo_prepare]
repo : Set fact whether repo_exists TAGS: [repo, repo_prepare]
repo : Move upstream repo to backup TAGS: [repo, repo_prepare]
repo : Add local file system repos TAGS: [repo, repo_prepare]
repo : Remake yum cache if not exists TAGS: [repo, repo_prepare]
repo : Install repo bootstrap packages TAGS: [repo, repo_boot]
repo : Render repo nginx server files TAGS: [repo, repo_nginx]
repo : Disable selinux for repo server TAGS: [repo, repo_nginx]
repo : Launch repo nginx server TAGS: [repo, repo_nginx]
repo : Waits repo server online TAGS: [repo, repo_nginx]
repo : Download web url packages TAGS: [repo, repo_download]
repo : Download repo packages TAGS: [repo, repo_download]
repo : Download repo pkg deps TAGS: [repo, repo_download]
repo : Create local repo index TAGS: [repo, repo_download]
repo : Copy bootstrap scripts TAGS: [repo, repo_download, repo_script]
repo : Mark repo cache as valid TAGS: [repo, repo_download]
play #2 (all): Provision Node TAGS: [node]
tasks:
node : Update node hostname TAGS: [node, node_name]
node : Add new hostname to /etc/hosts TAGS: [node, node_name]
node : Write static dns records TAGS: [node, node_dns]
node : Get old nameservers TAGS: [node, node_resolv]
node : Truncate resolv file TAGS: [node, node_resolv]
node : Write resolv options TAGS: [node, node_resolv]
node : Add new nameservers TAGS: [node, node_resolv]
node : Append old nameservers TAGS: [node, node_resolv]
node : Node configure disable firewall TAGS: [node, node_firewall]
node : Node disable selinux by default TAGS: [node, node_firewall]
node : Backup existing repos TAGS: [node, node_repo]
node : Install upstream repo TAGS: [node, node_repo]
node : Install local repo TAGS: [node, node_repo]
node : Install node basic packages TAGS: [node, node_pkgs]
node : Install node extra packages TAGS: [node, node_pkgs]
node : Install meta specific packages TAGS: [node, node_pkgs]
node : Install node basic packages TAGS: [node, node_pkgs]
node : Install node extra packages TAGS: [node, node_pkgs]
node : Install meta specific packages TAGS: [node, node_pkgs]
node : Node configure disable numa TAGS: [node, node_feature]
node : Node configure disable swap TAGS: [node, node_feature]
node : Node configure unmount swap TAGS: [node, node_feature]
node : Node setup static network TAGS: [node, node_feature]
node : Node configure disable firewall TAGS: [node, node_feature]
node : Node configure disk prefetch TAGS: [node, node_feature]
node : Enable linux kernel modules TAGS: [node, node_kernel]
node : Enable kernel module on reboot TAGS: [node, node_kernel]
node : Get config parameter page count TAGS: [node, node_tuned]
node : Get config parameter page size TAGS: [node, node_tuned]
node : Tune shmmax and shmall via mem TAGS: [node, node_tuned]
node : Create tuned profiles TAGS: [node, node_tuned]
node : Render tuned profiles TAGS: [node, node_tuned]
node : Active tuned profile TAGS: [node, node_tuned]
node : Change additional sysctl params TAGS: [node, node_tuned]
node : Copy default user bash profile TAGS: [node, node_profile]
node : Setup node default pam ulimits TAGS: [node, node_ulimit]
node : Create os user group admin TAGS: [node, node_admin]
node : Create os user admin TAGS: [node, node_admin]
node : Grant admin group nopass sudo TAGS: [node, node_admin]
node : Add no host checking to ssh config TAGS: [node, node_admin]
node : Add admin ssh no host checking TAGS: [node, node_admin]
node : Fetch all admin public keys TAGS: [node, node_admin]
node : Exchange all admin ssh keys TAGS: [node, node_admin]
node : Install public keys TAGS: [node, node_admin]
node : Install ntp package TAGS: [node, ntp_install]
node : Install chrony package TAGS: [node, ntp_install]
node : Setup default node timezone TAGS: [node, ntp_config]
node : Copy the ntp.conf file TAGS: [node, ntp_config]
node : Copy the chrony.conf template TAGS: [node, ntp_config]
node : Launch ntpd service TAGS: [node, ntp_launch]
node : Launch chronyd service TAGS: [node, ntp_launch]
play #3 (meta): Init meta service TAGS: [meta]
tasks:
ca : Create local ca directory TAGS: [ca, ca_dir, meta]
ca : Copy ca cert from local files TAGS: [ca, ca_copy, meta]
ca : Check ca key cert exists TAGS: [ca, ca_create, meta]
ca : Create self-signed CA key-cert TAGS: [ca, ca_create, meta]
nameserver : Make sure dnsmasq package installed TAGS: [meta, nameserver]
nameserver : Copy dnsmasq /etc/dnsmasq.d/config TAGS: [meta, nameserver]
nameserver : Add dynamic dns records to meta TAGS: [meta, nameserver]
nameserver : Launch meta dnsmasq service TAGS: [meta, nameserver]
nameserver : Wait for meta dnsmasq online TAGS: [meta, nameserver]
nameserver : Register consul dnsmasq service TAGS: [meta, nameserver]
nameserver : Reload consul TAGS: [meta, nameserver]
nginx : Make sure nginx package installed TAGS: [meta, nginx, nginx_install]
nginx : Create local html directory TAGS: [meta, nginx, nginx_dir]
nginx : Update default nginx index page TAGS: [meta, nginx, nginx_dir]
nginx : Copy nginx default config TAGS: [meta, nginx, nginx_config]
nginx : Copy nginx upstream conf TAGS: [meta, nginx, nginx_config]
nginx : Fetch haproxy facts TAGS: [meta, nginx, nginx_config, nginx_haproxy]
nginx : Templating /etc/nginx/haproxy.conf TAGS: [meta, nginx, nginx_config, nginx_haproxy]
nginx : Templating haproxy.html TAGS: [meta, nginx, nginx_config, nginx_haproxy]
nginx : Launch nginx server TAGS: [meta, nginx, nginx_reload]
nginx : Restart meta nginx service TAGS: [meta, nginx, nginx_launch]
nginx : Wait for nginx service online TAGS: [meta, nginx, nginx_launch]
nginx : Make sure nginx exporter installed TAGS: [meta, nginx, nginx_exporter]
nginx : Config nginx_exporter options TAGS: [meta, nginx, nginx_exporter]
nginx : Restart nginx_exporter service TAGS: [meta, nginx, nginx_exporter]
nginx : Wait for nginx exporter online TAGS: [meta, nginx, nginx_exporter]
nginx : Register cosnul nginx service TAGS: [meta, nginx, nginx_register]
nginx : Register consul nginx-exporter service TAGS: [meta, nginx, nginx_register]
nginx : Reload consul TAGS: [meta, nginx, nginx_register]
prometheus : Install prometheus and alertmanager TAGS: [meta, prometheus, prometheus_install]
prometheus : Wipe out prometheus config dir TAGS: [meta, prometheus, prometheus_clean]
prometheus : Wipe out existing prometheus data TAGS: [meta, prometheus, prometheus_clean]
prometheus : Create postgres directory structure TAGS: [meta, prometheus, prometheus_config]
prometheus : Copy prometheus bin scripts TAGS: [meta, prometheus, prometheus_config]
prometheus : Copy prometheus rules scripts TAGS: [meta, prometheus, prometheus_config]
prometheus : Copy altermanager config TAGS: [meta, prometheus, prometheus_config]
prometheus : Render prometheus config TAGS: [meta, prometheus, prometheus_config]
prometheus : Config /etc/prometheus opts TAGS: [meta, prometheus, prometheus_config]
prometheus : Fetch prometheus static monitoring targets TAGS: [meta, prometheus, prometheus_config, prometheus_targets]
prometheus : Render prometheus static targets TAGS: [meta, prometheus, prometheus_config, prometheus_targets]
prometheus : Launch prometheus service TAGS: [meta, prometheus, prometheus_launch]
prometheus : Launch alertmanager service TAGS: [meta, prometheus, prometheus_launch]
prometheus : Wait for prometheus online TAGS: [meta, prometheus, prometheus_launch]
prometheus : Wait for alertmanager online TAGS: [meta, prometheus, prometheus_launch]
prometheus : Reload prometheus service TAGS: [meta, prometheus, prometheus_reload]
prometheus : Copy prometheus service definition TAGS: [meta, prometheus, prometheus_register]
prometheus : Copy alertmanager service definition TAGS: [meta, prometheus, prometheus_register]
prometheus : Reload consul to register prometheus TAGS: [meta, prometheus, prometheus_register]
grafana : Make sure grafana is installed TAGS: [grafana, grafana_install, meta]
grafana : Check grafana plugin cache exists TAGS: [grafana, grafana_plugin, meta]
grafana : Provision grafana plugins via cache TAGS: [grafana, grafana_plugin, meta]
grafana : Download grafana plugins from web TAGS: [grafana, grafana_plugin, meta]
grafana : Download grafana plugins from web TAGS: [grafana, grafana_plugin, meta]
grafana : Create grafana plugins cache TAGS: [grafana, grafana_plugin, meta]
grafana : Copy /etc/grafana/grafana.ini TAGS: [grafana, grafana_config, meta]
grafana : Remove grafana provision dir TAGS: [grafana, grafana_config, meta]
grafana : Copy provisioning content TAGS: [grafana, grafana_config, meta]
grafana : Copy pigsty dashboards TAGS: [grafana, grafana_config, meta]
grafana : Copy pigsty icon image TAGS: [grafana, grafana_config, meta]
grafana : Replace grafana icon with pigsty TAGS: [grafana, grafana_config, grafana_customize, meta]
grafana : Launch grafana service TAGS: [grafana, grafana_launch, meta]
grafana : Wait for grafana online TAGS: [grafana, grafana_launch, meta]
grafana : Update grafana default preferences TAGS: [grafana, grafana_provision, meta]
grafana : Register consul grafana service TAGS: [grafana, grafana_register, meta]
grafana : Reload consul TAGS: [grafana, grafana_register, meta]
play #4 (all): Init dcs TAGS: []
tasks:
consul : Check for existing consul TAGS: [consul_check, dcs]
consul : Consul exists flag fact set TAGS: [consul_check, dcs]
consul : Abort due to consul exists TAGS: [consul_check, dcs]
consul : Clean existing consul instance TAGS: [consul_clean, dcs]
consul : Stop any running consul instance TAGS: [consul_clean, dcs]
consul : Remove existing consul dir TAGS: [consul_clean, dcs]
consul : Recreate consul dir TAGS: [consul_clean, dcs]
consul : Make sure consul is installed TAGS: [consul_install, dcs]
consul : Make sure consul dir exists TAGS: [consul_config, dcs]
consul : Get dcs server node names TAGS: [consul_config, dcs]
consul : Get dcs node name from var TAGS: [consul_config, dcs]
consul : Get dcs node name from var TAGS: [consul_config, dcs]
consul : Fetch hostname as dcs node name TAGS: [consul_config, dcs]
consul : Get dcs name from hostname TAGS: [consul_config, dcs]
consul : Copy /etc/consul.d/consul.json TAGS: [consul_config, dcs]
consul : Copy consul agent service TAGS: [consul_config, dcs]
consul : Get dcs bootstrap expect quroum TAGS: [consul_server, dcs]
consul : Copy consul server service unit TAGS: [consul_server, dcs]
consul : Launch consul server service TAGS: [consul_server, dcs]
consul : Wait for consul server online TAGS: [consul_server, dcs]
consul : Launch consul agent service TAGS: [consul_agent, dcs]
consul : Wait for consul agent online TAGS: [consul_agent, dcs]
play #5 (all): Init database cluster TAGS: []
tasks:
postgres : Create os group postgres TAGS: [instal, pg_dbsu, postgres]
postgres : Make sure dcs group exists TAGS: [instal, pg_dbsu, postgres]
postgres : Create dbsu {{ pg_dbsu }} TAGS: [instal, pg_dbsu, postgres]
postgres : Grant dbsu nopass sudo TAGS: [instal, pg_dbsu, postgres]
postgres : Grant dbsu all sudo TAGS: [instal, pg_dbsu, postgres]
postgres : Grant dbsu limited sudo TAGS: [instal, pg_dbsu, postgres]
postgres : Config patroni watchdog support TAGS: [instal, pg_dbsu, postgres]
postgres : Add dbsu ssh no host checking TAGS: [instal, pg_dbsu, postgres]
postgres : Fetch dbsu public keys TAGS: [instal, pg_dbsu, postgres]
postgres : Exchange dbsu ssh keys TAGS: [instal, pg_dbsu, postgres]
postgres : Install offical pgdg yum repo TAGS: [instal, pg_install, postgres]
postgres : Install pg packages TAGS: [instal, pg_install, postgres]
postgres : Install pg extensions TAGS: [instal, pg_install, postgres]
postgres : Link /usr/pgsql to current version TAGS: [instal, pg_install, postgres]
postgres : Add pg bin dir to profile path TAGS: [instal, pg_install, postgres]
postgres : Fix directory ownership TAGS: [instal, pg_install, postgres]
postgres : Remove default postgres service TAGS: [instal, pg_install, postgres]
postgres : Check necessary variables exists TAGS: [always, pg_preflight, postgres, preflight]
postgres : Fetch variables via pg_cluster TAGS: [always, pg_preflight, postgres, preflight]
postgres : Set cluster basic facts for hosts TAGS: [always, pg_preflight, postgres, preflight]
postgres : Assert cluster primary singleton TAGS: [always, pg_preflight, postgres, preflight]
postgres : Setup cluster primary ip address TAGS: [always, pg_preflight, postgres, preflight]
postgres : Setup repl upstream for primary TAGS: [always, pg_preflight, postgres, preflight]
postgres : Setup repl upstream for replicas TAGS: [always, pg_preflight, postgres, preflight]
postgres : Debug print instance summary TAGS: [always, pg_preflight, postgres, preflight]
postgres : Check for existing postgres instance TAGS: [pg_check, postgres, prepare]
postgres : Set fact whether pg port is open TAGS: [pg_check, postgres, prepare]
postgres : Abort due to existing postgres instance TAGS: [pg_check, postgres, prepare]
postgres : Clean existing postgres instance TAGS: [pg_check, postgres, prepare]
postgres : Shutdown existing postgres service TAGS: [pg_clean, postgres, prepare]
postgres : Remove registerd consul service TAGS: [pg_clean, postgres, prepare]
postgres : Remove postgres metadata in consul TAGS: [pg_clean, postgres, prepare]
postgres : Remove existing postgres data TAGS: [pg_clean, postgres, prepare]
postgres : Make sure main and backup dir exists TAGS: [pg_dir, postgres, prepare]
postgres : Create postgres directory structure TAGS: [pg_dir, postgres, prepare]
postgres : Create pgbouncer directory structure TAGS: [pg_dir, postgres, prepare]
postgres : Create links from pgbkup to pgroot TAGS: [pg_dir, postgres, prepare]
postgres : Create links from current cluster TAGS: [pg_dir, postgres, prepare]
postgres : Copy pg_cluster to /pg/meta/cluster TAGS: [pg_meta, postgres, prepare]
postgres : Copy pg_version to /pg/meta/version TAGS: [pg_meta, postgres, prepare]
postgres : Copy pg_instance to /pg/meta/instance TAGS: [pg_meta, postgres, prepare]
postgres : Copy pg_seq to /pg/meta/sequence TAGS: [pg_meta, postgres, prepare]
postgres : Copy pg_role to /pg/meta/role TAGS: [pg_meta, postgres, prepare]
postgres : Copy postgres scripts to /pg/bin/ TAGS: [pg_scripts, postgres, prepare]
postgres : Copy alias profile to /etc/profile.d TAGS: [pg_scripts, postgres, prepare]
postgres : Copy psqlrc to postgres home TAGS: [pg_scripts, postgres, prepare]
postgres : Setup hostname to pg instance name TAGS: [pg_hostname, postgres, prepare]
postgres : Copy consul node-meta definition TAGS: [pg_nodemeta, postgres, prepare]
postgres : Restart consul to load new node-meta TAGS: [pg_nodemeta, postgres, prepare]
postgres : Config patroni watchdog support TAGS: [pg_watchdog, postgres, prepare]
postgres : Get config parameter page count TAGS: [pg_config, postgres]
postgres : Get config parameter page size TAGS: [pg_config, postgres]
postgres : Tune shared buffer and work mem TAGS: [pg_config, postgres]
postgres : Hanlde small size mem occasion TAGS: [pg_config, postgres]
postgres : Calculate postgres mem params TAGS: [pg_config, postgres]
postgres : create patroni config dir TAGS: [pg_config, postgres]
postgres : use predefined patroni template TAGS: [pg_config, postgres]
postgres : Render default /pg/conf/patroni.yml TAGS: [pg_config, postgres]
postgres : Link /pg/conf/patroni to /pg/bin/ TAGS: [pg_config, postgres]
postgres : Link /pg/bin/patroni.yml to /etc/patroni/ TAGS: [pg_config, postgres]
postgres : Config patroni watchdog support TAGS: [pg_config, postgres]
postgres : create patroni systemd drop-in dir TAGS: [pg_config, postgres]
postgres : Copy postgres systemd service file TAGS: [pg_config, postgres]
postgres : create patroni systemd drop-in file TAGS: [pg_config, postgres]
postgres : Render default initdb scripts TAGS: [pg_config, postgres]
postgres : Launch patroni on primary instance TAGS: [pg_primary, postgres]
postgres : Wait for patroni primary online TAGS: [pg_primary, postgres]
postgres : Wait for postgres primary online TAGS: [pg_primary, postgres]
postgres : Check primary postgres service ready TAGS: [pg_primary, postgres]
postgres : Check replication connectivity to primary TAGS: [pg_primary, postgres]
postgres : Render default pg-init scripts TAGS: [pg_init, pg_init_config, postgres]
postgres : Render template init script TAGS: [pg_init, pg_init_config, postgres]
postgres : Execute initialization scripts TAGS: [pg_init, postgres]
postgres : Check primary instance ready TAGS: [pg_init, postgres]
postgres : Add dbsu password to pgpass if exists TAGS: [pg_pass, postgres]
postgres : Add system user to pgpass TAGS: [pg_pass, postgres]
postgres : Check replication connectivity to primary TAGS: [pg_replica, postgres]
postgres : Launch patroni on replica instances TAGS: [pg_replica, postgres]
postgres : Wait for patroni replica online TAGS: [pg_replica, postgres]
postgres : Wait for postgres replica online TAGS: [pg_replica, postgres]
postgres : Check replica postgres service ready TAGS: [pg_replica, postgres]
postgres : Render hba rules TAGS: [pg_hba, postgres]
postgres : Reload hba rules TAGS: [pg_hba, postgres]
postgres : Pause patroni TAGS: [pg_patroni, postgres]
postgres : Stop patroni on replica instance TAGS: [pg_patroni, postgres]
postgres : Stop patroni on primary instance TAGS: [pg_patroni, postgres]
postgres : Launch raw postgres on primary TAGS: [pg_patroni, postgres]
postgres : Launch raw postgres on primary TAGS: [pg_patroni, postgres]
postgres : Wait for postgres online TAGS: [pg_patroni, postgres]
postgres : Check pgbouncer is installed TAGS: [pgbouncer, pgbouncer_check, postgres]
postgres : Stop existing pgbouncer service TAGS: [pgbouncer, pgbouncer_clean, postgres]
postgres : Remove existing pgbouncer dirs TAGS: [pgbouncer, pgbouncer_clean, postgres]
postgres : Recreate dirs with owner postgres TAGS: [pgbouncer, pgbouncer_clean, postgres]
postgres : Copy /etc/pgbouncer/pgbouncer.ini TAGS: [pgbouncer, pgbouncer_config, pgbouncer_ini, postgres]
postgres : Copy /etc/pgbouncer/pgb_hba.conf TAGS: [pgbouncer, pgbouncer_config, pgbouncer_hba, postgres]
postgres : Touch userlist and database list TAGS: [pgbouncer, pgbouncer_config, postgres]
postgres : Add default users to pgbouncer TAGS: [pgbouncer, pgbouncer_config, postgres]
postgres : Copy pgbouncer systemd service TAGS: [pgbouncer, pgbouncer_launch, postgres]
postgres : Launch pgbouncer pool service TAGS: [pgbouncer, pgbouncer_launch, postgres]
postgres : Wait for pgbouncer service online TAGS: [pgbouncer, pgbouncer_launch, postgres]
postgres : Check pgbouncer service is ready TAGS: [pgbouncer, pgbouncer_launch, postgres]
postgres : Render business init script TAGS: [business, pg_biz_config, pg_biz_init, postgres]
postgres : Render database baseline sql TAGS: [business, pg_biz_config, pg_biz_init, postgres]
postgres : Execute business init script TAGS: [business, pg_biz_init, postgres]
postgres : Execute database baseline sql TAGS: [business, pg_biz_init, postgres]
postgres : Add pgbouncer busniess users TAGS: [business, pg_biz_pgbouncer, postgres]
postgres : Add pgbouncer busniess database TAGS: [business, pg_biz_pgbouncer, postgres]
postgres : Restart pgbouncer TAGS: [business, pg_biz_pgbouncer, postgres]
postgres : Copy pg service definition to consul TAGS: [pg_register, postgres, register]
postgres : Reload postgres consul service TAGS: [pg_register, postgres, register]
postgres : Render grafana datasource definition TAGS: [pg_grafana, postgres, register]
postgres : Register datasource to grafana TAGS: [pg_grafana, postgres, register]
monitor : Create /etc/pg_exporter conf dir TAGS: [monitor, pg_exporter]
monitor : Copy default pg_exporter.yaml TAGS: [monitor, pg_exporter]
monitor : Config /etc/default/pg_exporter TAGS: [monitor, pg_exporter]
monitor : Copy pg_exporter binary TAGS: [monitor, pg_exporter, pg_exporter_binary]
monitor : Config pg_exporter service unit TAGS: [monitor, pg_exporter]
monitor : Launch pg_exporter systemd service TAGS: [monitor, pg_exporter]
monitor : Wait for pg_exporter service online TAGS: [monitor, pg_exporter]
monitor : Register pg-exporter consul service TAGS: [monitor, pg_exporter_register]
monitor : Reload pg-exporter consul service TAGS: [monitor, pg_exporter_register]
monitor : Config pgbouncer_exporter opts TAGS: [monitor, pgbouncer_exporter]
monitor : Config pgbouncer_exporter service TAGS: [monitor, pgbouncer_exporter]
monitor : Launch pgbouncer_exporter service TAGS: [monitor, pgbouncer_exporter]
monitor : Wait for pgbouncer_exporter online TAGS: [monitor, pgbouncer_exporter]
monitor : Register pgb-exporter consul service TAGS: [monitor, node_exporter_register]
monitor : Reload pgb-exporter consul service TAGS: [monitor, node_exporter_register]
monitor : Copy node_exporter binary TAGS: [monitor, node_exporter, node_exporter_binary]
monitor : Copy node_exporter systemd service TAGS: [monitor, node_exporter]
monitor : Config default node_exporter options TAGS: [monitor, node_exporter]
monitor : Launch node_exporter service unit TAGS: [monitor, node_exporter]
monitor : Wait for node_exporter online TAGS: [monitor, node_exporter]
monitor : Register node-exporter service to consul TAGS: [monitor, node_exporter_register]
monitor : Reload node-exporter consul service TAGS: [monitor, node_exporter_register]
haproxy : Make sure haproxy is installed TAGS: [haproxy, haproxy_install]
haproxy : Create haproxy directory TAGS: [haproxy, haproxy_install]
haproxy : Copy haproxy systemd service file TAGS: [haproxy, haproxy_install, haproxy_unit]
haproxy : Fetch postgres cluster memberships TAGS: [haproxy, haproxy_config]
haproxy : Templating /etc/haproxy/haproxy.cfg TAGS: [haproxy, haproxy_config]
haproxy : Launch haproxy load balancer service TAGS: [haproxy, haproxy_launch, haproxy_restart]
haproxy : Wait for haproxy load balancer online TAGS: [haproxy, haproxy_launch]
haproxy : Reload haproxy load balancer service TAGS: [haproxy, haproxy_reload]
haproxy : Copy haproxy service definition TAGS: [haproxy, haproxy_register]
haproxy : Reload haproxy consul service TAGS: [haproxy, haproxy_register]
vip : Templating /etc/default/vip-manager.yml TAGS: [vip]
vip : create vip-manager. systemd drop-in dir TAGS: [vip]
vip : create vip-manager systemd drop-in file TAGS: [vip]
vip : Launch vip-manager TAGS: [vip]

5.3.4 - Remove Clusters
How to destroy postgres clusters and instances
剧本概览
数据库下线:可以移除现有的数据库集群或实例,回收节点:pgsql-remove.yml

日常管理
./pgsql-remove.yml -l pg-test # 下线在 pg-test 集群
./pgsql-remove.yml -l pg-test -l 10.10.10.13 # 下线在 pg-test 集群中的一个实例
剧本说明
#!/usr/bin/env ansible-playbook
---
#==============================================================#
# File : pgsql-remove.yml
# Mtime : 2020-05-12
# Mtime : 2021-03-15
# Desc : remove postgres & consul services
# Path : pgsql-remove.yml
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
# this playbook aims at removing postgres & consul & related service
# from # existing instances. So that the node can be recycled for
# re-initialize or other database clusters.
#------------------------------------------------------------------------------
# Remove load balancer
#------------------------------------------------------------------------------
- name: Remove load balancer
become: yes
hosts: all
serial: 1
gather_facts: no
tags: rm-lb
tasks:
- name: Stop load balancer
ignore_errors: true
systemd: name={{ item }} state=stopped enabled=no daemon_reload=yes
with_items:
- vip-manager
- haproxy
# - keepalived
#------------------------------------------------------------------------------
# Remove pg monitor
#------------------------------------------------------------------------------
- name: Remove monitor
become: yes
hosts: all
gather_facts: no
tags: rm-monitor
tasks:
- name: Stop monitor service
ignore_errors: true
systemd: name={{ item }} state=stopped enabled=no daemon_reload=yes
with_items:
- pg_exporter
- pgbouncer_exporter
- name: Deregister exporter service
ignore_errors: true
file: path=/etc/consul.d/svc-{{ item }}.json state=absent
with_items:
- haproxy
- pg-exporter
- pgbouncer-exporter
- name: Reload consul
systemd: name=consul state=reloaded
#------------------------------------------------------------------------------
# Remove watchdog owner
#------------------------------------------------------------------------------
- name: Remove monitor
become: yes
hosts: all
gather_facts: no
tags: rm-watchdog
tasks:
# - watchdog owner - #
- name: Remove patroni watchdog ownership
ignore_errors: true
file: path=/dev/watchdog owner=root group=root
#------------------------------------------------------------------------------
# Remove postgres service
#------------------------------------------------------------------------------
- name: Remove Postgres service
become: yes
hosts: all
serial: 1
gather_facts: no
tags: rm-pg
tasks:
- name: Remove postgres replica services
when: pg_role != 'primary'
ignore_errors: true
systemd: name={{ item }} state=stopped enabled=no daemon_reload=yes
with_items:
- patroni
- postgres
- pgbouncer
# if in resume mode, postgres will not be stopped
- name: Force stop postgres non-primary process
become_user: "{{ pg_dbsu }}"
when: pg_role != 'primary'
ignore_errors: true
shell: |
{{ pg_bin_dir }}/pg_ctl -D {{ pg_data }} stop -m immediate
exit 0
- name: Remove postgres primary services
when: pg_role == 'primary'
ignore_errors: true
systemd: name={{ item }} state=stopped enabled=no daemon_reload=yes
with_items:
- patroni
- postgres
- pgbouncer
- name: Force stop postgres primary process
become_user: "{{ pg_dbsu }}"
when: pg_role == 'primary'
ignore_errors: true
shell: |
{{ pg_bin_dir }}/pg_ctl -D {{ pg_data }} stop -m immediate
exit 0
- name: Deregister postgres services
ignore_errors: true
file: path=/etc/consul.d/svc-{{ item }}.json state=absent
with_items:
- postgres
- pgbouncer
- patroni
#------------------------------------------------------------------------------
# Remove postgres service
#------------------------------------------------------------------------------
- name: Remove Infrastructure
become: yes
hosts: all
serial: 1
gather_facts: no
tags: rm-infra
tasks:
- name: Consul leave cluster
ignore_errors: true
command: /usr/bin/consul leave
- name: Stop consul and node_exporter
ignore_errors: true
systemd: name={{ item }} state=stopped enabled=no daemon_reload=yes
with_items:
- node_exporter
- consul
#------------------------------------------------------------------------------
# Uninstall postgres and consul
#------------------------------------------------------------------------------
- name: Uninstall Packages
become: yes
hosts: all
gather_facts: no
tags: rm-pkgs
tasks:
- name: Uninstall postgres and consul
when: yum_remove is defined and yum_remove|bool
shell: |
yum remove -y consul
yum remove -y postgresql{{ pg_version }}*
...
使用样例
./pgsql-remove.yml -l pg-test
执行结果
任务详情
默认任务如下:
playbook: ./pgsql-remove.yml
play #1 (all): Remove load balancer TAGS: [rm-lb]
tasks:
Stop load balancer TAGS: [rm-lb]
play #2 (all): Remove monitor TAGS: [rm-monitor]
tasks:
Stop monitor service TAGS: [rm-monitor]
Deregister exporter service TAGS: [rm-monitor]
Reload consul TAGS: [rm-monitor]
play #3 (all): Remove monitor TAGS: [rm-watchdog]
tasks:
Remove patroni watchdog ownership TAGS: [rm-watchdog]
play #4 (all): Remove Postgres service TAGS: [rm-pg]
tasks:
Remove postgres replica services TAGS: [rm-pg]
Force stop postgres non-primary process TAGS: [rm-pg]
Remove postgres primary services TAGS: [rm-pg]
Force stop postgres primary process TAGS: [rm-pg]
Deregister postgres services TAGS: [rm-pg]
play #5 (all): Remove Infrastructure TAGS: [rm-infra]
tasks:
Consul leave cluster TAGS: [rm-infra]
Stop consul and node_exporter TAGS: [rm-infra]
play #6 (all): Uninstall Packages TAGS: [rm-pkgs]
tasks:
Uninstall postgres and consul TAGS: [rm-pkgs]
5.3.5 - Monitor Only
How to deploy pigsty monitoring system without provisioning solution?
剧本概览
部署监控系统:可以在现有集群中创建新的用户或修改现有用户:pgsql-monitor.yml

日常管理
# 在 pg-test 集群中部署监控
./pgsql-monitor.yml -l pg-test
剧本说明
#!/usr/bin/env ansible-playbook
---
#==============================================================#
# File : pgsql-monitor.yml
# Ctime : 2021-02-23
# Mtime : 2021-02-27
# Desc : deploy monitor components only
# Path : pgsql-monitor.yml
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
# this is pgsql monitor setup playbook for MONITOR ONLY mode
# MONITOR-ONLY (monly) mode is a special deployment mode for
# integration with exterior provisioning solution or existing
# postgres clusters.
# with limited functionalities
# For monly deployment, The infra part is still the same.
# You MUST use static services discovery for prometheus
# You CAN NOT use services_registry
#------------------------------------------------------------------------------
# Deploy monitor on selected targets
#------------------------------------------------------------------------------
- name: Monitor Only Deployment
become: yes
hosts: all
gather_facts: no
tags: monitor
roles:
- role: monitor # init monitor system
vars:
#------------------------------------------------------------------------------
# RECOMMEND CHANGES
#------------------------------------------------------------------------------
# You'd better change those options in your main config file
# prometheus_sd_method: static # MUST use static sd for monitor only mode
service_registry: none # MUST NOT register services
exporter_install: binary # none|yum|binary, none by default
# exporter_install controls how node_exporter & pg_exporter are installed
# none : I've already installed manually
# yum : Use yum install, `exporter_repo_url` will be added if specified
# binary : Copy binary to /usr/bin. You must have binary in your `files` dir
#------------------------------------------------------------------------------
# MONITOR PROVISION
#------------------------------------------------------------------------------
# - install - #
# exporter_install: none # none|yum|binary, none by default
# exporter_repo_url: '' # if set, repo will be added to /etc/yum.repos.d/ before yum installation
# - collect - #
# exporter_metrics_path: /metrics # default metric path for pg related exporter
# - node exporter - #
# node_exporter_enabled: true # setup node_exporter on instance
# node_exporter_port: 9100 # default port for node exporter
# node_exporter_options: '--no-collector.softnet --collector.systemd --collector.ntp --collector.tcpstat --collector.processes'
# - pg exporter - #
# pg_exporter_config: pg_exporter-demo.yaml # default config files for pg_exporter
# pg_exporter_enabled: true # setup pg_exporter on instance
# pg_exporter_port: 9630 # default port for pg exporter
# pg_exporter_url: '' # optional, if not set, generate from reference parameters
# - pgbouncer exporter - #
# pgbouncer exporter require pgbouncer to work, so it is disabled by default in monitor-only mode
# pgbouncer_exporter_enabled: false # setup pgbouncer_exporter on instance (if you don't have pgbouncer, disable it)
# pgbouncer_exporter_port: 9631 # default port for pgbouncer exporter
# pgbouncer_exporter_url: '' # optional, if not set, generate from reference parameters
# - postgres variables reference - #
# pg_dbsu: postgres
# pg_port: 5432 # postgres port (5432 by default)
# pgbouncer_port: 6432 # pgbouncer port (6432 by default)
# pg_localhost: /var/run/postgresql # localhost unix socket dir for connection
# pg_default_database: postgres # default database will be used as primary monitor target
# pg_monitor_username: dbuser_monitor # system monitor username, for postgres and pgbouncer
# pg_monitor_password: DBUser.Monitor # system monitor user's password
# service_registry: consul # none | consul | etcd | both
#------------------------------------------------------------------------------
# update static inventory in meta node and reload
#------------------------------------------------------------------------------
- name: Update prometheus static sd files
become: yes
hosts: meta
tags: prometheus
gather_facts: no
vars:
#------------------------------------------------------------------------------
# RECOMMEND CHANGES
#------------------------------------------------------------------------------
prometheus_sd_method: static # service discovery method: static|consul|etcd
tasks:
- include_tasks: roles/prometheus/tasks/targets.yml
- include_tasks: roles/prometheus/tasks/reload.yml
...
使用样例
./pgsql-monitor.yml -l pg-test
执行结果
$ ./pgsql-monitor.yml -l pg-test -e pg_user=test
[WARNING]: Invalid characters were found in group names but not replaced, use -vvvv to see details
PLAY [Create user in cluster] *****************************************************************************************************************************************************
TASK [Check parameter pg_user] ****************************************************************************************************************************************************
ok: [10.10.10.11] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.12] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.13] => {
"changed": false,
"msg": "All assertions passed"
}
TASK [Fetch user definition] ******************************************************************************************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [debug] **********************************************************************************************************************************************************************
ok: [10.10.10.11] => {
"msg": {
"comment": "default test user for production usage",
"name": "test",
"password": "test",
"pgbouncer": true,
"roles": [
"dbrole_readwrite"
]
}
}
ok: [10.10.10.12] => {
"msg": {
"comment": "default test user for production usage",
"name": "test",
"password": "test",
"pgbouncer": true,
"roles": [
"dbrole_readwrite"
]
}
}
ok: [10.10.10.13] => {
"msg": {
"comment": "default test user for production usage",
"name": "test",
"password": "test",
"pgbouncer": true,
"roles": [
"dbrole_readwrite"
]
}
}
TASK [Check user definition] ******************************************************************************************************************************************************
ok: [10.10.10.11] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.12] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.13] => {
"changed": false,
"msg": "All assertions passed"
}
TASK [include_tasks] **************************************************************************************************************************************************************
included: /Volumes/Data/pigsty/roles/postgres/tasks/monitor.yml for 10.10.10.11, 10.10.10.12, 10.10.10.13
TASK [Render user test creation sql] **********************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.11]
TASK [Execute user test creation sql on primary] **********************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.11]
TASK [Add user to pgbouncer] ******************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [Reload pgbouncer to add user] ***********************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
PLAY RECAP ************************************************************************************************************************************************************************
10.10.10.11 : ok=9 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
10.10.10.12 : ok=7 changed=2 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
10.10.10.13 : ok=7 changed=2 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
任务详情
默认任务如下:
playbook: ./pgsql-monitor.yml
play #1 (all): Monitor Only Deployment TAGS: [monitor]
tasks:
monitor : Install exporter yum repo TAGS: [exporter_install, exporter_yum_install, monitor]
monitor : Install node_exporter and pg_exporter TAGS: [exporter_install, exporter_yum_install, monitor]
monitor : Copy node_exporter binary TAGS: [exporter_binary_install, exporter_install, monitor]
monitor : Copy pg_exporter binary TAGS: [exporter_binary_install, exporter_install, monitor]
monitor : Create /etc/pg_exporter conf dir TAGS: [monitor, pg_exporter]
monitor : Copy default pg_exporter.yaml TAGS: [monitor, pg_exporter]
monitor : Config /etc/default/pg_exporter TAGS: [monitor, pg_exporter]
monitor : Config pg_exporter service unit TAGS: [monitor, pg_exporter]
monitor : Launch pg_exporter systemd service TAGS: [monitor, pg_exporter]
monitor : Wait for pg_exporter service online TAGS: [monitor, pg_exporter]
monitor : Register pg-exporter consul service TAGS: [monitor, pg_exporter_register]
monitor : Reload pg-exporter consul service TAGS: [monitor, pg_exporter_register]
monitor : Config pgbouncer_exporter opts TAGS: [monitor, pgbouncer_exporter]
monitor : Config pgbouncer_exporter service TAGS: [monitor, pgbouncer_exporter]
monitor : Launch pgbouncer_exporter service TAGS: [monitor, pgbouncer_exporter]
monitor : Wait for pgbouncer_exporter online TAGS: [monitor, pgbouncer_exporter]
monitor : Register pgb-exporter consul service TAGS: [monitor, node_exporter_register]
monitor : Reload pgb-exporter consul service TAGS: [monitor, node_exporter_register]
monitor : Copy node_exporter systemd service TAGS: [monitor, node_exporter]
monitor : Config default node_exporter options TAGS: [monitor, node_exporter]
monitor : Launch node_exporter service unit TAGS: [monitor, node_exporter]
monitor : Wait for node_exporter online TAGS: [monitor, node_exporter]
monitor : Register node-exporter service to consul TAGS: [monitor, node_exporter_register]
monitor : Reload node-exporter consul service TAGS: [monitor, node_exporter_register]
play #2 (meta): Update prometheus static sd files TAGS: [prometheus]
tasks:
include_tasks TAGS: [prometheus]
include_tasks TAGS: [prometheus]
5.3.6 - Create User
How to create new users on existing clusters?
剧本概览
创建业务用户:可以在现有集群中创建新的用户或修改现有用户:pgsql-createuser.yml

日常管理
# 在 pg-test 集群创建名为 test 的用户
./pgsql-createuser.yml -l pg-test -e pg_user=test
请注意,pg_user 指定的用户,必须已经存在于集群pg_users的定义中,否则会报错。这意味着用户必须先定义用户,再创建用户。
剧本说明
#!/usr/bin/env ansible-playbook
---
#==============================================================#
# File : pgsql-createuser.yml
# Ctime : 2021-02-27
# Mtime : 2021-02-27
# Desc : create user on running cluster
# Path : pgsql-createuser.yml
# Deps : templates/pg-user.sql
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
#=============================================================================#
# How to create user ?
# 1. define user in your configuration file! <cluster>.vars.pg_usesrs
# 2. execute this playbook with pg_user set to your new user.name
# 3. run playbook on target cluster
# It essentially does:
# 1. create sql file in /pg/tmp/pg-user-{{ user.name }}.sql
# 2. create user on primary instance with that sql
# 3. if {{ user.pgbouncer }}, add to all cluster members and reload
#=============================================================================#
- name: Create user in cluster
become: yes
hosts: all
gather_facts: no
vars:
##################################################################################
# IMPORTANT: Change this or use cli-arg to specify target user in inventory #
##################################################################################
pg_user: test
tasks:
#------------------------------------------------------------------------------
# pre-flight check: validate pg_user and user definition
# ------------------------------------------------------------------------------
- name: Preflight
block:
- name: Check parameter pg_user
connection: local
assert:
that:
- pg_user is defined
- pg_user != ''
- pg_user != 'postgres'
fail_msg: variable 'pg_user' should be specified to create target user
- name: Fetch user definition
connection: local
set_fact:
pg_user_definition={{ pg_users | json_query(pg_user_definition_query) }}
vars:
pg_user_definition_query: "[?name=='{{ pg_user }}'] | [0]"
# print user definition
- debug:
msg: "{{ pg_user_definition }}"
- name: Check user definition
assert:
that:
- pg_user_definition is defined
- pg_user_definition != None
- pg_user_definition != ''
- pg_user_definition != {}
fail_msg: user definition for {{ pg_user }} should exists in pg_users
#------------------------------------------------------------------------------
# Create user on cluster primary and add pgbouncer entry to cluster members
#------------------------------------------------------------------------------
# create user according to user definition
- include_tasks: roles/postgres/tasks/createuser.yml
vars:
user: "{{ pg_user_definition }}"
#------------------------------------------------------------------------------
# Pgbouncer Reload (entire cluster)
#------------------------------------------------------------------------------
- name: Reload pgbouncer to add user
when: pg_user_definition.pgbouncer is defined and pg_user_definition.pgbouncer|bool
tags: pgbouncer_reload
systemd: name=pgbouncer state=reloaded enabled=yes daemon_reload=yes
...
使用样例
./pgsql-createuser.yml -l pg-test -e pg_user=test
执行结果
$ ./pgsql-createuser.yml -l pg-test -e pg_user=test
[WARNING]: Invalid characters were found in group names but not replaced, use -vvvv to see details
PLAY [Create user in cluster] *****************************************************************************************************************************************************
TASK [Check parameter pg_user] ****************************************************************************************************************************************************
ok: [10.10.10.11] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.12] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.13] => {
"changed": false,
"msg": "All assertions passed"
}
TASK [Fetch user definition] ******************************************************************************************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [debug] **********************************************************************************************************************************************************************
ok: [10.10.10.11] => {
"msg": {
"comment": "default test user for production usage",
"name": "test",
"password": "test",
"pgbouncer": true,
"roles": [
"dbrole_readwrite"
]
}
}
ok: [10.10.10.12] => {
"msg": {
"comment": "default test user for production usage",
"name": "test",
"password": "test",
"pgbouncer": true,
"roles": [
"dbrole_readwrite"
]
}
}
ok: [10.10.10.13] => {
"msg": {
"comment": "default test user for production usage",
"name": "test",
"password": "test",
"pgbouncer": true,
"roles": [
"dbrole_readwrite"
]
}
}
TASK [Check user definition] ******************************************************************************************************************************************************
ok: [10.10.10.11] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.12] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.13] => {
"changed": false,
"msg": "All assertions passed"
}
TASK [include_tasks] **************************************************************************************************************************************************************
included: /Volumes/Data/pigsty/roles/postgres/tasks/createuser.yml for 10.10.10.11, 10.10.10.12, 10.10.10.13
TASK [Render user test creation sql] **********************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.11]
TASK [Execute user test creation sql on primary] **********************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.11]
TASK [Add user to pgbouncer] ******************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [Reload pgbouncer to add user] ***********************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
PLAY RECAP ************************************************************************************************************************************************************************
10.10.10.11 : ok=9 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
10.10.10.12 : ok=7 changed=2 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
10.10.10.13 : ok=7 changed=2 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
任务详情
默认任务如下:
playbook: ./pgsql-createuser.yml
play #1 (all): Create user in cluster TAGS: []
tasks:
Check parameter pg_user TAGS: []
Fetch user definition TAGS: []
debug TAGS: []
Check user definition TAGS: []
include_tasks TAGS: []
Reload pgbouncer to add user TAGS: [pgbouncer_reload]
5.3.7 - Create Database
How to create new database on running clusters?
剧本概览
创建业务数据库:可以在现有集群中创建新的数据库或修改现有数据库:pgsql-createdb.yml

日常管理
# 在 pg-test 集群创建名为 test 的数据库
./pgsql-createdb.yml -l pg-test -e pg_database=test
剧本说明
#!/usr/bin/env ansible-playbook
---
#==============================================================#
# File : pgsql-createdb.yml
# Ctime : 2021-02-27
# Mtime : 2021-02-27
# Desc : create database on running cluster
# Deps : templates/pg-db.sql
# Path : pgsql-createdb.yml
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
#=============================================================================#
# How to create database ?
# 1. define database in your configuration file! <cluster>.vars.pg_databases
# 2. execute this playbook with pg_database set to your new database.name
# 3. run playbook on target cluster
# It essentially does:
# 1. create sql file in /pg/tmp/pg-db-{{ database.name }}.sql
# 2. create database on primary instance with that sql
# 3. if {{ database.pgbouncer }}, add to all cluster members and reload
#=============================================================================#
- name: Create Database In Cluster
become: yes
hosts: all
gather_facts: no
vars:
##################################################################################
# IMPORTANT: Change this or use cli-arg to specify target database in inventory #
##################################################################################
pg_database: test
tasks:
#------------------------------------------------------------------------------
# pre-flight check: validate pg_database and database definition
# ------------------------------------------------------------------------------
- name: Preflight
block:
- name: Check parameter pg_database
connection: local
assert:
that:
- pg_database is defined
- pg_database != ''
- pg_database != 'postgres'
fail_msg: variable 'pg_database' should be specified to create target database
- name: Fetch database definition
connection: local
set_fact:
pg_database_definition={{ pg_databases | json_query(pg_database_definition_query) }}
vars:
pg_database_definition_query: "[?name=='{{ pg_database }}'] | [0]"
# print database definition
- debug:
msg: "{{ pg_database_definition }}"
- name: Check database definition
assert:
that:
- pg_database_definition is defined
- pg_database_definition != None
- pg_database_definition != ''
- pg_database_definition != {}
fail_msg: database definition for {{ pg_database }} should exists in pg_databases
#------------------------------------------------------------------------------
# Create database on cluster primary and add pgbouncer entry to cluster members
#------------------------------------------------------------------------------
# create database according to database definition
- include_tasks: roles/postgres/tasks/createdb.yml
vars:
database: "{{ pg_database_definition }}"
#------------------------------------------------------------------------------
# Pgbouncer Reload (entire cluster)
#------------------------------------------------------------------------------
- name: Reload pgbouncer to add database
when: pg_database_definition.pgbouncer is not defined or pg_database_definition.pgbouncer|bool
tags: pgbouncer_reload
systemd: name=pgbouncer state=reloaded enabled=yes daemon_reload=yes
...
使用样例
./pgsql-createdb.yml -l pg-test -e pg_database=test
执行结果
$ ./pgsql-createdb.yml -l pg-test -e pg_database=test
[WARNING]: Invalid characters were found in group names but not replaced, use -vvvv to see details
PLAY [Create Database In Cluster] *************************************************************************************************************************************************
TASK [Check parameter pg_database] ************************************************************************************************************************************************
ok: [10.10.10.11] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.12] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.13] => {
"changed": false,
"msg": "All assertions passed"
}
TASK [Fetch database definition] **************************************************************************************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [debug] **********************************************************************************************************************************************************************
ok: [10.10.10.11] => {
"msg": {
"name": "test"
}
}
ok: [10.10.10.12] => {
"msg": {
"name": "test"
}
}
ok: [10.10.10.13] => {
"msg": {
"name": "test"
}
}
TASK [Check database definition] **************************************************************************************************************************************************
ok: [10.10.10.11] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.12] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.13] => {
"changed": false,
"msg": "All assertions passed"
}
TASK [include_tasks] **************************************************************************************************************************************************************
included: /Volumes/Data/pigsty/roles/postgres/tasks/createdb.yml for 10.10.10.11, 10.10.10.12, 10.10.10.13
TASK [debug] **********************************************************************************************************************************************************************
ok: [10.10.10.11] => {
"msg": {
"name": "test"
}
}
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [Render database test creation sql] ******************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.11]
TASK [Render database test baseline sql] ******************************************************************************************************************************************
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [Execute database test creation command] *************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.11]
TASK [Execute database test creation sql] *****************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.11]
TASK [Execute database test creation sql] *****************************************************************************************************************************************
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [Add pgbouncer busniess database] ********************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [Reload pgbouncer to add database] *******************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
PLAY RECAP ************************************************************************************************************************************************************************
10.10.10.11 : ok=11 changed=5 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
10.10.10.12 : ok=7 changed=2 unreachable=0 failed=0 skipped=6 rescued=0 ignored=0
10.10.10.13 : ok=7 changed=2 unreachable=0 failed=0 skipped=6 rescued=0 ignored=0
任务详情
默认任务如下:
playbook: ./pgsql-createdb.yml
play #1 (all): Create Database In Cluster TAGS: []
tasks:
Check parameter pg_database TAGS: []
Fetch database definition TAGS: []
debug TAGS: []
Check database definition TAGS: []
include_tasks TAGS: []
Reload pgbouncer to add database TAGS: [pgbouncer_reload]
5.3.8 - Service Provision
Create or update service on cluster
剧本概览
创建业务数据库:可以在现有集群中创建新的数据库或修改现有数据库:pgsql-service.yml

日常管理
# 在 pg-test 集群创建所有服务
./pgsql-service.yml -l pg-test
剧本说明
#!/usr/bin/env ansible-playbook
---
#==============================================================#
# File : pgsql-service.yml
# Ctime : 2021-03-12
# Mtime : 2021-03-12
# Desc : reload service for postgres clusters
# Path : pgsql-service.yml
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
# PLEASE USE COMPLETE INVENTORY (at least contains a complete cluster definition!)
#------------------------------------------------------------------------------
# haproxy reload
# will not reload if haproxy_reload=false
#------------------------------------------------------------------------------
- name: Reload haproxy
become: yes
hosts: all
gather_facts: no
tags: haproxy
tasks:
- include_tasks: roles/service/tasks/haproxy_config.yml
when: haproxy_enabled
- include_tasks: roles/service/tasks/haproxy_reload.yml
when: haproxy_enabled and haproxy_reload|bool
#------------------------------------------------------------------------------
# l2-vip reload
# will only config without reload if vip_reload=false
#------------------------------------------------------------------------------
- name: Reload l2 VIP
become: yes
hosts: all
gather_facts: no
tags: vip_l2
tasks:
- include_tasks: roles/service/tasks/vip_l2_config.yml
when: vip_mode == 'l2'
- include_tasks: roles/service/tasks/vip_l2_reload.yml
when: vip_mode == 'l2' and vip_reload|bool
#------------------------------------------------------------------------------
# l4-vip reload
# will not reload if vip_reload=false
#------------------------------------------------------------------------------
- name: Reload l4 VIP
become: yes
hosts: all
gather_facts: no
tags: vip_l4
tasks:
- include_tasks: roles/service/tasks/vip_l4_config.yml
- include_tasks: roles/service/tasks/vip_l4_reload.yml
...
使用样例
./pgsql-service.yml -l pg-test
执行结果
$ ./pgsql-service.yml -l pg-test
[WARNING]: Invalid characters were found in group names but not replaced, use -vvvv to see details
PLAY [Reload haproxy] *************************************************************************************************************************************************************
TASK [include_tasks] **************************************************************************************************************************************************************
included: /Volumes/Data/pigsty/roles/service/tasks/haproxy_config.yml for 10.10.10.11, 10.10.10.12, 10.10.10.13
TASK [Fetch postgres cluster memberships] *****************************************************************************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [Templating /etc/haproxy/haproxy.cfg] ****************************************************************************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [include_tasks] **************************************************************************************************************************************************************
included: /Volumes/Data/pigsty/roles/service/tasks/haproxy_reload.yml for 10.10.10.11, 10.10.10.12, 10.10.10.13
TASK [Reload haproxy load balancer service] ***************************************************************************************************************************************
changed: [10.10.10.13]
changed: [10.10.10.12]
changed: [10.10.10.11]
PLAY [Reload l2 VIP] **************************************************************************************************************************************************************
TASK [include_tasks] **************************************************************************************************************************************************************
included: /Volumes/Data/pigsty/roles/service/tasks/vip_l2_config.yml for 10.10.10.11, 10.10.10.12, 10.10.10.13
TASK [Templating /etc/default/vip-manager.yml] ************************************************************************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.13]
ok: [10.10.10.12]
TASK [include_tasks] **************************************************************************************************************************************************************
included: /Volumes/Data/pigsty/roles/service/tasks/vip_l2_reload.yml for 10.10.10.11, 10.10.10.12, 10.10.10.13
TASK [Launch vip-manager] *********************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
PLAY [Reload l4 VIP] **************************************************************************************************************************************************************
TASK [include_tasks] **************************************************************************************************************************************************************
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [include_tasks] **************************************************************************************************************************************************************
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
PLAY RECAP ************************************************************************************************************************************************************************
10.10.10.11 : ok=9 changed=2 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
10.10.10.12 : ok=9 changed=2 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
10.10.10.13 : ok=9 changed=2 unreachable=0 failed=0 skipped=2 rescued=0 ignored=0
任务详情
默认任务如下:
playbook: ./pgsql-service.yml
play #1 (all): Reload haproxy TAGS: [haproxy]
tasks:
include_tasks TAGS: [haproxy]
include_tasks TAGS: [haproxy]
play #2 (all): Reload l2 VIP TAGS: [vip_l2]
tasks:
include_tasks TAGS: [vip_l2]
include_tasks TAGS: [vip_l2]
play #3 (all): Reload l4 VIP TAGS: [vip_l4]
tasks:
include_tasks TAGS: [vip_l4]
include_tasks TAGS: [vip_l4]
5.4 - Example
Real examples bout deploying pigsty
这里给出几个典型的部署样例,仅供参考。
5.4.1 - Vagrant Sandbox
Deploy pigsty on your local sandbox
概述
这个配置文件,是Pigsty自带的沙箱环境所使用的配置文件。
Github原地址为:https://github.com/Vonng/pigsty/blob/master/pigsty.yml
该配置文件可作为一个标准的学习样例,例如使用相同规格的虚拟机环境部署时,通常只需要在这份配置文件的基础上进行极少量修改就可以直接使用:例如,将10.10.10.10替换为您的元节点IP,将10.10.10.*替换为数据库节点的IP,修改或移除 ansible_host 系列连接参数以提供正确的连接信息。就可以将Pigsty部署到一组虚拟机上了。
配置文件
---
######################################################################
# File : pigsty.yml
# Path : pigsty.yml
# Desc : Pigsty Configuration file
# Note : follow ansible inventory file format
# Ctime : 2020-05-22
# Mtime : 2021-03-16
# Copyright (C) 2018-2021 Ruohang Feng
######################################################################
######################################################################
# Development Environment Inventory #
######################################################################
all: # top-level namespace, match all hosts
#==================================================================#
# Clusters #
#==================================================================#
# postgres database clusters are defined as kv pair in `all.children`
# where the key is cluster name and the value is the object consist
# of cluster members (hosts) and ad-hoc variables (vars)
# meta node are defined in special group "meta" with `meta_node=true`
children:
#-----------------------------
# meta controller
#-----------------------------
meta: # special group 'meta' defines the main controller machine
vars:
meta_node: true # mark node as meta controller
ansible_group_priority: 99 # meta group is top priority
# nodes in meta group
hosts: {10.10.10.10: {ansible_host: meta}}
#-----------------------------
# cluster: pg-meta
#-----------------------------
pg-meta:
# - cluster members - #
hosts:
10.10.10.10: {pg_seq: 1, pg_role: primary, ansible_host: meta}
# - cluster configs - #
vars:
pg_cluster: pg-meta # define actual cluster name
pg_version: 13 # define installed pgsql version
node_tune: tiny # tune node into oltp|olap|crit|tiny mode
pg_conf: tiny.yml # tune pgsql into oltp/olap/crit/tiny mode
patroni_mode: pause # enter maintenance mode, {default|pause|remove}
patroni_watchdog_mode: off # disable watchdog (require|automatic|off)
pg_lc_ctype: en_US.UTF8 # enabled pg_trgm i18n char support
pg_users:
# complete example of user/role definition for production user
- name: dbuser_meta # example production user have read-write access
password: DBUser.Meta # example user's password, can be encrypted
login: true # can login, true by default (should be false for role)
superuser: false # is superuser? false by default
createdb: false # can create database? false by default
createrole: false # can create role? false by default
inherit: true # can this role use inherited privileges?
replication: false # can this role do replication? false by default
bypassrls: false # can this role bypass row level security? false by default
connlimit: -1 # connection limit, -1 disable limit
expire_at: '2030-12-31' # 'timestamp' when this role is expired
expire_in: 365 # now + n days when this role is expired (OVERWRITE expire_at)
roles: [dbrole_readwrite] # dborole_admin|dbrole_readwrite|dbrole_readonly
pgbouncer: true # add this user to pgbouncer? false by default (true for production user)
parameters: # user's default search path
search_path: public
comment: test user
# simple example for personal user definition
- name: dbuser_vonng2 # personal user example which only have limited access to offline instance
password: DBUser.Vonng # or instance with explict mark `pg_offline_query = true`
roles: [dbrole_offline] # personal/stats/ETL user should be grant with dbrole_offline
expire_in: 365 # expire in 365 days since creation
pgbouncer: false # personal user should NOT be allowed to login with pgbouncer
comment: example personal user for interactive queries
pg_databases:
- name: meta # name is the only required field for a database
# owner: postgres # optional, database owner
# template: template1 # optional, template1 by default
# encoding: UTF8 # optional, UTF8 by default , must same as template database, leave blank to set to db default
# locale: C # optional, C by default , must same as template database, leave blank to set to db default
# lc_collate: C # optional, C by default , must same as template database, leave blank to set to db default
# lc_ctype: C # optional, C by default , must same as template database, leave blank to set to db default
allowconn: true # optional, true by default, false disable connect at all
revokeconn: false # optional, false by default, true revoke connect from public # (only default user and owner have connect privilege on database)
# tablespace: pg_default # optional, 'pg_default' is the default tablespace
connlimit: -1 # optional, connection limit, -1 or none disable limit (default)
extensions: # optional, extension name and where to create
- {name: postgis, schema: public}
parameters: # optional, extra parameters with ALTER DATABASE
enable_partitionwise_join: true
pgbouncer: true # optional, add this database to pgbouncer list? true by default
comment: pigsty meta database # optional, comment string for database
pg_default_database: meta # default database will be used as primary monitor target
# proxy settings
vip_mode: l2 # enable/disable vip (require members in same LAN)
vip_address: 10.10.10.2 # virtual ip address
vip_cidrmask: 8 # cidr network mask length
vip_interface: eth1 # interface to add virtual ip
#-----------------------------
# cluster: pg-test
#-----------------------------
pg-test: # define cluster named 'pg-test'
# - cluster members - #
hosts:
10.10.10.11: {pg_seq: 1, pg_role: primary, ansible_host: node-1}
10.10.10.12: {pg_seq: 2, pg_role: replica, ansible_host: node-2}
10.10.10.13: {pg_seq: 3, pg_role: offline, ansible_host: node-3}
# - cluster configs - #
vars:
# basic settings
pg_cluster: pg-test # define actual cluster name
pg_version: 13 # define installed pgsql version
node_tune: tiny # tune node into oltp|olap|crit|tiny mode
pg_conf: tiny.yml # tune pgsql into oltp/olap/crit/tiny mode
# business users, adjust on your own needs
pg_users:
- name: test # example production user have read-write access
password: test # example user's password
roles: [dbrole_readwrite] # dborole_admin|dbrole_readwrite|dbrole_readonly|dbrole_offline
pgbouncer: true # production user that access via pgbouncer
comment: default test user for production usage
pg_databases: # create a business database 'test'
- name: test # use the simplest form
pg_default_database: test # default database will be used as primary monitor target
# proxy settings
vip_mode: l2 # enable/disable vip (require members in same LAN)
vip_address: 10.10.10.3 # virtual ip address
vip_cidrmask: 8 # cidr network mask length
vip_interface: eth1 # interface to add virtual ip
#==================================================================#
# Globals #
#==================================================================#
vars:
#------------------------------------------------------------------------------
# CONNECTION PARAMETERS
#------------------------------------------------------------------------------
# this section defines connection parameters
# ansible_user: vagrant # admin user with ssh access and sudo privilege
proxy_env: # global proxy env when downloading packages
no_proxy: "localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.aliyuncs.com,mirrors.tuna.tsinghua.edu.cn,mirrors.zju.edu.cn"
# http_proxy: ''
# https_proxy: ''
# all_proxy: ''
#------------------------------------------------------------------------------
# REPO PROVISION
#------------------------------------------------------------------------------
# this section defines how to build a local repo
# - repo basic - #
repo_enabled: true # build local yum repo on meta nodes?
repo_name: pigsty # local repo name
repo_address: yum.pigsty # repo external address (ip:port or url)
repo_port: 80 # listen address, must same as repo_address
repo_home: /www # default repo dir location
repo_rebuild: false # force re-download packages
repo_remove: true # remove existing repos
# - where to download - #
repo_upstreams:
- name: base
description: CentOS-$releasever - Base - Aliyun Mirror
baseurl:
- http://mirrors.aliyun.com/centos/$releasever/os/$basearch/
- http://mirrors.aliyuncs.com/centos/$releasever/os/$basearch/
- http://mirrors.cloud.aliyuncs.com/centos/$releasever/os/$basearch/
gpgcheck: no
failovermethod: priority
- name: updates
description: CentOS-$releasever - Updates - Aliyun Mirror
baseurl:
- http://mirrors.aliyun.com/centos/$releasever/updates/$basearch/
- http://mirrors.aliyuncs.com/centos/$releasever/updates/$basearch/
- http://mirrors.cloud.aliyuncs.com/centos/$releasever/updates/$basearch/
gpgcheck: no
failovermethod: priority
- name: extras
description: CentOS-$releasever - Extras - Aliyun Mirror
baseurl:
- http://mirrors.aliyun.com/centos/$releasever/extras/$basearch/
- http://mirrors.aliyuncs.com/centos/$releasever/extras/$basearch/
- http://mirrors.cloud.aliyuncs.com/centos/$releasever/extras/$basearch/
gpgcheck: no
failovermethod: priority
- name: epel
description: CentOS $releasever - EPEL - Aliyun Mirror
baseurl: http://mirrors.aliyun.com/epel/$releasever/$basearch
gpgcheck: no
failovermethod: priority
- name: grafana
description: Grafana - TsingHua Mirror
gpgcheck: no
baseurl: https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm
- name: prometheus
description: Prometheus and exporters
gpgcheck: no
baseurl: https://packagecloud.io/prometheus-rpm/release/el/$releasever/$basearch
# consider using ZJU PostgreSQL mirror in mainland china
- name: pgdg-common
description: PostgreSQL common RPMs for RHEL/CentOS $releasever - $basearch
gpgcheck: no
# baseurl: https://download.postgresql.org/pub/repos/yum/common/redhat/rhel-$releasever-$basearch
baseurl: http://mirrors.zju.edu.cn/postgresql/repos/yum/common/redhat/rhel-$releasever-$basearch
- name: pgdg13
description: PostgreSQL 13 for RHEL/CentOS $releasever - $basearch
gpgcheck: no
# baseurl: https://download.postgresql.org/pub/repos/yum/13/redhat/rhel-$releasever-$basearch
baseurl: http://mirrors.zju.edu.cn/postgresql/repos/yum/13/redhat/rhel-$releasever-$basearch
- name: centos-sclo
description: CentOS-$releasever - SCLo
gpgcheck: no
mirrorlist: http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-sclo
- name: centos-sclo-rh
description: CentOS-$releasever - SCLo rh
gpgcheck: no
mirrorlist: http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-rh
- name: nginx
description: Nginx Official Yum Repo
skip_if_unavailable: true
gpgcheck: no
baseurl: http://nginx.org/packages/centos/$releasever/$basearch/
- name: haproxy
description: Copr repo for haproxy
skip_if_unavailable: true
gpgcheck: no
baseurl: https://download.copr.fedorainfracloud.org/results/roidelapluie/haproxy/epel-$releasever-$basearch/
# for latest consul & kubernetes
- name: harbottle
description: Copr repo for main owned by harbottle
skip_if_unavailable: true
gpgcheck: no
baseurl: https://download.copr.fedorainfracloud.org/results/harbottle/main/epel-$releasever-$basearch/
# - what to download - #
repo_packages:
# repo bootstrap packages
- epel-release nginx wget yum-utils yum createrepo # bootstrap packages
# node basic packages
- ntp chrony uuid lz4 nc pv jq vim-enhanced make patch bash lsof wget unzip git tuned # basic system util
- readline zlib openssl libyaml libxml2 libxslt perl-ExtUtils-Embed ca-certificates # basic pg dependency
- numactl grubby sysstat dstat iotop bind-utils net-tools tcpdump socat ipvsadm telnet # system utils
# dcs & monitor packages
- grafana prometheus2 pushgateway alertmanager # monitor and ui
- node_exporter postgres_exporter nginx_exporter blackbox_exporter # exporter
- consul consul_exporter consul-template etcd # dcs
# python3 dependencies
- ansible python python-pip python-psycopg2 audit # ansible & python
- python3 python3-psycopg2 python36-requests python3-etcd python3-consul # python3
- python36-urllib3 python36-idna python36-pyOpenSSL python36-cryptography # python3 patroni extra deps
# proxy and load balancer
- haproxy keepalived dnsmasq # proxy and dns
# postgres common Packages
- patroni patroni-consul patroni-etcd pgbouncer pg_cli pgbadger pg_activity # major components
- pgcenter boxinfo check_postgres emaj pgbconsole pg_bloat_check pgquarrel # other common utils
- barman barman-cli pgloader pgFormatter pitrery pspg pgxnclient PyGreSQL pgadmin4 tail_n_mail
# postgres 13 packages
- postgresql13* postgis31* citus_13 timescaledb_13 # pgrouting_13 # postgres 13 and postgis 31
- pg_repack13 pg_squeeze13 # maintenance extensions
- pg_qualstats13 pg_stat_kcache13 system_stats_13 bgw_replstatus13 # stats extensions
- plr13 plsh13 plpgsql_check_13 plproxy13 plr13 plsh13 plpgsql_check_13 pldebugger13 # PL extensions # pl extensions
- hdfs_fdw_13 mongo_fdw13 mysql_fdw_13 ogr_fdw13 redis_fdw_13 pgbouncer_fdw13 # FDW extensions
- wal2json13 count_distinct13 ddlx_13 geoip13 orafce13 # MISC extensions
- rum_13 hypopg_13 ip4r13 jsquery_13 logerrors_13 periods_13 pg_auto_failover_13 pg_catcheck13
- pg_fkpart13 pg_jobmon13 pg_partman13 pg_prioritize_13 pg_track_settings13 pgaudit15_13
- pgcryptokey13 pgexportdoc13 pgimportdoc13 pgmemcache-13 pgmp13 pgq-13
- pguint13 pguri13 prefix13 safeupdate_13 semver13 table_version13 tdigest13
repo_url_packages:
- https://github.com/Vonng/pg_exporter/releases/download/v0.3.2/pg_exporter-0.3.2-1.el7.x86_64.rpm
- https://github.com/cybertec-postgresql/vip-manager/releases/download/v0.6/vip-manager_0.6-1_amd64.rpm
- http://guichaz.free.fr/polysh/files/polysh-0.4-1.noarch.rpm
#------------------------------------------------------------------------------
# NODE PROVISION
#------------------------------------------------------------------------------
# this section defines how to provision nodes
# nodename: # if defined, node's hostname will be overwritten
# - node dns - #
node_dns_hosts: # static dns records in /etc/hosts
- 10.10.10.10 yum.pigsty
node_dns_server: add # add (default) | none (skip) | overwrite (remove old settings)
node_dns_servers: # dynamic nameserver in /etc/resolv.conf
- 10.10.10.10
node_dns_options: # dns resolv options
- options single-request-reopen timeout:1 rotate
- domain service.consul
# - node repo - #
node_repo_method: local # none|local|public (use local repo for production env)
node_repo_remove: true # whether remove existing repo
node_local_repo_url: # local repo url (if method=local, make sure firewall is configured or disabled)
- http://yum.pigsty/pigsty.repo
# - node packages - #
node_packages: # common packages for all nodes
- wget,yum-utils,ntp,chrony,tuned,uuid,lz4,vim-minimal,make,patch,bash,lsof,wget,unzip,git,readline,zlib,openssl
- numactl,grubby,sysstat,dstat,iotop,bind-utils,net-tools,tcpdump,socat,ipvsadm,telnet,tuned,pv,jq
- python3,python3-psycopg2,python36-requests,python3-etcd,python3-consul
- python36-urllib3,python36-idna,python36-pyOpenSSL,python36-cryptography
- node_exporter,consul,consul-template,etcd,haproxy,keepalived,vip-manager
node_extra_packages: # extra packages for all nodes
- patroni,patroni-consul,patroni-etcd,pgbouncer,pgbadger,pg_activity
node_meta_packages: # packages for meta nodes only
- grafana,prometheus2,alertmanager,nginx_exporter,blackbox_exporter,pushgateway
- dnsmasq,nginx,ansible,pgbadger,polysh
# - node features - #
node_disable_numa: false # disable numa, important for production database, reboot required
node_disable_swap: false # disable swap, important for production database
node_disable_firewall: true # disable firewall (required if using kubernetes)
node_disable_selinux: true # disable selinux (required if using kubernetes)
node_static_network: true # keep dns resolver settings after reboot
node_disk_prefetch: false # setup disk prefetch on HDD to increase performance
# - node kernel modules - #
node_kernel_modules:
- softdog
- br_netfilter
- ip_vs
- ip_vs_rr
- ip_vs_rr
- ip_vs_wrr
- ip_vs_sh
- nf_conntrack_ipv4
# - node tuned - #
node_tune: tiny # install and activate tuned profile: none|oltp|olap|crit|tiny
node_sysctl_params: # set additional sysctl parameters, k:v format
net.bridge.bridge-nf-call-iptables: 1 # for kubernetes
# - node user - #
node_admin_setup: true # setup an default admin user ?
node_admin_uid: 88 # uid and gid for admin user
node_admin_username: admin # default admin user
node_admin_ssh_exchange: true # exchange ssh key among cluster ?
node_admin_pks: # public key list that will be installed
- 'ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAAAgQC7IMAMNavYtWwzAJajKqwdn3ar5BhvcwCnBTxxEkXhGlCO2vfgosSAQMEflfgvkiI5nM1HIFQ8KINlx1XLO7SdL5KdInG5LIJjAFh0pujS4kNCT9a5IGvSq1BrzGqhbEcwWYdju1ZPYBcJm/MG+JD0dYCh8vfrYB/cYMD0SOmNkQ== vagrant@pigsty.com'
# - node ntp - #
node_ntp_service: ntp # ntp or chrony
node_ntp_config: true # overwrite existing ntp config?
node_timezone: Asia/Shanghai # default node timezone
node_ntp_servers: # default NTP servers
- pool cn.pool.ntp.org iburst
- pool pool.ntp.org iburst
- pool time.pool.aliyun.com iburst
- server 10.10.10.10 iburst
#------------------------------------------------------------------------------
# META PROVISION
#------------------------------------------------------------------------------
# - ca - #
ca_method: create # create|copy|recreate
ca_subject: "/CN=root-ca" # self-signed CA subject
ca_homedir: /ca # ca cert directory
ca_cert: ca.crt # ca public key/cert
ca_key: ca.key # ca private key
# - nginx - #
nginx_upstream:
- { name: home, host: pigsty, url: "127.0.0.1:3000"}
- { name: consul, host: c.pigsty, url: "127.0.0.1:8500" }
- { name: grafana, host: g.pigsty, url: "127.0.0.1:3000" }
- { name: prometheus, host: p.pigsty, url: "127.0.0.1:9090" }
- { name: alertmanager, host: a.pigsty, url: "127.0.0.1:9093" }
- { name: haproxy, host: h.pigsty, url: "127.0.0.1:9091" }
# - nameserver - #
dns_records: # dynamic dns record resolved by dnsmasq
- 10.10.10.2 pg-meta # sandbox vip for pg-meta
- 10.10.10.3 pg-test # sandbox vip for pg-test
- 10.10.10.10 meta-1 # sandbox node meta-1 (node-0)
- 10.10.10.11 node-1 # sandbox node node-1
- 10.10.10.12 node-2 # sandbox node node-2
- 10.10.10.13 node-3 # sandbox node node-3
- 10.10.10.10 pigsty
- 10.10.10.10 y.pigsty yum.pigsty
- 10.10.10.10 c.pigsty consul.pigsty
- 10.10.10.10 g.pigsty grafana.pigsty
- 10.10.10.10 p.pigsty prometheus.pigsty
- 10.10.10.10 a.pigsty alertmanager.pigsty
- 10.10.10.10 n.pigsty ntp.pigsty
- 10.10.10.10 h.pigsty haproxy.pigsty
# - prometheus - #
prometheus_data_dir: /export/prometheus/data # prometheus data dir
prometheus_options: '--storage.tsdb.retention=30d'
prometheus_reload: false # reload prometheus instead of recreate it
prometheus_sd_method: consul # service discovery method: static|consul|etcd
prometheus_scrape_interval: 2s # global scrape & evaluation interval
prometheus_scrape_timeout: 1s # scrape timeout
prometheus_sd_interval: 2s # service discovery refresh interval
# - grafana - #
grafana_url: http://admin:admin@10.10.10.10:3000 # grafana url
grafana_admin_password: admin # default grafana admin user password
grafana_plugin: install # none|install|reinstall
grafana_cache: /www/pigsty/grafana/plugins.tar.gz # path to grafana plugins tarball
grafana_customize: true # customize grafana resources
grafana_plugins: # default grafana plugins list
- redis-datasource
- simpod-json-datasource
- fifemon-graphql-datasource
- sbueringer-consul-datasource
- camptocamp-prometheus-alertmanager-datasource
- ryantxu-ajax-panel
- marcusolsson-hourly-heatmap-panel
- michaeldmoore-multistat-panel
- marcusolsson-treemap-panel
- pr0ps-trackmap-panel
- dalvany-image-panel
- magnesium-wordcloud-panel
- cloudspout-button-panel
- speakyourcode-button-panel
- jdbranham-diagram-panel
- grafana-piechart-panel
- snuids-radar-panel
- digrich-bubblechart-panel
grafana_git_plugins:
- https://github.com/Vonng/grafana-echarts
#------------------------------------------------------------------------------
# DCS PROVISION
#------------------------------------------------------------------------------
service_registry: consul # where to register services: none | consul | etcd | both
dcs_type: consul # consul | etcd | both
dcs_name: pigsty # consul dc name | etcd initial cluster token
dcs_servers: # dcs server dict in name:ip format
meta-1: 10.10.10.10 # you could use existing dcs cluster
# meta-2: 10.10.10.11 # host which have their IP listed here will be init as server
# meta-3: 10.10.10.12 # 3 or 5 dcs nodes are recommend for production environment
dcs_exists_action: clean # abort|skip|clean if dcs server already exists
dcs_disable_purge: false # set to true to disable purge functionality for good (force dcs_exists_action = abort)
consul_data_dir: /var/lib/consul # consul data dir (/var/lib/consul by default)
etcd_data_dir: /var/lib/etcd # etcd data dir (/var/lib/consul by default)
#------------------------------------------------------------------------------
# POSTGRES INSTALLATION
#------------------------------------------------------------------------------
# - dbsu - #
pg_dbsu: postgres # os user for database, postgres by default (change it is not recommended!)
pg_dbsu_uid: 26 # os dbsu uid and gid, 26 for default postgres users and groups
pg_dbsu_sudo: limit # none|limit|all|nopass (Privilege for dbsu, limit is recommended)
pg_dbsu_home: /var/lib/pgsql # postgresql binary
pg_dbsu_ssh_exchange: false # exchange ssh key among same cluster
# - postgres packages - #
pg_version: 13 # default postgresql version
pgdg_repo: false # use official pgdg yum repo (disable if you have local mirror)
pg_add_repo: false # add postgres related repo before install (useful if you want a simple install)
pg_bin_dir: /usr/pgsql/bin # postgres binary dir
pg_packages:
- postgresql${pg_version}*
- postgis31_${pg_version}*
- pgbouncer patroni pg_exporter pgbadger
- patroni patroni-consul patroni-etcd pgbouncer pgbadger pg_activity
- python3 python3-psycopg2 python36-requests python3-etcd python3-consul
- python36-urllib3 python36-idna python36-pyOpenSSL python36-cryptography
pg_extensions:
- pg_repack${pg_version} pg_qualstats${pg_version} pg_stat_kcache${pg_version} wal2json${pg_version}
# - ogr_fdw${pg_version} mysql_fdw_${pg_version} redis_fdw_${pg_version} mongo_fdw${pg_version} hdfs_fdw_${pg_version}
# - count_distinct${version} ddlx_${version} geoip${version} orafce${version} # popular features
# - hypopg_${version} ip4r${version} jsquery_${version} logerrors_${version} periods_${version} pg_auto_failover_${version} pg_catcheck${version}
# - pg_fkpart${version} pg_jobmon${version} pg_partman${version} pg_prioritize_${version} pg_track_settings${version} pgaudit15_${version}
# - pgcryptokey${version} pgexportdoc${version} pgimportdoc${version} pgmemcache-${version} pgmp${version} pgq-${version} pgquarrel pgrouting_${version}
# - pguint${version} pguri${version} prefix${version} safeupdate_${version} semver${version} table_version${version} tdigest${version}
#------------------------------------------------------------------------------
# POSTGRES PROVISION
#------------------------------------------------------------------------------
# - identity - #
# pg_cluster: # [REQUIRED] cluster name (validated during pg_preflight)
# pg_seq: 0 # [REQUIRED] instance seq (validated during pg_preflight)
# pg_role: replica # [REQUIRED] service role (validated during pg_preflight)
pg_hostname: false # overwrite node hostname with pg instance name
pg_nodename: true # overwrite consul nodename with pg instance name
# - retention - #
# pg_exists_action, available options: abort|clean|skip
# - abort: abort entire play's execution (default)
# - clean: remove existing cluster (dangerous)
# - skip: end current play for this host
# pg_exists: false # auxiliary flag variable (DO NOT SET THIS)
pg_exists_action: clean
pg_disable_purge: false # set to true to disable pg purge functionality for good (force pg_exists_action = abort)
# - storage - #
pg_data: /pg/data # postgres data directory
pg_fs_main: /export # data disk mount point /pg -> {{ pg_fs_main }}/postgres/{{ pg_instance }}
pg_fs_bkup: /var/backups # backup disk mount point /pg/* -> {{ pg_fs_bkup }}/postgres/{{ pg_instance }}/*
# - connection - #
pg_listen: '0.0.0.0' # postgres listen address, '0.0.0.0' by default (all ipv4 addr)
pg_port: 5432 # postgres port (5432 by default)
pg_localhost: /var/run/postgresql # localhost unix socket dir for connection
# - patroni - #
# patroni_mode, available options: default|pause|remove
# - default: default ha mode
# - pause: into maintenance mode
# - remove: remove patroni after bootstrap
patroni_mode: default # pause|default|remove
pg_namespace: /pg # top level key namespace in dcs
patroni_port: 8008 # default patroni port
patroni_watchdog_mode: automatic # watchdog mode: off|automatic|required
pg_conf: tiny.yml # user provided patroni config template path
# - localization - #
pg_encoding: UTF8 # default to UTF8
pg_locale: C # default to C
pg_lc_collate: C # default to C
pg_lc_ctype: en_US.UTF8 # default to en_US.UTF8
# - pgbouncer - #
pgbouncer_port: 6432 # pgbouncer port (6432 by default)
pgbouncer_poolmode: transaction # pooling mode: (transaction pooling by default)
pgbouncer_max_db_conn: 100 # important! do not set this larger than postgres max conn or conn limit
#------------------------------------------------------------------------------
# POSTGRES TEMPLATE
#------------------------------------------------------------------------------
# - template - #
pg_init: pg-init # init script for cluster template
# - system roles - #
pg_replication_username: replicator # system replication user
pg_replication_password: DBUser.Replicator # system replication password
pg_monitor_username: dbuser_monitor # system monitor user
pg_monitor_password: DBUser.Monitor # system monitor password
pg_admin_username: dbuser_admin # system admin user
pg_admin_password: DBUser.Admin # system admin password
# - default roles - #
# chekc http://pigsty.cc/zh/docs/concepts/provision/acl/ for more detail
pg_default_roles:
# common production readonly user
- name: dbrole_readonly # production read-only roles
login: false
comment: role for global readonly access
# common production read-write user
- name: dbrole_readwrite # production read-write roles
login: false
roles: [dbrole_readonly] # read-write includes read-only access
comment: role for global read-write access
# offline have same privileges as readonly, but with limited hba access on offline instance only
# for the purpose of running slow queries, interactive queries and perform ETL tasks
- name: dbrole_offline
login: false
comment: role for restricted read-only access (offline instance)
# admin have the privileges to issue DDL changes
- name: dbrole_admin
login: false
bypassrls: true
comment: role for object creation
roles: [dbrole_readwrite,pg_monitor,pg_signal_backend]
# dbsu, name is designated by `pg_dbsu`. It's not recommend to set password for dbsu
- name: postgres
superuser: true
comment: system superuser
# default replication user, name is designated by `pg_replication_username`, and password is set by `pg_replication_password`
- name: replicator
replication: true # for replication user
bypassrls: true # logical replication require bypassrls
roles: [pg_monitor, dbrole_readonly] # logical replication require select privileges
comment: system replicator
# default replication user, name is designated by `pg_monitor_username`, and password is set by `pg_monitor_password`
- name: dbuser_monitor
connlimit: 16
comment: system monitor user
roles: [pg_monitor, dbrole_readonly]
# default admin user, name is designated by `pg_admin_username`, and password is set by `pg_admin_password`
- name: dbuser_admin
bypassrls: true
superuser: true
comment: system admin user
roles: [dbrole_admin]
# default stats user, for ETL and slow queries
- name: dbuser_stats
password: DBUser.Stats
comment: business offline user for offline queries and ETL
roles: [dbrole_offline]
# - privileges - #
# object created by dbsu and admin will have their privileges properly set
pg_default_privileges:
- GRANT USAGE ON SCHEMAS TO dbrole_readonly
- GRANT SELECT ON TABLES TO dbrole_readonly
- GRANT SELECT ON SEQUENCES TO dbrole_readonly
- GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly
- GRANT USAGE ON SCHEMAS TO dbrole_offline
- GRANT SELECT ON TABLES TO dbrole_offline
- GRANT SELECT ON SEQUENCES TO dbrole_offline
- GRANT EXECUTE ON FUNCTIONS TO dbrole_offline
- GRANT INSERT, UPDATE, DELETE ON TABLES TO dbrole_readwrite
- GRANT USAGE, UPDATE ON SEQUENCES TO dbrole_readwrite
- GRANT TRUNCATE, REFERENCES, TRIGGER ON TABLES TO dbrole_admin
- GRANT CREATE ON SCHEMAS TO dbrole_admin
# - schemas - #
pg_default_schemas: [monitor] # default schemas to be created
# - extension - #
pg_default_extensions: # default extensions to be created
- { name: 'pg_stat_statements', schema: 'monitor' }
- { name: 'pgstattuple', schema: 'monitor' }
- { name: 'pg_qualstats', schema: 'monitor' }
- { name: 'pg_buffercache', schema: 'monitor' }
- { name: 'pageinspect', schema: 'monitor' }
- { name: 'pg_prewarm', schema: 'monitor' }
- { name: 'pg_visibility', schema: 'monitor' }
- { name: 'pg_freespacemap', schema: 'monitor' }
- { name: 'pg_repack', schema: 'monitor' }
- name: postgres_fdw
- name: file_fdw
- name: btree_gist
- name: btree_gin
- name: pg_trgm
- name: intagg
- name: intarray
# - hba - #
pg_offline_query: false # set to true to enable offline query on instance
pg_reload: true # reload postgres after hba changes
pg_hba_rules: # postgres host-based authentication rules
- title: allow meta node password access
role: common
rules:
- host all all 10.10.10.10/32 md5
- title: allow intranet admin password access
role: common
rules:
- host all +dbrole_admin 10.0.0.0/8 md5
- host all +dbrole_admin 172.16.0.0/12 md5
- host all +dbrole_admin 192.168.0.0/16 md5
- title: allow intranet password access
role: common
rules:
- host all all 10.0.0.0/8 md5
- host all all 172.16.0.0/12 md5
- host all all 192.168.0.0/16 md5
- title: allow local read/write (local production user via pgbouncer)
role: common
rules:
- local all +dbrole_readonly md5
- host all +dbrole_readonly 127.0.0.1/32 md5
- title: allow offline query (ETL,SAGA,Interactive) on offline instance
role: offline
rules:
- host all +dbrole_offline 10.0.0.0/8 md5
- host all +dbrole_offline 172.16.0.0/12 md5
- host all +dbrole_offline 192.168.0.0/16 md5
pg_hba_rules_extra: [] # extra hba rules (for cluster/instance overwrite)
pgbouncer_hba_rules: # pgbouncer host-based authentication rules
- title: local password access
role: common
rules:
- local all all md5
- host all all 127.0.0.1/32 md5
- title: intranet password access
role: common
rules:
- host all all 10.0.0.0/8 md5
- host all all 172.16.0.0/12 md5
- host all all 192.168.0.0/16 md5
pgbouncer_hba_rules_extra: [] # extra pgbouncer hba rules (for cluster/instance overwrite)
# pg_users: [] # business users
# pg_databases: [] # business databases
#------------------------------------------------------------------------------
# MONITOR PROVISION
#------------------------------------------------------------------------------
# - install - #
exporter_install: none # none|yum|binary, none by default
exporter_repo_url: '' # if set, repo will be added to /etc/yum.repos.d/ before yum installation
# - collect - #
exporter_metrics_path: /metrics # default metric path for pg related exporter
# - node exporter - #
node_exporter_enabled: true # setup node_exporter on instance
node_exporter_port: 9100 # default port for node exporter
node_exporter_options: '--no-collector.softnet --collector.systemd --collector.ntp --collector.tcpstat --collector.processes'
# - pg exporter - #
pg_exporter_config: pg_exporter-demo.yaml # default config files for pg_exporter
pg_exporter_enabled: true # setup pg_exporter on instance
pg_exporter_port: 9630 # default port for pg exporter
pg_exporter_url: '' # optional, if not set, generate from reference parameters
# - pgbouncer exporter - #
pgbouncer_exporter_enabled: true # setup pgbouncer_exporter on instance (if you don't have pgbouncer, disable it)
pgbouncer_exporter_port: 9631 # default port for pgbouncer exporter
pgbouncer_exporter_url: '' # optional, if not set, generate from reference parameters
#------------------------------------------------------------------------------
# SERVICE PROVISION
#------------------------------------------------------------------------------
pg_weight: 100 # default load balance weight (instance level)
# - service - #
pg_services: # how to expose postgres service in cluster?
# primary service will route {ip|name}:5433 to primary pgbouncer (5433->6432 rw)
- name: primary # service name {{ pg_cluster }}_primary
src_ip: "*"
src_port: 5433
dst_port: pgbouncer # 5433 route to pgbouncer
check_url: /primary # primary health check, success when instance is primary
selector: "[]" # select all instance as primary service candidate
# replica service will route {ip|name}:5434 to replica pgbouncer (5434->6432 ro)
- name: replica # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5434
dst_port: pgbouncer
check_url: /read-only # read-only health check. (including primary)
selector: "[]" # select all instance as replica service candidate
selector_backup: "[? pg_role == `primary`]" # primary are used as backup server in replica service
# default service will route {ip|name}:5436 to primary postgres (5436->5432 primary)
- name: default # service's actual name is {{ pg_cluster }}-{{ service.name }}
src_ip: "*" # service bind ip address, * for all, vip for cluster virtual ip address
src_port: 5436 # bind port, mandatory
dst_port: postgres # target port: postgres|pgbouncer|port_number , pgbouncer(6432) by default
check_method: http # health check method: only http is available for now
check_port: patroni # health check port: patroni|pg_exporter|port_number , patroni by default
check_url: /primary # health check url path, / as default
check_code: 200 # health check http code, 200 as default
selector: "[]" # instance selector
haproxy: # haproxy specific fields
maxconn: 3000 # default front-end connection
balance: roundrobin # load balance algorithm (roundrobin by default)
default_server_options: 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
# offline service will route {ip|name}:5438 to offline postgres (5438->5432 offline)
- name: offline # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5438
dst_port: postgres
check_url: /replica # offline MUST be a replica
selector: "[? pg_role == `offline` || pg_offline_query ]" # instances with pg_role == 'offline' or instance marked with 'pg_offline_query == true'
selector_backup: "[? pg_role == `replica` && !pg_offline_query]" # replica are used as backup server in offline service
pg_services_extra: [] # extra services to be added
# - haproxy - #
haproxy_enabled: true # enable haproxy among every cluster members
haproxy_reload: true # reload haproxy after config
haproxy_admin_auth_enabled: false # enable authentication for haproxy admin?
haproxy_admin_username: admin # default haproxy admin username
haproxy_admin_password: admin # default haproxy admin password
haproxy_exporter_port: 9101 # default admin/exporter port
haproxy_client_timeout: 3h # client side connection timeout
haproxy_server_timeout: 3h # server side connection timeout
# - vip - #
vip_mode: none # none | l2 | l4
vip_reload: true # whether reload service after config
# vip_address: 127.0.0.1 # virtual ip address ip (l2 or l4)
# vip_cidrmask: 24 # virtual ip address cidr mask (l2 only)
# vip_interface: eth0 # virtual ip network interface (l2 only)
...
5.4.2 - QCloud VPC Deployment
Deployment with cloud provider VPS
本样例将基于腾讯云VPC部署Pigsty
资源准备
申请虚拟机
买几台虚拟机,如下图所示,其中11这一台作为元节点,带有公网IP,数据库节点3台,普通1核1G即可。
配置SSH远程登录
现在假设我们的管理用户名为vonng,就是我啦!现在首先配置我在元节点上到其他三台节点的ssh免密码访问。
# vonng@172.21.0.11 # meta
ssh-copy-id root@172.21.0.3 # pg-test-1
ssh-copy-id root@172.21.0.4 # pg-test-2
ssh-copy-id root@172.21.0.16 # pg-test-3
scp ~/.ssh/id_rsa.pub root@172.21.0.3:/tmp/
scp ~/.ssh/id_rsa.pub root@172.21.0.4:/tmp/
scp ~/.ssh/id_rsa.pub root@172.21.0.16:/tmp/
ssh root@172.21.0.3 'useradd vonng; mkdir -m 700 -p /home/vonng/.ssh; mv /tmp/id_rsa.pub /home/vonng/.ssh/authorized_keys; chown -R vonng /home/vonng; chmod 0600 /home/vonng/.ssh/authorized_keys;'
ssh root@172.21.0.4 'useradd vonng; mkdir -m 700 -p /home/vonng/.ssh; mv /tmp/id_rsa.pub /home/vonng/.ssh/authorized_keys; chown -R vonng /home/vonng; chmod 0600 /home/vonng/.ssh/authorized_keys;'
ssh root@172.21.0.16 'useradd vonng; mkdir -m 700 -p /home/vonng/.ssh; mv /tmp/id_rsa.pub /home/vonng/.ssh/authorized_keys; chown -R vonng /home/vonng; chmod 0600 /home/vonng/.ssh/authorized_keys;'
然后配置该用户免密码执行sudo的权限:
ssh root@172.21.0.3 "echo '%vonng ALL=(ALL) NOPASSWD: ALL' > /etc/sudoers.d/vonng"
ssh root@172.21.0.4 "echo '%vonng ALL=(ALL) NOPASSWD: ALL' > /etc/sudoers.d/vonng"
ssh root@172.21.0.16 "echo '%vonng ALL=(ALL) NOPASSWD: ALL' > /etc/sudoers.d/vonng"
# 校验配置是否成功
ssh 172.21.0.3 'sudo ls'
ssh 172.21.0.4 'sudo ls'
ssh 172.21.0.16 'sudo ls'
下载项目
# 从Github克隆代码
git clone https://github.com/Vonng/pigsty
# 如果您不能访问Github,也可以使用Pigsty CDN下载代码包
curl http://pigsty-1304147732.cos.accelerate.myqcloud.com/latest/pigsty.tar.gz -o pigsty.tgz && tar -xf pigsty.tgz && cd pigsty
下载离线安装包
# 从Github Release页面下载
# https://github.com/Vonng/pigsty
# 如果您不能访问Github,也可以使用Pigsty CDN下载离线软件包
curl http://pigsty-1304147732.cos.accelerate.myqcloud.com/latest/pkg.tgz -o files/pkg.tgz
# 将离线安装包解压至元节点指定位置 (也许要sudo)
mv -rf /www/pigsty /www/pigsty-backup && mkdir -p /www/pigsty
tar -xf files/pkg.tgz --strip-component=1 -C /www/pigsty/
调整配置
我们可以基于Pigsty沙箱的配置文件进行调整。因为都是普通低配虚拟机,因此不需要任何实质配置修改,只需要修改连接参数与节点信息即可。简单的说,只要改IP地址就可以了!
现在将沙箱中的IP地址全部替换为云环境中的实际IP地址。(如果使用了L2 VIP,VIP也需要替换为合理的地址)
| 说明 |
沙箱IP |
虚拟机IP |
|
| 元节点 |
10.10.10.10 |
172.21.0.11 |
|
| 数据库节点1 |
10.10.10.11 |
172.21.0.3 |
|
| 数据库节点2 |
10.10.10.12 |
172.21.0.4 |
|
| 数据库节点3 |
10.10.10.13 |
172.21.0.16 |
|
| pg-meta VIP |
10.10.10.2 |
172.21.0.8 |
|
| pg-test VIP |
10.10.10.3 |
172.21.0.9 |
|
编辑配置文件:pigsty.yml,如果都是规格差不多的虚拟机,通常您只需要修改IP地址即可。特别需要注意的是在沙箱中我们是通过SSH Alias来连接的(诸如meta, node-1之类),记得移除所有ansible_host配置,我们将直接使用IP地址连接目标节点。
cat pigsty.yml | \
sed 's/10.10.10.10/172.21.0.11/g' |\
sed 's/10.10.10.11/172.21.0.3/g' |\
sed 's/10.10.10.12/172.21.0.4/g' |\
sed 's/10.10.10.13/172.21.0.16/g' |\
sed 's/10.10.10.2/172.21.0.8/g' |\
sed 's/10.10.10.3/172.21.0.9/g' |\
sed 's/10.10.10.3/172.21.0.9/g' |\
sed 's/, ansible_host: meta//g' |\
sed 's/ansible_host: meta//g' |\
sed 's/, ansible_host: node-[123]//g' |\
sed 's/vip_interface: eth1/vip_interface: eth0/g' |\
sed 's/vip_cidrmask: 8/vip_cidrmask: 24/g' > pigsty2.yml
mv pigsty.yml pigsty-backup.yml; mv pigsty2.yml pigsty.yml
就这?
是的,配置文件已经修改完了!我们可以看看到底修改了什么东西
$ diff pigsty.yml pigsty-backup.yml
38c38
< hosts: {172.21.0.11: {}}
---
> hosts: {10.10.10.10: {ansible_host: meta}}
46c46
< 172.21.0.11: {pg_seq: 1, pg_role: primary}
---
> 10.10.10.10: {pg_seq: 1, pg_role: primary, ansible_host: meta}
109,111c109,111
< vip_address: 172.21.0.8 # virtual ip address
< vip_cidrmask: 24 # cidr network mask length
< vip_interface: eth0 # interface to add virtual ip
---
> vip_address: 10.10.10.2 # virtual ip address
> vip_cidrmask: 8 # cidr network mask length
> vip_interface: eth1 # interface to add virtual ip
120,122c120,122
< 172.21.0.3: {pg_seq: 1, pg_role: primary}
< 172.21.0.4: {pg_seq: 2, pg_role: replica}
< 172.21.0.16: {pg_seq: 3, pg_role: offline}
---
> 10.10.10.11: {pg_seq: 1, pg_role: primary, ansible_host: node-1}
> 10.10.10.12: {pg_seq: 2, pg_role: replica, ansible_host: node-2}
> 10.10.10.13: {pg_seq: 3, pg_role: offline, ansible_host: node-3}
147,149c147,149
< vip_address: 172.21.0.9 # virtual ip address
< vip_cidrmask: 24 # cidr network mask length
< vip_interface: eth0 # interface to add virtual ip
---
> vip_address: 10.10.10.3 # virtual ip address
> vip_cidrmask: 8 # cidr network mask length
> vip_interface: eth1 # interface to add virtual ip
326c326
< - 172.21.0.11 yum.pigsty
---
> - 10.10.10.10 yum.pigsty
329c329
< - 172.21.0.11
---
> - 10.10.10.10
393c393
< - server 172.21.0.11 iburst
---
> - server 10.10.10.10 iburst
417,430c417,430
< - 172.21.0.8 pg-meta # sandbox vip for pg-meta
< - 172.21.0.9 pg-test # sandbox vip for pg-test
< - 172.21.0.11 meta-1 # sandbox node meta-1 (node-0)
< - 172.21.0.3 node-1 # sandbox node node-1
< - 172.21.0.4 node-2 # sandbox node node-2
< - 172.21.0.16 node-3 # sandbox node node-3
< - 172.21.0.11 pigsty
< - 172.21.0.11 y.pigsty yum.pigsty
< - 172.21.0.11 c.pigsty consul.pigsty
< - 172.21.0.11 g.pigsty grafana.pigsty
< - 172.21.0.11 p.pigsty prometheus.pigsty
< - 172.21.0.11 a.pigsty alertmanager.pigsty
< - 172.21.0.11 n.pigsty ntp.pigsty
< - 172.21.0.11 h.pigsty haproxy.pigsty
---
> - 10.10.10.2 pg-meta # sandbox vip for pg-meta
> - 10.10.10.3 pg-test # sandbox vip for pg-test
> - 10.10.10.10 meta-1 # sandbox node meta-1 (node-0)
> - 10.10.10.11 node-1 # sandbox node node-1
> - 10.10.10.12 node-2 # sandbox node node-2
> - 10.10.10.13 node-3 # sandbox node node-3
> - 10.10.10.10 pigsty
> - 10.10.10.10 y.pigsty yum.pigsty
> - 10.10.10.10 c.pigsty consul.pigsty
> - 10.10.10.10 g.pigsty grafana.pigsty
> - 10.10.10.10 p.pigsty prometheus.pigsty
> - 10.10.10.10 a.pigsty alertmanager.pigsty
> - 10.10.10.10 n.pigsty ntp.pigsty
> - 10.10.10.10 h.pigsty haproxy.pigsty
442c442
< grafana_url: http://admin:admin@172.21.0.11:3000 # grafana url
---
> grafana_url: http://admin:admin@10.10.10.10:3000 # grafana url
478,480c478,480
< meta-1: 172.21.0.11 # you could use existing dcs cluster
< # meta-2: 172.21.0.3 # host which have their IP listed here will be init as server
< # meta-3: 172.21.0.4 # 3 or 5 dcs nodes are recommend for production environment
---
> meta-1: 10.10.10.10 # you could use existing dcs cluster
> # meta-2: 10.10.10.11 # host which have their IP listed here will be init as server
> # meta-3: 10.10.10.12 # 3 or 5 dcs nodes are recommend for production environment
692c692
< - host all all 172.21.0.11/32 md5
---
> - host all all 10.10.10.10/32 md5
执行剧本
您可以使用同样的 沙箱初始化 来完成 基础设施和数据库集群的初始化。
其输出结果除了IP地址,与沙箱并无区别。参考输出
访问Demo
现在,您可以通过公网IP访问元节点上的服务了!请注意做好信息安全工作。
与沙箱环境不同的是,如果您需要从公网访问Pigsty管理界面,需要自己把定义的域名写入/etc/hosts中,或者使用真正申请的域名。
否则就只能通过IP端口直连的方式访问,例如: http://<meta_node_public_ip>:3000。
Nginx监听的域名可以通过可以通过 nginx_upstream 选项。
nginx_upstream:
- { name: home, host: pigsty.cc, url: "127.0.0.1:3000"}
- { name: consul, host: c.pigsty.cc, url: "127.0.0.1:8500" }
- { name: grafana, host: g.pigsty.cc, url: "127.0.0.1:3000" }
- { name: prometheus, host: p.pigsty.cc, url: "127.0.0.1:9090" }
- { name: alertmanager, host: a.pigsty.cc, url: "127.0.0.1:9093" }
- { name: haproxy, host: h.pigsty.cc, url: "127.0.0.1:9091" }
5.4.3 - Production
Production deployment based on high-end hardware
本样例将基于一个真实生产环境作为样例。
该环境包括了200台高规格 x86 物理机:Dell R740 64核CPU / 400GB内存 / 4TB PCI-E SSD / 双万兆网卡
资源准备
调整配置
执行剧本
访问服务
5.4.4 - Aliyun MyBase
How to deploy pigsty montoring system for “Aliyun MyBase for PostgreSQL”
Pigsty内置了数据库供给方案,但也可以单纯作为监控系统与外部供给方案集成,例如阿里云MyBase for PostgreSQL。
与外部系统集成时,用户只需要部署一个元节点,用于设置监控基础设施。同时在监控目标机器上,需要安装Node Exporter与PG Exporter采集指标。
Pigsty提供了静态服务发现机制与Exporter二进制部署模式,以减少对外部系统的侵入。
下面将以一个实际例子介绍如何使用Pigsty监控阿里云MyBase。
资源申请
部署监控基础设施
部署监控Exporter
管理实例身份
更新实例列表
5.5 - Monly Deployment
How to deploy pigsty monitor system only, and intergrated with existing postgres instances
如果用户只希望使用Pigsty的监控系统部分,比如希望使用Pigsty监控系统监控已有的PostgreSQL实例,那么可以使用 仅监控部署(monitor only) 模式。
仅监控模式的部署流程与标准模式大体上保持一致,但省略了很多步骤
- 在元节点上完成基础设施初始化的部分,与标准流程一致。
- 修改配置文件,在仅监控模式中,通常只需要修改监控系统部分的参数。
- 使用专用的剧本在数据库节点上完成仅监控部署,
./pgsql-monitor.yml 。
部署说明
监控用户
Pigsty在 PG供给 的阶段会创建监控用户,仅监控模式跳过了这些步骤,因此用户需要自行创建用于监控的用户。
用户需要自行在目标数据库集群上创建监控用户,并创建重要的监控模式与扩展(只有pg_stat_statements是必选项)。在待监控数据库实例上执行以下SQL以创建监控用户。
-- 创建监控用户
CREATE USER "dbuser_monitor" ;
ALTER ROLE "dbuser_monitor" PASSWORD 'DBUser.Monitor';
ALTER USER "dbuser_monitor" CONNECTION LIMIT 16;
GRANT "pg_monitor" TO "dbuser_monitor";
GRANT "dbrole_readonly" TO "dbuser_monitor";
-- 创建监控模式与扩展
CREATE SCHEMA IF NOT EXISTS monitor;
GRANT USAGE ON SCHEMA monitor TO "dbuser_monitor";
CREATE EXTENSION IF NOT EXISTS "pg_stat_statements" WITH SCHEMA "monitor";
-- 额外的监控函数,用于监控共享内存指标,只有PG13及以上版本才需要。
CREATE OR REPLACE FUNCTION monitor.pg_shmem() RETURNS SETOF
pg_shmem_allocations AS $$ SELECT * FROM pg_shmem_allocations;$$ LANGUAGE SQL SECURITY DEFINER;
COMMENT ON FUNCTION monitor.pg_shmem() IS 'security wrapper for pg_shmem';
监控连接串
默认情况下,Pigsty会尝试使用以下规则生成数据库与连接池的连接串。
PG_EXPORTER_URL='postgres://{{ pg_monitor_username }}:{{ pg_monitor_password }}@:{{ pg_port }}/{{ pg_default_database }}?host={{ pg_localhost }}&sslmode=disable'
PGBOUNCER_EXPORTER_URL='postgres://{{ pg_monitor_username }}:{{ pg_monitor_password }}@:{{ pgbouncer_port }}/pgbouncer?host={{ pg_localhost }}&sslmode=disable'
如果用户使用的监控角色连接串无法通过该规则生成,则可以使用以下参数直接配置数据库与连接池的连接信息:
作为样例,沙箱环境中元节点连接至数据库的连接串为:
PG_EXPORTER_URL='postgres://dbuser_monitor:DBUser.Monitor@:5432/meta?host=/var/run/postgresql&sslmode=disable'
懒人方案
如果不怎么关心安全性与权限,也可以直接使用dbsu ident认证的方式,例如postgres用户进行监控。
pg_exporter 默认以 dbsu 的用户执行,如果允许dbsu通过本地ident认证免密访问数据库(Pigsty默认配置),则可以直接使用超级用户监控数据库。Pigsty非常不推荐这种部署方式,但它确实很方便,既不用创建新用户,也不用配置权限。
PG_EXPORTER_URL='postgres:///postgres?host=/var/run/postgresql&sslmode=disable'
相关参数
使用仅监控部署时,只会用到Pigsty参数的一个子集。
基础设施部分
基础设施与元节点仍然与常规部署保持一致,除了以下两个参数必须强制使用指定的配置选项。
service_registry: none # 须关闭服务注册,因为目标环境可能没有DCS基础设施。
prometheus_sd_method: static # 须使用静态文件服务发现,因为目标实例可能并没有使用服务发现与服务注册
目标节点部分
目标节点的身份参数仍然为必选项,除此之外,通常只有监控系统参数需要调整。
---
#------------------------------------------------------------------------------
# MONITOR PROVISION
#------------------------------------------------------------------------------
# - install - #
exporter_install: none # none|yum|binary, none by default
exporter_repo_url: '' # if set, repo will be added to /etc/yum.repos.d/ before yum installation
# - collect - #
exporter_metrics_path: /metrics # default metric path for pg related exporter
# - node exporter - #
node_exporter_enabled: true # setup node_exporter on instance
node_exporter_port: 9100 # default port for node exporter
node_exporter_options: '--no-collector.softnet --collector.systemd --collector.ntp --collector.tcpstat --collector.processes'
# - pg exporter - #
pg_exporter_config: pg_exporter-demo.yaml # default config files for pg_exporter
pg_exporter_enabled: true # setup pg_exporter on instance
pg_exporter_port: 9630 # default port for pg exporter
pg_exporter_url: '' # optional, if not set, generate from reference parameters
# - pgbouncer exporter - #
pgbouncer_exporter_enabled: true # setup pgbouncer_exporter on instance (if you don't have pgbouncer, disable it)
pgbouncer_exporter_port: 9631 # default port for pgbouncer exporter
pgbouncer_exporter_url: '' # optional, if not set, generate from reference parameters
# - postgres variables reference - #
pg_dbsu: postgres
pg_port: 5432 # postgres port (5432 by default)
pgbouncer_port: 6432 # pgbouncer port (6432 by default)
pg_localhost: /var/run/postgresql # localhost unix socket dir for connection
pg_default_database: postgres # default database will be used as primary monitor target
pg_monitor_username: dbuser_monitor # system monitor username, for postgres and pgbouncer
pg_monitor_password: DBUser.Monitor # system monitor user's password
service_registry: consul # none | consul | etcd | both
...
通常来说,需要调整的参数包括:
exporter_install: binary # none|yum|binary 建议使用拷贝二进制的方式安装Exporter
pgbouncer_exporter_enabled: false # 如果目标实例没有关联的Pgbouncer实例,则需关闭Pgbouncer监控
pg_exporter_url: '' # 连接至 Postgres 的URL,如果不采用默认的URL拼合规则,则可使用此参数
pgbouncer_exporter_url: '' # 连接至 Pgbouncer 的URL,如果不采用默认的URL拼合规则,则可使用此参数
局限性
Pigsty监控系统 与 Pigsty供给方案 配合紧密,原装的总是最好的。尽管Pigsty并不推荐拆分使用,但这样做确实是可行的,只是存在一些局限性。
指标缺失
Pigsty会集成多种来源的指标,包括机器节点,数据库,Pgbouncer连接池,Haproxy负载均衡器。如果用户自己的供给方案中缺少这些组件,则相应指标也会发生缺失。
通常Node与PG的监控指标总是存在,而PGbouncer与Haproxy的缺失通常会导致100~200个不等的指标损失。
特别是,Pgbouncer监控指标中包含极其重要的PG QPS,TPS,RT,而这些指标是无法从PostgreSQL本身获取的。
工作假设
Pigsty监控系统 如果要与外部供给方案配合,监控已有数据库集群,需要一些工作假设:
- 数据库采用独占式部署,与节点存在一一对应关系。只有这样,节点指标才能有意义地与数据库指标关联。
- 目标节点可以被Ansible管理(NOPASS SSH与NOPASS SUDO),一些云厂商RDS产品并不允许这样做。
- 数据库需要创建可用于访问监控指标的监控用户,安装必须的监控模式与扩展,并合理配置其访问控制权限。
服务发现
外部供给方案通常拥有自己的身份管理机制,因此Pigsty不会越俎代庖地部署DCS用于服务发现。这意味着用户只能采用 静态配置文件 的方式管理监控对象的身份,通常这并不是一个问题。
在Pigsty沙箱中,当实例的角色身份发生变化时,系统会通过回调函数与反熵过程及时修正实例的角色信息,如将primary修改为replica,将其他角色修改为primary。
pg_up{cls="pg-meta", ins="pg-meta-1", instance="10.10.10.10:9630", ip="10.10.10.10", job="pg", role="primary", svc="pg-meta-primary"}
但与外部供给方案集成时,除非用户显式通知或回调 监控系统,根据最新角色定义生成配置文件,否则监控系统无法意识到主从发生了切换。上面的样例监控指标中,role与svc标签会因为不及时的角色调整受到影响,这意味着Service级别的监控数据准确性会受到影响(即pg:svc:*系列指标,例如服务的QPS)。但其他层次的监控指标与图表不受主从切换影响,因此影响不大,且有其他办法解决。
管理权限
Pigsty的监控指标依赖 node_exporter 与 pg_exporter 获取。
尽管pg_exporter可以采用exporter拉取远程数据库实例信息的方式部署,但node_exporter必须部署在数据库所属的节点上。
这意味着,用户必须拥有数据库所在机器的SSH登陆与sudo权限才能完成部署。换句话说,目标节点必须可以被Ansible纳入管理,而云厂商RDS通常不会给出此类权限。
6 - Config
Configuration reference of pigsty
Pigsty uses [declarative configuration] (../reference/config/): the user configuration describes the state, while Pigsty is responsible for tuning the real component to the expected state.
Pigsty configuration files follow Ansible rules in YAML format, see Config Files for details .
Pigsty have 156 parameters, divided into 10 categories and five levels. see Config Entry for details.
Most parameters are optional. There are only 3 mandatory identity parameters to define a new database cluster.
| No |
Category |
Type |
Args |
Function |
| 1 |
connect |
Infra |
1 |
Proxy settings, connect information |
| 2 |
repo |
Infra |
10 |
local yum repo |
| 3 |
node |
Infra |
29 |
node provision (ntp, dns, tuned, etc…) |
| 4 |
meta |
Infra |
21 |
setup infrastructure on meta node |
| 5 |
dcs |
Infra |
8 |
setup DCS (consul) |
| 6 |
pg-install |
PgSQL |
11 |
install postgres (repo, pkgs, extensions,users,dirs) |
| 7 |
pg-provision |
PgSQL |
27 |
pull up pg clusters (identity assignment) |
| 8 |
pg-template |
PgSQL |
19 |
customize cluster content and template |
| 9 |
monitor |
PgSQL |
13 |
install monitor components |
| 10 |
service |
PgSQL |
17 |
expose service via haproxy and vip |
6.1 - Config File
Structure, content, merge and split methods of Pigsty configuration files.
Pigsty配置文件遵循Ansible规则,采用YAML格式,默认使用单一配置文件,参考范例。
Pigsty的配置文件默认为 pigsty.yml ,配置文件需要与Ansible 配合使用,这是一个流行的DevOps工具。
用户可以在当前目录的 ansible.cfg 中指定默认配置文件路径,或在执行剧本时通过命令行参数:-i pigsty.yml 的方式显式指定配置文件路径。
配置文件结构
Pigsty的配置文件采用Ansible YAML Inventory格式,顶层结构如下:
all: # 顶层对象 all
vars: <123 keys> # 全局配置 all.vars
children: # 分组定义:all.children 每一个项目定义了一个数据库集群
meta: <2 keys>...
pg-meta: <2 keys>...
pg-test: <2 keys>... # 一个具体的数据库集群 pg-test 的详细定义
...
每一个具体的数据库集群,以Ansible Group的形式存在,如下所示:
pg-test: # 数据库集群名称默认作为群组名称
vars: # 数据库集群级别变量
pg_cluster: pg-test # 一个定义在集群级别的必选配置项,在整个pg-test中保持一致。
hosts: # 数据库集群成员
10.10.10.11: {pg_seq: 1, pg_role: primary} # 数据库实例成员
10.10.10.12: {pg_seq: 2, pg_role: replica} # 必须定义身份参数 pg_role 与 pg_seq
10.10.10.13: {pg_seq: 3, pg_role: offline} # 可以在此指定实例级别的变量
配置项
在Pigsty的配置文件中,配置项 可以出现在三种位置:
| 层级 |
范围 |
优先级 |
说明 |
位置 |
| Global |
全局 |
低 |
在同一套部署环境内一致 |
all.vars.xxx |
| Cluster |
集群 |
中 |
在同一套集群内保持一致 |
all.children.<cls>.vars.xxx |
| Instance |
实例 |
高 |
最细粒度的配置层次 |
all.children.<cls>.hosts.<ins>.xxx |
每一个配置项都由一对键值组成。键是配置项的名称,值是配置项的内容。值的类型各异,详情请参考 配置项 。
集群vars中定义的配置项会以同名键覆盖的方式覆盖全局配置项,实例中定义的配置项又会覆盖集群配置项与全局配置项。因此用户可以有的放矢,可以在不同层次,不同粒度上针对具体集群与具体实例进行精细配置。
分立式配置文件
有时候用户希望采用每个数据库集群一个配置文件的方式使用Pigsty,而不是共用一个巨大的配置清单。
这样做的好处是如果发生误操作,影响范围会局限在这个集群中,避免全局恶性事件。例如,下线某个集群时,错误地指定执行范围,有可能产生误删整个环境中所有数据库。
用户可以使用任何满足Ansible规则与和Pigsty变量层次语义的配置方式,但Pigsty推荐采用以下形式的配置文件拆分规则:
group_vars/all.yml : 在这里定义所有全局变量。group_vars/<pg_cluster>.yml :在这里定义数据库集群<pg_cluster>的集群变量。pgsql/<pg_cluster>.yml:在这里定义数据库集群<pg_cluster>的实例成员,以及实例变量。host_vars/<pg_instance>.yml:如果单个实例的配置项非常复杂,可在此列为独立配置文件。
采用分立式配置文件的Pigsty沙箱目录结构如下所示:
pigsty
|
^- group_vars # 全局/集群 配置项定义 (此目录名称固定)
| ^------ all.yml # 全局配置项
| ^------ meta.yml # 元节点配置项
| ^------ pg-meta.yml # pg-meta集群配置项 (覆盖全局定义)
| ^------ pg-test.yml # pg-test集群配置项 (覆盖全局定义)
| ^------ <cluster>.yml # <pg_cluster>集群配置项(覆盖全局定义)
|
^- host_vars # 【可选】抽离实例级变量定义
|. ^------ 10.10.10.10. # 定义了10.10.10.10的实例级配置项 (覆盖全局/集群配置项定义)
|
^- pgsql # 集群成员定义/实例级配置项(此目录名称随意)
^------ pg-meta.yml # pg-meta成员与实例配置项(覆盖全局/集群配置项定义)
^------ pg-test.yml # pg-test成员与实例配置项(覆盖全局/集群配置项定义)
^------ <cluster>.yml # <pg_cluster>成员与实例配置项(覆盖全局/集群配置项定义)
6.2 - Config Entry
Introduction to 156 config entries about pigsty
配置项分类
Pigsty的配置项按照负责的领域可以分为以下10个大类。
配置项粒度
Pigsty的参数可以在不同的粒度进行配置。
Pigsty默认提供三种粒度:全局,集群,实例。
在Pigsty的配置文件中,配置项 可以出现在三种位置。
| 粒度 |
范围 |
优先级 |
说明 |
位置 |
| Global |
全局 |
低 |
在同一套部署环境内一致 |
all.vars.xxx |
| Cluster |
集群 |
中 |
在同一套集群内保持一致 |
all.children.<cls>.vars.xxx |
| Instance |
实例 |
高 |
最细粒度的配置层次 |
all.children.<cls>.hosts.<ins>.xxx |
每一个配置项都由一对键值组成。键是配置项的名称,值是配置项的内容。值的类型各异
集群vars中定义的配置项会以同名键覆盖的方式覆盖全局配置项,实例中定义的配置项又会覆盖集群配置项与全局配置项。因此用户可以有的放矢,可以在不同层次,不同粒度上针对具体集群与具体实例进行精细配置。
除了配置项粒度中指定的三种配置粒度,Pigsty配置项目中还有两种额外的优先级。
- 默认:当一个配置项在全局/集群/实例级别都没有出现时,将使用默认配置项。默认值的优先级最低,所有配置项都有默认值。
- 参数:当用户通过命令行传入参数时,参数指定的配置项具有最高优先级,将覆盖一切层次的配置。一些配置项只能通过命令行参数的方式指定与使用。
| 层级 |
来源 |
优先级 |
说明 |
位置 |
| Default |
默认 |
最低 |
代码逻辑定义的默认值 |
roles/<role>/default/main.yml |
| Global |
全局 |
低 |
在同一套部署环境内一致 |
all.vars.xxx |
| Cluster |
集群 |
中 |
在同一套集群内保持一致 |
all.children.<cls>.vars.xxx |
| Instance |
实例 |
高 |
最细粒度的配置层次 |
all.children.<cls>.hosts.<ins>.xxx |
| Argument |
参数 |
最高 |
通过命令行参数传入 |
-e |
配置项列表
6.3 - Connect
parameters about connection info and proxy settings
参数概览
参数详解
proxy_env
在某些受到“互联网封锁”的地区,有些软件的下载会受到影响。
例如,从中国大陆访问PostgreSQL的官方源,下载速度可能只有几KB每秒。但如果使用了合适的HTTP代理,则可以达到几MB每秒。因此如果用户有代理服务器,请通过proxy_env进行配置,样例如下:
proxy_env: # global proxy env when downloading packages
http_proxy: 'http://username:password@proxy.address.com'
https_proxy: 'http://username:password@proxy.address.com'
all_proxy: 'http://username:password@proxy.address.com'
no_proxy: "localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.aliyuncs.com,mirrors.tuna.tsinghua.edu.cn,mirrors.zju.edu.cn"
ansible_host
如果用户的环境使用了跳板机,或者进行了某些定制化修改,无法通过简单的ssh <ip>方式访问,那么可以考虑使用Ansible的连接参数。ansible_host是ansiblel连接参数中最典型的一个。
Ansible中关于SSH连接的参数
-
ansible_host
The name of the host to connect to, if different from the alias you wish to give to it.
-
ansible_port
The ssh port number, if not 22
-
ansible_user
The default ssh user name to use.
-
ansible_ssh_pass
The ssh password to use (never store this variable in plain text; always use a vault. See Variables and Vaults)
-
ansible_ssh_private_key_file
Private key file used by ssh. Useful if using multiple keys and you don’t want to use SSH agent.
-
ansible_ssh_common_args
This setting is always appended to the default command line for sftp, scp, and ssh. Useful to configure a ProxyCommand for a certain host (or group).
-
ansible_sftp_extra_args
This setting is always appended to the default sftp command line.
-
ansible_scp_extra_args
This setting is always appended to the default scp command line.
-
ansible_ssh_extra_args
This setting is always appended to the default ssh command line.
-
ansible_ssh_pipelining
Determines whether or not to use SSH pipelining. This can override the pipelining setting in ansible.cfg.
最简单的用法是将ssh alias配置为ansible_host,只要用户可以通过 ssh <name>的方式访问目标机器,那么将ansible_host配置为<name>即可。
注意这些变量都是实例级别的变量。
Caveat
请注意,沙箱环境的默认配置使用了 SSH 别名 作为连接参数,这是因为vagrant宿主机访问虚拟机时使用了SSH别名配置。生产环境建议直接使用IP连接。
pg-meta:
hosts:
10.10.10.10: {pg_seq: 1, pg_role: primary, ansible_host: meta}
6.4 - Local Repo
Parameters about local yum repo: content, where to download, etc
Pigsty是一个复杂的软件系统,为了确保系统的稳定,Pigsty会在初始化过程中从互联网下载所有依赖的软件包并建立本地Yum源。
所有依赖的软件总大小约1GB左右,下载速度取决于您的网络情况。尽管Pigsty已经尽量使用镜像源以加速下载,但少量包的下载仍可能受到防火墙的阻挠,可能出现非常慢的情况。您可以通过proxy_env配置项设置下载代理以完成首次下载,或直接下载预先打包好的离线安装包。
建立本地Yum源时,如果{{ repo_home }}/{{ repo_name }}目录已经存在,而且里面有repo_complete的标记文件,Pigsty会认为本地Yum源已经初始化完毕,因此跳过软件下载阶段,显著加快速度。离线安装包即是把{{ repo_home }}/{{ repo_name }}目录整个打成压缩包。
参数概览
默认参数
repo_enabled: true # 是否启用本地源功能
repo_name: pigsty # 本地源名称
repo_address: yum.pigsty # 外部可访问的源地址 (ip:port 或 url)
repo_port: 80 # 源HTTP服务器监听地址
repo_home: /www # 默认根目录
repo_rebuild: false # 强制重新下载软件包
repo_remove: true # 移除已有的yum源
repo_upstreams: [...] # 上游Yum源
repo_packages: [...] # 需要下载的软件包
repo_url_packages: [...] # 通过URL下载的软件
参数详解
repo_enabled
如果为true(默认情况),执行正常的本地yum源创建流程,否则跳过构建本地yum源的操作。
repo_name
本地yum源的名称,默认为pigsty,您可以改为自己喜欢的名称,例如pgsql-rhel7等。
repo_address
本地yum源对外提供服务的地址,可以是域名也可以是IP地址,默认为yum.pigsty。
如果使用域名,您必须确保在当前环境中该域名会解析到本地源所在的服务器,也就是元节点。
如果您的本地yum源没有使用标准的80端口,您需要在地址中加入端口,并与repo_port变量保持一致。
您可以通过节点参数中的静态DNS配置来为环境中的所有节点写入Pigsty本地源的域名,沙箱环境中即是采用这种方式来解析默认的yum.pigsty域名。
repo_port
本地yum源使用的HTTP端口,默认为80端口。
repo_home
本地yum源的根目录,默认为www。
该目录将作为HTTP服务器的根对外暴露。
repo_rebuild
如果为false(默认情况),什么都不发生,如果为true,那么在任何情况下都会执行Repo重建的工作。
repo_remove
在执行本地源初始化的过程中,是否移除/etc/yum.repos.d中所有已有的repo?默认为true。
原有repo文件会备份至/etc/yum.repos.d/backup中。
因为操作系统已有的源内容不可控,建议强制移除并通过repo_upstreams进行显式配置。
repo_upstream
所有添加到/etc/yum.repos.d中的Yum源,Pigsty将从这些源中下载软件。
Pigsty默认使用阿里云的CentOS7镜像源,清华大学Grafana镜像源,PackageCloud的Prometheus源,PostgreSQL官方源,以及SCLo,Harbottle,Nginx, Haproxy等软件源。
- name: base
description: CentOS-$releasever - Base - Aliyun Mirror
baseurl:
- http://mirrors.aliyun.com/centos/$releasever/os/$basearch/
- http://mirrors.aliyuncs.com/centos/$releasever/os/$basearch/
- http://mirrors.cloud.aliyuncs.com/centos/$releasever/os/$basearch/
gpgcheck: no
failovermethod: priority
- name: updates
description: CentOS-$releasever - Updates - Aliyun Mirror
baseurl:
- http://mirrors.aliyun.com/centos/$releasever/updates/$basearch/
- http://mirrors.aliyuncs.com/centos/$releasever/updates/$basearch/
- http://mirrors.cloud.aliyuncs.com/centos/$releasever/updates/$basearch/
gpgcheck: no
failovermethod: priority
- name: extras
description: CentOS-$releasever - Extras - Aliyun Mirror
baseurl:
- http://mirrors.aliyun.com/centos/$releasever/extras/$basearch/
- http://mirrors.aliyuncs.com/centos/$releasever/extras/$basearch/
- http://mirrors.cloud.aliyuncs.com/centos/$releasever/extras/$basearch/
gpgcheck: no
failovermethod: priority
- name: epel
description: CentOS $releasever - EPEL - Aliyun Mirror
baseurl: http://mirrors.aliyun.com/epel/$releasever/$basearch
gpgcheck: no
failovermethod: priority
- name: grafana
description: Grafana - TsingHua Mirror
gpgcheck: no
baseurl: https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm
- name: prometheus
description: Prometheus and exporters
gpgcheck: no
baseurl: https://packagecloud.io/prometheus-rpm/release/el/$releasever/$basearch
- name: pgdg-common
description: PostgreSQL common RPMs for RHEL/CentOS $releasever - $basearch
gpgcheck: no
baseurl: https://download.postgresql.org/pub/repos/yum/common/redhat/rhel-$releasever-$basearch
- name: pgdg13
description: PostgreSQL 13 for RHEL/CentOS $releasever - $basearch - Updates testing
gpgcheck: no
baseurl: https://download.postgresql.org/pub/repos/yum/13/redhat/rhel-$releasever-$basearch
- name: centos-sclo
description: CentOS-$releasever - SCLo
gpgcheck: no
mirrorlist: http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-sclo
- name: centos-sclo-rh
description: CentOS-$releasever - SCLo rh
gpgcheck: no
mirrorlist: http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-rh
- name: nginx
description: Nginx Official Yum Repo
skip_if_unavailable: true
gpgcheck: no
baseurl: http://nginx.org/packages/centos/$releasever/$basearch/
- name: haproxy
description: Copr repo for haproxy
skip_if_unavailable: true
gpgcheck: no
baseurl: https://download.copr.fedorainfracloud.org/results/roidelapluie/haproxy/epel-$releasever-$basearch/
# for latest consul & kubernetes
- name: harbottle
description: Copr repo for main owned by harbottle
skip_if_unavailable: true
gpgcheck: no
baseurl: https://download.copr.fedorainfracloud.org/results/harbottle/main/epel-$releasever-$basearch/
repo_packages
需要下载的rpm安装包列表,默认下载的软件包如下所示:
# - what to download - #
repo_packages:
# repo bootstrap packages
- epel-release nginx wget yum-utils yum createrepo # bootstrap packages
# node basic packages
- ntp chrony uuid lz4 nc pv jq vim-enhanced make patch bash lsof wget unzip git tuned # basic system util
- readline zlib openssl libyaml libxml2 libxslt perl-ExtUtils-Embed ca-certificates # basic pg dependency
- numactl grubby sysstat dstat iotop bind-utils net-tools tcpdump socat ipvsadm telnet # system utils
# dcs & monitor packages
- grafana prometheus2 pushgateway alertmanager # monitor and ui
- node_exporter postgres_exporter nginx_exporter blackbox_exporter # exporter
- consul consul_exporter consul-template etcd # dcs
# python3 dependencies
- ansible python python-pip python-psycopg2 # ansible & python
- python3 python3-psycopg2 python36-requests python3-etcd python3-consul # python3
- python36-urllib3 python36-idna python36-pyOpenSSL python36-cryptography # python3 patroni extra deps
# proxy and load balancer
- haproxy keepalived dnsmasq # proxy and dns
# postgres common Packages
- patroni patroni-consul patroni-etcd pgbouncer pg_cli pgbadger pg_activity # major components
- pgcenter boxinfo check_postgres emaj pgbconsole pg_bloat_check pgquarrel # other common utils
- barman barman-cli pgloader pgFormatter pitrery pspg pgxnclient PyGreSQL pgadmin4 tail_n_mail
# postgres 13 packages
- postgresql13* postgis31* citus_13 pgrouting_13 # postgres 13 and postgis 31
- pg_repack13 pg_squeeze13 # maintenance extensions
- pg_qualstats13 pg_stat_kcache13 system_stats_13 bgw_replstatus13 # stats extensions
- plr13 plsh13 plpgsql_check_13 plproxy13 plr13 plsh13 plpgsql_check_13 pldebugger13 # PL extensions # pl extensions
- hdfs_fdw_13 mongo_fdw13 mysql_fdw_13 ogr_fdw13 redis_fdw_13 pgbouncer_fdw13 # FDW extensions
- wal2json13 count_distinct13 ddlx_13 geoip13 orafce13 # MISC extensions
- rum_13 hypopg_13 ip4r13 jsquery_13 logerrors_13 periods_13 pg_auto_failover_13 pg_catcheck13
- pg_fkpart13 pg_jobmon13 pg_partman13 pg_prioritize_13 pg_track_settings13 pgaudit15_13
- pgcryptokey13 pgexportdoc13 pgimportdoc13 pgmemcache-13 pgmp13 pgq-13
- pguint13 pguri13 prefix13 safeupdate_13 semver13 table_version13 tdigest13
repo_url_packages
采用URL直接下载,而非yum下载的软件包。您可以将自定义的软件包连接添加到这里。
Pigsty默认会通过URL下载三款软件:
pg_exporter(必须,监控系统核心组件)vip-manager(可选,启用VIP时必须)polysh(可选,多机管理便捷工具)
repo_url_packages:
- https://github.com/Vonng/pg_exporter/releases/download/v0.3.1/pg_exporter-0.3.1-1.el7.x86_64.rpm
- https://github.com/cybertec-postgresql/vip-manager/releases/download/v0.6/vip-manager_0.6-1_amd64.rpm
- http://guichaz.free.fr/polysh/files/polysh-0.4-1.noarch.rpm
6.5 - Node Provision
Parameters about os, machine, infrastructure on all nodes
Pigsty中关于机器与操作系统、基础设施的配置参数
参数概览
默认配置
#------------------------------------------------------------------------------
# NODE PROVISION
#------------------------------------------------------------------------------
# this section defines how to provision nodes
# nodename: # if defined, node's hostname will be overwritten
# - node dns - #
node_dns_hosts: # static dns records in /etc/hosts
- 10.10.10.10 yum.pigsty
node_dns_server: add # add (default) | none (skip) | overwrite (remove old settings)
node_dns_servers: # dynamic nameserver in /etc/resolv.conf
- 10.10.10.10
node_dns_options: # dns resolv options
- options single-request-reopen timeout:1 rotate
- domain service.consul
# - node repo - #
node_repo_method: local # none|local|public (use local repo for production env)
node_repo_remove: true # whether remove existing repo
# local repo url (if method=local, make sure firewall is configured or disabled)
node_local_repo_url:
- http://yum.pigsty/pigsty.repo
# - node packages - #
node_packages: # common packages for all nodes
- wget,yum-utils,ntp,chrony,tuned,uuid,lz4,vim-minimal,make,patch,bash,lsof,wget,unzip,git,readline,zlib,openssl
- numactl,grubby,sysstat,dstat,iotop,bind-utils,net-tools,tcpdump,socat,ipvsadm,telnet,tuned,pv,jq
- python3,python3-psycopg2,python36-requests,python3-etcd,python3-consul
- python36-urllib3,python36-idna,python36-pyOpenSSL,python36-cryptography
- node_exporter,consul,consul-template,etcd,haproxy,keepalived,vip-manager
node_extra_packages: # extra packages for all nodes
- patroni,patroni-consul,patroni-etcd,pgbouncer,pgbadger,pg_activity
node_meta_packages: # packages for meta nodes only
- grafana,prometheus2,alertmanager,nginx_exporter,blackbox_exporter,pushgateway
- dnsmasq,nginx,ansible,pgbadger,polysh
# - node features - #
node_disable_numa: false # disable numa, important for production database, reboot required
node_disable_swap: false # disable swap, important for production database
node_disable_firewall: true # disable firewall (required if using kubernetes)
node_disable_selinux: true # disable selinux (required if using kubernetes)
node_static_network: true # keep dns resolver settings after reboot
node_disk_prefetch: false # setup disk prefetch on HDD to increase performance
# - node kernel modules - #
node_kernel_modules:
- softdog
- br_netfilter
- ip_vs
- ip_vs_rr
- ip_vs_rr
- ip_vs_wrr
- ip_vs_sh
- nf_conntrack_ipv4
# - node tuned - #
node_tune: tiny # install and activate tuned profile: none|oltp|olap|crit|tiny
node_sysctl_params: # set additional sysctl parameters, k:v format
net.bridge.bridge-nf-call-iptables: 1 # for kubernetes
# - node user - #
node_admin_setup: true # setup an default admin user ?
node_admin_uid: 88 # uid and gid for admin user
node_admin_username: admin # default admin user
node_admin_ssh_exchange: true # exchange ssh key among cluster ?
node_admin_pks: # public key list that will be installed
- 'ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAAAgQC7IMAMNavYtWwzAJajKqwdn3ar5BhvcwCnBTxxEkXhGlCO2vfgosSAQMEflfgvkiI5nM1HIFQ8KINlx1XLO7SdL5KdInG5LIJjAFh0pujS4kNCT9a5IGvSq1BrzGqhbEcwWYdju1ZPYBcJm/MG+JD0dYCh8vfrYB/cYMD0SOmNkQ== vagrant@pigsty.com'
# - node ntp - #
node_ntp_service: ntp # ntp or chrony
node_ntp_config: true # overwrite existing ntp config?
node_timezone: Asia/Shanghai # default node timezone
node_ntp_servers: # default NTP servers
- pool cn.pool.ntp.org iburst
- pool pool.ntp.org iburst
- pool time.pool.aliyun.com iburst
- server 10.10.10.10 iburst
参数详解
nodename
如果配置了该参数,那么实例的HOSTNAM将会被该名称覆盖。
该选项可用于为节点显式指定名称。如果要使用PG的实例名称作为节点名称,可以使用pg_hostname选项
node_dns_hosts
机器节点的默认静态DNS解析记录,每一条记录都会在机器节点初始化时写入/etc/hosts中,特别适合用于配置基础设施地址。
node_dns_hosts是一个数组,每一个元素都是形如ip domain_name的字符串,代表一条DNS解析记录。
默认情况下,Pigsty会向/etc/hosts中写入10.10.10.10 yum.pigsty,这样可以在DNS Nameserver启动之前,采用域名的方式访问本地yum源。
node_dns_server
机器节点默认的动态DNS服务器的配置方式,有三种模式:
add:将node_dns_servers中的记录追加至/etc/resolv.conf,并保留已有DNS服务器。(默认)overwrite:使用将node_dns_servers中的记录覆盖/etc/resolv.confnone:跳过DNS服务器配置
node_dns_servers
如果node_dns_server配置为add或overwrite,则node_dns_servers中的记录会被追加或覆盖至/etc/resolv.conf中。具体格式请参考Linux文档关于/etc/resolv.conf的说明。
Pigsty默认会添加元节点作为DNS Server,元节点上的DNSMASQ会响应环境中的DNS请求。
node_dns_servers: # dynamic nameserver in /etc/resolv.conf
- 10.10.10.10
node_dns_options
如果node_dns_server配置为add或overwrite,则node_dns_options中的记录会被追加或覆盖至/etc/resolv.conf中。具体格式请参考Linux文档关于/etc/resolv.conf的说明
Pigsty默认添加的解析选项为:
- options single-request-reopen timeout:1 rotate
- domain service.consul
node_repo_method
机器节点Yum软件源的配置方式,有三种模式:
local:使用元节点上的本地Yum源,默认行为,推荐。public:直接使用互联网源安装,将repo_upstream中的公共repo写入/etc/yum.repos.d/none:不对本地源进行配置与修改。
node_repo_remove
原有Yum源的处理方式,是否移除节点上原有的Yum源?
Pigsty默认会移除/etc/yum.repos.d中原有的配置文件,并备份至/etc/yum.repos.d/backup
node_local_repo_url
如果node_repo_method配置为local,则这里列出的Repo文件URL会被下载至/etc/yum.repos.d中
这里是一个Repo File URL 构成的数组,Pigsty默认会将元节点上的本地Yum源加入机器的源配置中。
node_local_repo_url:
- http://yum.pigsty/pigsty.repo
node_packages
通过yum安装的软件包列表。
软件包列表为数组,但每个元素可以包含由逗号分隔的多个软件包,Pigsty默认安装的软件包列表如下:
node_packages: # common packages for all nodes
- wget,yum-utils,ntp,chrony,tuned,uuid,lz4,vim-minimal,make,patch,bash,lsof,wget,unzip,git,readline,zlib,openssl
- numactl,grubby,sysstat,dstat,iotop,bind-utils,net-tools,tcpdump,socat,ipvsadm,telnet,tuned,pv,jq
- python3,python3-psycopg2,python36-requests,python3-etcd,python3-consul
- python36-urllib3,python36-idna,python36-pyOpenSSL,python36-cryptography
- node_exporter,consul,consul-template,etcd,haproxy,keepalived,vip-manager
通过yum安装的额外软件包列表。
与node_packages类似,但node_packages通常是全局统一配置,而node_extra_packages则是针对具体节点进行例外处理。例如,您可以为运行PG的节点安装额外的工具包。该变量通常在集群和实例级别进行覆盖定义。
Pigsty默认安装的额外软件包列表如下:
- patroni,patroni-consul,patroni-etcd,pgbouncer,pgbadger,pg_activity
通过yum安装的元节点软件包列表。
与node_packages和node_extra_packages类似,但node_meta_packages中列出的软件包只会在元节点上安装。因此通常都是监控软件,管理工具,构建工具等。
Pigsty默认安装的元节点软件包列表如下:
node_meta_packages: # packages for meta nodes only
- grafana,prometheus2,alertmanager,nginx_exporter,blackbox_exporter,pushgateway
- dnsmasq,nginx,ansible,pgbadger,polysh
node_disable_numa
是否关闭Numa,注意,该选项需要重启后生效!默认不关闭,但生产环境强烈建议关闭NUMA。
node_disable_swap
是否禁用SWAP,如果您有足够的内存,且数据库采用独占式部署,建议直接关闭SWAP提高性能,默认关闭。
node_disable_firewall
是否关闭防火墙,这个东西非常讨厌,建议关闭,默认关闭。
node_disable_selinux
是否关闭SELinux,这个东西非常讨厌,建议关闭,默认关闭。
node_static_network
是否采用静态网络配置,默认启用
启用静态网络,意味着您的DNS Resolv配置不会因为机器重启与网卡变动被覆盖。建议启用。
node_disk_prefetch
是否启用磁盘预读?
针对HDD部署的实例可以优化吞吐量,默认关闭。
node_kernel_modules
需要安装的内核模块
Pigsty默认会启用以下内核模块
node_kernel_modules: [softdog, ip_vs, ip_vs_rr, ip_vs_rr, ip_vs_wrr, ip_vs_sh]
node_tune
针对机器进行调优的预制方案
node_sysctl_params
修改sysctl系统参数
字典KV结构
node_admin_setup
是否在每个节点上创建管理员用户(免密sudo与ssh),默认会创建。
Pigsty默认会创建名为admin (uid=88)的管理用户,可以从元节点上通过SSH免密访问环境中的其他节点并执行免密sudo。
node_admin_uid
管理员用户的uid,默认为88
node_admin_username
管理员用户的名称,默认为admin
node_admin_ssh_exchange
是否在当前执行命令的机器之间相互交换管理员用户的SSH密钥?
默认会执行交换,这样管理员可以在机器间快速跳转。
node_admin_pks
写入到管理员~/.ssh/authorized_keys中的密钥
持有对应私钥的用户可以以管理员身份登陆。
node_ntp_service
指明系统使用的NTP服务类型:
ntp:传统NTP服务chrony:CentOS 7/8默认使用的时间服务
node_ntp_config
是否覆盖现有NTP配置?
布尔选项,默认覆盖。
node_timezone
默认使用的时区
Pigsty默认使用Asia/Shanghai,请根据您的实际情况调整。
node_ntp_servers
NTP服务器地址
Pigsty默认会使用以下NTP服务器
- pool cn.pool.ntp.org iburst
- pool pool.ntp.org iburst
- pool time.pool.aliyun.com iburst
- server 10.10.10.10 iburst
6.6 - Infrastructure
Parameteres about infrastructures
这一节定义了部署于元节点上的 基础设施 ,包括:
参数概览
默认参数
#------------------------------------------------------------------------------
# META PROVISION
#------------------------------------------------------------------------------
# - ca - #
ca_method: create # create|copy|recreate
ca_subject: "/CN=root-ca" # self-signed CA subject
ca_homedir: /ca # ca cert directory
ca_cert: ca.crt # ca public key/cert
ca_key: ca.key # ca private key
# - nginx - #
nginx_upstream:
- { name: home, host: pigsty, url: "127.0.0.1:3000"}
- { name: consul, host: c.pigsty, url: "127.0.0.1:8500" }
- { name: grafana, host: g.pigsty, url: "127.0.0.1:3000" }
- { name: prometheus, host: p.pigsty, url: "127.0.0.1:9090" }
- { name: alertmanager, host: a.pigsty, url: "127.0.0.1:9093" }
- { name: haproxy, host: h.pigsty, url: "127.0.0.1:9091" }
# - nameserver - #
dns_records: # dynamic dns record resolved by dnsmasq
- 10.10.10.2 pg-meta # sandbox vip for pg-meta
- 10.10.10.3 pg-test # sandbox vip for pg-test
- 10.10.10.10 meta-1 # sandbox node meta-1 (node-0)
- 10.10.10.11 node-1 # sandbox node node-1
- 10.10.10.12 node-2 # sandbox node node-2
- 10.10.10.13 node-3 # sandbox node node-3
- 10.10.10.10 pigsty
- 10.10.10.10 y.pigsty yum.pigsty
- 10.10.10.10 c.pigsty consul.pigsty
- 10.10.10.10 g.pigsty grafana.pigsty
- 10.10.10.10 p.pigsty prometheus.pigsty
- 10.10.10.10 a.pigsty alertmanager.pigsty
- 10.10.10.10 n.pigsty ntp.pigsty
- 10.10.10.10 h.pigsty haproxy.pigsty
# - prometheus - #
prometheus_data_dir: /export/prometheus/data # prometheus data dir
prometheus_options: '--storage.tsdb.retention=30d'
prometheus_reload: false # reload prometheus instead of recreate it
prometheus_sd_method: consul # service discovery method: static|consul|etcd
prometheus_scrape_interval: 2s # global scrape & evaluation interval
prometheus_scrape_timeout: 1s # scrape timeout
prometheus_sd_interval: 2s # service discovery refresh interval
# - grafana - #
grafana_url: http://admin:admin@10.10.10.10:3000 # grafana url
grafana_admin_password: admin # default grafana admin user password
grafana_plugin: install # none|install|reinstall
grafana_cache: /www/pigsty/grafana/plugins.tar.gz # path to grafana plugins tarball
grafana_customize: true # customize grafana resources
grafana_plugins: # default grafana plugins list
- redis-datasource
- simpod-json-datasource
- fifemon-graphql-datasource
- sbueringer-consul-datasource
- camptocamp-prometheus-alertmanager-datasource
- ryantxu-ajax-panel
- marcusolsson-hourly-heatmap-panel
- michaeldmoore-multistat-panel
- marcusolsson-treemap-panel
- pr0ps-trackmap-panel
- dalvany-image-panel
- magnesium-wordcloud-panel
- cloudspout-button-panel
- speakyourcode-button-panel
- jdbranham-diagram-panel
- grafana-piechart-panel
- snuids-radar-panel
- digrich-bubblechart-panel
grafana_git_plugins:
- https://github.com/Vonng/grafana-echarts
参数详解
ca_method
- create:创建新的公私钥用于CA
- copy:拷贝现有的CA公私钥用于构建CA
ca_subject
CA自签名的主题
默认主题为:
"/CN=root-ca"
ca_homedir
CA文件的根目录
默认为/ca
ca_cert
CA公钥证书名称
默认为:ca.crt
ca_key
CA私钥文件名称
默认为ca.key
nginx_upstream
Nginx上游服务的URL与域名
Nginx会通过Host进行流量转发,因此确保访问Pigsty基础设施服务时,配置有正确的域名。
不要修改name 部分的定义。
nginx_upstream:
- { name: home, host: pigsty, url: "127.0.0.1:3000"}
- { name: consul, host: c.pigsty, url: "127.0.0.1:8500" }
- { name: grafana, host: g.pigsty, url: "127.0.0.1:3000" }
- { name: prometheus, host: p.pigsty, url: "127.0.0.1:9090" }
- { name: alertmanager, host: a.pigsty, url: "127.0.0.1:9093" }
- { name: haproxy, host: h.pigsty, url: "127.0.0.1:9091" }
dns_records
动态DNS解析记录
每一条记录都会写入元节点的/etc/hosts中,并由元节点上的域名服务器提供解析。
prometheus_data_dir
Prometheus数据目录
默认位于/export/prometheus/data
prometheus_options
Prometheus命令行参数
默认参数为:--storage.tsdb.retention=30d,即保留30天的监控数据
参数prometheus_retention的功能被此参数覆盖,于v0.6后弃用。
prometheus_reload
如果为true,执行Prometheus任务时不会清除已有数据目录。
默认为:false,即执行prometheus剧本时会清除已有监控数据。
prometheus_sd_method
Prometheus使用的服务发现机制,默认为consul,可选项:
consul:基于Consul进行服务发现static:基于本地配置文件进行服务发现
Pigsty建议使用consul服务发现,当服务器发生Failover时,监控系统会自动更正目标实例所注册的身份。
static服务发现依赖/etc/prometheus/targets/*.yml中的配置进行服务发现。采用这种方式的优势是不依赖Consul。当Pigsty监控系统与外部管控方案集成时,这种模式对原系统的侵入性较小。同时,当集群内发生主从切换时,您需要自行维护实例角色信息。
手动维护时,可以根据以下命令从配置文件生成Prometheus所需的监控对象配置文件。
./infra.yml --tags=prometheus_targtes,prometheus_reload
详细信息请参考:服务发现
prometheus_sd_target(过时)
目前Pigsty中Prometheus的服务发现对象统一采用集群模式管理,不再提供配置。
当 prometheus_sd_method == 'static' 时,监控目标定义文件管理的方式:
batch:使用批量管理的单一配置文件:/etc/prometheus/targets/all.ymlsingle:使用每个实例一个的配置文件:/etc/prometheus/targets/{{ pg_instance }}.yml
使用批量管理的单一配置文件管理简单,但用户必须使用默认的单一配置文件方式(即所有数据库集群的定义都在同一个配置文件中),才可以使用这种管理方式。
当使用分立式的配置文件(每个集群一个配置文件)时,用户需要使用 single 管理模式。每一个新数据库实例都会在元节点的 /etc/prometheus/targets/ 目录下创建一个新的定义文件。
prometheus_scrape_interval
Prometheus抓取周期
默认为2s,建议在生产环境中使用15s。
prometheus_scrape_timeout
Prometheus抓取超时
默认为1s,建议在生产环境中使用10s,或根据实际需求进行配置。
prometheus_sd_interval
Prometheus刷新服务发现列表的周期
默认为5s,建议在生产环境中使用更长的间隔,或根据实际需求进行配置。
prometheus_metrics_path (弃用)
Prometheus 抓取指标暴露器的URL路径,默认为/metrics
已经被外部变量引用exporter_metrics_path所替代,不再生效。
prometheus_retention(弃用)
Prometheus数据保留期限,默认配置30天
参数prometheus_retention的功能被参数prometheus_options覆盖,于v0.6后弃用。
grafana_url
Grafana对外提供服务的端点,需要带上用户名与密码。
Grafana Provision的过程中会使用该URL调用Grafana API
grafana_admin_password
Grafana管理用户的密码
默认为admin
grafana_plugin
Grafana插件的供给方式
none:不安装插件install: 安装Grafana插件(默认)reinstall: 强制重新安装Grafana插件
Grafana需要访问互联网以下载若干扩展插件,如果您的元节点没有互联网访问,离线安装包中已经包含了所有下载好的Grafana插件。Pigsty会在插件下载完成后重新制作新的插件缓存安装包。
grafana_cache
Grafana插件缓存文件地址
离线安装包中已经包含了所有下载并打包好的Grafana插件,如果插件包目录已经存在,Pigsty就不会尝试从互联网重新下载Grafana插件。
默认的离线插件缓存地址为:/www/pigsty/grafana/plugins.tar.gz (假设本地Yum源名为pigsty)
grafana_customize
标记,是否要定制Grafana
如果选择是,Grafana的Logo会被替换为Pigsty,你懂的。
grafana_plugins
Grafana插件列表
数组,每个元素是一个插件名称。
插件会通过grafana-cli plugins install的方式进行安装。
默认安装的插件有:
grafana_plugins: # default grafana plugins list
- redis-datasource
- simpod-json-datasource
- fifemon-graphql-datasource
- sbueringer-consul-datasource
- camptocamp-prometheus-alertmanager-datasource
- ryantxu-ajax-panel
- marcusolsson-hourly-heatmap-panel
- michaeldmoore-multistat-panel
- marcusolsson-treemap-panel
- pr0ps-trackmap-panel
- dalvany-image-panel
- magnesium-wordcloud-panel
- cloudspout-button-panel
- speakyourcode-button-panel
- jdbranham-diagram-panel
- grafana-piechart-panel
- snuids-radar-panel
- digrich-bubblechart-panel
grafana_git_plugins
Grafana的Git插件
一些插件无法通过官方命令行下载,但可以通过Git Clone的方式下载,则可以考虑使用本参数。
数组,每个元素是一个插件名称。
插件会通过cd /var/lib/grafana/plugins && git clone 的方式进行安装。
默认会下载一个可视化插件:
grafana_git_plugins:
- https://github.com/Vonng/grafana-echarts
6.7 - DCS
Parameters about distributed configuration storage
Pigsty使用DCS(Distributive Configuration Storage)作为元数据库。DCS有三个重要作用:
- 主库选举:Patroni基于DCS进行选举与切换
- 配置管理:Patroni使用DCS管理Postgres的配置
- 身份管理:监控系统基于DCS管理并维护数据库实例的身份信息。
DCS对于数据库的稳定至关重要,Pigsty出于演示目的提供了基本的Consul与Etcd支持,在元节点部署了DCS服务。建议在生产环境中使用专用机器部署专用DCS集群。
参数概览
默认参数
#------------------------------------------------------------------------------
# DCS PROVISION
#------------------------------------------------------------------------------
service_registry: consul # where to register services: none | consul | etcd | both
dcs_type: consul # consul | etcd | both
dcs_name: pigsty # consul dc name | etcd initial cluster token
dcs_servers: # dcs server dict in name:ip format
meta-1: 10.10.10.10 # you could use existing dcs cluster
# meta-2: 10.10.10.11 # host which have their IP listed here will be init as server
# meta-3: 10.10.10.12 # 3 or 5 dcs nodes are recommend for production environment
dcs_exists_action: skip # abort|skip|clean if dcs server already exists
dcs_disable_purge: false # set to true to disable purge functionality for good (force dcs_exists_action = abort)
consul_data_dir: /var/lib/consul # consul data dir (/var/lib/consul by default)
etcd_data_dir: /var/lib/etcd # etcd data dir (/var/lib/consul by default)
参数详解
service_registry
服务注册的地址,被多个组件引用。
none:不执行服务注册(当执行仅监控部署时,必须指定none模式)consul:将服务注册至Consul中etcd:将服务注册至Etcd中(尚未支持)
dcs_type
DCS类型,有两种选项:
dcs_name
DCS集群名称
默认为pigsty
在Consul中代表 DataCenter名称
dcs_servers
DCS服务器名称与地址,采用字典格式,Key为DCS服务器实例名称,Value为对应的IP地址。
可以使用外部的已有DCS服务器,也可以在目标机器上初始化新的DCS服务器。
如果采用初始化新DCS实例的方式,建议先在所有DCS Server(通常也是元节点)上完成DCS初始化。
尽管您也可以一次性初始化所有的DCS Server与DCS Agent,但必须在完整初始化时将所有Server囊括在内。此时所有IP地址匹配dcs_servers项的目标机器将会在DCS初始化过程中,初始化为DCS Server。
强烈建议使用奇数个DCS Server,演示环境可使用单个DCS Server,生产环境建议使用3~5个确保DCS可用性。
您必须根据实际情况显式配置DCS Server,例如在沙箱环境中,您可以选择启用1个或3个DCS节点。
dcs_servers:
meta-1: 10.10.10.10
meta-2: 10.10.10.11
meta-3: 10.10.10.12
dcs_exists_action
安全保险,当Consul实例已经存在时,系统应当执行的动作
- abort: 中止整个剧本的执行(默认行为)
- clean: 抹除现有DCS实例并继续(极端危险)
- skip: 忽略存在DCS实例的目标(中止),在其他目标机器上继续执行。
如果您真的需要强制清除已经存在的DCS实例,建议先使用pgsql-rm.yml完成集群与实例的下线与销毁,在重新执行初始化。否则,则需要通过命令行参数-e dcs_exists_action=clean完成覆写,强制在初始化过程中抹除已有实例。
dcs_disable_purge
双重安全保险,默认为false。如果为true,强制设置dcs_exists_action变量为abort。
等效于关闭dcs_exists_action的清理功能,确保任何情况下DCS实例都不会被抹除。
consul_data_dir
Consul数据目录地址
默认为/var/lib/consul
etcd_data_dir
Etcd数据目录地址
默认为/var/lib/etcd
6.8 - PG Install
Parameters about postgres installation
PG Install 部分负责在一台装有基本软件的机器上完成所有PostgreSQL依赖项的安装。用户可以配置数据库超级用户的名称、ID、权限、访问,配置安装所用的源,配置安装地址,安装的版本,所需的软件包与扩展插件。
这里的大多数参数只需要在整体升级数据库大版本时修改,用户可以通过pg_version指定需要安装的软件版本,并在集群层面进行覆盖,为不同的集群安装不同的数据库版本。
参数概览
默认参数
#------------------------------------------------------------------------------
# POSTGRES INSTALLATION
#------------------------------------------------------------------------------
# - dbsu - #
pg_dbsu: postgres # os user for database, postgres by default (change it is not recommended!)
pg_dbsu_uid: 26 # os dbsu uid and gid, 26 for default postgres users and groups
pg_dbsu_sudo: limit # none|limit|all|nopass (Privilege for dbsu, limit is recommended)
pg_dbsu_home: /var/lib/pgsql # postgresql binary
pg_dbsu_ssh_exchange: false # exchange ssh key among same cluster
# - postgres packages - #
pg_version: 13 # default postgresql version
pgdg_repo: false # use official pgdg yum repo (disable if you have local mirror)
pg_add_repo: false # add postgres related repo before install (useful if you want a simple install)
pg_bin_dir: /usr/pgsql/bin # postgres binary dir
pg_packages:
- postgresql${pg_version}*
- postgis31_${pg_version}*
- pgbouncer patroni pg_exporter pgbadger
- patroni patroni-consul patroni-etcd pgbouncer pgbadger pg_activity
- python3 python3-psycopg2 python36-requests python3-etcd python3-consul
- python36-urllib3 python36-idna python36-pyOpenSSL python36-cryptography
pg_extensions:
- pg_repack${pg_version} pg_qualstats${pg_version} pg_stat_kcache${pg_version} wal2json${pg_version}
# - ogr_fdw${pg_version} mysql_fdw_${pg_version} redis_fdw_${pg_version} mongo_fdw${pg_version} hdfs_fdw_${pg_version}
# - count_distinct${version} ddlx_${version} geoip${version} orafce${version} # popular features
# - hypopg_${version} ip4r${version} jsquery_${version} logerrors_${version} periods_${version} pg_auto_failover_${version} pg_catcheck${version}
# - pg_fkpart${version} pg_jobmon${version} pg_partman${version} pg_prioritize_${version} pg_track_settings${version} pgaudit15_${version}
# - pgcryptokey${version} pgexportdoc${version} pgimportdoc${version} pgmemcache-${version} pgmp${version} pgq-${version} pgquarrel pgrouting_${version}
# - pguint${version} pguri${version} prefix${version} safeupdate_${version} semver${version} table_version${version} tdigest${version}
参数详解
pg_dbsu
数据库默认使用的操作系统用户(超级用户)的用户名称,默认为postgres,不建议修改。
pg_dbsu_uid
数据库默认使用的操作系统用户(超级用户)的UID,默认为26。
与CentOS下PostgreSQL官方RPM包的配置一致,不建议修改。
pg_dbsu_sudo
数据库超级用户的默认权限:
none:没有sudo权限limit:有限的sudo权限,可以执行数据库相关组件的systemctl命令,默认all:带有完整sudo权限,但需要密码。nopass:不需要密码的完整sudo权限(不建议)
pg_dbsu_home
数据库超级用户的家目录,默认为/var/lib/pgsql
pg_dbsu_ssh_exchange
是否在执行的机器之间交换超级用户的SSH公私钥
pg_version
希望安装的PostgreSQL版本,默认为13
建议在集群级别按需覆盖此变量。
pgdg_repo
标记,是否使用PostgreSQL官方源?默认不使用
使用该选项,可以在没有本地源的情况下,直接从互联网官方源下载安装PostgreSQL相关软件包。
pg_add_repo
如果使用,则会在安装PostgreSQL前添加PGDG的官方源
启用此选项,则可以在未执行基础设施初始化的前提下直接执行数据库初始化,尽管可能会很慢,但对于缺少基础设施的场景尤为实用。
pg_bin_dir
PostgreSQL二进制目录
默认为/usr/pgsql/bin/,这是一个安装过程中手动创建的软连接,指向安装的具体Postgres版本目录。
例如/usr/pgsql -> /usr/pgsql-13。
pg_packages
默认安装的PostgreSQL软件包
软件包中的${pg_version}会被替换为实际安装的PostgreSQL版本。
pg_extensions
需要安装的PostgreSQL扩展插件软件包
软件包中的${pg_version}会被替换为实际安装的PostgreSQL版本。
默认安装的插件包括:
pg_repack${pg_version}
pg_qualstats${pg_version}
pg_stat_kcache${pg_version}
wal2json${pg_version}
按需启用,但强烈建议安装pg_repack扩展。
6.9 - PG Provision
Parameters about how to pull up new clusters and assign identity to entities
PG供给,是在一台安装完Postgres的机器上,创建并拉起一套数据库的过程,包括:
- 集群身份定义,清理现有实例,创建目录结构,拷贝工具与脚本,配置环境变量
- 渲染Patroni模板配置文件,使用Patroni拉起主库,使用Patroni拉起从库
- 配置Pgbouncer,初始化业务用户与数据库,将数据库与数据源服务注册至DCS。
参数概览
默认参数
#------------------------------------------------------------------------------
# POSTGRES PROVISION
#------------------------------------------------------------------------------
# - identity - #
# pg_cluster: # [REQUIRED] cluster name (validated during pg_preflight)
# pg_seq: 0 # [REQUIRED] instance seq (validated during pg_preflight)
# pg_role: replica # [REQUIRED] service role (validated during pg_preflight)
pg_hostname: false # overwrite node hostname with pg instance name
pg_nodename: true # overwrite consul nodename with pg instance name
# - retention - #
# pg_exists_action, available options: abort|clean|skip
# - abort: abort entire play's execution (default)
# - clean: remove existing cluster (dangerous)
# - skip: end current play for this host
# pg_exists: false # auxiliary flag variable (DO NOT SET THIS)
pg_exists_action: clean
pg_disable_purge: false # set to true to disable pg purge functionality for good (force pg_exists_action = abort)
# - storage - #
pg_data: /pg/data # postgres data directory
pg_fs_main: /export # data disk mount point /pg -> {{ pg_fs_main }}/postgres/{{ pg_instance }}
pg_fs_bkup: /var/backups # backup disk mount point /pg/* -> {{ pg_fs_bkup }}/postgres/{{ pg_instance }}/*
# - connection - #
pg_listen: '0.0.0.0' # postgres listen address, '0.0.0.0' by default (all ipv4 addr)
pg_port: 5432 # postgres port (5432 by default)
pg_localhost: /var/run/postgresql # localhost unix socket dir for connection
# - patroni - #
# patroni_mode, available options: default|pause|remove
# - default: default ha mode
# - pause: into maintenance mode
# - remove: remove patroni after bootstrap
patroni_mode: default # pause|default|remove
pg_namespace: /pg # top level key namespace in dcs
patroni_port: 8008 # default patroni port
patroni_watchdog_mode: automatic # watchdog mode: off|automatic|required
pg_conf: tiny.yml # user provided patroni config template path
# - localization - #
pg_encoding: UTF8 # default to UTF8
pg_locale: C # default to C
pg_lc_collate: C # default to C
pg_lc_ctype: en_US.UTF8 # default to en_US.UTF8
# - pgbouncer - #
pgbouncer_port: 6432 # pgbouncer port (6432 by default)
pgbouncer_poolmode: transaction # pooling mode: (transaction pooling by default)
pgbouncer_max_db_conn: 100 # important! do not set this larger than postgres max conn or conn limit
身份参数
pg_cluster,pg_role,pg_seq 属于 身份参数
除了IP地址外,这三个参数是定义一套新的数据库集群的最小必须参数集,如下面的配置所示。
其他参数都可以继承自全局配置或默认配置,但身份参数必须显式指定,手工分配。
pg_cluster 标识了集群的名称,在集群层面进行配置。pg_role 在实例层面进行配置,标识了实例的角色,只有primary角色会进行特殊处理,如果不填,默认为replica角色,此外,还有特殊的delayed与offline角色。pg_seq 用于在集群内标识实例,通常采用从0或1开始递增的整数,一旦分配不再更改。{{ pg_cluster }}-{{ pg_seq }} 被用于唯一标识实例,即pg_instance{{ pg_cluster }}-{{ pg_role }} 用于标识集群内的服务,即pg_service
pg-test:
hosts:
10.10.10.11: {pg_seq: 1, pg_role: replica}
10.10.10.12: {pg_seq: 2, pg_role: primary}
10.10.10.13: {pg_seq: 3, pg_role: replica}
vars:
pg_cluster: pg-test
参数详解
pg_cluster
PG数据库集群的名称,将用作集群内资源的命名空间。
集群命名需要遵循特定命名规则:[a-z][a-z0-9-]*,以兼容不同约束对身份标识的要求。
身份参数,必填参数,集群级参数
pg_seq
数据库实例的序号,在集群内部唯一,用于区别与标识集群内的不同实例,从0或1开始分配。
身份参数,必填参数,实例级参数
pg_role
数据库实例的角色,默认角色包括:primary, replica。
后续可选角色包括:offline与delayed。
身份参数,必填参数,实例级参数
pg_shard
只有分片集群需要设置此参数。
当多个数据库集群以水平分片的方式共同服务于同一个 业务时,Pigsty将这一组集群称为 分片集簇(Sharding Cluster) 。pg_shard是数据库集群所属分片集簇的名称,一个分片集簇可以指定任意名称,但Pigsty建议采用具有意义的命名规则。
例如参与分片集簇的集群,可以使用 分片集簇名 pg_shard + shard + 集群所属分片编号pg_sindex构成集群名称:
shard: test
pg-testshard1
pg-testshard2
pg-testshard3
pg-testshard4
身份参数,可选参数,集群级参数
pg_sindex
集群在分片集簇中的编号,通常从0或1开始依次分配。
只有分片集群需要设置此参数。
身份参数,选填参数,集群级参数
pg_hostname
是否将PG实例的名称pg_instance 注册为主机名,默认禁用。
pg_nodename
是否将PG实例的名称注册为Consul中的节点名称,默认启用。
pg_exists
PG实例是否存在的标记位,不可配置。
pg_exists_action
安全保险,当PostgreSQL实例已经存在时,系统应当执行的动作
- abort: 中止整个剧本的执行(默认行为)
- clean: 抹除现有实例并继续(极端危险)
- skip: 忽略存在实例的目标(中止),在其他目标机器上继续执行。
如果您真的需要强制清除已经存在的数据库实例,建议先使用pgsql-rm.yml完成集群与实例的下线与销毁,在重新执行初始化。否则,则需要通过命令行参数-e pg_exists_action=clean完成覆写,强制在初始化过程中抹除已有实例。
pg_disable_purge
双重安全保险,默认为false。如果为true,强制设置pg_exists_action变量为abort。
等效于关闭pg_exists_action的清理功能,确保任何情况下Postgres实例都不会被抹除。
这意味着您需要通过专用下线脚本pgsql-rm.yml来完成已有实例的清理,然后才可以在清理干净的节点上重新完成数据库的初始化。
pg_data
默认数据目录,默认为/pg/data
pg_fs_main
主数据盘目录,默认为/export
Pigsty的默认目录结构假设系统中存在一个主数据盘挂载点,用于盛放数据库目录。
pg_fs_bkup
归档与备份盘目录,默认为/var/backups
Pigsty的默认目录结构假设系统中存在一个备份数据盘挂载点,用于盛放备份与归档数据。备份盘并不是必选项,如果系统中不存在备份盘,用户也可以指定一个主数据盘上的子目录作为备份盘根目录挂载点。
pg_listen
数据库监听的IP地址,默认为所有IPv4地址0.0.0.0,如果要包括所有IPv6地址,可以使用*。
pg_port
数据库监听的端口,默认端口为5432,不建议修改。
pg_localhost
Unix Socket目录,用于盛放PostgreSQL与Pgbouncer的Unix socket文件。
默认为/var/run/postgresql
patroni_mode
Patroni的工作模式:
default: 启用Patronipause: 启用Patroni,但在完成初始化后自动进入维护模式(不自动执行主从切换)remove: 依然使用Patroni初始化集群,但初始化完成后移除Patroni
pg_namespace
Patroni在DCS中使用的KV存储顶层命名空间
默认为pg
patroni_port
Patroni API服务器默认监听的端口
默认端口为8008
patroni_watchdog_mode
当发生主从切换时,Patroni会尝试在提升从库前关闭主库。如果指定超时时间内主库仍未成功关闭,Patroni会根据配置使用Linux内核功能softdog进行fencing关机。
off:不使用watchdogautomatic:如果内核启用了softdog,则启用watchdog,不强制,默认行为。required:强制使用watchdog,如果系统未启用softdog则拒绝启动。
pg_conf
拉起Postgres集群所用的Patroni模板。Pigsty预制了4种模板
oltp.yml 常规OLTP模板,默认配置olap.yml OLAP模板,提高并行度,针对吞吐量优化,针对长时间运行的查询进行优化。crit.yml) 核心业务模板,基于OLTP模板针对安全性,数据完整性进行优化,采用同步复制,强制启用数据校验和。tiny.yml 微型数据库模板,针对低资源场景进行优化,例如运行于虚拟机中的演示数据库集群。
pg_encoding
PostgreSQL实例初始化时,使用的字符集编码。
默认为UTF8,如果没有特殊需求,不建议修改此参数。
pg_locale
PostgreSQL实例初始化时,使用的本地化规则。
默认为C,如果没有特殊需求,不建议修改此参数。
pg_lc_collate
PostgreSQL实例初始化时,使用的本地化字符串排序规则。
默认为C,如果没有特殊需求,强烈不建议修改此参数。用户总是可以通过COLLATE表达式实现本地化排序相关功能,错误的本地化排序规则可能导致某些操作产生成倍的性能损失,请在真的有本地化需求的情况下修改此参数。
pg_lc_ctype
PostgreSQL实例初始化时,使用的本地化字符集定义
默认为en_US.UTF8,因为一些PG扩展(pg_trgm)需要额外的字符分类定义才可以针对国际化字符正常工作,因此Pigsty默认会使用en_US.UTF8字符集定义,不建议修改此参数。
pgbouncer_port
Pgbouncer连接池默认监听的端口
默认为6432
pgbouncer_poolmode
Pgbouncer连接池默认使用的Pool模式
默认为transaction,即事务级连接池。其他可选项包括:session|statemente
pgbouncer_max_db_conn
允许连接池与单个数据库之间建立的最大连接数
默认值为100
使用事务Pooling模式时,活跃服务端连接数通常处于个位数。如果采用会话Pooling,可以适当增大此参数。
6.10 - PG Template
Parameters about customize template and other database content.
PG Provision负责拉起一套全新的Postgres集群,而PG Template负责在PG Provision的基础上,在这套全新的数据库集群中创建默认的对象,包括
- 基本角色:只读角色,读写角色、管理角色
- 基本用户:复制用户、超级用户、监控用户、管理用户
- 模板数据库中的默认权限
- 默认 模式
- 默认 扩展
- HBA黑白名单规则
关于定制数据库集群的更多信息,请参考 定制集群
参数概览
默认参数
#------------------------------------------------------------------------------
# POSTGRES TEMPLATE
#------------------------------------------------------------------------------
# - template - #
pg_init: pg-init # init script for cluster template
# - system roles - #
pg_replication_username: replicator # system replication user
pg_replication_password: DBUser.Replicator # system replication password
pg_monitor_username: dbuser_monitor # system monitor user
pg_monitor_password: DBUser.Monitor # system monitor password
pg_admin_username: dbuser_admin # system admin user
pg_admin_password: DBUser.Admin # system admin password
# - default roles - #
# chekc http://pigsty.cc/zh/docs/concepts/provision/acl/ for more detail
pg_default_roles:
# common production readonly user
- name: dbrole_readonly # production read-only roles
login: false
comment: role for global readonly access
# common production read-write user
- name: dbrole_readwrite # production read-write roles
login: false
roles: [dbrole_readonly] # read-write includes read-only access
comment: role for global read-write access
# offline have same privileges as readonly, but with limited hba access on offline instance only
# for the purpose of running slow queries, interactive queries and perform ETL tasks
- name: dbrole_offline
login: false
comment: role for restricted read-only access (offline instance)
# admin have the privileges to issue DDL changes
- name: dbrole_admin
login: false
bypassrls: true
comment: role for object creation
roles: [dbrole_readwrite,pg_monitor,pg_signal_backend]
# dbsu, name is designated by `pg_dbsu`. It's not recommend to set password for dbsu
- name: postgres
superuser: true
comment: system superuser
# default replication user, name is designated by `pg_replication_username`, and password is set by `pg_replication_password`
- name: replicator
replication: true
roles: [pg_monitor, dbrole_readonly]
comment: system replicator
# default replication user, name is designated by `pg_monitor_username`, and password is set by `pg_monitor_password`
- name: dbuser_monitor
connlimit: 16
comment: system monitor user
roles: [pg_monitor, dbrole_readonly]
# default admin user, name is designated by `pg_admin_username`, and password is set by `pg_admin_password`
- name: dbuser_admin
bypassrls: true
comment: system admin user
roles: [dbrole_admin]
# default stats user, for ETL and slow queries
- name: dbuser_stats
password: DBUser.Stats
comment: business offline user for offline queries and ETL
roles: [dbrole_offline]
# - privileges - #
# object created by dbsu and admin will have their privileges properly set
pg_default_privileges:
- GRANT USAGE ON SCHEMAS TO dbrole_readonly
- GRANT SELECT ON TABLES TO dbrole_readonly
- GRANT SELECT ON SEQUENCES TO dbrole_readonly
- GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly
- GRANT USAGE ON SCHEMAS TO dbrole_offline
- GRANT SELECT ON TABLES TO dbrole_offline
- GRANT SELECT ON SEQUENCES TO dbrole_offline
- GRANT EXECUTE ON FUNCTIONS TO dbrole_offline
- GRANT INSERT, UPDATE, DELETE ON TABLES TO dbrole_readwrite
- GRANT USAGE, UPDATE ON SEQUENCES TO dbrole_readwrite
- GRANT TRUNCATE, REFERENCES, TRIGGER ON TABLES TO dbrole_admin
- GRANT CREATE ON SCHEMAS TO dbrole_admin
# - schemas - #
pg_default_schemas: [monitor] # default schemas to be created
# - extension - #
pg_default_extensions: # default extensions to be created
- { name: 'pg_stat_statements', schema: 'monitor' }
- { name: 'pgstattuple', schema: 'monitor' }
- { name: 'pg_qualstats', schema: 'monitor' }
- { name: 'pg_buffercache', schema: 'monitor' }
- { name: 'pageinspect', schema: 'monitor' }
- { name: 'pg_prewarm', schema: 'monitor' }
- { name: 'pg_visibility', schema: 'monitor' }
- { name: 'pg_freespacemap', schema: 'monitor' }
- { name: 'pg_repack', schema: 'monitor' }
- name: postgres_fdw
- name: file_fdw
- name: btree_gist
- name: btree_gin
- name: pg_trgm
- name: intagg
- name: intarray
# - hba - #
pg_offline_query: false # set to true to enable offline query on instance
pg_hba_rules: # postgres host-based authentication rules
- title: allow meta node password access
role: common
rules:
- host all all 10.10.10.10/32 md5
- title: allow intranet admin password access
role: common
rules:
- host all +dbrole_admin 10.0.0.0/8 md5
- host all +dbrole_admin 172.16.0.0/12 md5
- host all +dbrole_admin 192.168.0.0/16 md5
- title: allow intranet password access
role: common
rules:
- host all all 10.0.0.0/8 md5
- host all all 172.16.0.0/12 md5
- host all all 192.168.0.0/16 md5
- title: allow local read/write (local production user via pgbouncer)
role: common
rules:
- local all +dbrole_readonly md5
- host all +dbrole_readonly 127.0.0.1/32 md5
- title: allow offline query (ETL,SAGA,Interactive) on offline instance
role: offline
rules:
- host all +dbrole_offline 10.0.0.0/8 md5
- host all +dbrole_offline 172.16.0.0/12 md5
- host all +dbrole_offline 192.168.0.0/16 md5
pg_hba_rules_extra: [] # extra hba rules (for cluster/instance overwrite)
pgbouncer_hba_rules: # pgbouncer host-based authentication rules
- title: local password access
role: common
rules:
- local all all md5
- host all all 127.0.0.1/32 md5
- title: intranet password access
role: common
rules:
- host all all 10.0.0.0/8 md5
- host all all 172.16.0.0/12 md5
- host all all 192.168.0.0/16 md5
pgbouncer_hba_rules_extra: [] # extra pgbouncer hba rules (for cluster/instance overwrite)
参数详解
pg_init
用于初始化数据库模板的Shell脚本位置,默认为pg-init,该脚本会被拷贝至/pg/bin/pg-init后执行。
默认的pg-init 只是预渲染SQL命令的包装:
# system default roles
psql postgres -qAXwtf /pg/tmp/pg-init-roles.sql
# system default template
psql template1 -qAXwtf /pg/tmp/pg-init-template.sql
# make postgres same as templated database (optional)
psql postgres -qAXwtf /pg/tmp/pg-init-template.sql
用户可以在自定义的pg-init脚本中添加自己的集群初始化逻辑。
pg_replication_username
用于执行PostgreSQL流复制的数据库用户名
默认为replicator
pg_replication_password
用于执行PostgreSQL流复制的数据库用户密码,必须使用明文
默认为DBUser.Replicator,强烈建议修改!
pg_monitor_username
用于执行PostgreSQL与Pgbouncer监控任务的数据库用户名
默认为dbuser_monitor
pg_monitor_password
用于执行PostgreSQL与Pgbouncer监控任务的数据库用户密码,必须使用明文
默认为DBUser.Monitor,强烈建议修改!
pg_admin_username
用于执行PostgreSQL数据库管理任务(DDL变更)的数据库用户名
默认为dbuser_admin
pg_admin_password
用于执行PostgreSQL数据库管理任务(DDL变更)的数据库用户密码,必须使用明文
默认为DBUser.Admin,强烈建议修改!
pg_default_roles
定义了PostgreSQL中默认的角色与用户,形式为对象数组,每一个对象定义一个用户或角色。
每一个用户或角色必须指定 name ,其余字段均为可选项。
-
password是可选项,如果留空则不设置密码,可以使用MD5密文密码。
-
login, superuser, createdb, createrole, inherit, replication, bypassrls 都是布尔类型,用于设置用户属性。如果不设置,则采用系统默认值。
-
用户通过CREATE USER创建,所以默认具有login属性,如果创建的是角色,需要指定login: false。
-
expire_at与expire_in用于控制用户过期时间,expire_at使用形如YYYY-mm-DD的日期时间戳。expire_in使用从现在开始的过期天数,如果expire_in存在则会覆盖expire_at选项。
-
新用户默认不会添加至Pgbouncer用户列表中,必须显式定义pgbouncer: true,该用户才会被加入到Pgbouncer用户列表。
-
用户/角色会按顺序创建,后面定义的用户可以属于前面定义的角色。
pg_users:
# complete example of user/role definition for production user
- name: dbuser_meta # example production user have read-write access
password: DBUser.Meta # example user's password, can be encrypted
login: true # can login, true by default (should be false for role)
superuser: false # is superuser? false by default
createdb: false # can create database? false by default
createrole: false # can create role? false by default
inherit: true # can this role use inherited privileges?
replication: false # can this role do replication? false by default
bypassrls: false # can this role bypass row level security? false by default
connlimit: -1 # connection limit, -1 disable limit
expire_at: '2030-12-31' # 'timestamp' when this role is expired
expire_in: 365 # now + n days when this role is expired (OVERWRITE expire_at)
roles: [dbrole_readwrite] # dborole_admin|dbrole_readwrite|dbrole_readonly|dbrole_offline
pgbouncer: true # add this user to pgbouncer? false by default (true for production user)
parameters: # user's default search path
search_path: public
comment: test user
Pigsty定义了由四个默认角色与四个默认用户组成的基本访问控制系统,详细信息请参考 访问控制。
pg_default_privileges
定义数据库模板中的默认权限。
任何由{{ dbsu」}}与{{ pg_admin_username }}创建的对象都会具有以下默认权限:
pg_default_privileges:
- GRANT USAGE ON SCHEMAS TO dbrole_readonly
- GRANT SELECT ON TABLES TO dbrole_readonly
- GRANT SELECT ON SEQUENCES TO dbrole_readonly
- GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly
- GRANT USAGE ON SCHEMAS TO dbrole_offline
- GRANT SELECT ON TABLES TO dbrole_offline
- GRANT SELECT ON SEQUENCES TO dbrole_offline
- GRANT EXECUTE ON FUNCTIONS TO dbrole_offline
- GRANT INSERT, UPDATE, DELETE ON TABLES TO dbrole_readwrite
- GRANT USAGE, UPDATE ON SEQUENCES TO dbrole_readwrite
- GRANT TRUNCATE, REFERENCES, TRIGGER ON TABLES TO dbrole_admin
- GRANT CREATE ON SCHEMAS TO dbrole_admin
详细信息请参考 访问控制。
pg_default_schemas
创建于模版数据库的默认模式
Pigsty默认会创建名为monitor的模式用于安装监控扩展。
pg_default_schemas: [monitor] # default schemas to be created
pg_default_extensions
默认安装于模板数据库的扩展,对象数组。
如果没有指定schema字段,扩展会根据当前的search_path安装至对应模式中。
pg_default_extensions:
- { name: 'pg_stat_statements', schema: 'monitor' }
- { name: 'pgstattuple', schema: 'monitor' }
- { name: 'pg_qualstats', schema: 'monitor' }
- { name: 'pg_buffercache', schema: 'monitor' }
- { name: 'pageinspect', schema: 'monitor' }
- { name: 'pg_prewarm', schema: 'monitor' }
- { name: 'pg_visibility', schema: 'monitor' }
- { name: 'pg_freespacemap', schema: 'monitor' }
- { name: 'pg_repack', schema: 'monitor' }
- name: postgres_fdw
- name: file_fdw
- name: btree_gist
- name: btree_gin
- name: pg_trgm
- name: intagg
- name: intarray
pg_offline_query
实例级变量,布尔类型,默认为false。
设置为true时,无论当前实例的角色为何,用户组dbrole_offline都可以连接至该实例并执行离线查询。
对于实例数量较少(例如一主一从)的情况较为实用,用户可以将唯一的从库标记为pg_offline_query = true,从而接受ETL,慢查询与交互式访问。详细信息请参考 访问控制-离线用户。
pg_reload
命令行参数,布尔类型,默认为true。
设置为true时,Pigsty会在生成HBA规则后立刻执行pg_ctl reload应用。
当您希望生成pg_hba.conf文件,并手工比较后再应用生效时,可以指定-e pg_reload=false来禁用它。
pg_hba_rules
设置数据库的客户端IP黑白名单规则。对象数组,每一个对象都代表一条规则。
每一条规则由三部分组成:
title,规则标题,会转换为HBA文件中的注释role,应用角色,common代表应用至所有实例,其他取值(如replica, offline)则仅会安装至匹配的角色上。例如role='replica'代表这条规则只会应用到pg_role == 'replica' 的实例上。rules,字符串数组,每一条记录代表一条最终写入pg_hba.conf的规则。
作为一个特例,role == 'offline' 的HBA规则,还会额外安装至 pg_offline_query == true 的实例上。
pg_hba_rules:
- title: allow meta node password access
role: common
rules:
- host all all 10.10.10.10/32 md5
- title: allow intranet admin password access
role: common
rules:
- host all +dbrole_admin 10.0.0.0/8 md5
- host all +dbrole_admin 172.16.0.0/12 md5
- host all +dbrole_admin 192.168.0.0/16 md5
- title: allow intranet password access
role: common
rules:
- host all all 10.0.0.0/8 md5
- host all all 172.16.0.0/12 md5
- host all all 192.168.0.0/16 md5
- title: allow local read-write access (local production user via pgbouncer)
role: common
rules:
- local all +dbrole_readwrite md5
- host all +dbrole_readwrite 127.0.0.1/32 md5
- title: allow read-only user (stats, personal) password directly access
role: replica
rules:
- local all +dbrole_readonly md5
- host all +dbrole_readonly 127.0.0.1/32 md5
建议在全局配置统一的pg_hba_rules,针对特定集群使用pg_hba_rules_extra进行额外定制。
与pg_hba_rules类似,但通常用于集群层面的HBA规则设置。
pg_hba_rules_extra 会以同样的方式 追加 至pg_hba.conf中。
如果用户需要彻底覆写集群的HBA规则,即不想继承全局HBA配置,则应当在集群层面配置pg_hba_rules并覆盖全局配置。
pgbouncer_hba_rules
与pg_hba_rules类似,用于Pgbouncer的HBA规则设置。
默认的Pgbouncer HBA规则很简单,用户可以按照自己的需求进行定制。
默认的Pgbouncer HBA规则较为宽松:
- 允许从本地使用密码登陆
- 允许从内网网断使用密码登陆
pgbouncer_hba_rules:
- title: local password access
role: common
rules:
- local all all md5
- host all all 127.0.0.1/32 md5
- title: intranet password access
role: common
rules:
- host all all 10.0.0.0/8 md5
- host all all 172.16.0.0/12 md5
- host all all 192.168.0.0/16 md5
与pg_hba_rules_extras类似,用于在集群层次对Pgbouncer的HBA规则进行额外配置。
业务模板
以下两个参数属于业务模板,用户应当在这里定义所需的业务用户与业务数据库。
在这里定义的用户与数据库,会在以下两个步骤中完成应用,不仅仅包括数据库中的用户与DB,还有Pgbouncer连接池中的对应配置。
./pgsql.yml --tags=pg_biz_init,pg_biz_pgbouncer
pg_users
通常用于在数据库集群层面定义业务用户,与 pg_default_roles 采用相同的形式。
对象数组,每个对象定义一个业务用户。用户名name字段为必选项,密码可以使用MD5密文密码
用户可以通过roles字段为业务用户添加默认权限组:
dbrole_readonly:默认生产只读用户,具有全局只读权限。(只读生产访问)dbrole_offline:默认离线只读用户,在特定实例上具有只读权限。(离线查询,个人账号,ETL)dbrole_readwrite:默认生产读写用户,具有全局CRUD权限。(常规生产使用)dbrole_admin:默认生产管理用户,具有执行DDL变更的权限。(管理员)
应当为生产账号配置 pgbouncer: true,允许其通过连接池访问,普通用户不应当通过连接池访问数据库。
下面是一个创建业务账号的例子:
pg_users:
# complete example of user/role definition for production user
- name: dbuser_meta # example production user have read-write access
password: DBUser.Meta # example user's password, can be encrypted
login: true # can login, true by default (should be false for role)
superuser: false # is superuser? false by default
createdb: false # can create database? false by default
createrole: false # can create role? false by default
inherit: true # can this role use inherited privileges?
replication: false # can this role do replication? false by default
bypassrls: false # can this role bypass row level security? false by default
connlimit: -1 # connection limit, -1 disable limit
expire_at: '2030-12-31' # 'timestamp' when this role is expired
expire_in: 365 # now + n days when this role is expired (OVERWRITE expire_at)
roles: [dbrole_readwrite] # dborole_admin|dbrole_readwrite|dbrole_readonly
pgbouncer: true # add this user to pgbouncer? false by default (true for production user)
parameters: # user's default search path
search_path: public
comment: test user
# simple example for personal user definition
- name: dbuser_vonng2 # personal user example which only have limited access to offline instance
password: DBUser.Vonng # or instance with explict mark `pg_offline_query = true`
roles: [dbrole_offline] # personal/stats/ETL user should be grant with dbrole_offline
expire_in: 365 # expire in 365 days since creation
pgbouncer: false # personal user should NOT be allowed to login with pgbouncer
comment: example personal user for interactive queries
pg_databases
对象数组,每个对象定义一个业务数据库。每个数据库定义中,数据库名称 name 为必选项,其余均为可选项。
name:数据库名称,必选项。owner:数据库属主,默认为postgrestemplate:数据库创建时使用的模板,默认为template1encoding:数据库默认字符编码,默认为UTF8,默认与实例保持一致。建议不要配置与修改。locale:数据库默认的本地化规则,默认为C,建议不要配置,与实例保持一致。lc_collate:数据库默认的本地化字符串排序规则,默认与实例设置相同,建议不要修改,必须与模板数据库一致。强烈建议不要配置,或配置为C。lc_ctype:数据库默认的LOCALE,默认与实例设置相同,建议不要修改或设置,必须与模板数据库一致。建议配置为C或en_US.UTF8。allowconn:是否允许连接至数据库,默认为true,不建议修改。revokeconn:是否回收连接至数据库的权限?默认为false。如果为true,则数据库上的PUBLIC CONNECT权限会被回收。只有默认用户(dbsu|monitor|admin|replicator|owner)可以连接。此外,admin|owner 会拥有GRANT OPTION,可以赋予其他用户连接权限。tablespace:数据库关联的表空间,默认为pg_default。connlimit:数据库连接数限制,默认为-1,即没有限制。extensions:对象数组 ,每一个对象定义了一个数据库中的扩展,以及其安装的模式。parameters:KV对象,每一个KV定义了一个需要针对数据库通过ALTER DATABASE修改的参数。pgbouncer:布尔选项,是否将该数据库加入到Pgbouncer中。所有数据库都会加入至Pgbouncer,除非显式指定pgbouncer: false。comment:数据库备注信息。
pg_databases:
- name: meta # name is the only required field for a database
owner: postgres # optional, database owner
template: template1 # optional, template1 by default
encoding: UTF8 # optional, UTF8 by default
locale: C # optional, C by default
lc_collate: C # optional, C by default , must same as template database, leave blank to set to db default
lc_ctype: C # optional, C by default , must same as template database, leave blank to set to db default
allowconn: true # optional, true by default, false disable connect at all
revokeconn: false # optional, false by default, true revoke connect from public # (only default user and owner have connect privilege on database)
tablespace: pg_default # optional, 'pg_default' is the default tablespace
connlimit: -1 # optional, connection limit, -1 or none disable limit (default)
extensions: # optional, extension name and where to create
- {name: postgis, schema: public}
parameters: # optional, extra parameters with ALTER DATABASE
enable_partitionwise_join: true
pgbouncer: true # optional, add this database to pgbouncer list? true by default
comment: pigsty meta database # optional, comment string for database
6.11 - Monitor
Parameters about monitoring components
Pigsty的监控系统包含两个组件:Node Exporter , PG Exporter
Node Exporter用于暴露机器节点的监控指标,PG Exporter用于拉取数据库与Pgbouncer连接池的监控指标;此外,Haproxy将直接通过管理端口对外暴露监控指标。
默认情况下,所有监控Exporter都会被注册至Consul,Prometheus会通过服务发现的方式管理这些任务。但用户可以通过配置 prometheus_sd_method 为 static 改用静态服务发现,通过配置文件的方式管理所有Exporter。监控已有数据库实例时,建议采用这种方式。
参数概览
默认参数
#------------------------------------------------------------------------------
# MONITOR PROVISION
#------------------------------------------------------------------------------
# - install - #
exporter_install: none # none|yum|binary, none by default
exporter_repo_url: '' # if set, repo will be added to /etc/yum.repos.d/ before yum installation
# - collect - #
exporter_metrics_path: /metrics # default metric path for pg related exporter
# - node exporter - #
node_exporter_enabled: true # setup node_exporter on instance
node_exporter_port: 9100 # default port for node exporter
node_exporter_options: '--no-collector.softnet --collector.systemd --collector.ntp --collector.tcpstat --collector.processes'
# - pg exporter - #
pg_exporter_config: pg_exporter-demo.yaml # default config files for pg_exporter
pg_exporter_enabled: true # setup pg_exporter on instance
pg_exporter_port: 9630 # default port for pg exporter
pg_exporter_url: '' # optional, if not set, generate from reference parameters
# - pgbouncer exporter - #
pgbouncer_exporter_enabled: true # setup pgbouncer_exporter on instance (if you don't have pgbouncer, disable it)
pgbouncer_exporter_port: 9631 # default port for pgbouncer exporter
pgbouncer_exporter_url: '' # optional, if not set, generate from reference parameters
参数详解
exporter_install
指明安装Exporter的方式:
none:不安装,(默认行为,Exporter已经在先前由 node.pkgs 任务完成安装)yum:使用yum安装(如果启用yum安装,在部署Exporter前执行yum安装 node_exporter 与 pg_exporter )binary:使用拷贝二进制的方式安装(从files中直接拷贝node_exporter与 pg_exporter 二进制)
使用yum安装时,如果指定了exporter_repo_url(不为空),在执行安装时会首先将该URL下的REPO文件安装至/etc/yum.repos.d中。这一功能可以在不执行节点基础设施初始化的环境下直接进行Exporter的安装。
使用binary安装时,用户需要确保已经将 node_exporter 与 pg_exporter 的Linux二进制程序放置在files目录中。
<meta>:<pigsty>/files/node_exporter -> <target>:/usr/bin/node_exporter
<meta>:<pigsty>/files/pg_exporter -> <target>:/usr/bin/pg_exporter
exporter_binary_install(弃用)
该参数已被expoter_install 参数覆盖
是否采用复制二进制文件的方式安装Node Exporter与PG Exporter,默认为false
该选项主要用于集成外部供给方案时,减少对原有系统的工作假设。启用该选项将直接将Linux二进制文件复制至目标机器。
<meta>:<pigsty>/files/node_exporter -> <target>:/usr/bin/node_exporter
<meta>:<pigsty>/files/pg_exporter -> <target>:/usr/bin/pg_exporter
用户需要通过files/download-exporter.sh从Github下载Linux二进制程序至files目录,方可启用该选项。
exporter_metrics_path
所有Exporter对外暴露指标的URL PATH,默认为/metrics
该变量被外部角色prometheus引用,Prometheus会根据这里的配置,针对job = pg的监控对象应用此配置。
node_exporter_enabled
是否安装并配置node_exporter,默认为true
node_exporter_port
node_exporter监听的端口
默认端口9100
node_exporter_options
node_exporter 使用的额外命令行选项。
该选项主要用于定制 node_exporter 启用的指标收集器,Node Exporter支持的收集器列表可以参考:Node Exporter Collectors
该选项的默认值为:
node_exporter_options: '--no-collector.softnet --collector.systemd --collector.ntp --collector.tcpstat --collector.processes'
pg_exporter_config
pg_exporter使用的默认配置文件,定义了Pigsty中的指标。
Pigsty默认提供了两个配置文件:
如果用户采用了不同的Prometheus架构,建议对pg_exporter的配置文件进行检查与调整。
Pigsty使用的PG Exporter配置文件默认从PostgreSQL 10.0 开始提供支持,目前支持至最新的PG 13版本
pg_exporter_enabled
是否安装并配置pg_exporter,默认为true
pg_exporter_url
PG Exporter用于连接至数据库的PGURL
可选参数,默认为空字符串。
Pigsty默认使用以下规则生成监控的目标URL,如果配置了pg_exporter_url选项,则会直接使用该URL作为连接串。
PG_EXPORTER_URL='postgres://{{ pg_monitor_username }}:{{ pg_monitor_password }}@:{{ pg_port }}/{{ pg_default_database }}?host={{ pg_localhost }}&sslmode=disable'
该选项以环境变量的方式配置于 /etc/default/pg_exporter 中。
pgbouncer_exporter_enabled
是否安装并配置pgbouncer_exporter,默认为true
pg_exporter_port
pg_exporter监听的端口
默认端口9630
pgbouncer_exporter_port
pgbouncer_exporter监听的端口
默认端口9631
pgbouncer_exporter_url
PGBouncer Exporter用于连接至数据库的URL
可选参数,默认为空字符串。
Pigsty默认使用以下规则生成监控的目标URL,如果配置了pgbouncer_exporter_url选项,则会直接使用该URL作为连接串。
PG_EXPORTER_URL='postgres://{{ pg_monitor_username }}:{{ pg_monitor_password }}@:{{ pgbouncer_port }}/pgbouncer?host={{ pg_localhost }}&sslmode=disable'
该选项以环境变量的方式配置于 /etc/default/pgbouncer_exporter 中。
6.12 - Service Provision
Parameters about exposing cluster’s service
服务(Service),是数据库集群对外提供功能的形式。通常来说,一个数据库集群至少应当提供两种服务:
- 读写服务(primary) :用户可以写入数据库
- 只读服务(replica) :用户可以访问只读副本
此外,根据具体的业务场景,可能还会有其他的服务:
- 离线从库服务(offline):不承接线上只读流量的专用从库,用于ETL与个人用户查询。
- 同步从库服务(standby) :采用同步提交,没有复制延迟的只读服务。
- 延迟从库服务(delayed) : 允许业务访问固定时间间隔之前的旧数据。
- 默认直连服务(default) : 允许(管理)用户绕过连接池直接管理数据库的服务
参数概览
默认参数
#------------------------------------------------------------------------------
# SERVICE PROVISION
#------------------------------------------------------------------------------
pg_weight: 100 # default load balance weight (instance level)
# - service - #
pg_services: # how to expose postgres service in cluster?
# primary service will route {ip|name}:5433 to primary pgbouncer (5433->6432 rw)
- name: primary # service name {{ pg_cluster }}_primary
src_ip: "*"
src_port: 5433
dst_port: pgbouncer # 5433 route to pgbouncer
check_url: /primary # primary health check, success when instance is primary
selector: "[]" # select all instance as primary service candidate
# replica service will route {ip|name}:5434 to replica pgbouncer (5434->6432 ro)
- name: replica # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5434
dst_port: pgbouncer
check_url: /read-only # read-only health check. (including primary)
selector: "[]" # select all instance as replica service candidate
selector_backup: "[? pg_role == `primary`]" # primary are used as backup server in replica service
# default service will route {ip|name}:5436 to primary postgres (5436->5432 primary)
- name: default # service's actual name is {{ pg_cluster }}-{{ service.name }}
src_ip: "*" # service bind ip address, * for all, vip for cluster virtual ip address
src_port: 5436 # bind port, mandatory
dst_port: postgres # target port: postgres|pgbouncer|port_number , pgbouncer(6432) by default
check_method: http # health check method: only http is available for now
check_port: patroni # health check port: patroni|pg_exporter|port_number , patroni by default
check_url: /primary # health check url path, / as default
check_code: 200 # health check http code, 200 as default
selector: "[]" # instance selector
haproxy: # haproxy specific fields
maxconn: 3000 # default front-end connection
balance: roundrobin # load balance algorithm (roundrobin by default)
default_server_options: 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
# offline service will route {ip|name}:5438 to offline postgres (5438->5432 offline)
- name: offline # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5438
dst_port: postgres
check_url: /replica # offline MUST be a replica
selector: "[? pg_role == `offline` || pg_offline_query ]" # instances with pg_role == 'offline' or instance marked with 'pg_offline_query == true'
selector_backup: "[? pg_role == `replica` && !pg_offline_query]" # replica are used as backup server in offline service
pg_services_extra: [] # extra services to be added
# - haproxy - #
haproxy_enabled: true # enable haproxy among every cluster members
haproxy_reload: true # reload haproxy after config
haproxy_admin_auth_enabled: false # enable authentication for haproxy admin?
haproxy_admin_username: admin # default haproxy admin username
haproxy_admin_password: admin # default haproxy admin password
haproxy_exporter_port: 9101 # default admin/exporter port
haproxy_client_timeout: 3h # client side connection timeout
haproxy_server_timeout: 3h # server side connection timeout
# - vip - #
vip_mode: none # none | l2 | l4
vip_reload: true · # whether reload service after config
# vip_address: 127.0.0.1 # virtual ip address ip (l2 or l4)
# vip_cidrmask: 24 # virtual ip address cidr mask (l2 only)
# vip_interface: eth0 # virtual ip network interface (l2 only)
参数详解
pg_weight
当执行负载均衡时,数据库实例的相对权重。默认为100
pg_services
由服务定义对象构成的数组,定义了每一个数据库集群中对外暴露的服务。
每一个集群都可以定义多个服务,每个服务包含任意数量的集群成员,服务通过端口进行区分。
每一个服务的定义结构如下例所示:
- name: default # service's actual name is {{ pg_cluster }}-{{ service.name }}
src_ip: "*" # service bind ip address, * for all, vip for cluster virtual ip address
src_port: 5436 # bind port, mandatory
dst_port: postgres # target port: postgres|pgbouncer|port_number , pgbouncer(6432) by default
check_method: http # health check method: only http is available for now
check_port: patroni # health check port: patroni|pg_exporter|port_number , patroni by default
check_url: /primary # health check url path, / as default
check_code: 200 # health check http code, 200 as default
selector: "[]" # instance selector
haproxy: # haproxy specific fields
maxconn: 3000 # default front-end connection
balance: roundrobin # load balance algorithm (roundrobin by default)
default_server_options: 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
必选项目
-
名称(service.name):
服务名称,服务的完整名称以数据库集群名为前缀,以service.name为后缀,通过-连接。例如在pg-test集群中name=primary的服务,其完整服务名称为pg-test-primary。
-
端口(service.port):
在Pigsty中,服务默认采用NodePort的形式对外暴露,因此暴露端口为必选项。但如果使用外部负载均衡服务接入方案,您也可以通过其他的方式区分服务。
-
选择器(service.selector):
选择器指定了服务的实例成员,采用JMESPath的形式,从所有集群实例成员中筛选变量。默认的[]选择器会选取所有的集群成员。
可选项目
-
备份选择器(service.selector):
可选的 备份选择器service.selector_backup会选择或标记用于服务备份的实例列表,即集群中所有其他成员失效时,备份实例才接管服务。例如可以将primary实例加入replica服务的备选集中,当所有从库失效后主库依然可以承载集群的只读流量。
-
源端IP(service.src_ip) :
表示服务对外使用的IP地址,默认为*,即本机所有IP地址。使用vip则会使用vip_address变量取值,或者也可以填入网卡支持的特定IP地址。
-
宿端口(service.dst_port):
服务的流量将指向目标实例上的哪个端口?postgres 会指向数据库监听的端口,pgbouncer会指向连接池所监听的端口,也可以填入固定的端口号。
-
健康检查方式(service.check_method):
服务如何检查实例的健康状态?目前仅支持HTTP
-
健康检查端口(service.check_port):
服务检查实例的哪个端口获取实例的健康状态? patroni会从Patroni(默认8008)获取,pg_exporter会从PG Exporter(默认9630)获取,用户也可以填入自定义的端口号。
-
健康检查路径(service.check_url):
服务执行HTTP检查时,使用的URL PATH。默认会使用/作为健康检查,PG Exporter与Patroni提供了多样的健康检查方式,可以用于主从流量区分。例如,/primary仅会对主库返回成功,/replica仅会对从库返回成功。/read-only则会对任何支持只读的实例(包括主库)返回成功。
-
健康检查代码(service.check_code):
HTTP健康检查所期待的代码,默认为200
-
Haproxy特定配置(service.haproxy) :
关于服务供应软件(HAproxy)的专有配置项
由服务定义对象构成的数组,在集群层面定义,追加至全局的服务定义中。
如果用户希望为某一个数据库集群创建特殊的服务,例如单独为某一套带有延迟从库的集群创建特殊的服务,则可以使用本配置项。
haproxy_enabled
是否启用Haproxy组件
Pigsty默认会在所有数据库节点上部署Haproxy,您可以通过覆盖实例级变量,仅在特定实例/节点上启用Haproxy负载均衡器。
haproxy_admin_auth_enabled
是否启用为Haproxy管理界面启用基本认证
默认不启用,建议在生产环境启用,或在Nginx或其他接入层添加访问控制。
haproxy_admin_username
启用Haproxy管理界面认证默认用户名,默认为admin
haproxy_admin_password
启用Haproxy管理界面认证默认密码,默认为admin
haproxy_client_timeout
Haproxy客户端连接超时,默认为3小时
haproxy_server_timeout
Haproxy服务端连接超时,默认为3小时
haproxy_exporter_port
Haproxy管理界面与监控指标暴露端点所监听的端口。
默认端口为9101
vip_mode
VIP的模式,枚举类型,可选值包括:
- none:不设置VIP
- l2:配置绑定在主库上的二层VIP(需要所有成员位于同一个二层网络广播域中)
- l4 :通过外部L4负载均衡器进行流量分发。(未纳入Pigsty当前实现中)
VIP用于确保读写服务与负载均衡器的高可用,当使用L2 VIP时,Pigsty的VIP由vip-manager托管,会绑定在集群主库上。
这意味着您始终可以通过VIP访问集群主库,或者通过VIP访问主库上的负载均衡器(如果主库的压力很大,这样做可能会有性能压力)。
注意,您必须保证VIP候选实例处于同一个二层网络(VLAN、交换机)下。
vip_address
VIP地址,可用于L2或L4 VIP。
vip_address没有默认值,用户必须为每一个集群显式指定并分配VIP地址
vip_cidrmask
VIP的CIDR网络长度,仅当使用L2 VIP时需要。
vip_cidrmask没有默认值,用户必须为每一个集群显式指定VIP的网络CIDR。
vip_interface
VIP网卡名称,仅当使用L2 VIP时需要。
默认为eth0,用户必须为每一个集群/实例指明VIP使用的网卡名称。
过时参数
这些参数现在定义于服务中,不再使用。
haproxy_policy
haproxy负载均衡所使用的算法,可选策略为roundrobin与leastconn
默认为roundrobin
haproxy_check_port
Haproxy对后端PostgreSQL进程执行健康检查的端口。
默认端口为8008,即Patroni的端口。
其他的选项包括9630,即使用pg_exporter作为健康检查的端口。
haproxy_primary_port
Haproxy中集群读写服务默认端口,所有链接至该端口的客户端链接都会被转发至主实例的对应端口。
默认读写服务的端口为5433
haproxy_replica_port
Haproxy中集群只读服务默认端口,所有链接至该端口的客户端链接都会被转发至主从例的对应端口。
默认读写服务的端口为5434
haproxy_backend_port
Haproxy将客户端连接转发至后端的对应端口,可选:5432/6432
默认为6432,即Haproxy会将流量转发至6432连接池端口,修改为5432表示直接将流量转发至数据库。
haproxy_weight
Haproxy进行负载均衡时的标准权重,默认为100,建议在实例层次进行覆盖。
haproxy_weight_fallback
用于控制主库承载只读流量的权重。
如果haproxy_weight_fallback为0,主库不会承担任何只读流量(发送至haproxy_replica_port)。
如果haproxy_weight_fallback为1(或更高的值时),在集群正常工作时,主库会在从库服务集中承担 1/总权重 的微小流量,而当从库集中所有的只读实例故障时,只读流量可以漂移至主库承载。
该配置对于一主一从的情况非常实用,如果您有多台从库,建议将其配置为0。
7 - Tasks
database access, HA drills, some of the tasks that can be explored in Pigsty
After configuring Pigsty, you can do some interesting explorations and experiments with it.
7.1 - Migration based on logical replication
How to perform a smooth migration based on logical replication
本文基于Pigsty沙箱中的实例,介绍基于逻辑复制进行主从切换与数据库迁移的原理,细节与注意事项。
逻辑复制相关基础知识可参考 Postgres逻辑复制详解 一文。
0 逻辑复制迁移
逻辑复制通常可用于跨大版本跨操作系统在线升级PostgreSQL,例如从PG 10到PG 13,从Windows到Linux。
0.1 逻辑迁移的优点
相比原地pg_upgrade升级与pg_dump升级,逻辑复制的好处有:
- 在线:迁移可以在线进行,不需要或者只需要极小的停机窗口。
- 灵活:目标库的结构可以与源库不同,例如普通表改为分区表,加列等。可以跨越大版本使用。
- 安全:相比物理复制,目标库是可写的,因此在最终切换前,可以随意进行测试并重建。
- 快速:停机窗口很短,可以控制在秒级到分钟级。
0.2 逻辑迁移的局限性
逻辑复制的局限性主要在于设置相对繁琐,初始时刻拷贝数据较物理复制更慢,对于单实例多DB的情况需要迁移多次。大对象与序列号需要在迁移时手动同步。
总体来说都,属于可以解决或可以容忍的问题。
0.3 逻辑迁移的基本流程
整体上讲,基于逻辑复制的迁移遵循以下步骤:
其中准备工作与存量迁移部分耗时较长,但不需要停机,不会对生产业务产生影响。
切换时刻需要短暂的停机窗口,采用自动化的脚本可以将停机时间控制在秒级到分钟级。
下面将基于Pigsty沙箱介绍这些步骤涉及到的具体细节。
1 准备工作
1.1 准备源宿集群
在进行迁移之前,首先要确定迁移的源端集群与目标集群配置正确。
Pigsty标准沙箱由四个节点与两套数据库集群构成。
两套数据库集群pg-meta与pg-test将分别作为逻辑复制的源端(SRC)与宿端(DST)。
本例将pg-meta-1作为发布者,pg-test-1作为订阅者,将pgbench相关表从pg-meta迁移至pg-test。
1.1.1 用户
迁移通常需要在原宿两端拥有两个用户,分别用于管理与复制。
CREATE USER dbuser_admin SUPERUSER; -- 超级用户用于创建发布与订阅
CREATE USER replicator REPLICATION BYPASSRLS; -- 复制用户用于订阅变更
1.1.2 HBA规则
同时,还需要配置相应的HBA规则,允许复制用户在原宿集群间相互访问。
此外,迁移通常会从中控机发起,应当允许管理用户从中控机访问原/宿集群。
因为创建订阅需要超级用户权限,建议为管理用户(永久或临时)配置SUPERUSER权限。
1.1.3 配置项
必选的配置项是wal_level,您必须在源端将wal_level配置为logical,方能启用逻辑复制。
其他一些关于复制的相关参数也需要合理配置,但除了wal_level外的参数默认值都不会影响逻辑复制正常工作,均为可选。
推荐在源端与宿端使用相同的配置项,下面是在64核机器上,一些相关配置的参考值:
wal_level: logical # MANDATORY!
max_worker_processes: 64 # default 8 -> 64, set to CPU CORE 64
max_parallel_workers: 32 # default 8 -> 32, limit by max_worker_processes
max_parallel_maintenance_workers: 16 # default 2 -> 16, limit by parallel worker
max_parallel_workers_per_gather: 0 # default 2 -> 0, disable parallel query on OLTP instance
# max_parallel_workers_per_gather: 16 # default 2 -> 16, enable parallel query on OLAP instance
max_wal_senders: 24 # 10 -> 24
max_replication_slots: 16 # 10 -> 16
max_logical_replication_workers: 8 # 4 -> 8, 6 sync worker + 1~2 apply worker
max_sync_workers_per_subscription: 6 # 2 -> 6, 6 sync worker
对于数据库来说,通常还需要关注数据库的 编码(encoding)与 本地化 (locale)配置项是否正确,通常建议统一使用C.UTF8。
1.1.4 连接信息
为了执行管理命令,您需要通过连接串访问原/宿集群的主库。
建议不要在连接串中使用明文密码,密码可以通过~/.pgpass,~/.pg_service,环境变量等方式管理,下面使用时将不会列出密码。
PGSRC='postgres://dbuser_admin@10.10.10.10/meta' # 源端发布者 (SU)
PGDST='postgres://dbuser_admin@10.10.10.11/test' # 宿端订阅者 (SU)
建议在中控机/元节点上执行迁移命令,并在操作过程中保持上面两个变量生效。
1.2 确定迁移对象
相比于物理复制,逻辑复制允许用户对复制的内容与过程施加更为精细的控制。您可以选择数据库内容的一个子集进行复制。不过在这个例子中,我们将进行整库复制。
在本例中,我们采用pgbench提供的用例作为迁移标的。因此可以在源端集群使用pgbench初始化相关表项。
此外,考虑到测试的覆盖范围,我们还将创建一张额外的测试数据表(用于测试Sequence的迁移)
psql ${PGSRC} -qAXtw <<-EOF
DROP TABLE IF EXISTS pgbench_extras;
CREATE TABLE IF NOT EXISTS pgbench_extras
(id BIGSERIAL PRIMARY KEY,v TIMESTAMP NOT NULL UNIQUE);
EOF
要注意,只有 基本表 (包括分区表)可以参与逻辑复制,其他类型的对象,包括 视图,物化视图,外部表,索引,序列号都无法加入到逻辑复制中。使用以下查询,可以列出当前数据库中可以加入逻辑复制的表的完全限定名。
SELECT quote_ident(nspname) || '.' || quote_ident(relname) AS name
FROM pg_class c JOIN pg_namespace n ON c.relnamespace = n.oid
WHERE relkind = 'r' AND nspname NOT IN ('pg_catalog', 'information_schema', 'monitor', 'repack', 'pg_toast')
在准备阶段,您需要筛选出希望进行复制的表。在存量迁移中将这些表的结构定义同步至宿集群中,并建立在这些表上的逻辑复制。
1.3 修复复制标识
并不是所有的表都可以直接纳入逻辑复制中并正常工作。在进行迁移前,您需要对所有待迁移的表进行检查,确认它们都已经正确配置了复制标识。
| 复制身份模式\表上的约束 |
主键(p) |
非空唯一索引(u) |
两者皆无(n) |
| default |
有效 |
x |
x |
| index |
x |
有效 |
x |
| full |
低效 |
低效 |
低效 |
| nothing |
x |
x |
x |
-
如果表上有主键,则会默认使用 REPLICA IDENTITY default,这是最好的,不用进行任何修改。
-
如果表上没有主键,有条件的话请创建一个,没有条件的话,一个建立在非空列集上的唯一索引也可以起到同样的作用。在这种情况下需要显式的为表配置REPLICA IDENTITY USING <tbl_unique_key_idx_name>。
-
如果表上既没有主键,也没有唯一索引,那么您可以为表配置REPLICA IDENTITY FULL,将完整的一行作为复制标识。
使用FULL身份标识的性能非常差,发布侧和订阅侧的删改操作都会导致顺序扫表,建议只将其作为保底手段使用。
另一种选择是为表配置REPLICA IDENTITY NOTHING,这样任何在发布端对此表进行UPDATE|DELETE操作都会直接报错中止。
使用以下查询,可以列出所有表的完全限定名,复制标识配置,以及表上是否有主键或唯一索引,
SELECT quote_ident(nspname) || '.' || quote_ident(relname) AS name, con.ri AS keys,
CASE relreplident WHEN 'd' THEN 'default' WHEN 'n' THEN 'nothing' WHEN 'f' THEN 'full' WHEN 'i' THEN 'index' END AS identity
FROM pg_class c JOIN pg_namespace n ON c.relnamespace = n.oid, LATERAL (SELECT array_agg(contype) AS ri FROM pg_constraint WHERE conrelid = c.oid) con
WHERE relkind = 'r' AND nspname NOT IN ('pg_catalog', 'information_schema', 'monitor', 'repack', 'pg_toast')
ORDER BY 2,3;
以1.2的测试场景为例:
name | keys | identity
-------------------------+-------+----------
public.spatial_ref_sys | {c,p} | default
public.pgbench_accounts | {p} | default
public.pgbench_branches | {p} | default
public.pgbench_tellers | {p} | default
public.pgbench_extras | {p,u} | default
public.pgbench_history | NULL | default
如果表上只有唯一索引,例如您需要检查该唯一索引是否满足要求:所有列都为非空,not deferrable,not partial,如果满足,则可以使用以下命令将表的复制身份修改为index模式。
-- 一个例子:即使pgbench_extras上有主键,但也可以使用唯一索引作为身份标识
ALTER TABLE pgbench_extras REPLICA IDENTITY USING INDEX pgbench_extras_v_key;
如果表上没有主键,也没有唯一约束。如上面的pgbench_history表,那就需要通过以下命令将其复制身份设置为FULL|NOTHING。
ALTER TABLE pgbench_history REPLICA IDENTITY FULL;
完成修复后,所有表都应当具有合适的复制身份:
name | keys | identity
-------------------------+-------+----------
public.spatial_ref_sys | {c,p} | default
public.pgbench_accounts | {p} | default
public.pgbench_branches | {p} | default
public.pgbench_tellers | {p} | default
public.pgbench_extras | {p,u} | index
public.pgbench_history | NULL | full
2 存量迁移
2.1 同步数据库模式
2.1.1 转储
使用以下命令转储所有对象定义,并复制到宿端应用。
pg_dump ${PGSRC} --schema-only -n public | psql ${PGDST}
可以通过pg_dump的-n,-t参数进行灵活控制,只转储所需的对象。例如,如果只需要public模式下pgbench的相关表,则可以通过以下命令转储:
pg_dump ${PGSRC} --schema-only -n public -t 'pgbench_*' | psql ${PGDST}
2.1.2 校验
同步完成后,通常需要进行模式校验。
- 所有目标表及其索引、序列号是否已经建立
- 函数、类型、模式、用户、权限是否均符合预期?
数据库模式需要根据用户自己的需求进行同步与校验,没有什么通用的方式。
2.2 在源端创建发布
源端集群主库作为发布者,需要创建发布,将所需的表加入到发布集中。
2.2.1 创建发布的方式
创建发布的语法如下所示:
CREATE PUBLICATION name
[ FOR TABLE [ ONLY ] table_name [ * ] [, ...]
| FOR ALL TABLES ]
[ WITH ( publication_parameter [= value] [, ... ] ) ]
针对所有表创建发布(需要超级用户权限):
CREATE PUBLICATION "pg_meta_pub" FOR ALL TABLES;
注意无论是发布还是订阅,名称都建议遵循PostgreSQL对象标识符命名规则([a-z][0-9a-z_]+),特别是不要在名称中使用-。以免不必要的麻烦,例如创建订阅同名的复制槽因命名不规范而失败。
如果需要控制订阅的事件类型(不常见),可以通过参数publish指定,默认为insert, update, delete, truncate。
如果源端上有分区表,有一个参数可以用于控制其复制行为。把分区表当成一张表(使用分区根表的复制标识),还是当成多张子表(使用子表上的复制标识)来处理。启用这个选项可以把分区表在逻辑上看成一张表(分区根表),而不是一系列的分区子表,所以订阅端只需要存在一张分区根表的同名表即可正常复制,这是13版本引入的新选项。该选项默认为false,也就是说逻辑复制分区表时,源端的每一个分区都必须在订阅端存在。
额外的参数可以通过以下的形式传入:
CREATE PUBLICATION "pg_meta_pub" FOR ALL TABLES
WITH(publish = 'insert', publish_via_partition_root = true);
2.2.2 发布的内容
如果不希望发布所有的表,则可以在发布中具体指定所需的表名称。
例如在这个例子中spatial_ref_sys是一张postgis扩展使用的常量表,并不需要迁移,我们可以将其排除。利用以下SQL,可以直接在数据库中拼接出创建发布的SQL命令:
SELECT E'CREATE PUBLICATION pg_meta_pub FOR TABLE\n' ||
string_agg(quote_ident(nspname) || '.' || quote_ident(relname), E',\n') || ';' AS sql
FROM pg_class c JOIN pg_namespace n ON c.relnamespace = n.oid
WHERE relkind = 'r' AND nspname NOT IN ('pg_catalog', 'information_schema', 'monitor', 'repack', 'pg_toast')
AND relname ~ 'pgbench'; -- 只复制表名形如 pgbench* 的表
\gexec -- 在psql中执行上面命令生成的SQL语句
在这个例子中,实际生成并执行的命令如下:
psql ${PGSRC} -Xtw <<-EOF
CREATE PUBLICATION pg_meta_pub FOR TABLE
public.pgbench_accounts,
public.pgbench_branches,
public.pgbench_tellers,
public.pgbench_history,
public.pgbench_extras;
EOF
2.2.3 确认发布状态
建立完发布后,可以从 pg_publication 视图看到所创建的发布。
$ psql ${PGSRC} -Xxwc 'table pg_publication;'
-[ RECORD 1 ]+------------
oid | 24679
pubname | pg_meta_pub
pubowner | 10
puballtables | f
pubinsert | t
pubupdate | t
pubdelete | t
pubtruncate | t
pubviaroot | f
可以从pg_publication_tables确认纳入到发布中的表有哪些。
$ psql ${PGSRC} -Xwc 'table pg_publication_tables;'
pubname | schemaname | tablename
-------------+------------+------------------
pg_meta_pub | public | pgbench_history
pg_meta_pub | public | pgbench_tellers
pg_meta_pub | public | pgbench_accounts
pg_meta_pub | public | pgbench_branches
pg_meta_pub | public | pgbench_extras
确认无误后,发布端的工作完成。接下来要在宿端集群主库上创建订阅,订阅源端集群主库上的这个发布。
2.3 在宿端创建订阅
宿端集群主库作为订阅者,需要创建订阅,从发布者上订阅所需的变更。
2.3.1 创建订阅
创建订阅需要SUPERUSER权限,创建订阅的语法如下所示:
CREATE SUBSCRIPTION subscription_name
CONNECTION 'conninfo'
PUBLICATION publication_name [, ...]
[ WITH ( subscription_parameter [= value] [, ... ] ) ]
创建订阅必须使用CONNECTION子句指定发布者的连接信息,通过PUBLICATION子句指定发布名称。这里使用replicator用户连接发布者,该用户的密码已经写入宿端实例下~/.pgpass,因此这里可以在连接串中省去。
创建订阅还有一些其他的参数,通常只有手动管理复制槽时才需要修改这些参数:
copy_data,默认为true,当复制开始时,是否要复制全量数据。create_slot,默认为true,该订阅是否会在发布实例上创建复制槽。enabled,默认为true,是否立即开始订阅。connect,默认为true,是否连接至订阅实例,如果不连接,上面几个选项都会被重置为false。
这里,创建订阅的实际命令为:
psql ${PGDST} -Xtw <<-EOF
CREATE SUBSCRIPTION "pg_test_sub"
CONNECTION 'host=10.10.10.10 user=replicator dbname=meta'
PUBLICATION "pg_meta_pub";
EOF
2.3.2 订阅状态确认
成功创建订阅后,可以从 pg_subscription 视图看到所创建的发布。
$ psql ${PGDST} -Xxwc 'TABLE pg_subscription;'
-[ RECORD 1 ]---+---------------------------------------------
oid | 20759
subdbid | 19351
subname | pg_test_sub
subowner | 16390
subenabled | t
subconninfo | host=10.10.10.10 user=replicator dbname=meta
subslotname | pg_test_sub
subsynccommit | off
subpublications | {pg_meta_pub}
可以从pg_subscription_rel中确认哪些表被纳入到订阅的范围,及其复制状态。
$ psql ${PGDST} -Xwc 'table pg_subscription_rel;'
srsubid | srrelid | srsubstate | srsublsn
---------+---------+------------+------------
20759 | 20742 | r | 0/B0BC1FB8
20759 | 20734 | r | 0/B0BC20B0
20759 | 20737 | r | 0/B0BC20B0
20759 | 20745 | r | 0/B0BC20B0
20759 | 20731 | r | 0/B0BC20B0
2.4 等待逻辑复制同步
创建订阅后,首先必须监控 发布端与订阅端两侧的数据库日志,确保没有错误产生。
2.4.1 逻辑复制状态机
如果一切正常,逻辑复制会自动开始,针对每张订阅中的表执行复制状态机逻辑,如下图所示。
当所有的表都完成复制,进入r(ready)状态时,逻辑复制的存量同步阶段便完成了,发布端与订阅端整体进入同步状态。
stateDiagram-v2
[*] --> init : 表被加入到订阅集中
init --> data : 开始同步表的初始快照
data --> sync : 存量数据同步完成
sync --> ready : 同步期间的增量变更应用完毕,进入就绪状态
当创建或刷新订阅时,表会被加入到 订阅集 中,每一张订阅集中的表都会在pg_subscription_rel视图中有一条对应纪录,展示这张表当前的复制状态。刚加入订阅集的表初始状态为i,即initialize,初始状态。
如果订阅的copy_data选项为真(默认情况),且工作进程池中有空闲的Worker,PostgreSQL会为这张表分配一个同步工作进程,同步这张表上的存量数据,此时表的状态进入d,即拷贝数据中。对表做数据同步类似于对数据库集群进行basebackup,Sync Worker会在发布端创建临时的复制槽,获取表上的快照并通过COPY完成基础数据同步。
当表上的基础数据拷贝完成后,表会进入sync模式,即数据同步,同步进程会追赶同步过程中发生的增量变更。当追赶完成时,同步进程会将这张表标记为r(ready)状态,转交逻辑复制主Apply进程管理变更,表示这张表已经处于正常复制中。
2.4.2 同步进度跟踪
数据同步(d)阶段可能需要花费一些时间,取决于网卡,网络,磁盘,表的大小与分布,逻辑复制的同步worker数量等因素。
作为参考,1TB的数据库,20张表,包含有250GB的大表,双万兆网卡,在6个数据同步worker的负责下大约需要6~8小时完成复制。
在数据同步过程中,每个表同步任务都会源端库上创建临时的复制槽。请确保逻辑复制初始同步期间不要给源端主库施加过大的不必要写入压力,以免WAL撑爆磁盘。
发布侧的 pg_stat_replication,pg_replication_slots,订阅端的pg_stat_subscription,pg_subscription_rel提供了逻辑复制状态的相关信息,需要关注。
psql ${PGDST} -Xxw <<-'EOF'
SELECT subname, json_object_agg(srsubstate, cnt) FROM
pg_subscription s JOIN
(SELECT srsubid, srsubstate, count(*) AS cnt FROM pg_subscription_rel
GROUP BY srsubid, srsubstate) sr
ON s.oid = sr.srsubid GROUP BY subname;
EOF
可以使用以下SQL确认订阅中表的状态,如果所有表的状态都显示为r,则表示逻辑复制已经成功建立,订阅端可以用于切换。
subname | json_object_agg
-------------+-----------------
pg_test_sub | { "r" : 5 }
当然,最好的方式始终是通过监控系统来跟踪复制状态。
3 切换时刻
3.1 准备工作
一个良好的工程实践是,在搞事情之前,在源端宿端都执行几次存盘操作,避免后续操作因被内存刷盘拖慢。
也可以执行分析命令更新统计信息,便于后续快速对比校验数据完整性。
psql ${PGSRC} -Xxwc 'CHECKPOINT;ANALYZE;CHECKPOINT;'
psql ${PGSRC} -Xxwc 'CHECKPOINT;ANALYZE;CHECKPOINT;'
在此之后的操作,都处于服务不可用状态,因此尽可能快地进行。通常情况下在分钟级内完成较为合适。
3.2 停止源端写入流量
3.2.1 选择合适的停止方式
暂停源端写入有多种方式,请根据实际业务场景选择与组合:
- 告知业务方停止流量
- 停止解析源端主库域名
- 停止或暂停负载均衡器(Haproxy | VIP)的流量转发
- 停止或暂停连接池Pgbouncer
- 停止或暂停Postgres实例
- 修改数据库主库的参数,设置默认事务模式为只读。
- 修改数据库主库的HBA规则,拒绝业务访问。
通常建议使用修改HBA,修改连接池,修改负载均衡器的方式停止主库的写入流量。
请注意,无论使用何种方式,建议保持PostgreSQL存活,并且管理用户和复制用户仍然可以连接到源端主库。
3.2.2 确认源端写入流量停止
当源端主库停止接受写入后,首先执行确认逻辑,通过观察pg_stat_replication,确认逻辑订阅者已经与发布者保持同步。
psql ${PGSRC} -Xxw <<-EOF
SELECT application_name AS name,
pg_current_wal_lsn() AS lsn,
pg_current_wal_lsn() - replay_lsn AS lag
FROM pg_stat_replication;
EOF
-[ RECORD 1 ]-----
name | pg_test_sub
lsn | 0/B0C24918
lag | 0
重复执行上述命令,如果lsn字段保持不变,lag始终为0,就说明主库的写入流量已经正确停止,且逻辑从库上已经没有复制延迟,可以用于切换。
3.2.3 建立反向逻辑复制(可选)
如果要求迁移失败后业务可以随时回滚,可以在停止源端写入流量后,设置反向的逻辑复制,将后续订阅端(新主库)的变更反向同步至原来的发布端(旧主库)。不过此过程需要重新同步数据,耗时太久。通常情况下,只有在数据非常重要,且数据量不大或停机窗口足够长的情况下才适用于此方法。
首先停止宿端现有的逻辑订阅。必须停止现有逻辑复制才能继续后面的步骤,否则会形成循环复制。
停止源端写入流量后,继续维持逻辑复制没有意义,因此可以停止宿端的订阅。但建议保留该订阅,只是禁用它,以备迁移失败回滚。
psql ${PGDST} -qAXtwc 'ALTER SUBSCRIPTION pg_test_sub DISABLE;'
然后依照上述流程重新建立 反向的逻辑复制,这里只给出命令:
# 在宿端创建发布:pg_test_pub
psql ${PGDST} -Xtw <<-EOF
CREATE PUBLICATION pg_test_pub FOR TABLE
public.pgbench_accounts,
public.pgbench_branches,
public.pgbench_tellers,
public.pgbench_history,
public.pgbench_extras;
TABLE pg_publication;
EOF
# 在源端创建订阅
psql ${PGSRC} -Xtw <<-EOF
CREATE SUBSCRIPTION "pg_meta_sub"
CONNECTION 'host=10.10.10.11 user=replicator dbname=test'
PUBLICATION "pg_test_pub";
TABLE pg_subscription;
EOF
# 清空源端所有相关表(危险),等待/或者不等待同步完成
psql ${PGSRC} -Xtw <<-EOF
TRUNCATE TABLE
public.pgbench_accounts,
public.pgbench_branches,
public.pgbench_tellers,
public.pgbench_history,
public.pgbench_extras;
TABLE pg_publication;
EOF
3.3 同步序列号与其他对象
逻辑复制不复制序列号(Sequence),因此基于逻辑复制做Failover时,必须在切换前手工同步序列号的值。
3.3.1 从源端同步序列号值
如果您的序列号都是从表上的SERIAL列定义自动创建的,而且宿端库也单纯只从源端订阅,那么同步序列号比较简单。从订阅端找出所有需要同步的序列号:
PGSRC='postgres://dbuser_admin@10.10.10.10/meta' # 源端发布者 (SU)
PGDST='postgres://dbuser_admin@10.10.10.11/test' # 宿端订阅者 (SU)
-- 查询订阅端,生成的用于同步SEQUENCE的shell命令
psql ${PGDST} -qAXtw <<-'EOF'
SELECT 'pg_dump ${PGSRC} -a ' ||
string_agg('-t ' || quote_ident(schemaname) || '.' || quote_ident(sequencename), ' ') ||
' | grep setval | psql -qAXtw ${PGDST}'
FROM pg_sequences;
EOF
在本例中,只有pgbench_extras.id上有一个对应的SEQUENCE pgbench_extras_id_seq。这里生成的同步语句为
pg_dump ${PGSRC} -a -t public.pgbench_extras_id_seq | grep setval | psql -qAXtw ${PGDST}
比较复杂的情况,需要您手工生成这条命令,通过-t依次指定需要转储的序列号。
3.3.2 基于业务数据设置序列号值
另一种管理序列号的方式是直接根据表中的数据设置序列号的值,而无需从源端同步。
例如,表pgbench_extras.id的最大值为100,那么将订阅端端pgbench_extras_id_seq直接设置为一个足够大的值,例如100+10000 = 10100,就可以保证迁移后使用该序列号分配的新id不会与已有数据冲突。
采用这种方式,可以直接在故障切换前进行序列号的设置,减少迁移切换所需的停机时间。但这样可能会导致业务数据序列号分配出现空洞,对于一些边界条件与特殊的序列号使用场景需要特别小心。例如:序列号从未被使用过,序列号的增长步长为负数,采用函数发号器调用Sequence等。
直接设置序列号的命令如下所示:
psql ${PGDST} -qAXtw <<-'EOF'
SELECT pg_catalog.setval('public.pgbench_extras_id_seq', (SELECT max(id) + 1000 FROM pgbench_extras));
EOF
3.3.3 其他对象的同步
某些无法被逻辑复制处理的对象,也需要在这里一并进行同步。
例如:刷新物化视图,手工迁移大对象等。但这些功能很少有人会用到,所以在此不详细展开。
3.4 校验数据一致性
如果逻辑复制工作正常,通常不用校验数据,您可以在第二步中间执行多次对比校验以增强对逻辑复制的信心。
在停机窗口期间,建议只进行简单基本的数据校验,例如,比较表中的行数,主键的最大最小值是否一致。
以下函数用于执行这一校验
function compare_relation(){
local relname=$1
local identity=${2-'id'}
psql ${3-${PGSRC}} -AXtwc "SELECT count(*) AS cnt, max($identity) AS max, min($identity) AS min FROM ${relname};"
psql ${4-${PGDST}} -AXtwc "SELECT count(*) AS cnt, max($identity) AS max, min($identity) AS min FROM ${relname};"
}
compare_relation pgbench_accounts aid
compare_relation pgbench_branches bid
compare_relation pgbench_history tid
compare_relation pgbench_tellers tid
function compare_relation() {
local src_url=${1}
local dst_url=${2}
local relname=${3}
res1=$(psql "${src_url}" -AXtwc "SELECT count(*) AS cnt FROM ${relname};")
res2=$(psql "${dst_url}" -AXtwc "SELECT count(*) AS cnt FROM ${relname};")
if [[ "${res1}" == "${res2}" ]]; then
echo -e "[ok] ${relname}\t\t\t${res1}\t${res2}"
else
echo -e "[xx] ${relname}\t\t\t${res1}\t${res2}"
fi
}
function compare_all() {
local src_url=${1}
local dst_url=${2}
tables=$(psql ${src_url} -AXtwc "SELECT quote_ident(nspname) || '.' || quote_ident(relname) AS name FROM pg_class c JOIN pg_namespace n ON c.relnamespace = n.oid WHERE relkind = 'r' AND nspname NOT IN ('pg_catalog', 'information_schema', 'monitor', 'repack', 'pg_toast')")
for tbl in $tables; do
result=$(compare_relation "${src_url}" "${dst_url}" ${tbl})
echo ${result}
done
}
compare_all ${PGSRC} ${PGDST}
同时,也可以过一遍3.3中同步的序列号,确认其配置是否相同。
psql ${PGSRC} -qwXtc "SELECT schemaname || '.' || sequencename AS name, last_value AS v FROM pg_sequences;"
psql ${PGDST} -qwXtc "SELECT schemaname || '.' || sequencename AS name, last_value AS v FROM pg_sequences;"
其他在3.3.3中手工同步的对象请按需自行校验。如果需要进行其他业务侧的校验,也在这里进行。但停机窗口时间宝贵,花费在这里的时间越长,服务不可用时间也越久。
校验完成后,就可以进行最终的流量切换了。
3.5 流量切换与善后
完成数据校验后就可以进行流量切换。
流量切换的方式取决于您所使用的访问方式,通常与3.2中停流量的方式对偶。例如:
- 修改应用端连接串,并应用生效
- 将源端主库域名解析至新主库
- 将负载均衡器(Haproxy | VIP)的流量转发至新主库
- 将原主库上Pgbouncer连接池的流量转发至新主库
通过监控系统或其他方式,确认写入流量已经正确应用订阅端的新主库后,基于逻辑复制的迁移就完成了。
不要忘记一些善后清理工作,停用并删除订阅端的订阅,删除发布端的发布。
同时,应当继续确保原主库拒绝新的写入,以免有未清理干净的流量因为配置失误错漏仍然向旧主库访问。
# 删除订阅侧的 订阅
psql ${PGDST} -qAXtw <<-'EOF'
ALTER SUBSCRIPTION pg_test_sub DISABLE;
DROP SUBSCRIPTION pg_test_sub;
EOF
# 删除发布侧的 发布
psql ${PGSRC} -qAXtw <<-'EOF'
DROP PUBLICATION pg_meta_sub;
EOF
至此,基于逻辑复制的完整迁移结束。
7.2 - HA Drill
Be prepared for failures!
Simulate several common failures in production environments to test the self-healing capabilities of Pigsty’s highly available database cluster.
Patroni Quick Start
patronictl is the patroni cli tool, aliased as pt
alias pt='patronictl -c /pg/bin/patroni.yml'
alias pt-up='sudo systemctl start patroni' # launch patroni
alias pt-dw='sudo systemctl stop patroni' # stop patroni
alias pt-st='systemctl status patroni' # report patroni status
alias pt-ps='ps aux | grep patroni' # show patroni processes
alias pt-log='tail -f /pg/log/patroni.log' # watch patroni logs
Patroni commands requires dbsu (which is postgres by default )
$ pt --help
Usage: patronictl [OPTIONS] COMMAND [ARGS]...
Options:
-c, --config-file TEXT Configuration file
-d, --dcs TEXT Use this DCS
-k, --insecure Allow connections to SSL sites without certs
--help Show this message and exit.
Commands:
configure Create configuration file
dsn Generate a dsn for the provided member,...
edit-config Edit cluster configuration
failover Failover to a replica
flush Discard scheduled events
history Show the history of failovers/switchovers
list List the Patroni members for a given Patroni
pause Disable auto failover
query Query a Patroni PostgreSQL member
reinit Reinitialize cluster member
reload Reload cluster member configuration
remove Remove cluster from DCS
restart Restart cluster member
resume Resume auto failover
scaffold Create a structure for the cluster in DCS
show-config Show cluster configuration
switchover Switchover to a replica
topology Prints ASCII topology for given cluster
version Output version of patronictl command or a...
场景一:Switchover
Switch是主动切换集群领导者
$ pt switchover
Master [pg-test-3]: pg-test-3
Candidate ['pg-test-1', 'pg-test-2'] []: pg-test-1
When should the switchover take place (e.g. 2020-10-23T17:06 ) [now]: now
Current cluster topology
+ Cluster: pg-test (6886641621295638555) -----+----+-----------+-----------------+
| Member | Host | Role | State | TL | Lag in MB | Tags |
+-----------+-------------+---------+---------+----+-----------+-----------------+
| pg-test-1 | 10.10.10.11 | Replica | running | 2 | 0 | clonefrom: true |
| pg-test-2 | 10.10.10.12 | Replica | running | 2 | 0 | clonefrom: true |
| pg-test-3 | 10.10.10.13 | Leader | running | 2 | | clonefrom: true |
+-----------+-------------+---------+---------+----+-----------+-----------------+
Are you sure you want to switchover cluster pg-test, demoting current master pg-test-3? [y/N]: y
2020-10-23 16:06:11.76252 Successfully switched over to "pg-test-1"
场景二:Failover
# run as postgres @ any member of cluster `pg-test`
$ pt failover
Candidate ['pg-test-2', 'pg-test-3'] []: pg-test-3
Current cluster topology
+ Cluster: pg-test (6886641621295638555) -----+----+-----------+-----------------+
| Member | Host | Role | State | TL | Lag in MB | Tags |
+-----------+-------------+---------+---------+----+-----------+-----------------+
| pg-test-1 | 10.10.10.11 | Leader | running | 1 | | clonefrom: true |
| pg-test-2 | 10.10.10.12 | Replica | running | 1 | 0 | clonefrom: true |
| pg-test-3 | 10.10.10.13 | Replica | running | 1 | 0 | clonefrom: true |
+-----------+-------------+---------+---------+----+-----------+-----------------+
Are you sure you want to failover cluster pg-test, demoting current master pg-test-1? [y/N]: y
+ Cluster: pg-test (6886641621295638555) -----+----+-----------+-----------------+
| Member | Host | Role | State | TL | Lag in MB | Tags |
+-----------+-------------+---------+---------+----+-----------+-----------------+
| pg-test-1 | 10.10.10.11 | Replica | running | 2 | 0 | clonefrom: true |
| pg-test-2 | 10.10.10.12 | Replica | running | 2 | 0 | clonefrom: true |
| pg-test-3 | 10.10.10.13 | Leader | running | 2 | | clonefrom: true |
+-----------+-------------+---------+---------+----+-----------+-----------------+
场景三:从库Patroni/Postgres宕机
场景四:主库Patroni/Postgres宕机
场景五:DCS不可用
场景六:维护模式
问题探讨
关键问题:DCS的SLA如何保障?
==在自动切换模式下,如果DCS挂了,当前主库会在retry_timeout 后Demote成从库,导致所有集群不可写==。
作为分布式共识数据库,Consul/Etcd是相当稳健的,但仍必须确保DCS的SLA高于DB的SLA。
解决方法:配置一个足够大的retry_timeout,并通过几种以下方式从管理上解决此问题。
- SLA确保DCS一年的不可用时间短于该时长
- 运维人员能确保在
retry_timeout之内解决DCS Service Down的问题。
- DBA能确保在
retry_timeout之内将关闭集群的自动切换功能(打开维护模式)。
可以优化的点? 添加绕开DCS的P2P检测,如果主库意识到自己所处的分区仍为Major分区,不触发操作。
关键问题:HA策略,RPO优先或RTO优先?
可用性与一致性谁优先?例如,普通库RTO优先,金融支付类RPO优先。
普通库允许紧急故障切换时丢失极少量数据(阈值可配置,例如最近1M写入)
与钱相关的库不允许丢数据,相应地在故障切换时需要更多更审慎的检查或人工介入。
关键问题:Fencing机制,是否允许关机?
在正常情况下,Patroni会在发生Leader Change时先执行Primary Fencing,通过杀掉PG进程的方式进行。
但在某些极端情况下,比如vm暂停,软件Bug,或者极高负载,有可能没法成功完成这一点。那么就需要通过重启机器的方式一了百了。是否可以接受?在极端环境下会有怎样的表现?
关键操作:选主之后
选主之后要记得存盘。手工做一次Checkpoint确保万无一失。
关键问题:流量切换怎样做,2层,4层,7层
- 2层:VIP漂移
- 4层:Haproxy分发
- 7层:DNS域名解析
关键问题:一主一从的特殊场景
- 2层:VIP漂移
- 4层:Haproxy分发
- 7层:DNS域名解析
HA Procedure
Failure Detection
https://patroni.readthedocs.io/en/latest/SETTINGS.html#dynamic-configuration-settings
Fencing
https://patroni.readthedocs.io/en/latest/watchdog.html
Bad Cases
Traffic Routing
DNS
VIP
HAproxy
Pgbouncer

7.3 - How to optmize slow queries with pigsty
A typical example of optimizing slow queries
下面以Pigsty自带的沙箱环境为例,介绍一个使用Pigsty监控系统处理慢查询的过程。
慢查询:模拟
因为没有实际的业务系统,这里我们以一种简单快捷的方式模拟系统中的慢查询。即pgbench自带的tpc-c。
在主库上执行以下命令
ALTER TABLE pgbench_accounts DROP CONSTRAINT pgbench_accounts_pkey ;
该命令会移除 pgbench_accounts 表上的主键,导致相关查询变慢,系统瞬间雪崩过载。
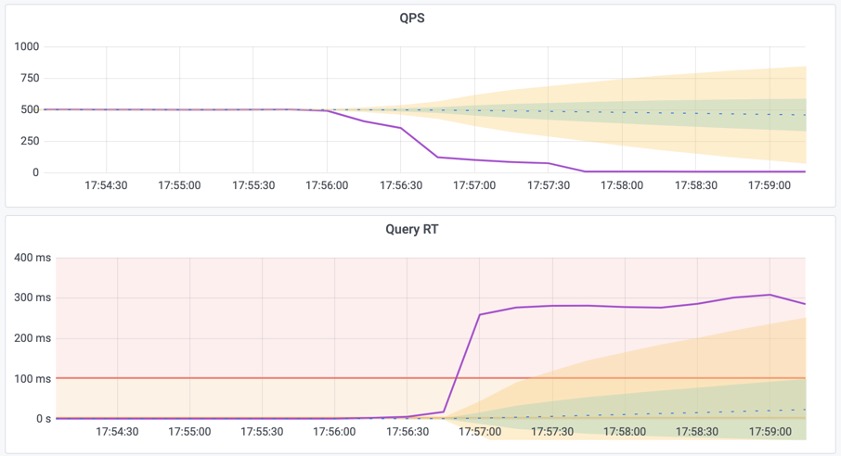
图1:单个从库实例的QPS从500下降至7,Query RT下降至300ms

图2:系统负载达到200%,触发机器负载过大,与查询响应时间过长的报警规则。
慢查询:定位
首先,使用PG Cluster面板定位慢查询所在的具体实例,这里以 pg-test-2为例
然后,使用PG Query面板定位具体的慢查询:编号为 -6041100154778468427
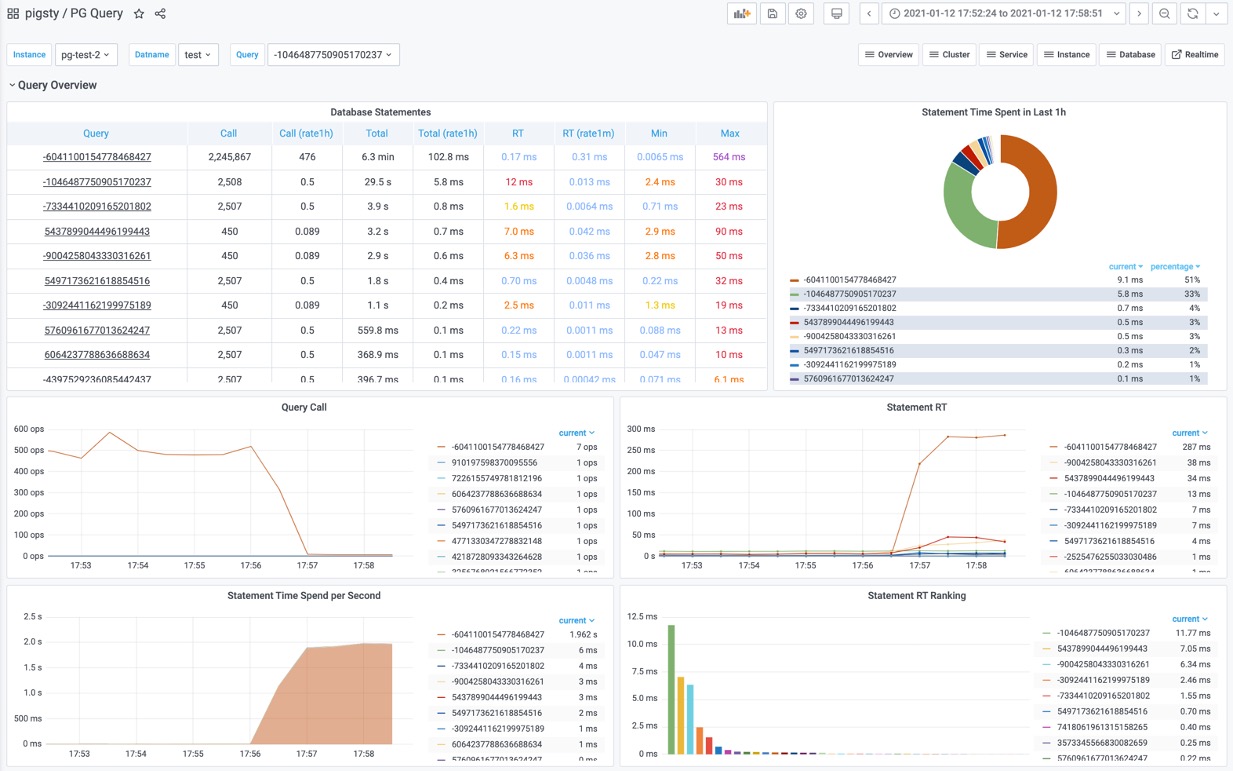
图3:从查询总览中发现异常慢查询
该查询表现出:
- 响应时间显著上升: 17us 升至 280ms
- QPS 显著下降: 从500下降到 7
- 花费在该查询上的时间占比显著增加
可以确定,就是这个查询变慢了!
接下来,利用PG Stat Statements面板或PG Query Detail,根据查询ID定位慢查询的具体语句。

图4:定位的查询是SELECT abalance FROM pgbench_accounts WHERE aid = $1
慢查询:猜想
接下来,我们需要推断慢查询产生的原因。
SELECT abalance FROM pgbench_accounts WHERE aid = $1
该查询以 aid 作为过滤条件查询 pgbench_accounts 表,如此简单的查询变慢,大概率是这张表上的索引出了问题。
用屁股想都知道是索引少了,因为就是我们自己删掉的嘛!
分析查询后提出猜想: 该查询变慢是pgbench_accounts表上aid列缺少索引
下一步,查阅 PG Table Detail 面板,检查 pgbench_accounts 表上的访问,来验证我们的猜想

图5: pgbench_accounts 表上的访问情况
通过观察,我们发现表上的索引扫描归零,与此同时顺序扫描却有相应增长。这印证了我们的猜想!
慢查询:解决
确定了问题根源后,我们将着手解决。
尝试在 pgbench_accounts 表上为 aid 列添加索引,看看能否解决这个问题。
加上索引后,神奇的事情发生了。

图6:可以看到,查询的响应时间与QPS已经恢复正常。
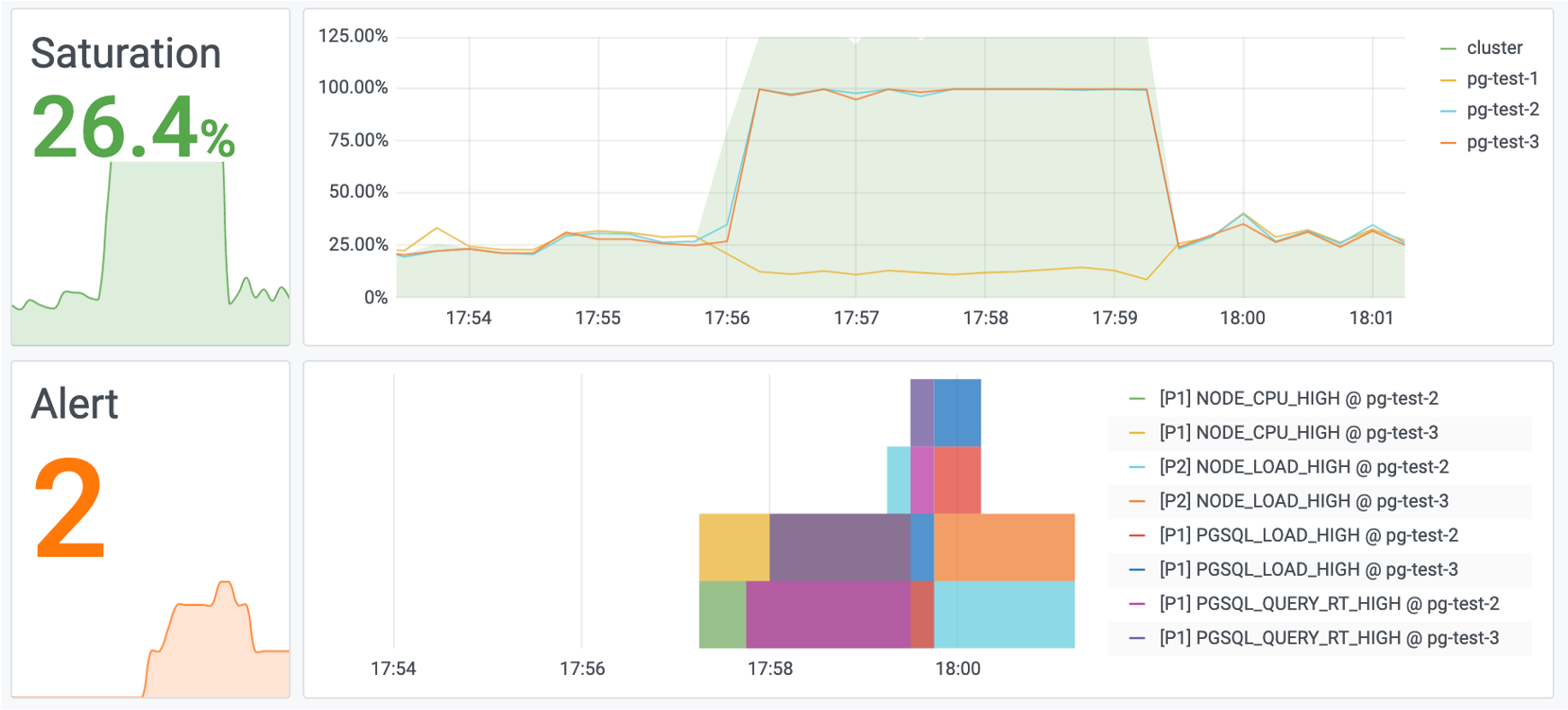
图7:系统的负载也恢复正常
慢查询:样例
通过这篇教程,您已经掌握了慢查询优化的一般方法论。
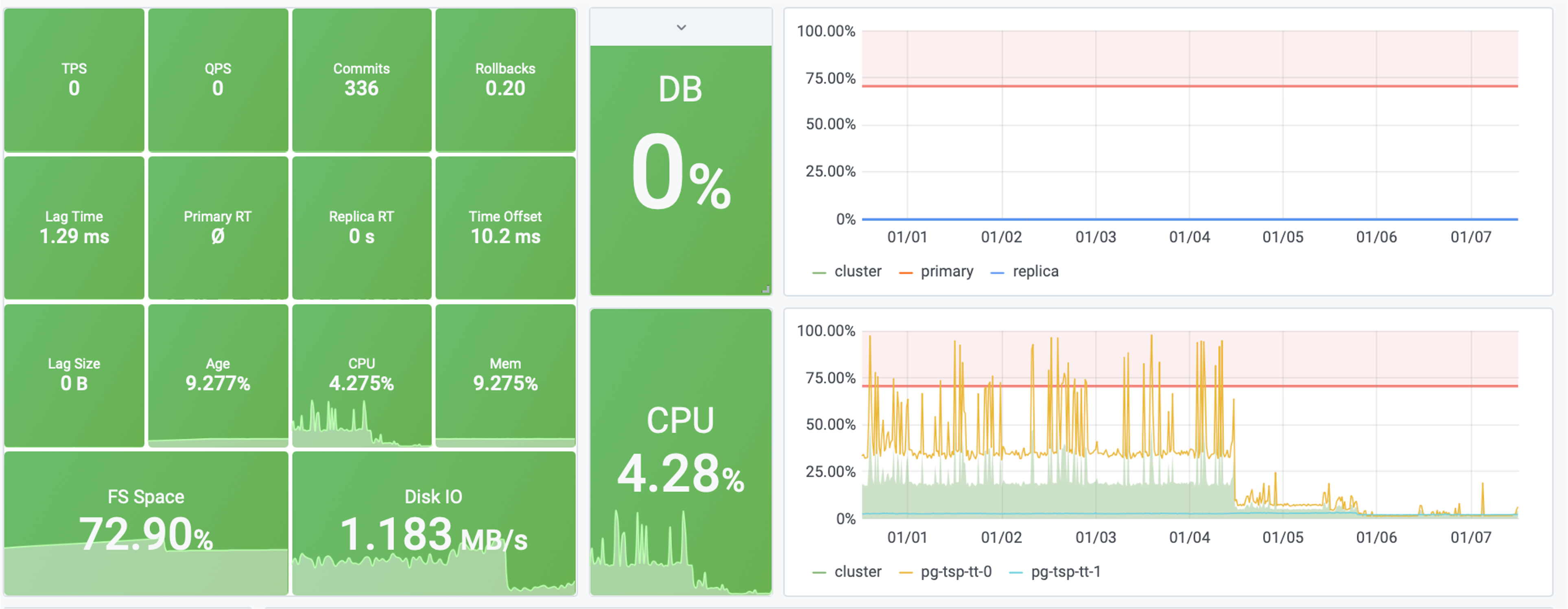
图8:一个慢查询优化的实际例子,将系统的饱和度从40%降到了4%
7.4 - App Example
Example application based on pigsty
If you have a database and don’t know what to do with it, check out another open source project by the author: Vonng/isd
You can directly reuse the monitoring system Grafana to interactively access sub-hourly weather data from nearly 30,000 surface weather stations over the past 120 years.
ISD – Intergrated Surface Data
All the tools you need to download, parse, process, and visualize NOAA ISD datasets are included here.
It gives you access to sub-hourly weather data from nearly 30,000 surface weather stations over the last 120 years. And experience the power of PostgreSQL for data analysis and processing!
SYNOPSIS
Download, Parse, Visualize Intergrated Suface Dataset.
Including 30000 meteorology station, sub-hourly observation records, from 1900-2020.
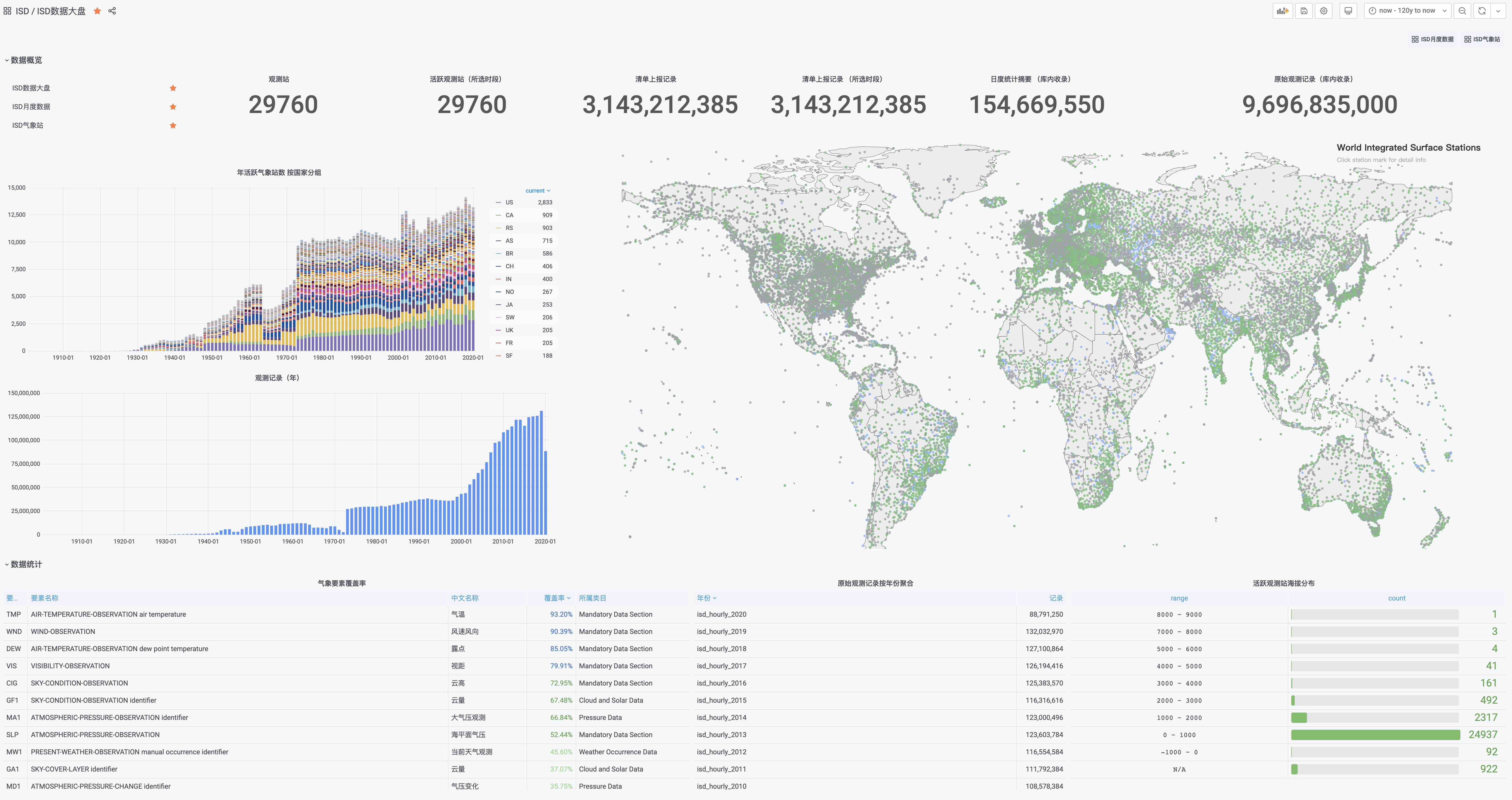
Quick Started
-
Clone repo
git clone https://github.com/Vonng/isd && cd isd
-
Prepare a postgres database
Connect via something like isd or postgres://user:pass@host/dbname)
# skip this if you already have a viable database
PGURL=postgres
psql ${PGURL} -c 'CREATE DATABASE isd;'
# database connection string, something like `isd` or `postgres://user:pass@host/dbname`
PGURL='isd'
psql ${PGURL} -AXtwc 'CREATE EXTENSION postgis;'
# create tables, partitions, functions
psql ${PGURL} -AXtwf 'sql/schema.sql'
-
Download data
- ISD Station: Station metadata, id, name, location, country, etc…
- ISD History: Station observation records: observation count per month
- ISD Hourly: Yearly archived station (sub-)hourly observation records
- ISD Daily: Yearly archvied station daily aggregated summary
git clone https://github.com/Vonng/isd && cd isd
bin/get-isd-station.sh # download isd station from noaa (proxy makes it faster)
bin/get-isd-history.sh # download isd history observation from noaa
bin/get-isd-hourly.sh <year> # download isd hourly data (yearly tarball 1901-2020)
bin/get-isd-daily.sh <year> # download isd daily data (yearly tarball 1929-2020)
-
Build Parser
There are two ISD dataset parsers written in Golang : isdh for isd hourly dataset and isdd for isd daily dataset.
make isdh and make isdd will build it and copy to bin. These parsers are required for loading data into database.
You can download pre-compiled binary to bin/ dir to skip this phase.
-
Load data
Metadata includes world_fences, china_fences, isd_elements, isd_mwcode, isd_station, isd_history. These are gzipped csv file lies in data/meta/. world_fences, china_fences, isd_elements, isd_mwcode are constant dict table. But isd_station and isd_history are frequently updated. You’ll have to download it from noaa before loading it.
# load metadata: fences, dicts, station, history,...
bin/load-meta.sh
# load a year's daily data to database
bin/load-isd-daily <year>
# load a year's hourly data to database
bin/laod-isd-hourly <year>
Note that the original isd_daily dataset has some un-cleansed data, refer caveat for detail.
Data
Dataset
Hourly Data: Oringinal tarball size 105GB, Table size 1TB (+600GB Indexes).
Daily Data: Oringinal tarball size 3.2GB, table size 24 GB
It is recommended to have 2TB storage for a full installation, and at least 40GB for daily data only installation.
Schema
Data schema definition
Station
CREATE TABLE public.isd_station
(
station VARCHAR(12) PRIMARY KEY,
usaf VARCHAR(6) GENERATED ALWAYS AS (substring(station, 1, 6)) STORED,
wban VARCHAR(5) GENERATED ALWAYS AS (substring(station, 7, 5)) STORED,
name VARCHAR(32),
country VARCHAR(2),
province VARCHAR(2),
icao VARCHAR(4),
location GEOMETRY(POINT),
longitude NUMERIC GENERATED ALWAYS AS (Round(ST_X(location)::NUMERIC, 6)) STORED,
latitude NUMERIC GENERATED ALWAYS AS (Round(ST_Y(location)::NUMERIC, 6)) STORED,
elevation NUMERIC,
period daterange,
begin_date DATE GENERATED ALWAYS AS (lower(period)) STORED,
end_date DATE GENERATED ALWAYS AS (upper(period)) STORED
);
Hourly Data
CREATE TABLE public.isd_hourly
(
station VARCHAR(11) NOT NULL,
ts TIMESTAMP NOT NULL,
temp NUMERIC(3, 1),
dewp NUMERIC(3, 1),
slp NUMERIC(5, 1),
stp NUMERIC(5, 1),
vis NUMERIC(6),
wd_angle NUMERIC(3),
wd_speed NUMERIC(4, 1),
wd_gust NUMERIC(4, 1),
wd_code VARCHAR(1),
cld_height NUMERIC(5),
cld_code VARCHAR(2),
sndp NUMERIC(5, 1),
prcp NUMERIC(5, 1),
prcp_hour NUMERIC(2),
prcp_code VARCHAR(1),
mw_code VARCHAR(2),
aw_code VARCHAR(2),
pw_code VARCHAR(1),
pw_hour NUMERIC(2),
data JSONB
) PARTITION BY RANGE (ts);
Daily Data
CREATE TABLE public.isd_daily
(
station VARCHAR(12) NOT NULL,
ts DATE NOT NULL,
temp_mean NUMERIC(3, 1),
temp_min NUMERIC(3, 1),
temp_max NUMERIC(3, 1),
dewp_mean NUMERIC(3, 1),
slp_mean NUMERIC(5, 1),
stp_mean NUMERIC(5, 1),
vis_mean NUMERIC(6),
wdsp_mean NUMERIC(4, 1),
wdsp_max NUMERIC(4, 1),
gust NUMERIC(4, 1),
prcp_mean NUMERIC(5, 1),
prcp NUMERIC(5, 1),
sndp NuMERIC(5, 1),
is_foggy BOOLEAN,
is_rainy BOOLEAN,
is_snowy BOOLEAN,
is_hail BOOLEAN,
is_thunder BOOLEAN,
is_tornado BOOLEAN,
temp_count SMALLINT,
dewp_count SMALLINT,
slp_count SMALLINT,
stp_count SMALLINT,
wdsp_count SMALLINT,
visib_count SMALLINT,
temp_min_f BOOLEAN,
temp_max_f BOOLEAN,
prcp_flag CHAR,
PRIMARY KEY (ts, station)
) PARTITION BY RANGE (ts);
Update
ISD Daily and ISD hourly dataset will rolling update each day. Run following scripts to load latest data into database.
# download, clean, reload latest hourly dataset
bin/get-isd-daily.sh
bin/load-isd-daily.sh
# download, clean, reload latest daily dataset
bin/get-isd-daily.sh
bin/load-isd-daily.sh
# recalculate latest partition of monthly and yearly
bin/refresh-latest.sh
Parser
There are two parser: isdd and isdh, which takes noaa original yearly tarball as input, generate CSV as output (which could be directly consume by PostgreSQL Copy command).
NAME
isdh -- Intergrated Surface Dataset Hourly Parser
SYNOPSIS
isdh [-i <input|stdin>] [-o <output|st>] -p -d -c -v
DESCRIPTION
The isdh program takes isd hourly (yearly tarball file) as input.
And generate csv format as output
OPTIONS
-i <input> input file, stdin by default
-o <output> output file, stdout by default
-p <profpath> pprof file path (disable by default)
-v verbose progress report
-d de-duplicate rows (raw, ts-first, hour-first)
-c add comma separated extra columns
UI
ISD Station
ISD Monthly
8 - Business
Need professional support ?
Pigisty is an open source project. Free of charge.
If you need professional support.:Contact me for more information: @Vonng(rh@vonng.com)
For example:
- Complete version of monitoring system.
- Security Enhancement
- Extra dashboards
- Meta database and catalog explore
- Logging summary system
- Backup / Recovery plan
- Existing system intergration
- Failure diagnostic
- Customize support
- Tickets
8.1 - Compare
Comparing to other monitoring solution for PostgreSQL
Overview
some candidates:
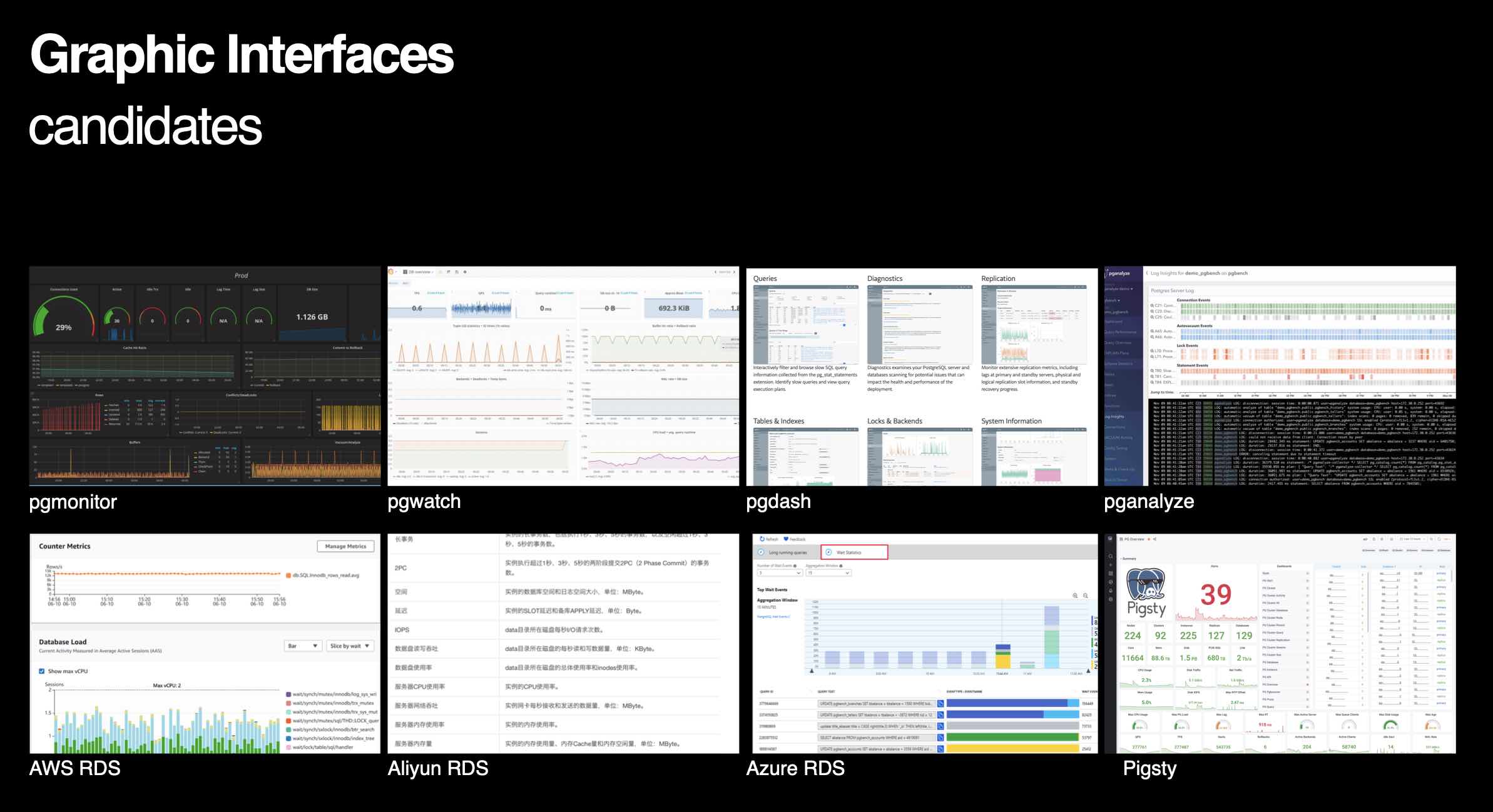
Comparsion
Here is a cross-sectional comparison of the number of metrics. Only database-related metrics are taken here, meaning that the machine CPU disk metrics are left aside.
There are some open source, or commercial, or cloud vendor’s PG monitoring system, here according to their publicly available code or documentation for statistics. A family of words is suspected of selling the melon and boasting, welcome your correction. At least on the order of magnitude, this chart is still not too much of a problem, refer to the link at the end of the article for details.
One might ask, although the metrics look impressive with a lot of metrics, what is the practical significance of this? It is true that for fault alerting only a few key metrics are needed. But adequate metrics coverage can further improve our insight and control over the database, and that can’t be too high, more is better.
Competitor
PGWatch
PG Analyze

PGDash
PGMonitor
AWS RDS
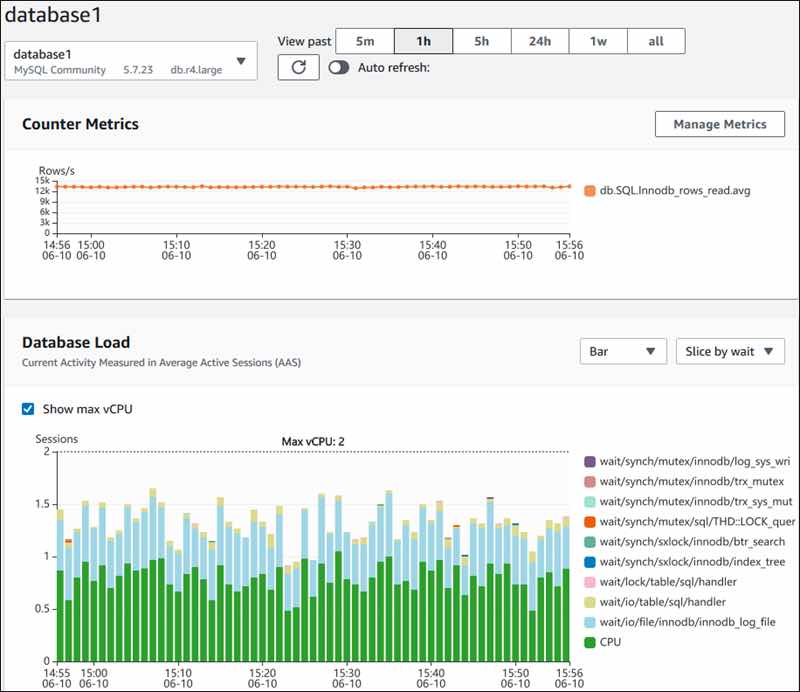
Azure RDS
Aliyun RDS
参考连接
pgwatch
pgmonitor
datadog
pgDash
ClusterControl
pganalyze
Aliyun RDS
AWS RDS
Azure RDS
8.2 - Open Source
Why pigsty choose open source?
Pigsty was designed with the intention of making up for the regrets in the PostgreSQL open source ecosystem. Based on open source, it is only right to give back to the community.
Pigsty is based on open source component customization, so it has chosen to become an open source project itself, based on the Apache 2.0 License open source.
This thing can really sell money, so also provide optional commercial support.
The commercial version will have more monitoring panels and metrics, but the open source version itself is also completely more than adequate for production use.
Despite the choice of open source, but still respect the cloud vendors: although you can use, white whoring is not good, at least please respect the original author ha.
8.3 - Roadmap
Next steps for pigsty
Version planning
Pigsty current version is v0.8.0 in RC status. However, it is guaranteed that the supply solution function Freeze and API will not be changed.
The next version v0.9.0 will be the last overall calibration of the monitoring system metrics, rules, visualization scheme and enter RC state (May 2021).
It will enter GA state (June 2021) in v1.0 (mid 2021).
After v1.0, no new features will be added to the provisioning solution section, focusing on the development and optimization of monitoring system metrics and panels.
Database Administration
- admin-report.yml
- admin-backup.yml
- admin-repack.yml
- admin-vacuum.yml
- admin-deploy.yml
- admin-restart.yml
- admin-reload.yml
- admin-createdb.yml
- admin-createuser.yml
- admin-edit-hba.yml
- admin-edit-config.yml
- admin-dump-schema.yml
- admin-dump-table.yml
- admin-copy-data.yml
- admin-pg-exporter-reload.yml
Database HA
- ha-switchover.yml
- ha-failover.yml
- ha-election.yml
- ha-rewind.yml
- ha-restore.yml
- ha-pitr.yml
- ha-drain.yml
- ha-proxy-add.yml
- ha-proxy-remove.yml
- ha-proxy-switch.yml
- ha-repl-report.yml
- ha-repl-sync.yml
- ha-repl-retarget.yml
- ha-pool-retarget.yml
- ha-pool-pause.yml
- ha-pool-resume.yml
- Intergrate Haproxy admin web UI to nginx
- Add blackbox exporter support
- add complete etcd support
- add L4 VIP support
- add pgbadger logging summary support
- add citus deployment
- add slow query auto analyze features
- add pev2 to pigsty
- other enhancement to monitoring dashboards
9 - Reference
Low level reference about pigsty
9.1 - Example Config
Example config file for pigsty sandbox
以下是用于沙箱环境的默认配置文件:pigsty.yml
---
######################################################################
# File : pigsty.yml
# Path : pigsty.yml
# Desc : Pigsty Configuration file
# Note : follow ansible inventory file format
# Ctime : 2020-05-22
# Mtime : 2021-03-16
# Copyright (C) 2018-2021 Ruohang Feng
######################################################################
######################################################################
# Development Environment Inventory #
######################################################################
all: # top-level namespace, match all hosts
#==================================================================#
# Clusters #
#==================================================================#
# postgres database clusters are defined as kv pair in `all.children`
# where the key is cluster name and the value is the object consist
# of cluster members (hosts) and ad-hoc variables (vars)
# meta node are defined in special group "meta" with `meta_node=true`
children:
#-----------------------------
# meta controller
#-----------------------------
meta: # special group 'meta' defines the main controller machine
vars:
meta_node: true # mark node as meta controller
ansible_group_priority: 99 # meta group is top priority
# nodes in meta group
hosts: {10.10.10.10: {ansible_host: meta}}
#-----------------------------
# cluster: pg-meta
#-----------------------------
pg-meta:
# - cluster members - #
hosts:
10.10.10.10: {pg_seq: 1, pg_role: primary, ansible_host: meta}
# - cluster configs - #
vars:
pg_cluster: pg-meta # define actual cluster name
pg_version: 13 # define installed pgsql version
node_tune: tiny # tune node into oltp|olap|crit|tiny mode
pg_conf: tiny.yml # tune pgsql into oltp/olap/crit/tiny mode
patroni_mode: pause # enter maintenance mode, {default|pause|remove}
patroni_watchdog_mode: off # disable watchdog (require|automatic|off)
pg_lc_ctype: en_US.UTF8 # enabled pg_trgm i18n char support
pg_users:
# complete example of user/role definition for production user
- name: dbuser_meta # example production user have read-write access
password: DBUser.Meta # example user's password, can be encrypted
login: true # can login, true by default (should be false for role)
superuser: false # is superuser? false by default
createdb: false # can create database? false by default
createrole: false # can create role? false by default
inherit: true # can this role use inherited privileges?
replication: false # can this role do replication? false by default
bypassrls: false # can this role bypass row level security? false by default
connlimit: -1 # connection limit, -1 disable limit
expire_at: '2030-12-31' # 'timestamp' when this role is expired
expire_in: 365 # now + n days when this role is expired (OVERWRITE expire_at)
roles: [dbrole_readwrite] # dborole_admin|dbrole_readwrite|dbrole_readonly
pgbouncer: true # add this user to pgbouncer? false by default (true for production user)
parameters: # user's default search path
search_path: public
comment: test user
# simple example for personal user definition
- name: dbuser_vonng2 # personal user example which only have limited access to offline instance
password: DBUser.Vonng # or instance with explict mark `pg_offline_query = true`
roles: [dbrole_offline] # personal/stats/ETL user should be grant with dbrole_offline
expire_in: 365 # expire in 365 days since creation
pgbouncer: false # personal user should NOT be allowed to login with pgbouncer
comment: example personal user for interactive queries
pg_databases:
- name: meta # name is the only required field for a database
# owner: postgres # optional, database owner
# template: template1 # optional, template1 by default
# encoding: UTF8 # optional, UTF8 by default , must same as template database, leave blank to set to db default
# locale: C # optional, C by default , must same as template database, leave blank to set to db default
# lc_collate: C # optional, C by default , must same as template database, leave blank to set to db default
# lc_ctype: C # optional, C by default , must same as template database, leave blank to set to db default
allowconn: true # optional, true by default, false disable connect at all
revokeconn: false # optional, false by default, true revoke connect from public # (only default user and owner have connect privilege on database)
# tablespace: pg_default # optional, 'pg_default' is the default tablespace
connlimit: -1 # optional, connection limit, -1 or none disable limit (default)
extensions: # optional, extension name and where to create
- {name: postgis, schema: public}
parameters: # optional, extra parameters with ALTER DATABASE
enable_partitionwise_join: true
pgbouncer: true # optional, add this database to pgbouncer list? true by default
comment: pigsty meta database # optional, comment string for database
pg_default_database: meta # default database will be used as primary monitor target
# proxy settings
vip_mode: l2 # enable/disable vip (require members in same LAN)
vip_address: 10.10.10.2 # virtual ip address
vip_cidrmask: 8 # cidr network mask length
vip_interface: eth1 # interface to add virtual ip
#-----------------------------
# cluster: pg-test
#-----------------------------
pg-test: # define cluster named 'pg-test'
# - cluster members - #
hosts:
10.10.10.11: {pg_seq: 1, pg_role: primary, ansible_host: node-1}
10.10.10.12: {pg_seq: 2, pg_role: replica, ansible_host: node-2}
10.10.10.13: {pg_seq: 3, pg_role: offline, ansible_host: node-3}
# - cluster configs - #
vars:
# basic settings
pg_cluster: pg-test # define actual cluster name
pg_version: 13 # define installed pgsql version
node_tune: tiny # tune node into oltp|olap|crit|tiny mode
pg_conf: tiny.yml # tune pgsql into oltp/olap/crit/tiny mode
# business users, adjust on your own needs
pg_users:
- name: test # example production user have read-write access
password: test # example user's password
roles: [dbrole_readwrite] # dborole_admin|dbrole_readwrite|dbrole_readonly|dbrole_offline
pgbouncer: true # production user that access via pgbouncer
comment: default test user for production usage
pg_databases: # create a business database 'test'
- name: test # use the simplest form
pg_default_database: test # default database will be used as primary monitor target
# proxy settings
vip_mode: l2 # enable/disable vip (require members in same LAN)
vip_address: 10.10.10.3 # virtual ip address
vip_cidrmask: 8 # cidr network mask length
vip_interface: eth1 # interface to add virtual ip
#==================================================================#
# Globals #
#==================================================================#
vars:
#------------------------------------------------------------------------------
# CONNECTION PARAMETERS
#------------------------------------------------------------------------------
# this section defines connection parameters
# ansible_user: vagrant # admin user with ssh access and sudo privilege
proxy_env: # global proxy env when downloading packages
no_proxy: "localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.aliyuncs.com,mirrors.tuna.tsinghua.edu.cn,mirrors.zju.edu.cn"
# http_proxy: ''
# https_proxy: ''
# all_proxy: ''
#------------------------------------------------------------------------------
# REPO PROVISION
#------------------------------------------------------------------------------
# this section defines how to build a local repo
# - repo basic - #
repo_enabled: true # build local yum repo on meta nodes?
repo_name: pigsty # local repo name
repo_address: yum.pigsty # repo external address (ip:port or url)
repo_port: 80 # listen address, must same as repo_address
repo_home: /www # default repo dir location
repo_rebuild: false # force re-download packages
repo_remove: true # remove existing repos
# - where to download - #
repo_upstreams:
- name: base
description: CentOS-$releasever - Base - Aliyun Mirror
baseurl:
- http://mirrors.aliyun.com/centos/$releasever/os/$basearch/
- http://mirrors.aliyuncs.com/centos/$releasever/os/$basearch/
- http://mirrors.cloud.aliyuncs.com/centos/$releasever/os/$basearch/
gpgcheck: no
failovermethod: priority
- name: updates
description: CentOS-$releasever - Updates - Aliyun Mirror
baseurl:
- http://mirrors.aliyun.com/centos/$releasever/updates/$basearch/
- http://mirrors.aliyuncs.com/centos/$releasever/updates/$basearch/
- http://mirrors.cloud.aliyuncs.com/centos/$releasever/updates/$basearch/
gpgcheck: no
failovermethod: priority
- name: extras
description: CentOS-$releasever - Extras - Aliyun Mirror
baseurl:
- http://mirrors.aliyun.com/centos/$releasever/extras/$basearch/
- http://mirrors.aliyuncs.com/centos/$releasever/extras/$basearch/
- http://mirrors.cloud.aliyuncs.com/centos/$releasever/extras/$basearch/
gpgcheck: no
failovermethod: priority
- name: epel
description: CentOS $releasever - EPEL - Aliyun Mirror
baseurl: http://mirrors.aliyun.com/epel/$releasever/$basearch
gpgcheck: no
failovermethod: priority
- name: grafana
description: Grafana - TsingHua Mirror
gpgcheck: no
baseurl: https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm
- name: prometheus
description: Prometheus and exporters
gpgcheck: no
baseurl: https://packagecloud.io/prometheus-rpm/release/el/$releasever/$basearch
# consider using ZJU PostgreSQL mirror in mainland china
- name: pgdg-common
description: PostgreSQL common RPMs for RHEL/CentOS $releasever - $basearch
gpgcheck: no
# baseurl: https://download.postgresql.org/pub/repos/yum/common/redhat/rhel-$releasever-$basearch
baseurl: http://mirrors.zju.edu.cn/postgresql/repos/yum/common/redhat/rhel-$releasever-$basearch
- name: pgdg13
description: PostgreSQL 13 for RHEL/CentOS $releasever - $basearch
gpgcheck: no
# baseurl: https://download.postgresql.org/pub/repos/yum/13/redhat/rhel-$releasever-$basearch
baseurl: http://mirrors.zju.edu.cn/postgresql/repos/yum/13/redhat/rhel-$releasever-$basearch
- name: centos-sclo
description: CentOS-$releasever - SCLo
gpgcheck: no
mirrorlist: http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-sclo
- name: centos-sclo-rh
description: CentOS-$releasever - SCLo rh
gpgcheck: no
mirrorlist: http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-rh
- name: nginx
description: Nginx Official Yum Repo
skip_if_unavailable: true
gpgcheck: no
baseurl: http://nginx.org/packages/centos/$releasever/$basearch/
- name: haproxy
description: Copr repo for haproxy
skip_if_unavailable: true
gpgcheck: no
baseurl: https://download.copr.fedorainfracloud.org/results/roidelapluie/haproxy/epel-$releasever-$basearch/
# for latest consul & kubernetes
- name: harbottle
description: Copr repo for main owned by harbottle
skip_if_unavailable: true
gpgcheck: no
baseurl: https://download.copr.fedorainfracloud.org/results/harbottle/main/epel-$releasever-$basearch/
# - what to download - #
repo_packages:
# repo bootstrap packages
- epel-release nginx wget yum-utils yum createrepo # bootstrap packages
# node basic packages
- ntp chrony uuid lz4 nc pv jq vim-enhanced make patch bash lsof wget unzip git tuned # basic system util
- readline zlib openssl libyaml libxml2 libxslt perl-ExtUtils-Embed ca-certificates # basic pg dependency
- numactl grubby sysstat dstat iotop bind-utils net-tools tcpdump socat ipvsadm telnet # system utils
# dcs & monitor packages
- grafana prometheus2 pushgateway alertmanager # monitor and ui
- node_exporter postgres_exporter nginx_exporter blackbox_exporter # exporter
- consul consul_exporter consul-template etcd # dcs
# python3 dependencies
- ansible python python-pip python-psycopg2 audit # ansible & python
- python3 python3-psycopg2 python36-requests python3-etcd python3-consul # python3
- python36-urllib3 python36-idna python36-pyOpenSSL python36-cryptography # python3 patroni extra deps
# proxy and load balancer
- haproxy keepalived dnsmasq # proxy and dns
# postgres common Packages
- patroni patroni-consul patroni-etcd pgbouncer pg_cli pgbadger pg_activity # major components
- pgcenter boxinfo check_postgres emaj pgbconsole pg_bloat_check pgquarrel # other common utils
- barman barman-cli pgloader pgFormatter pitrery pspg pgxnclient PyGreSQL pgadmin4 tail_n_mail
# postgres 13 packages
- postgresql13* postgis31* citus_13 timescaledb_13 # pgrouting_13 # postgres 13 and postgis 31
- pg_repack13 pg_squeeze13 # maintenance extensions
- pg_qualstats13 pg_stat_kcache13 system_stats_13 bgw_replstatus13 # stats extensions
- plr13 plsh13 plpgsql_check_13 plproxy13 plr13 plsh13 plpgsql_check_13 pldebugger13 # PL extensions # pl extensions
- hdfs_fdw_13 mongo_fdw13 mysql_fdw_13 ogr_fdw13 redis_fdw_13 pgbouncer_fdw13 # FDW extensions
- wal2json13 count_distinct13 ddlx_13 geoip13 orafce13 # MISC extensions
- rum_13 hypopg_13 ip4r13 jsquery_13 logerrors_13 periods_13 pg_auto_failover_13 pg_catcheck13
- pg_fkpart13 pg_jobmon13 pg_partman13 pg_prioritize_13 pg_track_settings13 pgaudit15_13
- pgcryptokey13 pgexportdoc13 pgimportdoc13 pgmemcache-13 pgmp13 pgq-13
- pguint13 pguri13 prefix13 safeupdate_13 semver13 table_version13 tdigest13
repo_url_packages:
- https://github.com/Vonng/pg_exporter/releases/download/v0.3.2/pg_exporter-0.3.2-1.el7.x86_64.rpm
- https://github.com/cybertec-postgresql/vip-manager/releases/download/v0.6/vip-manager_0.6-1_amd64.rpm
- http://guichaz.free.fr/polysh/files/polysh-0.4-1.noarch.rpm
#------------------------------------------------------------------------------
# NODE PROVISION
#------------------------------------------------------------------------------
# this section defines how to provision nodes
# nodename: # if defined, node's hostname will be overwritten
# - node dns - #
node_dns_hosts: # static dns records in /etc/hosts
- 10.10.10.10 yum.pigsty
node_dns_server: add # add (default) | none (skip) | overwrite (remove old settings)
node_dns_servers: # dynamic nameserver in /etc/resolv.conf
- 10.10.10.10
node_dns_options: # dns resolv options
- options single-request-reopen timeout:1 rotate
- domain service.consul
# - node repo - #
node_repo_method: local # none|local|public (use local repo for production env)
node_repo_remove: true # whether remove existing repo
node_local_repo_url: # local repo url (if method=local, make sure firewall is configured or disabled)
- http://yum.pigsty/pigsty.repo
# - node packages - #
node_packages: # common packages for all nodes
- wget,yum-utils,ntp,chrony,tuned,uuid,lz4,vim-minimal,make,patch,bash,lsof,wget,unzip,git,readline,zlib,openssl
- numactl,grubby,sysstat,dstat,iotop,bind-utils,net-tools,tcpdump,socat,ipvsadm,telnet,tuned,pv,jq
- python3,python3-psycopg2,python36-requests,python3-etcd,python3-consul
- python36-urllib3,python36-idna,python36-pyOpenSSL,python36-cryptography
- node_exporter,consul,consul-template,etcd,haproxy,keepalived,vip-manager
node_extra_packages: # extra packages for all nodes
- patroni,patroni-consul,patroni-etcd,pgbouncer,pgbadger,pg_activity
node_meta_packages: # packages for meta nodes only
- grafana,prometheus2,alertmanager,nginx_exporter,blackbox_exporter,pushgateway
- dnsmasq,nginx,ansible,pgbadger,polysh
# - node features - #
node_disable_numa: false # disable numa, important for production database, reboot required
node_disable_swap: false # disable swap, important for production database
node_disable_firewall: true # disable firewall (required if using kubernetes)
node_disable_selinux: true # disable selinux (required if using kubernetes)
node_static_network: true # keep dns resolver settings after reboot
node_disk_prefetch: false # setup disk prefetch on HDD to increase performance
# - node kernel modules - #
node_kernel_modules:
- softdog
- br_netfilter
- ip_vs
- ip_vs_rr
- ip_vs_rr
- ip_vs_wrr
- ip_vs_sh
- nf_conntrack_ipv4
# - node tuned - #
node_tune: tiny # install and activate tuned profile: none|oltp|olap|crit|tiny
node_sysctl_params: # set additional sysctl parameters, k:v format
net.bridge.bridge-nf-call-iptables: 1 # for kubernetes
# - node user - #
node_admin_setup: true # setup an default admin user ?
node_admin_uid: 88 # uid and gid for admin user
node_admin_username: admin # default admin user
node_admin_ssh_exchange: true # exchange ssh key among cluster ?
node_admin_pks: # public key list that will be installed
- 'ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAAAgQC7IMAMNavYtWwzAJajKqwdn3ar5BhvcwCnBTxxEkXhGlCO2vfgosSAQMEflfgvkiI5nM1HIFQ8KINlx1XLO7SdL5KdInG5LIJjAFh0pujS4kNCT9a5IGvSq1BrzGqhbEcwWYdju1ZPYBcJm/MG+JD0dYCh8vfrYB/cYMD0SOmNkQ== vagrant@pigsty.com'
# - node ntp - #
node_ntp_service: ntp # ntp or chrony
node_ntp_config: true # overwrite existing ntp config?
node_timezone: Asia/Shanghai # default node timezone
node_ntp_servers: # default NTP servers
- pool cn.pool.ntp.org iburst
- pool pool.ntp.org iburst
- pool time.pool.aliyun.com iburst
- server 10.10.10.10 iburst
#------------------------------------------------------------------------------
# META PROVISION
#------------------------------------------------------------------------------
# - ca - #
ca_method: create # create|copy|recreate
ca_subject: "/CN=root-ca" # self-signed CA subject
ca_homedir: /ca # ca cert directory
ca_cert: ca.crt # ca public key/cert
ca_key: ca.key # ca private key
# - nginx - #
nginx_upstream:
- { name: home, host: pigsty, url: "127.0.0.1:3000"}
- { name: consul, host: c.pigsty, url: "127.0.0.1:8500" }
- { name: grafana, host: g.pigsty, url: "127.0.0.1:3000" }
- { name: prometheus, host: p.pigsty, url: "127.0.0.1:9090" }
- { name: alertmanager, host: a.pigsty, url: "127.0.0.1:9093" }
- { name: haproxy, host: h.pigsty, url: "127.0.0.1:9091" }
# - nameserver - #
dns_records: # dynamic dns record resolved by dnsmasq
- 10.10.10.2 pg-meta # sandbox vip for pg-meta
- 10.10.10.3 pg-test # sandbox vip for pg-test
- 10.10.10.10 meta-1 # sandbox node meta-1 (node-0)
- 10.10.10.11 node-1 # sandbox node node-1
- 10.10.10.12 node-2 # sandbox node node-2
- 10.10.10.13 node-3 # sandbox node node-3
- 10.10.10.10 pigsty
- 10.10.10.10 y.pigsty yum.pigsty
- 10.10.10.10 c.pigsty consul.pigsty
- 10.10.10.10 g.pigsty grafana.pigsty
- 10.10.10.10 p.pigsty prometheus.pigsty
- 10.10.10.10 a.pigsty alertmanager.pigsty
- 10.10.10.10 n.pigsty ntp.pigsty
- 10.10.10.10 h.pigsty haproxy.pigsty
# - prometheus - #
prometheus_data_dir: /export/prometheus/data # prometheus data dir
prometheus_options: '--storage.tsdb.retention=30d'
prometheus_reload: false # reload prometheus instead of recreate it
prometheus_sd_method: consul # service discovery method: static|consul|etcd
prometheus_scrape_interval: 2s # global scrape & evaluation interval
prometheus_scrape_timeout: 1s # scrape timeout
prometheus_sd_interval: 2s # service discovery refresh interval
# - grafana - #
grafana_url: http://admin:admin@10.10.10.10:3000 # grafana url
grafana_admin_password: admin # default grafana admin user password
grafana_plugin: install # none|install|reinstall
grafana_cache: /www/pigsty/grafana/plugins.tar.gz # path to grafana plugins tarball
grafana_customize: true # customize grafana resources
grafana_plugins: # default grafana plugins list
- redis-datasource
- simpod-json-datasource
- fifemon-graphql-datasource
- sbueringer-consul-datasource
- camptocamp-prometheus-alertmanager-datasource
- ryantxu-ajax-panel
- marcusolsson-hourly-heatmap-panel
- michaeldmoore-multistat-panel
- marcusolsson-treemap-panel
- pr0ps-trackmap-panel
- dalvany-image-panel
- magnesium-wordcloud-panel
- cloudspout-button-panel
- speakyourcode-button-panel
- jdbranham-diagram-panel
- grafana-piechart-panel
- snuids-radar-panel
- digrich-bubblechart-panel
grafana_git_plugins:
- https://github.com/Vonng/grafana-echarts
#------------------------------------------------------------------------------
# DCS PROVISION
#------------------------------------------------------------------------------
service_registry: consul # where to register services: none | consul | etcd | both
dcs_type: consul # consul | etcd | both
dcs_name: pigsty # consul dc name | etcd initial cluster token
dcs_servers: # dcs server dict in name:ip format
meta-1: 10.10.10.10 # you could use existing dcs cluster
# meta-2: 10.10.10.11 # host which have their IP listed here will be init as server
# meta-3: 10.10.10.12 # 3 or 5 dcs nodes are recommend for production environment
dcs_exists_action: clean # abort|skip|clean if dcs server already exists
dcs_disable_purge: false # set to true to disable purge functionality for good (force dcs_exists_action = abort)
consul_data_dir: /var/lib/consul # consul data dir (/var/lib/consul by default)
etcd_data_dir: /var/lib/etcd # etcd data dir (/var/lib/consul by default)
#------------------------------------------------------------------------------
# POSTGRES INSTALLATION
#------------------------------------------------------------------------------
# - dbsu - #
pg_dbsu: postgres # os user for database, postgres by default (change it is not recommended!)
pg_dbsu_uid: 26 # os dbsu uid and gid, 26 for default postgres users and groups
pg_dbsu_sudo: limit # none|limit|all|nopass (Privilege for dbsu, limit is recommended)
pg_dbsu_home: /var/lib/pgsql # postgresql binary
pg_dbsu_ssh_exchange: false # exchange ssh key among same cluster
# - postgres packages - #
pg_version: 13 # default postgresql version
pgdg_repo: false # use official pgdg yum repo (disable if you have local mirror)
pg_add_repo: false # add postgres related repo before install (useful if you want a simple install)
pg_bin_dir: /usr/pgsql/bin # postgres binary dir
pg_packages:
- postgresql${pg_version}*
- postgis31_${pg_version}*
- pgbouncer patroni pg_exporter pgbadger
- patroni patroni-consul patroni-etcd pgbouncer pgbadger pg_activity
- python3 python3-psycopg2 python36-requests python3-etcd python3-consul
- python36-urllib3 python36-idna python36-pyOpenSSL python36-cryptography
pg_extensions:
- pg_repack${pg_version} pg_qualstats${pg_version} pg_stat_kcache${pg_version} wal2json${pg_version}
# - ogr_fdw${pg_version} mysql_fdw_${pg_version} redis_fdw_${pg_version} mongo_fdw${pg_version} hdfs_fdw_${pg_version}
# - count_distinct${version} ddlx_${version} geoip${version} orafce${version} # popular features
# - hypopg_${version} ip4r${version} jsquery_${version} logerrors_${version} periods_${version} pg_auto_failover_${version} pg_catcheck${version}
# - pg_fkpart${version} pg_jobmon${version} pg_partman${version} pg_prioritize_${version} pg_track_settings${version} pgaudit15_${version}
# - pgcryptokey${version} pgexportdoc${version} pgimportdoc${version} pgmemcache-${version} pgmp${version} pgq-${version} pgquarrel pgrouting_${version}
# - pguint${version} pguri${version} prefix${version} safeupdate_${version} semver${version} table_version${version} tdigest${version}
#------------------------------------------------------------------------------
# POSTGRES PROVISION
#------------------------------------------------------------------------------
# - identity - #
# pg_cluster: # [REQUIRED] cluster name (validated during pg_preflight)
# pg_seq: 0 # [REQUIRED] instance seq (validated during pg_preflight)
# pg_role: replica # [REQUIRED] service role (validated during pg_preflight)
pg_hostname: false # overwrite node hostname with pg instance name
pg_nodename: true # overwrite consul nodename with pg instance name
# - retention - #
# pg_exists_action, available options: abort|clean|skip
# - abort: abort entire play's execution (default)
# - clean: remove existing cluster (dangerous)
# - skip: end current play for this host
# pg_exists: false # auxiliary flag variable (DO NOT SET THIS)
pg_exists_action: clean
pg_disable_purge: false # set to true to disable pg purge functionality for good (force pg_exists_action = abort)
# - storage - #
pg_data: /pg/data # postgres data directory
pg_fs_main: /export # data disk mount point /pg -> {{ pg_fs_main }}/postgres/{{ pg_instance }}
pg_fs_bkup: /var/backups # backup disk mount point /pg/* -> {{ pg_fs_bkup }}/postgres/{{ pg_instance }}/*
# - connection - #
pg_listen: '0.0.0.0' # postgres listen address, '0.0.0.0' by default (all ipv4 addr)
pg_port: 5432 # postgres port (5432 by default)
pg_localhost: /var/run/postgresql # localhost unix socket dir for connection
# - patroni - #
# patroni_mode, available options: default|pause|remove
# - default: default ha mode
# - pause: into maintenance mode
# - remove: remove patroni after bootstrap
patroni_mode: default # pause|default|remove
pg_namespace: /pg # top level key namespace in dcs
patroni_port: 8008 # default patroni port
patroni_watchdog_mode: automatic # watchdog mode: off|automatic|required
pg_conf: tiny.yml # user provided patroni config template path
# - localization - #
pg_encoding: UTF8 # default to UTF8
pg_locale: C # default to C
pg_lc_collate: C # default to C
pg_lc_ctype: en_US.UTF8 # default to en_US.UTF8
# - pgbouncer - #
pgbouncer_port: 6432 # pgbouncer port (6432 by default)
pgbouncer_poolmode: transaction # pooling mode: (transaction pooling by default)
pgbouncer_max_db_conn: 100 # important! do not set this larger than postgres max conn or conn limit
#------------------------------------------------------------------------------
# POSTGRES TEMPLATE
#------------------------------------------------------------------------------
# - template - #
pg_init: pg-init # init script for cluster template
# - system roles - #
pg_replication_username: replicator # system replication user
pg_replication_password: DBUser.Replicator # system replication password
pg_monitor_username: dbuser_monitor # system monitor user
pg_monitor_password: DBUser.Monitor # system monitor password
pg_admin_username: dbuser_admin # system admin user
pg_admin_password: DBUser.Admin # system admin password
# - default roles - #
# chekc http://pigsty.cc/zh/docs/concepts/provision/acl/ for more detail
pg_default_roles:
# common production readonly user
- name: dbrole_readonly # production read-only roles
login: false
comment: role for global readonly access
# common production read-write user
- name: dbrole_readwrite # production read-write roles
login: false
roles: [dbrole_readonly] # read-write includes read-only access
comment: role for global read-write access
# offline have same privileges as readonly, but with limited hba access on offline instance only
# for the purpose of running slow queries, interactive queries and perform ETL tasks
- name: dbrole_offline
login: false
comment: role for restricted read-only access (offline instance)
# admin have the privileges to issue DDL changes
- name: dbrole_admin
login: false
bypassrls: true
comment: role for object creation
roles: [dbrole_readwrite,pg_monitor,pg_signal_backend]
# dbsu, name is designated by `pg_dbsu`. It's not recommend to set password for dbsu
- name: postgres
superuser: true
comment: system superuser
# default replication user, name is designated by `pg_replication_username`, and password is set by `pg_replication_password`
- name: replicator
replication: true # for replication user
bypassrls: true # logical replication require bypassrls
roles: [pg_monitor, dbrole_readonly] # logical replication require select privileges
comment: system replicator
# default replication user, name is designated by `pg_monitor_username`, and password is set by `pg_monitor_password`
- name: dbuser_monitor
connlimit: 16
comment: system monitor user
roles: [pg_monitor, dbrole_readonly]
# default admin user, name is designated by `pg_admin_username`, and password is set by `pg_admin_password`
- name: dbuser_admin
bypassrls: true
superuser: true
comment: system admin user
roles: [dbrole_admin]
# default stats user, for ETL and slow queries
- name: dbuser_stats
password: DBUser.Stats
comment: business offline user for offline queries and ETL
roles: [dbrole_offline]
# - privileges - #
# object created by dbsu and admin will have their privileges properly set
pg_default_privileges:
- GRANT USAGE ON SCHEMAS TO dbrole_readonly
- GRANT SELECT ON TABLES TO dbrole_readonly
- GRANT SELECT ON SEQUENCES TO dbrole_readonly
- GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly
- GRANT USAGE ON SCHEMAS TO dbrole_offline
- GRANT SELECT ON TABLES TO dbrole_offline
- GRANT SELECT ON SEQUENCES TO dbrole_offline
- GRANT EXECUTE ON FUNCTIONS TO dbrole_offline
- GRANT INSERT, UPDATE, DELETE ON TABLES TO dbrole_readwrite
- GRANT USAGE, UPDATE ON SEQUENCES TO dbrole_readwrite
- GRANT TRUNCATE, REFERENCES, TRIGGER ON TABLES TO dbrole_admin
- GRANT CREATE ON SCHEMAS TO dbrole_admin
# - schemas - #
pg_default_schemas: [monitor] # default schemas to be created
# - extension - #
pg_default_extensions: # default extensions to be created
- { name: 'pg_stat_statements', schema: 'monitor' }
- { name: 'pgstattuple', schema: 'monitor' }
- { name: 'pg_qualstats', schema: 'monitor' }
- { name: 'pg_buffercache', schema: 'monitor' }
- { name: 'pageinspect', schema: 'monitor' }
- { name: 'pg_prewarm', schema: 'monitor' }
- { name: 'pg_visibility', schema: 'monitor' }
- { name: 'pg_freespacemap', schema: 'monitor' }
- { name: 'pg_repack', schema: 'monitor' }
- name: postgres_fdw
- name: file_fdw
- name: btree_gist
- name: btree_gin
- name: pg_trgm
- name: intagg
- name: intarray
# - hba - #
pg_offline_query: false # set to true to enable offline query on instance
pg_reload: true # reload postgres after hba changes
pg_hba_rules: # postgres host-based authentication rules
- title: allow meta node password access
role: common
rules:
- host all all 10.10.10.10/32 md5
- title: allow intranet admin password access
role: common
rules:
- host all +dbrole_admin 10.0.0.0/8 md5
- host all +dbrole_admin 172.16.0.0/12 md5
- host all +dbrole_admin 192.168.0.0/16 md5
- title: allow intranet password access
role: common
rules:
- host all all 10.0.0.0/8 md5
- host all all 172.16.0.0/12 md5
- host all all 192.168.0.0/16 md5
- title: allow local read/write (local production user via pgbouncer)
role: common
rules:
- local all +dbrole_readonly md5
- host all +dbrole_readonly 127.0.0.1/32 md5
- title: allow offline query (ETL,SAGA,Interactive) on offline instance
role: offline
rules:
- host all +dbrole_offline 10.0.0.0/8 md5
- host all +dbrole_offline 172.16.0.0/12 md5
- host all +dbrole_offline 192.168.0.0/16 md5
pg_hba_rules_extra: [] # extra hba rules (for cluster/instance overwrite)
pgbouncer_hba_rules: # pgbouncer host-based authentication rules
- title: local password access
role: common
rules:
- local all all md5
- host all all 127.0.0.1/32 md5
- title: intranet password access
role: common
rules:
- host all all 10.0.0.0/8 md5
- host all all 172.16.0.0/12 md5
- host all all 192.168.0.0/16 md5
pgbouncer_hba_rules_extra: [] # extra pgbouncer hba rules (for cluster/instance overwrite)
#------------------------------------------------------------------------------
# MONITOR PROVISION
#------------------------------------------------------------------------------
# - install - #
exporter_install: none # none|yum|binary, none by default
exporter_repo_url: '' # if set, repo will be added to /etc/yum.repos.d/ before yum installation
# - collect - #
exporter_metrics_path: /metrics # default metric path for pg related exporter
# - node exporter - #
node_exporter_enabled: true # setup node_exporter on instance
node_exporter_port: 9100 # default port for node exporter
node_exporter_options: '--no-collector.softnet --collector.systemd --collector.ntp --collector.tcpstat --collector.processes'
# - pg exporter - #
pg_exporter_config: pg_exporter-demo.yaml # default config files for pg_exporter
pg_exporter_enabled: true # setup pg_exporter on instance
pg_exporter_port: 9630 # default port for pg exporter
pg_exporter_url: '' # optional, if not set, generate from reference parameters
# - pgbouncer exporter - #
pgbouncer_exporter_enabled: true # setup pgbouncer_exporter on instance (if you don't have pgbouncer, disable it)
pgbouncer_exporter_port: 9631 # default port for pgbouncer exporter
pgbouncer_exporter_url: '' # optional, if not set, generate from reference parameters
#------------------------------------------------------------------------------
# SERVICE PROVISION
#------------------------------------------------------------------------------
pg_weight: 100 # default load balance weight (instance level)
# - service - #
pg_services: # how to expose postgres service in cluster?
# primary service will route {ip|name}:5433 to primary pgbouncer (5433->6432 rw)
- name: primary # service name {{ pg_cluster }}_primary
src_ip: "*"
src_port: 5433
dst_port: pgbouncer # 5433 route to pgbouncer
check_url: /primary # primary health check, success when instance is primary
selector: "[]" # select all instance as primary service candidate
# replica service will route {ip|name}:5434 to replica pgbouncer (5434->6432 ro)
- name: replica # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5434
dst_port: pgbouncer
check_url: /read-only # read-only health check. (including primary)
selector: "[]" # select all instance as replica service candidate
selector_backup: "[? pg_role == `primary`]" # primary are used as backup server in replica service
# default service will route {ip|name}:5436 to primary postgres (5436->5432 primary)
- name: default # service's actual name is {{ pg_cluster }}-{{ service.name }}
src_ip: "*" # service bind ip address, * for all, vip for cluster virtual ip address
src_port: 5436 # bind port, mandatory
dst_port: postgres # target port: postgres|pgbouncer|port_number , pgbouncer(6432) by default
check_method: http # health check method: only http is available for now
check_port: patroni # health check port: patroni|pg_exporter|port_number , patroni by default
check_url: /primary # health check url path, / as default
check_code: 200 # health check http code, 200 as default
selector: "[]" # instance selector
haproxy: # haproxy specific fields
maxconn: 3000 # default front-end connection
balance: roundrobin # load balance algorithm (roundrobin by default)
default_server_options: 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
# offline service will route {ip|name}:5438 to offline postgres (5438->5432 offline)
- name: offline # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5438
dst_port: postgres
check_url: /replica # offline MUST be a replica
selector: "[? pg_role == `offline` || pg_offline_query ]" # instances with pg_role == 'offline' or instance marked with 'pg_offline_query == true'
selector_backup: "[? pg_role == `replica` && !pg_offline_query]" # replica are used as backup server in offline service
pg_services_extra: [] # extra services to be added
# - haproxy - #
haproxy_enabled: true # enable haproxy among every cluster members
haproxy_reload: true # reload haproxy after config
haproxy_policy: roundrobin # roundrobin, leastconn
haproxy_admin_auth_enabled: false # enable authentication for haproxy admin?
haproxy_admin_username: admin # default haproxy admin username
haproxy_admin_password: admin # default haproxy admin password
haproxy_exporter_port: 9101 # default admin/exporter port
haproxy_client_timeout: 3h # client side connection timeout
haproxy_server_timeout: 3h # server side connection timeout
# - vip - #
vip_mode: none # none | l2 | l4
vip_reload: true # whether reload service after config
# vip_address: 127.0.0.1 # virtual ip address ip (l2 or l4)
# vip_cidrmask: 24 # virtual ip address cidr mask (l2 only)
# vip_interface: eth0 # virtual ip network interface (l2 only)
...
9.2 - Kernel Optimize
Pigsty parameter tuning for the OS kernel
Pigsty使用tuned调整操作系统配置,tuned是CentOS7自带的调参工具。
Pigsty Tuned配置
Pigsty默认会为操作系统安装四种tuned profile:
tuned-adm profile oltp # 启用OLTP模式
tuned-adm profile olap # 启用OLAP模式
tuned-adm profile crit # 启用CRIT模式
tuned-adm profile tiny # 启用TINY模式
Tuned基本操作
# 如需启动 tuned,请以 root 身份运行下列指令:
systemctl start tuned
# 若要在每次计算机启动时激活 tuned,请输入以下指令:
systemctl enable tuned
# 其它的 tuned 控制,例如配置文件选择等,请使用:
tuned-adm
# 若要查看可用的已安装配置文件,此命令需要 tuned 服务正在运行。
tuned-adm list
# 若要查看目前已激活的配置文件,请运行:
tuned-adm active
# 若要选择或激活某一配置文件,请运行:
tuned-adm profile profile
# 例如
tuned-adm profile powersave
# 若要让 tuned 推荐最适合您的系统的配置文件,同时不改变任何现有的配置文件,也不使用安装期间使用过的逻辑,请运行以下指令:
tuned-adm recommend
# 要禁用所有微调:
tuned-adm off
要列出所有可用配置文件并识别目前激活的配置文件,请运行:
tuned-adm list
要只显示当前激活的配置文件请运行:
tuned-adm active
要切换到某个可用的配置文件请运行:
tuned-adm profile profile_name
例如:
tuned-adm profile server-powersave
OLTP配置
# tuned configuration
#==============================================================#
# File : tuned.conf
# Mtime : 2020-06-29
# Desc : Tune operatiing system to oltp mode
# Path : /etc/tuned/oltp/tuned.conf
# Author : Vonng(fengruohang@outlook.com)
# Copyright (C) 2019-2020 Ruohang Feng
#==============================================================#
[main]
summary=Optimize for PostgreSQL OLTP System
include=network-latency
[cpu]
force_latency=1
governor=performance
energy_perf_bias=performance
min_perf_pct=100
[vm]
# disable transparent hugepages
transparent_hugepages=never
[sysctl]
#-------------------------------------------------------------#
# KERNEL #
#-------------------------------------------------------------#
# disable numa balancing
kernel.numa_balancing=0
# total shmem size in bytes: $(expr $(getconf _PHYS_PAGES) / 2 \* $(getconf PAGE_SIZE))
{% if param_shmall is defined and param_shmall != '' %}
kernel.shmall = {{ param_shmall }}
{% endif %}
# total shmem size in pages: $(expr $(getconf _PHYS_PAGES) / 2)
{% if param_shmmax is defined and param_shmmax != '' %}
kernel.shmmax = {{ param_shmmax }}
{% endif %}
# total shmem segs 4096 -> 8192
kernel.shmmni=8192
# total msg queue number, set to mem size in MB
kernel.msgmni=32768
# max length of message queue
kernel.msgmnb=65536
# max size of message
kernel.msgmax=65536
kernel.pid_max=131072
# max(Sem in Set)=2048, max(Sem)=max(Sem in Set) x max(SemSet) , max(Sem per Ops)=2048, max(SemSet)=65536
kernel.sem=2048 134217728 2048 65536
# do not sched postgres process in group
kernel.sched_autogroup_enabled = 0
# total time the scheduler will consider a migrated process cache hot and, thus, less likely to be remigrated
# defaut = 0.5ms (500000ns), update to 5ms , depending on your typical query (e.g < 1ms)
kernel.sched_migration_cost_ns=5000000
#-------------------------------------------------------------#
# VM #
#-------------------------------------------------------------#
# try not using swap
vm.swappiness=0
# disable when most mem are for file cache
vm.zone_reclaim_mode=0
# overcommit threshhold = 80%
vm.overcommit_memory=2
vm.overcommit_ratio=80
# vm.dirty_background_bytes=67108864 # 64MB mem (2xRAID cache) wake the bgwriter
vm.dirty_background_ratio=3 # latency-performance default
vm.dirty_ratio=10 # latency-performance default
# deny access on 0x00000 - 0x10000
vm.mmap_min_addr=65536
#-------------------------------------------------------------#
# Filesystem #
#-------------------------------------------------------------#
# max open files: 382589 -> 167772160
fs.file-max=167772160
# max concurrent unfinished async io, should be larger than 1M. 65536->1M
fs.aio-max-nr=1048576
#-------------------------------------------------------------#
# Network #
#-------------------------------------------------------------#
# max connection in listen queue (triggers retrans if full)
net.core.somaxconn=65535
net.core.netdev_max_backlog=8192
# tcp receive/transmit buffer default = 256KiB
net.core.rmem_default=262144
net.core.wmem_default=262144
# receive/transmit buffer limit = 4MiB
net.core.rmem_max=4194304
net.core.wmem_max=4194304
# ip options
net.ipv4.ip_forward=1
net.ipv4.ip_nonlocal_bind=1
net.ipv4.ip_local_port_range=32768 65000
# tcp options
net.ipv4.tcp_timestamps=1
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_recycle=0
net.ipv4.tcp_syncookies=0
net.ipv4.tcp_synack_retries=1
net.ipv4.tcp_syn_retries=1
# tcp read/write buffer
net.ipv4.tcp_rmem="4096 87380 16777216"
net.ipv4.tcp_wmem="4096 16384 16777216"
net.ipv4.udp_mem="3145728 4194304 16777216"
# tcp probe fail interval: 75s -> 20s
net.ipv4.tcp_keepalive_intvl=20
# tcp break after 3 * 20s = 1m
net.ipv4.tcp_keepalive_probes=3
# probe peroid = 1 min
net.ipv4.tcp_keepalive_time=60
net.ipv4.tcp_fin_timeout=5
net.ipv4.tcp_max_tw_buckets=262144
net.ipv4.tcp_max_syn_backlog=8192
net.ipv4.neigh.default.gc_thresh1=80000
net.ipv4.neigh.default.gc_thresh2=90000
net.ipv4.neigh.default.gc_thresh3=100000
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-arptables=1
# max connection tracking number
net.netfilter.nf_conntrack_max=1048576
OLAP配置
# tuned configuration
#==============================================================#
# File : tuned.conf
# Mtime : 2020-09-18
# Desc : Tune operatiing system to olap mode
# Path : /etc/tuned/olap/tuned.conf
# Author : Vonng(fengruohang@outlook.com)
# Copyright (C) 2019-2020 Ruohang Feng
#==============================================================#
[main]
summary=Optimize for PostgreSQL OLAP System
include=network-throughput
[cpu]
force_latency=1
governor=performance
energy_perf_bias=performance
min_perf_pct=100
[vm]
# disable transparent hugepages
transparent_hugepages=never
[sysctl]
#-------------------------------------------------------------#
# KERNEL #
#-------------------------------------------------------------#
# disable numa balancing
kernel.numa_balancing=0
# total shmem size in bytes: $(expr $(getconf _PHYS_PAGES) / 2 \* $(getconf PAGE_SIZE))
{% if param_shmall is defined and param_shmall != '' %}
kernel.shmall = {{ param_shmall }}
{% endif %}
# total shmem size in pages: $(expr $(getconf _PHYS_PAGES) / 2)
{% if param_shmmax is defined and param_shmmax != '' %}
kernel.shmmax = {{ param_shmmax }}
{% endif %}
# total shmem segs 4096 -> 8192
kernel.shmmni=8192
# total msg queue number, set to mem size in MB
kernel.msgmni=32768
# max length of message queue
kernel.msgmnb=65536
# max size of message
kernel.msgmax=65536
kernel.pid_max=131072
# max(Sem in Set)=2048, max(Sem)=max(Sem in Set) x max(SemSet) , max(Sem per Ops)=2048, max(SemSet)=65536
kernel.sem=2048 134217728 2048 65536
# do not sched postgres process in group
kernel.sched_autogroup_enabled = 0
# total time the scheduler will consider a migrated process cache hot and, thus, less likely to be remigrated
# defaut = 0.5ms (500000ns), update to 5ms , depending on your typical query (e.g < 1ms)
kernel.sched_migration_cost_ns=5000000
#-------------------------------------------------------------#
# VM #
#-------------------------------------------------------------#
# try not using swap
# vm.swappiness=10
# disable when most mem are for file cache
vm.zone_reclaim_mode=0
# overcommit threshhold = 80%
vm.overcommit_memory=2
vm.overcommit_ratio=80
vm.dirty_background_ratio = 10 # throughput-performance default
vm.dirty_ratio=80 # throughput-performance default 40 -> 80
# deny access on 0x00000 - 0x10000
vm.mmap_min_addr=65536
#-------------------------------------------------------------#
# Filesystem #
#-------------------------------------------------------------#
# max open files: 382589 -> 167772160
fs.file-max=167772160
# max concurrent unfinished async io, should be larger than 1M. 65536->1M
fs.aio-max-nr=1048576
#-------------------------------------------------------------#
# Network #
#-------------------------------------------------------------#
# max connection in listen queue (triggers retrans if full)
net.core.somaxconn=65535
net.core.netdev_max_backlog=8192
# tcp receive/transmit buffer default = 256KiB
net.core.rmem_default=262144
net.core.wmem_default=262144
# receive/transmit buffer limit = 4MiB
net.core.rmem_max=4194304
net.core.wmem_max=4194304
# ip options
net.ipv4.ip_forward=1
net.ipv4.ip_nonlocal_bind=1
net.ipv4.ip_local_port_range=32768 65000
# tcp options
net.ipv4.tcp_timestamps=1
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_recycle=0
net.ipv4.tcp_syncookies=0
net.ipv4.tcp_synack_retries=1
net.ipv4.tcp_syn_retries=1
# tcp read/write buffer
net.ipv4.tcp_rmem="4096 87380 16777216"
net.ipv4.tcp_wmem="4096 16384 16777216"
net.ipv4.udp_mem="3145728 4194304 16777216"
# tcp probe fail interval: 75s -> 20s
net.ipv4.tcp_keepalive_intvl=20
# tcp break after 3 * 20s = 1m
net.ipv4.tcp_keepalive_probes=3
# probe peroid = 1 min
net.ipv4.tcp_keepalive_time=60
net.ipv4.tcp_fin_timeout=5
net.ipv4.tcp_max_tw_buckets=262144
net.ipv4.tcp_max_syn_backlog=8192
net.ipv4.neigh.default.gc_thresh1=80000
net.ipv4.neigh.default.gc_thresh2=90000
net.ipv4.neigh.default.gc_thresh3=100000
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-arptables=1
# max connection tracking number
net.netfilter.nf_conntrack_max=1048576
CRIT配置
# tuned configuration
#==============================================================#
# File : tuned.conf
# Mtime : 2020-06-29
# Desc : Tune operatiing system to crit mode
# Path : /etc/tuned/crit/tuned.conf
# Author : Vonng(fengruohang@outlook.com)
# Copyright (C) 2019-2020 Ruohang Feng
#==============================================================#
[main]
summary=Optimize for PostgreSQL CRIT System
include=network-latency
[cpu]
force_latency=1
governor=performance
energy_perf_bias=performance
min_perf_pct=100
[vm]
# disable transparent hugepages
transparent_hugepages=never
[sysctl]
#-------------------------------------------------------------#
# KERNEL #
#-------------------------------------------------------------#
# disable numa balancing
kernel.numa_balancing=0
# total shmem size in bytes: $(expr $(getconf _PHYS_PAGES) / 2 \* $(getconf PAGE_SIZE))
{% if param_shmall is defined and param_shmall != '' %}
kernel.shmall = {{ param_shmall }}
{% endif %}
# total shmem size in pages: $(expr $(getconf _PHYS_PAGES) / 2)
{% if param_shmmax is defined and param_shmmax != '' %}
kernel.shmmax = {{ param_shmmax }}
{% endif %}
# total shmem segs 4096 -> 8192
kernel.shmmni=8192
# total msg queue number, set to mem size in MB
kernel.msgmni=32768
# max length of message queue
kernel.msgmnb=65536
# max size of message
kernel.msgmax=65536
kernel.pid_max=131072
# max(Sem in Set)=2048, max(Sem)=max(Sem in Set) x max(SemSet) , max(Sem per Ops)=2048, max(SemSet)=65536
kernel.sem=2048 134217728 2048 65536
# do not sched postgres process in group
kernel.sched_autogroup_enabled = 0
# total time the scheduler will consider a migrated process cache hot and, thus, less likely to be remigrated
# defaut = 0.5ms (500000ns), update to 5ms , depending on your typical query (e.g < 1ms)
kernel.sched_migration_cost_ns=5000000
#-------------------------------------------------------------#
# VM #
#-------------------------------------------------------------#
# try not using swap
vm.swappiness=0
# disable when most mem are for file cache
vm.zone_reclaim_mode=0
# overcommit threshhold = 80%
vm.overcommit_memory=2
vm.overcommit_ratio=100
# 64MB mem (2xRAID cache) wake the bgwriter
vm.dirty_background_bytes=67108864
# vm.dirty_background_ratio=3 # latency-performance default
vm.dirty_ratio=6 # latency-performance default
# deny access on 0x00000 - 0x10000
vm.mmap_min_addr=65536
#-------------------------------------------------------------#
# Filesystem #
#-------------------------------------------------------------#
# max open files: 382589 -> 167772160
fs.file-max=167772160
# max concurrent unfinished async io, should be larger than 1M. 65536->1M
fs.aio-max-nr=1048576
#-------------------------------------------------------------#
# Network #
#-------------------------------------------------------------#
# max connection in listen queue (triggers retrans if full)
net.core.somaxconn=65535
net.core.netdev_max_backlog=8192
# tcp receive/transmit buffer default = 256KiB
net.core.rmem_default=262144
net.core.wmem_default=262144
# receive/transmit buffer limit = 4MiB
net.core.rmem_max=4194304
net.core.wmem_max=4194304
# ip options
net.ipv4.ip_forward=1
net.ipv4.ip_nonlocal_bind=1
net.ipv4.ip_local_port_range=32768 65000
# tcp options
net.ipv4.tcp_timestamps=1
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_recycle=0
net.ipv4.tcp_syncookies=0
net.ipv4.tcp_synack_retries=1
net.ipv4.tcp_syn_retries=1
# tcp read/write buffer
net.ipv4.tcp_rmem="4096 87380 16777216"
net.ipv4.tcp_wmem="4096 16384 16777216"
net.ipv4.udp_mem="3145728 4194304 16777216"
# tcp probe fail interval: 75s -> 20s
net.ipv4.tcp_keepalive_intvl=20
# tcp break after 3 * 20s = 1m
net.ipv4.tcp_keepalive_probes=3
# probe peroid = 1 min
net.ipv4.tcp_keepalive_time=60
net.ipv4.tcp_fin_timeout=5
net.ipv4.tcp_max_tw_buckets=262144
net.ipv4.tcp_max_syn_backlog=8192
net.ipv4.neigh.default.gc_thresh1=80000
net.ipv4.neigh.default.gc_thresh2=90000
net.ipv4.neigh.default.gc_thresh3=100000
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-arptables=1
# max connection tracking number
net.netfilter.nf_conntrack_max=1048576
TINY配置
# tuned configuration
#==============================================================#
# File : tuned.conf
# Mtime : 2020-06-29
# Desc : Tune operatiing system to tiny mode
# Path : /etc/tuned/tiny/tuned.conf
# Author : Vonng(fengruohang@outlook.com)
# Copyright (C) 2019-2020 Ruohang Feng
#==============================================================#
[main]
summary=Optimize for PostgreSQL TINY System
# include=virtual-guest
[vm]
# disable transparent hugepages
transparent_hugepages=never
[sysctl]
#-------------------------------------------------------------#
# KERNEL #
#-------------------------------------------------------------#
# disable numa balancing
kernel.numa_balancing=0
# If a workload mostly uses anonymous memory and it hits this limit, the entire
# working set is buffered for I/O, and any more write buffering would require
# swapping, so it's time to throttle writes until I/O can catch up. Workloads
# that mostly use file mappings may be able to use even higher values.
#
# The generator of dirty data starts writeback at this percentage (system default
# is 20%)
vm.dirty_ratio = 40
# Filesystem I/O is usually much more efficient than swapping, so try to keep
# swapping low. It's usually safe to go even lower than this on systems with
# server-grade storage.
vm.swappiness = 30
#-------------------------------------------------------------#
# Network #
#-------------------------------------------------------------#
# tcp options
net.ipv4.tcp_timestamps=1
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_recycle=0
net.ipv4.tcp_syncookies=0
net.ipv4.tcp_synack_retries=1
net.ipv4.tcp_syn_retries=1
# tcp probe fail interval: 75s -> 20s
net.ipv4.tcp_keepalive_intvl=20
# tcp break after 3 * 20s = 1m
net.ipv4.tcp_keepalive_probes=3
# probe peroid = 1 min
net.ipv4.tcp_keepalive_time=60
数据库内核调优参考
# Database kernel optimisation
fs.aio-max-nr = 1048576 # 限制并发未完成的异步请求数目,,不应小于1M
fs.file-max = 16777216 # 最大打开16M个文件
# kernel
kernel.shmmax = 485058 # 共享内存最大页面数量: $(expr $(getconf _PHYS_PAGES) / 2)
kernel.shmall = 1986797568 # 共享内存总大小: $(expr $(getconf _PHYS_PAGES) / 2 \* $(getconf PAGE_SIZE))
kernel.shmmni = 16384 # 系统范围内共享内存段的最大数量 4096 -> 16384
kernel.msgmni = 32768 # 系统的消息队列数目,影响可以启动的代理程序数 设为内存MB数
kernel.msgmnb = 65536 # 影响队列的大小
kernel.msgmax = 65536 # 影响队列中可以发送的消息的大小
kernel.numa_balancing = 0 # Numa禁用
kernel.sched_migration_cost_ns = 5000000 # 5ms内,调度认为进程还是Hot的。
kernel.sem = 2048 134217728 2048 65536 # 每个信号集最大信号量2048,系统总共可用信号量134217728,单次最大操作2048,信号集总数65536
# vm
vm.dirty_ratio = 80 # 绝对限制,超过80%阻塞写请求刷盘
vm.dirty_background_bytes = 268435456 # 256MB脏数据唤醒刷盘进程
vm.dirty_expire_centisecs = 6000 # 1分钟前的数据被认为需要刷盘
vm.dirty_writeback_centisecs= 500 # 刷新进程运行间隔5秒
vm.mmap_min_addr = 65536 # 禁止访问0x10000下的内存
vm.zone_reclaim_mode = 0 # Numa禁用
# vm swap
vm.swappiness = 0 # 禁用SWAP,但高水位仍会有
vm.overcommit_memory = 2 # 允许一定程度的Overcommit
vm.overcommit_ratio = 50 # 允许的Overcommit:$((($mem - $swap) * 100 / $mem))
# tcp memory
net.ipv4.tcp_rmem = 8192 65536 16777216 # tcp读buffer: 32M/256M/16G
net.ipv4.tcp_wmem = 8192 65536 16777216 # tcp写buffer: 32M/256M/16G
net.ipv4.tcp_mem = 131072 262144 16777216 # tcp 内存使用 512M/1G/16G
net.core.rmem_default = 262144 # 接受缓冲区默认大小: 256K
net.core.rmem_max = 4194304 # 接受缓冲区最大大小: 4M
net.core.wmem_default = 262144 # 发送缓冲区默认大小: 256K
net.core.wmem_max = 4194304 # 发送缓冲区最大大小: 4M
# tcp keepalive
net.ipv4.tcp_keepalive_intvl = 20 # 探测没有确认时,重新发送探测的频度。默认75s -> 20s
net.ipv4.tcp_keepalive_probes = 3 # 3 * 20 = 1分钟超时断开
net.ipv4.tcp_keepalive_time = 60 # 探活周期1分钟
# tcp port resure
net.ipv4.tcp_tw_reuse = 1 # 允许将TIME_WAIT socket用于新的TCP连接。默认为0
net.ipv4.tcp_tw_recycle = 0 # 快速回收,已弃用
net.ipv4.tcp_fin_timeout = 5 # 保持在FIN-WAIT-2状态的秒时间
net.ipv4.tcp_timestamps = 1
# tcp anti-flood
net.ipv4.tcp_syncookies = 1 # SYN_RECV队列满后发cookie,防止恶意攻击
net.ipv4.tcp_synack_retries = 1 # 收到不完整sync后的重试次数 5->2
net.ipv4.tcp_syn_retries = 1 #表示在内核放弃建立连接之前发送SYN包的数量。
# tcp load-balancer
net.ipv4.ip_forward = 1 # IP转发
net.ipv4.ip_nonlocal_bind = 1 # 绑定非本机地址
net.netfilter.nf_conntrack_max = 1048576 # 最大跟踪连接数
net.ipv4.ip_local_port_range = 10000 65535 # 端口范围
net.ipv4.tcp_max_tw_buckets = 262144 # 256k TIME_WAIT
net.core.somaxconn = 65535 # 限制LISTEN队列最大数据包量,触发重传机制。
net.ipv4.tcp_max_syn_backlog = 8192 # SYN队列大小:1024->8192
net.core.netdev_max_backlog = 8192 # 网卡收包快于内核时,允许队列长度
9.3 - Metrics List
Available metrics list in Pigsty
Below is the list of monitoring indicators currently available for Pigsty.
For rules on defining derivative indicators, please refer to Derivative Metrics.
监控指标列表
| name |
| go_gc_duration_seconds |
| go_gc_duration_seconds_count |
| go_gc_duration_seconds_sum |
| go_goroutines |
| go_info |
| go_memstats_alloc_bytes |
| go_memstats_alloc_bytes_total |
| go_memstats_buck_hash_sys_bytes |
| go_memstats_frees_total |
| go_memstats_gc_cpu_fraction |
| go_memstats_gc_sys_bytes |
| go_memstats_heap_alloc_bytes |
| go_memstats_heap_idle_bytes |
| go_memstats_heap_inuse_bytes |
| go_memstats_heap_objects |
| go_memstats_heap_released_bytes |
| go_memstats_heap_sys_bytes |
| go_memstats_last_gc_time_seconds |
| go_memstats_lookups_total |
| go_memstats_mallocs_total |
| go_memstats_mcache_inuse_bytes |
| go_memstats_mcache_sys_bytes |
| go_memstats_mspan_inuse_bytes |
| go_memstats_mspan_sys_bytes |
| go_memstats_next_gc_bytes |
| go_memstats_other_sys_bytes |
| go_memstats_stack_inuse_bytes |
| go_memstats_stack_sys_bytes |
| go_memstats_sys_bytes |
| go_threads |
| haproxy_backend_active_servers |
| haproxy_backend_backup_servers |
| haproxy_backend_bytes_in_total |
| haproxy_backend_bytes_out_total |
| haproxy_backend_check_last_change_seconds |
| haproxy_backend_check_up_down_total |
| haproxy_backend_client_aborts_total |
| haproxy_backend_connect_time_average_seconds |
| haproxy_backend_connection_attempts_total |
| haproxy_backend_connection_errors_total |
| haproxy_backend_connection_reuses_total |
| haproxy_backend_current_queue |
| haproxy_backend_current_sessions |
| haproxy_backend_downtime_seconds_total |
| haproxy_backend_failed_header_rewriting_total |
| haproxy_backend_http_cache_hits_total |
| haproxy_backend_http_cache_lookups_total |
| haproxy_backend_http_comp_bytes_bypassed_total |
| haproxy_backend_http_comp_bytes_in_total |
| haproxy_backend_http_comp_bytes_out_total |
| haproxy_backend_http_comp_responses_total |
| haproxy_backend_http_requests_total |
| haproxy_backend_http_responses_total |
| haproxy_backend_internal_errors_total |
| haproxy_backend_last_session_seconds |
| haproxy_backend_limit_sessions |
| haproxy_backend_loadbalanced_total |
| haproxy_backend_max_connect_time_seconds |
| haproxy_backend_max_queue |
| haproxy_backend_max_queue_time_seconds |
| haproxy_backend_max_response_time_seconds |
| haproxy_backend_max_session_rate |
| haproxy_backend_max_sessions |
| haproxy_backend_max_total_time_seconds |
| haproxy_backend_queue_time_average_seconds |
| haproxy_backend_redispatch_warnings_total |
| haproxy_backend_requests_denied_total |
| haproxy_backend_response_errors_total |
| haproxy_backend_response_time_average_seconds |
| haproxy_backend_responses_denied_total |
| haproxy_backend_retry_warnings_total |
| haproxy_backend_server_aborts_total |
| haproxy_backend_sessions_total |
| haproxy_backend_status |
| haproxy_backend_total_time_average_seconds |
| haproxy_backend_weight |
| haproxy_frontend_bytes_in_total |
| haproxy_frontend_bytes_out_total |
| haproxy_frontend_connections_rate_max |
| haproxy_frontend_connections_total |
| haproxy_frontend_current_sessions |
| haproxy_frontend_denied_connections_total |
| haproxy_frontend_denied_sessions_total |
| haproxy_frontend_failed_header_rewriting_total |
| haproxy_frontend_http_cache_hits_total |
| haproxy_frontend_http_cache_lookups_total |
| haproxy_frontend_http_comp_bytes_bypassed_total |
| haproxy_frontend_http_comp_bytes_in_total |
| haproxy_frontend_http_comp_bytes_out_total |
| haproxy_frontend_http_comp_responses_total |
| haproxy_frontend_http_requests_rate_max |
| haproxy_frontend_http_requests_total |
| haproxy_frontend_http_responses_total |
| haproxy_frontend_intercepted_requests_total |
| haproxy_frontend_internal_errors_total |
| haproxy_frontend_limit_session_rate |
| haproxy_frontend_limit_sessions |
| haproxy_frontend_max_session_rate |
| haproxy_frontend_max_sessions |
| haproxy_frontend_request_errors_total |
| haproxy_frontend_requests_denied_total |
| haproxy_frontend_responses_denied_total |
| haproxy_frontend_sessions_total |
| haproxy_frontend_status |
| haproxy_process_active_peers |
| haproxy_process_busy_polling_enabled |
| haproxy_process_connected_peers |
| haproxy_process_connections_total |
| haproxy_process_current_backend_ssl_key_rate |
| haproxy_process_current_connection_rate |
| haproxy_process_current_connections |
| haproxy_process_current_frontend_ssl_key_rate |
| haproxy_process_current_run_queue |
| haproxy_process_current_session_rate |
| haproxy_process_current_ssl_connections |
| haproxy_process_current_ssl_rate |
| haproxy_process_current_tasks |
| haproxy_process_current_zlib_memory |
| haproxy_process_dropped_logs_total |
| haproxy_process_frontent_ssl_reuse |
| haproxy_process_hard_max_connections |
| haproxy_process_http_comp_bytes_in_total |
| haproxy_process_http_comp_bytes_out_total |
| haproxy_process_idle_time_percent |
| haproxy_process_jobs |
| haproxy_process_limit_connection_rate |
| haproxy_process_limit_http_comp |
| haproxy_process_limit_session_rate |
| haproxy_process_limit_ssl_rate |
| haproxy_process_listeners |
| haproxy_process_max_backend_ssl_key_rate |
| haproxy_process_max_connection_rate |
| haproxy_process_max_connections |
| haproxy_process_max_fds |
| haproxy_process_max_frontend_ssl_key_rate |
| haproxy_process_max_memory_bytes |
| haproxy_process_max_pipes |
| haproxy_process_max_session_rate |
| haproxy_process_max_sockets |
| haproxy_process_max_ssl_connections |
| haproxy_process_max_ssl_rate |
| haproxy_process_max_zlib_memory |
| haproxy_process_nbproc |
| haproxy_process_nbthread |
| haproxy_process_pipes_free_total |
| haproxy_process_pipes_used_total |
| haproxy_process_pool_allocated_bytes |
| haproxy_process_pool_failures_total |
| haproxy_process_pool_used_bytes |
| haproxy_process_relative_process_id |
| haproxy_process_requests_total |
| haproxy_process_ssl_cache_lookups_total |
| haproxy_process_ssl_cache_misses_total |
| haproxy_process_ssl_connections_total |
| haproxy_process_start_time_seconds |
| haproxy_process_stopping |
| haproxy_process_unstoppable_jobs |
| haproxy_server_bytes_in_total |
| haproxy_server_bytes_out_total |
| haproxy_server_check_code |
| haproxy_server_check_duration_seconds |
| haproxy_server_check_failures_total |
| haproxy_server_check_last_change_seconds |
| haproxy_server_check_status |
| haproxy_server_check_up_down_total |
| haproxy_server_client_aborts_total |
| haproxy_server_connect_time_average_seconds |
| haproxy_server_connection_attempts_total |
| haproxy_server_connection_errors_total |
| haproxy_server_connection_reuses_total |
| haproxy_server_current_queue |
| haproxy_server_current_sessions |
| haproxy_server_current_throttle |
| haproxy_server_downtime_seconds_total |
| haproxy_server_failed_header_rewriting_total |
| haproxy_server_internal_errors_total |
| haproxy_server_last_session_seconds |
| haproxy_server_limit_sessions |
| haproxy_server_loadbalanced_total |
| haproxy_server_max_connect_time_seconds |
| haproxy_server_max_queue |
| haproxy_server_max_queue_time_seconds |
| haproxy_server_max_response_time_seconds |
| haproxy_server_max_session_rate |
| haproxy_server_max_sessions |
| haproxy_server_max_total_time_seconds |
| haproxy_server_queue_limit |
| haproxy_server_queue_time_average_seconds |
| haproxy_server_redispatch_warnings_total |
| haproxy_server_response_errors_total |
| haproxy_server_response_time_average_seconds |
| haproxy_server_responses_denied_total |
| haproxy_server_retry_warnings_total |
| haproxy_server_server_aborts_total |
| haproxy_server_server_idle_connections_current |
| haproxy_server_server_idle_connections_limit |
| haproxy_server_sessions_total |
| haproxy_server_status |
| haproxy_server_total_time_average_seconds |
| haproxy_server_weight |
| node:cls:cpu_count |
| node:cls:cpu_mode |
| node:cls:cpu_usage |
| node:cls:cpu_usage_avg5m |
| node:cls:disk_io_rate |
| node:cls:disk_iops |
| node:cls:disk_read_iops |
| node:cls:disk_read_rate |
| node:cls:disk_write_iops |
| node:cls:disk_write_rate |
| node:cls:mem_usage |
| node:cls:network_io |
| node:cls:network_rx |
| node:cls:network_tx |
| node:cls:ntp_offset_range |
| node:cls:sched_timeslicesa |
| node:cpu:cpu_mode |
| node:cpu:cpu_usage |
| node:cpu:cpu_usage_avg5m |
| node:cpu:sched_timeslices |
| node:dev:disk_io_rate |
| node:dev:disk_iops |
| node:dev:disk_read_iops |
| node:dev:disk_read_rate |
| node:dev:disk_read_rt |
| node:dev:disk_read_time |
| node:dev:disk_write_iops |
| node:dev:disk_write_rate |
| node:dev:disk_write_rt |
| node:dev:disk_write_time |
| node:dev:network_io_rate |
| node:dev:network_rx |
| node:dev:network_tx |
| node:fs:avail_bytes |
| node:fs:free_bytes |
| node:fs:free_inode |
| node:fs:inode_usage |
| node:fs:size_bytes |
| node:fs:space_deriv_1h |
| node:fs:space_exhaust |
| node:fs:space_usage |
| node:fs:total_inode |
| node:ins:cpu_count |
| node:ins:cpu_mode |
| node:ins:cpu_usage |
| node:ins:cpu_usage_avg5m |
| node:ins:ctx_switch |
| node:ins:disk_io_rate |
| node:ins:disk_iops |
| node:ins:disk_read_iops |
| node:ins:disk_read_rate |
| node:ins:disk_write_iops |
| node:ins:disk_write_rate |
| node:ins:fd_usage |
| node:ins:forks |
| node:ins:intrrupt |
| node:ins:mem_app |
| node:ins:mem_free |
| node:ins:mem_usage |
| node:ins:network_io |
| node:ins:network_rx |
| node:ins:network_tx |
| node:ins:pagefault |
| node:ins:pagein |
| node:ins:pageout |
| node:ins:sched_timeslices |
| node:ins:stdload1 |
| node:ins:stdload15 |
| node:ins:stdload5 |
| node:ins:swap_usage |
| node:ins:swapin |
| node:ins:swapout |
| node:ins:tcp_active_opens |
| node:ins:tcp_dropped |
| node:ins:tcp_insegs |
| node:ins:tcp_outsegs |
| node:ins:tcp_overflow |
| node:ins:tcp_overflow_rate |
| node:ins:tcp_passive_opens |
| node:ins:tcp_retrans_rate |
| node:ins:tcp_retranssegs |
| node:ins:tcp_segs |
| node:uptime |
| node_arp_entries |
| node_boot_time_seconds |
| node_context_switches_total |
| node_cooling_device_cur_state |
| node_cooling_device_max_state |
| node_cpu_guest_seconds_total |
| node_cpu_seconds_total |
| node_disk_io_now |
| node_disk_io_time_seconds_total |
| node_disk_io_time_weighted_seconds_total |
| node_disk_read_bytes_total |
| node_disk_read_time_seconds_total |
| node_disk_reads_completed_total |
| node_disk_reads_merged_total |
| node_disk_write_time_seconds_total |
| node_disk_writes_completed_total |
| node_disk_writes_merged_total |
| node_disk_written_bytes_total |
| node_entropy_available_bits |
| node_exporter_build_info |
| node_filefd_allocated |
| node_filefd_maximum |
| node_filesystem_avail_bytes |
| node_filesystem_device_error |
| node_filesystem_files |
| node_filesystem_files_free |
| node_filesystem_free_bytes |
| node_filesystem_readonly |
| node_filesystem_size_bytes |
| node_forks_total |
| node_intr_total |
| node_ipvs_connections_total |
| node_ipvs_incoming_bytes_total |
| node_ipvs_incoming_packets_total |
| node_ipvs_outgoing_bytes_total |
| node_ipvs_outgoing_packets_total |
| node_load1 |
| node_load15 |
| node_load5 |
| node_memory_Active_anon_bytes |
| node_memory_Active_bytes |
| node_memory_Active_file_bytes |
| node_memory_AnonHugePages_bytes |
| node_memory_AnonPages_bytes |
| node_memory_Bounce_bytes |
| node_memory_Buffers_bytes |
| node_memory_Cached_bytes |
| node_memory_CmaFree_bytes |
| node_memory_CmaTotal_bytes |
| node_memory_CommitLimit_bytes |
| node_memory_Committed_AS_bytes |
| node_memory_DirectMap2M_bytes |
| node_memory_DirectMap4k_bytes |
| node_memory_Dirty_bytes |
| node_memory_HardwareCorrupted_bytes |
| node_memory_HugePages_Free |
| node_memory_HugePages_Rsvd |
| node_memory_HugePages_Surp |
| node_memory_HugePages_Total |
| node_memory_Hugepagesize_bytes |
| node_memory_Inactive_anon_bytes |
| node_memory_Inactive_bytes |
| node_memory_Inactive_file_bytes |
| node_memory_KernelStack_bytes |
| node_memory_Mapped_bytes |
| node_memory_MemAvailable_bytes |
| node_memory_MemFree_bytes |
| node_memory_MemTotal_bytes |
| node_memory_Mlocked_bytes |
| node_memory_NFS_Unstable_bytes |
| node_memory_PageTables_bytes |
| node_memory_Percpu_bytes |
| node_memory_SReclaimable_bytes |
| node_memory_SUnreclaim_bytes |
| node_memory_Shmem_bytes |
| node_memory_Slab_bytes |
| node_memory_SwapCached_bytes |
| node_memory_SwapFree_bytes |
| node_memory_SwapTotal_bytes |
| node_memory_Unevictable_bytes |
| node_memory_VmallocChunk_bytes |
| node_memory_VmallocTotal_bytes |
| node_memory_VmallocUsed_bytes |
| node_memory_WritebackTmp_bytes |
| node_memory_Writeback_bytes |
| node_netstat_Icmp6_InErrors |
| node_netstat_Icmp6_InMsgs |
| node_netstat_Icmp6_OutMsgs |
| node_netstat_Icmp_InErrors |
| node_netstat_Icmp_InMsgs |
| node_netstat_Icmp_OutMsgs |
| node_netstat_Ip6_InOctets |
| node_netstat_Ip6_OutOctets |
| node_netstat_IpExt_InOctets |
| node_netstat_IpExt_OutOctets |
| node_netstat_Ip_Forwarding |
| node_netstat_TcpExt_ListenDrops |
| node_netstat_TcpExt_ListenOverflows |
| node_netstat_TcpExt_SyncookiesFailed |
| node_netstat_TcpExt_SyncookiesRecv |
| node_netstat_TcpExt_SyncookiesSent |
| node_netstat_TcpExt_TCPSynRetrans |
| node_netstat_Tcp_ActiveOpens |
| node_netstat_Tcp_CurrEstab |
| node_netstat_Tcp_InErrs |
| node_netstat_Tcp_InSegs |
| node_netstat_Tcp_OutSegs |
| node_netstat_Tcp_PassiveOpens |
| node_netstat_Tcp_RetransSegs |
| node_netstat_Udp6_InDatagrams |
| node_netstat_Udp6_InErrors |
| node_netstat_Udp6_NoPorts |
| node_netstat_Udp6_OutDatagrams |
| node_netstat_Udp6_RcvbufErrors |
| node_netstat_Udp6_SndbufErrors |
| node_netstat_UdpLite6_InErrors |
| node_netstat_UdpLite_InErrors |
| node_netstat_Udp_InDatagrams |
| node_netstat_Udp_InErrors |
| node_netstat_Udp_NoPorts |
| node_netstat_Udp_OutDatagrams |
| node_netstat_Udp_RcvbufErrors |
| node_netstat_Udp_SndbufErrors |
| node_network_address_assign_type |
| node_network_carrier |
| node_network_carrier_changes_total |
| node_network_device_id |
| node_network_dormant |
| node_network_flags |
| node_network_iface_id |
| node_network_iface_link |
| node_network_iface_link_mode |
| node_network_info |
| node_network_mtu_bytes |
| node_network_net_dev_group |
| node_network_protocol_type |
| node_network_receive_bytes_total |
| node_network_receive_compressed_total |
| node_network_receive_drop_total |
| node_network_receive_errs_total |
| node_network_receive_fifo_total |
| node_network_receive_frame_total |
| node_network_receive_multicast_total |
| node_network_receive_packets_total |
| node_network_transmit_bytes_total |
| node_network_transmit_carrier_total |
| node_network_transmit_colls_total |
| node_network_transmit_compressed_total |
| node_network_transmit_drop_total |
| node_network_transmit_errs_total |
| node_network_transmit_fifo_total |
| node_network_transmit_packets_total |
| node_network_transmit_queue_length |
| node_network_up |
| node_nf_conntrack_entries |
| node_nf_conntrack_entries_limit |
| node_ntp_leap |
| node_ntp_offset_seconds |
| node_ntp_reference_timestamp_seconds |
| node_ntp_root_delay_seconds |
| node_ntp_root_dispersion_seconds |
| node_ntp_rtt_seconds |
| node_ntp_sanity |
| node_ntp_stratum |
| node_power_supply_capacity |
| node_power_supply_cyclecount |
| node_power_supply_energy_full |
| node_power_supply_energy_full_design |
| node_power_supply_energy_watthour |
| node_power_supply_info |
| node_power_supply_online |
| node_power_supply_power_watt |
| node_power_supply_present |
| node_power_supply_voltage_min_design |
| node_power_supply_voltage_volt |
| node_processes_max_processes |
| node_processes_max_threads |
| node_processes_pids |
| node_processes_state |
| node_processes_threads |
| node_procs_blocked |
| node_procs_running |
| node_schedstat_running_seconds_total |
| node_schedstat_timeslices_total |
| node_schedstat_waiting_seconds_total |
| node_scrape_collector_duration_seconds |
| node_scrape_collector_success |
| node_sockstat_FRAG6_inuse |
| node_sockstat_FRAG6_memory |
| node_sockstat_FRAG_inuse |
| node_sockstat_FRAG_memory |
| node_sockstat_RAW6_inuse |
| node_sockstat_RAW_inuse |
| node_sockstat_TCP6_inuse |
| node_sockstat_TCP_alloc |
| node_sockstat_TCP_inuse |
| node_sockstat_TCP_mem |
| node_sockstat_TCP_mem_bytes |
| node_sockstat_TCP_orphan |
| node_sockstat_TCP_tw |
| node_sockstat_UDP6_inuse |
| node_sockstat_UDPLITE6_inuse |
| node_sockstat_UDPLITE_inuse |
| node_sockstat_UDP_inuse |
| node_sockstat_UDP_mem |
| node_sockstat_UDP_mem_bytes |
| node_sockstat_sockets_used |
| node_systemd_socket_accepted_connections_total |
| node_systemd_socket_current_connections |
| node_systemd_system_running |
| node_systemd_timer_last_trigger_seconds |
| node_systemd_unit_state |
| node_systemd_units |
| node_systemd_version |
| node_tcp_connection_states |
| node_textfile_scrape_error |
| node_time_seconds |
| node_timex_estimated_error_seconds |
| node_timex_frequency_adjustment_ratio |
| node_timex_loop_time_constant |
| node_timex_maxerror_seconds |
| node_timex_offset_seconds |
| node_timex_pps_calibration_total |
| node_timex_pps_error_total |
| node_timex_pps_frequency_hertz |
| node_timex_pps_jitter_seconds |
| node_timex_pps_jitter_total |
| node_timex_pps_shift_seconds |
| node_timex_pps_stability_exceeded_total |
| node_timex_pps_stability_hertz |
| node_timex_status |
| node_timex_sync_status |
| node_timex_tai_offset_seconds |
| node_timex_tick_seconds |
| node_udp_queues |
| node_uname_info |
| node_vmstat_pgfault |
| node_vmstat_pgmajfault |
| node_vmstat_pgpgin |
| node_vmstat_pgpgout |
| node_vmstat_pswpin |
| node_vmstat_pswpout |
| node_xfs_allocation_btree_compares_total |
| node_xfs_allocation_btree_lookups_total |
| node_xfs_allocation_btree_records_deleted_total |
| node_xfs_allocation_btree_records_inserted_total |
| node_xfs_block_map_btree_compares_total |
| node_xfs_block_map_btree_lookups_total |
| node_xfs_block_map_btree_records_deleted_total |
| node_xfs_block_map_btree_records_inserted_total |
| node_xfs_block_mapping_extent_list_compares_total |
| node_xfs_block_mapping_extent_list_deletions_total |
| node_xfs_block_mapping_extent_list_insertions_total |
| node_xfs_block_mapping_extent_list_lookups_total |
| node_xfs_block_mapping_reads_total |
| node_xfs_block_mapping_unmaps_total |
| node_xfs_block_mapping_writes_total |
| node_xfs_directory_operation_create_total |
| node_xfs_directory_operation_getdents_total |
| node_xfs_directory_operation_lookup_total |
| node_xfs_directory_operation_remove_total |
| node_xfs_extent_allocation_blocks_allocated_total |
| node_xfs_extent_allocation_blocks_freed_total |
| node_xfs_extent_allocation_extents_allocated_total |
| node_xfs_extent_allocation_extents_freed_total |
| node_xfs_read_calls_total |
| node_xfs_vnode_active_total |
| node_xfs_vnode_allocate_total |
| node_xfs_vnode_get_total |
| node_xfs_vnode_hold_total |
| node_xfs_vnode_reclaim_total |
| node_xfs_vnode_release_total |
| node_xfs_vnode_remove_total |
| node_xfs_write_calls_total |
| pg:all:active_backends |
| pg:all:age |
| pg:all:backends |
| pg:all:buf_alloc |
| pg:all:buf_flush |
| pg:all:commits |
| pg:all:commits_realtime |
| pg:all:ixact_backends |
| pg:all:lag_bytes |
| pg:all:lag_seconds |
| pg:all:qps_realtime |
| pg:all:rollbacks |
| pg:all:rollbacks_realtime |
| pg:all:sessions |
| pg:all:tps_realtime |
| pg:all:tup_deleted |
| pg:all:tup_inserted |
| pg:all:tup_modified |
| pg:all:tup_selected |
| pg:all:tup_touched |
| pg:all:tup_updated |
| pg:all:wal_rate |
| pg:all:xacts |
| pg:all:xacts_avg30m |
| pg:all:xacts_mu |
| pg:all:xacts_realtime |
| pg:all:xacts_sigma |
| pg:cls:active_backends |
| pg:cls:age |
| pg:cls:backends |
| pg:cls:buf_alloc |
| pg:cls:buf_flush |
| pg:cls:ckpt_1h |
| pg:cls:commits |
| pg:cls:commits_realtime |
| pg:cls:ixact_backends |
| pg:cls:lag_bytes |
| pg:cls:lag_seconds |
| pg:cls:leader |
| pg:cls:load0 |
| pg:cls:load1 |
| pg:cls:load15 |
| pg:cls:load5 |
| pg:cls:lock_count |
| pg:cls:locks |
| pg:cls:primarys |
| pg:cls:qps_realtime |
| pg:cls:replicas |
| pg:cls:rlock |
| pg:cls:rollbacks |
| pg:cls:rollbacks_realtime |
| pg:cls:saturation0 |
| pg:cls:saturation1 |
| pg:cls:saturation15 |
| pg:cls:saturation5 |
| pg:cls:sessions |
| pg:cls:size |
| pg:cls:synchronous |
| pg:cls:temp_bytes |
| pg:cls:temp_files |
| pg:cls:timeline |
| pg:cls:tps_realtime |
| pg:cls:tup_deleted |
| pg:cls:tup_inserted |
| pg:cls:tup_modified |
| pg:cls:tup_selected |
| pg:cls:tup_touched |
| pg:cls:tup_updated |
| pg:cls:wal_rate |
| pg:cls:wlock |
| pg:cls:xacts |
| pg:cls:xacts_avg30m |
| pg:cls:xacts_mu |
| pg:cls:xacts_realtime |
| pg:cls:xacts_sigma |
| pg:cls:xlock |
| pg:db:age_deriv_1h |
| pg:db:age_exhaust |
| pg:db:backends |
| pg:db:blks_access_1m |
| pg:db:blks_hit_1m |
| pg:db:blks_read_1m |
| pg:db:buffer_hit_rate |
| pg:db:commits |
| pg:db:commits_realtime |
| pg:db:io_time_usage |
| pg:db:lock_count |
| pg:db:locks |
| pg:db:pool_current_conn |
| pg:db:pool_disabled |
| pg:db:pool_max_conn |
| pg:db:pool_paused |
| pg:db:pool_reserve_size |
| pg:db:pool_size |
| pg:db:qps_realtime |
| pg:db:read_time_usage |
| pg:db:rlock |
| pg:db:rollbacks |
| pg:db:rollbacks_realtime |
| pg:db:sessions |
| pg:db:temp_bytes |
| pg:db:temp_files |
| pg:db:tps_realtime |
| pg:db:tup_deleted |
| pg:db:tup_inserted |
| pg:db:tup_modified |
| pg:db:tup_selected |
| pg:db:tup_touched |
| pg:db:tup_updated |
| pg:db:wlock |
| pg:db:write_time_usage |
| pg:db:xacts |
| pg:db:xacts_avg30m |
| pg:db:xacts_mu |
| pg:db:xacts_realtime |
| pg:db:xacts_sigma |
| pg:db:xlock |
| pg:ins:active_backends |
| pg:ins:age |
| pg:ins:backends |
| pg:ins:buf_alloc |
| pg:ins:buf_flush |
| pg:ins:buf_flush_backend |
| pg:ins:buf_flush_checkpoint |
| pg:ins:checkpoint_lsn |
| pg:ins:ckpt_req |
| pg:ins:ckpt_timed |
| pg:ins:commits |
| pg:ins:commits_realtime |
| pg:ins:free_clients |
| pg:ins:free_servers |
| pg:ins:hit_rate |
| pg:ins:ixact_backends |
| pg:ins:lag_bytes |
| pg:ins:lag_seconds |
| pg:ins:last_ckpt |
| pg:ins:load0 |
| pg:ins:load1 |
| pg:ins:load15 |
| pg:ins:load5 |
| pg:ins:lock_count |
| pg:ins:locks |
| pg:ins:login_clients |
| pg:ins:pool_databases |
| pg:ins:pool_users |
| pg:ins:pools |
| pg:ins:qps_realtime |
| pg:ins:query_rt |
| pg:ins:query_rt_avg30m |
| pg:ins:query_rt_mu |
| pg:ins:query_rt_sigma |
| pg:ins:query_time_rate15m |
| pg:ins:query_time_rate1m |
| pg:ins:query_time_rate5m |
| pg:ins:recv_init_lsn |
| pg:ins:recv_init_tli |
| pg:ins:recv_last_lsn |
| pg:ins:recv_last_tli |
| pg:ins:redo_lsn |
| pg:ins:rlock |
| pg:ins:rollbacks |
| pg:ins:rollbacks_realtime |
| pg:ins:saturation0 |
| pg:ins:saturation1 |
| pg:ins:saturation15 |
| pg:ins:saturation5 |
| pg:ins:sessions |
| pg:ins:slot_retained_bytes |
| pg:ins:temp_bytes |
| pg:ins:temp_files |
| pg:ins:tps_realtime |
| pg:ins:tup_deleted |
| pg:ins:tup_inserted |
| pg:ins:tup_modified |
| pg:ins:tup_selected |
| pg:ins:tup_touched |
| pg:ins:tup_updated |
| pg:ins:used_clients |
| pg:ins:wal_rate |
| pg:ins:wlock |
| pg:ins:xact_rt |
| pg:ins:xact_rt_avg30m |
| pg:ins:xact_rt_mu |
| pg:ins:xact_rt_sigma |
| pg:ins:xact_time_rate15m |
| pg:ins:xact_time_rate1m |
| pg:ins:xact_time_rate5m |
| pg:ins:xacts |
| pg:ins:xacts_avg30m |
| pg:ins:xacts_mu |
| pg:ins:xacts_realtime |
| pg:ins:xacts_sigma |
| pg:ins:xlock |
| pg:query:call |
| pg:query:rt |
| pg:svc:active_backends |
| pg:svc:backends |
| pg:svc:buf_alloc |
| pg:svc:buf_flush |
| pg:svc:commits |
| pg:svc:commits_realtime |
| pg:svc:ixact_backends |
| pg:svc:load0 |
| pg:svc:load1 |
| pg:svc:load15 |
| pg:svc:load5 |
| pg:svc:lock_count |
| pg:svc:locks |
| pg:svc:qps_realtime |
| pg:svc:query_rt |
| pg:svc:query_rt_avg30m |
| pg:svc:query_rt_mu |
| pg:svc:query_rt_sigma |
| pg:svc:rlock |
| pg:svc:rollbacks |
| pg:svc:rollbacks_realtime |
| pg:svc:sessions |
| pg:svc:temp_bytes |
| pg:svc:temp_files |
| pg:svc:tps_realtime |
| pg:svc:tup_deleted |
| pg:svc:tup_inserted |
| pg:svc:tup_modified |
| pg:svc:tup_selected |
| pg:svc:tup_touched |
| pg:svc:tup_updated |
| pg:svc:wlock |
| pg:svc:xact_rt |
| pg:svc:xact_rt_avg30m |
| pg:svc:xact_rt_mu |
| pg:svc:xact_rt_sigma |
| pg:svc:xacts |
| pg:svc:xacts_avg30m |
| pg:svc:xacts_mu |
| pg:svc:xacts_realtime |
| pg:svc:xacts_sigma |
| pg:svc:xlock |
| pg_activity_count |
| pg_activity_max_conn_duration |
| pg_activity_max_duration |
| pg_activity_max_tx_duration |
| pg_backend_count |
| pg_backup_time |
| pg_bgwriter_buffers_alloc |
| pg_bgwriter_buffers_backend |
| pg_bgwriter_buffers_backend_fsync |
| pg_bgwriter_buffers_checkpoint |
| pg_bgwriter_buffers_clean |
| pg_bgwriter_checkpoint_sync_time |
| pg_bgwriter_checkpoint_write_time |
| pg_bgwriter_checkpoints_req |
| pg_bgwriter_checkpoints_timed |
| pg_bgwriter_maxwritten_clean |
| pg_bgwriter_stats_reset |
| pg_boot_time |
| pg_checkpoint_checkpoint_lsn |
| pg_checkpoint_elapse |
| pg_checkpoint_full_page_writes |
| pg_checkpoint_newest_commit_ts_xid |
| pg_checkpoint_next_multi_offset |
| pg_checkpoint_next_multixact_id |
| pg_checkpoint_next_oid |
| pg_checkpoint_next_xid |
| pg_checkpoint_next_xid_epoch |
| pg_checkpoint_oldest_active_xid |
| pg_checkpoint_oldest_commit_ts_xid |
| pg_checkpoint_oldest_multi_dbid |
| pg_checkpoint_oldest_multi_xid |
| pg_checkpoint_oldest_xid |
| pg_checkpoint_oldest_xid_dbid |
| pg_checkpoint_prev_tli |
| pg_checkpoint_redo_lsn |
| pg_checkpoint_time |
| pg_checkpoint_tli |
| pg_class_relage |
| pg_class_relpages |
| pg_class_relsize |
| pg_class_reltuples |
| pg_conf_reload_time |
| pg_database_age |
| pg_database_allow_conn |
| pg_database_conn_limit |
| pg_database_frozen_xid |
| pg_database_is_template |
| pg_db_blk_read_time |
| pg_db_blk_write_time |
| pg_db_blks_access |
| pg_db_blks_hit |
| pg_db_blks_read |
| pg_db_checksum_failures |
| pg_db_checksum_last_failure |
| pg_db_confl_bufferpin |
| pg_db_confl_deadlock |
| pg_db_confl_lock |
| pg_db_confl_snapshot |
| pg_db_confl_tablespace |
| pg_db_conflicts |
| pg_db_deadlocks |
| pg_db_numbackends |
| pg_db_stats_reset |
| pg_db_temp_bytes |
| pg_db_temp_files |
| pg_db_tup_deleted |
| pg_db_tup_fetched |
| pg_db_tup_inserted |
| pg_db_tup_modified |
| pg_db_tup_returned |
| pg_db_tup_updated |
| pg_db_xact_commit |
| pg_db_xact_rollback |
| pg_db_xact_total |
| pg_downstream_count |
| pg_exporter_last_scrape_time |
| pg_exporter_query_cache_ttl |
| pg_exporter_query_scrape_duration |
| pg_exporter_query_scrape_error_count |
| pg_exporter_query_scrape_hit_count |
| pg_exporter_query_scrape_metric_count |
| pg_exporter_query_scrape_total_count |
| pg_exporter_scrape_duration |
| pg_exporter_scrape_error_count |
| pg_exporter_scrape_total_count |
| pg_exporter_server_scrape_duration |
| pg_exporter_server_scrape_total_count |
| pg_exporter_server_scrape_total_seconds |
| pg_exporter_up |
| pg_exporter_uptime |
| pg_flush_lsn |
| pg_func_calls |
| pg_func_self_time |
| pg_func_total_time |
| pg_in_recovery |
| pg_index_bloat_ratio |
| pg_index_bloat_size |
| pg_index_idx_blks_hit |
| pg_index_idx_blks_read |
| pg_index_idx_scan |
| pg_index_idx_tup_fetch |
| pg_index_idx_tup_read |
| pg_insert_lsn |
| pg_is_in_backup |
| pg_is_in_recovery |
| pg_is_primary |
| pg_is_replica |
| pg_is_wal_replay_paused |
| pg_lag |
| pg_last_replay_time |
| pg_lock_count |
| pg_lsn |
| pg_meta_info |
| pg_query_blk_io_time |
| pg_query_calls |
| pg_query_max_time |
| pg_query_mean_time |
| pg_query_min_time |
| pg_query_rows |
| pg_query_stddev_time |
| pg_query_total_time |
| pg_query_wal_bytes |
| pg_receive_lsn |
| pg_replay_lsn |
| pg_setting_block_size |
| pg_setting_data_checksums |
| pg_setting_max_connections |
| pg_setting_max_locks_per_transaction |
| pg_setting_max_prepared_transactions |
| pg_setting_max_replication_slots |
| pg_setting_max_wal_senders |
| pg_setting_max_worker_processes |
| pg_setting_wal_log_hints |
| pg_shmem_allocated_size |
| pg_shmem_offset |
| pg_shmem_size |
| pg_size_bytes |
| pg_slru_blks_exists |
| pg_slru_blks_hit |
| pg_slru_blks_read |
| pg_slru_blks_written |
| pg_slru_blks_zeroed |
| pg_slru_flushes |
| pg_slru_stats_reset |
| pg_slru_truncates |
| pg_status |
| pg_sync_standby_disabled |
| pg_sync_standby_enabled |
| pg_table_analyze_count |
| pg_table_autoanalyze_count |
| pg_table_autovacuum_count |
| pg_table_bloat_ratio |
| pg_table_bloat_size |
| pg_table_heap_blks_hit |
| pg_table_heap_blks_read |
| pg_table_idx_blks_hit |
| pg_table_idx_blks_read |
| pg_table_idx_scan |
| pg_table_idx_tup_fetch |
| pg_table_last_analyze |
| pg_table_last_autoanalyze |
| pg_table_last_autovacuum |
| pg_table_last_vacuum |
| pg_table_n_dead_tup |
| pg_table_n_live_tup |
| pg_table_n_mod_since_analyze |
| pg_table_n_tup_del |
| pg_table_n_tup_hot_upd |
| pg_table_n_tup_ins |
| pg_table_n_tup_mod |
| pg_table_n_tup_upd |
| pg_table_seq_scan |
| pg_table_seq_tup_read |
| pg_table_size_bytes |
| pg_table_size_indexsize |
| pg_table_size_relsize |
| pg_table_size_toastsize |
| pg_table_tbl_scan |
| pg_table_tidx_blks_hit |
| pg_table_tidx_blks_read |
| pg_table_toast_blks_hit |
| pg_table_toast_blks_read |
| pg_table_tup_read |
| pg_table_vacuum_count |
| pg_timeline |
| pg_timestamp |
| pg_up |
| pg_uptime |
| pg_version |
| pg_write_lsn |
| pg_xact_xmax |
| pg_xact_xmin |
| pg_xact_xnum |
| pgbouncer_database_current_connections |
| pgbouncer_database_disabled |
| pgbouncer_database_max_connections |
| pgbouncer_database_paused |
| pgbouncer_database_pool_size |
| pgbouncer_database_reserve_pool |
| pgbouncer_exporter_last_scrape_time |
| pgbouncer_exporter_query_cache_ttl |
| pgbouncer_exporter_query_scrape_duration |
| pgbouncer_exporter_query_scrape_error_count |
| pgbouncer_exporter_query_scrape_hit_count |
| pgbouncer_exporter_query_scrape_metric_count |
| pgbouncer_exporter_query_scrape_total_count |
| pgbouncer_exporter_scrape_duration |
| pgbouncer_exporter_scrape_error_count |
| pgbouncer_exporter_scrape_total_count |
| pgbouncer_exporter_server_scrape_duration |
| pgbouncer_exporter_server_scrape_total_count |
| pgbouncer_exporter_server_scrape_total_seconds |
| pgbouncer_exporter_up |
| pgbouncer_exporter_uptime |
| pgbouncer_in_recovery |
| pgbouncer_list_items |
| pgbouncer_pool_active_clients |
| pgbouncer_pool_active_servers |
| pgbouncer_pool_idle_servers |
| pgbouncer_pool_login_servers |
| pgbouncer_pool_maxwait |
| pgbouncer_pool_maxwait_us |
| pgbouncer_pool_tested_servers |
| pgbouncer_pool_used_servers |
| pgbouncer_pool_waiting_clients |
| pgbouncer_stat_avg_query_count |
| pgbouncer_stat_avg_query_time |
| pgbouncer_stat_avg_recv |
| pgbouncer_stat_avg_sent |
| pgbouncer_stat_avg_wait_time |
| pgbouncer_stat_avg_xact_count |
| pgbouncer_stat_avg_xact_time |
| pgbouncer_stat_total_query_count |
| pgbouncer_stat_total_query_time |
| pgbouncer_stat_total_received |
| pgbouncer_stat_total_sent |
| pgbouncer_stat_total_wait_time |
| pgbouncer_stat_total_xact_count |
| pgbouncer_stat_total_xact_time |
| pgbouncer_up |
| pgbouncer_version |
| process_cpu_seconds_total |
| process_max_fds |
| process_open_fds |
| process_resident_memory_bytes |
| process_start_time_seconds |
| process_virtual_memory_bytes |
| process_virtual_memory_max_bytes |
| promhttp_metric_handler_errors_total |
| promhttp_metric_handler_requests_in_flight |
| promhttp_metric_handler_requests_total |
| scrape_duration_seconds |
| scrape_samples_post_metric_relabeling |
| scrape_samples_scraped |
| scrape_series_added |
| up |
9.4 - Derived Metrics
Details of the definition of Pigsty-derived monitoring metrics
Here are the rules for defining all Pigsty’s derived indicators.
Derived Metrics for Node
---
- name: node-rules
rules:
#==============================================================#
# Aliveness #
#==============================================================#
# TODO: change this to your node exporter port
- record: node_exporter_up
expr: up{instance=~".*:9099"}
- record: node:uptime
expr: time() - node_boot_time_seconds{}
#==============================================================#
# CPU #
#==============================================================#
# cpu mode time ratio
- record: node:cpu:cpu_mode
expr: irate(node_cpu_seconds_total{}[1m])
- record: node:ins:cpu_mode
expr: sum without (cpu) (node:cpu:cpu_mode)
- record: node:cls:cpu_mode
expr: sum by (cls, mode) (node:ins:cpu_mode)
# cpu schedule time-slices
- record: node:cpu:sched_timeslices
expr: irate(node_schedstat_timeslices_total{}[1m])
- record: node:ins:sched_timeslices
expr: sum without (cpu) (node:cpu:sched_timeslices)
- record: node:cls:sched_timeslicesa
expr: sum by (cls) (node:ins:sched_timeslices)
# cpu count
- record: node:ins:cpu_count
expr: count without (cpu) (node:cpu:cpu_usage)
- record: node:cls:cpu_count
expr: sum by (cls) (node:ins:cpu_count)
# cpu usage
- record: node:cpu:cpu_usage
expr: 1 - sum without (mode) (node:cpu:cpu_mode{mode="idle"})
- record: node:ins:cpu_usage
expr: sum without (cpu) (node:cpu:cpu_usage) / node:ins:cpu_count
- record: node:cls:cpu_usage
expr: sum by (cls) (node:ins:cpu_usage * node:ins:cpu_count) / sum by (cls) (node:ins:cpu_count)
# cpu usage avg5m
- record: node:cpu:cpu_usage_avg5m
expr: avg_over_time(node:cpu:cpu_usage[5m])
- record: node:ins:cpu_usage_avg5m
expr: avg_over_time(node:ins:cpu_usage[5m])
- record: node:cls:cpu_usage_avg5m
expr: avg_over_time(node:cls:cpu_usage[5m])
#==============================================================#
# Memory #
#==============================================================#
# mem usage
- record: node:ins:mem_app
expr: node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Buffers_bytes - node_memory_Cached_bytes - node_memory_Slab_bytes - node_memory_PageTables_bytes - node_memory_SwapCached_bytes
- record: node:ins:mem_free
expr: node_memory_MemFree_bytes{} + node_memory_Cached_bytes{}
- record: node:ins:mem_usage
expr: node:ins:mem_app / node_memory_MemTotal_bytes
- record: node:cls:mem_usage
expr: sum by (cls) (node:ins:mem_app) / sum by (cls) (node_memory_MemTotal_bytes)
- record: node:ins:swap_usage
expr: 1 - node_memory_SwapFree_bytes{} / node_memory_SwapTotal_bytes{}
#==============================================================#
# Disk #
#==============================================================#
# disk read iops
- record: node:dev:disk_read_iops
expr: irate(node_disk_reads_completed_total{device=~"[a-zA-Z-_]+"}[1m])
- record: node:ins:disk_read_iops
expr: sum without (device) (node:dev:disk_read_iops)
- record: node:cls:disk_read_iops
expr: sum by (cls) (node:ins:disk_read_iops)
# disk write iops
- record: node:dev:disk_write_iops
expr: irate(node_disk_writes_completed_total{device=~"[a-zA-Z-_]+"}[1m])
- record: node:ins:disk_write_iops
expr: sum without (device) (node:dev:disk_write_iops)
- record: node:cls:disk_write_iops
expr: sum by (cls) (node:ins:disk_write_iops)
# disk iops
- record: node:dev:disk_iops
expr: node:dev:disk_read_iops + node:dev:disk_write_iops
- record: node:ins:disk_iops
expr: node:ins:disk_read_iops + node:ins:disk_write_iops
- record: node:cls:disk_iops
expr: node:cls:disk_read_iops + node:cls:disk_write_iops
# read bandwidth (rate1m)
- record: node:dev:disk_read_rate
expr: rate(node_disk_read_bytes_total{device=~"[a-zA-Z-_]+"}[1m])
- record: node:ins:disk_read_rate
expr: sum without (device) (node:dev:disk_read_rate)
- record: node:cls:disk_read_rate
expr: sum by (cls) (node:ins:disk_read_rate)
# write bandwidth (rate1m)
- record: node:dev:disk_write_rate
expr: rate(node_disk_written_bytes_total{device=~"[a-zA-Z-_]+"}[1m])
- record: node:ins:disk_write_rate
expr: sum without (device) (node:dev:disk_write_rate)
- record: node:cls:disk_write_rate
expr: sum by (cls) (node:ins:disk_write_rate)
# io bandwidth (rate1m)
- record: node:dev:disk_io_rate
expr: node:dev:disk_read_rate + node:dev:disk_write_rate
- record: node:ins:disk_io_rate
expr: node:ins:disk_read_rate + node:ins:disk_write_rate
- record: node:cls:disk_io_rate
expr: node:cls:disk_read_rate + node:cls:disk_write_rate
# read/write total time
- record: node:dev:disk_read_time
expr: rate(node_disk_read_time_seconds_total{device=~"[a-zA-Z-_]+"}[1m])
- record: node:dev:disk_write_time
expr: rate(node_disk_read_time_seconds_total{device=~"[a-zA-Z-_]+"}[1m])
# read/write response time
- record: node:dev:disk_read_rt
expr: node:dev:disk_read_time / node:dev:disk_read_iops
- record: node:dev:disk_write_rt
expr: node:dev:disk_write_time / node:dev:disk_write_iops
- record: node:dev:disk_rt
expr: (node:dev:disk_read_time + node:dev:disk_write_time) / node:dev:iops
#==============================================================#
# Network #
#==============================================================#
# transmit bandwidth (out)
- record: node:dev:network_tx
expr: irate(node_network_transmit_bytes_total{}[1m])
- record: node:ins:network_tx
expr: sum without (device) (node:dev:network_tx{device!~"lo|bond.*"})
- record: node:cls:network_tx
expr: sum by (cls) (node:ins:network_tx)
# receive bandwidth (in)
- record: node:dev:network_rx
expr: irate(node_network_receive_bytes_total{}[1m])
- record: node:ins:network_rx
expr: sum without (device) (node:dev:network_rx{device!~"lo|bond.*"})
- record: node:cls:network_rx
expr: sum by (cls) (node:ins:network_rx)
# io bandwidth
- record: node:dev:network_io_rate
expr: node:dev:network_tx + node:dev:network_rx
- record: node:ins:network_io
expr: node:ins:network_tx + node:ins:network_rx
- record: node:cls:network_io
expr: node:cls:network_tx + node:cls:network_rx
#==============================================================#
# Schedule #
#==============================================================#
# normalized load
- record: node:ins:stdload1
expr: node_load1 / node:ins:cpu_count
- record: node:ins:stdload5
expr: node_load5 / node:ins:cpu_count
- record: node:ins:stdload15
expr: node_load15 / node:ins:cpu_count
# process
- record: node:ins:forks
expr: irate(node_forks_total[1m])
# interrupt & context switch
- record: node:ins:intrrupt
expr: irate(node_intr_total[1m])
- record: node:ins:ctx_switch
expr: irate(node_context_switches_total{}[1m])
#==============================================================#
# VM #
#==============================================================#
- record: node:ins:pagefault
expr: irate(node_vmstat_pgfault[1m])
- record: node:ins:pagein
expr: irate(node_vmstat_pgpgin[1m])
- record: node:ins:pageout
expr: irate(node_vmstat_pgpgout[1m])
- record: node:ins:swapin
expr: irate(node_vmstat_pswpin[1m])
- record: node:ins:swapout
expr: irate(node_vmstat_pswpout[1m])
#==============================================================#
# FS #
#==============================================================#
# filesystem space usage
- record: node:fs:free_bytes
expr: max without(device, fstype) (node_filesystem_free_bytes{fstype!~"(n|root|tmp)fs.*"})
- record: node:fs:avail_bytes
expr: max without(device, fstype) (node_filesystem_avail_bytes{fstype!~"(n|root|tmp)fs.*"})
- record: node:fs:size_bytes
expr: max without(device, fstype) (node_filesystem_size_bytes{fstype!~"(n|root|tmp)fs.*"})
- record: node:fs:space_usage
expr: 1 - (node:fs:avail_bytes{} / node:fs:size_bytes{})
- record: node:fs:free_inode
expr: max without(device, fstype) (node_filesystem_files_free{fstype!~"(n|root|tmp)fs.*"})
- record: node:fs:total_inode
expr: max without(device, fstype) (node_filesystem_files{fstype!~"(n|root|tmp)fs.*"})
# space delta and prediction
- record: node:fs:space_deriv_1h
expr: 0 - deriv(node_filesystem_avail_bytes{}[1h])
- record: node:fs:space_exhaust
expr: (node_filesystem_avail_bytes{} / node:fs:space_deriv_1h{}) > 0
# fs inode usage
- record: node:fs:inode_usage
expr: 1 - (node:fs:free_inode / node:fs:total_inode)
# file descriptor usage
- record: node:ins:fd_usage
expr: node_filefd_allocated / node_filefd_maximum
#==============================================================#
# TCP #
#==============================================================#
# tcp segments (rate1m)
- record: node:ins:tcp_insegs
expr: rate(node_netstat_Tcp_InSegs{}[1m])
- record: node:ins:tcp_outsegs
expr: rate(node_netstat_Tcp_OutSegs{}[1m])
- record: node:ins:tcp_retranssegs
expr: rate(node_netstat_Tcp_RetransSegs{}[1m])
- record: node:ins:tcp_segs
expr: node:ins:tcp_insegs + node:ins:tcp_outsegs
# retransmit
- record: node:ins:tcp_retrans_rate
expr: node:ins:tcp_retranssegs / node:ins:tcp_outsegs
# overflow
- record: node:ins:tcp_overflow_rate
expr: rate(node_netstat_TcpExt_ListenOverflows[1m])
#==============================================================#
# Netstat #
#==============================================================#
# tcp open (rate1m)
- record: node:ins:tcp_passive_opens
expr: rate(node_netstat_Tcp_PassiveOpens[1m])
- record: node:ins:tcp_active_opens
expr: rate(node_netstat_Tcp_ActiveOpens[1m])
# tcp close
- record: node:ins:tcp_attempt_fails
expr: rate(node_netstat_Tcp_AttemptFails[1m])
- record: node:ins:tcp_estab_resets
expr: rate(node_netstat_Tcp_EstabResets[1m])
# tcp drop
- record: node:ins:tcp_overflow
expr: rate(node_netstat_TcpExt_ListenOverflows[1m])
- record: node:ins:tcp_dropped
expr: rate(node_netstat_TcpExt_ListenDrops[1m])
#==============================================================#
# NTP #
#==============================================================#
- record: node:cls:ntp_offset_range
expr: max by (cls)(node_ntp_offset_seconds) - min by (cls)(node_ntp_offset_seconds)
...
Derived Metrics about postgres and pgbouncer
---
#==============================================================#
# File : pgsql.yml
# Ctime : 2020-04-22
# Mtime : 2020-12-03
# Desc : Record and alert rules for postgres
# Path : /etc/prometheus/rules/pgsql.yml
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
groups:
################################################################
# PgSQL Rules #
################################################################
- name: pgsql-rules
rules:
#==============================================================#
# Aliveness #
#==============================================================#
# TODO: change these to your pg_exporter & pgbouncer_exporter port
- record: pg_exporter_up
expr: up{instance=~".*:9185"}
- record: pgbouncer_exporter_up
expr: up{instance=~".*:9127"}
#==============================================================#
# Identity #
#==============================================================#
- record: pg_is_primary
expr: 1 - pg_in_recovery
- record: pg_is_replica
expr: pg_in_recovery
- record: pg_status
expr: (pg_up{} * 2) + (1 - pg_in_recovery{})
# encoded: 0:replica[DOWN] 1:primary[DOWN] 2:replica 3:primary
#==============================================================#
# Age #
#==============================================================#
# age
- record: pg:ins:age
expr: max without (datname) (pg_database_age{datname!~"template[0-9]"})
- record: pg:cls:age
expr: max by (cls) (pg:ins:age)
- record: pg:all:age
expr: max(pg:cls:age)
# age derive and prediction
- record: pg:db:age_deriv_1h
expr: deriv(pg_database_age{}[1h])
- record: pg:db:age_exhaust
expr: (2147483648 - pg_database_age{}) / pg:db:age_deriv_1h
#==============================================================#
# Sessions #
#==============================================================#
# session count (by state)
- record: pg:db:sessions
expr: pg_activity_count
- record: pg:ins:sessions
expr: sum without (datname) (pg:db:sessions)
- record: pg:svc:sessions
expr: sum by (cls, role, state) (pg:ins:sessions)
- record: pg:cls:sessions
expr: sum by (cls, state) (pg:ins:sessions)
- record: pg:all:sessions
expr: sum by (state) (pg:cls:sessions)
# backends
- record: pg:db:backends
expr: pg_db_numbackends
- record: pg:ins:backends
expr: sum without (datname) (pg_db_numbackends)
- record: pg:svc:backends
expr: sum by (cls, role) (pg:ins:backends)
- record: pg:cls:backends
expr: sum by (cls) (pg:ins:backends)
- record: pg:all:backends
expr: sum(pg:cls:backends)
# active backends
- record: pg:ins:active_backends
expr: pg:ins:sessions{state="active"}
- record: pg:svc:active_backends
expr: sum by (cls, role) (pg:ins:active_backends)
- record: pg:cls:active_backends
expr: sum by (cls) (pg:ins:active_backends)
- record: pg:all:active_backends
expr: sum(pg:cls:active_backends)
# idle in xact backends (including abort)
- record: pg:ins:ixact_backends
expr: pg:ins:sessions{state=~"idle in.*"}
- record: pg:svc:ixact_backends
expr: sum by (cls, role) (pg:ins:active_backends)
- record: pg:cls:ixact_backends
expr: sum by (cls) (pg:ins:active_backends)
- record: pg:all:ixact_backends
expr: sum(pg:cls:active_backends)
#==============================================================#
# Servers (Pgbouncer) #
#==============================================================#
# active servers
- record: pg:pool:active_servers
expr: pgbouncer_pool_active_servers{datname!="pgbouncer"}
- record: pg:db:active_servers
expr: sum without(user) (pg:pool:active_servers)
- record: pg:ins:active_servers
expr: sum without(user, datname) (pg:pool:active_servers)
- record: pg:svc:active_servers
expr: sum by (cls, role) (pg:ins:active_servers)
- record: pg:cls:active_servers
expr: sum by (cls) (pg:ins:active_servers)
- record: pg:all:active_servers
expr: sum(pg:cls:active_servers)
# idle servers
- record: pg:pool:idle_servers
expr: pgbouncer_pool_idle_servers{datname!="pgbouncer"}
- record: pg:db:idle_servers
expr: sum without(user) (pg:pool:idle_servers)
- record: pg:ins:idle_servers
expr: sum without(user, datname) (pg:pool:idle_servers)
- record: pg:svc:idle_servers
expr: sum by (cls, role) (pg:ins:idle_servers)
- record: pg:cls:idle_servers
expr: sum by (cls) (pg:ins:idle_servers)
- record: pg:all:idle_servers
expr: sum(pg:cls:idle_servers)
# used servers
- record: pg:pool:used_servers
expr: pgbouncer_pool_used_servers{datname!="pgbouncer"}
- record: pg:db:used_servers
expr: sum without(user) (pg:pool:used_servers)
- record: pg:ins:used_servers
expr: sum without(user, datname) (pg:pool:used_servers)
- record: pg:svc:used_servers
expr: sum by (cls, role) (pg:ins:used_servers)
- record: pg:cls:used_servers
expr: sum by (cls) (pg:ins:used_servers)
- record: pg:all:used_servers
expr: sum(pg:cls:used_servers)
# tested servers
- record: pg:pool:tested_servers
expr: pgbouncer_pool_tested_servers{datname!="pgbouncer"}
- record: pg:db:tested_servers
expr: sum without(user) (pg:pool:tested_servers)
- record: pg:ins:tested_servers
expr: sum without(user, datname) (pg:pool:tested_servers)
- record: pg:svc:tested_servers
expr: sum by (cls, role) (pg:ins:tested_servers)
- record: pg:cls:tested_servers
expr: sum by (cls) (pg:ins:tested_servers)
- record: pg:all:tested_servers
expr: sum(pg:cls:tested_servers)
# login servers
- record: pg:pool:login_servers
expr: pgbouncer_pool_login_servers{datname!="pgbouncer"}
- record: pg:db:login_servers
expr: sum without(user) (pg:pool:login_servers)
- record: pg:ins:login_servers
expr: sum without(user, datname) (pg:pool:login_servers)
- record: pg:svc:login_servers
expr: sum by (cls, role) (pg:ins:login_servers)
- record: pg:cls:login_servers
expr: sum by (cls) (pg:ins:login_servers)
- record: pg:all:login_servers
expr: sum(pg:cls:login_servers)
#==============================================================#
# Clients (Pgbouncer) #
#==============================================================#
# active clients
- record: pg:pool:active_clients
expr: pgbouncer_pool_active_clients{datname!="pgbouncer"}
- record: pg:db:active_clients
expr: sum without(user) (pg:pool:active_clients)
- record: pg:ins:active_clients
expr: sum without(user, datname) (pg:pool:active_clients)
- record: pg:svc:active_clients
expr: sum by (cls, role) (pg:ins:active_clients)
- record: pg:cls:active_clients
expr: sum by (cls) (pg:ins:active_clients)
- record: pg:all:active_clients
expr: sum(pg:cls:active_clients)
# waiting clients
- record: pg:pool:waiting_clients
expr: pgbouncer_pool_waiting_clients{datname!="pgbouncer"}
- record: pg:db:waiting_clients
expr: sum without(user) (pg:pool:waiting_clients)
- record: pg:ins:waiting_clients
expr: sum without(user, datname) (pg:pool:waiting_clients)
- record: pg:svc:waiting_clients
expr: sum by (cls, role) (pg:ins:waiting_clients)
- record: pg:cls:waiting_clients
expr: sum by (cls) (pg:ins:waiting_clients)
- record: pg:all:waiting_clients
expr: sum(pg:cls:waiting_clients)
#==============================================================#
# Transactions #
#==============================================================#
# commits (realtime)
- record: pg:db:commits_realtime
expr: irate(pg_db_xact_commit{}[1m])
- record: pg:ins:commits_realtime
expr: sum without (datname) (pg:db:commits_realtime)
- record: pg:svc:commits_realtime
expr: sum by (cls, role) (pg:ins:commits_realtime)
- record: pg:cls:commits_realtime
expr: sum by (cls) (pg:ins:commits_realtime)
- record: pg:all:commits_realtime
expr: sum(pg:cls:commits_realtime)
# commits (rate1m)
- record: pg:db:commits
expr: rate(pg_db_xact_commit{}[1m])
- record: pg:ins:commits
expr: sum without (datname) (pg:db:commits)
- record: pg:svc:commits
expr: sum by (cls, role) (pg:ins:commits)
- record: pg:cls:commits
expr: sum by (cls) (pg:ins:commits)
- record: pg:all:commits
expr: sum(pg:cls:commits)
# rollbacks realtime
- record: pg:db:rollbacks_realtime
expr: irate(pg_db_xact_rollback{}[1m])
- record: pg:ins:rollbacks_realtime
expr: sum without (datname) (pg:db:rollbacks_realtime)
- record: pg:svc:rollbacks_realtime
expr: sum by (cls, role) (pg:ins:rollbacks_realtime)
- record: pg:cls:rollbacks_realtime
expr: sum by (cls) (pg:ins:rollbacks_realtime)
- record: pg:all:rollbacks_realtime
expr: sum(pg:cls:rollbacks_realtime)
# rollbacks
- record: pg:db:rollbacks
expr: rate(pg_db_xact_rollback{}[1m])
- record: pg:ins:rollbacks
expr: sum without (datname) (pg:db:rollbacks)
- record: pg:svc:rollbacks
expr: sum by (cls, role) (pg:ins:rollbacks)
- record: pg:cls:rollbacks
expr: sum by (cls) (pg:ins:rollbacks)
- record: pg:all:rollbacks
expr: sum(pg:cls:rollbacks)
# xacts (realtime)
- record: pg:db:xacts_realtime
expr: irate(pg_db_xact_commit{}[1m])
- record: pg:ins:xacts_realtime
expr: sum without (datname) (pg:db:xacts_realtime)
- record: pg:svc:xacts_realtime
expr: sum by (cls, role) (pg:ins:xacts_realtime)
- record: pg:cls:xacts_realtime
expr: sum by (cls) (pg:ins:xacts_realtime)
- record: pg:all:xacts_realtime
expr: sum(pg:cls:xacts_realtime)
# xacts (rate1m)
- record: pg:db:xacts
expr: rate(pg_db_xact_commit{}[1m])
- record: pg:ins:xacts
expr: sum without (datname) (pg:db:xacts)
- record: pg:svc:xacts
expr: sum by (cls, role) (pg:ins:xacts)
- record: pg:cls:xacts
expr: sum by (cls) (pg:ins:xacts)
- record: pg:all:xacts
expr: sum(pg:cls:xacts)
# xacts avg30m
- record: pg:db:xacts_avg30m
expr: avg_over_time(pg:db:xacts[30m])
- record: pg:ins:xacts_avg30m
expr: avg_over_time(pg:ins:xacts[30m])
- record: pg:svc:xacts_avg30m
expr: avg_over_time(pg:svc:xacts[30m])
- record: pg:cls:xacts_avg30m
expr: avg_over_time(pg:cls:xacts[30m])
- record: pg:all:xacts_avg30m
expr: avg_over_time(pg:all:xacts[30m])
# xacts µ
- record: pg:db:xacts_mu
expr: avg_over_time(pg:db:xacts_avg30m[30m])
- record: pg:ins:xacts_mu
expr: avg_over_time(pg:ins:xacts_avg30m[30m])
- record: pg:svc:xacts_mu
expr: avg_over_time(pg:svc:xacts_avg30m[30m])
- record: pg:cls:xacts_mu
expr: avg_over_time(pg:cls:xacts_avg30m[30m])
- record: pg:all:xacts_mu
expr: avg_over_time(pg:all:xacts_avg30m[30m])
# xacts σ: sigma
- record: pg:db:xacts_sigma
expr: stddev_over_time(pg:db:xacts[30m])
- record: pg:ins:xacts_sigma
expr: stddev_over_time(pg:ins:xacts[30m])
- record: pg:svc:xacts_sigma
expr: stddev_over_time(pg:svc:xacts[30m])
- record: pg:cls:xacts_sigma
expr: stddev_over_time(pg:cls:xacts[30m])
- record: pg:all:xacts_sigma
expr: stddev_over_time(pg:all:xacts[30m])
#==============================================================#
# TPS (Pgbouncer) #
#==============================================================#
# TPS realtime (irate1m)
- record: pg:db:tps_realtime
expr: irate(pgbouncer_stat_total_xact_count{}[1m])
- record: pg:ins:tps_realtime
expr: sum without(datname) (pg:db:tps_realtime{})
- record: pg:svc:tps_realtime
expr: sum by(cls, role) (pg:ins:tps_realtime{})
- record: pg:cls:tps_realtime
expr: sum by(cls) (pg:ins:tps_realtime{})
- record: pg:all:tps_realtime
expr: sum(pg:cls:tps_realtime{})
# TPS (rate1m)
- record: pg:db:tps
expr: pgbouncer_stat_avg_xact_count{datname!="pgbouncer"}
- record: pg:ins:tps
expr: sum without(datname) (pg:db:tps)
- record: pg:svc:tps
expr: sum by (cls, role) (pg:ins:tps)
- record: pg:cls:tps
expr: sum by(cls) (pg:ins:tps)
- record: pg:all:tps
expr: sum(pg:cls:tps)
# tps : avg30m
- record: pg:db:tps_avg30m
expr: avg_over_time(pg:db:tps[30m])
- record: pg:ins:tps_avg30m
expr: avg_over_time(pg:ins:tps[30m])
- record: pg:svc:tps_avg30m
expr: avg_over_time(pg:svc:tps[30m])
- record: pg:cls:tps_avg30m
expr: avg_over_time(pg:cls:tps[30m])
- record: pg:all:tps_avg30m
expr: avg_over_time(pg:all:tps[30m])
# tps µ
- record: pg:db:tps_mu
expr: avg_over_time(pg:db:tps_avg30m[30m])
- record: pg:ins:tps_mu
expr: avg_over_time(pg:ins:tps_avg30m[30m])
- record: pg:svc:tps_mu
expr: avg_over_time(pg:svc:tps_avg30m[30m])
- record: pg:cls:tps_mu
expr: avg_over_time(pg:cls:tps_avg30m[30m])
- record: pg:all:tps_mu
expr: avg_over_time(pg:all:tps_avg30m[30m])
# tps σ
- record: pg:db:tps_sigma
expr: stddev_over_time(pg:db:tps[30m])
- record: pg:ins:tps_sigma
expr: stddev_over_time(pg:ins:tps[30m])
- record: pg:svc:tps_sigma
expr: stddev_over_time(pg:svc:tps[30m])
- record: pg:cls:tps_sigma
expr: stddev_over_time(pg:cls:tps[30m])
- record: pg:all:tps_sigma
expr: stddev_over_time(pg:all:tps[30m])
# xact rt (rate1m)
- record: pg:db:xact_rt
expr: pgbouncer_stat_avg_xact_time{datname!="pgbouncer"} / 1000000
- record: pg:ins:xact_rt
expr: sum without(datname) (rate(pgbouncer_stat_total_xact_time[1m])) / sum without(datname) (rate(pgbouncer_stat_total_xact_count[1m])) / 1000000
- record: pg:svc:xact_rt
expr: sum by (cls, role) (rate(pgbouncer_stat_total_xact_time[1m])) / sum by (cls, role) (rate(pgbouncer_stat_total_xact_count[1m])) / 1000000
# xact_rt avg30m
- record: pg:db:xact_rt_avg30m
expr: avg_over_time(pg:db:xact_rt[30m])
- record: pg:ins:xact_rt_avg30m
expr: avg_over_time(pg:ins:xact_rt[30m])
- record: pg:svc:xact_rt_avg30m
expr: avg_over_time(pg:svc:xact_rt[30m])
# xact_rt µ
- record: pg:db:xact_rt_mu
expr: avg_over_time(pg:db:xact_rt_avg30m[30m])
- record: pg:ins:xact_rt_mu
expr: avg_over_time(pg:ins:xact_rt_avg30m[30m])
- record: pg:svc:xact_rt_mu
expr: avg_over_time(pg:svc:xact_rt_avg30m[30m])
# xact_rt σ: stddev30m
- record: pg:db:xact_rt_sigma
expr: stddev_over_time(pg:db:xact_rt[30m])
- record: pg:ins:xact_rt_sigma
expr: stddev_over_time(pg:ins:xact_rt[30m])
- record: pg:svc:xact_rt_sigma
expr: stddev_over_time(pg:svc:xact_rt[30m])
#==============================================================#
# QPS (Pgbouncer) #
#==============================================================#
# QPS realtime (irate1m)
- record: pg:db:qps_realtime
expr: irate(pgbouncer_stat_total_query_count{}[1m])
- record: pg:ins:qps_realtime
expr: sum without(datname) (pg:db:qps_realtime{})
- record: pg:svc:qps_realtime
expr: sum by(cls, role) (pg:ins:qps_realtime{})
- record: pg:cls:qps_realtime
expr: sum by(cls) (pg:ins:qps_realtime{})
- record: pg:all:qps_realtime
expr: sum(pg:cls:qps_realtime{})
# qps (rate1m)
- record: pg:db:qps
expr: pgbouncer_stat_avg_query_count{datname!="pgbouncer"}
- record: pg:ins:qps
expr: sum without(datname) (pg:db:qps)
- record: pg:svc:qps
expr: sum by (cls, role) (pg:ins:qps)
- record: pg:cls:qps
expr: sum by(cls) (pg:ins:qps)
- record: pg:all:qps
expr: sum(pg:cls:qps)
# qps avg30m
- record: pg:db:qps_avg30m
expr: avg_over_time(pg:db:qps[30m])
- record: pg:ins:qps_avg30m
expr: avg_over_time(pg:ins:qps[30m])
- record: pg:svc:qps_avg30m
expr: avg_over_time(pg:svc:qps[30m])
- record: pg:cls:qps_avg30m
expr: avg_over_time(pg:cls:qps[30m])
- record: pg:all:qps_avg30m
expr: avg_over_time(pg:all:qps[30m])
# qps µ
- record: pg:db:qps_mu
expr: avg_over_time(pg:db:qps_avg30m[30m])
- record: pg:ins:qps_mu
expr: avg_over_time(pg:ins:qps_avg30m[30m])
- record: pg:svc:qps_mu
expr: avg_over_time(pg:svc:qps_avg30m[30m])
- record: pg:cls:qps_mu
expr: avg_over_time(pg:cls:qps_avg30m[30m])
- record: pg:all:qps_mu
expr: avg_over_time(pg:all:qps_avg30m[30m])
# qps σ: stddev30m qps
- record: pg:db:qps_sigma
expr: stddev_over_time(pg:db:qps[30m])
- record: pg:ins:qps_sigma
expr: stddev_over_time(pg:ins:qps[30m])
- record: pg:svc:qps_sigma
expr: stddev_over_time(pg:svc:qps[30m])
- record: pg:cls:qps_sigma
expr: stddev_over_time(pg:cls:qps[30m])
- record: pg:all:qps_sigma
expr: stddev_over_time(pg:all:qps[30m])
# query rt (1m avg)
- record: pg:db:query_rt
expr: pgbouncer_stat_avg_query_time{datname!="pgbouncer"} / 1000000
- record: pg:ins:query_rt
expr: sum without(datname) (rate(pgbouncer_stat_total_query_time[1m])) / sum without(datname) (rate(pgbouncer_stat_total_query_count[1m])) / 1000000
- record: pg:svc:query_rt
expr: sum by (cls, role) (rate(pgbouncer_stat_total_query_time[1m])) / sum by (cls, role) (rate(pgbouncer_stat_total_query_count[1m])) / 1000000
# query_rt avg30m
- record: pg:db:query_rt_avg30m
expr: avg_over_time(pg:db:query_rt[30m])
- record: pg:ins:query_rt_avg30m
expr: avg_over_time(pg:ins:query_rt[30m])
- record: pg:svc:query_rt_avg30m
expr: avg_over_time(pg:svc:query_rt[30m])
# query_rt µ
- record: pg:db:query_rt_mu
expr: avg_over_time(pg:db:query_rt_avg30m[30m])
- record: pg:ins:query_rt_mu
expr: avg_over_time(pg:ins:query_rt_avg30m[30m])
- record: pg:svc:query_rt_mu
expr: avg_over_time(pg:svc:query_rt_avg30m[30m])
# query_rt σ: stddev30m
- record: pg:db:query_rt_sigma
expr: stddev_over_time(pg:db:query_rt[30m])
- record: pg:ins:query_rt_sigma
expr: stddev_over_time(pg:ins:query_rt[30m])
- record: pg:svc:query_rt_sigma
expr: stddev_over_time(pg:svc:query_rt[30m])
#==============================================================#
# PG Load #
#==============================================================#
# seconds spend on transaction in last minute
- record: pg:ins:xact_time_rate1m
expr: sum without (datname) (rate(pgbouncer_stat_total_xact_time{}[1m])) / 1000000
- record: pg:ins:xact_time_rate5m
expr: sum without (datname) (rate(pgbouncer_stat_total_xact_time{}[5m])) / 1000000
- record: pg:ins:xact_time_rate15m
expr: sum without (datname) (rate(pgbouncer_stat_total_xact_time{}[15m])) / 1000000
# seconds spend on queries in last minute
- record: pg:ins:query_time_rate1m
expr: sum without (datname) (rate(pgbouncer_stat_total_query_time{}[1m])) / 1000000
- record: pg:ins:query_time_rate5m
expr: sum without (datname) (rate(pgbouncer_stat_total_query_time{}[5m])) / 1000000
- record: pg:ins:query_time_rate15m
expr: sum without (datname) (rate(pgbouncer_stat_total_query_time{}[15m])) / 1000000
# instance level load
- record: pg:ins:load0
expr: sum without (datname) (irate(pgbouncer_stat_total_xact_time{}[1m])) / on (ip) group_left() node:ins:cpu_count / 1000000
- record: pg:ins:load1
expr: pg:ins:xact_time_rate1m / on (ip) group_left() node:ins:cpu_count
- record: pg:ins:load5
expr: pg:ins:xact_time_rate5m / on (ip) group_left() node:ins:cpu_count
- record: pg:ins:load15
expr: pg:ins:xact_time_rate15m / on (ip) group_left() node:ins:cpu_count
# service level load
- record: pg:svc:load0
expr: sum by (svc, cls, role) (irate(pgbouncer_stat_total_xact_time{}[1m])) / on (svc) group_left() sum by (svc) (node:ins:cpu_count{}) / 1000000
- record: pg:svc:load1
expr: sum by (svc, cls, role) (pg:ins:xact_time_rate1m) / on (svc) group_left() sum by (svc) (node:ins:cpu_count{}) / 1000000
- record: pg:svc:load5
expr: sum by (svc, cls, role) (pg:ins:xact_time_rate5m) / on (svc) group_left() sum by (svc) (node:ins:cpu_count{}) / 1000000
- record: pg:svc:load15
expr: sum by (svc, cls, role) (pg:ins:xact_time_rate15m) / on (svc) group_left() sum by (svc) (node:ins:cpu_count{}) / 1000000
# cluster level load
- record: pg:cls:load0
expr: sum by (cls) (irate(pgbouncer_stat_total_xact_time{}[1m])) / on (cls) node:cls:cpu_count{} / 1000000
- record: pg:cls:load1
expr: sum by (cls) (pg:ins:xact_time_rate1m) / on (cls) node:cls:cpu_count
- record: pg:cls:load5
expr: sum by (cls) (pg:ins:xact_time_rate5m) / on (cls) node:cls:cpu_count
- record: pg:cls:load15
expr: sum by (cls) (pg:ins:xact_time_rate15m) / on (cls) node:cls:cpu_count
#==============================================================#
# PG Saturation #
#==============================================================#
# max value of pg_load and cpu_usage
# instance level saturation
- record: pg:ins:saturation0
expr: pg:ins:load0 > node:ins:cpu_usage or node:ins:cpu_usage
- record: pg:ins:saturation1
expr: pg:ins:load1 > node:ins:cpu_usage or node:ins:cpu_usage
- record: pg:ins:saturation5
expr: pg:ins:load5 > node:ins:cpu_usage or node:ins:cpu_usage
- record: pg:ins:saturation15
expr: pg:ins:load15 > node:ins:cpu_usage or node:ins:cpu_usage
# cluster level saturation
- record: pg:cls:saturation0
expr: pg:cls:load0 > node:cls:cpu_usage or node:cls:cpu_usage
- record: pg:cls:saturation1
expr: pg:cls:load1 > node:cls:cpu_usage or node:cls:cpu_usage
- record: pg:cls:saturation5
expr: pg:cls:load5 > node:cls:cpu_usage or node:cls:cpu_usage
- record: pg:cls:saturation15
expr: pg:cls:load15 > node:cls:cpu_usage or node:cls:cpu_usage
#==============================================================#
# CRUD #
#==============================================================#
# rows touched
- record: pg:db:tup_touched
expr: irate(pg_db_tup_fetched{}[1m])
- record: pg:ins:tup_touched
expr: sum without(datname) (pg:db:tup_touched)
- record: pg:svc:tup_touched
expr: sum by (cls, role) (pg:ins:tup_touched)
- record: pg:cls:tup_touched
expr: sum by (cls) (pg:ins:tup_touched)
- record: pg:all:tup_touched
expr: sum(pg:cls:tup_touched)
# selected
- record: pg:db:tup_selected
expr: irate(pg_db_tup_returned{}[1m])
- record: pg:ins:tup_selected
expr: sum without(datname) (pg:db:tup_selected)
- record: pg:svc:tup_selected
expr: sum by (cls, role) (pg:ins:tup_selected)
- record: pg:cls:tup_selected
expr: sum by (cls) (pg:ins:tup_selected)
- record: pg:all:tup_selected
expr: sum(pg:cls:tup_selected)
# inserted
- record: pg:db:tup_inserted
expr: irate(pg_db_tup_inserted{}[1m])
- record: pg:ins:tup_inserted
expr: sum without(datname) (pg:db:tup_inserted)
- record: pg:svc:tup_inserted
expr: sum by (cls, role) (pg:ins:tup_inserted)
- record: pg:cls:tup_inserted
expr: sum by (cls) (pg:ins:tup_inserted{role="primary"})
- record: pg:all:tup_inserted
expr: sum(pg:cls:tup_inserted)
# updated
- record: pg:db:tup_updated
expr: irate(pg_db_tup_updated{}[1m])
- record: pg:ins:tup_updated
expr: sum without(datname) (pg:db:tup_updated)
- record: pg:svc:tup_updated
expr: sum by (cls, role) (pg:ins:tup_updated)
- record: pg:cls:tup_updated
expr: sum by (cls) (pg:ins:tup_updated{role="primary"})
- record: pg:all:tup_updated
expr: sum(pg:cls:tup_updated)
# deleted
- record: pg:db:tup_deleted
expr: irate(pg_db_tup_deleted{}[1m])
- record: pg:ins:tup_deleted
expr: sum without(datname) (pg:db:tup_deleted)
- record: pg:svc:tup_deleted
expr: sum by (cls, role) (pg:ins:tup_deleted)
- record: pg:cls:tup_deleted
expr: sum by (cls) (pg:ins:tup_deleted{role="primary"})
- record: pg:all:tup_deleted
expr: sum(pg:cls:tup_deleted)
# modified
- record: pg:db:tup_modified
expr: irate(pg_db_tup_modified{}[1m])
- record: pg:ins:tup_modified
expr: sum without(datname) (pg:db:tup_modified)
- record: pg:svc:tup_modified
expr: sum by (cls, role) (pg:ins:tup_modified)
- record: pg:cls:tup_modified
expr: sum by (cls) (pg:ins:tup_modified{role="primary"})
- record: pg:all:tup_modified
expr: sum(pg:cls:tup_deleted)
#==============================================================#
# Object Access #
#==============================================================#
# table access
- record: pg:table:idx_scan
expr: rate(pg_table_idx_scan{}[1m])
- record: pg:table:seq_scan
expr: rate(pg_table_seq_scan{}[1m])
- record: pg:table:qps_realtime
expr: irate(pg_table_idx_scan{}[1m])
# index access
- record: pg:index:idx_scan
expr: rate(pg_index_idx_scan{}[1m])
- record: pg:index:qps_realtime
expr: irate(pg_index_idx_scan{}[1m])
# func access
- record: pg:func:call
expr: rate(pg_func_calls{}[1m])
- record: pg:func:rt
expr: rate(pg_func_total_time{}[1m]) / pg:func:call
# query access
- record: pg:query:call
expr: rate(pg_query_calls{}[1m])
- record: pg:query:rt
expr: rate(pg_query_total_time{}[1m]) / pg:query:call / 1000
#==============================================================#
# Blocks IO #
#==============================================================#
# blocks read/hit/access in 1min
- record: pg:db:blks_read_1m
expr: increase(pg_db_blks_read{}[1m])
- record: pg:db:blks_hit_1m
expr: increase(pg_db_blks_hit{}[1m])
- record: pg:db:blks_access_1m
expr: increase(pg_db_blks_access{}[1m])
# buffer hit rate (1m)
- record: pg:db:buffer_hit_rate
expr: pg:db:blks_hit_1m / pg:db:blks_access_1m
- record: pg:ins:hit_rate
expr: sum without(datname) (pg:db:blks_hit_1m) / sum without(datname) (pg:db:blks_access_1m)
# read/write time usage
- record: pg:db:read_time_usage
expr: rate(pg_db_blk_read_time[1m])
- record: pg:db:write_time_usage
expr: rate(pg_db_blk_write_time[1m])
- record: pg:db:io_time_usage
expr: pg:db:read_time_usage + pg:db:write_time_usage
#==============================================================#
# Traffic IO (Pgbouncer) #
#==============================================================#
# transmit bandwidth (sent, out)
- record: pg:db:tx
expr: irate(pgbouncer_stat_total_sent{datname!="pgbouncer"}[1m])
- record: pg:ins:tx
expr: sum without (user, datname) (pg:db:tx)
- record: pg:svc:tx
expr: sum by (cls, role) (pg:ins:tx)
- record: pg:cls:tx
expr: sum by (cls) (pg:ins:tx)
- record: pg:all:tx
expr: sum(pg:cls:tx)
# receive bandwidth (sent, out)
- record: pg:db:rx
expr: irate(pgbouncer_stat_total_received{datname!="pgbouncer"}[1m])
- record: pg:ins:rx
expr: sum without (datname) (pg:db:rx)
- record: pg:svc:rx
expr: sum by (cls, role) (pg:ins:rx)
- record: pg:cls:rx
expr: sum by (cls) (pg:ins:rx)
- record: pg:all:rx
expr: sum(pg:cls:rx)
#==============================================================#
# Lock #
#==============================================================#
# lock count by mode
- record: pg:db:locks
expr: pg_lock_count
- record: pg:ins:locks
expr: sum without(datname) (pg:db:locks)
- record: pg:svc:locks
expr: sum by (cls, role, mode) (pg:ins:locks)
- record: pg:cls:locks
expr: sum by (cls, mode) (pg:ins:locks)
# total lock count
- record: pg:db:lock_count
expr: sum without (mode) (pg_lock_count{})
- record: pg:ins:lock_count
expr: sum without(datname) (pg:db:lock_count)
- record: pg:svc:lock_count
expr: sum by (cls, role) (pg:ins:lock_count)
- record: pg:cls:lock_count
expr: sum by (cls) (pg:ins:lock_count)
# read category lock
- record: pg:db:rlock
expr: sum without (mode) (pg_lock_count{mode="AccessShareLock"})
- record: pg:ins:rlock
expr: sum without(datname) (pg:db:rlock)
- record: pg:svc:rlock
expr: sum by (cls, role) (pg:ins:rlock)
- record: pg:cls:rlock
expr: sum by (cls) (pg:ins:rlock)
# write category lock (insert|update|delete)
- record: pg:db:wlock
expr: sum without (mode) (pg_lock_count{mode=~"RowShareLock|RowExclusiveLock"})
- record: pg:ins:wlock
expr: sum without(datname) (pg:db:wlock)
- record: pg:svc:wlock
expr: sum by (cls, role) (pg:ins:wlock)
- record: pg:cls:wlock
expr: sum by (cls) (pg:ins:wlock)
# exclusive category lock
- record: pg:db:xlock
expr: sum without (mode) (pg_lock_count{mode=~"AccessExclusiveLock|ExclusiveLock|ShareRowExclusiveLock|ShareLock|ShareUpdateExclusiveLock"})
- record: pg:ins:xlock
expr: sum without(datname) (pg:db:xlock)
- record: pg:svc:xlock
expr: sum by (cls, role) (pg:ins:xlock)
- record: pg:cls:xlock
expr: sum by (cls) (pg:ins:xlock)
#==============================================================#
# Temp #
#==============================================================#
# temp files and bytes
- record: pg:db:temp_bytes
expr: rate(pg_db_temp_bytes{}[1m])
- record: pg:ins:temp_bytes
expr: sum without(datname) (pg:db:temp_bytes)
- record: pg:svc:temp_bytes
expr: sum by (cls, role) (pg:ins:temp_bytes)
- record: pg:cls:temp_bytes
expr: sum by (cls) (pg:ins:temp_bytes)
# temp file count in last 1m
- record: pg:db:temp_files
expr: increase(pg_db_temp_files{}[1m])
- record: pg:ins:temp_files
expr: sum without(datname) (pg:db:temp_files)
- record: pg:svc:temp_files
expr: sum by (cls, role) (pg:ins:temp_files)
- record: pg:cls:temp_files
expr: sum by (cls) (pg:ins:temp_files)
#==============================================================#
# Size #
#==============================================================#
# database size
- record: pg:ins:db_size
expr: pg_size_database
- record: pg:cls:db_size
expr: sum by (cls) (pg:ins:db_size)
# wal size
- record: pg:ins:wal_size
expr: pg_size_wal
- record: pg:cls:wal_size
expr: sum by (cls) (pg:ins:wal_size)
# log size
- record: pg:ins:log_size
expr: pg_size_log
- record: pg:cls:log_size
expr: sum by (cls) (pg_size_log)
#==============================================================#
# Checkpoint #
#==============================================================#
# checkpoint stats
- record: pg:ins:last_ckpt
expr: pg_checkpoint_elapse
- record: pg:ins:ckpt_timed
expr: increase(pg_bgwriter_checkpoints_timed{}[30s])
- record: pg:ins:ckpt_req
expr: increase(pg_bgwriter_checkpoints_req{}[30s])
- record: pg:cls:ckpt_1h
expr: increase(pg:ins:ckpt_timed[1h]) + increase(pg:ins:ckpt_req[1h])
# buffer flush & alloc
- record: pg:ins:buf_flush_backend
expr: irate(pg_bgwriter_buffers_backend{}[1m]) * 8192
- record: pg:ins:buf_flush_checkpoint
expr: irate(pg_bgwriter_buffers_checkpoint{}[1m]) * 8192
- record: pg:ins:buf_flush
expr: pg:ins:buf_flush_backend + pg:ins:buf_flush_checkpoint
- record: pg:svc:buf_flush
expr: sum by (cls, role) (pg:ins:buf_flush)
- record: pg:cls:buf_flush
expr: sum by (cls) (pg:ins:buf_flush)
- record: pg:all:buf_flush
expr: sum(pg:cls:buf_flush)
- record: pg:ins:buf_alloc
expr: irate(pg_bgwriter_buffers_alloc{}[1m]) * 8192
- record: pg:svc:buf_alloc
expr: sum by (cls, role) (pg:ins:buf_alloc)
- record: pg:cls:buf_alloc
expr: sum by (cls) (pg:ins:buf_alloc)
- record: pg:all:buf_alloc
expr: sum(pg:cls:buf_alloc)
#==============================================================#
# LSN #
#==============================================================#
# timeline & LSN
- record: pg_timeline
expr: pg_checkpoint_tli
- record: pg:ins:redo_lsn
expr: pg_checkpoint_redo_lsn
- record: pg:ins:checkpoint_lsn
expr: pg_checkpoint_checkpoint_lsn
# wal rate
- record: pg:ins:wal_rate
expr: rate(pg_lsn[1m])
- record: pg:cls:wal_rate
expr: max by (cls) (pg:ins:wal_rate{role="primary"})
- record: pg:all:wal_rate
expr: sum(pg:cls:wal_rate)
#==============================================================#
# Replication #
#==============================================================#
# lag time from replica's view
- record: pg:ins:lag_seconds
expr: pg_lag
- record: pg:cls:lag_seconds
expr: max by (cls) (pg:ins:lag_seconds)
- record: pg:all:lag_seconds
expr: max(pg:cls:lag_seconds)
# sync status
- record: pg:ins:sync_status # application_name must set to replica ins name
expr: max by (ins, svc, cls) (label_replace(pg_replication_sync_status, "ins", "$1", "application_name", "(.+)"))
# lag of self (application_name must set to standby ins name)
- record: pg:ins:lag_bytes
expr: max by (ins, svc, cls, role) (label_replace(pg_replication_lsn{} - pg_replication_replay_lsn{}, "ins", "$1", "application_name", "(.+)"))
- record: pg:cls:lag_bytes
expr: max by (cls) (pg:ins:lag_bytes)
- record: pg:all:lag_bytes
expr: max(pg:cls:lag_bytes)
# replication slot retained bytes
- record: pg:ins:slot_retained_bytes
expr: pg_slot_retained_bytes
# replica walreceiver
- record: pg:ins:recv_init_lsn
expr: pg_walreceiver_init_lsn
- record: pg:ins:recv_last_lsn
expr: pg_walreceiver_last_lsn
- record: pg:ins:recv_init_tli
expr: pg_walreceiver_init_tli
- record: pg:ins:recv_last_tli
expr: pg_walreceiver_last_tli
#==============================================================#
# Cluster Level Metrics
#==============================================================#
# cluster member count
- record: pg:cls:leader
expr: count by (cls, ins) (max by (cls, ins) (pg_status{}) == 3)
- record: pg:cls:size
expr: count by (cls) (max by (cls, ins) (pg_up{}))
- record: pg:cls:timeline
expr: max by (cls) (pg_checkpoint_tli{})
- record: pg:cls:primarys
expr: count by (cls) (max by (cls, ins) (pg_in_recovery{}) == 0)
- record: pg:cls:replicas
expr: count by (cls) (max by (cls, ins) (pg_in_recovery{}) == 1)
- record: pg:cls:synchronous
expr: max by (cls) (pg_sync_standby_enabled) > bool 0
- record: pg:cls:bridging_instances
expr: count by (cls, role, ins, ip) (pg_replication_lsn{state="streaming", role!="primary"} > 0)
- record: pg:cls:bridging
expr: count by (cls) (pg:cls:bridging_instances)
- record: pg:cls:cascading
expr: count by (cls) (pg_replication_lsn{state="streaming", role!="primary"})
#==============================================================#
# Pgbouncer List #
#==============================================================#
# object list
- record: pg:ins:pools
expr: pgbouncer_list_items{list="pools"}
- record: pg:ins:pool_databases
expr: pgbouncer_list_items{list="databases"}
- record: pg:ins:pool_users
expr: pgbouncer_list_items{list="users"}
- record: pg:ins:login_clients
expr: pgbouncer_list_items{list="login_clients"}
- record: pg:ins:free_clients
expr: pgbouncer_list_items{list="free_clients"}
- record: pg:ins:used_clients
expr: pgbouncer_list_items{list="used_clients"}
- record: pg:ins:free_servers
expr: pgbouncer_list_items{list="free_servers"}
#==============================================================#
# DBConfig (Pgbouncer) #
#==============================================================#
- record: pg:db:pool_max_conn
expr: pgbouncer_database_pool_size{datname!="pgbouncer"} + pgbouncer_database_reserve_pool{datname!="pgbouncer"}
- record: pg:db:pool_size
expr: pgbouncer_database_pool_size{datname!="pgbouncer"}
- record: pg:db:pool_reserve_size
expr: pgbouncer_database_reserve_pool{datname!="pgbouncer"}
- record: pg:db:pool_current_conn
expr: pgbouncer_database_current_connections{datname!="pgbouncer"}
- record: pg:db:pool_paused
expr: pgbouncer_database_paused{datname!="pgbouncer"}
- record: pg:db:pool_disabled
expr: pgbouncer_database_disabled{datname!="pgbouncer"}
#==============================================================#
# Waiting (Pgbouncer) #
#==============================================================#
# average wait time
- record: pg:db:wait_rt
expr: pgbouncer_stat_avg_wait_time{datname!="pgbouncer"} / 1000000
# max wait time among all clients
- record: pg:pool:maxwait
expr: pgbouncer_pool_maxwait{datname!="pgbouncer"} + pgbouncer_pool_maxwait_us{datname!="pgbouncer"} / 1000000
- record: pg:db:maxwait
expr: max without(user) (pg:pool:maxwait)
- record: pg:ins:maxwait
expr: max without(user, datname) (pg:db:maxwait)
- record: pg:svc:maxwait
expr: max by (cls, role) (pg:ins:maxwait)
- record: pg:cls:maxwait
expr: max by (cls) (pg:ins:maxwait)
- record: pg:all:maxwait
expr: max(pg:cls:maxwait)
...
9.5 - Alert Rules
Alter rules definition of Pigsty
Prometheus Alert Rules

Node Alert Rules
################################################################
# Node Alert #
################################################################
- name: node-alert
rules:
# node exporter down for 1m triggers a P1 alert
- alert: NODE_EXPORTER_DOWN
expr: up{instance=~"^.*:(9100)$"} == 0
for: 1m
labels:
severity: P1
annotations:
summary: "P1 Node Exporter Down: {{ $labels.ins }} {{ $value }}"
description: |
up[instance={{ $labels.instance }}] = {{ $value }} == 0
https://dba.p1staff.com/d/node?var-ip={{ $labels.instance }}&from=now-5m&to=now&refresh=10s
#==============================================================#
# CPU & Load #
#==============================================================#
# node avg CPU usage > 90% for 1m
- alert: NODE_CPU_HIGH
expr: node:ins:cpu_usage > 0.90
for: 1m
labels:
severity: P1
annotations:
summary: "P1 Node CPU High: {{ $labels.ins }} {{ $labels.ip }}"
description: |
node:ins:cpu_usage[ins={{ $labels.ins }}, ip={{ $labels.ip }}] = {{ $value }} > 90%
http://g.pigsty/d/node?&from=now-10m&to=now&viewPanel=28&fullscreen&var-ip={{ $labels.ip }}
# node load5 > 100%
- alert: NODE_LOAD_HIGH
expr: node:ins:stdload5 > 1
for: 3m
labels:
severity: P2
annotations:
summary: "P2 Node Load High: {{ $labels.ins }} {{ $labels.ip }}"
description: |
node:ins:stdload5[ins={{ $labels.ins }}, ip={{ $labels.ip }}] = {{ $value }} > 100%
http://g.pigsty/d/node?&from=now-10m&to=now&viewPanel=37&fullscreen&var-ip={{ $labels.ip }}
#==============================================================#
# Disk & Filesystem #
#==============================================================#
# main fs readonly triggers an immediate P0 alert
- alert: NODE_FS_READONLY
expr: node_filesystem_readonly{fstype!~"(n|root|tmp)fs.*"} == 1
labels:
severity: P0
annotations:
summary: "P0 Node Filesystem Readonly: {{ $labels.ins }} {{ $labels.ip }}"
description: |
node_filesystem_readonly{ins={{ $labels.ins }}, ip={{ $labels.ip }},fstype!~"(n|root|tmp)fs.*"} == 1
http://g.pigsty/d/node?&from=now-10m&to=now&viewPanel=110&fullscreen&var-ip={{ $labels.ip }}
# main fs usage > 90% for 1m triggers P1 alert
- alert: NODE_FS_SPACE_FULL
expr: node:fs:space_usage > 0.90
for: 1m
labels:
severity: P1
annotations:
summary: "P1 Node Filesystem Space Full: {{ $labels.ins }} {{ $labels.ip }}"
description: |
node:fs:space_usage[ins={{ $labels.ins }}, ip={{ $labels.ip }}] = {{ $value }} > 90%
http://g.pigsty/d/node?&from=now-10m&to=now&viewPanel=110&fullscreen&var-ip={{ $labels.ip }}
# main fs inode usage > 90% for 1m triggers P1 alert
- alert: NODE_FS_INODE_FULL
expr: node:fs:inode_usage > 0.90
for: 1m
labels:
severity: P1
annotations:
summary: "P1 Node Filesystem iNode Full: {{ $labels.ins }} {{ $labels.ip }}"
description: |
node:fs:inode_usage[ins={{ $labels.ins }}, ip={{ $labels.ip }}] = {{ $value }} > 90%
http://g.pigsty/d/node?&from=now-10m&to=now&viewPanel=110&fullscreen&var-ip={{ $labels.ip }}
# fd usage > 90% for 1m triggers P1 alert
- alert: NODE_FD_FULL
expr: node:fs:fd_usage > 0.90
for: 1m
labels:
severity: P1
annotations:
summary: "P1 Node File Descriptor Full: {{ $labels.ins }} {{ $labels.ip }}"
description: |
node:fs:fd_usage[ins={{ $labels.ins }}, ip={{ $labels.ip }}] = {{ $value }} > 90%
http://g.pigsty/d/node?&from=now-10m&to=now&viewPanel=58&fullscreen&var-ip={{ $labels.ip }}
# ssd read latency > 32ms for 3m (except long-read)
- alert: NODE_READ_LATENCY_HIGH
expr: node:dev:disk_read_rt < 10000 and node:dev:disk_read_rt > 0.032
for: 3m
labels:
severity: P2
annotations:
summary: "P2 Node Read Latency High: {{ $labels.ins }} {{ $labels.ip }}"
description: |
node:dev:disk_read_rt[ins={{ $labels.ins }}, ip={{ $labels.ip }}, device={{ $labels.device }}] = {{ $value }} > 32ms
http://g.pigsty/d/node?&from=now-10m&to=now&viewPanel=29&fullscreen&var-ip={{ $labels.ip }}
# ssd write latency > 16ms for 3m
- alert: NODE_WRITE_LATENCY_HIGH
expr: node:dev:disk_write_rt < 10000 and node:dev:disk_write_rt > 0.016
for: 3m
labels:
severity: P2
annotations:
summary: "P2 Node Write Latency High: {{ $labels.ins }} {{ $labels.ip }}"
description: |
node:dev:disk_write_rt[ins={{ $labels.ins }}, ip={{ $labels.ip }}, device={{ $labels.device }}] = {{ $value }} > 16ms
http://g.pigsty/d/node?&from=now-10m&to=now&viewPanel=29&fullscreen&var-ip={{ $labels.ip }}
#==============================================================#
# Memory #
#==============================================================#
# shared memory usage > 80% for 1m triggers a P1 alert
- alert: NODE_MEM_HIGH
expr: node:ins:mem_usage > 0.80
for: 1m
labels:
severity: P1
annotations:
summary: "P1 Node Mem High: {{ $labels.ins }} {{ $labels.ip }}"
description: |
node:ins:mem_usage[ins={{ $labels.ins }}, ip={{ $labels.ip }}] = {{ $value }} > 80%
http://g.pigsty/d/node?&from=now-10m&to=now&viewPanel=40&fullscreen&var-ip={{ $labels.ip }}
#==============================================================#
# Network & TCP #
#==============================================================#
# node tcp listen overflow > 2 for 3m
- alert: NODE_TCP_LISTEN_OVERFLOW
expr: node:ins:tcp_overflow_rate > 2
for: 3m
labels:
severity: P1
annotations:
summary: "P1 Node TCP Listen Overflow: {{ $labels.ins }} {{ $labels.ip }}"
description: |
node:ins:tcp_overflow_rate[ins={{ $labels.ins }}, ip={{ $labels.ip }}] = {{ $value }} > 2
http://g.pigsty/d/node?&from=now-10m&to=now&viewPanel=55&fullscreen&var-ip={{ $labels.ip }}
# node tcp retrans > 32 per sec for 3m
- alert: NODE_TCP_RETRANS_HIGH
expr: node:ins:tcp_retranssegs > 32
for: 3m
labels:
severity: P2
annotations:
summary: "P2 Node TCP Retrans High: {{ $labels.ins }} {{ $labels.ip }}"
description: |
node:ins:tcp_retranssegs[ins={{ $labels.ins }}, ip={{ $labels.ip }}] = {{ $value }} > 32
http://g.pigsty/d/node?&from=now-10m&to=now&viewPanel=52&fullscreen&var-ip={{ $labels.ip }}
# node tcp conn > 32768 for 1m
- alert: NODE_TCP_CONN_HIGH
expr: node_netstat_Tcp_CurrEstab > 32768
for: 3m
labels:
severity: P2
annotations:
summary: "P2 Node TCP Connection High: {{ $labels.ins }} {{ $labels.ip }}"
description: |
node_netstat_Tcp_CurrEstab[ins={{ $labels.ins }}, ip={{ $labels.ip }}] = {{ $value }} > 32768
http://g.pigsty/d/node?&from=now-10m&to=now&viewPanel=54&fullscreen&var-ip={{ $labels.ip }}
#==============================================================#
# Misc #
#==============================================================#
# node ntp offset > 1s for 1m
- alert: NODE_NTP_OFFSET_HIGH
expr: abs(node_ntp_offset_seconds) > 1
for: 1m
labels:
severity: P1
annotations:
summary: "P1 Node NTP Offset High: {{ $labels.ins }} {{ $labels.ip }}"
description: |
node_ntp_offset_seconds[ins={{ $labels.ins }}, ip={{ $labels.ip }}] = {{ $value }} > 32768
http://g.pigsty/d/node?&from=now-10m&to=now&viewPanel=70&fullscreen&var-ip={{ $labels.ip }}
数据库与连接池报警规则
---
################################################################
# PgSQL Alert #
################################################################
- name: pgsql-alert
rules:
#==============================================================#
# Error / Aliveness #
#==============================================================#
# cluster size change triggers a P0 alert (warn: auto heal in 5min)
- alert: PGSQL_CLUSTER_SHRINK
expr: delta(pg:cls:size{}[5m]) < 0
for: 15s
labels:
severity: P1
annotations:
summary: 'delta(pg:cls:size{cls={{ $labels.cls }}}[15s]) = {{ $value | printf "%.0f" }} < 0'
description: |
http://g.pigsty/d/pg-cluster&from=now-10m&to=now&var-cls={{ $labels.cls }}
# postgres down for 15s triggers a P0 alert
- alert: PGSQL_DOWN
expr: PGSQL_up{} == 0
labels:
severity: P0
annotations:
summary: "[P0] PGSQL_DOWN: {{ $labels.ins }} {{ $value }}"
description: |
PGSQL_up[ins={{ $labels.ins }}] = {{ $value }} == 0
http://g.pigsty/d/pg-instance&from=now-10m&to=now&var-ins={{ $labels.ins }}
# pgbouncer down for 15s triggers a P0 alert
- alert: PGBOUNCER_DOWN
expr: pgbouncer_up{} == 0
labels:
severity: P0
annotations:
summary: "P0 Pgbouncer Down: {{ $labels.ins }} {{ $value }}"
description: |
pgbouncer_up[ins={{ $labels.ins }}] = {{ $value }} == 0
http://g.pigsty/d/pg-pgbouncer&from=now-10m&to=now&var-ins={{ $labels.ins }}
# pg/pgbouncer exporter down for 1m triggers a P1 alert
- alert: PGSQL_EXPORTER_DOWN
expr: up{instance=~"^.*:(9630|9631)$"} == 0
for: 1m
labels:
severity: P1
annotations:
summary: "P1 PG/PGB Exporter Down: {{ $labels.ins }} {{ $labels.instance }} {{ $value }}"
description: |
up[instance={{ $labels.instance }}] = {{ $value }} == 0
http://g.pigsty/d/pg-instance?from=now-10m&to=now&viewPanel=262&fullscreen&var-ins={{ $labels.ins }}
#==============================================================#
# Latency #
#==============================================================#
# replication break for 1m triggers a P1 alert (warn: heal in 5m)
- alert: PGSQL_REPLICATION_BREAK
expr: delta(PGSQL_downstream_count{state="streaming"}[5m]) < 0
for: 1m
labels:
severity: P1
annotations:
summary: "P1 PG Replication Break: {{ $labels.ins }} {{ $value }}"
description: |
PGSQL_downstream_count_delta[ins={{ $labels.ins }}] = {{ $value }} < 0
http://g.pigsty/d/pg-instance?from=now-10m&to=now&viewPanel=180&fullscreen&var-ins={{ $labels.ins }}
# replication lag greater than 8 second for 3m triggers a P1 alert
- alert: PGSQL_REPLICATION_LAG
expr: PGSQL_replication_replay_lag{application_name!='PGSQL_receivewal'} > 8
for: 3m
labels:
severity: P1
annotations:
summary: "P1 PG Replication Lagged: {{ $labels.ins }} {{ $value }}"
description: |
PGSQL_replication_replay_lag[ins={{ $labels.ins }}] = {{ $value }} > 8s
http://g.pigsty/d/pg-instance?from=now-10m&to=now&viewPanel=384&fullscreen&var-ins={{ $labels.ins }}
# pg avg response time > 16ms
- alert: PGSQL_QUERY_RT_HIGH
expr: pg:ins:query_rt > 0.016
for: 1m
labels:
severity: P1
annotations:
summary: "P1 PG Query Response Time High: {{ $labels.ins }} {{ $value }}"
description: |
pg:ins:query_rt[ins={{ $labels.ins }}] = {{ $value }} > 16ms
http://g.pigsty/d/pg-instance?from=now-10m&to=now&viewPanel=137&fullscreen&var-ins={{ $labels.ins }}
#==============================================================#
# Saturation #
#==============================================================#
# pg load1 high than 70% for 3m triggers a P1 alert
- alert: PGSQL_LOAD_HIGH
expr: pg:ins:load1{} > 0.70
for: 3m
labels:
severity: P1
annotations:
summary: "P1 PG Load High: {{ $labels.ins }} {{ $value }}"
description: |
pg:ins:load1[ins={{ $labels.ins }}] = {{ $value }} > 70%
http://g.pigsty/d/pg-instance?from=now-10m&to=now&viewPanel=210&fullscreen&var-ins={{ $labels.ins }}
# pg active backend more than 2 times of available cpu cores for 3m triggers a P1 alert
- alert: PGSQL_BACKEND_HIGH
expr: pg:ins:active_backends / on(ins) node:ins:cpu_count > 2
for: 3m
labels:
severity: P1
annotations:
summary: "P1 PG Backend High: {{ $labels.ins }} {{ $value }}"
description: |
pg:ins:active_backends/node:ins:cpu_count[ins={{ $labels.ins }}] = {{ $value }} > 2
http://g.pigsty/d/pg-instance?from=now-10m&to=now&viewPanel=150&fullscreen&var-ins={{ $labels.ins }}
# max idle xact duration exceed 3m
- alert: PGSQL_IDLE_XACT_BACKEND_HIGH
expr: pg:ins:ixact_backends > 1
for: 3m
labels:
severity: P2
annotations:
summary: "P1 PG Idle In Transaction Backend High: {{ $labels.ins }} {{ $value }}"
description: |
pg:ins:ixact_backends[ins={{ $labels.ins }}] = {{ $value }} > 1
http://g.pigsty/d/pg-instance?from=now-10m&to=now&viewPanel=161&fullscreen&var-ins={{ $labels.ins }}
# 2 waiting clients for 3m triggers a P1 alert
- alert: PGSQL_CLIENT_QUEUING
expr: pg:ins:waiting_clients > 2
for: 3m
labels:
severity: P1
annotations:
summary: "P1 PG Client Queuing: {{ $labels.ins }} {{ $value }}"
description: |
pg:ins:waiting_clients[ins={{ $labels.ins }}] = {{ $value }} > 2
http://g.pigsty/d/pg-instance?from=now-10m&to=now&viewPanel=159&fullscreen&var-ins={{ $labels.ins }}
# age wrap around (near half) triggers a P1 alert
- alert: PGSQL_AGE_HIGH
expr: pg:ins:age > 1000000000
for: 3m
labels:
severity: P1
annotations:
summary: "P1 PG Age High: {{ $labels.ins }} {{ $value }}"
description: |
pg:ins:age[ins={{ $labels.ins }}] = {{ $value }} > 1000000000
http://g.pigsty/d/pg-instance?from=now-10m&to=now&viewPanel=172&fullscreen&var-ins={{ $labels.ins }}
#==============================================================#
# Traffic #
#==============================================================#
# more than 30k TPS lasts for 3m triggers a P1 (pgbouncer bottleneck)
- alert: PGSQL_TPS_HIGH
expr: pg:ins:xacts > 30000
for: 3m
labels:
severity: P1
annotations:
summary: "P1 Postgres TPS High: {{ $labels.ins }} {{ $value }}"
description: |
pg:ins:xacts[ins={{ $labels.ins }}] = {{ $value }} > 30000
http://g.pigsty/d/pg-instance?from=now-10m&to=now&viewPanel=125&fullscreen&var-ins={{ $labels.ins }}
...
9.6 - Sandbox Stdout
standard output of sandbox bootstrap
Makefile shortcuts and their expected outputs
Overview
# Clone the repo and enter it
cd /tmp && git clone git@github.com:Vonng/pigsty.git && cd pigsty
make up # 拉起vagrant虚拟机
make ssh # 配置虚拟机ssh访问 【单次,下次启动无需再次执行】
sudo make dns # 写入Pigsty静态DNS域名 【sudo输入密码,可选,单次】
make download # 下载最新离线软件包 【可选,可显著加速初始化】
make upload # 将离线软件包上传至元节点
make init # 初始化Pigsty
make mon-view # 打开Pigsty监控首页(默认用户密码:admin:admin)
clone
克隆并进入项目目录,后续操作均位于项目根目录中(以/tmp/pigsty为例)
cd /tmp && git clone git@github.com:Vonng/pigsty.git && cd pigsty
clean
清理所有的沙箱痕迹(如果有)
$ make clean
cd vagrant && vagrant destroy -f --parallel; exit 0
==> vagrant: A new version of Vagrant is available: 2.2.14 (installed version: 2.2.13)!
==> vagrant: To upgrade visit: https://www.vagrantup.com/downloads.html
==> node-3: Forcing shutdown of VM...
==> node-3: Destroying VM and associated drives...
==> node-2: Forcing shutdown of VM...
==> node-2: Destroying VM and associated drives...
==> node-1: Forcing shutdown of VM...
==> node-1: Destroying VM and associated drives...
==> meta: Forcing shutdown of VM...
==> meta: Destroying VM and associated drives...
up
执行make up将调用vagrant up命令,根据Vagrantfile中的定义,使用Virtualbox创建四台虚拟机。
请注意第一次执行vagrant up时,软件会自动从官网下载 CentOS/7 的虚拟机镜像。如果您的网络状况不佳(例如没有FQ代理),则可能需要等待相当长的一段时间。您也可以选择自己创建虚拟机,并根据 部署 一章的说明进行Pigsty部署(不建议)。
$ make up
cd vagrant && vagrant up
Bringing machine 'meta' up with 'virtualbox' provider...
Bringing machine 'node-1' up with 'virtualbox' provider...
Bringing machine 'node-2' up with 'virtualbox' provider...
Bringing machine 'node-3' up with 'virtualbox' provider...
==> meta: Cloning VM...
==> meta: Matching MAC address for NAT networking...
==> meta: Setting the name of the VM: vagrant_meta_1614587906789_29514
==> meta: Clearing any previously set network interfaces...
==> meta: Preparing network interfaces based on configuration...
meta: Adapter 1: nat
meta: Adapter 2: hostonly
==> meta: Forwarding ports...
meta: 22 (guest) => 2222 (host) (adapter 1)
==> meta: Running 'pre-boot' VM customizations...
==> meta: Booting VM...
==> meta: Waiting for machine to boot. This may take a few minutes...
meta: SSH address: 127.0.0.1:2222
meta: SSH username: vagrant
meta: SSH auth method: private key
==> meta: Machine booted and ready!
==> meta: Checking for guest additions in VM...
meta: No guest additions were detected on the base box for this VM! Guest
meta: additions are required for forwarded ports, shared folders, host only
meta: networking, and more. If SSH fails on this machine, please install
meta: the guest additions and repackage the box to continue.
meta:
meta: This is not an error message; everything may continue to work properly,
meta: in which case you may ignore this message.
==> meta: Setting hostname...
==> meta: Configuring and enabling network interfaces...
==> meta: Rsyncing folder: /Volumes/Data/pigsty/vagrant/ => /vagrant
==> meta: Running provisioner: shell...
meta: Running: /var/folders/_5/_0mbf4292pl9y4xgy0kn2r1h0000gn/T/vagrant-shell20210301-60046-1jv6obp.sh
meta: [INFO] write ssh config to /home/vagrant/.ssh
==> node-1: Cloning VM...
==> node-1: Matching MAC address for NAT networking...
==> node-1: Setting the name of the VM: vagrant_node-1_1614587930603_84690
==> node-1: Fixed port collision for 22 => 2222. Now on port 2200.
==> node-1: Clearing any previously set network interfaces...
==> node-1: Preparing network interfaces based on configuration...
node-1: Adapter 1: nat
node-1: Adapter 2: hostonly
==> node-1: Forwarding ports...
node-1: 22 (guest) => 2200 (host) (adapter 1)
==> node-1: Running 'pre-boot' VM customizations...
==> node-1: Booting VM...
==> node-1: Waiting for machine to boot. This may take a few minutes...
node-1: SSH address: 127.0.0.1:2200
node-1: SSH username: vagrant
node-1: SSH auth method: private key
==> node-1: Machine booted and ready!
==> node-1: Checking for guest additions in VM...
node-1: No guest additions were detected on the base box for this VM! Guest
node-1: additions are required for forwarded ports, shared folders, host only
node-1: networking, and more. If SSH fails on this machine, please install
node-1: the guest additions and repackage the box to continue.
node-1:
node-1: This is not an error message; everything may continue to work properly,
node-1: in which case you may ignore this message.
==> node-1: Setting hostname...
==> node-1: Configuring and enabling network interfaces...
==> node-1: Rsyncing folder: /Volumes/Data/pigsty/vagrant/ => /vagrant
==> node-1: Running provisioner: shell...
node-1: Running: /var/folders/_5/_0mbf4292pl9y4xgy0kn2r1h0000gn/T/vagrant-shell20210301-60046-5w83e1.sh
node-1: [INFO] write ssh config to /home/vagrant/.ssh
==> node-2: Cloning VM...
==> node-2: Matching MAC address for NAT networking...
==> node-2: Setting the name of the VM: vagrant_node-2_1614587953786_32441
==> node-2: Fixed port collision for 22 => 2222. Now on port 2201.
==> node-2: Clearing any previously set network interfaces...
==> node-2: Preparing network interfaces based on configuration...
node-2: Adapter 1: nat
node-2: Adapter 2: hostonly
==> node-2: Forwarding ports...
node-2: 22 (guest) => 2201 (host) (adapter 1)
==> node-2: Running 'pre-boot' VM customizations...
==> node-2: Booting VM...
==> node-2: Waiting for machine to boot. This may take a few minutes...
node-2: SSH address: 127.0.0.1:2201
node-2: SSH username: vagrant
node-2: SSH auth method: private key
==> node-2: Machine booted and ready!
==> node-2: Checking for guest additions in VM...
node-2: No guest additions were detected on the base box for this VM! Guest
node-2: additions are required for forwarded ports, shared folders, host only
node-2: networking, and more. If SSH fails on this machine, please install
node-2: the guest additions and repackage the box to continue.
node-2:
node-2: This is not an error message; everything may continue to work properly,
node-2: in which case you may ignore this message.
==> node-2: Setting hostname...
==> node-2: Configuring and enabling network interfaces...
==> node-2: Rsyncing folder: /Volumes/Data/pigsty/vagrant/ => /vagrant
==> node-2: Running provisioner: shell...
node-2: Running: /var/folders/_5/_0mbf4292pl9y4xgy0kn2r1h0000gn/T/vagrant-shell20210301-60046-1xljcde.sh
node-2: [INFO] write ssh config to /home/vagrant/.ssh
==> node-3: Cloning VM...
==> node-3: Matching MAC address for NAT networking...
==> node-3: Setting the name of the VM: vagrant_node-3_1614587977533_52921
==> node-3: Fixed port collision for 22 => 2222. Now on port 2202.
==> node-3: Clearing any previously set network interfaces...
==> node-3: Preparing network interfaces based on configuration...
node-3: Adapter 1: nat
node-3: Adapter 2: hostonly
==> node-3: Forwarding ports...
node-3: 22 (guest) => 2202 (host) (adapter 1)
==> node-3: Running 'pre-boot' VM customizations...
==> node-3: Booting VM...
==> node-3: Waiting for machine to boot. This may take a few minutes...
node-3: SSH address: 127.0.0.1:2202
node-3: SSH username: vagrant
node-3: SSH auth method: private key
==> node-3: Machine booted and ready!
==> node-3: Checking for guest additions in VM...
node-3: No guest additions were detected on the base box for this VM! Guest
node-3: additions are required for forwarded ports, shared folders, host only
node-3: networking, and more. If SSH fails on this machine, please install
node-3: the guest additions and repackage the box to continue.
node-3:
node-3: This is not an error message; everything may continue to work properly,
node-3: in which case you may ignore this message.
==> node-3: Setting hostname...
==> node-3: Configuring and enabling network interfaces...
==> node-3: Rsyncing folder: /Volumes/Data/pigsty/vagrant/ => /vagrant
==> node-3: Running provisioner: shell...
node-3: Running: /var/folders/_5/_0mbf4292pl9y4xgy0kn2r1h0000gn/T/vagrant-shell20210301-60046-1cykx8o.sh
node-3: [INFO] write ssh config to /home/vagrant/.ssh
ssh
新拉起的虚拟机默认用户为vagrant,需要配置本机到虚拟机的免密ssh访问。 执行make ssh命令将调用vagrant的ssh-config命令,将pigsty虚拟机节点的ssh配置文件写入~/.ssh/pigsty_config。
通常该命令只需要在首次启动沙箱时执行一次,后续重新拉起的虚拟机通常会保有相同的SSH配置。
执行完毕后,用户才可以使用类似ssh node-1的方式通过SSH别名连接至沙箱内的虚拟机节点。
$ make ssh
cd vagrant && vagrant ssh-config > ~/.ssh/pigsty_config 2>/dev/null; true
if ! grep --quiet "pigsty_config" ~/.ssh/config ; then (echo 'Include ~/.ssh/pigsty_config' && cat ~/.ssh/config) > ~/.ssh/config.tmp; mv ~/.ssh/config.tmp ~/.ssh/config && chmod 0600 ~/.ssh/config; fi
if ! grep --quiet "StrictHostKeyChecking=no" ~/.ssh/config ; then (echo 'StrictHostKeyChecking=no' && cat ~/.ssh/config) > ~/.ssh/config.tmp; mv ~/.ssh/config.tmp ~/.ssh/config && chmod 0600 ~/.ssh/config; fi
dns
此命令将Pigsty沙箱虚拟机的静态DNS配置写入/etc/hosts,通常该命令只需要在首次启动沙箱时执行一次。
执行完毕后,用户才可以从本地浏览器使用域名访问 http://g.pigsty 等WebUI。
注意DNS命令需要SUDO权限执行,需要输入密码,因为/etc/hosts文件需要特权方可修改。
$ sudo make dns
Password: #<在此输入用户密码>
if ! grep --quiet "pigsty dns records" /etc/hosts ; then cat files/dns >> /etc/hosts; fi
download
从CDN下载最新的Pigsty离线安装包至本地,大小约1GB,约1分钟下载完成。
$ make download
curl http://pigsty-1304147732.cos.accelerate.myqcloud.com/pkg.tgz -o files/pkg.tgz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1067M 100 1067M 0 0 15.2M 0 0:01:10 0:01:10 --:--:-- 29.0M
Pigsty是一个复杂的软件系统,为了确保系统的稳定,Pigsty会在初始化过程中从互联网下载所有依赖的软件包并建立本地Yum源。
所有依赖的软件总大小约1GB左右,下载速度取决于您的网络情况。尽管Pigsty已经尽量使用镜像源以加速下载,但少量包的下载仍可能受到防火墙的阻挠,可能出现非常慢的情况。您可以通过proxy_env配置项设置下载代理以完成首次下载,或直接下载预先打包好的离线安装包。
最新的离线安装包地址为:
Github Release:https://github.com/Vonng/pigsty/releases
CDN Download:http://pigsty-1304147732.cos.accelerate.myqcloud.com/pkg.tgz
您也可以手工下载好后放置于files/pkg.tgz。
upload
将下载的离线安装包上传元节点并解压,加速后续初始化。
$ make upload
ssh -t meta "sudo rm -rf /tmp/pkg.tgz"
Connection to 127.0.0.1 closed.
scp -r files/pkg.tgz meta:/tmp/pkg.tgz
pkg.tgz 100% 1068MB 53.4MB/s 00:19
ssh -t meta "sudo mkdir -p /www/pigsty/; sudo rm -rf /www/pigsty/*; sudo tar -xf /tmp/pkg.tgz --strip-component=1 -C /www/pigsty/"
Connection to 127.0.0.1 closed.
init
完成上述操作后,执行make init即会调用ansible完成Pigsty系统的初始化。
$ make init
./sandbox.yml # 快速初始化,并行初始化元节点与普通数据库节点
sandbox.yml是专门为本地沙箱环境准备的初始化剧本,通过同时初始化元节点和数据库节点节省了一半时间。 生产环境建议使用infra.yml与pgsql.yml分别依次完成元节点与普通节点的初始化。
如果您已经将离线安装包上传至元节点,那么初始化环境会比较快,视机器配置可能总共需要5~10分钟不等。
若离线安装包不存在,那么Pigsty会在初始化过程中从互联网下载约1GB数据,视网络条件可能需要20分钟或更久。
$ make init
./sandbox.yml # interleave sandbox provisioning
[WARNING]: Invalid characters were found in group names but not replaced, use -vvvv to see details
PLAY [Init local repo] ***********************************************************************************************************************************************************************************
TASK [repo : Create local repo directory] ****************************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [repo : Backup & remove existing repos] *************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [repo : Add required upstream repos] ****************************************************************************************************************************************************************
[WARNING]: Using a variable for a task's 'args' is unsafe in some situations (see https://docs.ansible.com/ansible/devel/reference_appendices/faq.html#argsplat-unsafe)
changed: [10.10.10.10] => (item={'name': 'base', 'description': 'CentOS-$releasever - Base - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/os/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/os/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/os/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
changed: [10.10.10.10] => (item={'name': 'updates', 'description': 'CentOS-$releasever - Updates - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/updates/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/updates/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/updates/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
changed: [10.10.10.10] => (item={'name': 'extras', 'description': 'CentOS-$releasever - Extras - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/extras/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/extras/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/extras/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
changed: [10.10.10.10] => (item={'name': 'epel', 'description': 'CentOS $releasever - EPEL - Aliyun Mirror', 'baseurl': 'http://mirrors.aliyun.com/epel/$releasever/$basearch', 'gpgcheck': False, 'failovermethod': 'priority'})
changed: [10.10.10.10] => (item={'name': 'grafana', 'description': 'Grafana - TsingHua Mirror', 'gpgcheck': False, 'baseurl': 'https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm'})
changed: [10.10.10.10] => (item={'name': 'prometheus', 'description': 'Prometheus and exporters', 'gpgcheck': False, 'baseurl': 'https://packagecloud.io/prometheus-rpm/release/el/$releasever/$basearch'})
changed: [10.10.10.10] => (item={'name': 'pgdg-common', 'description': 'PostgreSQL common RPMs for RHEL/CentOS $releasever - $basearch', 'gpgcheck': False, 'baseurl': 'http://mirrors.zju.edu.cn/postgresql/repos/yum/common/redhat/rhel-$releasever-$basearch'})
changed: [10.10.10.10] => (item={'name': 'pgdg13', 'description': 'PostgreSQL 13 for RHEL/CentOS $releasever - $basearch', 'gpgcheck': False, 'baseurl': 'http://mirrors.zju.edu.cn/postgresql/repos/yum/13/redhat/rhel-$releasever-$basearch'})
changed: [10.10.10.10] => (item={'name': 'centos-sclo', 'description': 'CentOS-$releasever - SCLo', 'gpgcheck': False, 'mirrorlist': 'http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-sclo'})
changed: [10.10.10.10] => (item={'name': 'centos-sclo-rh', 'description': 'CentOS-$releasever - SCLo rh', 'gpgcheck': False, 'mirrorlist': 'http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-rh'})
changed: [10.10.10.10] => (item={'name': 'nginx', 'description': 'Nginx Official Yum Repo', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'http://nginx.org/packages/centos/$releasever/$basearch/'})
changed: [10.10.10.10] => (item={'name': 'haproxy', 'description': 'Copr repo for haproxy', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'https://download.copr.fedorainfracloud.org/results/roidelapluie/haproxy/epel-$releasever-$basearch/'})
changed: [10.10.10.10] => (item={'name': 'harbottle', 'description': 'Copr repo for main owned by harbottle', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'https://download.copr.fedorainfracloud.org/results/harbottle/main/epel-$releasever-$basearch/'})
TASK [repo : Check repo pkgs cache exists] ***************************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [repo : Set fact whether repo_exists] ***************************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [repo : Move upstream repo to backup] ***************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [repo : Add local file system repos] ****************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [repo : Remake yum cache if not exists] *************************************************************************************************************************************************************
[WARNING]: Consider using the yum module rather than running 'yum'. If you need to use command because yum is insufficient you can add 'warn: false' to this command task or set
'command_warnings=False' in ansible.cfg to get rid of this message.
changed: [10.10.10.10]
TASK [repo : Install repo bootstrap packages] ************************************************************************************************************************************************************
changed: [10.10.10.10] => (item=['yum-utils', 'createrepo', 'ansible', 'nginx', 'wget'])
TASK [repo : Render repo nginx server files] *************************************************************************************************************************************************************
changed: [10.10.10.10] => (item={'src': 'index.html.j2', 'dest': '/www/index.html'})
changed: [10.10.10.10] => (item={'src': 'default.conf.j2', 'dest': '/etc/nginx/conf.d/default.conf'})
changed: [10.10.10.10] => (item={'src': 'local.repo.j2', 'dest': '/www/pigsty.repo'})
changed: [10.10.10.10] => (item={'src': 'nginx.conf.j2', 'dest': '/etc/nginx/nginx.conf'})
TASK [repo : Disable selinux for repo server] ************************************************************************************************************************************************************
[WARNING]: SELinux state temporarily changed from 'enforcing' to 'permissive'. State change will take effect next reboot.
changed: [10.10.10.10]
TASK [repo : Launch repo nginx server] *******************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [repo : Waits repo server online] *******************************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [repo : Download web url packages] ******************************************************************************************************************************************************************
skipping: [10.10.10.10] => (item=https://github.com/Vonng/pg_exporter/releases/download/v0.3.2/pg_exporter-0.3.2-1.el7.x86_64.rpm)
skipping: [10.10.10.10] => (item=https://github.com/cybertec-postgresql/vip-manager/releases/download/v0.6/vip-manager_0.6-1_amd64.rpm)
skipping: [10.10.10.10] => (item=http://guichaz.free.fr/polysh/files/polysh-0.4-1.noarch.rpm)
TASK [repo : Download repo packages] *********************************************************************************************************************************************************************
skipping: [10.10.10.10] => (item=epel-release nginx wget yum-utils yum createrepo)
skipping: [10.10.10.10] => (item=ntp chrony uuid lz4 nc pv jq vim-enhanced make patch bash lsof wget unzip git tuned)
skipping: [10.10.10.10] => (item=readline zlib openssl libyaml libxml2 libxslt perl-ExtUtils-Embed ca-certificates)
skipping: [10.10.10.10] => (item=numactl grubby sysstat dstat iotop bind-utils net-tools tcpdump socat ipvsadm telnet)
skipping: [10.10.10.10] => (item=grafana prometheus2 pushgateway alertmanager)
skipping: [10.10.10.10] => (item=node_exporter postgres_exporter nginx_exporter blackbox_exporter)
skipping: [10.10.10.10] => (item=consul consul_exporter consul-template etcd)
skipping: [10.10.10.10] => (item=ansible python python-pip python-psycopg2 audit)
skipping: [10.10.10.10] => (item=python3 python3-psycopg2 python36-requests python3-etcd python3-consul)
skipping: [10.10.10.10] => (item=python36-urllib3 python36-idna python36-pyOpenSSL python36-cryptography)
skipping: [10.10.10.10] => (item=haproxy keepalived dnsmasq)
skipping: [10.10.10.10] => (item=patroni patroni-consul patroni-etcd pgbouncer pg_cli pgbadger pg_activity)
skipping: [10.10.10.10] => (item=pgcenter boxinfo check_postgres emaj pgbconsole pg_bloat_check pgquarrel)
skipping: [10.10.10.10] => (item=barman barman-cli pgloader pgFormatter pitrery pspg pgxnclient PyGreSQL pgadmin4 tail_n_mail)
skipping: [10.10.10.10] => (item=postgresql13* postgis31* citus_13 timescaledb_13)
skipping: [10.10.10.10] => (item=pg_repack13 pg_squeeze13)
skipping: [10.10.10.10] => (item=pg_qualstats13 pg_stat_kcache13 system_stats_13 bgw_replstatus13)
skipping: [10.10.10.10] => (item=plr13 plsh13 plpgsql_check_13 plproxy13 plr13 plsh13 plpgsql_check_13 pldebugger13)
skipping: [10.10.10.10] => (item=hdfs_fdw_13 mongo_fdw13 mysql_fdw_13 ogr_fdw13 redis_fdw_13 pgbouncer_fdw13)
skipping: [10.10.10.10] => (item=wal2json13 count_distinct13 ddlx_13 geoip13 orafce13)
skipping: [10.10.10.10] => (item=rum_13 hypopg_13 ip4r13 jsquery_13 logerrors_13 periods_13 pg_auto_failover_13 pg_catcheck13)
skipping: [10.10.10.10] => (item=pg_fkpart13 pg_jobmon13 pg_partman13 pg_prioritize_13 pg_track_settings13 pgaudit15_13)
skipping: [10.10.10.10] => (item=pgcryptokey13 pgexportdoc13 pgimportdoc13 pgmemcache-13 pgmp13 pgq-13)
skipping: [10.10.10.10] => (item=pguint13 pguri13 prefix13 safeupdate_13 semver13 table_version13 tdigest13)
TASK [repo : Download repo pkg deps] *********************************************************************************************************************************************************************
skipping: [10.10.10.10] => (item=epel-release nginx wget yum-utils yum createrepo)
skipping: [10.10.10.10] => (item=ntp chrony uuid lz4 nc pv jq vim-enhanced make patch bash lsof wget unzip git tuned)
skipping: [10.10.10.10] => (item=readline zlib openssl libyaml libxml2 libxslt perl-ExtUtils-Embed ca-certificates)
skipping: [10.10.10.10] => (item=numactl grubby sysstat dstat iotop bind-utils net-tools tcpdump socat ipvsadm telnet)
skipping: [10.10.10.10] => (item=grafana prometheus2 pushgateway alertmanager)
skipping: [10.10.10.10] => (item=node_exporter postgres_exporter nginx_exporter blackbox_exporter)
skipping: [10.10.10.10] => (item=consul consul_exporter consul-template etcd)
skipping: [10.10.10.10] => (item=ansible python python-pip python-psycopg2 audit)
skipping: [10.10.10.10] => (item=python3 python3-psycopg2 python36-requests python3-etcd python3-consul)
skipping: [10.10.10.10] => (item=python36-urllib3 python36-idna python36-pyOpenSSL python36-cryptography)
skipping: [10.10.10.10] => (item=haproxy keepalived dnsmasq)
skipping: [10.10.10.10] => (item=patroni patroni-consul patroni-etcd pgbouncer pg_cli pgbadger pg_activity)
skipping: [10.10.10.10] => (item=pgcenter boxinfo check_postgres emaj pgbconsole pg_bloat_check pgquarrel)
skipping: [10.10.10.10] => (item=barman barman-cli pgloader pgFormatter pitrery pspg pgxnclient PyGreSQL pgadmin4 tail_n_mail)
skipping: [10.10.10.10] => (item=postgresql13* postgis31* citus_13 timescaledb_13)
skipping: [10.10.10.10] => (item=pg_repack13 pg_squeeze13)
skipping: [10.10.10.10] => (item=pg_qualstats13 pg_stat_kcache13 system_stats_13 bgw_replstatus13)
skipping: [10.10.10.10] => (item=plr13 plsh13 plpgsql_check_13 plproxy13 plr13 plsh13 plpgsql_check_13 pldebugger13)
skipping: [10.10.10.10] => (item=hdfs_fdw_13 mongo_fdw13 mysql_fdw_13 ogr_fdw13 redis_fdw_13 pgbouncer_fdw13)
skipping: [10.10.10.10] => (item=wal2json13 count_distinct13 ddlx_13 geoip13 orafce13)
skipping: [10.10.10.10] => (item=rum_13 hypopg_13 ip4r13 jsquery_13 logerrors_13 periods_13 pg_auto_failover_13 pg_catcheck13)
skipping: [10.10.10.10] => (item=pg_fkpart13 pg_jobmon13 pg_partman13 pg_prioritize_13 pg_track_settings13 pgaudit15_13)
skipping: [10.10.10.10] => (item=pgcryptokey13 pgexportdoc13 pgimportdoc13 pgmemcache-13 pgmp13 pgq-13)
skipping: [10.10.10.10] => (item=pguint13 pguri13 prefix13 safeupdate_13 semver13 table_version13 tdigest13)
TASK [repo : Create local repo index] ********************************************************************************************************************************************************************
skipping: [10.10.10.10]
TASK [repo : Copy bootstrap scripts] *********************************************************************************************************************************************************************
skipping: [10.10.10.10]
TASK [repo : Mark repo cache as valid] *******************************************************************************************************************************************************************
skipping: [10.10.10.10]
PLAY [Provision Node] ************************************************************************************************************************************************************************************
TASK [node : Update node hostname] ***********************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [node : Add new hostname to /etc/hosts] *************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [node : Write static dns records] *******************************************************************************************************************************************************************
changed: [10.10.10.10] => (item=10.10.10.10 yum.pigsty)
changed: [10.10.10.11] => (item=10.10.10.10 yum.pigsty)
changed: [10.10.10.13] => (item=10.10.10.10 yum.pigsty)
changed: [10.10.10.12] => (item=10.10.10.10 yum.pigsty)
TASK [node : Get old nameservers] ************************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [node : Truncate resolv file] ***********************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [node : Write resolv options] ***********************************************************************************************************************************************************************
changed: [10.10.10.11] => (item=options single-request-reopen timeout:1 rotate)
changed: [10.10.10.12] => (item=options single-request-reopen timeout:1 rotate)
changed: [10.10.10.10] => (item=options single-request-reopen timeout:1 rotate)
changed: [10.10.10.13] => (item=options single-request-reopen timeout:1 rotate)
changed: [10.10.10.11] => (item=domain service.consul)
changed: [10.10.10.12] => (item=domain service.consul)
changed: [10.10.10.13] => (item=domain service.consul)
changed: [10.10.10.10] => (item=domain service.consul)
TASK [node : Add new nameservers] ************************************************************************************************************************************************************************
changed: [10.10.10.11] => (item=10.10.10.10)
changed: [10.10.10.12] => (item=10.10.10.10)
changed: [10.10.10.10] => (item=10.10.10.10)
changed: [10.10.10.13] => (item=10.10.10.10)
TASK [node : Append old nameservers] *********************************************************************************************************************************************************************
changed: [10.10.10.11] => (item=10.0.2.3)
changed: [10.10.10.12] => (item=10.0.2.3)
changed: [10.10.10.10] => (item=10.0.2.3)
changed: [10.10.10.13] => (item=10.0.2.3)
TASK [node : Node configure disable firewall] ************************************************************************************************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.10]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [node : Node disable selinux by default] ************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
[WARNING]: SELinux state change will take effect next reboot
ok: [10.10.10.10]
TASK [node : Backup existing repos] **********************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [node : Install upstream repo] **********************************************************************************************************************************************************************
skipping: [10.10.10.10] => (item={'name': 'base', 'description': 'CentOS-$releasever - Base - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/os/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/os/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/os/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.10] => (item={'name': 'updates', 'description': 'CentOS-$releasever - Updates - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/updates/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/updates/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/updates/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.11] => (item={'name': 'base', 'description': 'CentOS-$releasever - Base - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/os/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/os/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/os/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.10] => (item={'name': 'extras', 'description': 'CentOS-$releasever - Extras - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/extras/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/extras/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/extras/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.11] => (item={'name': 'updates', 'description': 'CentOS-$releasever - Updates - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/updates/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/updates/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/updates/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.10] => (item={'name': 'epel', 'description': 'CentOS $releasever - EPEL - Aliyun Mirror', 'baseurl': 'http://mirrors.aliyun.com/epel/$releasever/$basearch', 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.12] => (item={'name': 'base', 'description': 'CentOS-$releasever - Base - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/os/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/os/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/os/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.11] => (item={'name': 'extras', 'description': 'CentOS-$releasever - Extras - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/extras/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/extras/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/extras/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.10] => (item={'name': 'grafana', 'description': 'Grafana - TsingHua Mirror', 'gpgcheck': False, 'baseurl': 'https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm'})
skipping: [10.10.10.12] => (item={'name': 'updates', 'description': 'CentOS-$releasever - Updates - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/updates/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/updates/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/updates/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.11] => (item={'name': 'epel', 'description': 'CentOS $releasever - EPEL - Aliyun Mirror', 'baseurl': 'http://mirrors.aliyun.com/epel/$releasever/$basearch', 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.13] => (item={'name': 'base', 'description': 'CentOS-$releasever - Base - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/os/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/os/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/os/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.12] => (item={'name': 'extras', 'description': 'CentOS-$releasever - Extras - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/extras/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/extras/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/extras/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.11] => (item={'name': 'grafana', 'description': 'Grafana - TsingHua Mirror', 'gpgcheck': False, 'baseurl': 'https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm'})
skipping: [10.10.10.13] => (item={'name': 'updates', 'description': 'CentOS-$releasever - Updates - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/updates/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/updates/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/updates/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.12] => (item={'name': 'epel', 'description': 'CentOS $releasever - EPEL - Aliyun Mirror', 'baseurl': 'http://mirrors.aliyun.com/epel/$releasever/$basearch', 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.13] => (item={'name': 'extras', 'description': 'CentOS-$releasever - Extras - Aliyun Mirror', 'baseurl': ['http://mirrors.aliyun.com/centos/$releasever/extras/$basearch/', 'http://mirrors.aliyuncs.com/centos/$releasever/extras/$basearch/', 'http://mirrors.cloud.aliyuncs.com/centos/$releasever/extras/$basearch/'], 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.12] => (item={'name': 'grafana', 'description': 'Grafana - TsingHua Mirror', 'gpgcheck': False, 'baseurl': 'https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm'})
skipping: [10.10.10.13] => (item={'name': 'epel', 'description': 'CentOS $releasever - EPEL - Aliyun Mirror', 'baseurl': 'http://mirrors.aliyun.com/epel/$releasever/$basearch', 'gpgcheck': False, 'failovermethod': 'priority'})
skipping: [10.10.10.13] => (item={'name': 'grafana', 'description': 'Grafana - TsingHua Mirror', 'gpgcheck': False, 'baseurl': 'https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm'})
skipping: [10.10.10.10] => (item={'name': 'prometheus', 'description': 'Prometheus and exporters', 'gpgcheck': False, 'baseurl': 'https://packagecloud.io/prometheus-rpm/release/el/$releasever/$basearch'})
skipping: [10.10.10.10] => (item={'name': 'pgdg-common', 'description': 'PostgreSQL common RPMs for RHEL/CentOS $releasever - $basearch', 'gpgcheck': False, 'baseurl': 'http://mirrors.zju.edu.cn/postgresql/repos/yum/common/redhat/rhel-$releasever-$basearch'})
skipping: [10.10.10.11] => (item={'name': 'prometheus', 'description': 'Prometheus and exporters', 'gpgcheck': False, 'baseurl': 'https://packagecloud.io/prometheus-rpm/release/el/$releasever/$basearch'})
skipping: [10.10.10.10] => (item={'name': 'pgdg13', 'description': 'PostgreSQL 13 for RHEL/CentOS $releasever - $basearch', 'gpgcheck': False, 'baseurl': 'http://mirrors.zju.edu.cn/postgresql/repos/yum/13/redhat/rhel-$releasever-$basearch'})
skipping: [10.10.10.11] => (item={'name': 'pgdg-common', 'description': 'PostgreSQL common RPMs for RHEL/CentOS $releasever - $basearch', 'gpgcheck': False, 'baseurl': 'http://mirrors.zju.edu.cn/postgresql/repos/yum/common/redhat/rhel-$releasever-$basearch'})
skipping: [10.10.10.12] => (item={'name': 'prometheus', 'description': 'Prometheus and exporters', 'gpgcheck': False, 'baseurl': 'https://packagecloud.io/prometheus-rpm/release/el/$releasever/$basearch'})
skipping: [10.10.10.10] => (item={'name': 'centos-sclo', 'description': 'CentOS-$releasever - SCLo', 'gpgcheck': False, 'mirrorlist': 'http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-sclo'})
skipping: [10.10.10.11] => (item={'name': 'pgdg13', 'description': 'PostgreSQL 13 for RHEL/CentOS $releasever - $basearch', 'gpgcheck': False, 'baseurl': 'http://mirrors.zju.edu.cn/postgresql/repos/yum/13/redhat/rhel-$releasever-$basearch'})
skipping: [10.10.10.12] => (item={'name': 'pgdg-common', 'description': 'PostgreSQL common RPMs for RHEL/CentOS $releasever - $basearch', 'gpgcheck': False, 'baseurl': 'http://mirrors.zju.edu.cn/postgresql/repos/yum/common/redhat/rhel-$releasever-$basearch'})
skipping: [10.10.10.10] => (item={'name': 'centos-sclo-rh', 'description': 'CentOS-$releasever - SCLo rh', 'gpgcheck': False, 'mirrorlist': 'http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-rh'})
skipping: [10.10.10.11] => (item={'name': 'centos-sclo', 'description': 'CentOS-$releasever - SCLo', 'gpgcheck': False, 'mirrorlist': 'http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-sclo'})
skipping: [10.10.10.12] => (item={'name': 'pgdg13', 'description': 'PostgreSQL 13 for RHEL/CentOS $releasever - $basearch', 'gpgcheck': False, 'baseurl': 'http://mirrors.zju.edu.cn/postgresql/repos/yum/13/redhat/rhel-$releasever-$basearch'})
skipping: [10.10.10.10] => (item={'name': 'nginx', 'description': 'Nginx Official Yum Repo', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'http://nginx.org/packages/centos/$releasever/$basearch/'})
skipping: [10.10.10.13] => (item={'name': 'prometheus', 'description': 'Prometheus and exporters', 'gpgcheck': False, 'baseurl': 'https://packagecloud.io/prometheus-rpm/release/el/$releasever/$basearch'})
skipping: [10.10.10.11] => (item={'name': 'centos-sclo-rh', 'description': 'CentOS-$releasever - SCLo rh', 'gpgcheck': False, 'mirrorlist': 'http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-rh'})
skipping: [10.10.10.12] => (item={'name': 'centos-sclo', 'description': 'CentOS-$releasever - SCLo', 'gpgcheck': False, 'mirrorlist': 'http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-sclo'})
skipping: [10.10.10.13] => (item={'name': 'pgdg-common', 'description': 'PostgreSQL common RPMs for RHEL/CentOS $releasever - $basearch', 'gpgcheck': False, 'baseurl': 'http://mirrors.zju.edu.cn/postgresql/repos/yum/common/redhat/rhel-$releasever-$basearch'})
skipping: [10.10.10.10] => (item={'name': 'haproxy', 'description': 'Copr repo for haproxy', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'https://download.copr.fedorainfracloud.org/results/roidelapluie/haproxy/epel-$releasever-$basearch/'})
skipping: [10.10.10.11] => (item={'name': 'nginx', 'description': 'Nginx Official Yum Repo', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'http://nginx.org/packages/centos/$releasever/$basearch/'})
skipping: [10.10.10.12] => (item={'name': 'centos-sclo-rh', 'description': 'CentOS-$releasever - SCLo rh', 'gpgcheck': False, 'mirrorlist': 'http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-rh'})
skipping: [10.10.10.10] => (item={'name': 'harbottle', 'description': 'Copr repo for main owned by harbottle', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'https://download.copr.fedorainfracloud.org/results/harbottle/main/epel-$releasever-$basearch/'})
skipping: [10.10.10.13] => (item={'name': 'pgdg13', 'description': 'PostgreSQL 13 for RHEL/CentOS $releasever - $basearch', 'gpgcheck': False, 'baseurl': 'http://mirrors.zju.edu.cn/postgresql/repos/yum/13/redhat/rhel-$releasever-$basearch'})
skipping: [10.10.10.11] => (item={'name': 'haproxy', 'description': 'Copr repo for haproxy', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'https://download.copr.fedorainfracloud.org/results/roidelapluie/haproxy/epel-$releasever-$basearch/'})
skipping: [10.10.10.12] => (item={'name': 'nginx', 'description': 'Nginx Official Yum Repo', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'http://nginx.org/packages/centos/$releasever/$basearch/'})
skipping: [10.10.10.13] => (item={'name': 'centos-sclo', 'description': 'CentOS-$releasever - SCLo', 'gpgcheck': False, 'mirrorlist': 'http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-sclo'})
skipping: [10.10.10.11] => (item={'name': 'harbottle', 'description': 'Copr repo for main owned by harbottle', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'https://download.copr.fedorainfracloud.org/results/harbottle/main/epel-$releasever-$basearch/'})
skipping: [10.10.10.12] => (item={'name': 'haproxy', 'description': 'Copr repo for haproxy', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'https://download.copr.fedorainfracloud.org/results/roidelapluie/haproxy/epel-$releasever-$basearch/'})
skipping: [10.10.10.13] => (item={'name': 'centos-sclo-rh', 'description': 'CentOS-$releasever - SCLo rh', 'gpgcheck': False, 'mirrorlist': 'http://mirrorlist.centos.org?arch=$basearch&release=7&repo=sclo-rh'})
skipping: [10.10.10.12] => (item={'name': 'harbottle', 'description': 'Copr repo for main owned by harbottle', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'https://download.copr.fedorainfracloud.org/results/harbottle/main/epel-$releasever-$basearch/'})
skipping: [10.10.10.13] => (item={'name': 'nginx', 'description': 'Nginx Official Yum Repo', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'http://nginx.org/packages/centos/$releasever/$basearch/'})
skipping: [10.10.10.13] => (item={'name': 'haproxy', 'description': 'Copr repo for haproxy', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'https://download.copr.fedorainfracloud.org/results/roidelapluie/haproxy/epel-$releasever-$basearch/'})
skipping: [10.10.10.13] => (item={'name': 'harbottle', 'description': 'Copr repo for main owned by harbottle', 'skip_if_unavailable': True, 'gpgcheck': False, 'baseurl': 'https://download.copr.fedorainfracloud.org/results/harbottle/main/epel-$releasever-$basearch/'})
TASK [node : Install local repo] *************************************************************************************************************************************************************************
changed: [10.10.10.13] => (item=http://yum.pigsty/pigsty.repo)
changed: [10.10.10.12] => (item=http://yum.pigsty/pigsty.repo)
changed: [10.10.10.11] => (item=http://yum.pigsty/pigsty.repo)
changed: [10.10.10.10] => (item=http://yum.pigsty/pigsty.repo)
TASK [node : Install node basic packages] ****************************************************************************************************************************************************************
skipping: [10.10.10.10] => (item=[])
skipping: [10.10.10.11] => (item=[])
skipping: [10.10.10.12] => (item=[])
skipping: [10.10.10.13] => (item=[])
TASK [node : Install node extra packages] ****************************************************************************************************************************************************************
skipping: [10.10.10.10] => (item=[])
skipping: [10.10.10.11] => (item=[])
skipping: [10.10.10.12] => (item=[])
skipping: [10.10.10.13] => (item=[])
TASK [node : Install meta specific packages] *************************************************************************************************************************************************************
skipping: [10.10.10.10] => (item=[])
skipping: [10.10.10.11] => (item=[])
skipping: [10.10.10.12] => (item=[])
skipping: [10.10.10.13] => (item=[])
TASK [node : Install node basic packages] ****************************************************************************************************************************************************************
changed: [10.10.10.10] => (item=['wget,yum-utils,ntp,chrony,tuned,uuid,lz4,vim-minimal,make,patch,bash,lsof,wget,unzip,git,readline,zlib,openssl', 'numactl,grubby,sysstat,dstat,iotop,bind-utils,net-tools,tcpdump,socat,ipvsadm,telnet,tuned,pv,jq', 'python3,python3-psycopg2,python36-requests,python3-etcd,python3-consul', 'python36-urllib3,python36-idna,python36-pyOpenSSL,python36-cryptography', 'node_exporter,consul,consul-template,etcd,haproxy,keepalived,vip-manager'])
changed: [10.10.10.13] => (item=['wget,yum-utils,ntp,chrony,tuned,uuid,lz4,vim-minimal,make,patch,bash,lsof,wget,unzip,git,readline,zlib,openssl', 'numactl,grubby,sysstat,dstat,iotop,bind-utils,net-tools,tcpdump,socat,ipvsadm,telnet,tuned,pv,jq', 'python3,python3-psycopg2,python36-requests,python3-etcd,python3-consul', 'python36-urllib3,python36-idna,python36-pyOpenSSL,python36-cryptography', 'node_exporter,consul,consul-template,etcd,haproxy,keepalived,vip-manager'])
changed: [10.10.10.11] => (item=['wget,yum-utils,ntp,chrony,tuned,uuid,lz4,vim-minimal,make,patch,bash,lsof,wget,unzip,git,readline,zlib,openssl', 'numactl,grubby,sysstat,dstat,iotop,bind-utils,net-tools,tcpdump,socat,ipvsadm,telnet,tuned,pv,jq', 'python3,python3-psycopg2,python36-requests,python3-etcd,python3-consul', 'python36-urllib3,python36-idna,python36-pyOpenSSL,python36-cryptography', 'node_exporter,consul,consul-template,etcd,haproxy,keepalived,vip-manager'])
changed: [10.10.10.12] => (item=['wget,yum-utils,ntp,chrony,tuned,uuid,lz4,vim-minimal,make,patch,bash,lsof,wget,unzip,git,readline,zlib,openssl', 'numactl,grubby,sysstat,dstat,iotop,bind-utils,net-tools,tcpdump,socat,ipvsadm,telnet,tuned,pv,jq', 'python3,python3-psycopg2,python36-requests,python3-etcd,python3-consul', 'python36-urllib3,python36-idna,python36-pyOpenSSL,python36-cryptography', 'node_exporter,consul,consul-template,etcd,haproxy,keepalived,vip-manager'])
TASK [node : Install node extra packages] ****************************************************************************************************************************************************************
changed: [10.10.10.11] => (item=['patroni,patroni-consul,patroni-etcd,pgbouncer,pgbadger,pg_activity'])
changed: [10.10.10.12] => (item=['patroni,patroni-consul,patroni-etcd,pgbouncer,pgbadger,pg_activity'])
changed: [10.10.10.13] => (item=['patroni,patroni-consul,patroni-etcd,pgbouncer,pgbadger,pg_activity'])
changed: [10.10.10.10] => (item=['patroni,patroni-consul,patroni-etcd,pgbouncer,pgbadger,pg_activity'])
TASK [node : Install meta specific packages] *************************************************************************************************************************************************************
skipping: [10.10.10.11] => (item=[])
skipping: [10.10.10.12] => (item=[])
skipping: [10.10.10.13] => (item=[])
changed: [10.10.10.10] => (item=['grafana,prometheus2,alertmanager,nginx_exporter,blackbox_exporter,pushgateway', 'dnsmasq,nginx,ansible,pgbadger,polysh'])
TASK [node : Node configure disable numa] ****************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [node : Node configure disable swap] ****************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [node : Node configure unmount swap] ****************************************************************************************************************************************************************
skipping: [10.10.10.10] => (item=swap)
skipping: [10.10.10.10] => (item=none)
skipping: [10.10.10.11] => (item=swap)
skipping: [10.10.10.11] => (item=none)
skipping: [10.10.10.12] => (item=swap)
skipping: [10.10.10.12] => (item=none)
skipping: [10.10.10.13] => (item=swap)
skipping: [10.10.10.13] => (item=none)
TASK [node : Node setup static network] ******************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.10]
TASK [node : Node configure disable firewall] ************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.10]
changed: [10.10.10.13]
TASK [node : Node configure disk prefetch] ***************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [node : Enable linux kernel modules] ****************************************************************************************************************************************************************
changed: [10.10.10.13] => (item=softdog)
changed: [10.10.10.12] => (item=softdog)
changed: [10.10.10.11] => (item=softdog)
changed: [10.10.10.10] => (item=softdog)
changed: [10.10.10.13] => (item=br_netfilter)
changed: [10.10.10.12] => (item=br_netfilter)
changed: [10.10.10.11] => (item=br_netfilter)
changed: [10.10.10.10] => (item=br_netfilter)
changed: [10.10.10.12] => (item=ip_vs)
changed: [10.10.10.13] => (item=ip_vs)
changed: [10.10.10.11] => (item=ip_vs)
changed: [10.10.10.10] => (item=ip_vs)
changed: [10.10.10.13] => (item=ip_vs_rr)
changed: [10.10.10.12] => (item=ip_vs_rr)
changed: [10.10.10.11] => (item=ip_vs_rr)
changed: [10.10.10.10] => (item=ip_vs_rr)
ok: [10.10.10.13] => (item=ip_vs_rr)
ok: [10.10.10.12] => (item=ip_vs_rr)
ok: [10.10.10.11] => (item=ip_vs_rr)
ok: [10.10.10.10] => (item=ip_vs_rr)
changed: [10.10.10.13] => (item=ip_vs_wrr)
changed: [10.10.10.12] => (item=ip_vs_wrr)
changed: [10.10.10.11] => (item=ip_vs_wrr)
changed: [10.10.10.10] => (item=ip_vs_wrr)
changed: [10.10.10.13] => (item=ip_vs_sh)
changed: [10.10.10.12] => (item=ip_vs_sh)
changed: [10.10.10.11] => (item=ip_vs_sh)
changed: [10.10.10.10] => (item=ip_vs_sh)
changed: [10.10.10.13] => (item=nf_conntrack_ipv4)
changed: [10.10.10.12] => (item=nf_conntrack_ipv4)
changed: [10.10.10.11] => (item=nf_conntrack_ipv4)
changed: [10.10.10.10] => (item=nf_conntrack_ipv4)
TASK [node : Enable kernel module on reboot] *************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
changed: [10.10.10.10]
TASK [node : Get config parameter page count] ************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [node : Get config parameter page size] *************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [node : Tune shmmax and shmall via mem] *************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [node : Create tuned profiles] **********************************************************************************************************************************************************************
changed: [10.10.10.11] => (item=oltp)
changed: [10.10.10.12] => (item=oltp)
changed: [10.10.10.10] => (item=oltp)
changed: [10.10.10.13] => (item=oltp)
changed: [10.10.10.11] => (item=olap)
changed: [10.10.10.12] => (item=olap)
changed: [10.10.10.13] => (item=olap)
changed: [10.10.10.10] => (item=olap)
changed: [10.10.10.11] => (item=crit)
changed: [10.10.10.12] => (item=crit)
changed: [10.10.10.13] => (item=crit)
changed: [10.10.10.10] => (item=crit)
changed: [10.10.10.11] => (item=tiny)
changed: [10.10.10.12] => (item=tiny)
changed: [10.10.10.13] => (item=tiny)
changed: [10.10.10.10] => (item=tiny)
TASK [node : Render tuned profiles] **********************************************************************************************************************************************************************
changed: [10.10.10.11] => (item=oltp)
changed: [10.10.10.12] => (item=oltp)
changed: [10.10.10.13] => (item=oltp)
changed: [10.10.10.10] => (item=oltp)
changed: [10.10.10.12] => (item=olap)
changed: [10.10.10.11] => (item=olap)
changed: [10.10.10.13] => (item=olap)
changed: [10.10.10.10] => (item=olap)
changed: [10.10.10.12] => (item=crit)
changed: [10.10.10.11] => (item=crit)
changed: [10.10.10.13] => (item=crit)
changed: [10.10.10.10] => (item=crit)
changed: [10.10.10.11] => (item=tiny)
changed: [10.10.10.12] => (item=tiny)
changed: [10.10.10.13] => (item=tiny)
changed: [10.10.10.10] => (item=tiny)
TASK [node : Active tuned profile] ***********************************************************************************************************************************************************************
changed: [10.10.10.13]
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.11]
TASK [node : Change additional sysctl params] ************************************************************************************************************************************************************
changed: [10.10.10.13] => (item={'key': 'net.bridge.bridge-nf-call-iptables', 'value': 1})
changed: [10.10.10.12] => (item={'key': 'net.bridge.bridge-nf-call-iptables', 'value': 1})
changed: [10.10.10.11] => (item={'key': 'net.bridge.bridge-nf-call-iptables', 'value': 1})
changed: [10.10.10.10] => (item={'key': 'net.bridge.bridge-nf-call-iptables', 'value': 1})
TASK [node : Copy default user bash profile] *************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.10]
TASK [node : Setup node default pam ulimits] *************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.10]
TASK [node : Create os user group admin] *****************************************************************************************************************************************************************
changed: [10.10.10.12]
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.10]
TASK [node : Create os user admin] ***********************************************************************************************************************************************************************
changed: [10.10.10.13]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.10]
TASK [node : Grant admin group nopass sudo] **************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.10]
TASK [node : Add no host checking to ssh config] *********************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.10]
TASK [node : Add admin ssh no host checking] *************************************************************************************************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.10]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [node : Fetch all admin public keys] ****************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.10]
changed: [10.10.10.13]
TASK [node : Exchange all admin ssh keys] ****************************************************************************************************************************************************************
changed: [10.10.10.10 -> meta] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDfXbkp7ATV3rIzcpCwxcwpumIjnjldzDp9qfu65d4W5gSNumN/wvOORnG17rB2y/msyjstu1C42v2V60yho/XjPNIqqPWPtM/bc6MHNeNJJxvEEtDsY530z3n37QTcVI1kg3zRqnzm8HDKEE+BAll+iyXjzTFoGHc39syDRF8r5sZpG0qiNY2QaqEnByASsoHM4RQ3Jw2D2SbA78wFBz1zqsdz5VympAcc9wcfuUqhwk0ExL+AtrPNUeyEXwgRr1Br6JXVHjT6EHLsZburTD7uT94Jqzixd3LXRwsmuCrPIssASrYvfnWVQ29MxhiZqrmLcwp4ImjQetcZE2EgfzEp ansible-generated on meta', '10.10.10.10'])
changed: [10.10.10.13 -> meta] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDbkD6WQhs9KAv9HTYtZ+q2Nfxqhj72YbP16m0mTrEOS2evd4MWDBhVgAE6qK4gvAhVBdEdNaHc3f2W/wDpKvvbvCbwy+HZldUCTVUe1W3sycm1ZwP7m9Xr7Rg0Dd1Nom87CWsqmlmN6afPYyvJV3wCl4ZuqrAMQ5oCrR4D1B8yZBL7rj55JpzggnNJYv7+ueIeUYoPzE6mu32k9wPxEa2qXcdVelgL7dwjTAt1nsNukWAufuAI1nZcJahsNjj1B2XEEwgA1mHUzDPpemn5alCNeCb+Hdb0Y12No/Wo2Gcn3b5vh9pOamLCm3CGrrsAXZ2B8tQPGFObhGkSOB6pddkT ansible-generated on node-3', '10.10.10.10'])
changed: [10.10.10.12 -> meta] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC3IAopnkVwQ779/Hk5MceAVZbhb/y3YaUu7ZROI87TaY/XK5WKJjplfNlLBC2vXGNkYMirbW+Qmmz/XIsyL7qvKmQfcMGP3ILD4FtMMlJMWLwBTIw5ORxvoZGxaWfw0bcZSIw5rv9rBA4UJR9JfZhpUkBMj7cq8jNDyIrLpoJ+hlnJa5G5zyiMWBqe7VKOoiBo7d2WBIauhRgHY3G79H9pVxJti6JJOeQ1tsUI5UtOMCRO+dbmsuRWruac4jWOj864RG/EjFveWEfCTagMFakqaxPTgF3RHAwPVBjbMm3+2lBiVNd2Zt2g/2gPdkEbIE+xXXP/f5kh21gXFea4ENsV ansible-generated on node-2', '10.10.10.10'])
changed: [10.10.10.11 -> meta] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC2TJItJzBUEZ452k7ADL6mIQsGk7gb4AUqvN0pAHwR06pVv1XUmpCI5Wb0RUOoNFwmSBVTUXoXCnK7SB44ftpzD29cpxw3tlLEphYeY1wfrd2lblhpn2KxzBhyJZ27lK2qcZk7Ik20pZDhQZRuZuhb6HufYn7FGOutB8kgQChrcpqr9zRhjZOe4Y8tLR2lmEAVrp6ZsS04rjiBJ65TDCWCNSnin8DVbM1EerJ6Pvxy1cOY+B00EYMHlMni/3orzcrlnZqpkR/NRpgs9+lo+DZ4SCuEtIEOzpPzcm/O4oLhxSnTMJKTFwcc+bgmE0t1LMxvIKOQTwhIX+KoBE/syxh9 ansible-generated on node-1', '10.10.10.10'])
changed: [10.10.10.10 -> node-1] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDfXbkp7ATV3rIzcpCwxcwpumIjnjldzDp9qfu65d4W5gSNumN/wvOORnG17rB2y/msyjstu1C42v2V60yho/XjPNIqqPWPtM/bc6MHNeNJJxvEEtDsY530z3n37QTcVI1kg3zRqnzm8HDKEE+BAll+iyXjzTFoGHc39syDRF8r5sZpG0qiNY2QaqEnByASsoHM4RQ3Jw2D2SbA78wFBz1zqsdz5VympAcc9wcfuUqhwk0ExL+AtrPNUeyEXwgRr1Br6JXVHjT6EHLsZburTD7uT94Jqzixd3LXRwsmuCrPIssASrYvfnWVQ29MxhiZqrmLcwp4ImjQetcZE2EgfzEp ansible-generated on meta', '10.10.10.11'])
changed: [10.10.10.12 -> node-1] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC3IAopnkVwQ779/Hk5MceAVZbhb/y3YaUu7ZROI87TaY/XK5WKJjplfNlLBC2vXGNkYMirbW+Qmmz/XIsyL7qvKmQfcMGP3ILD4FtMMlJMWLwBTIw5ORxvoZGxaWfw0bcZSIw5rv9rBA4UJR9JfZhpUkBMj7cq8jNDyIrLpoJ+hlnJa5G5zyiMWBqe7VKOoiBo7d2WBIauhRgHY3G79H9pVxJti6JJOeQ1tsUI5UtOMCRO+dbmsuRWruac4jWOj864RG/EjFveWEfCTagMFakqaxPTgF3RHAwPVBjbMm3+2lBiVNd2Zt2g/2gPdkEbIE+xXXP/f5kh21gXFea4ENsV ansible-generated on node-2', '10.10.10.11'])
changed: [10.10.10.13 -> node-1] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDbkD6WQhs9KAv9HTYtZ+q2Nfxqhj72YbP16m0mTrEOS2evd4MWDBhVgAE6qK4gvAhVBdEdNaHc3f2W/wDpKvvbvCbwy+HZldUCTVUe1W3sycm1ZwP7m9Xr7Rg0Dd1Nom87CWsqmlmN6afPYyvJV3wCl4ZuqrAMQ5oCrR4D1B8yZBL7rj55JpzggnNJYv7+ueIeUYoPzE6mu32k9wPxEa2qXcdVelgL7dwjTAt1nsNukWAufuAI1nZcJahsNjj1B2XEEwgA1mHUzDPpemn5alCNeCb+Hdb0Y12No/Wo2Gcn3b5vh9pOamLCm3CGrrsAXZ2B8tQPGFObhGkSOB6pddkT ansible-generated on node-3', '10.10.10.11'])
changed: [10.10.10.11 -> node-1] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC2TJItJzBUEZ452k7ADL6mIQsGk7gb4AUqvN0pAHwR06pVv1XUmpCI5Wb0RUOoNFwmSBVTUXoXCnK7SB44ftpzD29cpxw3tlLEphYeY1wfrd2lblhpn2KxzBhyJZ27lK2qcZk7Ik20pZDhQZRuZuhb6HufYn7FGOutB8kgQChrcpqr9zRhjZOe4Y8tLR2lmEAVrp6ZsS04rjiBJ65TDCWCNSnin8DVbM1EerJ6Pvxy1cOY+B00EYMHlMni/3orzcrlnZqpkR/NRpgs9+lo+DZ4SCuEtIEOzpPzcm/O4oLhxSnTMJKTFwcc+bgmE0t1LMxvIKOQTwhIX+KoBE/syxh9 ansible-generated on node-1', '10.10.10.11'])
changed: [10.10.10.10 -> node-2] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDfXbkp7ATV3rIzcpCwxcwpumIjnjldzDp9qfu65d4W5gSNumN/wvOORnG17rB2y/msyjstu1C42v2V60yho/XjPNIqqPWPtM/bc6MHNeNJJxvEEtDsY530z3n37QTcVI1kg3zRqnzm8HDKEE+BAll+iyXjzTFoGHc39syDRF8r5sZpG0qiNY2QaqEnByASsoHM4RQ3Jw2D2SbA78wFBz1zqsdz5VympAcc9wcfuUqhwk0ExL+AtrPNUeyEXwgRr1Br6JXVHjT6EHLsZburTD7uT94Jqzixd3LXRwsmuCrPIssASrYvfnWVQ29MxhiZqrmLcwp4ImjQetcZE2EgfzEp ansible-generated on meta', '10.10.10.12'])
changed: [10.10.10.13 -> node-2] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDbkD6WQhs9KAv9HTYtZ+q2Nfxqhj72YbP16m0mTrEOS2evd4MWDBhVgAE6qK4gvAhVBdEdNaHc3f2W/wDpKvvbvCbwy+HZldUCTVUe1W3sycm1ZwP7m9Xr7Rg0Dd1Nom87CWsqmlmN6afPYyvJV3wCl4ZuqrAMQ5oCrR4D1B8yZBL7rj55JpzggnNJYv7+ueIeUYoPzE6mu32k9wPxEa2qXcdVelgL7dwjTAt1nsNukWAufuAI1nZcJahsNjj1B2XEEwgA1mHUzDPpemn5alCNeCb+Hdb0Y12No/Wo2Gcn3b5vh9pOamLCm3CGrrsAXZ2B8tQPGFObhGkSOB6pddkT ansible-generated on node-3', '10.10.10.12'])
changed: [10.10.10.12 -> node-2] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC3IAopnkVwQ779/Hk5MceAVZbhb/y3YaUu7ZROI87TaY/XK5WKJjplfNlLBC2vXGNkYMirbW+Qmmz/XIsyL7qvKmQfcMGP3ILD4FtMMlJMWLwBTIw5ORxvoZGxaWfw0bcZSIw5rv9rBA4UJR9JfZhpUkBMj7cq8jNDyIrLpoJ+hlnJa5G5zyiMWBqe7VKOoiBo7d2WBIauhRgHY3G79H9pVxJti6JJOeQ1tsUI5UtOMCRO+dbmsuRWruac4jWOj864RG/EjFveWEfCTagMFakqaxPTgF3RHAwPVBjbMm3+2lBiVNd2Zt2g/2gPdkEbIE+xXXP/f5kh21gXFea4ENsV ansible-generated on node-2', '10.10.10.12'])
changed: [10.10.10.11 -> node-2] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC2TJItJzBUEZ452k7ADL6mIQsGk7gb4AUqvN0pAHwR06pVv1XUmpCI5Wb0RUOoNFwmSBVTUXoXCnK7SB44ftpzD29cpxw3tlLEphYeY1wfrd2lblhpn2KxzBhyJZ27lK2qcZk7Ik20pZDhQZRuZuhb6HufYn7FGOutB8kgQChrcpqr9zRhjZOe4Y8tLR2lmEAVrp6ZsS04rjiBJ65TDCWCNSnin8DVbM1EerJ6Pvxy1cOY+B00EYMHlMni/3orzcrlnZqpkR/NRpgs9+lo+DZ4SCuEtIEOzpPzcm/O4oLhxSnTMJKTFwcc+bgmE0t1LMxvIKOQTwhIX+KoBE/syxh9 ansible-generated on node-1', '10.10.10.12'])
changed: [10.10.10.10 -> node-3] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDfXbkp7ATV3rIzcpCwxcwpumIjnjldzDp9qfu65d4W5gSNumN/wvOORnG17rB2y/msyjstu1C42v2V60yho/XjPNIqqPWPtM/bc6MHNeNJJxvEEtDsY530z3n37QTcVI1kg3zRqnzm8HDKEE+BAll+iyXjzTFoGHc39syDRF8r5sZpG0qiNY2QaqEnByASsoHM4RQ3Jw2D2SbA78wFBz1zqsdz5VympAcc9wcfuUqhwk0ExL+AtrPNUeyEXwgRr1Br6JXVHjT6EHLsZburTD7uT94Jqzixd3LXRwsmuCrPIssASrYvfnWVQ29MxhiZqrmLcwp4ImjQetcZE2EgfzEp ansible-generated on meta', '10.10.10.13'])
changed: [10.10.10.13 -> node-3] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDbkD6WQhs9KAv9HTYtZ+q2Nfxqhj72YbP16m0mTrEOS2evd4MWDBhVgAE6qK4gvAhVBdEdNaHc3f2W/wDpKvvbvCbwy+HZldUCTVUe1W3sycm1ZwP7m9Xr7Rg0Dd1Nom87CWsqmlmN6afPYyvJV3wCl4ZuqrAMQ5oCrR4D1B8yZBL7rj55JpzggnNJYv7+ueIeUYoPzE6mu32k9wPxEa2qXcdVelgL7dwjTAt1nsNukWAufuAI1nZcJahsNjj1B2XEEwgA1mHUzDPpemn5alCNeCb+Hdb0Y12No/Wo2Gcn3b5vh9pOamLCm3CGrrsAXZ2B8tQPGFObhGkSOB6pddkT ansible-generated on node-3', '10.10.10.13'])
changed: [10.10.10.11 -> node-3] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC2TJItJzBUEZ452k7ADL6mIQsGk7gb4AUqvN0pAHwR06pVv1XUmpCI5Wb0RUOoNFwmSBVTUXoXCnK7SB44ftpzD29cpxw3tlLEphYeY1wfrd2lblhpn2KxzBhyJZ27lK2qcZk7Ik20pZDhQZRuZuhb6HufYn7FGOutB8kgQChrcpqr9zRhjZOe4Y8tLR2lmEAVrp6ZsS04rjiBJ65TDCWCNSnin8DVbM1EerJ6Pvxy1cOY+B00EYMHlMni/3orzcrlnZqpkR/NRpgs9+lo+DZ4SCuEtIEOzpPzcm/O4oLhxSnTMJKTFwcc+bgmE0t1LMxvIKOQTwhIX+KoBE/syxh9 ansible-generated on node-1', '10.10.10.13'])
changed: [10.10.10.12 -> node-3] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC3IAopnkVwQ779/Hk5MceAVZbhb/y3YaUu7ZROI87TaY/XK5WKJjplfNlLBC2vXGNkYMirbW+Qmmz/XIsyL7qvKmQfcMGP3ILD4FtMMlJMWLwBTIw5ORxvoZGxaWfw0bcZSIw5rv9rBA4UJR9JfZhpUkBMj7cq8jNDyIrLpoJ+hlnJa5G5zyiMWBqe7VKOoiBo7d2WBIauhRgHY3G79H9pVxJti6JJOeQ1tsUI5UtOMCRO+dbmsuRWruac4jWOj864RG/EjFveWEfCTagMFakqaxPTgF3RHAwPVBjbMm3+2lBiVNd2Zt2g/2gPdkEbIE+xXXP/f5kh21gXFea4ENsV ansible-generated on node-2', '10.10.10.13'])
TASK [node : Install public keys] ************************************************************************************************************************************************************************
changed: [10.10.10.11] => (item=ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAAAgQC7IMAMNavYtWwzAJajKqwdn3ar5BhvcwCnBTxxEkXhGlCO2vfgosSAQMEflfgvkiI5nM1HIFQ8KINlx1XLO7SdL5KdInG5LIJjAFh0pujS4kNCT9a5IGvSq1BrzGqhbEcwWYdju1ZPYBcJm/MG+JD0dYCh8vfrYB/cYMD0SOmNkQ== vagrant@pigsty.com)
changed: [10.10.10.10] => (item=ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAAAgQC7IMAMNavYtWwzAJajKqwdn3ar5BhvcwCnBTxxEkXhGlCO2vfgosSAQMEflfgvkiI5nM1HIFQ8KINlx1XLO7SdL5KdInG5LIJjAFh0pujS4kNCT9a5IGvSq1BrzGqhbEcwWYdju1ZPYBcJm/MG+JD0dYCh8vfrYB/cYMD0SOmNkQ== vagrant@pigsty.com)
changed: [10.10.10.12] => (item=ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAAAgQC7IMAMNavYtWwzAJajKqwdn3ar5BhvcwCnBTxxEkXhGlCO2vfgosSAQMEflfgvkiI5nM1HIFQ8KINlx1XLO7SdL5KdInG5LIJjAFh0pujS4kNCT9a5IGvSq1BrzGqhbEcwWYdju1ZPYBcJm/MG+JD0dYCh8vfrYB/cYMD0SOmNkQ== vagrant@pigsty.com)
changed: [10.10.10.13] => (item=ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAAAgQC7IMAMNavYtWwzAJajKqwdn3ar5BhvcwCnBTxxEkXhGlCO2vfgosSAQMEflfgvkiI5nM1HIFQ8KINlx1XLO7SdL5KdInG5LIJjAFh0pujS4kNCT9a5IGvSq1BrzGqhbEcwWYdju1ZPYBcJm/MG+JD0dYCh8vfrYB/cYMD0SOmNkQ== vagrant@pigsty.com)
TASK [node : Install ntp package] ************************************************************************************************************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.10]
ok: [10.10.10.13]
TASK [node : Install chrony package] *********************************************************************************************************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
ok: [10.10.10.10]
TASK [node : Setup default node timezone] ****************************************************************************************************************************************************************
changed: [10.10.10.13]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.10]
TASK [node : Copy the ntp.conf file] *********************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.10]
TASK [node : Copy the chrony.conf template] **************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.10]
TASK [node : Launch ntpd service] ************************************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [node : Launch chronyd service] *********************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
PLAY [Init meta service] *********************************************************************************************************************************************************************************
TASK [ca : Create local ca directory] ********************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [ca : Copy ca cert from local files] ****************************************************************************************************************************************************************
skipping: [10.10.10.10] => (item=ca.key)
skipping: [10.10.10.10] => (item=ca.crt)
TASK [ca : Check ca key cert exists] *********************************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [ca : Create self-signed CA key-cert] ***************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [nameserver : Make sure dnsmasq package installed] **************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [nameserver : Copy dnsmasq /etc/dnsmasq.d/config] ***************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [nameserver : Add dynamic dns records to meta] ******************************************************************************************************************************************************
changed: [10.10.10.10] => (item=10.10.10.2 pg-meta)
changed: [10.10.10.10] => (item=10.10.10.3 pg-test)
changed: [10.10.10.10] => (item=10.10.10.10 meta-1)
changed: [10.10.10.10] => (item=10.10.10.11 node-1)
changed: [10.10.10.10] => (item=10.10.10.12 node-2)
changed: [10.10.10.10] => (item=10.10.10.13 node-3)
changed: [10.10.10.10] => (item=10.10.10.10 pigsty)
changed: [10.10.10.10] => (item=10.10.10.10 y.pigsty yum.pigsty)
changed: [10.10.10.10] => (item=10.10.10.10 c.pigsty consul.pigsty)
changed: [10.10.10.10] => (item=10.10.10.10 g.pigsty grafana.pigsty)
changed: [10.10.10.10] => (item=10.10.10.10 p.pigsty prometheus.pigsty)
changed: [10.10.10.10] => (item=10.10.10.10 a.pigsty alertmanager.pigsty)
changed: [10.10.10.10] => (item=10.10.10.10 n.pigsty ntp.pigsty)
changed: [10.10.10.10] => (item=10.10.10.10 h.pigsty haproxy.pigsty)
TASK [nameserver : Launch meta dnsmasq service] **********************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [nameserver : Wait for meta dnsmasq online] *********************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [nameserver : Register consul dnsmasq service] ******************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [nameserver : Reload consul] ************************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [nginx : Make sure nginx installed] *****************************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [nginx : Create local html directory] ***************************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [nginx : Create nginx config directory] *************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [nginx : Update default nginx index page] ***********************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [nginx : Copy nginx default config] *****************************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [nginx : Copy nginx upstream conf] ******************************************************************************************************************************************************************
changed: [10.10.10.10] => (item={'name': 'home', 'host': 'pigsty', 'url': '127.0.0.1:3000'})
changed: [10.10.10.10] => (item={'name': 'consul', 'host': 'c.pigsty', 'url': '127.0.0.1:8500'})
changed: [10.10.10.10] => (item={'name': 'grafana', 'host': 'g.pigsty', 'url': '127.0.0.1:3000'})
changed: [10.10.10.10] => (item={'name': 'prometheus', 'host': 'p.pigsty', 'url': '127.0.0.1:9090'})
changed: [10.10.10.10] => (item={'name': 'alertmanager', 'host': 'a.pigsty', 'url': '127.0.0.1:9093'})
changed: [10.10.10.10] => (item={'name': 'haproxy', 'host': 'h.pigsty', 'url': '127.0.0.1:9091'})
TASK [nginx : Templating /etc/nginx/haproxy.conf] ********************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [nginx : Render haproxy upstream in cluster mode] ***************************************************************************************************************************************************
changed: [10.10.10.10] => (item=pg-meta)
changed: [10.10.10.10] => (item=pg-test)
TASK [nginx : Render haproxy location in cluster mode] ***************************************************************************************************************************************************
changed: [10.10.10.10] => (item=pg-meta)
changed: [10.10.10.10] => (item=pg-test)
TASK [nginx : Templating haproxy cluster index] **********************************************************************************************************************************************************
changed: [10.10.10.10] => (item=pg-meta)
changed: [10.10.10.10] => (item=pg-test)
TASK [nginx : Templating haproxy cluster index] **********************************************************************************************************************************************************
changed: [10.10.10.10] => (item=pg-meta)
ok: [10.10.10.10] => (item=pg-test)
TASK [nginx : Restart meta nginx service] ****************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [nginx : Wait for nginx service online] *************************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [nginx : Make sure nginx exporter installed] ********************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [nginx : Config nginx_exporter options] *************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [nginx : Restart nginx_exporter service] ************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [nginx : Wait for nginx exporter online] ************************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [nginx : Register cosnul nginx service] *************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [nginx : Register consul nginx-exporter service] ****************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [nginx : Reload consul] *****************************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [prometheus : Install prometheus and alertmanager] **************************************************************************************************************************************************
ok: [10.10.10.10] => (item=prometheus2)
ok: [10.10.10.10] => (item=alertmanager)
TASK [prometheus : Wipe out prometheus config dir] *******************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [prometheus : Wipe out existing prometheus data] ****************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [prometheus : Create postgres directory structure] **************************************************************************************************************************************************
changed: [10.10.10.10] => (item=/etc/prometheus)
changed: [10.10.10.10] => (item=/etc/prometheus/bin)
changed: [10.10.10.10] => (item=/etc/prometheus/rules)
changed: [10.10.10.10] => (item=/etc/prometheus/targets)
changed: [10.10.10.10] => (item=/export/prometheus/data)
TASK [prometheus : Copy prometheus bin scripts] **********************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [prometheus : Copy prometheus rules scripts] ********************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [prometheus : Copy altermanager config] *************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [prometheus : Render prometheus config] *************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [prometheus : Config /etc/prometheus opts] **********************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [prometheus : Launch prometheus service] ************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [prometheus : Launch alertmanager service] **********************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [prometheus : Wait for prometheus online] ***********************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [prometheus : Wait for alertmanager online] *********************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [prometheus : Render prometheus targets in cluster mode] ********************************************************************************************************************************************
changed: [10.10.10.10] => (item=pg-meta)
changed: [10.10.10.10] => (item=pg-test)
TASK [prometheus : Reload prometheus service] ************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [prometheus : Copy prometheus service definition] ***************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [prometheus : Copy alertmanager service definition] *************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [prometheus : Reload consul to register prometheus] *************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [grafana : Make sure grafana is installed] **********************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [grafana : Check grafana plugin cache exists] *******************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [grafana : Provision grafana plugins via cache] *****************************************************************************************************************************************************
[WARNING]: Consider using the file module with state=absent rather than running 'rm'. If you need to use command because file is insufficient you can add 'warn: false' to this command task or set
'command_warnings=False' in ansible.cfg to get rid of this message.
changed: [10.10.10.10]
TASK [grafana : Download grafana plugins from web] *******************************************************************************************************************************************************
skipping: [10.10.10.10] => (item=redis-datasource)
skipping: [10.10.10.10] => (item=simpod-json-datasource)
skipping: [10.10.10.10] => (item=fifemon-graphql-datasource)
skipping: [10.10.10.10] => (item=sbueringer-consul-datasource)
skipping: [10.10.10.10] => (item=camptocamp-prometheus-alertmanager-datasource)
skipping: [10.10.10.10] => (item=ryantxu-ajax-panel)
skipping: [10.10.10.10] => (item=marcusolsson-hourly-heatmap-panel)
skipping: [10.10.10.10] => (item=michaeldmoore-multistat-panel)
skipping: [10.10.10.10] => (item=marcusolsson-treemap-panel)
skipping: [10.10.10.10] => (item=pr0ps-trackmap-panel)
skipping: [10.10.10.10] => (item=dalvany-image-panel)
skipping: [10.10.10.10] => (item=magnesium-wordcloud-panel)
skipping: [10.10.10.10] => (item=cloudspout-button-panel)
skipping: [10.10.10.10] => (item=speakyourcode-button-panel)
skipping: [10.10.10.10] => (item=jdbranham-diagram-panel)
skipping: [10.10.10.10] => (item=grafana-piechart-panel)
skipping: [10.10.10.10] => (item=snuids-radar-panel)
skipping: [10.10.10.10] => (item=digrich-bubblechart-panel)
TASK [grafana : Download grafana plugins from web] *******************************************************************************************************************************************************
skipping: [10.10.10.10] => (item=https://github.com/Vonng/grafana-echarts)
TASK [grafana : Create grafana plugins cache] ************************************************************************************************************************************************************
skipping: [10.10.10.10]
TASK [grafana : Copy /etc/grafana/grafana.ini] ***********************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [grafana : Remove grafana provision dir] ************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [grafana : Copy provisioning content] ***************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [grafana : Copy pigsty dashboards] ******************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [grafana : Copy pigsty icon image] ******************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [grafana : Replace grafana icon with pigsty] ********************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [grafana : Launch grafana service] ******************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [grafana : Wait for grafana online] *****************************************************************************************************************************************************************
ok: [10.10.10.10]
TASK [grafana : Update grafana default preferences] ******************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [grafana : Register consul grafana service] *********************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [grafana : Reload consul] ***************************************************************************************************************************************************************************
changed: [10.10.10.10]
PLAY [Init dcs] ******************************************************************************************************************************************************************************************
TASK [consul : Check for existing consul] ****************************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [consul : Consul exists flag fact set] **************************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [consul : Abort due to consul exists] ***************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [consul : Clean existing consul instance] ***********************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [consul : Stop any running consul instance] *********************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [consul : Remove existing consul dir] ***************************************************************************************************************************************************************
changed: [10.10.10.10] => (item=/etc/consul.d)
changed: [10.10.10.11] => (item=/etc/consul.d)
changed: [10.10.10.12] => (item=/etc/consul.d)
changed: [10.10.10.13] => (item=/etc/consul.d)
changed: [10.10.10.10] => (item=/var/lib/consul)
changed: [10.10.10.11] => (item=/var/lib/consul)
changed: [10.10.10.12] => (item=/var/lib/consul)
changed: [10.10.10.13] => (item=/var/lib/consul)
TASK [consul : Recreate consul dir] **********************************************************************************************************************************************************************
changed: [10.10.10.10] => (item=/etc/consul.d)
changed: [10.10.10.11] => (item=/etc/consul.d)
changed: [10.10.10.12] => (item=/etc/consul.d)
changed: [10.10.10.13] => (item=/etc/consul.d)
changed: [10.10.10.10] => (item=/var/lib/consul)
changed: [10.10.10.11] => (item=/var/lib/consul)
changed: [10.10.10.13] => (item=/var/lib/consul)
changed: [10.10.10.12] => (item=/var/lib/consul)
TASK [consul : Make sure consul is installed] ************************************************************************************************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.10]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [consul : Make sure consul dir exists] **************************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [consul : Get dcs server node names] ****************************************************************************************************************************************************************
ok: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [consul : Get dcs node name from var] ***************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [consul : Get dcs node name from var] ***************************************************************************************************************************************************************
skipping: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [consul : Fetch hostname as dcs node name] **********************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [consul : Get dcs name from hostname] ***************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [consul : Copy /etc/consul.d/consul.json] ***********************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [consul : Copy consul agent service] ****************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.10]
TASK [consul : Get dcs bootstrap expect quroum] **********************************************************************************************************************************************************
ok: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [consul : Copy consul server service unit] **********************************************************************************************************************************************************
changed: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [consul : Launch consul server service] *************************************************************************************************************************************************************
changed: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [consul : Wait for consul server online] ************************************************************************************************************************************************************
ok: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [consul : Launch consul agent service] **************************************************************************************************************************************************************
skipping: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [consul : Wait for consul agent online] *************************************************************************************************************************************************************
skipping: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
PLAY [Init database cluster] *****************************************************************************************************************************************************************************
TASK [postgres : Create os group postgres] ***************************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Make sure dcs group exists] *************************************************************************************************************************************************************
ok: [10.10.10.10] => (item=consul)
ok: [10.10.10.11] => (item=consul)
ok: [10.10.10.12] => (item=consul)
ok: [10.10.10.13] => (item=consul)
ok: [10.10.10.11] => (item=etcd)
ok: [10.10.10.10] => (item=etcd)
ok: [10.10.10.12] => (item=etcd)
ok: [10.10.10.13] => (item=etcd)
TASK [postgres : Create dbsu postgres] *******************************************************************************************************************************************************************
changed: [10.10.10.13]
changed: [10.10.10.12]
changed: [10.10.10.10]
changed: [10.10.10.11]
TASK [postgres : Grant dbsu nopass sudo] *****************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Grant dbsu all sudo] ********************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Grant dbsu limited sudo] ****************************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Config patroni watchdog support] ********************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Add dbsu ssh no host checking] **********************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Fetch dbsu public keys] *****************************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Exchange dbsu ssh keys] *****************************************************************************************************************************************************************
skipping: [10.10.10.10] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC8ahlH3Yo0nTb1hhd7SGTF1sCwnjEVA/yGra2ktQcZ/i8S/2tfumVomxtnNTeOZqNeQygVUbRgIH77lABXrXwBOimw+J0EmoekPsW7q/NCT5EJgqfoDe5vWBpyhrCe1ixCxESlP2GfpaJYGqeMW2G8HiFU6ieDZcfGcFn1q9JBjtrrV851Htw+Ik/fed93ipGgWzzZnu4NOjz7tpmrsmE3/1J/RvPQdRT7Pjuy2pLn+oCjMkQHJezvUKruVTVwxjObaWO7WFlvQCy2dRez1GBxEK80LRbsZfmgkfIQPzmqHOaacqNBAHe+OeYlBh3fMMbpALzJHnhgJSW5GpdRwiUJ ansible-generated on meta', '10.10.10.10'])
skipping: [10.10.10.10] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC8ahlH3Yo0nTb1hhd7SGTF1sCwnjEVA/yGra2ktQcZ/i8S/2tfumVomxtnNTeOZqNeQygVUbRgIH77lABXrXwBOimw+J0EmoekPsW7q/NCT5EJgqfoDe5vWBpyhrCe1ixCxESlP2GfpaJYGqeMW2G8HiFU6ieDZcfGcFn1q9JBjtrrV851Htw+Ik/fed93ipGgWzzZnu4NOjz7tpmrsmE3/1J/RvPQdRT7Pjuy2pLn+oCjMkQHJezvUKruVTVwxjObaWO7WFlvQCy2dRez1GBxEK80LRbsZfmgkfIQPzmqHOaacqNBAHe+OeYlBh3fMMbpALzJHnhgJSW5GpdRwiUJ ansible-generated on meta', '10.10.10.11'])
skipping: [10.10.10.10] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC8ahlH3Yo0nTb1hhd7SGTF1sCwnjEVA/yGra2ktQcZ/i8S/2tfumVomxtnNTeOZqNeQygVUbRgIH77lABXrXwBOimw+J0EmoekPsW7q/NCT5EJgqfoDe5vWBpyhrCe1ixCxESlP2GfpaJYGqeMW2G8HiFU6ieDZcfGcFn1q9JBjtrrV851Htw+Ik/fed93ipGgWzzZnu4NOjz7tpmrsmE3/1J/RvPQdRT7Pjuy2pLn+oCjMkQHJezvUKruVTVwxjObaWO7WFlvQCy2dRez1GBxEK80LRbsZfmgkfIQPzmqHOaacqNBAHe+OeYlBh3fMMbpALzJHnhgJSW5GpdRwiUJ ansible-generated on meta', '10.10.10.12'])
skipping: [10.10.10.10] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC8ahlH3Yo0nTb1hhd7SGTF1sCwnjEVA/yGra2ktQcZ/i8S/2tfumVomxtnNTeOZqNeQygVUbRgIH77lABXrXwBOimw+J0EmoekPsW7q/NCT5EJgqfoDe5vWBpyhrCe1ixCxESlP2GfpaJYGqeMW2G8HiFU6ieDZcfGcFn1q9JBjtrrV851Htw+Ik/fed93ipGgWzzZnu4NOjz7tpmrsmE3/1J/RvPQdRT7Pjuy2pLn+oCjMkQHJezvUKruVTVwxjObaWO7WFlvQCy2dRez1GBxEK80LRbsZfmgkfIQPzmqHOaacqNBAHe+OeYlBh3fMMbpALzJHnhgJSW5GpdRwiUJ ansible-generated on meta', '10.10.10.13'])
skipping: [10.10.10.11] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDCIr/IW4qyd4Ls8dztCJyYHt354iPFbhLAUUiEK9R3A5W8UOSiJK/WVwlxMazH8QUaMWHuQAlTtW66kW1DDU+fsJ4xGxrNjEnwUbmWfj3BBnoANJQHYOid8iLJwWZuykvz0EIdGMDVpUpIx/qqm3/ZlC+cD0iukXQyEyAw3Qgts/Twqr5IJGeQOFy9Z4rmqSXtz/8tS0YOHCHVC5GGsUpD5+GLqhwPd64xCbWnvpYY61IX45Hzf+zO80xGqPeQLqF9HULs5wi2i6plKrSRl76VWCq9T7QMQMKJJSLUabnrXrKm+sr21LImgpSxSbqbBVVNUVS+adQvvylWb6yaFWov ansible-generated on node-1', '10.10.10.10'])
skipping: [10.10.10.11] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDCIr/IW4qyd4Ls8dztCJyYHt354iPFbhLAUUiEK9R3A5W8UOSiJK/WVwlxMazH8QUaMWHuQAlTtW66kW1DDU+fsJ4xGxrNjEnwUbmWfj3BBnoANJQHYOid8iLJwWZuykvz0EIdGMDVpUpIx/qqm3/ZlC+cD0iukXQyEyAw3Qgts/Twqr5IJGeQOFy9Z4rmqSXtz/8tS0YOHCHVC5GGsUpD5+GLqhwPd64xCbWnvpYY61IX45Hzf+zO80xGqPeQLqF9HULs5wi2i6plKrSRl76VWCq9T7QMQMKJJSLUabnrXrKm+sr21LImgpSxSbqbBVVNUVS+adQvvylWb6yaFWov ansible-generated on node-1', '10.10.10.11'])
skipping: [10.10.10.11] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDCIr/IW4qyd4Ls8dztCJyYHt354iPFbhLAUUiEK9R3A5W8UOSiJK/WVwlxMazH8QUaMWHuQAlTtW66kW1DDU+fsJ4xGxrNjEnwUbmWfj3BBnoANJQHYOid8iLJwWZuykvz0EIdGMDVpUpIx/qqm3/ZlC+cD0iukXQyEyAw3Qgts/Twqr5IJGeQOFy9Z4rmqSXtz/8tS0YOHCHVC5GGsUpD5+GLqhwPd64xCbWnvpYY61IX45Hzf+zO80xGqPeQLqF9HULs5wi2i6plKrSRl76VWCq9T7QMQMKJJSLUabnrXrKm+sr21LImgpSxSbqbBVVNUVS+adQvvylWb6yaFWov ansible-generated on node-1', '10.10.10.12'])
skipping: [10.10.10.11] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDCIr/IW4qyd4Ls8dztCJyYHt354iPFbhLAUUiEK9R3A5W8UOSiJK/WVwlxMazH8QUaMWHuQAlTtW66kW1DDU+fsJ4xGxrNjEnwUbmWfj3BBnoANJQHYOid8iLJwWZuykvz0EIdGMDVpUpIx/qqm3/ZlC+cD0iukXQyEyAw3Qgts/Twqr5IJGeQOFy9Z4rmqSXtz/8tS0YOHCHVC5GGsUpD5+GLqhwPd64xCbWnvpYY61IX45Hzf+zO80xGqPeQLqF9HULs5wi2i6plKrSRl76VWCq9T7QMQMKJJSLUabnrXrKm+sr21LImgpSxSbqbBVVNUVS+adQvvylWb6yaFWov ansible-generated on node-1', '10.10.10.13'])
skipping: [10.10.10.12] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQChMymmlyxGn7PnUvAUvh968/gxTnwGZhhMhIc2+aiuA0QP/D8CSmKfzRYoMVP6/nm3cJsYXM28wzWZ1X/sLp33rYYxbwWpj5n8oBalzqKmSzK0HI5CePKAlWlEeLRDxvKpZYhZwXmro5Ov9lfp63kNHU84nAP7BPBOlufFyydn50bUwP1xKEsG1BC9Xqd4XqB5+eRLjkQDuC743bgxFc3FM8fij1/MuvxtG3HvL6DgEvCo3Lx4qkiVO3akR6Lo3bQEkf76Gq94cFbecAAnYZzdkPHR5LqJiIGS0DYj0yZQXrdN+DtjpyIBfZzi+TFdcVW1Agy1IUQ7Lrt29HJw+/sD ansible-generated on node-2', '10.10.10.10'])
skipping: [10.10.10.12] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQChMymmlyxGn7PnUvAUvh968/gxTnwGZhhMhIc2+aiuA0QP/D8CSmKfzRYoMVP6/nm3cJsYXM28wzWZ1X/sLp33rYYxbwWpj5n8oBalzqKmSzK0HI5CePKAlWlEeLRDxvKpZYhZwXmro5Ov9lfp63kNHU84nAP7BPBOlufFyydn50bUwP1xKEsG1BC9Xqd4XqB5+eRLjkQDuC743bgxFc3FM8fij1/MuvxtG3HvL6DgEvCo3Lx4qkiVO3akR6Lo3bQEkf76Gq94cFbecAAnYZzdkPHR5LqJiIGS0DYj0yZQXrdN+DtjpyIBfZzi+TFdcVW1Agy1IUQ7Lrt29HJw+/sD ansible-generated on node-2', '10.10.10.11'])
skipping: [10.10.10.12] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQChMymmlyxGn7PnUvAUvh968/gxTnwGZhhMhIc2+aiuA0QP/D8CSmKfzRYoMVP6/nm3cJsYXM28wzWZ1X/sLp33rYYxbwWpj5n8oBalzqKmSzK0HI5CePKAlWlEeLRDxvKpZYhZwXmro5Ov9lfp63kNHU84nAP7BPBOlufFyydn50bUwP1xKEsG1BC9Xqd4XqB5+eRLjkQDuC743bgxFc3FM8fij1/MuvxtG3HvL6DgEvCo3Lx4qkiVO3akR6Lo3bQEkf76Gq94cFbecAAnYZzdkPHR5LqJiIGS0DYj0yZQXrdN+DtjpyIBfZzi+TFdcVW1Agy1IUQ7Lrt29HJw+/sD ansible-generated on node-2', '10.10.10.12'])
skipping: [10.10.10.12] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQChMymmlyxGn7PnUvAUvh968/gxTnwGZhhMhIc2+aiuA0QP/D8CSmKfzRYoMVP6/nm3cJsYXM28wzWZ1X/sLp33rYYxbwWpj5n8oBalzqKmSzK0HI5CePKAlWlEeLRDxvKpZYhZwXmro5Ov9lfp63kNHU84nAP7BPBOlufFyydn50bUwP1xKEsG1BC9Xqd4XqB5+eRLjkQDuC743bgxFc3FM8fij1/MuvxtG3HvL6DgEvCo3Lx4qkiVO3akR6Lo3bQEkf76Gq94cFbecAAnYZzdkPHR5LqJiIGS0DYj0yZQXrdN+DtjpyIBfZzi+TFdcVW1Agy1IUQ7Lrt29HJw+/sD ansible-generated on node-2', '10.10.10.13'])
skipping: [10.10.10.13] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCo9KBPH2DVYQrM/WZ4CO4Ipvr+5L6FhqWBr1A6C0Ms+qi77aKHwFEIbrxKqj7wZFbHWoTPt/cbWkXhZgnkfDBR81/wBImnFz0QfuL0tNDN0/YP/4cePo5bQERGcnBI6vkjmXMyGGpRQobNRj71fX/Wt5WMw6dM+d4XjfgUKHIJxEKnz8HYnkiwWm5Flc9EHKTWN+87vZ9B6cdi7gxLQu8LL3x+4e2ArRoz9u5yZIajUTvexqD2IIReqsFt+QObpinLaTc/g7Q+w/no1hAZERS3pImx9l0GF6Ktdp/HMHH1vk2cwnyogrk+OLw1WccI1YkBes/xdzBFTWOwUX3w/vBt ansible-generated on node-3', '10.10.10.10'])
skipping: [10.10.10.13] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCo9KBPH2DVYQrM/WZ4CO4Ipvr+5L6FhqWBr1A6C0Ms+qi77aKHwFEIbrxKqj7wZFbHWoTPt/cbWkXhZgnkfDBR81/wBImnFz0QfuL0tNDN0/YP/4cePo5bQERGcnBI6vkjmXMyGGpRQobNRj71fX/Wt5WMw6dM+d4XjfgUKHIJxEKnz8HYnkiwWm5Flc9EHKTWN+87vZ9B6cdi7gxLQu8LL3x+4e2ArRoz9u5yZIajUTvexqD2IIReqsFt+QObpinLaTc/g7Q+w/no1hAZERS3pImx9l0GF6Ktdp/HMHH1vk2cwnyogrk+OLw1WccI1YkBes/xdzBFTWOwUX3w/vBt ansible-generated on node-3', '10.10.10.11'])
skipping: [10.10.10.13] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCo9KBPH2DVYQrM/WZ4CO4Ipvr+5L6FhqWBr1A6C0Ms+qi77aKHwFEIbrxKqj7wZFbHWoTPt/cbWkXhZgnkfDBR81/wBImnFz0QfuL0tNDN0/YP/4cePo5bQERGcnBI6vkjmXMyGGpRQobNRj71fX/Wt5WMw6dM+d4XjfgUKHIJxEKnz8HYnkiwWm5Flc9EHKTWN+87vZ9B6cdi7gxLQu8LL3x+4e2ArRoz9u5yZIajUTvexqD2IIReqsFt+QObpinLaTc/g7Q+w/no1hAZERS3pImx9l0GF6Ktdp/HMHH1vk2cwnyogrk+OLw1WccI1YkBes/xdzBFTWOwUX3w/vBt ansible-generated on node-3', '10.10.10.12'])
skipping: [10.10.10.13] => (item=['ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCo9KBPH2DVYQrM/WZ4CO4Ipvr+5L6FhqWBr1A6C0Ms+qi77aKHwFEIbrxKqj7wZFbHWoTPt/cbWkXhZgnkfDBR81/wBImnFz0QfuL0tNDN0/YP/4cePo5bQERGcnBI6vkjmXMyGGpRQobNRj71fX/Wt5WMw6dM+d4XjfgUKHIJxEKnz8HYnkiwWm5Flc9EHKTWN+87vZ9B6cdi7gxLQu8LL3x+4e2ArRoz9u5yZIajUTvexqD2IIReqsFt+QObpinLaTc/g7Q+w/no1hAZERS3pImx9l0GF6Ktdp/HMHH1vk2cwnyogrk+OLw1WccI1YkBes/xdzBFTWOwUX3w/vBt ansible-generated on node-3', '10.10.10.13'])
TASK [postgres : Install offical pgdg yum repo] **********************************************************************************************************************************************************
skipping: [10.10.10.10] => (item=postgresql${pg_version}*)
skipping: [10.10.10.10] => (item=postgis31_${pg_version}*)
skipping: [10.10.10.10] => (item=pgbouncer patroni pg_exporter pgbadger)
skipping: [10.10.10.11] => (item=postgresql${pg_version}*)
skipping: [10.10.10.10] => (item=patroni patroni-consul patroni-etcd pgbouncer pgbadger pg_activity)
skipping: [10.10.10.11] => (item=postgis31_${pg_version}*)
skipping: [10.10.10.10] => (item=python3 python3-psycopg2 python36-requests python3-etcd python3-consul)
skipping: [10.10.10.11] => (item=pgbouncer patroni pg_exporter pgbadger)
skipping: [10.10.10.12] => (item=postgresql${pg_version}*)
skipping: [10.10.10.10] => (item=python36-urllib3 python36-idna python36-pyOpenSSL python36-cryptography)
skipping: [10.10.10.11] => (item=patroni patroni-consul patroni-etcd pgbouncer pgbadger pg_activity)
skipping: [10.10.10.12] => (item=postgis31_${pg_version}*)
skipping: [10.10.10.11] => (item=python3 python3-psycopg2 python36-requests python3-etcd python3-consul)
skipping: [10.10.10.12] => (item=pgbouncer patroni pg_exporter pgbadger)
skipping: [10.10.10.13] => (item=postgresql${pg_version}*)
skipping: [10.10.10.11] => (item=python36-urllib3 python36-idna python36-pyOpenSSL python36-cryptography)
skipping: [10.10.10.12] => (item=patroni patroni-consul patroni-etcd pgbouncer pgbadger pg_activity)
skipping: [10.10.10.13] => (item=postgis31_${pg_version}*)
skipping: [10.10.10.12] => (item=python3 python3-psycopg2 python36-requests python3-etcd python3-consul)
skipping: [10.10.10.13] => (item=pgbouncer patroni pg_exporter pgbadger)
skipping: [10.10.10.12] => (item=python36-urllib3 python36-idna python36-pyOpenSSL python36-cryptography)
skipping: [10.10.10.13] => (item=patroni patroni-consul patroni-etcd pgbouncer pgbadger pg_activity)
skipping: [10.10.10.13] => (item=python3 python3-psycopg2 python36-requests python3-etcd python3-consul)
skipping: [10.10.10.13] => (item=python36-urllib3 python36-idna python36-pyOpenSSL python36-cryptography)
TASK [postgres : Install pg packages] ********************************************************************************************************************************************************************
changed: [10.10.10.10] => (item=['postgresql13*', 'postgis31_13*', 'pgbouncer,patroni,pg_exporter,pgbadger', 'patroni,patroni-consul,patroni-etcd,pgbouncer,pgbadger,pg_activity', 'python3,python3-psycopg2,python36-requests,python3-etcd,python3-consul', 'python36-urllib3,python36-idna,python36-pyOpenSSL,python36-cryptography'])
changed: [10.10.10.11] => (item=['postgresql13*', 'postgis31_13*', 'pgbouncer,patroni,pg_exporter,pgbadger', 'patroni,patroni-consul,patroni-etcd,pgbouncer,pgbadger,pg_activity', 'python3,python3-psycopg2,python36-requests,python3-etcd,python3-consul', 'python36-urllib3,python36-idna,python36-pyOpenSSL,python36-cryptography'])
changed: [10.10.10.13] => (item=['postgresql13*', 'postgis31_13*', 'pgbouncer,patroni,pg_exporter,pgbadger', 'patroni,patroni-consul,patroni-etcd,pgbouncer,pgbadger,pg_activity', 'python3,python3-psycopg2,python36-requests,python3-etcd,python3-consul', 'python36-urllib3,python36-idna,python36-pyOpenSSL,python36-cryptography'])
changed: [10.10.10.12] => (item=['postgresql13*', 'postgis31_13*', 'pgbouncer,patroni,pg_exporter,pgbadger', 'patroni,patroni-consul,patroni-etcd,pgbouncer,pgbadger,pg_activity', 'python3,python3-psycopg2,python36-requests,python3-etcd,python3-consul', 'python36-urllib3,python36-idna,python36-pyOpenSSL,python36-cryptography'])
TASK [postgres : Install pg extensions] ******************************************************************************************************************************************************************
changed: [10.10.10.11] => (item=['pg_repack13,pg_qualstats13,pg_stat_kcache13,wal2json13'])
changed: [10.10.10.10] => (item=['pg_repack13,pg_qualstats13,pg_stat_kcache13,wal2json13'])
changed: [10.10.10.13] => (item=['pg_repack13,pg_qualstats13,pg_stat_kcache13,wal2json13'])
changed: [10.10.10.12] => (item=['pg_repack13,pg_qualstats13,pg_stat_kcache13,wal2json13'])
TASK [postgres : Link /usr/pgsql to current version] *****************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Add pg bin dir to profile path] *********************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [postgres : Fix directory ownership] ****************************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [postgres : Remove default postgres service] ********************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Check necessary variables exists] *******************************************************************************************************************************************************
ok: [10.10.10.10] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.11] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.12] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.13] => {
"changed": false,
"msg": "All assertions passed"
}
TASK [postgres : Fetch variables via pg_cluster] *********************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [postgres : Set cluster basic facts for hosts] ******************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [postgres : Assert cluster primary singleton] *******************************************************************************************************************************************************
ok: [10.10.10.10] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.11] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.12] => {
"changed": false,
"msg": "All assertions passed"
}
ok: [10.10.10.13] => {
"changed": false,
"msg": "All assertions passed"
}
TASK [postgres : Setup cluster primary ip address] *******************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [postgres : Setup repl upstream for primary] ********************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Setup repl upstream for replicas] *******************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [postgres : Debug print instance summary] ***********************************************************************************************************************************************************
ok: [10.10.10.10] => {
"msg": "cluster=pg-meta service=pg-meta-primary instance=pg-meta-1 replication=[primary:itself]->10.10.10.10"
}
ok: [10.10.10.11] => {
"msg": "cluster=pg-test service=pg-test-primary instance=pg-test-1 replication=[primary:itself]->10.10.10.11"
}
ok: [10.10.10.12] => {
"msg": "cluster=pg-test service=pg-test-replica instance=pg-test-2 replication=[primary:itself]->10.10.10.12"
}
ok: [10.10.10.13] => {
"msg": "cluster=pg-test service=pg-test-offline instance=pg-test-3 replication=[primary:itself]->10.10.10.13"
}
TASK [postgres : Check for existing postgres instance] ***************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Set fact whether pg port is open] *******************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [postgres : Abort due to existing postgres instance] ************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Clean existing postgres instance] *******************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Shutdown existing postgres service] *****************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Remove registerd consul service] ********************************************************************************************************************************************************
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.11]
changed: [10.10.10.10]
TASK [postgres : Remove postgres metadata in consul] *****************************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.11]
changed: [10.10.10.10]
TASK [postgres : Remove existing postgres data] **********************************************************************************************************************************************************
ok: [10.10.10.10] => (item=/pg)
ok: [10.10.10.11] => (item=/pg)
ok: [10.10.10.12] => (item=/pg)
ok: [10.10.10.13] => (item=/pg)
ok: [10.10.10.10] => (item=/export/postgres)
ok: [10.10.10.11] => (item=/export/postgres)
ok: [10.10.10.12] => (item=/export/postgres)
ok: [10.10.10.13] => (item=/export/postgres)
ok: [10.10.10.10] => (item=/var/backups/postgres)
ok: [10.10.10.11] => (item=/var/backups/postgres)
ok: [10.10.10.12] => (item=/var/backups/postgres)
ok: [10.10.10.13] => (item=/var/backups/postgres)
changed: [10.10.10.10] => (item=/etc/pgbouncer)
changed: [10.10.10.11] => (item=/etc/pgbouncer)
changed: [10.10.10.13] => (item=/etc/pgbouncer)
changed: [10.10.10.12] => (item=/etc/pgbouncer)
changed: [10.10.10.10] => (item=/var/log/pgbouncer)
changed: [10.10.10.11] => (item=/var/log/pgbouncer)
changed: [10.10.10.13] => (item=/var/log/pgbouncer)
changed: [10.10.10.12] => (item=/var/log/pgbouncer)
changed: [10.10.10.10] => (item=/var/run/pgbouncer)
changed: [10.10.10.11] => (item=/var/run/pgbouncer)
changed: [10.10.10.13] => (item=/var/run/pgbouncer)
changed: [10.10.10.12] => (item=/var/run/pgbouncer)
TASK [postgres : Make sure main and backup dir exists] ***************************************************************************************************************************************************
changed: [10.10.10.11] => (item=/export)
changed: [10.10.10.12] => (item=/export)
changed: [10.10.10.13] => (item=/export)
changed: [10.10.10.10] => (item=/export)
changed: [10.10.10.11] => (item=/var/backups)
changed: [10.10.10.12] => (item=/var/backups)
changed: [10.10.10.13] => (item=/var/backups)
changed: [10.10.10.10] => (item=/var/backups)
TASK [postgres : Create postgres directory structure] ****************************************************************************************************************************************************
changed: [10.10.10.10] => (item=/export/postgres)
changed: [10.10.10.11] => (item=/export/postgres)
changed: [10.10.10.12] => (item=/export/postgres)
changed: [10.10.10.13] => (item=/export/postgres)
changed: [10.10.10.10] => (item=/export/postgres/pg-meta-13)
changed: [10.10.10.11] => (item=/export/postgres/pg-test-13)
changed: [10.10.10.12] => (item=/export/postgres/pg-test-13)
changed: [10.10.10.13] => (item=/export/postgres/pg-test-13)
changed: [10.10.10.10] => (item=/export/postgres/pg-meta-13/bin)
changed: [10.10.10.12] => (item=/export/postgres/pg-test-13/bin)
changed: [10.10.10.11] => (item=/export/postgres/pg-test-13/bin)
changed: [10.10.10.13] => (item=/export/postgres/pg-test-13/bin)
changed: [10.10.10.10] => (item=/export/postgres/pg-meta-13/log)
changed: [10.10.10.12] => (item=/export/postgres/pg-test-13/log)
changed: [10.10.10.11] => (item=/export/postgres/pg-test-13/log)
changed: [10.10.10.13] => (item=/export/postgres/pg-test-13/log)
changed: [10.10.10.10] => (item=/export/postgres/pg-meta-13/tmp)
changed: [10.10.10.12] => (item=/export/postgres/pg-test-13/tmp)
changed: [10.10.10.11] => (item=/export/postgres/pg-test-13/tmp)
changed: [10.10.10.13] => (item=/export/postgres/pg-test-13/tmp)
changed: [10.10.10.10] => (item=/export/postgres/pg-meta-13/conf)
changed: [10.10.10.12] => (item=/export/postgres/pg-test-13/conf)
changed: [10.10.10.11] => (item=/export/postgres/pg-test-13/conf)
changed: [10.10.10.13] => (item=/export/postgres/pg-test-13/conf)
changed: [10.10.10.10] => (item=/export/postgres/pg-meta-13/data)
changed: [10.10.10.12] => (item=/export/postgres/pg-test-13/data)
changed: [10.10.10.11] => (item=/export/postgres/pg-test-13/data)
changed: [10.10.10.13] => (item=/export/postgres/pg-test-13/data)
changed: [10.10.10.10] => (item=/export/postgres/pg-meta-13/meta)
changed: [10.10.10.12] => (item=/export/postgres/pg-test-13/meta)
changed: [10.10.10.11] => (item=/export/postgres/pg-test-13/meta)
changed: [10.10.10.13] => (item=/export/postgres/pg-test-13/meta)
changed: [10.10.10.10] => (item=/export/postgres/pg-meta-13/stat)
changed: [10.10.10.12] => (item=/export/postgres/pg-test-13/stat)
changed: [10.10.10.11] => (item=/export/postgres/pg-test-13/stat)
changed: [10.10.10.13] => (item=/export/postgres/pg-test-13/stat)
changed: [10.10.10.10] => (item=/export/postgres/pg-meta-13/change)
changed: [10.10.10.12] => (item=/export/postgres/pg-test-13/change)
changed: [10.10.10.11] => (item=/export/postgres/pg-test-13/change)
changed: [10.10.10.13] => (item=/export/postgres/pg-test-13/change)
changed: [10.10.10.10] => (item=/var/backups/postgres/pg-meta-13/postgres)
changed: [10.10.10.12] => (item=/var/backups/postgres/pg-test-13/postgres)
changed: [10.10.10.11] => (item=/var/backups/postgres/pg-test-13/postgres)
changed: [10.10.10.13] => (item=/var/backups/postgres/pg-test-13/postgres)
changed: [10.10.10.10] => (item=/var/backups/postgres/pg-meta-13/arcwal)
changed: [10.10.10.12] => (item=/var/backups/postgres/pg-test-13/arcwal)
changed: [10.10.10.11] => (item=/var/backups/postgres/pg-test-13/arcwal)
changed: [10.10.10.13] => (item=/var/backups/postgres/pg-test-13/arcwal)
changed: [10.10.10.10] => (item=/var/backups/postgres/pg-meta-13/backup)
changed: [10.10.10.12] => (item=/var/backups/postgres/pg-test-13/backup)
changed: [10.10.10.11] => (item=/var/backups/postgres/pg-test-13/backup)
changed: [10.10.10.13] => (item=/var/backups/postgres/pg-test-13/backup)
changed: [10.10.10.10] => (item=/var/backups/postgres/pg-meta-13/remote)
changed: [10.10.10.12] => (item=/var/backups/postgres/pg-test-13/remote)
changed: [10.10.10.11] => (item=/var/backups/postgres/pg-test-13/remote)
changed: [10.10.10.13] => (item=/var/backups/postgres/pg-test-13/remote)
TASK [postgres : Create pgbouncer directory structure] ***************************************************************************************************************************************************
changed: [10.10.10.10] => (item=/etc/pgbouncer)
changed: [10.10.10.11] => (item=/etc/pgbouncer)
changed: [10.10.10.12] => (item=/etc/pgbouncer)
changed: [10.10.10.13] => (item=/etc/pgbouncer)
changed: [10.10.10.11] => (item=/var/log/pgbouncer)
changed: [10.10.10.10] => (item=/var/log/pgbouncer)
changed: [10.10.10.12] => (item=/var/log/pgbouncer)
changed: [10.10.10.13] => (item=/var/log/pgbouncer)
changed: [10.10.10.11] => (item=/var/run/pgbouncer)
changed: [10.10.10.10] => (item=/var/run/pgbouncer)
changed: [10.10.10.12] => (item=/var/run/pgbouncer)
changed: [10.10.10.13] => (item=/var/run/pgbouncer)
TASK [postgres : Create links from pgbkup to pgroot] *****************************************************************************************************************************************************
changed: [10.10.10.10] => (item=arcwal)
changed: [10.10.10.11] => (item=arcwal)
changed: [10.10.10.12] => (item=arcwal)
changed: [10.10.10.13] => (item=arcwal)
changed: [10.10.10.10] => (item=backup)
changed: [10.10.10.11] => (item=backup)
changed: [10.10.10.12] => (item=backup)
changed: [10.10.10.13] => (item=backup)
changed: [10.10.10.10] => (item=remote)
changed: [10.10.10.11] => (item=remote)
changed: [10.10.10.12] => (item=remote)
changed: [10.10.10.13] => (item=remote)
TASK [postgres : Create links from current cluster] ******************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.11]
TASK [postgres : Copy pg_cluster to /pg/meta/cluster] ****************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Copy pg_version to /pg/meta/version] ****************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Copy pg_instance to /pg/meta/instance] **************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Copy pg_seq to /pg/meta/sequence] *******************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Copy pg_role to /pg/meta/role] **********************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Copy postgres scripts to /pg/bin/] ******************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [postgres : Copy alias profile to /etc/profile.d] ***************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [postgres : Copy psqlrc to postgres home] ***********************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Setup hostname to pg instance name] *****************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Copy consul node-meta definition] *******************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [postgres : Restart consul to load new node-meta] ***************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.11]
changed: [10.10.10.13]
TASK [postgres : Config patroni watchdog support] ********************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [postgres : Get config parameter page count] ********************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Get config parameter page size] *********************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.10]
TASK [postgres : Tune shared buffer and work mem] ********************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [postgres : Hanlde small size mem occasion] *********************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [postgres : Calculate postgres mem params] **********************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : create patroni config dir] **************************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : use predefined patroni template] ********************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Render default /pg/conf/patroni.yml] ****************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Link /pg/conf/patroni to /pg/bin/] ******************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Link /pg/bin/patroni.yml to /etc/patroni/] **********************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Config patroni watchdog support] ********************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [postgres : Copy patroni systemd service file] ******************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : create patroni systemd drop-in dir] *****************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [postgres : Copy postgres systemd service file] *****************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Drop-In consul dependency for patroni] **************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Render default initdb scripts] **********************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.11]
changed: [10.10.10.13]
TASK [postgres : Launch patroni on primary instance] *****************************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.10]
changed: [10.10.10.11]
TASK [postgres : Wait for patroni primary online] ********************************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
ok: [10.10.10.10]
ok: [10.10.10.11]
TASK [postgres : Wait for postgres primary online] *******************************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
ok: [10.10.10.10]
ok: [10.10.10.11]
TASK [postgres : Check primary postgres service ready] ***************************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
[WARNING]: Module remote_tmp /var/lib/pgsql/.ansible/tmp did not exist and was created with a mode of 0700, this may cause issues when running as another user. To avoid this, create the remote_tmp dir
with the correct permissions manually
changed: [10.10.10.10]
changed: [10.10.10.11]
TASK [postgres : Check replication connectivity to primary] **********************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.10]
changed: [10.10.10.11]
TASK [postgres : Render init roles sql] ******************************************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.10]
changed: [10.10.10.11]
TASK [postgres : Render init template sql] ***************************************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.10]
changed: [10.10.10.11]
TASK [postgres : Render default pg-init scripts] *********************************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.11]
changed: [10.10.10.10]
TASK [postgres : Execute initialization scripts] *********************************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.10]
changed: [10.10.10.11]
TASK [postgres : Check primary instance ready] ***********************************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.10]
changed: [10.10.10.11]
TASK [postgres : Add dbsu password to pgpass if exists] **************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Add system user to pgpass] **************************************************************************************************************************************************************
changed: [10.10.10.10] => (item={'username': 'replicator', 'password': 'DBUser.Replicator'})
changed: [10.10.10.11] => (item={'username': 'replicator', 'password': 'DBUser.Replicator'})
changed: [10.10.10.12] => (item={'username': 'replicator', 'password': 'DBUser.Replicator'})
changed: [10.10.10.13] => (item={'username': 'replicator', 'password': 'DBUser.Replicator'})
changed: [10.10.10.11] => (item={'username': 'dbuser_monitor', 'password': 'DBUser.Monitor'})
changed: [10.10.10.10] => (item={'username': 'dbuser_monitor', 'password': 'DBUser.Monitor'})
changed: [10.10.10.13] => (item={'username': 'dbuser_monitor', 'password': 'DBUser.Monitor'})
changed: [10.10.10.12] => (item={'username': 'dbuser_monitor', 'password': 'DBUser.Monitor'})
changed: [10.10.10.13] => (item={'username': 'dbuser_admin', 'password': 'DBUser.Admin'})
changed: [10.10.10.12] => (item={'username': 'dbuser_admin', 'password': 'DBUser.Admin'})
changed: [10.10.10.10] => (item={'username': 'dbuser_admin', 'password': 'DBUser.Admin'})
changed: [10.10.10.11] => (item={'username': 'dbuser_admin', 'password': 'DBUser.Admin'})
TASK [postgres : Check replication connectivity to primary] **********************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Launch patroni on replica instances] ****************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Wait for patroni replica online] ********************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [postgres : Wait for postgres replica online] *******************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [postgres : Check replica postgres service ready] ***************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Render hba rules] ***********************************************************************************************************************************************************************
changed: [10.10.10.13]
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.11]
TASK [postgres : Reload hba rules] ***********************************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [postgres : Pause patroni] **************************************************************************************************************************************************************************
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.10]
TASK [postgres : Stop patroni on replica instance] *******************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Stop patroni on primary instance] *******************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Launch raw postgres on primary] *********************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Launch raw postgres on primary] *********************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Wait for postgres online] ***************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Check pgbouncer is installed] ***********************************************************************************************************************************************************
changed: [10.10.10.12]
changed: [10.10.10.11]
changed: [10.10.10.10]
changed: [10.10.10.13]
TASK [postgres : Stop existing pgbouncer service] ********************************************************************************************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.10]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [postgres : Remove existing pgbouncer dirs] *********************************************************************************************************************************************************
changed: [10.10.10.10] => (item=/etc/pgbouncer)
changed: [10.10.10.12] => (item=/etc/pgbouncer)
changed: [10.10.10.13] => (item=/etc/pgbouncer)
changed: [10.10.10.11] => (item=/etc/pgbouncer)
changed: [10.10.10.10] => (item=/var/log/pgbouncer)
changed: [10.10.10.12] => (item=/var/log/pgbouncer)
changed: [10.10.10.13] => (item=/var/log/pgbouncer)
changed: [10.10.10.11] => (item=/var/log/pgbouncer)
changed: [10.10.10.10] => (item=/var/run/pgbouncer)
changed: [10.10.10.12] => (item=/var/run/pgbouncer)
changed: [10.10.10.13] => (item=/var/run/pgbouncer)
changed: [10.10.10.11] => (item=/var/run/pgbouncer)
TASK [postgres : Recreate dirs with owner postgres] ******************************************************************************************************************************************************
changed: [10.10.10.10] => (item=/etc/pgbouncer)
changed: [10.10.10.11] => (item=/etc/pgbouncer)
changed: [10.10.10.12] => (item=/etc/pgbouncer)
changed: [10.10.10.13] => (item=/etc/pgbouncer)
changed: [10.10.10.10] => (item=/var/log/pgbouncer)
changed: [10.10.10.12] => (item=/var/log/pgbouncer)
changed: [10.10.10.11] => (item=/var/log/pgbouncer)
changed: [10.10.10.13] => (item=/var/log/pgbouncer)
changed: [10.10.10.10] => (item=/var/run/pgbouncer)
changed: [10.10.10.12] => (item=/var/run/pgbouncer)
changed: [10.10.10.11] => (item=/var/run/pgbouncer)
changed: [10.10.10.13] => (item=/var/run/pgbouncer)
TASK [postgres : Copy /etc/pgbouncer/pgbouncer.ini] ******************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.11]
changed: [10.10.10.13]
TASK [postgres : Copy /etc/pgbouncer/pgb_hba.conf] *******************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [postgres : Touch userlist and database list] *******************************************************************************************************************************************************
changed: [10.10.10.10] => (item=database.txt)
changed: [10.10.10.11] => (item=database.txt)
changed: [10.10.10.12] => (item=database.txt)
changed: [10.10.10.13] => (item=database.txt)
changed: [10.10.10.10] => (item=userlist.txt)
changed: [10.10.10.11] => (item=userlist.txt)
changed: [10.10.10.12] => (item=userlist.txt)
changed: [10.10.10.13] => (item=userlist.txt)
TASK [postgres : Add default users to pgbouncer] *********************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.10]
TASK [postgres : Copy pgbouncer systemd service] *********************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.11]
changed: [10.10.10.13]
TASK [postgres : Launch pgbouncer pool service] **********************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.11]
changed: [10.10.10.13]
TASK [postgres : Wait for pgbouncer service online] ******************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [postgres : Check pgbouncer service is ready] *******************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : include_tasks] **************************************************************************************************************************************************************************
included: /private/tmp/pigsty/roles/postgres/tasks/createuser.yml for 10.10.10.10 => (item={'name': 'dbuser_meta', 'password': 'DBUser.Meta', 'login': True, 'superuser': False, 'createdb': False, 'createrole': False, 'inherit': True, 'replication': False, 'bypassrls': False, 'connlimit': -1, 'expire_at': '2030-12-31', 'expire_in': 365, 'roles': ['dbrole_readwrite'], 'pgbouncer': True, 'parameters': {'search_path': 'public'}, 'comment': 'test user'})
included: /private/tmp/pigsty/roles/postgres/tasks/createuser.yml for 10.10.10.10 => (item={'name': 'dbuser_vonng2', 'password': 'DBUser.Vonng', 'roles': ['dbrole_offline'], 'expire_in': 365, 'pgbouncer': False, 'comment': 'example personal user for interactive queries'})
included: /private/tmp/pigsty/roles/postgres/tasks/createuser.yml for 10.10.10.11, 10.10.10.12, 10.10.10.13 => (item={'name': 'test', 'password': 'test', 'roles': ['dbrole_readwrite'], 'pgbouncer': True, 'comment': 'default test user for production usage'})
TASK [postgres : Render user dbuser_meta creation sql] ***************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [postgres : Execute user dbuser_meta creation sql on primary] ***************************************************************************************************************************************
changed: [10.10.10.10]
TASK [postgres : Add user to pgbouncer] ******************************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [postgres : Render user dbuser_vonng2 creation sql] *************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [postgres : Execute user dbuser_vonng2 creation sql on primary] *************************************************************************************************************************************
changed: [10.10.10.10]
TASK [postgres : Add user to pgbouncer] ******************************************************************************************************************************************************************
skipping: [10.10.10.10]
TASK [postgres : Render user test creation sql] **********************************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.11]
TASK [postgres : Execute user test creation sql on primary] **********************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.11]
TASK [postgres : Add user to pgbouncer] ******************************************************************************************************************************************************************
changed: [10.10.10.12]
changed: [10.10.10.11]
changed: [10.10.10.13]
TASK [postgres : include_tasks] **************************************************************************************************************************************************************************
included: /private/tmp/pigsty/roles/postgres/tasks/createdb.yml for 10.10.10.10 => (item={'name': 'meta', 'allowconn': True, 'revokeconn': False, 'connlimit': -1, 'extensions': [{'name': 'postgis', 'schema': 'public'}], 'parameters': {'enable_partitionwise_join': True}, 'pgbouncer': True, 'comment': 'pigsty meta database'})
included: /private/tmp/pigsty/roles/postgres/tasks/createdb.yml for 10.10.10.11, 10.10.10.12, 10.10.10.13 => (item={'name': 'test'})
TASK [postgres : debug] **********************************************************************************************************************************************************************************
ok: [10.10.10.10] => {
"msg": {
"allowconn": true,
"comment": "pigsty meta database",
"connlimit": -1,
"extensions": [
{
"name": "postgis",
"schema": "public"
}
],
"name": "meta",
"parameters": {
"enable_partitionwise_join": true
},
"pgbouncer": true,
"revokeconn": false
}
}
TASK [postgres : Render database meta creation sql] ******************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [postgres : Render database meta baseline sql] ******************************************************************************************************************************************************
skipping: [10.10.10.10]
TASK [postgres : Execute database meta creation command] *************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [postgres : Execute database meta creation sql] *****************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [postgres : Execute database meta creation sql] *****************************************************************************************************************************************************
skipping: [10.10.10.10]
TASK [postgres : Add pgbouncer busniess database] ********************************************************************************************************************************************************
changed: [10.10.10.10]
TASK [postgres : debug] **********************************************************************************************************************************************************************************
ok: [10.10.10.11] => {
"msg": {
"name": "test"
}
}
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Render database test creation sql] ******************************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.11]
TASK [postgres : Render database test baseline sql] ******************************************************************************************************************************************************
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Execute database test creation command] *************************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.11]
TASK [postgres : Execute database test creation sql] *****************************************************************************************************************************************************
skipping: [10.10.10.12]
skipping: [10.10.10.13]
changed: [10.10.10.11]
TASK [postgres : Execute database test creation sql] *****************************************************************************************************************************************************
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [postgres : Add pgbouncer busniess database] ********************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [postgres : Reload pgbouncer to add db and users] ***************************************************************************************************************************************************
changed: [10.10.10.13]
changed: [10.10.10.12]
changed: [10.10.10.10]
changed: [10.10.10.11]
TASK [postgres : Copy pg service definition to consul] ***************************************************************************************************************************************************
changed: [10.10.10.10] => (item=postgres)
changed: [10.10.10.11] => (item=postgres)
changed: [10.10.10.12] => (item=postgres)
changed: [10.10.10.13] => (item=postgres)
changed: [10.10.10.10] => (item=pgbouncer)
changed: [10.10.10.11] => (item=pgbouncer)
changed: [10.10.10.12] => (item=pgbouncer)
changed: [10.10.10.13] => (item=pgbouncer)
changed: [10.10.10.10] => (item=patroni)
changed: [10.10.10.11] => (item=patroni)
changed: [10.10.10.12] => (item=patroni)
changed: [10.10.10.13] => (item=patroni)
TASK [postgres : Reload postgres consul service] *********************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.10]
TASK [postgres : Render grafana datasource definition] ***************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [postgres : Register datasource to grafana] *********************************************************************************************************************************************************
[WARNING]: Consider using the get_url or uri module rather than running 'curl'. If you need to use command because get_url or uri is insufficient you can add 'warn: false' to this command task or set
'command_warnings=False' in ansible.cfg to get rid of this message.
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [monitor : Install exporter yum repo] ***************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [monitor : Install node_exporter and pg_exporter] ***************************************************************************************************************************************************
skipping: [10.10.10.10] => (item=node_exporter)
skipping: [10.10.10.10] => (item=pg_exporter)
skipping: [10.10.10.11] => (item=node_exporter)
skipping: [10.10.10.11] => (item=pg_exporter)
skipping: [10.10.10.12] => (item=node_exporter)
skipping: [10.10.10.12] => (item=pg_exporter)
skipping: [10.10.10.13] => (item=node_exporter)
skipping: [10.10.10.13] => (item=pg_exporter)
TASK [monitor : Copy node_exporter binary] ***************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [monitor : Copy pg_exporter binary] *****************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [monitor : Create /etc/pg_exporter conf dir] ********************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [monitor : Copy default pg_exporter.yaml] ***********************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.10]
changed: [10.10.10.13]
TASK [monitor : Config /etc/default/pg_exporter] *********************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [monitor : Config pg_exporter service unit] *********************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.10]
changed: [10.10.10.13]
TASK [monitor : Launch pg_exporter systemd service] ******************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.10]
TASK [monitor : Wait for pg_exporter service online] *****************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.12]
ok: [10.10.10.11]
ok: [10.10.10.13]
TASK [monitor : Register pg-exporter consul service] *****************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [monitor : Reload pg-exporter consul service] *******************************************************************************************************************************************************
changed: [10.10.10.12]
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.10]
TASK [monitor : Config pgbouncer_exporter opts] **********************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [monitor : Config pgbouncer_exporter service] *******************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [monitor : Launch pgbouncer_exporter service] *******************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.13]
changed: [10.10.10.11]
changed: [10.10.10.12]
TASK [monitor : Wait for pgbouncer_exporter online] ******************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [monitor : Register pgb-exporter consul service] ****************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.13]
changed: [10.10.10.11]
changed: [10.10.10.12]
TASK [monitor : Reload pgb-exporter consul service] ******************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.10]
changed: [10.10.10.13]
TASK [monitor : Copy node_exporter systemd service] ******************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.11]
changed: [10.10.10.13]
TASK [monitor : Config default node_exporter options] ****************************************************************************************************************************************************
changed: [10.10.10.12]
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.13]
TASK [monitor : Launch node_exporter service unit] *******************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.11]
TASK [monitor : Wait for node_exporter online] ***********************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [monitor : Register node-exporter service to consul] ************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [monitor : Reload node-exporter consul service] *****************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.10]
changed: [10.10.10.13]
TASK [service : Make sure haproxy is installed] **********************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [service : Create haproxy directory] ****************************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.12]
ok: [10.10.10.13]
ok: [10.10.10.11]
TASK [service : Copy haproxy systemd service file] *******************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.11]
TASK [service : Fetch postgres cluster memberships] ******************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.11]
ok: [10.10.10.12]
ok: [10.10.10.13]
TASK [service : Templating /etc/haproxy/haproxy.cfg] *****************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.13]
changed: [10.10.10.11]
changed: [10.10.10.12]
TASK [service : Launch haproxy load balancer service] ****************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.13]
changed: [10.10.10.11]
TASK [service : Wait for haproxy load balancer online] ***************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.12]
ok: [10.10.10.11]
ok: [10.10.10.13]
TASK [service : Reload haproxy load balancer service] ****************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.13]
changed: [10.10.10.12]
changed: [10.10.10.11]
TASK [service : Copy haproxy exporter definition] ********************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.10]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [service : Copy haproxy service definition] *********************************************************************************************************************************************************
changed: [10.10.10.12] => (item={'name': 'primary', 'src_ip': '*', 'src_port': 5433, 'dst_port': 'pgbouncer', 'check_url': '/primary', 'selector': '[]'})
changed: [10.10.10.10] => (item={'name': 'primary', 'src_ip': '*', 'src_port': 5433, 'dst_port': 'pgbouncer', 'check_url': '/primary', 'selector': '[]'})
changed: [10.10.10.11] => (item={'name': 'primary', 'src_ip': '*', 'src_port': 5433, 'dst_port': 'pgbouncer', 'check_url': '/primary', 'selector': '[]'})
changed: [10.10.10.13] => (item={'name': 'primary', 'src_ip': '*', 'src_port': 5433, 'dst_port': 'pgbouncer', 'check_url': '/primary', 'selector': '[]'})
changed: [10.10.10.10] => (item={'name': 'replica', 'src_ip': '*', 'src_port': 5434, 'dst_port': 'pgbouncer', 'check_url': '/read-only', 'selector': '[]', 'selector_backup': '[? pg_role == `primary`]'})
changed: [10.10.10.12] => (item={'name': 'replica', 'src_ip': '*', 'src_port': 5434, 'dst_port': 'pgbouncer', 'check_url': '/read-only', 'selector': '[]', 'selector_backup': '[? pg_role == `primary`]'})
changed: [10.10.10.13] => (item={'name': 'replica', 'src_ip': '*', 'src_port': 5434, 'dst_port': 'pgbouncer', 'check_url': '/read-only', 'selector': '[]', 'selector_backup': '[? pg_role == `primary`]'})
changed: [10.10.10.11] => (item={'name': 'replica', 'src_ip': '*', 'src_port': 5434, 'dst_port': 'pgbouncer', 'check_url': '/read-only', 'selector': '[]', 'selector_backup': '[? pg_role == `primary`]'})
changed: [10.10.10.10] => (item={'name': 'default', 'src_ip': '*', 'src_port': 5436, 'dst_port': 'postgres', 'check_method': 'http', 'check_port': 'patroni', 'check_url': '/primary', 'check_code': 200, 'selector': '[]', 'haproxy': {'maxconn': 3000, 'balance': 'roundrobin', 'default_server_options': 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'}})
changed: [10.10.10.12] => (item={'name': 'default', 'src_ip': '*', 'src_port': 5436, 'dst_port': 'postgres', 'check_method': 'http', 'check_port': 'patroni', 'check_url': '/primary', 'check_code': 200, 'selector': '[]', 'haproxy': {'maxconn': 3000, 'balance': 'roundrobin', 'default_server_options': 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'}})
changed: [10.10.10.11] => (item={'name': 'default', 'src_ip': '*', 'src_port': 5436, 'dst_port': 'postgres', 'check_method': 'http', 'check_port': 'patroni', 'check_url': '/primary', 'check_code': 200, 'selector': '[]', 'haproxy': {'maxconn': 3000, 'balance': 'roundrobin', 'default_server_options': 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'}})
changed: [10.10.10.13] => (item={'name': 'default', 'src_ip': '*', 'src_port': 5436, 'dst_port': 'postgres', 'check_method': 'http', 'check_port': 'patroni', 'check_url': '/primary', 'check_code': 200, 'selector': '[]', 'haproxy': {'maxconn': 3000, 'balance': 'roundrobin', 'default_server_options': 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'}})
changed: [10.10.10.10] => (item={'name': 'offline', 'src_ip': '*', 'src_port': 5438, 'dst_port': 'postgres', 'check_url': '/replica', 'selector': '[? pg_role == `offline` || pg_offline_query ]', 'selector_backup': '[? pg_role == `replica` && !pg_offline_query]'})
changed: [10.10.10.12] => (item={'name': 'offline', 'src_ip': '*', 'src_port': 5438, 'dst_port': 'postgres', 'check_url': '/replica', 'selector': '[? pg_role == `offline` || pg_offline_query ]', 'selector_backup': '[? pg_role == `replica` && !pg_offline_query]'})
changed: [10.10.10.11] => (item={'name': 'offline', 'src_ip': '*', 'src_port': 5438, 'dst_port': 'postgres', 'check_url': '/replica', 'selector': '[? pg_role == `offline` || pg_offline_query ]', 'selector_backup': '[? pg_role == `replica` && !pg_offline_query]'})
changed: [10.10.10.13] => (item={'name': 'offline', 'src_ip': '*', 'src_port': 5438, 'dst_port': 'postgres', 'check_url': '/replica', 'selector': '[? pg_role == `offline` || pg_offline_query ]', 'selector_backup': '[? pg_role == `replica` && !pg_offline_query]'})
TASK [service : Reload haproxy consul service] ***********************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [service : Make sure vip-manager is installed] ******************************************************************************************************************************************************
ok: [10.10.10.10]
ok: [10.10.10.13]
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [service : Copy vip-manager systemd service file] ***************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.12]
changed: [10.10.10.11]
changed: [10.10.10.13]
TASK [service : create vip-manager systemd drop-in dir] **************************************************************************************************************************************************
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.10]
changed: [10.10.10.13]
TASK [service : create vip-manager systemd drop-in file] *************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.13]
changed: [10.10.10.12]
changed: [10.10.10.11]
TASK [service : Templating /etc/default/vip-manager.yml] *************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.12]
changed: [10.10.10.13]
TASK [service : Launch vip-manager] **********************************************************************************************************************************************************************
changed: [10.10.10.10]
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.12]
TASK [service : Fetch postgres cluster memberships] ******************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
TASK [service : Render L4 VIP configs] *******************************************************************************************************************************************************************
skipping: [10.10.10.10] => (item={'name': 'primary', 'src_ip': '*', 'src_port': 5433, 'dst_port': 'pgbouncer', 'check_url': '/primary', 'selector': '[]'})
skipping: [10.10.10.10] => (item={'name': 'replica', 'src_ip': '*', 'src_port': 5434, 'dst_port': 'pgbouncer', 'check_url': '/read-only', 'selector': '[]', 'selector_backup': '[? pg_role == `primary`]'})
skipping: [10.10.10.10] => (item={'name': 'default', 'src_ip': '*', 'src_port': 5436, 'dst_port': 'postgres', 'check_method': 'http', 'check_port': 'patroni', 'check_url': '/primary', 'check_code': 200, 'selector': '[]', 'haproxy': {'maxconn': 3000, 'balance': 'roundrobin', 'default_server_options': 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'}})
skipping: [10.10.10.11] => (item={'name': 'primary', 'src_ip': '*', 'src_port': 5433, 'dst_port': 'pgbouncer', 'check_url': '/primary', 'selector': '[]'})
skipping: [10.10.10.10] => (item={'name': 'offline', 'src_ip': '*', 'src_port': 5438, 'dst_port': 'postgres', 'check_url': '/replica', 'selector': '[? pg_role == `offline` || pg_offline_query ]', 'selector_backup': '[? pg_role == `replica` && !pg_offline_query]'})
skipping: [10.10.10.11] => (item={'name': 'replica', 'src_ip': '*', 'src_port': 5434, 'dst_port': 'pgbouncer', 'check_url': '/read-only', 'selector': '[]', 'selector_backup': '[? pg_role == `primary`]'})
skipping: [10.10.10.11] => (item={'name': 'default', 'src_ip': '*', 'src_port': 5436, 'dst_port': 'postgres', 'check_method': 'http', 'check_port': 'patroni', 'check_url': '/primary', 'check_code': 200, 'selector': '[]', 'haproxy': {'maxconn': 3000, 'balance': 'roundrobin', 'default_server_options': 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'}})
skipping: [10.10.10.12] => (item={'name': 'primary', 'src_ip': '*', 'src_port': 5433, 'dst_port': 'pgbouncer', 'check_url': '/primary', 'selector': '[]'})
skipping: [10.10.10.11] => (item={'name': 'offline', 'src_ip': '*', 'src_port': 5438, 'dst_port': 'postgres', 'check_url': '/replica', 'selector': '[? pg_role == `offline` || pg_offline_query ]', 'selector_backup': '[? pg_role == `replica` && !pg_offline_query]'})
skipping: [10.10.10.12] => (item={'name': 'replica', 'src_ip': '*', 'src_port': 5434, 'dst_port': 'pgbouncer', 'check_url': '/read-only', 'selector': '[]', 'selector_backup': '[? pg_role == `primary`]'})
skipping: [10.10.10.13] => (item={'name': 'primary', 'src_ip': '*', 'src_port': 5433, 'dst_port': 'pgbouncer', 'check_url': '/primary', 'selector': '[]'})
skipping: [10.10.10.12] => (item={'name': 'default', 'src_ip': '*', 'src_port': 5436, 'dst_port': 'postgres', 'check_method': 'http', 'check_port': 'patroni', 'check_url': '/primary', 'check_code': 200, 'selector': '[]', 'haproxy': {'maxconn': 3000, 'balance': 'roundrobin', 'default_server_options': 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'}})
skipping: [10.10.10.13] => (item={'name': 'replica', 'src_ip': '*', 'src_port': 5434, 'dst_port': 'pgbouncer', 'check_url': '/read-only', 'selector': '[]', 'selector_backup': '[? pg_role == `primary`]'})
skipping: [10.10.10.12] => (item={'name': 'offline', 'src_ip': '*', 'src_port': 5438, 'dst_port': 'postgres', 'check_url': '/replica', 'selector': '[? pg_role == `offline` || pg_offline_query ]', 'selector_backup': '[? pg_role == `replica` && !pg_offline_query]'})
skipping: [10.10.10.13] => (item={'name': 'default', 'src_ip': '*', 'src_port': 5436, 'dst_port': 'postgres', 'check_method': 'http', 'check_port': 'patroni', 'check_url': '/primary', 'check_code': 200, 'selector': '[]', 'haproxy': {'maxconn': 3000, 'balance': 'roundrobin', 'default_server_options': 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'}})
skipping: [10.10.10.13] => (item={'name': 'offline', 'src_ip': '*', 'src_port': 5438, 'dst_port': 'postgres', 'check_url': '/replica', 'selector': '[? pg_role == `offline` || pg_offline_query ]', 'selector_backup': '[? pg_role == `replica` && !pg_offline_query]'})
TASK [service : include_tasks] ***************************************************************************************************************************************************************************
skipping: [10.10.10.10]
skipping: [10.10.10.11]
skipping: [10.10.10.12]
skipping: [10.10.10.13]
PLAY RECAP ***********************************************************************************************************************************************************************************************
10.10.10.10 : ok=264 changed=205 unreachable=0 failed=0 skipped=62 rescued=0 ignored=0
10.10.10.11 : ok=182 changed=146 unreachable=0 failed=0 skipped=55 rescued=0 ignored=0
10.10.10.12 : ok=171 changed=135 unreachable=0 failed=0 skipped=66 rescued=0 ignored=0
10.10.10.13 : ok=171 changed=135 unreachable=0 failed=0 skipped=66 rescued=0 ignored=0
烈建议在第一次完成初始化后执行 make cache 命令,该命令会将下载好的软件打为离线缓存包,并放置于files/pkg.tgz中。这样当下一次创建新的pigsty环境时,只要宿主机内操作系统一致,就可以直接复用该离线包,省去大量下载时间。
mon-view
初始化完毕后,您可以通过浏览器访问 http://pigsty 前往监控系统主页。默认的用户名与密码均为admin
如果没有配置DNS,或者没有使用默认的IP地址,也可以直接访问 http://meta_ip_address:3000前往监控系统首页。
$ make mon-view
open -n 'http://g.pigsty/'
9.7 - PG Exporter
PG Exporter reference
PG Exporter
Prometheus exporter for PostgreSQL metrics. Gives you complete insight on your favourate elephant!
Latest binaries & rpms can be found on release page. Supported pg version: PostgreSQL 9.4+ & Pgbouncer 1.8+. Default collectors definition is compatible with PostgreSQL 10,11,12,13.
Latest pg_exporter version: 0.3.1
Features
- Support both Postgres & Pgbouncer
- Flexible: Almost all metrics are defined in customizable configuration files in SQL style.
- Fine-grained execution control (Tags Filter, Facts Filter, Version Filter, Timeout, Cache, etc…)
- Dynamic Planning: User could provide multiple branches of a metric queries. Queries matches server version & fact & tag will be actually installed.
- Configurable caching policy & query timeout
- Rich metrics about
pg_exporter itself.
- Auto discovery multi database in the same cluster (multiple database scrape TBD)
- Tested and verified in real world production environment for years (200+ Nodes)
- Metrics overhelming! Gives you complete insight on your favourate elephant!
- (Pgbouncer mode is enabled when target dbname is
pgbouncer)
性能表现

对于极端场景(几十万张表与几万种查询),一次抓取最多可能耗费秒级的时长。
好在所有指标收集器都是可选关闭的,且pg_exporter 允许为收集器配置主动超时取消(默认100ms)

自监控
Exporter展示了监控系统组件本身的监控指标,包括:
- Exporter是否存活,Uptime,Exporter每分钟被抓取的次数
- 每个监控查询的耗时,产生的指标数量与错误数量。
Prometheus的配置
Prometheus的抓取频率建议采用10~15秒,并配置适当的超时。
演示或特殊情况也可以配置的更精细(例如2秒,5秒等)
单Prometheus节点可以支持几百个实例的监控,约几百万个时间序列 (Dell R740 64 Core / 400GB Mem/ 3TB PCI-E SSD)
更大规模的集群可以通过Prometheus级联、联邦或分片实现伸缩。例如为每一个数据库集群部署一个Prometheus,并使用上级Prometheus统筹抓取并计算衍生指标
9.8 - Prometheus Service Discovery
How to perform static service discovery for Prometheus
当使用 prometheus_sd_method == ‘static’ 的静态文件服务发现模式时,Prometheus会使用静态文件进行服务发现,目标配置文件地址默认为 /etc/prometheus/targets/ 目录中的所有yml文件。
集中式配置
当 prometheus_sd_target 配置为batch 模式时,Pigsty会采用集中式配置管理Prometheus监控目标。
所有监控对象都定义于单一配置文件:/etc/prometheus/targets/all.yml 中。
#==============================================================#
# File : targets/all.yml
# Ctime : 2021-02-18
# Mtime : 2021-02-18
# Atime : 2021-03-01 16:46
# Note : Managed by Ansible
# Desc : Prometheus Static Monitoring Targets Definition
# Path : /etc/prometheus/targets/all.yml
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
# static monitor targets, batch version
#======> pg-meta-1 [primary]
- labels: {cls: pg-meta, ins: pg-meta-1, ip: 10.10.10.10, role: primary, svc: pg-meta-primary}
targets: [10.10.10.10:9630, 10.10.10.10:9100, 10.10.10.10:9631, 10.10.10.10:9101]
#======> pg-test-1 [primary]
- labels: {cls: pg-test, ins: pg-test-1, ip: 10.10.10.11, role: primary, svc: pg-test-primary}
targets: [10.10.10.11:9630, 10.10.10.11:9100, 10.10.10.11:9631, 10.10.10.11:9101]
#======> pg-test-2 [replica]
- labels: {cls: pg-test, ins: pg-test-2, ip: 10.10.10.12, role: replica, svc: pg-test-replica}
targets: [10.10.10.12:9630, 10.10.10.12:9100, 10.10.10.12:9631, 10.10.10.12:9101]
#======> pg-test-3 [replica]
- labels: {cls: pg-test, ins: pg-test-3, ip: 10.10.10.13, role: replica, svc: pg-test-replica}
targets: [10.10.10.13:9630, 10.10.10.13:9100, 10.10.10.13:9631, 10.10.10.13:9101]
分立式配置
当 prometheus_sd_target 配置为single 模式时,Pigsty会采用分立式配置管理Prometheus监控目标。
每个监控实例,都拥有自己独占的单一配置文件:/etc/prometheus/targets/{{ pg_instance }}.yml 中。
以 pg-meta-1 实例为例,其配置文件位置为:/etc/prometheus/targets/pg-meta-1.yml,内容为:
# pg-meta-1 [primary]
- labels: {cls: pg-meta, ins: pg-meta-1, ip: 10.10.10.10, role: primary, svc: pg-meta-primary}
targets: [10.10.10.10:9630, 10.10.10.10:9100, 10.10.10.10:9631, 10.10.10.10:9101]
9.9 - Tuned Template
Several pre-defined tuned templates
9.9.1 - OLTP
Tuned OLTP模板
Tuned OLTP模板主要针对延迟进行优化,此模板针对的机型是Dell R740 64核/400GB内存,使用PCI-E SSD的节点。您可以根据自己的实际机型进行调整。
# tuned configuration
#==============================================================#
# File : tuned.conf
# Mtime : 2020-06-29
# Desc : Tune operatiing system to oltp mode
# Path : /etc/tuned/oltp/tuned.conf
# Author : Vonng(fengruohang@outlook.com)
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
[main]
summary=Optimize for PostgreSQL OLTP System
include=network-latency
[cpu]
force_latency=1
governor=performance
energy_perf_bias=performance
min_perf_pct=100
[vm]
# disable transparent hugepages
transparent_hugepages=never
[sysctl]
#-------------------------------------------------------------#
# KERNEL #
#-------------------------------------------------------------#
# disable numa balancing
kernel.numa_balancing=0
# total shmem size in bytes: $(expr $(getconf _PHYS_PAGES) / 2 \* $(getconf PAGE_SIZE))
{% if param_shmall is defined and param_shmall != '' %}
kernel.shmall = {{ param_shmall }}
{% endif %}
# total shmem size in pages: $(expr $(getconf _PHYS_PAGES) / 2)
{% if param_shmmax is defined and param_shmmax != '' %}
kernel.shmmax = {{ param_shmmax }}
{% endif %}
# total shmem segs 4096 -> 8192
kernel.shmmni=8192
# total msg queue number, set to mem size in MB
kernel.msgmni=32768
# max length of message queue
kernel.msgmnb=65536
# max size of message
kernel.msgmax=65536
kernel.pid_max=131072
# max(Sem in Set)=2048, max(Sem)=max(Sem in Set) x max(SemSet) , max(Sem per Ops)=2048, max(SemSet)=65536
kernel.sem=2048 134217728 2048 65536
# do not sched postgres process in group
kernel.sched_autogroup_enabled = 0
# total time the scheduler will consider a migrated process cache hot and, thus, less likely to be remigrated
# defaut = 0.5ms (500000ns), update to 5ms , depending on your typical query (e.g < 1ms)
kernel.sched_migration_cost_ns=5000000
#-------------------------------------------------------------#
# VM #
#-------------------------------------------------------------#
# try not using swap
vm.swappiness=0
# disable when most mem are for file cache
vm.zone_reclaim_mode=0
# overcommit threshhold = 80%
vm.overcommit_memory=2
vm.overcommit_ratio=80
# vm.dirty_background_bytes=67108864 # 64MB mem (2xRAID cache) wake the bgwriter
vm.dirty_background_ratio=3 # latency-performance default
vm.dirty_ratio=10 # latency-performance default
# deny access on 0x00000 - 0x10000
vm.mmap_min_addr=65536
#-------------------------------------------------------------#
# Filesystem #
#-------------------------------------------------------------#
# max open files: 382589 -> 167772160
fs.file-max=167772160
# max concurrent unfinished async io, should be larger than 1M. 65536->1M
fs.aio-max-nr=1048576
#-------------------------------------------------------------#
# Network #
#-------------------------------------------------------------#
# max connection in listen queue (triggers retrans if full)
net.core.somaxconn=65535
net.core.netdev_max_backlog=8192
# tcp receive/transmit buffer default = 256KiB
net.core.rmem_default=262144
net.core.wmem_default=262144
# receive/transmit buffer limit = 4MiB
net.core.rmem_max=4194304
net.core.wmem_max=4194304
# ip options
net.ipv4.ip_forward=1
net.ipv4.ip_nonlocal_bind=1
net.ipv4.ip_local_port_range=32768 65000
# tcp options
net.ipv4.tcp_timestamps=1
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_recycle=0
net.ipv4.tcp_syncookies=0
net.ipv4.tcp_synack_retries=1
net.ipv4.tcp_syn_retries=1
# tcp read/write buffer
net.ipv4.tcp_rmem="4096 87380 16777216"
net.ipv4.tcp_wmem="4096 16384 16777216"
net.ipv4.udp_mem="3145728 4194304 16777216"
# tcp probe fail interval: 75s -> 20s
net.ipv4.tcp_keepalive_intvl=20
# tcp break after 3 * 20s = 1m
net.ipv4.tcp_keepalive_probes=3
# probe peroid = 1 min
net.ipv4.tcp_keepalive_time=60
net.ipv4.tcp_fin_timeout=5
net.ipv4.tcp_max_tw_buckets=262144
net.ipv4.tcp_max_syn_backlog=8192
net.ipv4.neigh.default.gc_thresh1=80000
net.ipv4.neigh.default.gc_thresh2=90000
net.ipv4.neigh.default.gc_thresh3=100000
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-arptables=1
# max connection tracking number
net.netfilter.nf_conntrack_max=1048576
9.9.2 - TINY
Tuned TINY模板
Tuned TINY模板主要针对极低配置的虚拟机进行优化,
此模板针对的典型机型是1核/1GB的虚拟机节点。您可以根据自己的实际机型进行调整。
# tuned configuration
#==============================================================#
# File : tuned.conf
# Mtime : 2020-06-29
# Desc : Tune operatiing system to tiny mode
# Path : /etc/tuned/tiny/tuned.conf
# Author : Vonng(fengruohang@outlook.com)
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
[main]
summary=Optimize for PostgreSQL TINY System
# include=virtual-guest
[vm]
# disable transparent hugepages
transparent_hugepages=never
[sysctl]
#-------------------------------------------------------------#
# KERNEL #
#-------------------------------------------------------------#
# disable numa balancing
kernel.numa_balancing=0
# If a workload mostly uses anonymous memory and it hits this limit, the entire
# working set is buffered for I/O, and any more write buffering would require
# swapping, so it's time to throttle writes until I/O can catch up. Workloads
# that mostly use file mappings may be able to use even higher values.
#
# The generator of dirty data starts writeback at this percentage (system default
# is 20%)
vm.dirty_ratio = 40
# Filesystem I/O is usually much more efficient than swapping, so try to keep
# swapping low. It's usually safe to go even lower than this on systems with
# server-grade storage.
vm.swappiness = 30
#-------------------------------------------------------------#
# Network #
#-------------------------------------------------------------#
# tcp options
net.ipv4.tcp_timestamps=1
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_recycle=0
net.ipv4.tcp_syncookies=0
net.ipv4.tcp_synack_retries=1
net.ipv4.tcp_syn_retries=1
# tcp probe fail interval: 75s -> 20s
net.ipv4.tcp_keepalive_intvl=20
# tcp break after 3 * 20s = 1m
net.ipv4.tcp_keepalive_probes=3
# probe peroid = 1 min
net.ipv4.tcp_keepalive_time=60
9.9.3 - OLAP
Tuned OLAP模板,针对高并行,长查询,高吞吐实例优化
Tuned OLAP模板主要针对吞吐量与计算并行度进行优化
此模板针对的机型是Dell R740 64核/400GB内存,使用PCI-E SSD的节点。您可以根据自己的实际机型进行调整。
# tuned configuration
#==============================================================#
# File : tuned.conf
# Mtime : 2020-09-18
# Desc : Tune operatiing system to olap mode
# Path : /etc/tuned/olap/tuned.conf
# Author : Vonng(fengruohang@outlook.com)
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
[main]
summary=Optimize for PostgreSQL OLAP System
include=network-throughput
[cpu]
force_latency=1
governor=performance
energy_perf_bias=performance
min_perf_pct=100
[vm]
# disable transparent hugepages
transparent_hugepages=never
[sysctl]
#-------------------------------------------------------------#
# KERNEL #
#-------------------------------------------------------------#
# disable numa balancing
kernel.numa_balancing=0
# total shmem size in bytes: $(expr $(getconf _PHYS_PAGES) / 2 \* $(getconf PAGE_SIZE))
{% if param_shmall is defined and param_shmall != '' %}
kernel.shmall = {{ param_shmall }}
{% endif %}
# total shmem size in pages: $(expr $(getconf _PHYS_PAGES) / 2)
{% if param_shmmax is defined and param_shmmax != '' %}
kernel.shmmax = {{ param_shmmax }}
{% endif %}
# total shmem segs 4096 -> 8192
kernel.shmmni=8192
# total msg queue number, set to mem size in MB
kernel.msgmni=32768
# max length of message queue
kernel.msgmnb=65536
# max size of message
kernel.msgmax=65536
kernel.pid_max=131072
# max(Sem in Set)=2048, max(Sem)=max(Sem in Set) x max(SemSet) , max(Sem per Ops)=2048, max(SemSet)=65536
kernel.sem=2048 134217728 2048 65536
# do not sched postgres process in group
kernel.sched_autogroup_enabled = 0
# total time the scheduler will consider a migrated process cache hot and, thus, less likely to be remigrated
# defaut = 0.5ms (500000ns), update to 5ms , depending on your typical query (e.g < 1ms)
kernel.sched_migration_cost_ns=5000000
#-------------------------------------------------------------#
# VM #
#-------------------------------------------------------------#
# try not using swap
# vm.swappiness=10
# disable when most mem are for file cache
vm.zone_reclaim_mode=0
# overcommit threshhold = 80%
vm.overcommit_memory=2
vm.overcommit_ratio=80
vm.dirty_background_ratio = 10 # throughput-performance default
vm.dirty_ratio=80 # throughput-performance default 40 -> 80
# deny access on 0x00000 - 0x10000
vm.mmap_min_addr=65536
#-------------------------------------------------------------#
# Filesystem #
#-------------------------------------------------------------#
# max open files: 382589 -> 167772160
fs.file-max=167772160
# max concurrent unfinished async io, should be larger than 1M. 65536->1M
fs.aio-max-nr=1048576
#-------------------------------------------------------------#
# Network #
#-------------------------------------------------------------#
# max connection in listen queue (triggers retrans if full)
net.core.somaxconn=65535
net.core.netdev_max_backlog=8192
# tcp receive/transmit buffer default = 256KiB
net.core.rmem_default=262144
net.core.wmem_default=262144
# receive/transmit buffer limit = 4MiB
net.core.rmem_max=4194304
net.core.wmem_max=4194304
# ip options
net.ipv4.ip_forward=1
net.ipv4.ip_nonlocal_bind=1
net.ipv4.ip_local_port_range=32768 65000
# tcp options
net.ipv4.tcp_timestamps=1
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_recycle=0
net.ipv4.tcp_syncookies=0
net.ipv4.tcp_synack_retries=1
net.ipv4.tcp_syn_retries=1
# tcp read/write buffer
net.ipv4.tcp_rmem="4096 87380 16777216"
net.ipv4.tcp_wmem="4096 16384 16777216"
net.ipv4.udp_mem="3145728 4194304 16777216"
# tcp probe fail interval: 75s -> 20s
net.ipv4.tcp_keepalive_intvl=20
# tcp break after 3 * 20s = 1m
net.ipv4.tcp_keepalive_probes=3
# probe peroid = 1 min
net.ipv4.tcp_keepalive_time=60
net.ipv4.tcp_fin_timeout=5
net.ipv4.tcp_max_tw_buckets=262144
net.ipv4.tcp_max_syn_backlog=8192
net.ipv4.neigh.default.gc_thresh1=80000
net.ipv4.neigh.default.gc_thresh2=90000
net.ipv4.neigh.default.gc_thresh3=100000
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-arptables=1
# max connection tracking number
net.netfilter.nf_conntrack_max=1048576
9.9.4 - CRIT
Tuned CRIT模板,针对金融场景、不允许数据丢失错漏的场景进行优化。
Tuned CRIT模板主要针对RPO进行优化,尽可能减少内存中脏数据的量。
此模板针对的机型是Dell R740 64核/400GB内存,使用PCI-E SSD的节点。您可以根据自己的实际机型进行调整。
# tuned configuration
#==============================================================#
# File : tuned.conf
# Mtime : 2020-06-29
# Desc : Tune operatiing system to crit mode
# Path : /etc/tuned/crit/tuned.conf
# Author : Vonng(fengruohang@outlook.com)
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
[main]
summary=Optimize for PostgreSQL CRIT System
include=network-latency
[cpu]
force_latency=1
governor=performance
energy_perf_bias=performance
min_perf_pct=100
[vm]
# disable transparent hugepages
transparent_hugepages=never
[sysctl]
#-------------------------------------------------------------#
# KERNEL #
#-------------------------------------------------------------#
# disable numa balancing
kernel.numa_balancing=0
# total shmem size in bytes: $(expr $(getconf _PHYS_PAGES) / 2 \* $(getconf PAGE_SIZE))
{% if param_shmall is defined and param_shmall != '' %}
kernel.shmall = {{ param_shmall }}
{% endif %}
# total shmem size in pages: $(expr $(getconf _PHYS_PAGES) / 2)
{% if param_shmmax is defined and param_shmmax != '' %}
kernel.shmmax = {{ param_shmmax }}
{% endif %}
# total shmem segs 4096 -> 8192
kernel.shmmni=8192
# total msg queue number, set to mem size in MB
kernel.msgmni=32768
# max length of message queue
kernel.msgmnb=65536
# max size of message
kernel.msgmax=65536
kernel.pid_max=131072
# max(Sem in Set)=2048, max(Sem)=max(Sem in Set) x max(SemSet) , max(Sem per Ops)=2048, max(SemSet)=65536
kernel.sem=2048 134217728 2048 65536
# do not sched postgres process in group
kernel.sched_autogroup_enabled = 0
# total time the scheduler will consider a migrated process cache hot and, thus, less likely to be remigrated
# defaut = 0.5ms (500000ns), update to 5ms , depending on your typical query (e.g < 1ms)
kernel.sched_migration_cost_ns=5000000
#-------------------------------------------------------------#
# VM #
#-------------------------------------------------------------#
# try not using swap
vm.swappiness=0
# disable when most mem are for file cache
vm.zone_reclaim_mode=0
# overcommit threshhold = 80%
vm.overcommit_memory=2
vm.overcommit_ratio=100
# 64MB mem (2xRAID cache) wake the bgwriter
vm.dirty_background_bytes=67108864
# vm.dirty_background_ratio=3 # latency-performance default
vm.dirty_ratio=6 # latency-performance default
# deny access on 0x00000 - 0x10000
vm.mmap_min_addr=65536
#-------------------------------------------------------------#
# Filesystem #
#-------------------------------------------------------------#
# max open files: 382589 -> 167772160
fs.file-max=167772160
# max concurrent unfinished async io, should be larger than 1M. 65536->1M
fs.aio-max-nr=1048576
#-------------------------------------------------------------#
# Network #
#-------------------------------------------------------------#
# max connection in listen queue (triggers retrans if full)
net.core.somaxconn=65535
net.core.netdev_max_backlog=8192
# tcp receive/transmit buffer default = 256KiB
net.core.rmem_default=262144
net.core.wmem_default=262144
# receive/transmit buffer limit = 4MiB
net.core.rmem_max=4194304
net.core.wmem_max=4194304
# ip options
net.ipv4.ip_forward=1
net.ipv4.ip_nonlocal_bind=1
net.ipv4.ip_local_port_range=32768 65000
# tcp options
net.ipv4.tcp_timestamps=1
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_recycle=0
net.ipv4.tcp_syncookies=0
net.ipv4.tcp_synack_retries=1
net.ipv4.tcp_syn_retries=1
# tcp read/write buffer
net.ipv4.tcp_rmem="4096 87380 16777216"
net.ipv4.tcp_wmem="4096 16384 16777216"
net.ipv4.udp_mem="3145728 4194304 16777216"
# tcp probe fail interval: 75s -> 20s
net.ipv4.tcp_keepalive_intvl=20
# tcp break after 3 * 20s = 1m
net.ipv4.tcp_keepalive_probes=3
# probe peroid = 1 min
net.ipv4.tcp_keepalive_time=60
net.ipv4.tcp_fin_timeout=5
net.ipv4.tcp_max_tw_buckets=262144
net.ipv4.tcp_max_syn_backlog=8192
net.ipv4.neigh.default.gc_thresh1=80000
net.ipv4.neigh.default.gc_thresh2=90000
net.ipv4.neigh.default.gc_thresh3=100000
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-arptables=1
# max connection tracking number
net.netfilter.nf_conntrack_max=1048576
9.10 - Patroni Template
Four pre-defined patroni templates
Pigsty使用Patroni管理与初始化Postgres数据库集群。
Pigsty使用Patroni完成供给的主体工作,即使用户选择了无Patroni模式,拉起数据库集群也会由Patroni负责,并在创建完成后移除Patroni组件。
用户可以通过Patroni配置文件,完成大部分的PostgreSQL集群定制工作,Patroni配置文件格式详情请参考 Patroni官方文档。
预定义模板
Pigsty提供了四种预定义的初始化模板,初始化模板是用于初始化数据库集群的定义文件,默认位于roles/postgres/templates/。包括:
oltp.yml OLTP模板,默认配置,针对生产机型优化延迟与性能。- `olap.yml OLAP模板,提高并行度,针对吞吐量,长查询进行优化。
crit.yml) 核心业务模板,基于OLTP模板针对RPO、安全性、数据完整性进行优化,启用同步复制与数据校验和。tiny.yml 微型数据库模板,针对低资源场景进行优化,例如运行于虚拟机中的演示数据库集群。
通过 pg_conf 参数指定所需使用的模板路径,如果使用预制模板,则只需填入模板文件名称即可。
如果使用定制的 Patroni配置模板,通常也应当针对机器节点使用配套的 节点优化模板。
更详细的配置信息,请参考 PG供给
9.10.1 - OLTP
Patroni OLTP模板
Patroni OLTP模板主要针对延迟进行优化,此模板针对的机型是Dell R740 64核/400GB内存,使用PCI-E SSD的节点。您可以根据自己的实际机型进行调整。
#!/usr/bin/env patroni
#==============================================================#
# File : patroni.yml
# Ctime : 2020-04-08
# Mtime : 2020-12-22
# Desc : patroni cluster definition for {{ pg_cluster }} (oltp)
# Path : /pg/bin/patroni.yml
# Real Path : /pg/conf/{{ pg_instance }}.yml
# Link : /pg/bin/patroni.yml -> /pg/conf/{{ pg_instance}}.yml
# Note : Transactional Database Cluster Template
# Doc : https://patroni.readthedocs.io/en/latest/SETTINGS.html
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
# OLTP database are optimized for performance, rt latency
# typical spec: 64 Core | 400 GB RAM | PCI-E SSD xTB
---
#------------------------------------------------------------------------------
# identity
#------------------------------------------------------------------------------
namespace: {{ pg_namespace }}/ # namespace
scope: {{ pg_cluster }} # cluster name
name: {{ pg_instance }} # instance name
#------------------------------------------------------------------------------
# log
#------------------------------------------------------------------------------
log:
level: INFO # NOTEST|DEBUG|INFO|WARNING|ERROR|CRITICAL
dir: /pg/log/ # default log file: /pg/log/patroni.log
file_size: 100000000 # 100MB log triggers a log rotate
# format: '%(asctime)s %(levelname)s: %(message)s'
#------------------------------------------------------------------------------
# dcs
#------------------------------------------------------------------------------
consul:
host: 127.0.0.1:8500
consistency: default # default|consistent|stale
register_service: true
service_check_interval: 15s
service_tags:
- {{ pg_cluster }}
#------------------------------------------------------------------------------
# api
#------------------------------------------------------------------------------
# how to expose patroni service
# listen on all ipv4, connect via public ip, use same credential as dbuser_monitor
restapi:
listen: 0.0.0.0:{{ patroni_port }}
connect_address: {{ inventory_hostname }}:{{ patroni_port }}
authentication:
verify_client: none # none|optional|required
username: {{ pg_monitor_username }}
password: '{{ pg_monitor_password }}'
#------------------------------------------------------------------------------
# ctl
#------------------------------------------------------------------------------
ctl:
optional:
insecure: true
# cacert: '/path/to/ca/cert'
# certfile: '/path/to/cert/file'
# keyfile: '/path/to/key/file'
#------------------------------------------------------------------------------
# tags
#------------------------------------------------------------------------------
tags:
nofailover: false
clonefrom: true
noloadbalance: false
nosync: false
{% if pg_upstream is defined %}
replicatefrom: {{ pg_upstream }} # clone from another replica rather than primary
{% endif %}
#------------------------------------------------------------------------------
# watchdog
#------------------------------------------------------------------------------
# available mode: off|automatic|required
watchdog:
mode: {{ patroni_watchdog_mode }}
device: /dev/watchdog
# safety_margin: 10s
#------------------------------------------------------------------------------
# bootstrap
#------------------------------------------------------------------------------
bootstrap:
#----------------------------------------------------------------------------
# bootstrap method
#----------------------------------------------------------------------------
method: initdb
# add custom bootstrap method here
# default bootstrap method: initdb
initdb:
- locale: C
- encoding: UTF8
# - data-checksums # enable data-checksum
#----------------------------------------------------------------------------
# bootstrap users
#---------------------------------------------------------------------------
# additional users which need to be created after initializing new cluster
# replication user and monitor user are required
users:
{{ pg_replication_username }}:
password: '{{ pg_replication_password }}'
{{ pg_monitor_username }}:
password: '{{ pg_monitor_password }}'
{{ pg_admin_username }}:
password: '{{ pg_admin_password }}'
# bootstrap hba, allow local and intranet password access & replication
# will be overwritten later
pg_hba:
- local all postgres ident
- local all all md5
- host all all 0.0.0.0/0 md5
- local replication postgres ident
- local replication all md5
- host replication all 0.0.0.0/0 md5
#----------------------------------------------------------------------------
# template
#---------------------------------------------------------------------------
# post_init: /pg/bin/pg-init
#----------------------------------------------------------------------------
# bootstrap config
#---------------------------------------------------------------------------
# this section will be written to /{{ pg_namespace }}/{{ pg_cluster }}/config
# if will NOT take any effect after cluster bootstrap
dcs:
{% if pg_role == 'primary' and pg_upstream is defined %}
#----------------------------------------------------------------------------
# standby cluster definition
#---------------------------------------------------------------------------
standby_cluster:
host: {{ pg_upstream }}
port: {{ pg_port }}
# primary_slot_name: patroni # must be create manually on upstream server, if specified
create_replica_methods:
- basebackup
{% endif %}
#----------------------------------------------------------------------------
# important parameters
#---------------------------------------------------------------------------
# constraint: ttl >: loop_wait + retry_timeout * 2
# the number of seconds the loop will sleep. Default value: 10
# this is patroni check loop interval
loop_wait: 10
# the TTL to acquire the leader lock (in seconds). Think of it as the length of time before initiation of the automatic failover process. Default value: 30
# config this according to your network condition to avoid false-positive failover
ttl: 30
# timeout for DCS and PostgreSQL operation retries (in seconds). DCS or network issues shorter than this will not cause Patroni to demote the leader. Default value: 10
retry_timeout: 10
# the amount of time a master is allowed to recover from failures before failover is triggered (in seconds)
# Max RTO: 2 loop wait + master_start_timeout
master_start_timeout: 10
# import: candidate will not be promoted if replication lag is higher than this
# maximum RPO: 1MB
maximum_lag_on_failover: 1048576
# The number of seconds Patroni is allowed to wait when stopping Postgres and effective only when synchronous_mode is enabled
master_stop_timeout: 30
# turns on synchronous replication mode. In this mode a replica will be chosen as synchronous and only the latest leader and synchronous replica are able to participate in leader election
# set to true for RPO mode
synchronous_mode: false
# prevents disabling synchronous replication if no synchronous replicas are available, blocking all client writes to the master
synchronous_mode_strict: false
#----------------------------------------------------------------------------
# postgres parameters
#---------------------------------------------------------------------------
postgresql:
use_slots: true
use_pg_rewind: true
remove_data_directory_on_rewind_failure: true
parameters:
#----------------------------------------------------------------------
# IMPORTANT PARAMETERS
#----------------------------------------------------------------------
max_connections: 400 # 100 -> 400
superuser_reserved_connections: 10 # reserve 10 connection for su
max_locks_per_transaction: 128 # 64 -> 128
max_prepared_transactions: 0 # 0 disable 2PC
track_commit_timestamp: on # enabled xact timestamp
max_worker_processes: 8 # default 8, set to cpu core
wal_level: logical # logical
wal_log_hints: on # wal log hints to support rewind
max_wal_senders: 16 # 10 -> 16
max_replication_slots: 16 # 10 -> 16
wal_keep_size: 100GB # keep at least 100GB WAL
password_encryption: md5 # use traditional md5 auth
#----------------------------------------------------------------------
# RESOURCE USAGE (except WAL)
#----------------------------------------------------------------------
# memory: shared_buffers and maintenance_work_mem will be dynamically set
shared_buffers: {{ pg_shared_buffers }}
maintenance_work_mem: {{ pg_maintenance_work_mem }}
work_mem: 32MB # 4MB -> 32MB
huge_pages: try # try huge pages
temp_file_limit: 100GB # 0 -> 100GB
vacuum_cost_delay: 2ms # wait 2ms per 10000 cost
vacuum_cost_limit: 10000 # 10000 cost each round
bgwriter_delay: 10ms # check dirty page every 10ms
bgwriter_lru_maxpages: 800 # 100 -> 800
bgwriter_lru_multiplier: 5.0 # 2.0 -> 5.0 more cushion buffer
#----------------------------------------------------------------------
# WAL
#----------------------------------------------------------------------
wal_buffers: 16MB # max to 16MB
wal_writer_delay: 20ms # wait period
wal_writer_flush_after: 1MB # max allowed data loss
min_wal_size: 100GB # at least 100GB WAL
max_wal_size: 400GB # at most 400GB WAL
commit_delay: 20 # 200ms -> 20ms, increase speed
commit_siblings: 10 # 5 -> 10
checkpoint_timeout: 60min # checkpoint 5min -> 1h
checkpoint_completion_target: 0.95 # 0.5 -> 0.95
archive_mode: on
archive_command: 'wal_dir=/pg/arcwal; [[ $(date +%H%M) == 1200 ]] && rm -rf ${wal_dir}/$(date -d"yesterday" +%Y%m%d); /bin/mkdir -p ${wal_dir}/$(date +%Y%m%d) && /usr/bin/lz4 -q -z %p > ${wal_dir}/$(date +%Y%m%d)/%f.lz4'
#----------------------------------------------------------------------
# REPLICATION
#----------------------------------------------------------------------
# synchronous_standby_names: ''
vacuum_defer_cleanup_age: 50000 # 0->50000 last 50000 xact changes will not be vacuumed
promote_trigger_file: promote.signal # default promote trigger file path
max_standby_archive_delay: 10min # max delay before canceling queries when reading WAL from archive;
max_standby_streaming_delay: 3min # max delay before canceling queries when reading streaming WAL;
wal_receiver_status_interval: 1s # send replies at least this often
hot_standby_feedback: on # send info from standby to prevent query conflicts
wal_receiver_timeout: 60s # time that receiver waits for
max_logical_replication_workers: 8 # 4 -> 8
max_sync_workers_per_subscription: 8 # 4 -> 8
#----------------------------------------------------------------------
# QUERY TUNING
#----------------------------------------------------------------------
# planner
# enable_partitionwise_join: on
random_page_cost: 1.1 # 4 for HDD, 1.1 for SSD
effective_cache_size: 320GB # max mem - shared buffer
default_statistics_target: 1000 # stat bucket 100 -> 1000
#----------------------------------------------------------------------
# REPORTING AND LOGGING
#----------------------------------------------------------------------
log_destination: csvlog # use standard csv log
logging_collector: on # enable csvlog
log_directory: log # default log dir: /pg/data/log
# log_filename: 'postgresql-%a.log' # weekly auto-recycle
log_filename: 'postgresql-%Y-%m-%d.log' # YYYY-MM-DD full log retention
log_checkpoints: on # log checkpoint info
log_lock_waits: on # log lock wait info
log_replication_commands: on # log replication info
log_statement: ddl # log ddl change
log_min_duration_statement: 100 # log slow query (>100ms)
#----------------------------------------------------------------------
# STATISTICS
#----------------------------------------------------------------------
track_io_timing: on # collect io statistics
track_functions: all # track all functions (none|pl|all)
track_activity_query_size: 8192 # max query length in pg_stat_activity
#----------------------------------------------------------------------
# AUTOVACUUM
#----------------------------------------------------------------------
log_autovacuum_min_duration: 1s # log autovacuum activity take more than 1s
autovacuum_max_workers: 3 # default autovacuum worker 3
autovacuum_naptime: 1min # default autovacuum naptime 1min
autovacuum_vacuum_scale_factor: 0.08 # fraction of table size before vacuum 20% -> 8%
autovacuum_analyze_scale_factor: 0.04 # fraction of table size before analyze 10% -> 4%
autovacuum_vacuum_cost_delay: -1 # default vacuum cost delay: same as vacuum_cost_delay
autovacuum_vacuum_cost_limit: -1 # default vacuum cost limit: same as vacuum_cost_limit
autovacuum_freeze_max_age: 100000000 # age > 1 billion triggers force vacuum
#----------------------------------------------------------------------
# CLIENT
#----------------------------------------------------------------------
deadlock_timeout: 50ms # 50ms for deadlock
idle_in_transaction_session_timeout: 10min # 10min timeout for idle in transaction
#----------------------------------------------------------------------
# CUSTOMIZED OPTIONS
#----------------------------------------------------------------------
# extensions
shared_preload_libraries: '{{ pg_shared_libraries | default("pg_stat_statements, auto_explain") }}'
# auto_explain
auto_explain.log_min_duration: 1s # auto explain query slower than 1s
auto_explain.log_analyze: true # explain analyze
auto_explain.log_verbose: true # explain verbose
auto_explain.log_timing: true # explain timing
auto_explain.log_nested_statements: true
# pg_stat_statements
pg_stat_statements.max: 10000 # 5000 -> 10000 queries
pg_stat_statements.track: all # track all statements (all|top|none)
pg_stat_statements.track_utility: off # do not track query other than CRUD
pg_stat_statements.track_planning: off # do not track planning metrics
#------------------------------------------------------------------------------
# postgres
#------------------------------------------------------------------------------
postgresql:
#----------------------------------------------------------------------------
# how to connect to postgres
#----------------------------------------------------------------------------
bin_dir: {{ pg_bin_dir }}
data_dir: {{ pg_data }}
config_dir: {{ pg_data }}
pgpass: {{ pg_dbsu_home }}/.pgpass
listen: {{ pg_listen }}:{{ pg_port }}
connect_address: {{ inventory_hostname }}:{{ pg_port }}
use_unix_socket: true # default: /var/run/postgresql, /tmp
#----------------------------------------------------------------------------
# who to connect to postgres
#----------------------------------------------------------------------------
authentication:
superuser:
username: {{ pg_dbsu }}
replication:
username: {{ pg_replication_username }}
password: '{{ pg_replication_password }}'
rewind:
username: {{ pg_replication_username }}
password: '{{ pg_replication_password }}'
#----------------------------------------------------------------------------
# how to react to database operations
#----------------------------------------------------------------------------
# event callback script log: /pg/log/callback.log
callbacks:
on_start: /pg/bin/pg-failover-callback
on_stop: /pg/bin/pg-failover-callback
on_reload: /pg/bin/pg-failover-callback
on_restart: /pg/bin/pg-failover-callback
on_role_change: /pg/bin/pg-failover-callback
# rewind policy: data checksum should be enabled before using rewind
use_pg_rewind: true
remove_data_directory_on_rewind_failure: true
remove_data_directory_on_diverged_timelines: false
#----------------------------------------------------------------------------
# how to create replica
#----------------------------------------------------------------------------
# create replica method: default pg_basebackup
create_replica_methods:
- basebackup
basebackup:
- max-rate: '1000M'
- checkpoint: fast
- status-interva: 1s
- verbose
- progress
#----------------------------------------------------------------------------
# ad hoc parameters (overwrite with default)
#----------------------------------------------------------------------------
# parameters:
#----------------------------------------------------------------------------
# host based authentication, overwrite default pg_hba.conf
#----------------------------------------------------------------------------
# pg_hba:
# - local all postgres ident
# - local all all md5
# - host all all 0.0.0.0/0 md5
# - local replication postgres ident
# - local replication all md5
# - host replication all 0.0.0.0/0 md5
...
9.10.2 - TINY
Patroni TINY模板
Patroni TINY模板主要针对极低配置的虚拟机进行优化,
此模板针对的典型机型是1核/1GB的虚拟机节点。您可以根据自己的实际机型进行调整。
#!/usr/bin/env patroni
#==============================================================#
# File : patroni.yml
# Ctime : 2020-04-08
# Mtime : 2020-12-22
# Desc : patroni cluster definition for {{ pg_cluster }} (tiny)
# Path : /pg/bin/patroni.yml
# Real Path : /pg/conf/{{ pg_instance }}.yml
# Link : /pg/bin/patroni.yml -> /pg/conf/{{ pg_instance}}.yml
# Note : Tiny Database Cluster Template
# Doc : https://patroni.readthedocs.io/en/latest/SETTINGS.html
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
# TINY database are optimized for low-resource situation (e.g 1 Core 1G)
# typical spec: 1 Core | 1-4 GB RAM | Normal SSD 10x GB
---
#------------------------------------------------------------------------------
# identity
#------------------------------------------------------------------------------
namespace: {{ pg_namespace }}/ # namespace
scope: {{ pg_cluster }} # cluster name
name: {{ pg_instance }} # instance name
#------------------------------------------------------------------------------
# log
#------------------------------------------------------------------------------
log:
level: INFO # NOTEST|DEBUG|INFO|WARNING|ERROR|CRITICAL
dir: /pg/log/ # default log file: /pg/log/patroni.log
file_size: 100000000 # 100MB log triggers a log rotate
# format: '%(asctime)s %(levelname)s: %(message)s'
#------------------------------------------------------------------------------
# dcs
#------------------------------------------------------------------------------
consul:
host: 127.0.0.1:8500
consistency: default # default|consistent|stale
register_service: true
service_check_interval: 15s
service_tags:
- {{ pg_cluster }}
#------------------------------------------------------------------------------
# api
#------------------------------------------------------------------------------
# how to expose patroni service
# listen on all ipv4, connect via public ip, use same credential as dbuser_monitor
restapi:
listen: 0.0.0.0:{{ patroni_port }}
connect_address: {{ inventory_hostname }}:{{ patroni_port }}
authentication:
verify_client: none # none|optional|required
username: {{ pg_monitor_username }}
password: '{{ pg_monitor_password }}'
#------------------------------------------------------------------------------
# ctl
#------------------------------------------------------------------------------
ctl:
optional:
insecure: true
# cacert: '/path/to/ca/cert'
# certfile: '/path/to/cert/file'
# keyfile: '/path/to/key/file'
#------------------------------------------------------------------------------
# tags
#------------------------------------------------------------------------------
tags:
nofailover: false
clonefrom: true
noloadbalance: false
nosync: false
{% if pg_upstream is defined %}
replicatefrom: {{ pg_upstream }} # clone from another replica rather than primary
{% endif %}
#------------------------------------------------------------------------------
# watchdog
#------------------------------------------------------------------------------
# available mode: off|automatic|required
watchdog:
mode: {{ patroni_watchdog_mode }}
device: /dev/watchdog
# safety_margin: 10s
#------------------------------------------------------------------------------
# bootstrap
#------------------------------------------------------------------------------
bootstrap:
#----------------------------------------------------------------------------
# bootstrap method
#----------------------------------------------------------------------------
method: initdb
# add custom bootstrap method here
# default bootstrap method: initdb
initdb:
- locale: C
- encoding: UTF8
- data-checksums # enable data-checksum
#----------------------------------------------------------------------------
# bootstrap users
#---------------------------------------------------------------------------
# additional users which need to be created after initializing new cluster
# replication user and monitor user are required
users:
{{ pg_replication_username }}:
password: '{{ pg_replication_password }}'
{{ pg_monitor_username }}:
password: '{{ pg_monitor_password }}'
# bootstrap hba, allow local and intranet password access & replication
# will be overwritten later
pg_hba:
- local all postgres ident
- local all all md5
- host all all 0.0.0.0/0 md5
- local replication postgres ident
- local replication all md5
- host replication all 0.0.0.0/0 md5
#----------------------------------------------------------------------------
# customization
#---------------------------------------------------------------------------
# post_init: /pg/bin/pg-init
#----------------------------------------------------------------------------
# bootstrap config
#---------------------------------------------------------------------------
# this section will be written to /{{ pg_namespace }}/{{ pg_cluster }}/config
# if will NOT take any effect after cluster bootstrap
dcs:
{% if pg_role == 'primary' and pg_upstream is defined %}
#----------------------------------------------------------------------------
# standby cluster definition
#---------------------------------------------------------------------------
standby_cluster:
host: {{ pg_upstream }}
port: {{ pg_port }}
# primary_slot_name: patroni # must be create manually on upstream server, if specified
create_replica_methods:
- basebackup
{% endif %}
#----------------------------------------------------------------------------
# important parameters
#---------------------------------------------------------------------------
# constraint: ttl >: loop_wait + retry_timeout * 2
# the number of seconds the loop will sleep. Default value: 10
# this is patroni check loop interval
loop_wait: 10
# the TTL to acquire the leader lock (in seconds). Think of it as the length of time before initiation of the automatic failover process. Default value: 30
# config this according to your network condition to avoid false-positive failover
ttl: 30
# timeout for DCS and PostgreSQL operation retries (in seconds). DCS or network issues shorter than this will not cause Patroni to demote the leader. Default value: 10
retry_timeout: 10
# the amount of time a master is allowed to recover from failures before failover is triggered (in seconds)
# Max RTO: 2 loop wait + master_start_timeout
master_start_timeout: 10
# import: candidate will not be promoted if replication lag is higher than this
# maximum RPO: 1MB
maximum_lag_on_failover: 1048576
# The number of seconds Patroni is allowed to wait when stopping Postgres and effective only when synchronous_mode is enabled
master_stop_timeout: 30
# turns on synchronous replication mode. In this mode a replica will be chosen as synchronous and only the latest leader and synchronous replica are able to participate in leader election
# set to true for RPO mode
synchronous_mode: false
# prevents disabling synchronous replication if no synchronous replicas are available, blocking all client writes to the master
synchronous_mode_strict: false
#----------------------------------------------------------------------------
# postgres parameters
#---------------------------------------------------------------------------
postgresql:
use_slots: true
use_pg_rewind: true
remove_data_directory_on_rewind_failure: true
parameters:
#----------------------------------------------------------------------
# IMPORTANT PARAMETERS
#----------------------------------------------------------------------
max_connections: 50 # default 100 -> 50
superuser_reserved_connections: 10 # reserve 10 connection for su
max_locks_per_transaction: 64 # default 64
max_prepared_transactions: 0 # 0 disable 2PC
track_commit_timestamp: on # enabled xact timestamp
max_worker_processes: 1 # default 8 -> 1 (set to cpu core)
wal_level: logical # logical
wal_log_hints: on # wal log hints to support rewind
max_wal_senders: 10 # default 10
max_replication_slots: 10 # default 10
wal_keep_size: 1GB # keep at least 1GB WAL
password_encryption: md5 # use traditional md5 auth
#----------------------------------------------------------------------
# RESOURCE USAGE (except WAL)
#----------------------------------------------------------------------
# memory: shared_buffers and maintenance_work_mem will be dynamically set
shared_buffers: {{ pg_shared_buffers }}
maintenance_work_mem: {{ pg_maintenance_work_mem }}
work_mem: 4MB # default 4MB
huge_pages: try # try huge pages
temp_file_limit: 40GB # 0 -> 40GB (according to your disk)
vacuum_cost_delay: 5ms # wait 5ms per 10000 cost
vacuum_cost_limit: 10000 # 10000 cost each round
bgwriter_delay: 10ms # check dirty page every 10ms
bgwriter_lru_maxpages: 800 # 100 -> 800
bgwriter_lru_multiplier: 5.0 # 2.0 -> 5.0 more cushion buffer
#----------------------------------------------------------------------
# WAL
#----------------------------------------------------------------------
wal_buffers: 16MB # max to 16MB
wal_writer_delay: 20ms # wait period
wal_writer_flush_after: 1MB # max allowed data loss
min_wal_size: 100GB # at least 100GB WAL
max_wal_size: 400GB # at most 400GB WAL
commit_delay: 20 # 200ms -> 20ms, increase speed
commit_siblings: 10 # 5 -> 10
checkpoint_timeout: 15min # checkpoint 5min -> 15min
checkpoint_completion_target: 0.80 # 0.5 -> 0.8
archive_mode: on
archive_command: 'wal_dir=/pg/arcwal; [[ $(date +%H%M) == 1200 ]] && rm -rf ${wal_dir}/$(date -d"yesterday" +%Y%m%d); /bin/mkdir -p ${wal_dir}/$(date +%Y%m%d) && /usr/bin/lz4 -q -z %p > ${wal_dir}/$(date +%Y%m%d)/%f.lz4'
#----------------------------------------------------------------------
# REPLICATION
#----------------------------------------------------------------------
# synchronous_standby_names: ''
vacuum_defer_cleanup_age: 50000 # 0->50000 last 50000 xact changes will not be vacuumed
promote_trigger_file: promote.signal # default promote trigger file path
max_standby_archive_delay: 10min # max delay before canceling queries when reading WAL from archive;
max_standby_streaming_delay: 3min # max delay before canceling queries when reading streaming WAL;
wal_receiver_status_interval: 1s # send replies at least this often
hot_standby_feedback: on # send info from standby to prevent query conflicts
wal_receiver_timeout: 60s # time that receiver waits for
max_logical_replication_workers: 8 # 4 -> 2 (set according to your cpu core)
max_sync_workers_per_subscription: 8 # 4 -> 2
#----------------------------------------------------------------------
# QUERY TUNING
#----------------------------------------------------------------------
# planner
# enable_partitionwise_join: on
random_page_cost: 1.1 # 4 for HDD, 1.1 for SSD
effective_cache_size: 2GB # max mem - shared buffer
default_statistics_target: 200 # stat bucket 100 -> 200
#----------------------------------------------------------------------
# REPORTING AND LOGGING
#----------------------------------------------------------------------
log_destination: csvlog # use standard csv log
logging_collector: on # enable csvlog
log_directory: log # default log dir: /pg/data/log
# log_filename: 'postgresql-%a.log' # weekly auto-recycle
log_filename: 'postgresql-%Y-%m-%d.log' # YYYY-MM-DD full log retention
log_checkpoints: on # log checkpoint info
log_lock_waits: on # log lock wait info
log_replication_commands: on # log replication info
log_statement: ddl # log ddl change
log_min_duration_statement: 100 # log slow query (>100ms)
#----------------------------------------------------------------------
# STATISTICS
#----------------------------------------------------------------------
track_io_timing: on # collect io statistics
track_functions: all # track all functions (none|pl|all)
track_activity_query_size: 8192 # max query length in pg_stat_activity
#----------------------------------------------------------------------
# AUTOVACUUM
#----------------------------------------------------------------------
log_autovacuum_min_duration: 1s # log autovacuum activity take more than 1s
autovacuum_max_workers: 1 # default autovacuum worker 3 -> 1
autovacuum_naptime: 1min # default autovacuum naptime 1min
autovacuum_vacuum_scale_factor: 0.08 # fraction of table size before vacuum 20% -> 8%
autovacuum_analyze_scale_factor: 0.04 # fraction of table size before analyze 10% -> 4%
autovacuum_vacuum_cost_delay: -1 # default vacuum cost delay: same as vacuum_cost_delay
autovacuum_vacuum_cost_limit: -1 # default vacuum cost limit: same as vacuum_cost_limit
autovacuum_freeze_max_age: 100000000 # age > 1 billion triggers force vacuum
#----------------------------------------------------------------------
# CLIENT
#----------------------------------------------------------------------
deadlock_timeout: 50ms # 50ms for deadlock
idle_in_transaction_session_timeout: 10min # 10min timeout for idle in transaction
#----------------------------------------------------------------------
# CUSTOMIZED OPTIONS
#----------------------------------------------------------------------
# extensions
shared_preload_libraries: '{{ pg_shared_libraries | default("pg_stat_statements, auto_explain") }}'
# auto_explain
auto_explain.log_min_duration: 1s # auto explain query slower than 1s
auto_explain.log_analyze: true # explain analyze
auto_explain.log_verbose: true # explain verbose
auto_explain.log_timing: true # explain timing
auto_explain.log_nested_statements: true
# pg_stat_statements
pg_stat_statements.max: 3000 # 5000 -> 3000 queries
pg_stat_statements.track: all # track all statements (all|top|none)
pg_stat_statements.track_utility: off # do not track query other than CRUD
pg_stat_statements.track_planning: off # do not track planning metrics
#------------------------------------------------------------------------------
# postgres
#------------------------------------------------------------------------------
postgresql:
#----------------------------------------------------------------------------
# how to connect to postgres
#----------------------------------------------------------------------------
bin_dir: {{ pg_bin_dir }}
data_dir: {{ pg_data }}
config_dir: {{ pg_data }}
pgpass: {{ pg_dbsu_home }}/.pgpass
listen: {{ pg_listen }}:{{ pg_port }}
connect_address: {{ inventory_hostname }}:{{ pg_port }}
use_unix_socket: true # default: /var/run/postgresql, /tmp
#----------------------------------------------------------------------------
# who to connect to postgres
#----------------------------------------------------------------------------
authentication:
superuser:
username: {{ pg_dbsu }}
replication:
username: {{ pg_replication_username }}
password: '{{ pg_replication_password }}'
rewind:
username: {{ pg_replication_username }}
password: '{{ pg_replication_password }}'
#----------------------------------------------------------------------------
# how to react to database operations
#----------------------------------------------------------------------------
# event callback script log: /pg/log/callback.log
callbacks:
on_start: /pg/bin/pg-failover-callback
on_stop: /pg/bin/pg-failover-callback
on_reload: /pg/bin/pg-failover-callback
on_restart: /pg/bin/pg-failover-callback
on_role_change: /pg/bin/pg-failover-callback
# rewind policy: data checksum should be enabled before using rewind
use_pg_rewind: true
remove_data_directory_on_rewind_failure: true
remove_data_directory_on_diverged_timelines: false
#----------------------------------------------------------------------------
# how to create replica
#----------------------------------------------------------------------------
# create replica method: default pg_basebackup
create_replica_methods:
- basebackup
basebackup:
- max-rate: '1000M'
- checkpoint: fast
- status-interva: 1s
- verbose
- progress
#----------------------------------------------------------------------------
# ad hoc parameters (overwrite with default)
#----------------------------------------------------------------------------
# parameters:
#----------------------------------------------------------------------------
# host based authentication, overwrite default pg_hba.conf
#----------------------------------------------------------------------------
# pg_hba:
# - local all postgres ident
# - local all all md5
# - host all all 0.0.0.0/0 md5
# - local replication postgres ident
# - local replication all md5
# - host replication all 0.0.0.0/0 md5
...
9.10.3 - OLAP
Patroni OLAP模板,针对高并行,长查询,高吞吐实例优化
Patroni OLAP模板主要针对吞吐量与计算并行度进行优化
此模板针对的机型是Dell R740 64核/400GB内存,使用PCI-E SSD的节点。您可以根据自己的实际机型进行调整。
#!/usr/bin/env patroni
#==============================================================#
# File : patroni.yml
# Ctime : 2020-04-08
# Mtime : 2020-12-22
# Desc : patroni cluster definition for {{ pg_cluster }} (olap)
# Path : /pg/bin/patroni.yml
# Real Path : /pg/conf/{{ pg_instance }}.yml
# Link : /pg/bin/patroni.yml -> /pg/conf/{{ pg_instance}}.yml
# Note : Analysis Database Cluster Template
# Doc : https://patroni.readthedocs.io/en/latest/SETTINGS.html
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
# OLTP database are optimized for throughput
# typical spec: 64 Core | 400 GB RAM | PCI-E SSD xTB
---
#------------------------------------------------------------------------------
# identity
#------------------------------------------------------------------------------
namespace: {{ pg_namespace }}/ # namespace
scope: {{ pg_cluster }} # cluster name
name: {{ pg_instance }} # instance name
#------------------------------------------------------------------------------
# log
#------------------------------------------------------------------------------
log:
level: INFO # NOTEST|DEBUG|INFO|WARNING|ERROR|CRITICAL
dir: /pg/log/ # default log file: /pg/log/patroni.log
file_size: 100000000 # 100MB log triggers a log rotate
# format: '%(asctime)s %(levelname)s: %(message)s'
#------------------------------------------------------------------------------
# dcs
#------------------------------------------------------------------------------
consul:
host: 127.0.0.1:8500
consistency: default # default|consistent|stale
register_service: true
service_check_interval: 15s
service_tags:
- {{ pg_cluster }}
#------------------------------------------------------------------------------
# api
#------------------------------------------------------------------------------
# how to expose patroni service
# listen on all ipv4, connect via public ip, use same credential as dbuser_monitor
restapi:
listen: 0.0.0.0:{{ patroni_port }}
connect_address: {{ inventory_hostname }}:{{ patroni_port }}
authentication:
verify_client: none # none|optional|required
username: {{ pg_monitor_username }}
password: '{{ pg_monitor_password }}'
#------------------------------------------------------------------------------
# ctl
#------------------------------------------------------------------------------
ctl:
optional:
insecure: true
# cacert: '/path/to/ca/cert'
# certfile: '/path/to/cert/file'
# keyfile: '/path/to/key/file'
#------------------------------------------------------------------------------
# tags
#------------------------------------------------------------------------------
tags:
nofailover: false
clonefrom: true
noloadbalance: false
nosync: false
{% if pg_upstream is defined %}
replicatefrom: {{ pg_upstream }} # clone from another replica rather than primary
{% endif %}
#------------------------------------------------------------------------------
# watchdog
#------------------------------------------------------------------------------
# available mode: off|automatic|required
watchdog:
mode: {{ patroni_watchdog_mode }}
device: /dev/watchdog
# safety_margin: 10s
#------------------------------------------------------------------------------
# bootstrap
#------------------------------------------------------------------------------
bootstrap:
#----------------------------------------------------------------------------
# bootstrap method
#----------------------------------------------------------------------------
method: initdb
# add custom bootstrap method here
# default bootstrap method: initdb
initdb:
- locale: C
- encoding: UTF8
# - data-checksums # enable data-checksum
#----------------------------------------------------------------------------
# bootstrap users
#---------------------------------------------------------------------------
# additional users which need to be created after initializing new cluster
# replication user and monitor user are required
users:
{{ pg_replication_username }}:
password: '{{ pg_replication_password }}'
{{ pg_monitor_username }}:
password: '{{ pg_monitor_password }}'
{{ pg_admin_username }}:
password: '{{ pg_admin_password }}'
# bootstrap hba, allow local and intranet password access & replication
# will be overwritten later
pg_hba:
- local all postgres ident
- local all all md5
- host all all 0.0.0.0/0 md5
- local replication postgres ident
- local replication all md5
- host replication all 0.0.0.0/0 md5
#----------------------------------------------------------------------------
# template
#---------------------------------------------------------------------------
# post_init: /pg/bin/pg-init
#----------------------------------------------------------------------------
# bootstrap config
#---------------------------------------------------------------------------
# this section will be written to /{{ pg_namespace }}/{{ pg_cluster }}/config
# if will NOT take any effect after cluster bootstrap
dcs:
{% if pg_role == 'primary' and pg_upstream is defined %}
#----------------------------------------------------------------------------
# standby cluster definition
#---------------------------------------------------------------------------
standby_cluster:
host: {{ pg_upstream }}
port: {{ pg_port }}
# primary_slot_name: patroni # must be create manually on upstream server, if specified
create_replica_methods:
- basebackup
{% endif %}
#----------------------------------------------------------------------------
# important parameters
#---------------------------------------------------------------------------
# constraint: ttl >: loop_wait + retry_timeout * 2
# the number of seconds the loop will sleep. Default value: 10
# this is patroni check loop interval
loop_wait: 10
# the TTL to acquire the leader lock (in seconds). Think of it as the length of time before initiation of the automatic failover process. Default value: 30
# config this according to your network condition to avoid false-positive failover
ttl: 30
# timeout for DCS and PostgreSQL operation retries (in seconds). DCS or network issues shorter than this will not cause Patroni to demote the leader. Default value: 10
retry_timeout: 10
# the amount of time a master is allowed to recover from failures before failover is triggered (in seconds)
# Max RTO: 2 loop wait + master_start_timeout
master_start_timeout: 10
# import: candidate will not be promoted if replication lag is higher than this
# maximum RPO: 16MB (analysis tolerate more data loss)
maximum_lag_on_failover: 16777216
# The number of seconds Patroni is allowed to wait when stopping Postgres and effective only when synchronous_mode is enabled
master_stop_timeout: 30
# turns on synchronous replication mode. In this mode a replica will be chosen as synchronous and only the latest leader and synchronous replica are able to participate in leader election
# set to true for RPO mode
synchronous_mode: false
# prevents disabling synchronous replication if no synchronous replicas are available, blocking all client writes to the master
synchronous_mode_strict: false
#----------------------------------------------------------------------------
# postgres parameters
#---------------------------------------------------------------------------
postgresql:
use_slots: true
use_pg_rewind: true
remove_data_directory_on_rewind_failure: true
parameters:
#----------------------------------------------------------------------
# IMPORTANT PARAMETERS
#----------------------------------------------------------------------
max_connections: 400 # 100 -> 400
superuser_reserved_connections: 10 # reserve 10 connection for su
max_locks_per_transaction: 256 # 64 -> 256 (analysis)
max_prepared_transactions: 0 # 0 disable 2PC
track_commit_timestamp: on # enabled xact timestamp
max_worker_processes: 64 # default 8 -> 64, SET THIS ACCORDING TO YOUR CPU CORES
wal_level: logical # logical
wal_log_hints: on # wal log hints to support rewind
max_wal_senders: 16 # 10 -> 16
max_replication_slots: 16 # 10 -> 16
wal_keep_size: 100GB # keep at least 100GB WAL
password_encryption: md5 # use traditional md5 auth
#----------------------------------------------------------------------
# RESOURCE USAGE (except WAL)
#----------------------------------------------------------------------
# memory: shared_buffers and maintenance_work_mem will be dynamically set
shared_buffers: {{ pg_shared_buffers }}
maintenance_work_mem: {{ pg_maintenance_work_mem }}
work_mem: 128MB # 4MB -> 128MB (analysis)
huge_pages: try # try huge pages
temp_file_limit: 500GB # 0 -> 500GB (analysis)
vacuum_cost_delay: 2ms # wait 2ms per 10000 cost
vacuum_cost_limit: 10000 # 10000 cost each round
bgwriter_delay: 10ms # check dirty page every 10ms
bgwriter_lru_maxpages: 1600 # 100 -> 1600 (analysis)
bgwriter_lru_multiplier: 5.0 # 2.0 -> 5.0 more cushion buffer
max_parallel_workers: 64 # SET THIS ACCORDING TO YOUR CPU CORES
max_parallel_workers_per_gather: 64 # SET THIS ACCORDING TO YOUR CPU CORES
max_parallel_maintenance_workers: 4 # 2 -> 4
#----------------------------------------------------------------------
# WAL
#----------------------------------------------------------------------
wal_buffers: 16MB # max to 16MB
wal_writer_delay: 20ms # wait period
wal_writer_flush_after: 16MB # max allowed data loss (analysis)
min_wal_size: 100GB # at least 100GB WAL
max_wal_size: 400GB # at most 400GB WAL
commit_delay: 20 # 200ms -> 20ms, increase speed
commit_siblings: 10 # 5 -> 10
checkpoint_timeout: 60min # checkpoint 5min -> 1h
checkpoint_completion_target: 0.95 # 0.5 -> 0.95
archive_mode: on
archive_command: 'wal_dir=/pg/arcwal; [[ $(date +%H%M) == 1200 ]] && rm -rf ${wal_dir}/$(date -d"yesterday" +%Y%m%d); /bin/mkdir -p ${wal_dir}/$(date +%Y%m%d) && /usr/bin/lz4 -q -z %p > ${wal_dir}/$(date +%Y%m%d)/%f.lz4'
#----------------------------------------------------------------------
# REPLICATION
#----------------------------------------------------------------------
# synchronous_standby_names: ''
vacuum_defer_cleanup_age: 0 # 0 (default)
promote_trigger_file: promote.signal # default promote trigger file path
max_standby_archive_delay: 10min # max delay before canceling queries when reading WAL from archive;
max_standby_streaming_delay: 3min # max delay before canceling queries when reading streaming WAL;
wal_receiver_status_interval: 1s # send replies at least this often
hot_standby_feedback: on # send info from standby to prevent query conflicts
wal_receiver_timeout: 60s # time that receiver waits for
max_logical_replication_workers: 8 # 4 -> 8
max_sync_workers_per_subscription: 8 # 4 -> 8
#----------------------------------------------------------------------
# QUERY TUNING
#----------------------------------------------------------------------
# planner
enable_partitionwise_join: on # enable on analysis
random_page_cost: 1.1 # 4 for HDD, 1.1 for SSD
effective_cache_size: 320GB # max mem - shared buffer
default_statistics_target: 1000 # stat bucket 100 -> 1000
jit: on # default on
jit_above_cost: 100000 # default jit threshold
#----------------------------------------------------------------------
# REPORTING AND LOGGING
#----------------------------------------------------------------------
log_destination: csvlog # use standard csv log
logging_collector: on # enable csvlog
log_directory: log # default log dir: /pg/data/log
# log_filename: 'postgresql-%a.log' # weekly auto-recycle
log_filename: 'postgresql-%Y-%m-%d.log' # YYYY-MM-DD full log retention
log_checkpoints: on # log checkpoint info
log_lock_waits: on # log lock wait info
log_replication_commands: on # log replication info
log_statement: ddl # log ddl change
log_min_duration_statement: 1000 # log slow query (>1s)
#----------------------------------------------------------------------
# STATISTICS
#----------------------------------------------------------------------
track_io_timing: on # collect io statistics
track_functions: all # track all functions (none|pl|all)
track_activity_query_size: 8192 # max query length in pg_stat_activity
#----------------------------------------------------------------------
# AUTOVACUUM
#----------------------------------------------------------------------
log_autovacuum_min_duration: 1s # log autovacuum activity take more than 1s
autovacuum_max_workers: 3 # default autovacuum worker 3
autovacuum_naptime: 1min # default autovacuum naptime 1min
autovacuum_vacuum_scale_factor: 0.08 # fraction of table size before vacuum 20% -> 8%
autovacuum_analyze_scale_factor: 0.04 # fraction of table size before analyze 10% -> 4%
autovacuum_vacuum_cost_delay: -1 # default vacuum cost delay: same as vacuum_cost_delay
autovacuum_vacuum_cost_limit: -1 # default vacuum cost limit: same as vacuum_cost_limit
autovacuum_freeze_max_age: 100000000 # age > 1 billion triggers force vacuum
#----------------------------------------------------------------------
# CLIENT
#----------------------------------------------------------------------
deadlock_timeout: 50ms # 50ms for deadlock
idle_in_transaction_session_timeout: 0 # Disable idle in xact timeout in analysis database
#----------------------------------------------------------------------
# CUSTOMIZED OPTIONS
#----------------------------------------------------------------------
# extensions
shared_preload_libraries: '{{ pg_shared_libraries | default("pg_stat_statements, auto_explain") }}'
# auto_explain
auto_explain.log_min_duration: 1s # auto explain query slower than 1s
auto_explain.log_analyze: true # explain analyze
auto_explain.log_verbose: true # explain verbose
auto_explain.log_timing: true # explain timing
auto_explain.log_nested_statements: true
# pg_stat_statements
pg_stat_statements.max: 10000 # 5000 -> 10000 queries
pg_stat_statements.track: all # track all statements (all|top|none)
pg_stat_statements.track_utility: off # do not track query other than CRUD
pg_stat_statements.track_planning: off # do not track planning metrics
#------------------------------------------------------------------------------
# postgres
#------------------------------------------------------------------------------
postgresql:
#----------------------------------------------------------------------------
# how to connect to postgres
#----------------------------------------------------------------------------
bin_dir: {{ pg_bin_dir }}
data_dir: {{ pg_data }}
config_dir: {{ pg_data }}
pgpass: {{ pg_dbsu_home }}/.pgpass
listen: {{ pg_listen }}:{{ pg_port }}
connect_address: {{ inventory_hostname }}:{{ pg_port }}
use_unix_socket: true # default: /var/run/postgresql, /tmp
#----------------------------------------------------------------------------
# who to connect to postgres
#----------------------------------------------------------------------------
authentication:
superuser:
username: {{ pg_dbsu }}
replication:
username: {{ pg_replication_username }}
password: '{{ pg_replication_password }}'
rewind:
username: {{ pg_replication_username }}
password: '{{ pg_replication_password }}'
#----------------------------------------------------------------------------
# how to react to database operations
#----------------------------------------------------------------------------
# event callback script log: /pg/log/callback.log
callbacks:
on_start: /pg/bin/pg-failover-callback
on_stop: /pg/bin/pg-failover-callback
on_reload: /pg/bin/pg-failover-callback
on_restart: /pg/bin/pg-failover-callback
on_role_change: /pg/bin/pg-failover-callback
# rewind policy: data checksum should be enabled before using rewind
use_pg_rewind: true
remove_data_directory_on_rewind_failure: true
remove_data_directory_on_diverged_timelines: false
#----------------------------------------------------------------------------
# how to create replica
#----------------------------------------------------------------------------
# create replica method: default pg_basebackup
create_replica_methods:
- basebackup
basebackup:
- max-rate: '1000M'
- checkpoint: fast
- status-interva: 1s
- verbose
- progress
#----------------------------------------------------------------------------
# ad hoc parameters (overwrite with default)
#----------------------------------------------------------------------------
# parameters:
#----------------------------------------------------------------------------
# host based authentication, overwrite default pg_hba.conf
#----------------------------------------------------------------------------
# pg_hba:
# - local all postgres ident
# - local all all md5
# - host all all 0.0.0.0/0 md5
# - local replication postgres ident
# - local replication all md5
# - host replication all 0.0.0.0/0 md5
...
9.10.4 - CRIT
Patroni CRIT模板,针对金融场景、不允许数据丢失错漏的场景进行优化。
Patroni CRIT模板主要针对RPO进行优化,采用同步复制,发生故障时确保不会有数据丢失。
此模板针对的机型是Dell R740 64核/400GB内存,使用PCI-E SSD的节点。用户可以根据自己的实际机型进行调整。
#!/usr/bin/env patroni
#==============================================================#
# File : patroni.yml
# Ctime : 2020-04-08
# Mtime : 2020-12-22
# Desc : patroni cluster definition for {{ pg_cluster }} (crit)
# Path : /pg/bin/patroni.yml
# Real Path : /pg/conf/{{ pg_instance }}.yml
# Link : /pg/bin/patroni.yml -> /pg/conf/{{ pg_instance}}.yml
# Note : Critical Database Cluster Template
# Doc : https://patroni.readthedocs.io/en/latest/SETTINGS.html
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
# CRIT database are optimized for security, integrity, RPO
# typical spec: 64 Core | 400 GB RAM | PCI-E SSD xTB
---
#------------------------------------------------------------------------------
# identity
#------------------------------------------------------------------------------
namespace: {{ pg_namespace }}/ # namespace
scope: {{ pg_cluster }} # cluster name
name: {{ pg_instance }} # instance name
#------------------------------------------------------------------------------
# log
#------------------------------------------------------------------------------
log:
level: INFO # NOTEST|DEBUG|INFO|WARNING|ERROR|CRITICAL
dir: /pg/log/ # default log file: /pg/log/patroni.log
file_size: 100000000 # 100MB log triggers a log rotate
# format: '%(asctime)s %(levelname)s: %(message)s'
#------------------------------------------------------------------------------
# dcs
#------------------------------------------------------------------------------
consul:
host: 127.0.0.1:8500
consistency: default # default|consistent|stale
register_service: true
service_check_interval: 15s
service_tags:
- {{ pg_cluster }}
#------------------------------------------------------------------------------
# api
#------------------------------------------------------------------------------
# how to expose patroni service
# listen on all ipv4, connect via public ip, use same credential as dbuser_monitor
restapi:
listen: 0.0.0.0:{{ patroni_port }}
connect_address: {{ inventory_hostname }}:{{ patroni_port }}
authentication:
verify_client: none # none|optional|required
username: {{ pg_monitor_username }}
password: '{{ pg_monitor_password }}'
#------------------------------------------------------------------------------
# ctl
#------------------------------------------------------------------------------
ctl:
optional:
insecure: true
# cacert: '/path/to/ca/cert'
# certfile: '/path/to/cert/file'
# keyfile: '/path/to/key/file'
#------------------------------------------------------------------------------
# tags
#------------------------------------------------------------------------------
tags:
nofailover: false
clonefrom: true
noloadbalance: false
nosync: false
{% if pg_upstream is defined %}
replicatefrom: {{ pg_upstream }} # clone from another replica rather than primary
{% endif %}
#------------------------------------------------------------------------------
# watchdog
#------------------------------------------------------------------------------
# available mode: off|automatic|required
watchdog:
mode: {{ patroni_watchdog_mode }}
device: /dev/watchdog
# safety_margin: 10s
#------------------------------------------------------------------------------
# bootstrap
#------------------------------------------------------------------------------
bootstrap:
#----------------------------------------------------------------------------
# bootstrap method
#----------------------------------------------------------------------------
method: initdb
# add custom bootstrap method here
# default bootstrap method: initdb
initdb:
- locale: C
- encoding: UTF8
# - data-checksums # enable data-checksum
#----------------------------------------------------------------------------
# bootstrap users
#---------------------------------------------------------------------------
# additional users which need to be created after initializing new cluster
# replication user and monitor user are required
users:
{{ pg_replication_username }}:
password: '{{ pg_replication_password }}'
{{ pg_monitor_username }}:
password: '{{ pg_monitor_password }}'
{{ pg_admin_username }}:
password: '{{ pg_admin_password }}'
# bootstrap hba, allow local and intranet password access & replication
# will be overwritten later
pg_hba:
- local all postgres ident
- local all all md5
- host all all 0.0.0.0/0 md5
- local replication postgres ident
- local replication all md5
- host replication all 0.0.0.0/0 md5
#----------------------------------------------------------------------------
# template
#---------------------------------------------------------------------------
# post_init: /pg/bin/pg-init
#----------------------------------------------------------------------------
# bootstrap config
#---------------------------------------------------------------------------
# this section will be written to /{{ pg_namespace }}/{{ pg_cluster }}/config
# if will NOT take any effect after cluster bootstrap
dcs:
{% if pg_role == 'primary' and pg_upstream is defined %}
#----------------------------------------------------------------------------
# standby cluster definition
#---------------------------------------------------------------------------
standby_cluster:
host: {{ pg_upstream }}
port: {{ pg_port }}
# primary_slot_name: patroni # must be create manually on upstream server, if specified
create_replica_methods:
- basebackup
{% endif %}
#----------------------------------------------------------------------------
# important parameters
#---------------------------------------------------------------------------
# constraint: ttl >: loop_wait + retry_timeout * 2
# the number of seconds the loop will sleep. Default value: 10
# this is patroni check loop interval
loop_wait: 10
# the TTL to acquire the leader lock (in seconds). Think of it as the length of time before initiation of the automatic failover process. Default value: 30
# config this according to your network condition to avoid false-positive failover
ttl: 30
# timeout for DCS and PostgreSQL operation retries (in seconds). DCS or network issues shorter than this will not cause Patroni to demote the leader. Default value: 10
retry_timeout: 10
# the amount of time a master is allowed to recover from failures before failover is triggered (in seconds)
# Max RTO: 2 loop wait + master_start_timeout
master_start_timeout: 120 # more patient on critical database
# import: candidate will not be promoted if replication lag is higher than this
# maximum RPO: 0 for critical database
maximum_lag_on_failover: 1
# The number of seconds Patroni is allowed to wait when stopping Postgres and effective only when synchronous_mode is enabled
master_stop_timeout: 10 # more patient on critical database
# turns on synchronous replication mode. In this mode a replica will be chosen as synchronous and only the latest leader and synchronous replica are able to participate in leader election
# set to true for RPO mode
synchronous_mode: true # use sync replication on critical database
# prevents disabling synchronous replication if no synchronous replicas are available, blocking all client writes to the master
synchronous_mode_strict: false
#----------------------------------------------------------------------------
# postgres parameters
#---------------------------------------------------------------------------
postgresql:
use_slots: true
use_pg_rewind: true
remove_data_directory_on_rewind_failure: true
parameters:
#----------------------------------------------------------------------
# IMPORTANT PARAMETERS
#----------------------------------------------------------------------
max_connections: 400 # 100 -> 400
superuser_reserved_connections: 10 # reserve 10 connection for su
max_locks_per_transaction: 128 # 64 -> 128
max_prepared_transactions: 0 # 0 disable 2PC
track_commit_timestamp: on # enabled xact timestamp
max_worker_processes: 8 # default 8, set to cpu core
wal_level: logical # logical
wal_log_hints: on # wal log hints to support rewind
max_wal_senders: 16 # 10 -> 16
max_replication_slots: 16 # 10 -> 16
wal_keep_size: 100GB # keep at least 100GB WAL
password_encryption: md5 # use traditional md5 auth
#----------------------------------------------------------------------
# RESOURCE USAGE (except WAL)
#----------------------------------------------------------------------
# memory: shared_buffers and maintenance_work_mem will be dynamically set
shared_buffers: {{ pg_shared_buffers }}
maintenance_work_mem: {{ pg_maintenance_work_mem }}
work_mem: 32MB # 4MB -> 32MB
huge_pages: try # try huge pages
temp_file_limit: 100GB # 0 -> 100GB
vacuum_cost_delay: 2ms # wait 2ms per 10000 cost
vacuum_cost_limit: 10000 # 10000 cost each round
bgwriter_delay: 10ms # check dirty page every 10ms
bgwriter_lru_maxpages: 800 # 100 -> 800
bgwriter_lru_multiplier: 5.0 # 2.0 -> 5.0 more cushion buffer
#----------------------------------------------------------------------
# WAL
#----------------------------------------------------------------------
wal_buffers: 16MB # max to 16MB
wal_writer_delay: 20ms # wait period
wal_writer_flush_after: 1MB # max allowed data loss
min_wal_size: 100GB # at least 100GB WAL
max_wal_size: 400GB # at most 400GB WAL
commit_delay: 20 # 200ms -> 20ms, increase speed
commit_siblings: 10 # 5 -> 10
checkpoint_timeout: 60min # checkpoint 5min -> 1h
checkpoint_completion_target: 0.95 # 0.5 -> 0.95
archive_mode: on
archive_command: 'wal_dir=/pg/arcwal; [[ $(date +%H%M) == 1200 ]] && rm -rf ${wal_dir}/$(date -d"yesterday" +%Y%m%d); /bin/mkdir -p ${wal_dir}/$(date +%Y%m%d) && /usr/bin/lz4 -q -z %p > ${wal_dir}/$(date +%Y%m%d)/%f.lz4'
#----------------------------------------------------------------------
# REPLICATION
#----------------------------------------------------------------------
# synchronous_standby_names: ''
vacuum_defer_cleanup_age: 50000 # 0->50000 last 50000 xact changes will not be vacuumed
promote_trigger_file: promote.signal # default promote trigger file path
max_standby_archive_delay: 10min # max delay before canceling queries when reading WAL from archive;
max_standby_streaming_delay: 3min # max delay before canceling queries when reading streaming WAL;
wal_receiver_status_interval: 1s # send replies at least this often
hot_standby_feedback: on # send info from standby to prevent query conflicts
wal_receiver_timeout: 60s # time that receiver waits for
max_logical_replication_workers: 8 # 4 -> 8
max_sync_workers_per_subscription: 8 # 4 -> 8
#----------------------------------------------------------------------
# QUERY TUNING
#----------------------------------------------------------------------
# planner
# enable_partitionwise_join: on
random_page_cost: 1.1 # 4 for HDD, 1.1 for SSD
effective_cache_size: 320GB # max mem - shared buffer
default_statistics_target: 1000 # stat bucket 100 -> 1000
#----------------------------------------------------------------------
# REPORTING AND LOGGING
#----------------------------------------------------------------------
log_destination: csvlog # use standard csv log
logging_collector: on # enable csvlog
log_directory: log # default log dir: /pg/data/log
# log_filename: 'postgresql-%a.log' # weekly auto-recycle
log_filename: 'postgresql-%Y-%m-%d.log' # YYYY-MM-DD full log retention
log_checkpoints: on # log checkpoint info
log_lock_waits: on # log lock wait info
log_replication_commands: on # log replication info
log_statement: ddl # log ddl change
log_min_duration_statement: 100 # log slow query (>100ms)
#----------------------------------------------------------------------
# STATISTICS
#----------------------------------------------------------------------
track_io_timing: on # collect io statistics
track_functions: all # track all functions (none|pl|all)
track_activity_query_size: 32768 # show full query on critical database
#----------------------------------------------------------------------
# AUTOVACUUM
#----------------------------------------------------------------------
log_autovacuum_min_duration: 1s # log autovacuum activity take more than 1s
autovacuum_max_workers: 3 # default autovacuum worker 3
autovacuum_naptime: 1min # default autovacuum naptime 1min
autovacuum_vacuum_scale_factor: 0.08 # fraction of table size before vacuum 20% -> 8%
autovacuum_analyze_scale_factor: 0.04 # fraction of table size before analyze 10% -> 4%
autovacuum_vacuum_cost_delay: -1 # default vacuum cost delay: same as vacuum_cost_delay
autovacuum_vacuum_cost_limit: -1 # default vacuum cost limit: same as vacuum_cost_limit
autovacuum_freeze_max_age: 100000000 # age > 1 billion triggers force vacuum
#----------------------------------------------------------------------
# CLIENT
#----------------------------------------------------------------------
deadlock_timeout: 50ms # 50ms for deadlock
idle_in_transaction_session_timeout: 1min # 1min timeout for idle in transaction in critical database
#----------------------------------------------------------------------
# CUSTOMIZED OPTIONS
#----------------------------------------------------------------------
# extensions
shared_preload_libraries: '{{ pg_shared_libraries | default("pg_stat_statements, auto_explain") }}'
# auto_explain
auto_explain.log_min_duration: 1s # auto explain query slower than 1s
auto_explain.log_analyze: true # explain analyze
auto_explain.log_verbose: true # explain verbose
auto_explain.log_timing: true # explain timing
auto_explain.log_nested_statements: true
# pg_stat_statements
pg_stat_statements.max: 10000 # 5000 -> 10000 queries
pg_stat_statements.track: all # track all statements (all|top|none)
pg_stat_statements.track_utility: on # TRACK all queries on critical database
pg_stat_statements.track_planning: off # do not track planning metrics
#------------------------------------------------------------------------------
# postgres
#------------------------------------------------------------------------------
postgresql:
#----------------------------------------------------------------------------
# how to connect to postgres
#----------------------------------------------------------------------------
bin_dir: {{ pg_bin_dir }}
data_dir: {{ pg_data }}
config_dir: {{ pg_data }}
pgpass: {{ pg_dbsu_home }}/.pgpass
listen: {{ pg_listen }}:{{ pg_port }}
connect_address: {{ inventory_hostname }}:{{ pg_port }}
use_unix_socket: true # default: /var/run/postgresql, /tmp
#----------------------------------------------------------------------------
# who to connect to postgres
#----------------------------------------------------------------------------
authentication:
superuser:
username: {{ pg_dbsu }}
replication:
username: {{ pg_replication_username }}
password: '{{ pg_replication_password }}'
rewind:
username: {{ pg_replication_username }}
password: '{{ pg_replication_password }}'
#----------------------------------------------------------------------------
# how to react to database operations
#----------------------------------------------------------------------------
# event callback script log: /pg/log/callback.log
callbacks:
on_start: /pg/bin/pg-failover-callback
on_stop: /pg/bin/pg-failover-callback
on_reload: /pg/bin/pg-failover-callback
on_restart: /pg/bin/pg-failover-callback
on_role_change: /pg/bin/pg-failover-callback
# rewind policy: data checksum should be enabled before using rewind
use_pg_rewind: true
remove_data_directory_on_rewind_failure: true
remove_data_directory_on_diverged_timelines: false
#----------------------------------------------------------------------------
# how to create replica
#----------------------------------------------------------------------------
# create replica method: default pg_basebackup
create_replica_methods:
- basebackup
basebackup:
- max-rate: '1000M'
- checkpoint: fast
- status-interva: 1s
- verbose
- progress
#----------------------------------------------------------------------------
# ad hoc parameters (overwrite with default)
#----------------------------------------------------------------------------
# parameters:
#----------------------------------------------------------------------------
# host based authentication, overwrite default pg_hba.conf
#----------------------------------------------------------------------------
# pg_hba:
# - local all postgres ident
# - local all all md5
# - host all all 0.0.0.0/0 md5
# - local replication postgres ident
# - local replication all md5
# - host replication all 0.0.0.0/0 md5
...
{kind=link}
{kind=link}
{kind=link}