文章
- 开箱即用的PG发行版:Pigsty
- 为什么PostgreSQL前途无量?
- 容器化数据库是个好主意吗?
- 理解时间:时间时区那些事
- PostgreSQL开发规约
- PG好处都有啥
- 区块链与分布式数据库
- 一致性:过载的术语
- 为什么要学习数据库原理
开箱即用的PG发行版:Pigsty
什么是Pigsty
Pigsty是开箱即用的生产级开源PostgreSQL发行版。

所谓发行版(Distribution),指的是由数据库内核及其一组软件包组成的数据库整体解决方案。例如,Linux是一个操作系统内核,而RedHat,Debian,SUSE则是基于此内核的操作系统发行版。PostgreSQL是一个数据库内核,而Pigsty,BigSQL,Percona,各种云RDS,换皮数据库则是基于此内核的数据库发行版。
Pigsty区别于其他数据库发行版的五个核心特性为:
- 全面专业的监控系统
- 稳定可靠的部署方案
- 简单省心的用户界面
- 灵活开放的扩展机制
- 免费友好的开源协议
这五个特性,使得Pigsty真正成为开箱即用的PostgreSQL发行版。
谁会感兴趣?
Pigsty面向的用户群体包括:DBA,架构师,OPS,软件厂商、云厂商、业务研发、内核研发、数据研发;对数据分析与数据可视化感兴趣的人;学生,新手程序员,有兴趣尝试数据库的用户。
对于DBA,架构师等专业用户,Pigsty提供了独一无二的专业级PostgreSQL监控系统,为数据库管理提供不可替代的价值点。与此同时,Pigsty还带有一个稳定可靠,久经考验的生产级PostgreSQL部署方案,可在生产环境中自动部署带有监控报警,日志采集,服务发现,连接池,负载均衡,VIP,以及高可用的PostgreSQL数据库集群。
对于研发人员(业务研发、内核研发、数据研发),学生,新手程序员,有兴趣尝试数据库的用户,Pigsty提供了门槛极低,一键拉起,一键安装的本地沙箱。本地沙箱除机器规格外与生产环境完全一致,包含完整的功能:带有开箱即用的数据库实例与监控系统。可用于学习,开发,测试,数据分析等场景。
此外,Pigsty提供了一种称为“Datalet”的灵活扩展机制 。对数据分析与数据可视化感兴趣的人可能会惊讶地发现,Pigsty还可以作为数据分析与可视化的集成开发环境。Pigsty集成了PostgreSQL与常用的数据分析插件,并带有Grafana和内嵌的Echarts支持,允许用户编写,测试,分发数据小应用(Datalet)。如:“Pigsty监控系统的额外扩展面板包”,“Redis监控系统”,“PG日志分析系统”,“应用监控”,“数据目录浏览器”等。
最后,Pigsty采用了免费友好的Apache License 2.0,可以免费用于商业目的。只要遵守Apache 2 License的显著声明条款,也欢迎云厂商与软件厂商集成与二次研发商用。
全面专业的监控系统

You can’t manage what you don’t measure.
— Peter F.Drucker
Pigsty提供专业级监控系统,面向专业用户提供不可替代的价值点。
以医疗器械类比,普通监控系统类似于心率计、血氧计,普通人无需学习也可以上手。它可以给出患者生命体征核心指标:起码用户可以知道人是不是要死了,但对于看病治病无能为力。例如,各种云厂商软件厂商提供的监控系统大抵属于此类:十几个核心指标,告诉你数据库是不是还活着,让人大致有个数,仅此而已。
专业级监控系统则类似于CT,核磁共振仪,可以检测出对象内部的全部细节,专业的医师可以根据CT/MRI报告快速定位疾病与隐患:有病治病,没病健体。Pigsty可以深入审视每一个数据库中的每一张表,每一个索引,每一个查询,提供巨细无遗的全面指标(1155类),并通过几千个仪表盘将其转换为洞察:将故障扼杀在萌芽状态,并为性能优化提供实时反馈。
Pigsty监控系统基于业内最佳实践,采用Prometheus、Grafana作为监控基础设施。开源开放,定制便利,可复用,可移植,没有厂商锁定。可与各类已有数据库实例集成。

稳定可靠的部署方案

A complex system that works is invariably found to have evolved from a simple system that works.
—John Gall, Systemantics (1975)
数据库是管理数据的软件,管控系统是管理数据库的软件。
Pigsty内置了一套以Ansible为核心的数据库管控方案。并基于此封装了命令行工具与图形界面。它集成了数据库管理中的核心功能:包括数据库集群的创建,销毁,扩缩容;用户、数据库、服务的创建等。Pigsty采纳“Infra as Code”的设计哲学使用了声明式配置,通过大量可选的配置选项对数据库与运行环境进行描述与定制,并通过幂等的预置剧本自动创建所需的数据库集群,提供近似私有云般的使用体验。

Pigsty创建的数据库集群是分布式、高可用的数据库集群。Pigsty创建的数据库基于DCS、Patroni、Haproxy实现了高可用。数据库集群中的每个数据库实例在使用上都是幂等的,任意实例都可以通过内建负载均衡组件提供完整的读写服务,提供分布式数据库的使用体验。数据库集群可以自动进行故障检测与主从切换,普通故障能在几秒到几十秒内自愈,且期间只读流量不受影响。故障时。集群中只要有任意实例存活,就可以对外提供完整的服务。
Pigsty的架构方案经过审慎的设计与评估,着眼于以最小复杂度实现所需功能。该方案经过长时间,大规模的生产环境验证,已经被互联网/B/G/M/F多个行业内的组织所使用。
简单省心的用户界面

Pigsty旨在降低PostgreSQL的使用门槛,因此在易用性上做了大量工作。
安装部署
Someone told me that each equation I included in the book would halve the sales.
— Stephen Hawking
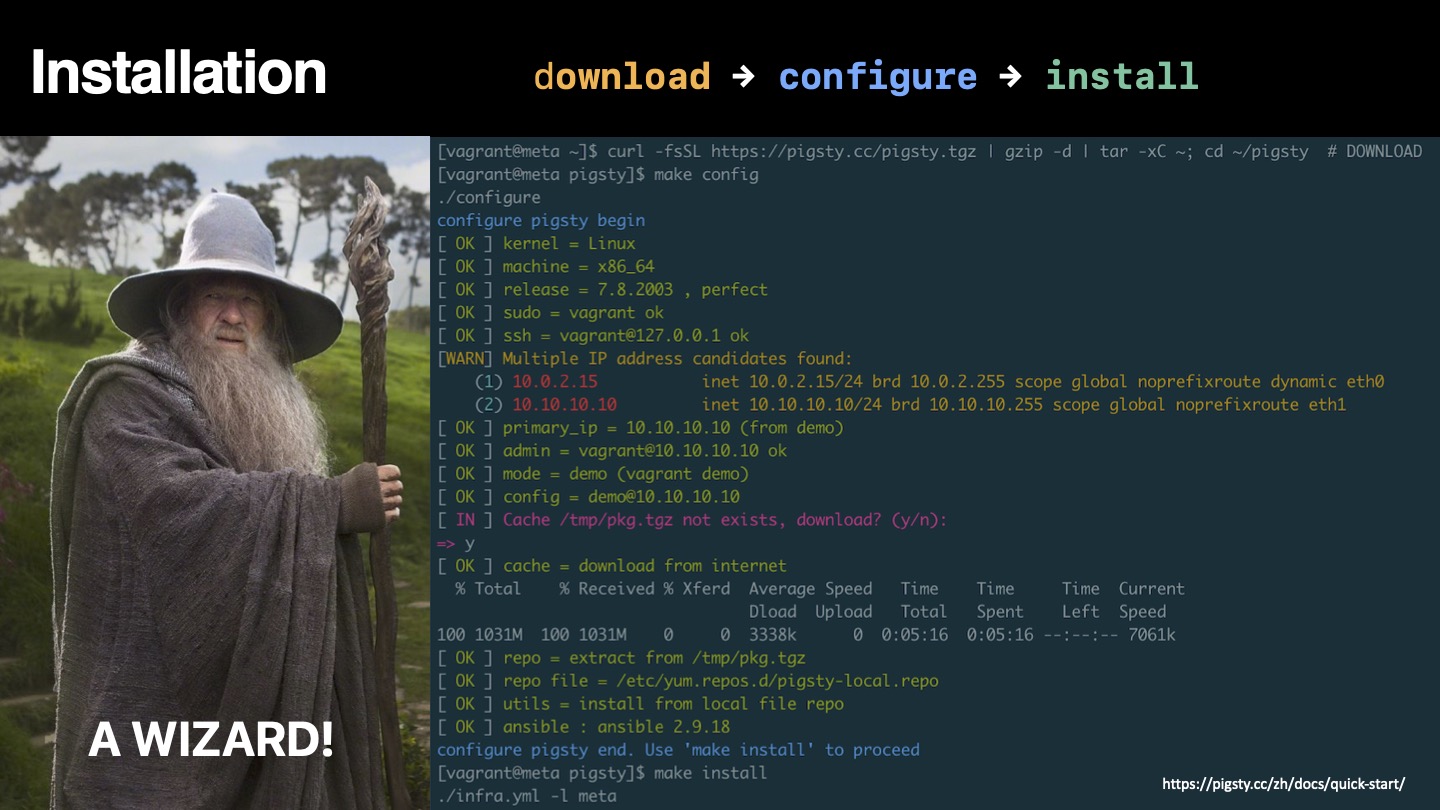
Pigsty的部署分为三步:下载源码,配置环境,执行安装,均可通过一行命令完成。遵循经典的软件安装模式,并提供了配置向导。您需要准备的只是一台CentOS7.8机器及其root权限。管理新节点时,Pigsty基于Ansible通过ssh发起管理,无需安装Agent,即使是新手也可以轻松完成部署。
Pigsty既可以在生产环境中管理成百上千个高规格的生产节点,也可以独立运行于本地1核1GB虚拟机中,作为开箱即用的数据库实例使用。在本地计算机上使用时,Pigsty提供基于Vagrant与Virtualbox的沙箱。可以一键拉起与生产环境一致的数据库环境,用于学习,开发,测试数据分析,数据可视化等场景。
用户接口
Clearly, we must break away from the sequential and not limit the computers. We must state definitions and provide for priorities and descriptions of data. We must state relation‐ ships, not procedures.
—Grace Murray Hopper, Management and the Computer of the Future (1962)
Pigsty吸纳了Kubernetes架构设计中的精髓,采用声明式的配置方式与幂等的操作剧本。用户只需要描述“自己想要什么样的数据库”,而无需关心Pigsty如何去创建它,修改它。Pigsty会根据用户的配置文件清单,在几分钟内从裸机节点上创造出所需的数据库集群。
在管理与使用上,Pigsty提供了不同层次的用户界面,以满足不同用户的需求。新手用户可以使用一键拉起的本地沙箱与图形用户界面,而开发者则可以选择使用pigsty-cli命令行工具与配置文件的方式进行管理。经验丰富的DBA、运维与架构师则可以直接通过Ansible原语对执行的任务进行精细控制。

灵活开放的扩展机制
PostgreSQL的 可扩展性(Extensible) 一直为人所称道,各种各样的扩展插件让PostgreSQL成为了最先进的开源关系型数据库。Pigsty亦尊重这一价值,提供了一种名为“Datalet”的扩展机制,允许用户和开发者对Pigsty进行进一步的定制,将其用到“意想不到”的地方,例如:数据分析与可视化。

当我们拥有监控系统与管控方案后,也就拥有了开箱即用的可视化平台Grafana与功能强大的数据库PostgreSQL。这样的组合拥有强大的威力 —— 特别是对于数据密集型应用而言。用户可以在无需编写前后端代码的情况下,进行数据分析与数据可视化,制作带有丰富交互的数据应用原型,甚至应用本身。
Pigsty集成了Echarts,以及常用地图底图等,可以方便地实现高级可视化需求。比起Julia,Matlab,R这样的传统科学计算语言/绘图库而言,PG + Grafana + Echarts的组合允许您以极低的成本制作出可分享,可交付,标准化的数据应用或可视化作品。
Pigsty监控系统本身就是Datalet的典范:所有Pigsty高级专题监控面板都会以Datalet的方式发布。Pigsty也自带了一些有趣的Datalet案例:Redis监控系统,新冠疫情数据分析,七普人口数据分析,PG日志挖掘等。后续还会添加更多的开箱即用的Datalet,不断扩充Pigsty的功能与应用场景。
免费友好的开源协议

Once open source gets good enough, competing with it would be insane.
Larry Ellison —— Oracle CEO
在软件行业,开源是一种大趋势,互联网的历史就是开源软件的历史,IT行业之所以有今天的繁荣,人们能享受到如此多的免费信息服务,核心原因之一就是开源软件。开源是一种真正成功的,由开发者构成的communism(译成社区主义会更贴切):软件这种IT业的核心生产资料变为全世界开发者公有,人人为我,我为人人。
一个开源程序员工作时,其劳动背后其实可能蕴含有数以万计的顶尖开发者的智慧结晶。通过开源,所有社区开发者形成合力,极大降低了重复造轮子的内耗。使得整个行业的技术水平以匪夷所思的速度向前迈进。开源的势头就像滚雪球,时至今日已经势不可挡。除了一些特殊场景和路径依赖,软件开发中闭门造车搞自力更生已经成了一个大笑话。
依托开源,回馈开源。Pigsty采用了友好的Apache License 2.0,可以免费用于商业目的。只要遵守Apache 2 License的显著声明条款,也欢迎云厂商与软件厂商集成与二次研发商用。
关于Pigsty
A system cannot be successful if it is too strongly influenced by a single person. Once the initial design is complete and fairly robust, the real test begins as people with many different viewpoints undertake their own experiments. — Donald Knuth
Pigsty围绕开源数据库PostgreSQL而构建,PostgreSQL是世界上最先进的开源关系型数据库,而Pigsty的目标就是:做最好用的开源PostgreSQL发行版。
在最开始时,Pigsty并没有这么宏大的目标。因为在市面上找不到任何满足我自己需求的监控系统,因此我只好自己动手,丰衣足食,给自己做了一个监控系统。没有想到它的效果出乎意料的好,有不少外部组织PG用户希望能用上。紧接着,监控系统的部署与交付成了一个问题,于是又将数据库部署管控的部分加了进去;在生产环境应用后,研发希望能在本地也有用于测试的沙箱环境,于是又有了本地沙箱;有用户反馈ansible不太好用,于是就有了封装命令的pigsty-cli命令行工具;有用户希望可以通过UI编辑配置文件,于是就有了Pigsty GUI。就这样,需求越来越多,功能也越来越丰富,Pigsty也在长时间的打磨中变得更加完善,已经远远超出了最初的预期。
做这件事本身也是一种挑战,做一个发行版有点类似于做一个RedHat,做一个SUSE,做一个“RDS产品”。通常只有一定规模的专业公司与团队才会去尝试。但我就是想试试,一个人可不可以?实际上除了慢一点,也没什么不可以。一个人在产品经理、开发者,终端用户的角色之间转换是很有趣的体验,而“Eat dog food”最大的好处就是,你自己既是开发者也是用户,你了解自己需要什么,也不会在自己的需求上偷懒。
不过,正如高德纳所说:“带有太强个人色彩的系统无法成功”。 要想让Pigsty成为一个具有旺盛生命力的项目,就必须开源,让更多的人用起来。“当最初的设计完成并足够稳定后,各式各样的用户以自己的方式去使用它时,真正的挑战才刚刚开始”。
Pigsty很好的解决了我自己的问题与需求,现在我希望它可以帮助到更多的人,并让PostgreSQL的生态更加繁荣,更加多彩。
为什么PostgreSQL前途无量?
最近做的事儿都围绕着PostgreSQL生态,因为我一直觉得这是一个前途无量的方向。
为什么这么说?因为数据库是信息系统的核心组件,关系型数据库是数据库中的绝对主力,而PostgreSQL是世界上最先进的开源关系型数据库。占据天时地利,何愁大业不成?
做一件事最重要的就是认清形势,时来天地皆同力,运去英雄不自由。
天下大势
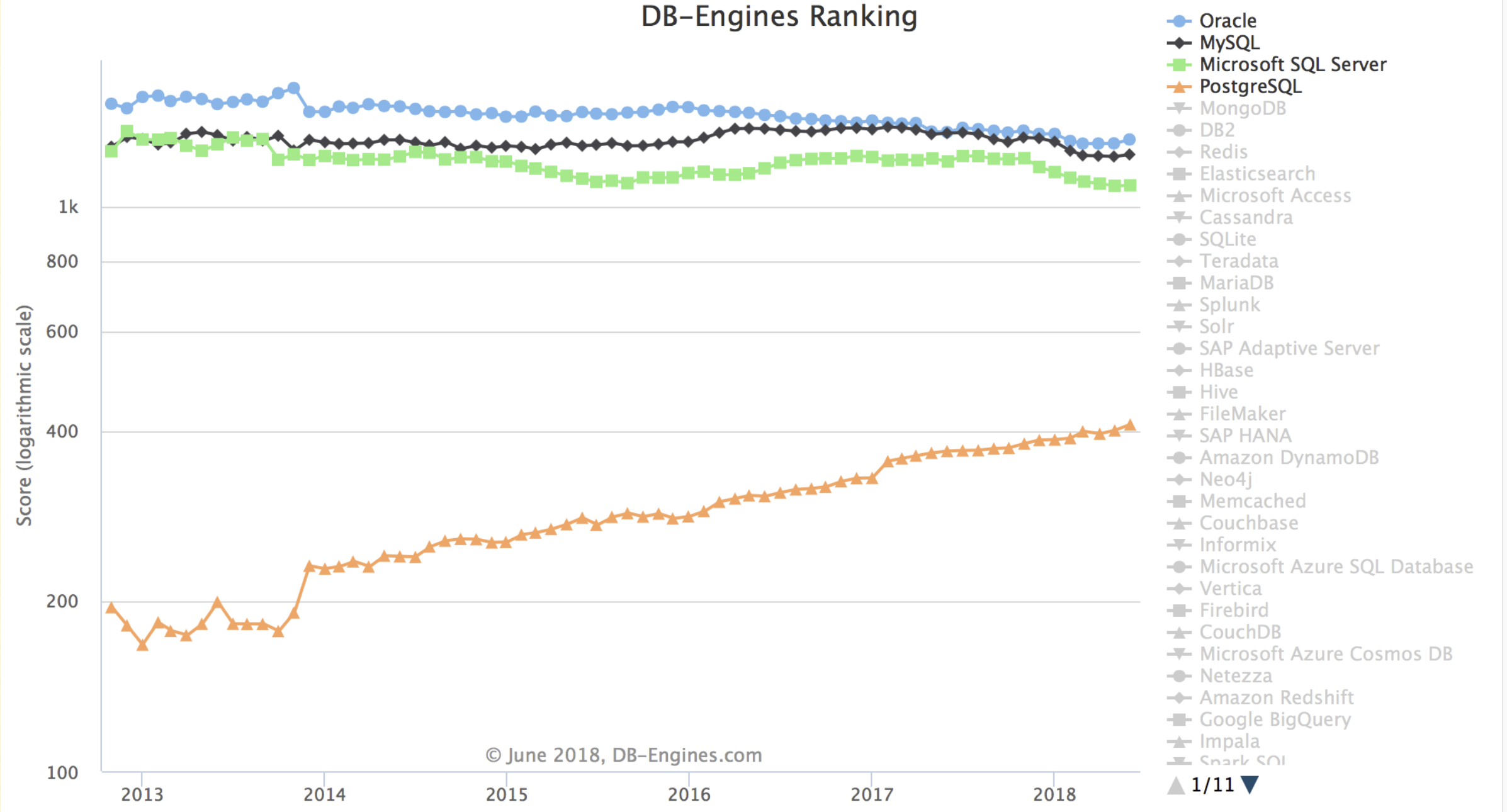
今天下三分,然Oracle | MySQL | SQL Server 疲敝,日薄西山。PostgreSQL紧随其后,如日中天。前四的数据库中,前三者都在走下坡路,唯有PG增长势头不减,此消彼长,前途无量。
![]()
数据库流行度趋势:https://db-engines.com/en/ranking_trend
(注意这是对数坐标系)
在唯二两个头部开源关系型数据库 MySQL & PgSQL 中,MySQL (2nd) 虽占上风,但其生态位却在逐渐被PostgreSQL (4th) 和非关系型的文档数据库MongoDB (5th) 抢占。按照现在的势头,几年后PostgreSQL的流行度即将跻身前三,与Oracle、MySQL分庭抗礼。
竞争关系
关系型数据库的生态位高度重叠,其关系可以视作零和博弈。与PostgreSQL形成直接竞争关系的,就是Oracle与MySQL。
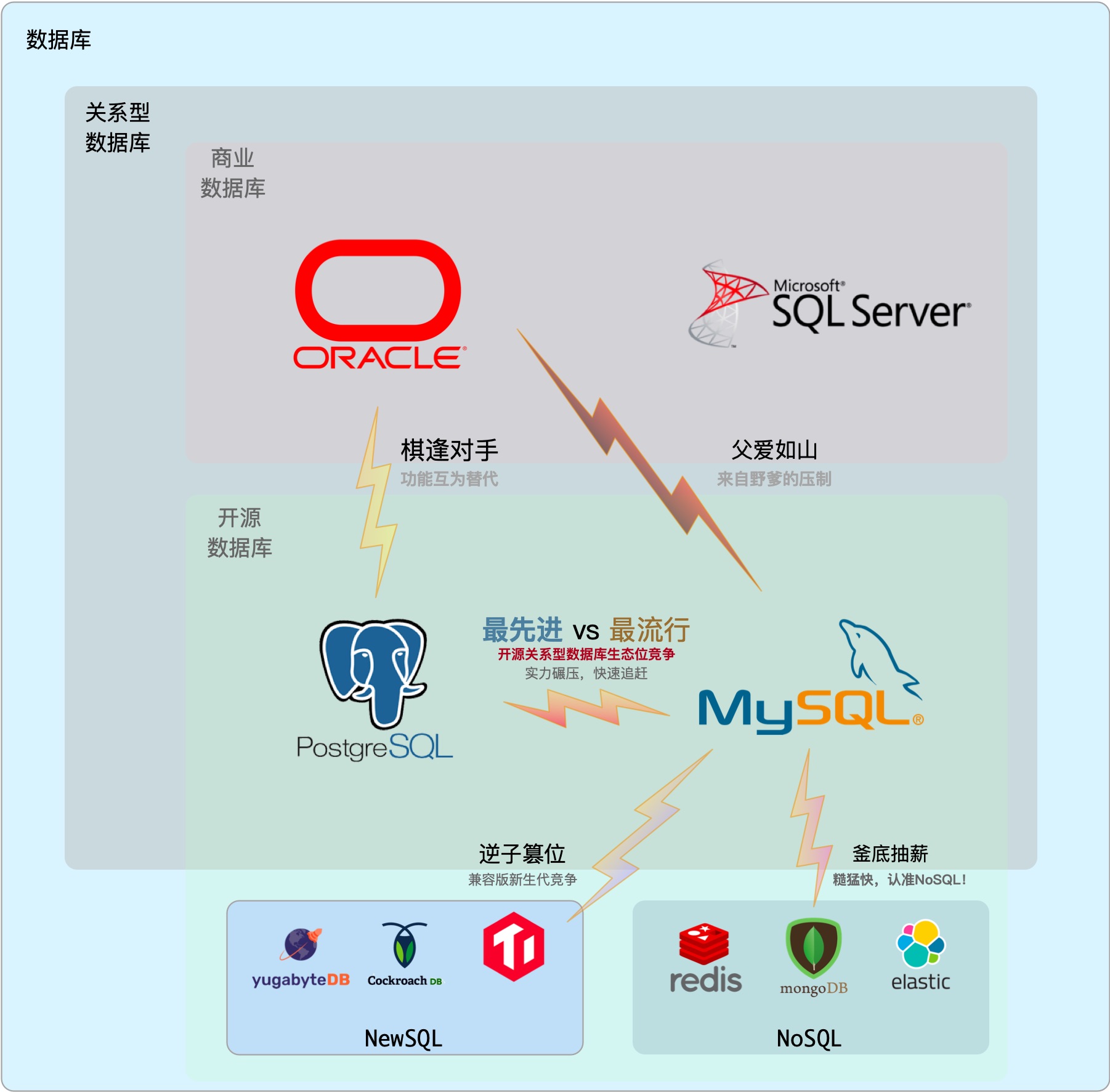
Oracle流行度位居第一,是老牌商业数据库,有着深厚的历史技术积淀,功能丰富,支持完善。稳坐数据库头把交椅,广受不差钱的企业组织喜爱。但Oracle费用昂贵,且以讼棍行径成为知名的业界毒瘤。排名第三的SQL Server属于相对独立的微软生态,性质上与Oracle类似,都属于商业数据库。商业数据库整体受开源数据库冲击,流行度处于缓慢衰减的状态。
MySQL流行度位居第二,但树大招风,处于前有狼后有虎,上有野爹下有逆子的不利境地:在严谨的事务处理和数据分析上,MySQL被同为开源关系型数据库的PgSQL甩开几条街;而在糙猛快的敏捷方法论上,MySQL又不如新兴NoSQL。同时,MySQL上有养父Oracle的压制,中有MariaDB分家,下有诸如TiDB,OB之类的兼容性新数据库分羹,因而也止步不前。
唯有PostgreSQL迎头赶上,保持着近乎指数增长的势头。如果说几年前PG的势还是Potential,那么现在Potential已经开始兑现为Impact,开始对竞品构成强力挑战。
而在这场你死我活的斗争中,PostgreSQL占据了三个“势”:
-
开源软件普及发展,蚕食商业软件市场
在去IOE与开源浪潮的大背景下,凭借开源生态对商业软件(Oracle)形成压制。
-
满足用户日益增长的数据处理功能需求
凭借地理空间数据的事实标准PostGIS处理立于不败之地,凭借对标Oracle的极为丰富的功能,对MySQL形成技术压制。
-
市场份额均值回归的势
国内PG市场份额因历史原因,远低于世界平均水平,本身蕴含着巨大势能。
Oracle作为老牌商业软件,才毋庸质疑,同时作为业界毒瘤,“德”也不必多说,故曰:“有才无德”。MySQL有开源之功德,但它一来采用了GPL协议,比起使用无私宽松BSD协议的PgSQL还是差不少意思,二来认贼作父,被Oracle收购,三来才疏学浅,功能简陋,故曰“才浅德薄”。
德不配位,必有灾殃。唯有PostgreSQL,既占据了开源崛起之天时,又把握住功能强劲之地利,还有着宽松BSD协议之人和。正所谓:藏器于身,因时而动。不鸣则已,一鸣惊人。德才兼备,攻守之势易矣!
德才兼备
PostgreSQL的德
PG的“德”在于开源。什么叫“德”,合乎于“道”的表现就是德。而这条“道”就是开源。
PG本身就是祖师爷级开源软件,是开源世界中的一颗明珠,是全世界开发者群策群力的成功典范。而且更重要的是它采用无私的BSD协议:除了打着PG的名号招摇撞骗外,基本可以说是百无禁忌:比如换皮改造为国产数据库出售。PG可谓无数数据库厂商们的衣食父母。子孙满堂,活人无数,功德无量。
数据库谱系图,若列出所有PgSQL衍生版,估计可以撑爆这张图
PostgreSQL的才
PG的“才”在于一专多长。PostgreSQL是一专多长的全栈数据库,天生就是HTAP,超融合数据库,一个打十个。基本单一组件便足以覆盖中小型企业绝大多数的数据库需求:OLTP,OLAP,时序数据库,空间GIS,全文检索,JSON/XML,图数据库,缓存,等等等等。
PostgreSQL在一个很可观的规模内都可以独立扮演多面手的角色,一个组件当多种组件使。而单一数据组件选型可以极大地削减项目额外复杂度,这意味着能节省很多成本。它让十个人才能搞定的事,变成一个人就能搞定的事。 如果真有那么一样技术可以满足你所有的需求,那么使用该技术就是最佳选择,而不是试图用多个组件来重新实现它。
参考阅读:PG好处都有啥
开源之德
开源是有大功德的。互联网的历史就是开源软件的历史,IT行业之所以有今天的繁荣,人们能享受到如此多的免费信息服务,核心原因之一就是开源软件。开源是一种真正成功的,由开发者构成的communism(译成社区主义会更贴切):软件这种IT业的核心生产资料变为全世界开发者公有,人人为我,我为人人。
一个开源程序员干活时,其劳动背后其实可能蕴含有数以万计的顶尖开发者的智慧结晶。互联网程序员贵,因为从效果上来讲,其实程序员不是一个工人,而是一个指挥软件和机器来干活的包工头。 程序员自己就是核心生产资料,服务器很容易取得(相比其他行业的科研设备与实验环境),软件来自公有社区,一个或几个高级的软件工程师可以很轻松的利用开源生态快速解决领域问题。
通过开源,所有社区开发者形成合力,极大降低了重复造轮子的内耗。使得整个行业的技术水平以匪夷所思的速度向前迈进。开源的势头就像滚雪球,时至今日已经势不可挡。基本上除了一些特殊场景和路径依赖,软件开发中闭门造车搞自力更生几乎成了一个大笑话。
所以说,搞数据库也好,做软件也罢,要搞技术就要搞开源的技术,闭源的东西生命力太弱,没意思。开源之德,也是PgSQL与MySQL对Oracle的最大底气所在。
生态之争
开源的核心就在于生态(ECO),每一个开源技术都有自己的小生态。所谓生态就是各种主体及其环境通过密集相互作用构成的一个系统,而开源软件的生态模式大致可以描述为由以下三个步骤组成的正反馈循环:
- 开源软件开发者给开源软件做贡献
- 开源软件本身免费,吸引更多用户
- 用户使用开源软件,产生需求,创造更多开源软件相关岗位
开源生态的繁荣有赖于这个闭环,而生态系统的规模(用户/开发者数量)与复杂度(用户/开发者质量)直接决定了这个软件的生命力,所以每一个开源软件都有天命去扩大自己的规模。而软件的规模通常取决于软件所占据的生态位,如果不同的软件的生态位重叠,就会发生竞争。在开源关系型数据库的生态位中,PgSQL与MySQL就是最直接的竞争者。
流行 vs 先进
MySQL的口号是“世界上最流行的开源关系型数据库”,而PostgreSQL的Slogan则是“世界上最先进的开源关系型数据库”,一看这就是一对老冤家了。这两个口号很好的反映出了两种产品的特质:PostgreSQL是功能丰富,一致性优先,高大上的严谨的学院派数据库;MySQL是功能粗陋,可用性优先,糙猛快的“工程派”数据库。
MySQL的主要用户群体集中在互联网公司,互联网公司的典型特点是什么?追逐潮流糙猛快,糙说的是互联网公司业务场景简单(CRUD居多);数据重要性不高,不像传统行业(例如银行)那样在意数据的一致性(正确性);可用性优先(相比停服务更能容忍数据丢乱错,而一些传统行业宁可停止服务也不能让账目出错)。 猛说的则是互联网行业数据量大,它们需要的就是水泥槽罐车,而不是高铁和载人飞船。 快说的则是互联网行业需求变化多端,出活周期短,要求响应时间快,大量需求的就是开箱即用的软件全家桶(如LAMP)和简单培训一下就能干活的CRUD Boy。于是糙猛快的互联网公司和糙猛快的MySQL一拍即合。
而PgSQL的用户则更偏向于传统行业,传统行业之所以称为传统行业,就是因为它们已经走过了野蛮生长的阶段,有着成熟的业务模型与深厚的底蕴积淀。它们需要的是正确的结果,稳定的表现,丰富的功能,对数据进行分析加工提炼的能力。所以在传统行业中,往往是Oracle、SQL Server、PostgreSQL的天下。特别是在地理相关的场景中更是有着不可替代的地位。与此同时,不少互联网公司的业务也开始成熟沉淀,已经一只脚迈入“传统行业”了,越来越多的互联网公司脱离了糙猛快的低级循环,将目光投向PostgreSQL 。
谁更正确?
最了解一个人的的往往是他的竞争对手,PostgreSQL与MySQL的口号都很精准地戳中了对手的痛点。PgSQL“最先进”的潜台词就是MySQL太落后,而MySQL”最流行“就是说PgSQL不流行。用户少但先进,用户多但落后。哪一个更”好“?这种价值判断的问题不好回答。
但我认为时间站在 先进 技术的一边:因为先进与落后是技术的核心度量,是因,而流行与否则是果;流行不流行是内因(技术是否先进)和外因(历史路径依赖)共同对时间积分的结果。当下的因会反映为未来的果:流行的东西因为落后而过气,而先进的东西会因为先进变得流行。
虽然很多流行的东西都是垃圾,但流行并不一定代表着落后。如果只是缺少一些功能,MySQL还不至于被称为“落后”。问题在于MySQL已经糙到连事务这种关系型数据库的基本功能都有缺陷,那就不是落后不落后能概括的问题,而是合格不合格的问题了。
ACID
一些作者声称,支持通用的两阶段提交代价太大,会带来性能与可用性的问题。让程序员来处理过度使用事务导致的性能问题,总比缺少事务编程好得多。
——James Corbett等,Spanner:Google的全球分布式数据库(2012)
在我看来, MySQL的哲学可以称之为:“好死不如赖活着”,以及,“我死后哪管洪水滔天”。 其“可用性”体现在各种“容错”上,例如允许呆瓜程序员写出的错误的SQL查询也能跑起来。最离谱的例子就是MySQL竟然允许部分成功的事务提交,这就违背了关系型数据库的基本约束:原子性与数据一致性。
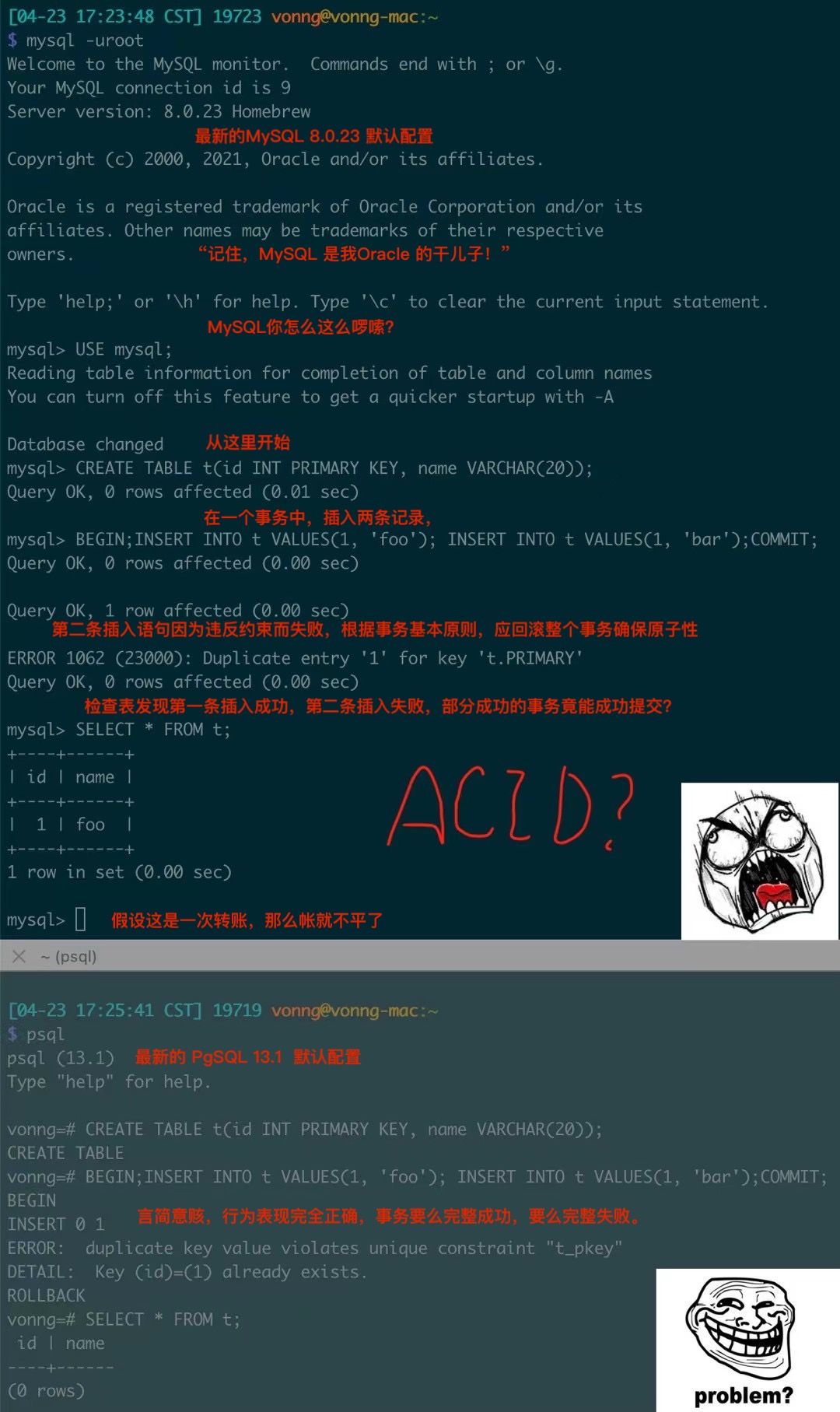
图:MySQL竟然允许部分成功的事务提交
这里在一个事务中插入了两条记录,第一条成功,第二条因为约束失败。根据事务的原子性,整个事务要么整个成功,要么整个失败(最终一条都没有插入)。结果MySQL的默认表现竟然是允许部分成功的事务提交,也就是事务没有原子性,没有原子性就没有一致性,如果这个事务是一笔转账(先扣再加),因为某些原因失败,那这里的帐就做不平了。这种数据库如果用来记账恐怕是一笔糊涂账,所以说什么“金融级MySQL”恐怕就是一个笑话。
当然,滑稽的是还有一些MySQL用户将其称为“特性”,说这体现了MySQL的容错性。实际上,此类“特殊容错”需求在SQL标准中完全可以通过SAVEPOINT机制实现。PgSQL对此的实现就堪称典范,psql客户端允许通过ON_ERROR_ROLLBACK选项,隐式地在每条语句后创建SAVEPOINT,并在语句失败后自动ROLLBACK TO SAVEPOINT,以标准SQL的方式,以客户端可选项的形式,在不破坏事物ACID的情况下,同样实现这种看上去便利实则苟且的功能。相比之下,MySQL的这种所谓“特性”是以直接在服务端默认牺牲事务ACID为代价的(这意味着用户使用JDBC,psycopg等应用驱动也照样受此影响)。
如果是互联网业务,注册个新用户丢个头像、丢个评论可能不是什么大事。数据那么多,丢几条,错几条又算个什么?别说是数据,业务本身很可能都处于朝不保夕的状态,所以糙又如何?万一成功了,前人拉的屎反正也是后人来擦。所以一些互联网公司通常并不在乎这些。
PostgreSQL所谓“严格的约束与语法“可能对新人来说“不近人情”,例如,一批数据中如果有几条脏数据,MySQL可能会照单全收,而PG则会严格拒绝。尽管苟且妥协看上去很省事,但在其他地方卖下了雷:因为逻辑炸弹深夜加班排查擦屁股的工程师,和不得不天天清洗脏数据的数据分析师肯定对此有很大怨念。从长期看,要想成功,做正确的事最重要。
一个成功的技术,现实的优先级必须高于公关,你可以糊弄别人,但糊弄不了自然规律。
——罗杰斯委员会报告(1986)
MySQL的流行度并没有和PgSQL相差太远,然而其功能比起PostgreSQL和Oracle却是差距不小。Oracle与PostgreSQL算诞生于同一时期,再怎么斗,立场与阵营不同,也有点惺惺相惜的老对手的意思:都是扎实修炼了半个世纪内功,厚积薄发的老法师。而MySQL就像心浮气躁耍刀弄枪的二十来岁毛头小伙子,凭着一把蛮力,借着互联网野蛮生长的黄金二十年趁势而起,占山为王。
时代所赋予的红利,也会随时代过去而退潮。在这个变革的时代中,没有先进的功能打底,“流行”也恐怕也难以长久。
发展前景
从个人职业发展前景的角度看,很多数程序员学习一门技术的原因都是为了提高自己的技术竞争力(从而更好占坑赚钱)。PostgreSQL是各种关系型数据库中性价比最高的选择:它不仅可以用来做传统的CRUD OLTP业务,数据分析更是它的拿手好戏。各种特色功能更是提供了切入多种行业以的契机:基于PostGIS的地理时空数据处理分析,基于Timescale的时序金融物联网数据处理分析,基于Pipeline存储过程触发器的流式处理,基于倒排索引全文检索的搜索引擎,FDW对接统一各式各样的外部数据源。可以说,它是真正一专多长的全栈数据库,用它可以实现的功能要比单纯的OLTP数据库要丰富得多,更是为CRUD码农提供了转型和深入的进阶道路。
从企业用户的角度来看,PostgreSQL在一个很可观的规模内都可以独立扮演多面手的角色,一个组件当多种组件使。而单一数据组件选型可以极大地削减项目额外复杂度,这意味着能节省很多成本。它让十个人才能搞定的事,变成一个人就能搞定的事。 当然这不是说PG要一个打十个把其他数据库的饭碗都掀翻,专业组件在专业领域的实力是毋庸置疑的。但切莫忘记,为了不需要的规模而设计是白费功夫,实际上这属于过早优化的一种形式。如果真有那么一样技术可以满足你所有的需求,那么使用该技术就是最佳选择,而不是试图用多个组件来重新实现它。
以探探为例,在250WTPS与200TB数据的量级下,单一PostgreSQL选型依然能稳如狗地支撑业务。能在很可观的规模内做到一专多长,除了本职的OLTP,Pg还在相当长的时间里兼任了缓存,OLAP,批处理,甚至消息队列的角色。当然神龟虽寿,犹有竟时。最终这些兼职功能还是要逐渐分拆出去由专用组件负责,但那已经是近千万日活时的事了。
从商业生态的角度看,PostgreSQL也有巨大的优势。一来PG技术先进,可称为 “开源版Oracle”。原生的PG基本可以对Oracle的功能做到八九成兼容,EDB更是有96% Oracle兼容的专业PG发行版。因此在抢占去O腾退出的市场中,PostgreSQL及其衍生版本的技术优势是压倒性的。二来PG协议友善,采用了宽松的BSD协议。因此各种数据库厂商,云厂商出品的“自研数据库”,以及很多“云数据库”大体都是基于PgSQL改造的。例如最近HW基于PostgreSQL搞openGaussDB就是一个很明智的选择。不要误会,PG的协议确实允许这样做,而且这样做也确实让PostgreSQL的生态更加繁荣壮大。卖PostgreSQL衍生版是一个很成熟的市场:传统企业不差钱且愿意为此付费买单。开源天才之火有商业利益之油浇灌,因而源源不断地释放出旺盛的生命力。
vs MySQL
作为老对手,MySQL的处境就有些尴尬了。
从个人职业发展上来看,学MySQL主要就是干CRUD。学好增删改查成为一个合格的码农是没问题的,然而谁又愿意一直“数据矿工”的活呢?数据分析才是数据产业链上的暴利肥差。以MySQL孱弱的分析能力,很难支持CURD程序员升级转型发展。此外,PostgreSQL的市场需求摆在那里,但现在却面临供不应求的状况(以至于现在大量良莠不齐的PG培训机构如雨后春笋般冒了出来),MySQL的人确实比PgSQL的人好招,这是不假的。但反过来说MySQL界的内卷程度也要大的多,供不应求方才体现稀缺性,人太多了技能也就贬值了。
从企业用户的角度来看,MySQL就是专用于OLTP的单一功能组件,往往需要ES, Redis, Mongo等其他等等一起配合才能满足完整的数据存储需求,而PG基本就不会有这个问题。此外,MySQL和PgSQL都是开源数据库,都“免费”。免费的Oracle和免费的MySQL用户会选择哪个呢?
从商业生态来看,MySQL面临的最大问题是 叫好不叫座。叫好当然是因为越流行则声音越大,尤其主要的用户互联网企业本身就占据话语权高地。不叫座当然也是因为互联网公司本身对于这类软件付费的意愿是极弱的:怎么算都是养几个MySQL DBA直接用开源的更合算。此外,因为MySQL的GPL协议要求衍生软件也要开源,软件厂商基于MySQL研发的动机也不强,基本都是采用 兼容“MySQL” 协议来分MySQL的市场蛋糕,而不是基于MySQL的代码进行开发与回馈,让人对其生态健康程度产生怀疑。
当然MySQL最大的问题就在于:它的生态位越来越狭窄。论严谨的事务处理与数据分析,PostgreSQL甩开它几条街;论糙猛快,快速出原型,NoSQL全家桶又要比MySQL方便太多。论商业发财,上面有Oracle干爹压着;论开源生态,又不断出现MySQL兼容的新生代产品来尝试替代主体。可以说MySQL处在一种吃老本的位置上,只是凭籍历史积分存量维持着现状的地位。时间是否会站在MySQL这一边,我们拭目以待。
vs NewSQL
最近市场上当然也有一些很亮眼的NewSQL产品,例如TiDB,Cockroachdb,Yugabytedb等等。何如?我认为它们都是很好的产品,有一些不错的技术亮点,都是对开源技术的贡献。但是它们可能同样面临叫好不叫座的困局。
NewSQL的大体特征是:主打“分布式”的概念,通过“分布式”解决水平扩展性与容灾高可用两个问题,并因分布式的内在局限性会牺牲许多功能,只能提供较为简单有限的查询支持。分布式数据库在高可用容灾方面与传统主从复制并没有质的区别,因此其特征主要可以概括为“以量换质”。
然而对很多企业而言,牺牲功能换取扩展性很可能是一个伪需求或弱需求。在我接触过的为数不少的用户中,绝大多数场景下的的数据量和负载水平完全落在单机Postgres的处理范围内(目前弄过的记录是单库15TB,单集群40万TPS)。从数据量上来讲,绝大多数企业终其生命周期的数据量也超不过这个瓶颈;至于性能就更不重要了,过早优化是万恶之源,很多企业的DB性能余量足够让他们把所有业务逻辑用存储过程编写然后高高兴兴的跑在数据库里。
NewSQL的祖师爷Google Spanner就是为了解决海量数据扩展性的问题,但又有多少企业能有Google的业务数据量?恐怕还是只有典型的互联网公司,或者某些大企业的部分业务会有这种量级的数据存储需求。所以和MySQL一样,NewSQL的问题就回到了谁来买单这个根本问题上。恐怕到最后只能还是由投资人和国资委来买吧。
但最起码,NewSQL的这种尝试始终是值得赞扬的。
vs 云数据库
“我想直率地说:多年来,我们就像个傻子一样,他们拿着我们开发的东西大赚了一笔”。
—— Ofer Bengal , Redis Labs 首席执行官
另一个值得关注的“竞争者”是所谓云数据库,包括两种,一种是放在云上托管的开源数据库。例如 RDS for PostgreSQL,另一种是自研的新一代云数据库。
针对前者,主要的问题是“云厂商吸血”。如果云厂商售卖开源软件,实际上会导致就会导致开源软件的相关岗位和利润向云厂商集中,而云厂商是否允许自己的程序员给开源项目做贡献,做多少贡献,其实是很难说的。负责人的大厂通常是会回馈社区,回馈生态的,但这取决于它们的自觉。开源软件还是应当将命运握在自己手中,防止云厂商过分做大形成垄断。相比少量垄断巨头,多数分散的小团体能提供更高的生态多样性,更有利于生态健康发展。
Gartner称2022年75%的数据库将部署至云平台,这个牛逼吹的太大了。(但也有圆的办法,毕竟用一台机器就可以轻松创建几亿个sqlite文件数据库,这算不算?)。因为云计算解决不了一个根本性的问题 —— 信任。实际上在商业活动中,技术牛逼不牛逼是很次要的因素,Trust才是最关键的。数据是很多企业的生命线,云厂商又不是真正的中立第三方,谁能保证数据不会被其偷窥,盗窃,泄漏,甚至直接被卡脖子关停(如各路云厂商锤Parler)?TDE之类的透明加密解决方案也属于鸡肋,充分的恶心了自己,但也防不住真正的有心人。也许要等真正实用的高效全同态加密技术成熟才能解决信任与安全这个问题吧。
另一个根本性的问题在于成本:就目前云厂商的定价策略,云数据库只有在小微规模下有优势。例如一台D740 64核|400G内存|3TB PCI-E SSD的高配机型四年综合成本撑死了十几万块。然而我能找到最大的规格RDS(比这差很多,32核|128GB)一年的价格就这个数了。只要数据量节点数稍微上那么点规模,雇个DBA自建就合算太多了。
云数据库的主要优势还是在于管控,说白了就是用起来方便,点点鼠标。日常运维功能已经覆盖的比较全面,也有一些基础的监控支持。总之下限是摆在那里,如果找不到靠谱的数据库人才,用云数据库起码不至于出太多幺蛾子。 不过这些管控软件虽好,基本都是闭源的,而且与供应商深度绑定。
如果你想找一个开源的PostgreSQL监控管控一条龙解决方案,不妨试试Pigsty。
后一种云数据库以AWS Aurora为代表,也包括一系列类似产品如阿里云PolarDB,腾讯云CynosDB。基本都是采用PostgreSQL与MySQL作为Base和协议层,基于云基础设施(共享存储,S3,RDMA)进行定制化,对扩容速度与性能进行了优化。这类产品在技术上肯定是有新颖性和创造性的。但灵魂问题就是,这类产品相比直接使用原生PostgreSQL的收益到底在哪里呢?能看到立竿见影的好处就是集群扩容会快很多(从几小时级到5分钟),不过相比高昂的费用与供应商锁定的问题,实在是挠不到痛点和痒点。
总的来说,云数据库对原生PostgreSQL 构成的威胁是有限的。也不用太担心云厂商的问题,云厂商总的来说还开源软件生态的一份子,对社区和生态是有贡献的。赚钱嘛,不磕碜,大家都有钱赚了,才有余力去搞公益,对不对?
弃暗投明?
通常来说,Oracle的程序员转PostgreSQL不会有什么包袱,因为两者功能类似,大多数经验都是通用的。实际上,很多PostgreSQL生态的成员都是从Oracle阵营转投PG的。例如国内著名的Oracle服务商云和恩墨(由中国第一位Oracle ACE总监盖国强创办),去年就公开宣布“躬身入局”,拥抱PostgreSQL。
也有不少MySQL阵营转投PgSQL的,其实这类用户对两者的区别感受才是最深的:基本上都是一副相见恨晚,弃暗投明的样子。实际上我自己最开始也是先用MySQL😆,能自己选型后就拥抱了PgSQL。不过有些老程序员已经和MySQL形成了深度利益绑定,嚷嚷着MySQL多好多好,还要不忘来碰瓷喷一喷PgSQL(特指某人)。这个其实是可以理解的,触动利益比触动灵魂还难,看到自己擅长的技术日落西山那肯定是愤懑不平😠。毕竟一把年纪投在MySQL上,PostgreSQL🐘再好,让我抛弃我心爱的小海豚🐬,做不到啊。
不过,刚入行的年轻人还是有机会去选择一条更光明的道路的。时间是最公平的裁判,而新生代的选择则是最有代表性的标杆。据我个人观察,在新兴的极有活力的Golang开发者群体中,PostgreSQL的流行程度要显著高于MySQL,不少创业型、创新型的公司现在都选择Go+Pg作为自己的技术栈,例如Instagram,TanTan,Apple都是Go+PG。
我认为这一现象的主要原因就是新生代开发者的崛起,Go之于Java,就像PgSQL之于MySQL。长江后浪推前浪,这其实就是演化的核心机制 —— 新陈代谢。Go和PgSQL慢慢拍扁Java和MySQL,但Go和PgSQL当然也有可能在以后被诸如Rust和某些真正革命性的NewSQL数据库拍扁。但说到底,搞技术还是要搞那些前景光明的,不要去搞那些日暮西山的。(当然下海太早当烈士也不合适)。要去看新生代开发者在用什么,有活力的创业公司、新项目、新团队在用什么,弄这些是没有错的。
PG的问题
当然PgSQL有没有自己的问题?当然也有 —— 流行度。
流行度关乎着着用户规模,信任水平,成熟案例数量,有效需求反馈量,开发者数量等等。尽管按目前的流行度发展趋势,PG将在几年后超过MySQL,所以从长期来看,我觉得这并不是问题。但作为PostgreSQL社区的一员,我觉得很有必要去进一步做一些事情,Secure this success,并加快这一进度。而要想让一样技术更加流行,效果最好的方式就是:降低门槛。
所以,我做了一个开源软件Pigsty,要把PostgreSQL部署、监控、管理、使用的门槛从天花板砸到地板,它有三个核心目标:
- 做最顶尖最专业的开源PostgreSQL 监控系统(类tidashboard)
- 做门槛最低最好用的开源PostgreSQL管控方案(类tiup)
- 做开箱即用的与数据分析&可视化集成开发环境(类minikube)
当然这里细节限于篇幅就不展开了,详情留待下篇分说。
容器化数据库是个好主意吗?
对于无状态的应用服务而言,容器是一个相当完美的开发运维解决方案。然而对于带持久状态的服务 —— 数据库来说,事情就没有那么简单了。生产环境的数据库是否应当放入容器中,仍然是一个充满争议的问题。
站在开发者的角度上,我非常喜欢Docker,并始终相信Docker是未来软件开发部署运维的标准方式,而Kubernetes则是事实上的下一代“操作系统”。但站在DBA的立场上,我认为就目前而言,将生产环境数据库放入Docker中仍然是一个馊主意。
Docker解决什么问题?
让我们先来看一看Docker对自己的描述。


Docker用于形容自己的词汇包括:轻量,标准化,可移植,节约成本,提高效率,自动,集成,高效运维。这些说法并没有问题,Docker在整体意义上确实让开发和运维都变得更容易了。因而可以看到很多公司都热切地希望将自己的软件与服务容器化。但有时候这种热情会走向另一个极端:将一切软件服务都容器化,甚至是生产环境的数据库。
容器最初是针对无状态的应用而设计的,在逻辑上,容器内应用产生的临时数据也属于该容器的一部分。用容器创建起一个服务,用完之后销毁它。这些应用本身没有状态,状态通常保存在容器外部的数据库里,这是经典的架构与用法,也是容器的设计哲学。
但当用户想把数据库本身也放到容器中时,事情就变得不一样了:数据库是有状态的,为了维持这个状态不随容器停止而销毁,数据库容器需要在容器上打一个洞,与底层操作系统上的数据卷相联通。这样的容器,不再是一个能够随意创建,销毁,搬运,转移的对象,而是与底层环境相绑定的对象。因此,传统应用使用容器的诸多优势,对于数据库容器来说都不复存在。
可靠性
让软件跑起来,和让软件可靠地运行是两回事。数据库是信息系统的核心,在绝大多数场景下属于**关键(Critical)**应用,Critical Application可按字面解释,就是出了问题会要命的应用。这与我们的日常经验相符:Word/Excel/PPT这些办公软件如果崩了强制重启即可,没什么大不了的;但正在编辑的文档如果丢了、脏了、乱了,那才是真的灾难。数据库亦然,对于不少公司,特别是互联网公司来说,如果数据库被删了又没有可用备份,基本上可以宣告关门大吉了。
可靠性(Reliability)是数据库最重要的属性。可靠性是系统在困境(adversity)(硬件故障、软件故障、人为错误)中仍可正常工作(正确完成功能,并能达到期望的性能水准)的能力。可靠性意味着容错(fault-tolerant)与韧性(resilient),它是一种安全属性,并不像性能与可维护性那样的活性属性直观可衡量。它只能通过长时间的正常运行来证明,或者某一次故障来否证。很多人往往会在平时忽视安全属性,而在生病后,车祸后,被抢劫后才追悔莫及。安全生产重于泰山,数据库被删,被搅乱,被脱库后再捶胸顿足是没有意义的。
回头再看一看Docker对自己的特性描述中,并没有包含“可靠”这个对于数据库至关重要的属性。
可靠性证明与社区知识
如前所述,可靠性并没有一个很好的衡量方式。只有通过长时间的正确运行,我们才能对一个系统的可靠性逐渐建立信心。在裸机上部署数据库可谓自古以来的实践,通过几十年的持续工作,它很好的证明了自己的可靠性。Docker虽为DevOps带来一场革命,但仅仅五年的历史对于可靠性证明而言仍然是图样图森破。对关乎身家性命的生产数据库而言还远远不够:因为还没有足够的小白鼠去趟雷。
想要提高可靠性,最重要的就是从故障中吸取经验。故障是宝贵的经验财富:它将未知问题变为已知问题,是运维知识的表现形式。社区的故障经验绝大多都基于裸机部署的假设,各式各样的故障在几十年里都已经被人们踩了个遍。如果你遇到一些问题,大概率是别人已经踩过的坑,可以比较方便地处理与解决。同样的故障如果加上一个“Docker”关键字,能找到的有用信息就要少的多。这也意味着当疑难杂症出现时,成功抢救恢复数据的概率要更低,处理紧急故障所需的时间会更长。
微妙的现实是,如果没有特殊理由,企业与个人通常并不愿意分享故障方面的经验。故障有损企业的声誉:可能暴露一些敏感信息,或者是企业与团队的垃圾程度。另一方面,故障经验几乎都是真金白银的损失与学费换来的,是运维人员的核心价值所在,因此有关故障方面的公开资料并不多。
额外失效点
开发关心Feature,而运维关注Bug。相比裸机部署而言,将数据库放入Docker中并不能降低硬件故障,软件错误,人为失误的发生概率。用裸机会有的硬件故障,用Docker一个也不会少。软件缺陷主要是应用Bug,也不会因为采用容器与否而降低,人为失误同理。相反,引入Docker会因为引入了额外的组件,额外的复杂度,额外的失效点,导致系统整体可靠性下降。
举个最简单的例子,dockerd守护进程崩了怎么办,数据库进程就直接歇菜了。尽管这种事情发生的概率并不高,但它们在裸机上压根不会发生。
此外,一个额外组件引入的失效点可能并不止一个:Docker产生的问题并不仅仅是Docker本身的问题。当故障发生时,可能是单纯Docker的问题,或者是Docker与数据库相互作用产生的问题,还可能是Docker与操作系统,编排系统,虚拟机,网络,磁盘相互作用产生的问题。可以参见官方PostgreSQL Docker镜像的Issue列表:https://github.com/docker-library/postgres/issues?q=。
此外,彼之蜜糖,吾之砒霜。某些Docker的Feature,在特定的环境下也可能会变为Bug。
隔离性
Docker提供了进程级别的隔离性,通常来说隔离性对应用来说是个好属性。应用看不见别的进程,自然也不会有很多相互作用导致的问题,进而提高了系统的可靠性。但隔离性对于数据库而言不一定完全是好事。
一个微妙的真实案例是在同一个数据目录上启动两个PostgreSQL实例,或者在宿主机和容器内同时启动了两个数据库实例。在裸机上第二次启动尝试会失败,因为PostgreSQL能意识到另一个实例的存在而拒绝启动;但在使用Docker的情况下因其隔离性,第二个实例无法意识到宿主机或其他数据库容器中的另一个实例。如果没有配置合理的Fencing机制(例如通过宿主机端口互斥,pid文件互斥),两个运行在同一数据目录上的数据库进程能把数据文件搅成一团浆糊。
数据库需不需要隔离性?当然需要, 但不是这种隔离性。数据库的性能很重要,因此往往是独占物理机部署。除了数据库进程和必要的工具,不会有其他应用。即使放在容器中,也往往采用独占绑定物理机的模式运行。因此Docker提供的隔离性对于这种数据库部署方案而言并没有什么意义;不过对云数据库厂商来说,这倒真是一个实用的Feature,用来搞多租户超卖妙用无穷。
工具
数据库需要工具来维护,包括各式各样的运维脚本,部署,备份,归档,故障切换,大小版本升级,插件安装,连接池,性能分析,监控,调优,巡检,修复。这些工具,也大多针对裸机部署而设计。这些工具与数据库一样,都需要精心而充分的测试。让一个东西跑起来,与确信这个东西能持久稳定正确的运行,是完全不同的可靠性水准。
一个简单的例子是插件,PostgreSQL提供了很多实用的插件,譬如PostGIS。假如想为数据库安装该插件,在裸机上只要yum install然后create extension postgis两条命令就可以。但如果是在Docker里,按照Docker的实践原则,用户需要在镜像层次进行这个变更,否则下次容器重启时这个扩展就没了。因而需要修改Dockerfile,重新构建新镜像并推送到服务器上,最后重启数据库容器,毫无疑问,要麻烦的多。
再比如说监控,在传统的裸机部署模式下,机器的各项指标是数据库指标的重要组成部分。容器中的监控与裸机上的监控有很多微妙的区别。不注意可能会掉到坑里。例如,CPU各种模式的时长之和,在裸机上始终会是100%,但这样的假设在容器中就不一定总是成立了。再比方说依赖/proc文件系统的监控程序可能在容器中获得与裸机上涵义完全不同的指标。虽然这类问题最终都是可解的(例如把Proc文件系统挂载到容器内),但相比简洁明了的方案,没人喜欢复杂丑陋的work around。
类似的问题包括一些故障检测工具与系统常用命令,虽然理论上可以直接在宿主机上执行,但谁能保证容器里的结果和裸机上的结果有着相同的涵义?更为棘手的是紧急故障处理时,一些需要临时安装使用的工具在容器里没有,外网不通,如果再走Dockerfile→Image→重启这种路径毫无疑问会让人抓狂。
把Docker当成虚拟机来用的话,很多工具大抵上还是可以正常工作的,不过这样就丧失了使用的Docker的大部分意义,不过是把它当成了另一个包管理器用而已。有人觉得Docker通过标准化的部署方式增加了系统的可靠性,因为环境更为标准化更为可控。这一点不能否认。私以为,标准化的部署方式虽然很不错,但如果运维管理数据库的人本身了解如何配置数据库环境,将环境初始化命令写在Shell脚本里和写在Dockerfile里并没有本质上的区别。
可维护性
软件的大部分开销并不在最初的开发阶段,而是在持续的维护阶段,包括修复漏洞、保持系统正常运行、处理故障、版本升级,偿还技术债、添加新的功能等等。可维护性对于运维人员的工作生活质量非常重要。应该说可维护性是Docker最讨喜的地方:Infrastructure as code。可以认为Docker的最大价值就在于它能够把软件的运维经验沉淀成可复用的代码,以一种简便的方式积累起来,而不再是散落在各个角落的install/setup文档。在这一点上Docker做的相当出色,尤其是对于逻辑经常变化的无状态应用而言。Docker和K8s能让用户轻松部署,完成扩容,缩容,发布,滚动升级等工作,让Dev也能干Ops的活,让Ops也能干DBA的活(迫真)。
环境配置
如果说Docker最大的优点是什么,那也许就是环境配置的标准化了。标准化的环境有助于交付变更,交流问题,复现Bug。使用二进制镜像(本质是物化了的Dockerfile安装脚本)相比执行安装脚本而言更为快捷,管理更方便。一些编译复杂,依赖如山的扩展也不用每次都重新构建了,这些都是很爽的特性。
不幸的是,数据库并不像通常的业务应用一样来来去去更新频繁,创建新实例或者交付环境本身是一个极低频的操作。同时DBA们通常都会积累下各种安装配置维护脚本,一键配置环境也并不会比Docker慢多少。因此在环境配置上Docker的优势就没有那么显著了,只能说是Nice to have。当然,在没有专职DBA时,使用Docker镜像可能还是要比自己瞎折腾要好一些,因为起码镜像中多少沉淀了一些运维经验。
通常来说,数据库初始化之后连续运行几个月几年也并不稀奇。占据数据库管理工作主要内容的并不是创建新实例与交付环境,主要还是日常运维的部分。不幸的是在这一点上Docker并没有什么优势,反而会产生一些麻烦。
日常运维
Docker确实能极大地简化来无状态应用的日常维护工作,诸如创建销毁,版本升级,扩容等,但同样的结论能延伸到数据库上吗?
数据库容器不可能像应用容器一样随意销毁创建,重启迁移。因而Docker并不能对数据库的日常运维的体验有什么提升,真正有帮助的倒是诸如ansible之类的工具。而对于日常运维而言,很多操作都需要通过docker exec的方式将脚本透传至容器内执行。底下跑的还是一样的脚本,只不过用docker-exec来执行又额外多了一层包装,这就有点脱裤子放屁的意味了。
此外,很多命令行工具在和Docker配合使用时都相当尴尬。譬如docker exec会将stderr和stdout混在一起,让很多依赖管道的命令无法正常工作。以PostgreSQL为例,在裸机部署模式下,某些日常ETL任务可以用一行bash轻松搞定:
psql <src-url> -c 'COPY tbl TO STDOUT' |\
psql <dst-url> -c 'COPY tdb FROM STDIN'
但如果宿主机上没有合适的客户端二进制程序,那就只能这样用Docker容器中的二进制:
docker exec -it srcpg gosu postgres bash -c "psql -c \"COPY tbl TO STDOUT\" 2>/dev/null" |\ docker exec -i dstpg gosu postgres psql -c 'COPY tbl FROM STDIN;'
当用户想为容器里的数据库做一个物理备份时,原本很简单的一条命令现在需要很多额外的包装:docker套gosu套bash套pg_basebackup:
docker exec -i postgres_pg_1 gosu postgres bash -c 'pg_basebackup -Xf -Ft -c fast -D - 2>/dev/null' | tar -xC /tmp/backup/basebackup
如果说客户端应用psql|pg_basebackup|pg_dump还可以通过在宿主机上安装对应版本的客户端工具来绕开这个问题,那么服务端的应用就真的无解了。总不能在不断升级容器内数据库软件的版本时每次都一并把宿主机上的服务器端二进制版本升级了吧?
另一个Docker喜欢讲的例子是软件版本升级:例如用Docker升级数据库小版本,只要简单地修改Dockerfile里的版本号,重新构建镜像然后重启数据库容器就可以了。没错,至少对于无状态的应用来说这是成立的。但当需要进行数据库原地大版本升级时问题就来了,用户还需要同时修改数据库状态。在裸机上一行bash命令就可以解决的问题,在Docker下可能就会变成这样的东西:https://github.com/tianon/docker-postgres-upgrade。
如果数据库容器不能像AppServer一样随意地调度,快速地扩展,也无法在初始配置,日常运维,以及紧急故障处理时相比普通脚本的方式带来更多便利性,我们又为什么要把生产环境的数据库塞进容器里呢?
Docker和K8s一个很讨喜的地方是很容易进行扩容,至少对于无状态的应用而言是这样:一键拉起起几个新容器,随意调度到哪个节点都无所谓。但数据库不一样,作为一个有状态的应用,数据库并不能像普通AppServer一样随意创建,销毁,水平扩展。譬如,用户创建一个新从库,即使使用容器,也得从主库上重新拉取基础备份。生产环境中动辄几TB的数据库,用万兆网卡也需要个把钟头才能完成,也很可能还是需要人工介入与检查。相比之下,在同样的操作系统初始环境下,运行现成的拉从库脚本与跑docker run在本质上又能有什么区别?毕竟时间都花在拖从库上了。
使用Docker承放生产数据库的一个尴尬之处就在于,数据库是有状态的,而且为了建立这个状态需要额外的工序。通常来说设置一个新PostgreSQL从库的流程是,先通过pg_baseback建立本地的数据目录副本,然后再在本地数据目录上启动postmaster进程。然而容器是和进程绑定的,一旦进程退出容器也随之停止。因此为了在Docker中扩容一个新从库:要么需要先后启动pg_baseback容器拉取数据目录,再在同一个数据卷上启动postgres两个容器;要么需要在创建容器的过程中就指定好复制目标并等待几个小时的复制完成;要么在postgres容器中再使用pg_basebackup偷天换日替换数据目录。无论哪一种方案都是既不优雅也不简洁。因为容器的这种进程隔离抽象,对于数据库这种充满状态的多进程,多任务,多实例协作的应用存在抽象泄漏,它很难优雅地覆盖这些场景。当然有很多折衷的办法可以打补丁来解决这类问题,然而其代价就是大量非本征复杂度,最终受伤的还是系统的可维护性。
总的来说,不可否认Docker对于提高系统整体的可维护性是有帮助的,只不过针对数据库来说这种优势并不显著:容器化的数据库能简化并加速创建新实例或扩容的速度,但也会在日常运维中引入一些麻烦和问题。不过,我相信随着Docker与K8s的进步,这些问题最终都是可以解决克服的。
性能
性能也是人们经常关注的一个维度。从性能的角度来看,数据库的基本部署原则当然是离硬件越近越好,额外的隔离与抽象不利于数据库的性能:越多的隔离意味着越多的开销,即使只是内核栈中的额外拷贝。对于追求性能的场景,一些数据库选择绕开操作系统的页面管理机制直接操作磁盘,而一些数据库甚至会使用FPGA甚至GPU加速查询处理。
实事求是地讲,Docker作为一种轻量化的容器,性能上的折损并不大,这也是Docker相比虚拟机的优势所在。但毫无疑问的是,将数据库放入Docker只会让性能变得更差而不是更好。
总结
容器技术与编排技术对于运维而言是非常有价值的东西,它实际上弥补了从软件到服务之间的空白,其愿景是将运维的经验与能力代码化模块化。容器技术将成为未来的包管理方式,而编排技术将进一步发展为“数据中心分布式集群操作系统”,成为一切软件的底层基础设施Runtime。当越来越多的坑被踩完后,人们可以放心大胆的把一切应用,有状态的还是无状态的都放到容器中去运行。但现在,起码对于数据库而言,还只是一个美好的愿景。
最后需要再次强调的是,以上讨论仅限于生产环境数据库。换句话说,对于开发环境而言,我其实是很支持将数据库放入Docker中的,毕竟不是所有的开发人员都知道怎么配置本地测试数据库环境,使用Docker交付环境显然要比一堆手册简单明了的多。对于生产环境的无状态应用,甚至一些带有衍生状态的不甚重要衍生数据系统(譬如Redis缓存),Docker也是一个不错的选择。但对于生产环境的核心关系型数据库而言,如果里面的数据真的很重要,使用Docker前还望三思:我愿意当小白鼠吗?出了疑难杂症我能Hold住吗?真搞砸了这锅我背的动吗?
任何技术决策都是一个利弊权衡的过程,譬如这里使用Docker的核心权衡可能就是牺牲可靠性换取可维护性。确实有一些场景,数据可靠性并不是那么重要,或者说有其他的考量:譬如对于云计算厂商来说,把数据库放到容器里混部超卖就是一件很好的事情:容器的隔离性,高资源利用率,以及管理上的便利性都与该场景十分契合。这种情况下将数据库放入Docker中也许就是利大于弊的。但对于多数的场景而言,可靠性往往都是优先级最高的的属性,牺牲可靠性换取可维护性通常并不是一个可取的选择。更何况实际很难说运维管理数据库的工作会因为用了Docker而轻松多少:为了安装部署一次性的便利而牺牲长久的日常运维可维护性,并不是一个很好的生意。
综上所述,我认为就目前对于普通用户而言,将生产环境的数据库放入容器中恐怕并不是一个明智的选择。
理解时间:时间时区那些事
时间是个很玄妙的东西,看不见也摸不着。我们都能意识到时间的存在,但要给它下个定义,很多人也说不上来。本文当然不是为了探讨哲学问题,但对时间的正确理解,对正确处理工作生活中的时间问题很有帮助(例如,计算机中的时间表示与时间处理,数据库,编程语言中对于时间的处理)。
0x01 秒与计时
时间的单位是秒,但秒的定义并不是一成不变的。它有一个天文学定义,也有一个物理学定义。
世界时(UT1)
在最开始,秒的定义来源于日。秒被定义为平均太阳日的1/86400。而太阳日,则是由天文学现象定义的:两次连续正午时分的间隔被定义为一个太阳日;一天有86400秒,一秒等于86400分之一天,Perfect!以这一标准形成的时间标准,就称为世界时(Univeral Time, UT1),或不严谨的说,格林威治标准时(Greenwich Mean Time, GMT),下面就用GMT来指代它了。 这个定义很直观,但有一个问题:它是基于天文学现象的,即地球与太阳的周期性运动。不论是用地球的公转还是自转来定义秒,都有一个很尴尬的地方:虽然地球自转与公转的变化速度很慢,但并不是恒常的,譬如:地球的自转越来越慢,而地月位置也导致了每天的时长其实都不完全相同。这意味着作为物理基本单位的秒,其时长竟然是变化的。在衡量时间段的长短上就比较尴尬,几十年的一秒可能和今天的一秒长度已经不是一回事了。
原子时(TAI)
为了解决这个问题,在1967年之后,秒的定义变成了:铯133原子基态的两个超精细能级间跃迁对应辐射的9,192,631,770个周期的持续时间。秒的定义从天文学定义升级成为了物理学定义,其描述由相对易变的天文现象升级到了更稳定的宇宙中的基本物理事实。现在我们有了真正精准的秒啦:一亿年的偏差也不超过一秒。
当然,这么精确的秒除了用来衡量时间间隔,也可以用来计时。从1958-01-01 00:00:00开始作为公共时间原点,国际原子钟开始了计数,每计数9,192,631,770这么多个原子能级跃迁周期就+1s,这个钟走的非常准,每一秒都很均匀。使用这定义的时间称为国际原子时(International Atomic Time, TAI),下文简称TAI。
冲突
在最开始,这两种秒是等价的:一天是86400天文秒,也等于86400物理秒,毕竟物理学这个定义就是特意去凑天文学的定义嘛。所以相应的,GMT也与国际原子时TAI也保持着同步。然而正如前面所说,天文学现象影响因素太多了,并不是真正的“天行有常”。随着地球自转公转速度变化,天文定义的秒要比物理定义的秒稍微长了那么一点点,这也就意味着GMT要比TAI稍微落后一点点。
那么哪种定义说了算,世界时还是原子时?如果理论与生活实践经验相违背,绝大多数人都不会选择反直觉的方案:假设一种极端场景,两个钟之间的差异日积月累,到最后出现了几分钟甚至几小时的差值:明明日当午,按GMT应当是12:00:00,但GMT走慢了,TAI显示的时间已经是晚上六点了,这就违背了直觉。在表示时刻这一点上,还是由天文定义说了算,即以GMT为准。
当然,就算是天文定义说了算,也要尊重物理规律,毕竟原子钟走的这么准不是?实际上世界时与原子时之间的差值也就在几秒的量级。那么我们会自然而然地想到,使用国际原子时TAI作为基准,但加上一些闰秒(leap second)修正到GMT不就行了?既有高精度,又符合常识。于是就有了新的协调世界时(Coordinated Universal Time, UTC)。
协调世界时(UTC)
UTC是调和GMT与TAI的产物:
-
UTC使用精确的国际原子时TAI作为计时基础
-
UTC使用国际时GMT作为修正目标
-
UTC使用闰秒作为修正手段,
我们通常所说的时间,通常就是指世界协调时间UTC,它与世界时GMT的差值在0.9秒内,在要求不严格的实践中,可以近似认为UTC时间与GMT时间是相同的,很多人也把它与GMT混为一谈。
但问题紧接着就来了,按照传统,一天24小时,一小时60分钟,一分钟60秒,日和秒之间有86400的换算关系。以前用日来定义秒,现在秒成了基本单位,就要用秒去定义日。但现在一天不等于86400秒了。无论用哪头定义哪头,都会顾此失彼。唯一的办法,就是打破这种传统:一分钟不一定只有60秒了,它在需要的时候可以有61秒! 这就是闰秒机制,UTC以TAI为基准,因此走的也比GMT快。假设UTC和GMT的差异不断变大,在即将超过一秒时,让UTC中的某一分钟变为61秒,续的这一秒就像UTC在等GMT一样,然后误差就追回来了。每次续一秒时,UTC时间都会落后TAI多一秒,截止至今,UTC已经落后TAI三十多秒了。最近的一次闰秒调整是在2016年跨年:
国际标准时间UTC将在格林尼治时间2016年12月31日23时59分59秒(北京时间2017年1月1日7时59分59秒)之后,在原子时钟实施一个正闰秒,即增加1秒,然后才会跨入新的一年。
所以说,GMT和UTC还是有区别的,UTC里你能看到2016-12-31 23:59:60的时间,但GMT里就不会。
0x02 本地时间与时区
刚才讨论的时间都默认了一个前提:位于本初子午线(0度经线)上的时间。我们还需要考虑地球上的其他地方:毕竟美帝艳阳高照时,中国还在午夜呢。
本地时间,顾名思义就是以当地的太阳来计算的时间:正午就是12:00。太阳东升西落,东经120度上的本地时间比起本初子午线上就早了120° / (360°/24) = 8个小时。这意味着在北京当地时间12点整时,UTC时间其实是12-8=4,早晨4:00。
大家统一用UTC时间好不好呢?可以当然可以,毕竟中国横跨三个时区,也只用了一个北京时间。只要大家习惯就行。但大家都已经习惯了本地正午算12点了,强迫全世界人民用统一的时间其实违背了历史习惯。时区的设置使得长途旅行者能够简单地知道当地人的作息时间:反正差不多都是朝九晚五上班。这就降低了沟通成本。于是就有了时区的概念。当然像新疆这种硬要用北京时间的结果就是,游客乍一看当地人11点12点才上班可能会有些懵。
但在大一统的国家内部,使用统一的时间也有助于降低沟通成本。假如一个新疆人和一个黑龙江人打电话,一个用的乌鲁木齐时间,一个用的北京时间,那就会鸡同鸭讲。都约着12点,结果实际差了两个小时。时区的选用并不完全是按照地理经度而来的,也有很多的其他因素考量(例如行政区划)。 这就引出了时区的概念:时区是地球上使用同一个本地时间定义的区域。时区实际上可以视作从地理区域到时间偏移量的单射。 但其实有没有那个地理区域都不重要,关键在于时间偏移量的概念。UTC/GMT时间本身的偏移量为0,时区的偏移量都是相对于UTC时间而言的。这里,本地时间,UTC时间与时区的关系是:
本地时间 = UTC时间 + 本地时区偏移量。
比如UTC、GMT的时区都是+0,意味着没有偏移量。中国所处的东八区偏移量就是+8。意味着计算当地时间时,要在UTC时间的基础上增加8个小时。
夏令时(Daylight Saving Time, DST),可以视为一种特殊的时区偏移修正。指的是在夏天天亮的较早的时候把时间调快一个小时(实际上不一定是一个小时),从而节省能源(灯火)。我国在86年到92年之间曾短暂使用过夏令时。欧盟从1996年开始使用夏令时,不过欧盟最近的民调显示,84%的民众希望取消夏令时。对程序员而言,夏令时也是一个额外的麻烦事,希望它能尽快被扫入历史的垃圾桶。
0x03 时间的表示
那么,时间又如何表示呢?使用TAI的秒数来表示时间当然不会有歧义,但使用不便。习惯上我们将时间分为三个部分:日期,时间,时区,而每个部分都有多种表示方法。对于时间的表示,世界诸国人民各有各的习惯,例如,2006年1月2日,美国人就可能喜欢使用诸如January 2, 1999,1/2/1999这样的日期表示形式,而中国人也许会用诸如“2006年1月2日”,“2006/01/02”这样的表示形式。发送邮件时,首部中的时间则采用RFC2822中规定的Sat, 24 Nov 2035 11:45:15 −0500格式。此外,还有一系列的RFC与标准,用于指定日期与时间的表示格式。
ANSIC = "Mon Jan _2 15:04:05 2006"
UnixDate = "Mon Jan _2 15:04:05 MST 2006"
RubyDate = "Mon Jan 02 15:04:05 -0700 2006"
RFC822 = "02 Jan 06 15:04 MST"
RFC822Z = "02 Jan 06 15:04 -0700" // RFC822 with numeric zone
RFC850 = "Monday, 02-Jan-06 15:04:05 MST"
RFC1123 = "Mon, 02 Jan 2006 15:04:05 MST"
RFC1123Z = "Mon, 02 Jan 2006 15:04:05 -0700" // RFC1123 with numeric zone
RFC3339 = "2006-01-02T15:04:05Z07:00"
RFC3339Nano = "2006-01-02T15:04:05.999999999Z07:00"
不过在这里,我们只关注计算机中的日期表示形式与存储方式。而计算机中,时间最经典的表示形式,就是Unix时间戳。
Unix时间戳
比起UTC/GMT,对于程序员来说,更为熟悉的可能是另一种时间:Unix时间戳。UNIX时间戳是从1970年1月1日(UTC/GMT的午夜,在1972年之前没有闰秒)开始所经过的秒数,注意这里的秒其实是GMT中的秒,也就是不计闰秒,毕竟一天等于86400秒已经写死到无数程序的逻辑里去了,想改是不可能改的。
使用GMT秒数的好处是,计算日期的时候根本不用考虑闰秒的问题。毕竟闰年已经很讨厌了,再来一个没有规律的闰秒,绝对会让程序员抓狂。当然这不代表就不需要考虑闰秒的问题了,诸如ntp等时间服务还是需要考虑闰秒的问题的,应用程序有可能会受到影响:比如遇到‘时光倒流’拿到两次59秒,或者获取到秒数为60的时间值,一些实现简陋的程序可能就直接崩了。当然,也有一种将闰秒均摊到某一天全天的顺滑手段。
Unix时间戳背后的思想很简单,建立一条时间轴,以某一个纪元点(Epoch)作为原点,将时间表示为距离原点的秒数。Unix时间戳的纪元为GMT时间的1970-01-01 00:00:00,32位系统上的时间戳实际上是一个有符号四字节整型,以秒为单位。这意味它能表示的时间范围为:2^32 / 86400 / 365 = 68年,差不多从1901年到2038年。
当然,时间戳并不是只有这一种表示方法,但通常这是最为传统稳妥可靠的做法。毕竟不是所有的程序员都能处理好许多和时区、闰秒相关的微妙错误。使用Unix时间戳的好处就是时区已经固定死了是GMT了,存储空间与某些计算处理(比如排序)也相对容易。
在*nix命令行中使用date +%s可以获取Unix时间戳。而date -r @1500000000则可以反向将Unix时间戳转换为其他时间格式,例如转换为2017-07-14 10:40:00可以使用:
date -d @1500000000 '+%Y-%m-%d %H:%M:%S' # Linux
date -r 1500000000 '+%Y-%m-%d %H:%M:%S' # MacOS, BSD
在很久以前,当主板上的电池没电之后,系统的时钟就会自动重置成0;还有很多软件的Bug也会导致导致时间戳为0,也就是1970-01-01;以至于这个纪元时间很多非程序员都知道了。
数据库中的时间存储
通常情况下,Unix时间戳是传递/存储时间的最佳方式,它通常在计算机内部以整型的形式存在,内容为距离某个特定纪元的秒数。它极为简单,无歧义,存储占用更紧实,便于比较大小,且在程序员之间存在广泛共识。不过,Epoch+整数偏移量的方式适合在机器上进行存储与交换,但它并不是一种人类可读的格式(也许有些程序员可读)。
PostgreSQL提供了丰富的日期时间数据类型与相关函数,它能以高度灵活的方式自动适配各种格式的时间输入输出,并在内部以高效的整型表示进行存储与计算。在PostgreSQL中,变量CURRENT_TIMESTAMP或函数now()会返回当前事务开始时的本地时间戳,返回的类型是TIMESTAMP WITH TIME ZONE,这是一个PostgreSQL扩展,会在时间戳上带有额外的时区信息。SQL标准所规定的类型为TIMESTAMP,在PostgreSQL中使用8字节的长整型实现。可以使用SQL语法AT TIME ZONE zone或内置函数timezone(zone,ts)将带有时区的TIMESTAMP转换为不带时区的标准版本。
通常(我认为的)最佳实践是,只要应用稍具规模或涉及到任何国际化的功能,存储时间就应当使用TIMESTAMP类型并存储GMT时间,当然,PostgreSQL Wiki中推荐的方式是使用PostgreSQL自己的TimestampTZ扩展类型,带时区的时间戳是12字节,而不带时区的则为8字节,在固定使用GMT时区的情况下,个人还是更倾向于使用不带时区的TIMESTAMP类型。
-- 获取本地事务开始时的时间戳
vonng=# SELECT now(), CURRENT_TIMESTAMP;
now | current_timestamp
-------------------------------+-------------------------------
2018-12-11 21:50:15.317141+08 | 2018-12-11 21:50:15.317141+08
-- now()/CURRENT_TIMESTAMP返回的是带有时区信息的时间戳
vonng=# SELECT pg_typeof(now()),pg_typeof(CURRENT_TIMESTAMP);
pg_typeof | pg_typeof
--------------------------+--------------------------
timestamp with time zone | timestamp with time zone
-- 将本地时区+8时间转换为UTC时间,转化得到的是TIMESTAMP
-- 注意不要使用从TIMESTAMPTZ到TIMESTAMP的强制类型转换,会直接截断时区信息。
vonng=# SELECT now() AT TIME ZONE 'UTC';
timezone
----------------------------
2018-12-11 13:50:25.790108
-- 再将UTC时间转换为太平洋时间
vonng=# SELECT (now() AT TIME ZONE 'UTC') AT TIME ZONE 'PST';
timezone
-------------------------------
2018-12-12 05:50:37.770066+08
-- 查看PG自带的时区数据表
vonng=# TABLE pg_timezone_names LIMIT 4;
name | abbrev | utc_offset | is_dst
------------------+--------+------------+--------
Indian/Mauritius | +04 | 04:00:00 | f
Indian/Chagos | +06 | 06:00:00 | f
Indian/Mayotte | EAT | 03:00:00 | f
Indian/Christmas | +07 | 07:00:00 | f
...
-- 查看PG自带的时区缩写
vonng=# TABLE pg_timezone_abbrevs LIMIT 4;
abbrev | utc_offset | is_dst
--------+------------+--------
ACDT | 10:30:00 | t
ACSST | 10:30:00 | t
ACST | 09:30:00 | f
ACT | -05:00:00 | f
...
一个经常让人困惑的问题就是TIMESTAMP与TIMESTAMPTZ之间的相互转化问题。
-- 使用::TIMESTAMP将TIMESTAMPTZ强制转换为TIMESTAMP,直接截断时区部分内容
-- 时间的其余"内容"保持不变
vonng=# SELECT now(), now()::TIMESTAMP;
now | now
-------------------------------+--------------------------
2018-12-12 05:50:37.770066+08 | 2018-12-12 05:50:37.770066+08
-- 对有时区版TIMESTAMPTZ使用AT TIME ZONE语法
-- 会将其转换为无时区版的TIMESTAMP,返回给定时区下的时间
vonng=# SELECT now(), now() AT TIME ZONE 'UTC';
now | timezone
-------------------------------+----------------------------
2019-05-23 16:58:47.071135+08 | 2019-05-23 08:58:47.071135
-- 对无时区版TIMESTAMP使用AT TIME ZONE语法
-- 会将其转换为带时区版的TIMESTAMPTZ,即在给定时区下解释该无时区时间戳。
vonng=# SELECT now()::TIMESTAMP, now()::TIMESTAMP AT TIME ZONE 'UTC';
now | timezone
----------------------------+-------------------------------
2019-05-23 17:03:00.872533 | 2019-05-24 01:03:00.872533+08
-- 这里的意思是,UTC时间的 2019-05-23 17:03:00
PostgreSQL开发规约
0x00背景
没有规矩,不成方圆。
PostgreSQL的功能非常强大,但是要把PostgreSQL用好,需要后端、运维、DBA的协力配合。
本文针对PostgreSQL数据库原理与特性,整理了一份开发规范,希望可以减少大家在使用PostgreSQL数据库过程中遇到的困惑。 你好我也好,大家都好。
0x01 命名规范
无名,万物之始,有名,万物之母。
【强制】 通用命名规则
- 本规则适用于所有对象名,包括:库名、表名、表名、列名、函数名、视图名、序列号名、别名等。
- 对象名务必只使用小写字母,下划线,数字,但首字母必须为小写字母,常规表禁止以
_打头。 - 对象名长度不超过63个字符,命名统一采用
snake_case。 - 禁止使用SQL保留字,使用
select pg_get_keywords();获取保留关键字列表。 - 禁止出现美元符号,禁止使用中文,不要以
pg开头。 - 提高用词品味,做到信达雅;不要使用拼音,不要使用生僻冷词,不要使用小众缩写。
【强制】 库命名规则
- 库名最好与应用或服务保持一致,必须为具有高区分度的英文单词。
- 命名必须以
<biz>-开头,<biz>为具体业务线名称,如果是分片库必须以-shard结尾。 - 多个部分使用
-连接。例如:<biz>-chat-shard,<biz>-payment等,总共不超过三段。
【强制】 角色命名规范
- 数据库
su有且仅有一个:postgres,用于流复制的用户命名为replication。 - 生产用户命名使用
<biz>-作为前缀,具体功能作为后缀。 - 所有数据库默认有三个基础角色:
<biz>-read,<biz>-write,<biz>-usage,分别拥有所有表的只读,只写,函数的执行权限。 - 生产用户,ETL用户,个人用户通过继承相应的基础角色获取权限。
- 更为精细的权限控制使用独立的角色与用户,依业务而异。
【强制】 模式命名规则
- 业务统一使用
<*>作为模式名,<*>为业务定义的名称,必须设置为search_path首位元素。 dba,monitor,trash为保留模式名。- 分片模式命名规则采用:
rel_<partition_total_num>_<partition_index>。 - 无特殊理由不应在其他模式中创建对象。
【推荐】 关系命名规则
- 关系命名以表意清晰为第一要义,不要使用含混的缩写,也不应过分冗长,遵循通用命名规则。
- 表名应当使用复数名词,与历史惯例保持一致,但应尽量避免带有不规则复数形式的单词。
- 视图以
v_作为命名前缀,物化视图使用mv_作为命名前缀,临时表以tmp_作为命名前缀。 - 继承或分区表应当以父表表名作为前缀,并以子表特性(规则,分片范围等)作为后缀。
【推荐】 索引命名规则
- 创建索引时如有条件应当指定索引名称,并与PostgreSQL默认命名规则保持一致,避免重复执行时建立重复索引。
- 用于主键的索引以
_pkey结尾,唯一索引以_key结尾,用于EXCLUDED约束的索引以_excl结尾,普通索引以_idx结尾。
【推荐】 函数命名规则
- 以
select,insert,delete,update,upsert打头,表示动作类型。 - 重要参数可以通过
_by_ids,_by_user_ids的后缀在函数名中体现。 - 避免函数重载,同名函数尽量只保留一个。
- 禁止通过
BIGINT/INTEGER/SMALLINT等整型进行重载,调用时可能产生歧义。
【推荐】 字段命名规则
- 不得使用系统列保留字段名:
oid,xmin,xmax,cmin,cmax,ctid等。 - 主键列通常命名为
id,或以id作为后缀。 - 创建时间通常命名为
created_time,修改时间通常命名为updated_time - 布尔型字段建议使用
is_,has_等作为前缀。 - 其余各字段名需与已有表命名惯例保持一致。
【推荐】 变量命名规则
- 存储过程与函数中的变量使用命名参数,而非位置参数。
- 如果参数名与对象名出现冲突,在参数后添加
_,例如user_id_。
【推荐】 注释规范
- 尽量为对象提供注释(
COMMENT),注释使用英文,言简意赅,一行为宜。 - 对象的模式或内容语义发生变更时,务必一并更新注释,与实际情况保持同步。
0x02 设计规范
Suum cuique
【强制】 字符编码必须为UTF8
- 禁止使用其他任何字符编码。
【强制】 容量规划
- 单表记录过亿,或超过10GB的量级,可以考虑开始进行分表。
- 单表容量超过1T,单库容量超过2T。需要考虑分片。
【强制】 不要滥用存储过程
- 存储过程适用于封装事务,减少并发冲突,减少网络往返,减少返回数据量,执行少量自定义逻辑。
- 存储过程不适合进行复杂计算,不适合进行平凡/频繁的类型转换与包装。
【强制】 存储计算分离
- 移除数据库中不必要的计算密集型逻辑,例如在数据库中使用SQL进行WGS84到其他坐标系的换算。
- 例外:与数据获取、筛选密切关联的计算逻辑允许在数据库中进行,如PostGIS中的几何关系判断。
【强制】 主键与身份列
- 每个表都必须有身份列,原则上必须有主键,最低要求为拥有非空唯一约束。
- 身份列用于唯一标识表中的任一元组,逻辑复制与诸多三方工具有赖于此。
【强制】 外键
- 不建议使用外键,建议在应用层解决。使用外键时,引用必须设置相应的动作:
SET NULL,SET DEFAULT,CASCADE,慎用级联操作。
【强制】 慎用宽表
- 字段数目超过15个的表视作宽表,宽表应当考虑进行纵向拆分,通过相同的主键与主表相互引用。
- 因为MVCC机制,宽表的写放大现象比较明显,尽量减少对宽表的频繁更新。
【强制】 配置合适的默认值
- 有默认值的列必须添加
DEFAULT子句指定默认值。 - 可以在默认值中使用函数,动态生成默认值(例如主键发号器)。
【强制】 合理应对空值
- 字段语义上没有零值与空值区分的,不允许空值存在,须为列配置
NOT NULL约束。
【强制】 唯一约束通过数据库强制。
- 唯一约束须由数据库保证,任何唯一列须有唯一约束。
EXCLUDE约束是泛化的唯一约束,可以在低频更新场景下用于保证数据完整性。
【强制】 注意整数溢出风险
- 注意SQL标准不提供无符号整型,超过
INTMAX但没超过UINTMAX的值需要升格存储。 - 不要存储超过
INT64MAX的值到BIGINT列中,会溢出为负数。
【强制】 统一时区
- 使用
TIMESTAMP存储时间,采用utc时区。 - 统一使用ISO-8601格式输入输出时间类型:
2006-01-02 15:04:05,避免DMY与MDY问题。 - 使用
TIMESTAMPTZ时,采用GMT/UTC时间,0时区标准时。
【强制】 及时清理过时函数
- 不再使用的,被替换的函数应当及时下线,避免与未来的函数发生冲突。
【推荐】 主键类型
- 主键通常使用整型,建议使用
BIGINT,允许使用不超过64字节的字符串。 - 主键允许使用
Serial自动生成,建议使用Default next_id()发号器函数。
【推荐】 选择合适的类型
- 能使用专有类型的,不使用字符串。(数值,枚举,网络地址,货币,JSON,UUID等)
- 使用正确的数据类型,能显著提高数据存储,查询,索引,计算的效率,并提高可维护性。
【推荐】 使用枚举类型
- 较稳定的,取值空间较小(十几个内)的字段应当使用枚举类型,不要使用整型与字符串表示。
- 使用枚举类型有性能、存储、可维护性上的优势。
【推荐】 选择合适的文本类型
- PostgreSQL的文本类型包括
char(n),varchar(n),text。 - 通常建议使用
varchar或text,带有(n)修饰符的类型会检查字符串长度,会导致微小的额外开销,对字符串长度有限制时应当使用varchar(n),避免插入过长的脏数据。 - 避免使用
char(n),为了与SQL标准兼容,该类型存在不合直觉的行为表现(补齐空格与截断),且并没有存储和性能优势。
【推荐】 选择合适的数值类型
- 常规数值字段使用
INTEGER。主键、容量拿不准的数值列使用BIGINT。 - 无特殊理由不要用
SMALLINT,性能与存储提升很小,会有很多额外的问题。 REAL表示4字节浮点数,FLOAT表示8字节浮点数- 浮点数仅可用于末尾精度无所谓的场景,例如地理坐标,不要对浮点数使用等值判断。
- 精确数值类型使用
NUMERIC,注意精度和小数位数设置。 - 货币数值类型使用
MONEY。
【推荐】 使用统一的函数创建语法
- 签名单独占用一行(函数名与参数),返回值单启一行,语言为第一个标签。
- 一定要标注函数易变性等级:
IMMUTABLE,STABLE,VOLATILE。 - 添加确定的属性标签,如:
RETURNS NULL ON NULL INPUT,PARALLEL SAFE,ROWS 1,注意版本兼容性。
CREATE OR REPLACE FUNCTION
nspname.myfunc(arg1_ TEXT, arg2_ INTEGER)
RETURNS VOID
LANGUAGE SQL
STABLE
PARALLEL SAFE
ROWS 1
RETURNS NULL ON NULL INPUT
AS $function$
SELECT 1;
$function$;
【推荐】 针对可演化性而设计
- 在设计表时,应当充分考虑未来的扩展需求,可以在建表时适当添加1~3个保留字段。
- 对于多变的非关键字段可以使用JSON类型。
【推荐】 选择合理的规范化等级
- 允许适当降低规范化等级,减少多表连接以提高性能。
【推荐】 使用新版本
- 新版本有无成本的性能提升,稳定性提升,有更多新功能。
- 充分利用新特性,降低设计复杂度。
【推荐】 慎用触发器
- 触发器会提高系统的复杂度与维护成本,不鼓励使用。
0x03 索引规范
Wer Ordnung hält, ist nur zu faul zum Suchen.
【强制】 在线查询必须有配套索引
- 所有在线查询必须针对其访问模式设计相应索引,除极个别小表外不允许全表扫描。
- 索引有代价,不允许创建不使用的索引。
【强制】 禁止在大字段上建立索引
- 被索引字段大小无法超过2KB(1/3的页容量),原则上禁止超过64个字符。
- 如有大字段索引需求,可以考虑对大字段取哈希,并建立函数索引。或使用其他类型的索引(GIN)。
【强制】 明确空值排序规则
- 如在可空列上有排序需求,需要在查询与索引中明确指定
NULLS FIRST还是NULLS LAST。 - 注意,
DESC排序的默认规则是NULLS FIRST,即空值会出现在排序的最前面,通常这不是期望行为。 - 索引的排序条件必须与查询匹配,如:
create index on tbl (id desc nulls last);
【强制】 利用GiST索引应对近邻查询问题
- 传统B树索引无法提供对KNN问题的良好支持,应当使用GiST索引。
【推荐】 利用函数索引
- 任何可以由同一行其他字段推断得出的冗余字段,可以使用函数索引替代。
- 对于经常使用表达式作为查询条件的语句,可以使用表达式或函数索引加速查询。
- 典型场景:建立大字段上的哈希函数索引,为需要左模糊查询的文本列建立reverse函数索引。
【推荐】 利用部分索引
- 查询中查询条件固定的部分,可以使用部分索引,减小索引大小并提升查询效率。
- 查询中某待索引字段若只有有限几种取值,也可以建立几个相应的部分索引。
【推荐】 利用范围索引
- 对于值与堆表的存储顺序线性相关的数据,如果通常的查询为范围查询,建议使用BRIN索引。
- 最典型场景如仅追加写入的时序数据,BRIN索引更为高效。
【推荐】 关注联合索引的区分度
- 区分度高的列放在前面
0x04 查询规范
The limits of my language mean the limits of my world.
—Ludwig Wittgenstein
【强制】 读写分离
- 原则上写请求走主库,读请求走从库。
- 例外:需要读己之写的一致性保证,且检测到显著的复制延迟。
【强制】 快慢分离
- 生产中1毫秒以内的查询称为快查询,生产中超过1秒的查询称为慢查询。
- 慢查询必须走离线从库,必须设置相应的超时。
- 生产中的在线普通查询执行时长,原则上应当控制在1ms内。
- 生产中的在线普通查询执行时长,超过10ms需修改技术方案,优化达标后再上线。
- 在线查询应当配置10ms数量级或更快的超时,避免堆积造成雪崩。
- Master与Slave角色不允许大批量拉取数据,数仓ETL程序应当从Offline从库拉取数据
【强制】 主动超时
- 为所有的语句配置主动超时,超时后主动取消请求,避免雪崩。
- 周期性执行的语句,必须配置小于执行周期的超时。
【强制】 关注复制延迟
- 应用必须意识到主从之间的同步延迟,并妥善处理好复制延迟超出合理范围的情况
- 平时在0.1ms的延迟,在极端情况下可能达到十几分钟甚至小时量级。应用可以选择从主库读取,稍后再度,或报错。
【强制】 使用连接池
- 应用必须通过连接池访问数据库,连接6432端口的pgbouncer而不是5432的postgres。
- 注意使用连接池与直连数据库的区别,一些功能可能无法使用(比如Notify/Listen),也可能存在连接污染的问题。
【强制】 禁止修改连接状态
- 使用公共连接池时禁止修改连接状态,包括修改连接参数,修改搜索路径,更换角色,更换数据库。
- 万不得已修改后必须彻底销毁连接,将状态变更后的连接放回连接池会导致污染扩散。
【强制】 重试失败的事务
- 查询可能因为并发争用,管理员命令等原因被杀死,应用需要意识到这一点并在必要时重试。
- 应用在数据库大量报错时可以触发断路器熔断,避免雪崩。但要注意区分错误的类型与性质。
【强制】 掉线重连
- 连接可能因为各种原因被中止,应用必须有掉线重连机制。
- 可以使用
SELECT 1作为心跳包查询,检测连接的有消息,并定期保活。
【强制】 在线服务应用代码禁止执行DDL
- 不要在应用代码里搞大新闻。
【强制】 显式指定列名
- 避免使用
SELECT *,或在RETURNING子句中使用*。请使用具体的字段列表,不要返回用不到的字段。当表结构发生变动时(例如,新值列),使用列通配符的查询很可能会发生列数不匹配的错误。 - 例外:当存储过程返回具体的表行类型时,允许使用通配符。
【强制】 禁止在线查询全表扫描
- 例外情况:常量极小表,极低频操作,表/返回结果集很小(百条记录/百KB内)。
- 在首层过滤条件上使用诸如
!=,<>的否定式操作符会导致全表扫描,必须避免。
【强制】 禁止在事务中长时间等待
- 开启事务后必须尽快提交或回滚,超过10分钟的
IDEL IN Transaction将被强制杀死。 - 应用应当开启AutoCommit,避免
BEGIN之后没有配对的ROLLBACK或COMMIT。 - 尽量使用标准库提供的事务基础设施,不到万不得已不要手动控制事务。
【强制】 使用游标后必须及时关闭
【强制】 科学计数
count(*)是统计行数的标准语法,与空值无关。count(col)统计的是col列中的非空记录数。该列中的NULL值不会被计入。count(distinct col)对col列除重计数,同样忽视空值,即只统计非空不同值的个数。count((col1, col2))对多列计数,即使待计数的列全为空也会被计数,(NULL,NULL)有效。a(distinct (col1, col2))对多列除重计数,即使待计数列全为空也会被计数,(NULL,NULL)有效。
【强制】 注意聚合函数的空值问题
- 除了
count之外的所有聚合函数都会忽略空值输入,因此当输入值全部为空时,结果是NULL。但count(col)在这种情况下会返回0,是一个例外。 - 如果聚集函数返回空并不是期望的结果,使用
coalesce来设置缺省值。
【强制】谨慎处理空值
- 明确区分零值与空值,空值使用
IS NULL进行等值判断,零值使用常规的=运算符进行等值判断。 - 空值作为函数输入参数时应当带有类型修饰符,否则对于有重载的函数将无法识别使用何者。
- 注意空值比较逻辑:任何涉及到空值比较运算结果都是
unknown,需要注意unknown参与布尔运算的逻辑:and:TRUE or UNKNOWN会因为逻辑短路返回TRUE。or:FALSE and UNKNOWN会因为逻辑短路返回FALSE- 其他情况只要运算对象出现
UNKNOWN,结果都是UNKNOWN
- 空值与任何值的逻辑判断,其结果都为空值,例如
NULL=NULL返回结果是NULL而不是TRUE/FALSE。 - 涉及空值与非空值的等值比较,请使用``IS DISTINCT FROM
- 空值与聚合函数:聚合函数当输入值全部为NULL时,返回结果为NULL。
【强制】 注意序列号空缺
- 当使用
Serial类型时,INSERT,UPSERT等操作都会消耗序列号,该消耗不会随事务失败而回滚。 - 当使用整型作为主键,且表存在频繁插入冲突时,需要关注整型溢出的问题。
【推荐】 重复查询使用准备语句
- 重复的查询应当使用准备语句(Prepared Statement),消除数据库硬解析的CPU开销。
- 准备语句会修改连接状态,请注意连接池对于准备语句的影响。
【推荐】 选择合适的事务隔离等级
- 默认隔离等级为读已提交,适合大多数简单读写事务,普通事务选择满足需求的最低隔离等级。
- 需要事务级一致性快照的写事务,请使用可重复读隔离等级。
- 对正确性有严格要求的写入事务请使用可序列化隔离等级。
- 在RR与SR隔离等级出现并发冲突时,应当视错误类型进行积极的重试。
【推荐】 判断结果存在性不要使用count
- 使用
SELECT 1 FROM tbl WHERE xxx LIMIT 1判断是否存满足条件的列,要比Count快。 - 可以使用
select exists(select * FROM app.sjqq where xxx limit 1)将存在性结果转换为布尔值。
【推荐】 使用RETURNING子句
- 如果用户需要在插入数据和,删除数据前,或者修改数据后马上拿到插入或被删除或修改后的数据,建议使用
RETURNING子句,减少数据库交互次数。
【推荐】 使用UPSERT简化逻辑
- 当业务出现插入-失败-更新的操作序列时,考虑使用
UPSERT替代。
【推荐】 利用咨询锁应对热点并发。
- 针对单行记录的极高频并发写入(秒杀),应当使用咨询锁对记录ID进行锁定。
- 如果能在应用层次解决高并发争用,就不要放在数据库层面进行。
【推荐】优化IN操作符
- 使用
EXISTS子句代替IN操作符,效果更佳。 - 使用
=ANY(ARRAY[1,2,3,4])代替IN (1,2,3,4),效果更佳。
【推荐】 不建议使用左模糊搜索
- 左模糊搜索
WHERE col LIKE '%xxx'无法充分利用B树索引,如有需要,可用reverse表达式函数索引。
【推荐】 使用数组代替临时表
- 考虑使用数组替代临时表,例如在获取一系列ID的对应记录时。
=ANY(ARRAY[1,2,3])要比临时表JOIN好。
0x05 发布规范
【强制】 发布形式
- 目前以邮件形式提交发布,发送邮件至dba@p1.com 归档并安排提交。
- 标题清晰:xx项目需在xx库执行xx动作。
- 目标明确:每个步骤需要在哪些实例上执行哪些操作,结果如何校验。
- 回滚方案:任何变更都需要提供回滚方案,新建也需要提供清理脚本。
【强制】发布评估
- 线上数据库发布需要经过研发自测,主管审核,(可选QA审核),DBA审核几个评估阶段。
- 自测阶段应当确保变更在开发、预发环境执行正确无误。
- 如果是新建表,应当给出记录数量级,数据日增量预估值,读写量级预估。
- 如果是新建函数,应当给出压测报告,至少需要给出平均执行时间。
- 如果是模式迁移,必须梳理清楚所有上下游依赖。
- Team Leader需要对变更进行评估与审核,对变更内容负责。
- DBA对发布的形式与影响进行评估与审核。
【强制】 发布窗口
- 19:00 后不允许数据库发布,紧急发布请TL做特殊说明,抄送CTO。
- 16:00点后确认的需求将顺延至第二天执行。(以TL确认时间为准)
0x06 管理规范
【强制】 关注备份
- 每日全量备份,段文件持续归档
【强制】 关注年龄
- 关注数据库与表的年龄,避免事物ID回卷。
【强制】 关注老化与膨胀
- 关注表与索引的膨胀率,避免性能劣化。
【强制】 关注复制延迟
- 监控复制延迟,使用复制槽时更必须十分留意。
【强制】 遵循最小权限原则
【强制】并发地创建与删除索引
- 对于生产表,必须使用
CREATE INDEX CONCURRENTLY并发创建索引。
【强制】 新从库数据预热
- 使用
pg_prewarm,或逐渐接入流量。
【强制】 审慎地进行模式变更
- 添加新列时必须使用不带默认值的语法,避免全表重写
- 变更类型时,必要时应当重建所有依赖该类型的函数。
【推荐】 切分大批量操作
- 大批量写入操作应当切分为小批量进行,避免一次产生大量WAL。
【推荐】 加速数据加载
- 关闭
autovacuum,使用COPY加载数据。 - 事后建立约束与索引。
- 调大
maintenance_work_mem,增大max_wal_size。 - 完成后执行
vacuum verbose analyze table。
PG好处都有啥
PostgreSQL的Slogan是“世界上最先进的开源关系型数据库”,但我觉得这口号不够响亮,而且一看就是在怼MySQL那个“世界上最流行的开源关系型数据库”的口号,有碰瓷之嫌。要我说最能生动体现PG特色的口号应该是:一专多长的全栈数据库,一招鲜吃遍天嘛。

全栈数据库
成熟的应用可能会用到许许多多的数据组件(功能):缓存,OLTP,OLAP/批处理/数据仓库,流处理/消息队列,搜索索引,NoSQL/文档数据库,地理数据库,空间数据库,时序数据库,图数据库。传统的架构选型呢,可能会组合使用多种组件,典型的如:Redis + MySQL + Greenplum/Hadoop + Kafuka/Flink + ElasticSearch,一套组合拳基本能应付大多数需求了。不过比较令人头大的就是异构系统集成了:大量的代码都是重复繁琐的胶水代码,干着把数据从A组件搬运到B组件的事情。

在这里,MySQL就只能扮演OLTP关系型数据库的角色,但如果是PostgreSQL,就可以身兼多职,One handle them all,比如:
-
OLTP:事务处理是PostgreSQL的本行
-
OLAP:citus分布式插件,ANSI SQL兼容,窗口函数,CTE,CUBE等高级分析功能,任意语言写UDF
-
流处理:PipelineDB扩展,Notify-Listen,物化视图,规则系统,灵活的存储过程与函数编写
-
时序数据:timescaledb时序数据库插件,分区表,BRIN索引
-
空间数据:PostGIS扩展(杀手锏),内建的几何类型支持,GiST索引。
-
搜索索引:全文搜索索引足以应对简单场景;丰富的索引类型,支持函数索引,条件索引
-
NoSQL:JSON,JSONB,XML,HStore原生支持,至NoSQL数据库的外部数据包装器
-
数据仓库:能平滑迁移至同属Pg生态的GreenPlum,DeepGreen,HAWK等,使用FDW进行ETL
-
图数据:递归查询
-
缓存:物化视图
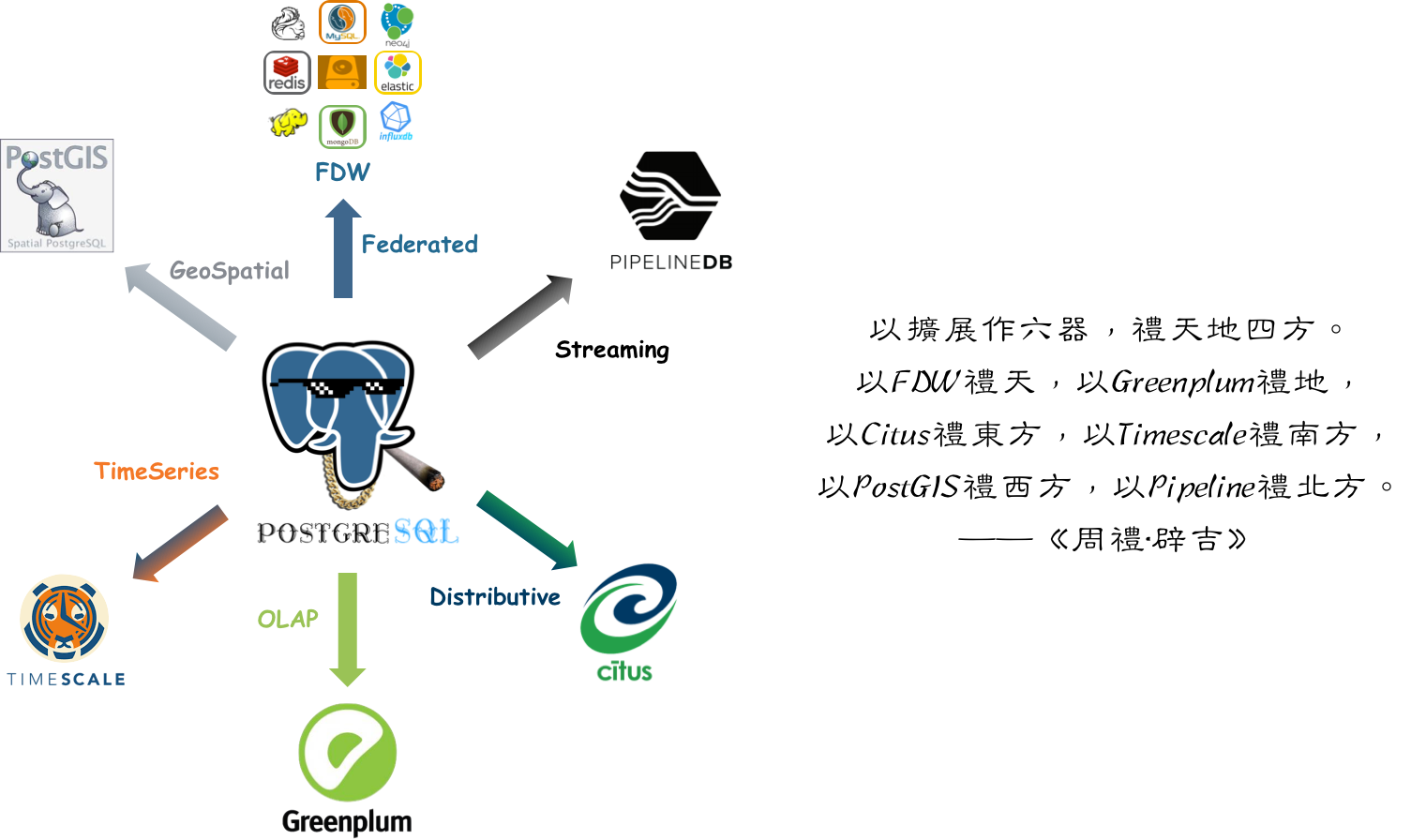
以Extension作六器,礼天地四方。
以Greenplum礼天,
以Postgres-XL礼地,
以Citus礼东方,
以TimescaleDB礼南方,
以PipelineDB礼西方,
以PostGIS礼北方。
—— 《周礼.PG》
在探探的旧版架构中,整个系统就是围绕PostgreSQL设计的。几百万日活,几百万全局DB-TPS,几百TB数据的规模下,数据组件只用了PostgreSQL。独立的数仓,消息队列和缓存都是后来才引入的。而且这只是验证过的规模量级,进一步压榨PG是完全可行的。
因此,在一个很可观的规模内,PostgreSQL都可以扮演多面手的角色,一个组件当多种组件使。虽然在某些领域它可能比不上专用组件,至少都做的都还不赖。而单一数据组件选型可以极大地削减项目额外复杂度,这意味着能节省很多成本。它让十个人才能搞定的事,变成一个人就能搞定的事。
为了不需要的规模而设计是白费功夫,实际上这属于过早优化的一种形式。只有当没有单个软件能满足你的所有需求时,才会存在分拆与集成的利弊权衡。集成多种异构技术是相当棘手的工作,如果真有那么一样技术可以满足你所有的需求,那么使用该技术就是最佳选择,而不是试图用多个组件来重新实现它。
当业务规模增长到一定量级时,可能不得不使用基于微服务/总线的架构,将数据库的功能分拆为多个组件。但PostgreSQL的存在极大地推后了这个权衡到来的阈值,而且分拆之后依然能继续发挥重要作用。
运维友好
当然除了功能强大之外,Pg的另外一个重要的优势就是运维友好。有很多非常实用的特性:
-
DDL能放入事务中,删表,TRUNCATE,创建函数,索引,都可以放在事务里原子生效,或者回滚。
这就能进行很多骚操作,比如在一个事务里通过RENAME,完成两张表的王车易位。
-
能够并发地创建、删除索引,添加非空字段,重整索引与表(不锁表)。
这意味着可以随时在线上不停机进行重大的模式变更,按需对索引进行优化。
-
复制方式多样:段复制,流复制,触发器复制,逻辑复制,插件复制等等。
这使得不停服务迁移数据变得相当容易:复制,改读,改写三步走,线上迁移稳如狗。
-
提交方式多样:异步提交,同步提交,法定人数同步提交。
这意味着Pg允许在C和A之间做出权衡与选择,例如交易库使用同步提交,普通库使用异步提交。
-
系统视图非常完备,做监控系统相当简单。
-
FDW的存在让ETL变得无比简单,一行SQL就能解决。
FDW可以方便地让一个实例访问其他实例的数据或元数据。在跨分区操作,数据库监控指标收集,数据迁移等场景中妙用无穷。同时还可以对接很多异构数据系统。
生态健康
PostgreSQL的生态也很健康,社区相当活跃。
相比MySQL,PostgreSQL的一个巨大的优势就是协议友好。PG采用类似BSD/MIT的PostgreSQL协议,差不多理解为只要别打着Pg的旗号出去招摇撞骗,随便你怎么搞,换皮出去卖都行。君不见多少国产数据库,或者不少“自研数据库”实际都是Pg的换皮或二次开发产品。
当然,也有很多衍生产品会回馈主干,比如timescaledb, pipelinedb, citus 这些基于PG的“数据库”,最后都变成了原生PG的插件。很多时候你想实现个什么功能,一搜就能找到对应的插件或实现。开源嘛,还是要讲一些情怀的。
Pg的代码质量相当之高,注释写的非常清晰。C的代码读起来有种Go的感觉,代码都可以当文档看了。能从中学到很多东西。相比之下,其他数据库,比如MongoDB,看一眼我就放弃了读下去的兴趣。
而MySQL呢,社区版采用的是GPL协议,这其实挺蛋疼的。要不是GPL传染,怎么会有这么多基于MySQL改的数据库开源出来呢?而且MySQL还在乌龟壳的手里,让自己的蛋蛋攥在别人手中可不是什么明智的选择,更何况是业界毒瘤呢?Facebook修改React协议的风波就算是一个前车之鉴了。
问题
当然,要说有什么缺点或者遗憾,那还是有几个的:
- 因为使用了MVCC,数据库需要定期VACUUM,需要定期维护表和索引避免性能下降。
- 没有很好的开源集群监控方案(或者太丑!),需要自己做。
- 慢查询日志和普通日志是混在一起的,需要自己解析处理。
- 官方Pg没有很好用的列存储,对数据分析而言算一个小遗憾。
当然都是些无关痛痒的小毛小病,不过真正的问题可能和技术无关……
说到底,MySQL确实是最流行的开源关系型数据库,没办法,写Java的,写PHP的,很多人最开始用的都是MySQL…,所以Pg招人相对困难是一个事实,很多时候只能自己培养。不过看DB Engines上的流行度趋势,未来还是很光明的。
其他
学PostgreSQL是一件很有趣的事,它让我意识到数据库的功能远远不止增删改查。我学着SQL Server与MySQL迈进数据库的大门。但却是PostgreSQL真正向我展示了数据库的奇妙世界。
之所以写本文,是因为在知乎上的老坟又被挖了出来,让笔者回想起当年邂逅PostgreSQL时的青葱岁月。(https://www.zhihu.com/question/20010554/answer/94999834 )当然,现在我干了专职的PG DBA,忍不住再给这老坟补几铲。“王婆卖瓜,自卖自夸”,夸一夸PG也是应该的。嘿嘿嘿……
全栈工程师就该用全栈数据库嘛。
我自己比较选型过MySQL和PostgreSQL,难得地在阿里这种MySQL的世界中有过选择的自由。我认为单从技术因素上来讲,PG是完爆MySQL的。尽管阻力很大,最后还是把PostgreSQL用了起来,推了起来。我用它做过很多项目,解决了很多需求(小到算统计报表,大到给公司创收个小目标)。大多数需求PG单挑就搞定了,少部分也会再用些MQ和NoSQL(Redis,MongoDB,Cassandra/HBase)。Pg实在是让人爱不释手。
最后实在是对Pg爱不释手,以至于专职去研究PG了。
在我的第一份工作中就深刻尝到了甜头,使用PostgreSQL,一个人的开发效率能顶一个小团队:
-
后端懒得写怎么办,PostGraphQL直接从数据库模式定义生成GraphQL API,自动监听DDL变更,生成相应的CRUD方法与存储过程包装,对于后台开发再方便不过,类似的工具还有PostgREST与pgrest。对于中小数据量的应用都还堪用,省了一大半后端开发的活。
-
需要用到Redis的功能,直接上Pg,模拟普通功能不在话下,缓存也省了。Pub/Sub使用Notify/Listen/Trigger实现,用来广播配置变更,做一些控制非常方便。
-
需要做分析,窗口函数,复杂JOIN,CUBE,GROUPING,自定义聚合,自定义语言,爽到飞起。如果觉得规模大了想scale out可以上citus扩展(或者换greenplum);比起数仓可能少个列存比较遗憾,但其他该有的都有了。
-
用到地理相关的功能,PostGIS堪称神器,千行代码才能实现的复杂地理需求,一行SQL轻松高效解决。
-
存储时序数据,timescaledb扩展虽然比不上专用时序数据库,但百万记录每秒的入库速率还是有的。用它解决过硬件传感器日志存储,监控系统Metrics存储的需求。
-
一些流计算的相关功能,可以用PipelineDB直接定义流式视图实现:UV,PV,用户画像实时呈现。
-
PostgreSQL的FDW是一种强大的机制,允许接入各种各样的数据源,以统一的SQL接口访问。它妙用无穷:
-
file_fdw这种自带的扩展,可以将任意程序的输出接入数据表。最简单的应用就是监控系统信息。- 管理多个PostgreSQL实例时,可以在一个元数据库中用自带的
postgres_fdw导入所有远程数据库的数据字典。统一访问所有数据库实例的元数据,一行SQL拉取所有数据库的实时指标,监控系统做起来不要太爽。 - 之前做过的一件事就是用hbase_fdw和MongoFDW,将HBase中的历史批量数据,MongoDB中的当日实时数据包装为PostgreSQL数据表,一个视图就简简单单地实现了融合批处理与流处理的Lambda架构。
- 使用
redis_fdw进行缓存更新推送;使用mongo_fdw完成从mongo到pg的数据迁移;使用mysql_fdw读取MySQL数据并存入数仓;实现跨数据库,甚至跨数据组件的JOIN;使用一行SQL就能完成原本多少行代码才能实现的复杂ETL,这是一件多么美妙的事情。
-
各种丰富的类型与方法支持:例如JSON,从数据库直接生成前端所需的JSON响应,轻松而惬意。范围类型,优雅地解决很多原本需要程序处理的边角情况。其他的例如数组,多维数组,自定义类型,枚举,网络地址,UUID,ISBN。很多开箱即用的数据结构让程序员省去了多少造轮子的功夫。
-
丰富的索引类型:通用的Btree索引;大幅优化顺序访问的Brin索引;等值查询的Hash索引;GIN倒排索引;GIST通用搜索树,高效支持地理查询,KNN查询;Bitmap同时利用多个独立索引;Bloom高效过滤索引;能大幅减小索引大小的条件索引;能优雅替代冗余字段的函数索引。而MySQL就只有那么可怜的几种索引。
-
稳定可靠,正确高效。MVCC轻松实现快照隔离,MySQL的RR隔离等级实现不完善,无法避免PMP与G-single异常。而且基于锁与回滚段的实现会有各种坑;PostgreSQL通过SSI能实现高性能的可序列化。
-
复制强大:WAL段复制,流复制(v9出现,同步、半同步、异步),逻辑复制(v10出现:订阅/发布),触发器复制,第三方复制,各种复制一应俱全。
-
运维友好:可以将DDL放在事务中执行(可回滚),创建索引不锁表,添加新列(不带默认值)不锁表,清理/备份不锁表。各种系统视图,监控功能都很完善。
-
扩展众多、功能丰富、可定制程度极强。在PostgreSQL中可以使用任意的语言编写函数:Python,Go,Javascript,Java,Shell等等。与其说Pg是数据库,不如说它是一个开发平台。我就试过很多没什么卵用但很好玩的东西:**数据库里(in-db)**的爬虫/ 推荐系统 / 神经网络 / Web服务器等等。有着各种功能强悍或脑洞清奇的第三方插件:https://pgxn.org。
-
PostgreSQL的License友好,BSD随便玩,君不见多少数据库都是PG的换皮产品。MySQL有GPL传染,还要被Oracle捏着蛋蛋。
区块链与分布式数据库
区块链的本质,想提供的功能,及其演化方向,就是分布式数据库。
确切的讲,是拜占庭容错(抗恶意节点攻击)的分布式(无领导者复制)数据库。
如果这种分布式数据库用来存储各种币的交易记录,这个系统就叫做所谓的“XX币”。例如以太坊就是这样一个分布式数据库,上面除了记载着各种山寨币的交易记录,还可以记载各种奇奇怪怪的内容。花一点以太币,就可以在这个分布式数据库里留下一条记录(一封信)。而所谓智能合约就是这个分布式数据库上的存储过程。
从形式上看,区块链与**预写式日志(Write-Ahead-Log, WAL, Binlog, Redolog)**在设计原理上是高度一致的。
WAL是数据库的核心数据结构,记录了从数据库创建之初到当前时刻的所有变更,用于实现主从复制、备份回滚、故障恢复等功能。如果保留了全量的WAL日志,就可以从起点回放WAL,时间旅行到任意时刻的状态,如PostgreSQL的PITR。
区块链其实就是这样一份日志,它记录了从创世以来的每笔Transaction。回放日志就可以还原数据库任意时刻的状态(反之则不成立)。所以区块链当然可以算作某种意义上的数据库。
区块链的两大特性:去中心化与防篡改,用数据库的概念也很好理解:
- 去中心化的实质就是无领导者复制(leaderless replication),核心在于分布式共识。
- 防篡改的实质就是拜占庭容错,即,使得篡改WAL的计算代价在概率上不可行。
正如WAL分为日志段,区块链也被划分为一个一个**区块,**且每一段带有先前日志段的哈希指纹。
所谓挖矿就是一个公开的猜数字比快游戏(满足条件的数字才会被共识承认),先猜中者能获取下一个日志段的初夜权:向日志段里写一笔向自己转账的记录(就是挖矿的奖励),并广播出去(如果别人也猜中了,以先广播至多数为准)。所有节点通过共识算法,保证当前最长的链为权威日志版本。区块链通过共识算法实现日志段的无主复制。
而如果想要修改某个WAL日志段中的一比交易记录,比如,转给自己一万个比特币,需要把这个区块以及其后所有区块的指纹给凑出来(连猜几次数字),并让多数节点相信这个伪造版本才行(拼一个更长的伪造版本,意味着猜更多次数字)。比特币中六个区块确认一个交易就是这个意思,篡改六个日志段之前的记录的算例代价,通常在概率上是不可行的。区块链通过这种机制(如Merkle树)实现拜占庭容错。
区块链涉及到的相关技术中,除了分布式共识外都很简单,但这种应用方式与机制设计确实是相当惊艳的。区块链可以算是一次数据库的演化尝试,长期来看前景广阔。但搞链能立竿见影起作用的领域,好像都是老大哥的地盘。而且不管怎么吹嘘,现在的区块链离真正意义上的分布式数据库还差的太远,所以现在入场搞应用的大概率都是先烈。
一致性:过载的术语
一致性这个词重载的很厉害,在不同的语境和上下文中,它其实代表着不同的东西:
- 在事务的上下文中,比如ACID里的C,指的就是通常的一致性(Consistency)
- 在分布式系统的上下文中,例如CAP里的C,实际指的是线性一致性(Linearizability)
- 此外,“一致性哈希”,“最终一致性”这些名词里的“一致性”也有不同的涵义。
这些一致性彼此不同却又有着千丝万缕的联系,所以经常会把人绕晕。
在事务的上下文中,一致性(Consistency) 的概念是:对数据的一组特定陈述必须始终成立。即不变量(invariants)。具体到分布式事务的上下文中这个不变量是:所有参与事务的节点状态保持一致:要么全部成功提交,要么全部失败回滚,不会出现一些节点成功一些节点失败的情况。
在分布式系统的上下文中,线性一致性(Linearizability) 的概念是:多副本的系统能够对外表现地像只有单个副本一样(系统保证从任何副本读取到的值都是最新的),且所有操作都以原子的方式生效(一旦某个新值被任一客户端读取到,后续任意读取不会再返回旧值)。
线性一致性这个词可能有些陌生,但说起它的另一个名字大家就清楚了:强一致性(strong consistency) ,当然还有一些诨名:原子一致性(atomic consistency),立即一致性(immediate consistency) 或 外部一致性(external consistency ) 说的都是它。
这两个“一致性”完全不是一回事儿,但之间其实有着微妙的联系,它们之间的桥梁就是共识(Consensus)
简单来说:
- 分布式事务一致性会因为协调者单点引入可用性问题
- 为了解决可用性问题,分布式事务的节点需要在协调者故障时就新协调者选取达成共识
- 解决共识问题等价于实现一个线性一致的存储
- 解决共识问题等价于实现全序广播(total order boardcast)
- Paxos/Raft 实现了全序广播
具体来讲:
为了保证分布式事务的一致性,分布式事务通常需要一个协调者(Coordinator)/事务管理器(Transaction Manager)来决定事务的最终提交状态。但无论2PC还是3PC,都无法应对协调者失效的问题,而且具有扩大故障的趋势。这就牺牲了可靠性、可维护性与可扩展性。为了让分布式事务真正可用,就需要在协调者挂点的时候能赶快选举出一个新的协调者来解决分歧,这就需要所有节点对谁是Boss达成共识(Consensus)。
共识意味着让几个节点就某事达成一致,可以用来确定一些互不相容的操作中,哪一个才是赢家。共识问题通常形式化如下:一个或多个节点可以提议(propose)某些值,而共识算法决定采用其中的某个值。在保证分布式事务一致性的场景中,每个节点可以投票提议,并对谁是新的协调者达成共识。
共识问题与许多问题等价,两个最典型的问题就是:
- 实现一个具有线性一致性的存储系统
- 实现全序广播(保证消息不丢失,且消息以相同的顺序传递给每个节点。)
Raft算法解决了全序广播问题。维护多副本日志间的一致性,其实就是让所有节点对同全局操作顺序达成一致,也其实就是让日志系统具有线性一致性。 因而解决了共识问题。(当然正因为共识问题与实现强一致存储问题等价,Raft的具体实现etcd 其实就是一个线性一致的分布式数据库。)
总结一下:
线性一致性是一个精确定义的术语,线性一致性是一种 一致性模型 ,对分布式系统的行为作出了很强的保证。
分布式事务中的一致性则与事务ACID中的C一脉相承,并不是一个严格的术语。(因为什么叫一致,什么叫不一致其实是应用说了算。在分布式事务的场景下可以认为是:所有节点的事务状态始终保持相同)
分布式事务本身的一致性是通过协调者内部的原子操作与多阶段提交协议保证的,不需要共识;但解决分布式事务一致性带来的可用性问题需要用到共识。
推荐阅读:
为什么要学习数据库原理
问题
我们学校开了数据库系统原理课程。但是我还是很迷茫,这几节课老师一上来就讲一堆令人头大的名词概念,我以为我们知道“如何设计构建表”,“如何mysql增删改查”就行了……那为什么还要了解关系模式的表示方法,计算,规范化……概念模型……各种模型的相互转换,为什么还要了解什么关系代数,什么笛卡尔积……这些的理论知识。我十分困惑,通过这些理论概念,该课的目的或者说该书的目的究竟是想让学生学会什么呢?
回答
只会写代码的是码农;学好数据库,基本能混口饭吃;在此基础上再学好操作系统和计算机网络,就能当一个不错的程序员。如果能再把离散数学、数字电路、体系结构、数据结构/算法、编译原理学通透,再加上丰富的实践经验与领域特定知识,就能算是一个优秀的工程师了。(前端算IO密集型应用就别抬杠了)
计算机其实就是存储/IO/CPU三大件; 而计算说穿了就是两个东西:数据与算法(状态与转移函数)。常见的软件应用,除了各种模拟仿真、模型训练、视频游戏这些属于计算密集型应用外,绝大多数都属于数据密集型应用。从最抽象的意义上讲,这些应用干的事儿就是把数据拿进来,存进数据库,需要的时候再拿出来。
抽象是应对复杂度的最强武器。操作系统提供了对存储的基本抽象:内存寻址空间与磁盘逻辑块号。文件系统在此基础上提供了文件名到地址空间的KV存储抽象。而数据库则在其基础上提供了对应用通用存储需求的高级抽象。
在真实世界中,除非准备从基础组件的轮子造起,不然根本没那么多机会去摆弄花哨的数据结构和算法(对数据密集型应用而言)。甚至写代码的本事可能也没那么重要:可能只会有那么一两个Ad Hoc算法需要在应用层实现,大部分需求都有现成的轮子可以使用,主要的创造性工作往往是在数据模型设计上。实际生产中,数据表就是数据结构,索引与查询就是算法。而应用代码往往扮演的是胶水的角色,处理IO与业务逻辑,其他大部分的工作都是在数据系统之间搬运数据。
在最宽泛的意义上,有状态的地方就有数据库。它无所不在,网站的背后、应用的内部,单机软件,区块链里,甚至在离数据库最远的Web浏览器中,也逐渐出现了其雏形:各类状态管理框架与本地存储。“数据库”可以简单地只是内存中的哈希表/磁盘上的日志,也可以复杂到由多种数据系统集成而来。关系型数据库只是数据系统的冰山一角(或者说冰山之巅),实际上存在着各种各样的数据系统组件:
- 数据库:存储数据,以便自己或其他应用程序之后能再次找到(PostgreSQL,MySQL,Oracle)
- 缓存:记住开销昂贵操作的结果,加快读取速度(Redis,Memcached)
- 搜索索引:允许用户按关键字搜索数据,或以各种方式对数据进行过滤(ElasticSearch)
- 流处理:向其他进程发送消息,进行异步处理(Kafka,Flink)
- 批处理:定期处理累积的大批量数据(Hadoop)
**架构师最重要的能力之一,就是了解这些组件的性能特点与应用场景,能够灵活地权衡取舍、集成拼接这些数据系统。**绝大多数工程师都不会去从零开始编写存储引擎,因为在开发应用时,数据库已经是足够完美的工具了。关系型数据库则是目前所有数据系统中使用最广泛的组件,可以说是程序员吃饭的主要家伙,重要性不言而喻。
了解意义(WHY)比了解方法(HOW)更重要。但一个很遗憾的现实是,以大多数学生,甚至相当一部分公司能够接触到的现实问题而言,拿几个文件甚至在内存里放着估计都能应付大多数场景了(需求简单到低级抽象就可以Handle)。没什么机会接触到数据库真正要解决的问题,也就难有真正使用与学习数据库的驱动力,更别提数据库原理了。当软硬件故障把数据搞成一团浆糊(可靠性);当单表超出了内存大小,并发访问的用户增多(可扩展性),当代码的复杂度发生爆炸,开发陷入泥潭(可维护性),人们才会真正意识到数据库的重要性。所以我也理解当前这种填鸭教学现状的苦衷:工作之后很难有这么大把的完整时间来学习原理了,所以老师只好先使劲灌输,多少让学生对这些知识有个印象。等学生参加工作后真正遇到这些问题,也许会想起大学好像还学了个叫数据库的东西,这些知识就会开始反刍。
数据库,尤其是关系型数据库,非常重要。那为什么要学习其原理呢?
对优秀的工程师来说,只会用数据库是远远不够的。学习原理对于当CRUD BOY搬砖收益并不大,但当通用组件真的无解需要自己撸起袖子上时,没有金坷垃怎么种庄稼?设计系统时,理解原理能让你以最少的复杂度代价写出更可靠高效的代码;遇到疑难杂症需要排查时,理解原理能带来精准的直觉与深刻的洞察。
数据库是一个博大精深的领域,存储I/O计算无所不包。其主要原理也可以粗略分为几个部分:数据模型设计原理(应用)、存储引擎原理(基础)、索引与查询优化器的原理(性能)、事务与并发控制的原理(正确性)、故障恢复与复制系统的原理(可靠性)。 所有的原理都有其存在意义:为了解决实际问题。
例如数据模型设计中的范式理论,就是为了解决数据冗余这一问题而提出的,它是为了把事情做漂亮(可维护)。它是模型设计中一个很重要的设计权衡:通常而言,冗余少则复杂度小/可维护性强,冗余高则性能好。比如用了冗余字段,那更新时原本一条SQL就搞定的事情,现在现在就要用两条SQL更新两个地方,需要考虑多对象事务,以及并发执行时可能的竞态条件。这就需要仔细权衡利弊,选择合适的规范化等级。数据模型设计,就是生产中的数据结构设计。不了解这些原理,就难以提取良好的抽象,其他工作也就无从谈起。
而关系代数与索引的原理,则在查询优化中扮演重要的角色,它是为了把事情做得快(性能,可扩展)。当数据量越来越大,SQL写的越来越复杂时,它的意义就会体现出来:**怎样写出等价但是更高效的查询?**当查询优化器没那么智能时,就需要人来干这件事。这种优化往往成本极小而收益巨大,比如一个需要几秒的KNN查询,如果知道R树索引的原理,就可以通过改写查询,创建GIST索引优化到1毫秒内,千倍的性能提升。**不了解索引与查询设计原理,就难以充分发挥数据库的性能。**
事务与并发控制的原理,是为了把事情做正确(可靠性)。事务是数据处理领域最伟大的抽象之一,它提供了很多有用的保证(ACID),但这些保证到底意味着什么?事务的原子性让你在提交前能随时中止事务并丢弃所有写入,相应地,事务的持久性则承诺一旦事务成功提交,即使发生硬件故障或数据库崩溃,写入的任何数据也不会丢失。这让错误处理变得无比简单:要么成功完事,要么失败重试。有了后悔药,程序员不用再担心半路翻车会留下惨不忍睹的车祸现场了。
另一方面,事务的隔离性则保证同时执行的事务无法相互影响(Serializable), 数据库提供了不同的隔离等级保证,以供程序员在性能与正确性之间进行权衡。编写并发程序并不容易,在几万TPS的负载下,各种极低概率,匪夷所思的问题都会出现:事务之间相互踩踏,丢失更新,幻读与写入偏差,慢查询拖慢快查询导致连接堆积,单表数据库并发增大后的性能急剧恶化,甚至快慢查询都减少但因比例变化导致的灵异抽风。这些问题,在低负载的情况下会潜伏着,随着规模量级增长突然跳出来,给你一个大大的惊喜。现实中真正可能出现的各类异常,也绝非SQL标准中简单的几种异常能说清的。 不理解事务的原理,意味着应用的可靠性可能遭受不必要的损失。
故障恢复与复制的原理,可能对于程序员没有那么重要,但架构师与DBA必须清楚。高可用是很多应用的追求目标,但什么是高可用,高可用怎么保证?读写分离?快慢分离?异地多活?x地x中心?说穿了底下的核心技术其实就是复制(Replication)(或再加上自动故障切换(Failover))。这里有无穷无尽的坑:复制延迟带来的各种灵异现象,网络分区与脑裂,存疑事务blahblah。不理解复制的原理,高可用就无从谈起。
对于一些程序员而言,可能数据库就是“增删改查”,包一包接口,原理似乎属于“屠龙之技”。如果止步于此,那原理确实没什么好学的,但有志者应当打破砂锅问到底的精神。私认为只了解自己本领域知识是不够的,只有把当前领域赖以建立的上层领域摸清楚,才能称为专家。在数据库面前,后端也是前端;对于程序员知识栈而言,数据库是一个合适的栈底。
上面讲了WHY,下面就说一下 HOW
数据库教学的一个矛盾是:如果连数据库都不会用,那学数据库原理有个卵用呢?
学数据库的原则是学以致用。只有实践,才能带来对问题的深刻理解;只有先知其然,才有条件去知其所以然。教材可以先草草的过一遍,然后直接去看数据库文档,上手去把数据库用起来,做个东西出来。通过实践掌握数据库的使用,再去学习原理就会事半功倍(以及充满动力)。对于学习而言,有条件去实习当然最好,没有条件那最好的办法就是自己创造场景,自己挖掘需求。
比如,从解决个人需求开始:管理个人密码,体重跟踪,记账,做个小网站、在线聊天小程序。当它演化的越来越复杂,开始有多个用户,出现各种蛋疼问题之后,你就会开始意识到事务的意义。
再比如,结合爬虫,抓一些房价、股价、地理、社交网络的数据存在数据库里,做一些挖掘与分析。当你积累的数据越来越多,分析查询越来越复杂;SQL长得没法读,跑起来慢出猪叫,这时候关系代数的理论就能指导你进一步进行优化。
当你意识到这些设计都是为了解决现实生产中的问题,并亲自遇到过这些问题之后,再去学习原理,才能相互印证,并知其所以然。当你发现查询时间随数据增长而指数增长时;当你遇到成千上万的用户同时读写为并发控制焦头烂额时;当你碰上软硬件故障把数据搅得稀巴烂时;当你发现数据冗余让代码复杂度快速爆炸时;你就会发现这些设计存在的意义。
教材、书籍、文档、视频、邮件组、博客都是很好的学习资源。教材的话华章的黑皮系列教材都还不错,《数据库系统概念》这本就挺好的。但我推荐先看看这本书:《设计数据密集型应用》 ,写的非常好,我觉得不错就义务翻译了一下。纸上得来终觉浅,绝知此事要躬行。实践方能出真知,新手上路选哪家?个人推荐世界上最先进的开源关系型数据库PostgreSQL,设计优雅,功能强大。传教就有请德哥出场了:https://github.com/digoal/blog 。有时间的话可以再看看Redis,源码简单易读,实践中也很常用,非关系型数据库也应当多了解一下。
最后,关系型数据库虽然强大,却绝非数据处理的终章,尽可能多地去尝试各种各样的数据库吧。