供给方案
Pigsty供给方案的相关概念
所谓供给方案(Provisioning Solution),指的是一套向用户交付数据库服务与监控系统的系统。
供给方案不是数据库,而是数据库工厂:
用户向供给系统提交一份配置,供给系统便会按照用户所需的规格在环境中创建出所需的数据库集群来。
这比较类似于向Kubernetes提交YAML文件,创建所需的各类资源。
定义数据库集群
例如,以下配置信息声明了一套名为pg-test的PostgreSQL数据库集群。
#-----------------------------
# cluster: pg-test
#-----------------------------
pg-test: # define cluster named 'pg-test'
# - cluster members - #
hosts:
10.10.10.11: {pg_seq: 1, pg_role: primary, ansible_host: node-1}
10.10.10.12: {pg_seq: 2, pg_role: replica, ansible_host: node-2}
10.10.10.13: {pg_seq: 3, pg_role: offline, ansible_host: node-3}
# - cluster configs - #
vars:
# basic settings
pg_cluster: pg-test # define actual cluster name
pg_version: 13 # define installed pgsql version
node_tune: tiny # tune node into oltp|olap|crit|tiny mode
pg_conf: tiny.yml # tune pgsql into oltp/olap/crit/tiny mode
# business users, adjust on your own needs
pg_users:
- name: test # example production user have read-write access
password: test # example user's password
roles: [dbrole_readwrite] # dborole_admin|dbrole_readwrite|dbrole_readonly|dbrole_offline
pgbouncer: true # production user that access via pgbouncer
comment: default test user for production usage
pg_databases: # create a business database 'test'
- name: test # use the simplest form
pg_default_database: test # default database will be used as primary monitor target
# proxy settings
vip_mode: l2 # enable/disable vip (require members in same LAN)
vip_address: 10.10.10.3 # virtual ip address
vip_cidrmask: 8 # cidr network mask length
vip_interface: eth1 # interface to add virtual ip
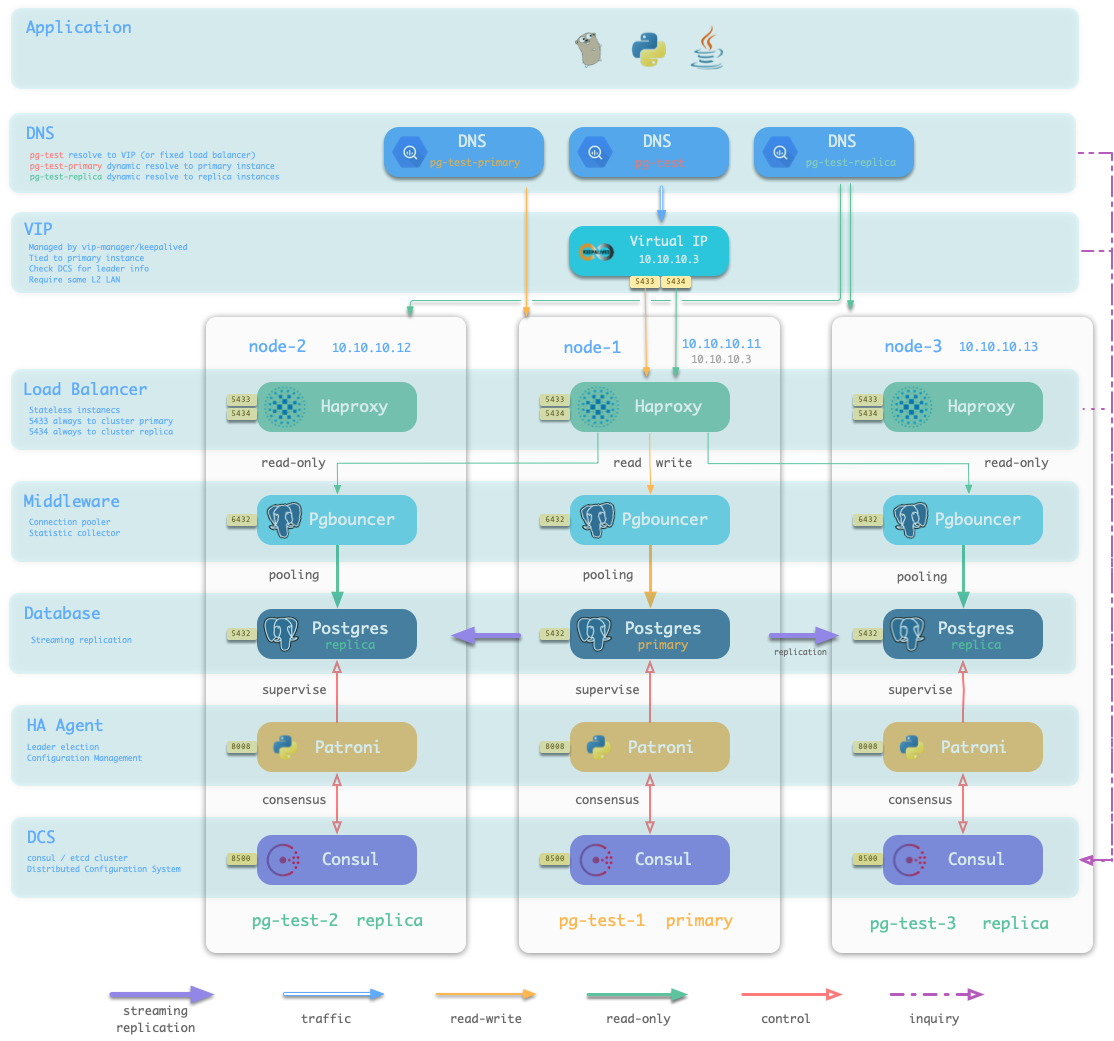
当执行 数据库供给 脚本 ./pgsql.yml 时,供给系统会根据清单中的定义,在10.10.10.11,10.10.10.12,10.10.10.13这三台机器上生成一主两从的PostgreSQL集群pg-test。并创建名为test的用户与数据库。同时,Pigsty还会根据要求,声明一个10.10.10.3的VIP绑定在集群的主库上面。结构如下图所示。
定义基础设施
用户能够定义的不仅仅是数据库集群,还包括了整个基础设施。
Pigsty通过154个变量实现了对数据库运行时环境的完整表述。
详细的可配置项,请参考 配置指南
供给方案的职责
供给方案通常只负责集群的创建。一旦集群创建完毕,日常的管理应当由管控平台负责。
尽管如此,Pigsty目前不包含管控平台部分,因此也提供了简单的资源回收销毁脚本,并亦可用于资源的更新与管理。但须知此并非供给方案的本职工作。
1 - 数据库接入
如何接入Pigsty所创建的数据库?
Pigsty提供了丰富的接入方式,用户可以根据自己的基础设施情况与喜好自行选择接入模式。
数据库访问方式
用户可以通过多种方式访问数据库服务。
在集群层次,用户可以通过集群域名+服务端口的方式访问集群提供的 四种默认服务,Pigsty强烈建议使用这种方式。当然用户也可以绕开域名,直接使用集群的VIP(L2 or L4)访问数据库集群。
在实例层次,用户可以通过节点IP/域名 + 5432端口直连Postgres数据库,也可以用6432端口经由Pgbouncer访问数据库。还可以通过Haproxy经由5433~543x访问实例所属集群提供的服务。
如何访问数据库,最终取决于数据库所使用的流量接入方案。
典型接入方案
Pigsty推荐使用基于Haproxy的接入方案(1/2),在生产环境中如果有基础设施支持,也可以使用基于L4VIP(或与之等效的负载均衡服务)的接入方案(3)。
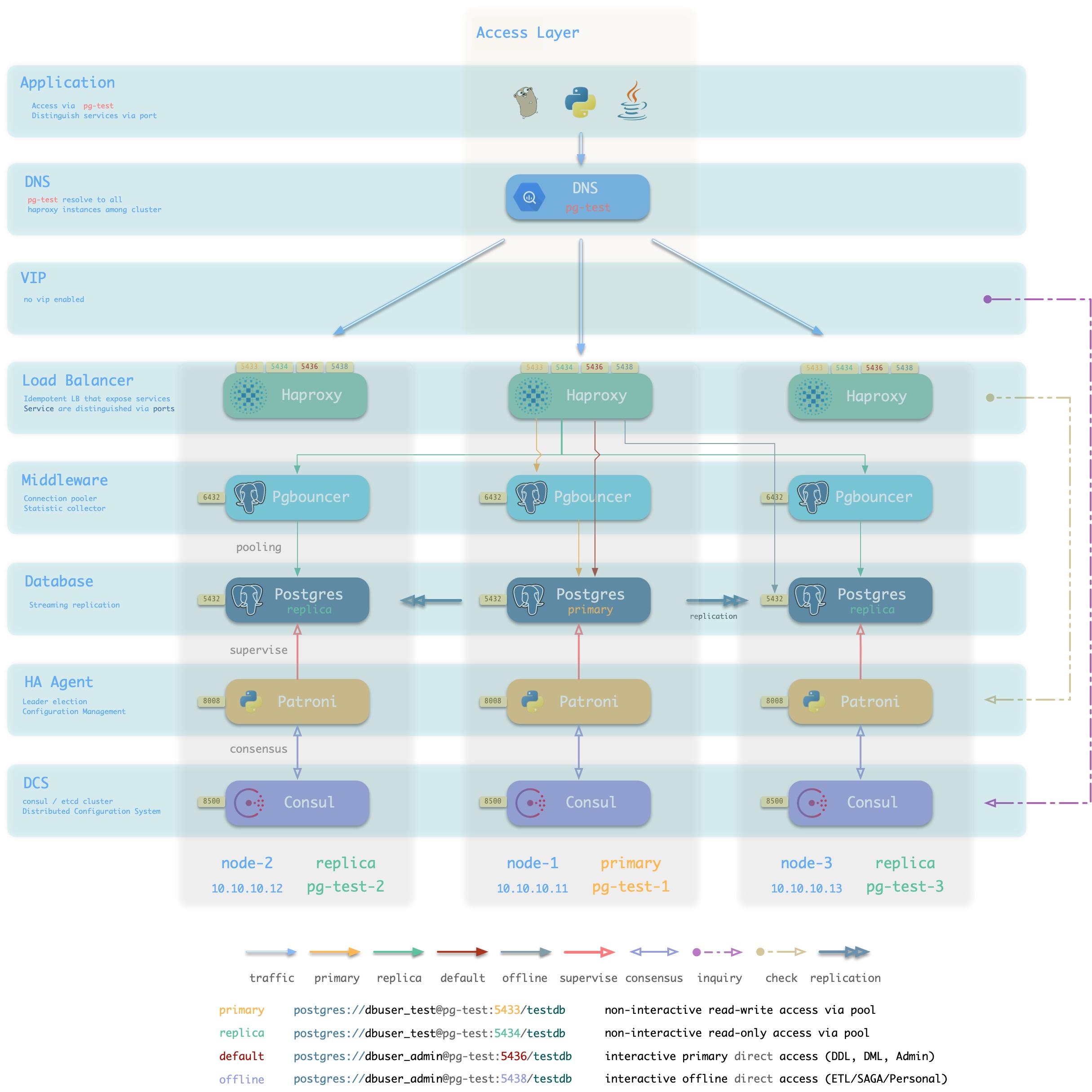
DNS + Haproxy
方案简介
标准高可用接入方案,系统无单点。灵活性,适用性,性能的最佳平衡点。
集群中的Haproxy采用Node Port的方式统一对外暴露 服务。每个Haproxy都是幂等的实例,提供完整的负载均衡与服务分发功能。Haproxy部署于每一个数据库节点上,因此整个集群的每一个成员在使用效果上都是幂等的。(例如访问任何一个成员的5433端口都会连接至主库连接池,访问任意成员的5434端口都会连接至某个从库的连接池)
Haproxy本身的可用性通过幂等副本实现,每一个Haproxy都可以作为访问入口,用户可以使用一个、两个、多个,所有Haproxy实例,每一个Haproxy提供的功能都是完全相同的。
用户需要自行确保应用能够访问到任意一个健康的Haproxy实例。作为最朴素的一种实现,用户可以将数据库集群的DNS域名解析至若干Haproxy实例,并启用DNS轮询响应。而客户端可以选择完全不缓存DNS,或者使用长连接并实现建立连接失败后重试的机制。又或者参考方案2,在架构侧通过额外的L2/L4 VIP确保Haproxy本身的高可用。
方案优越性
-
无单点,高可用
-
VIP固定绑定至主库,可以灵活访问
方案局限性
-
多一跳
-
Client IP地址丢失,部分HBA策略无法正常生效
-
Haproxy本身的高可用通过幂等副本,DNS轮询与客户端重连实现
DNS应有轮询机制,客户端应当使用长连接,并有建连失败重试机制。以便单Haproxy故障时可以自动漂移至集群中的其他Haproxy实例。如果无法做到这一点,可以考虑使用接入方案2,使用L2/L4 VIP确保Haproxy高可用。
方案示意
L2 VIP + Haproxy
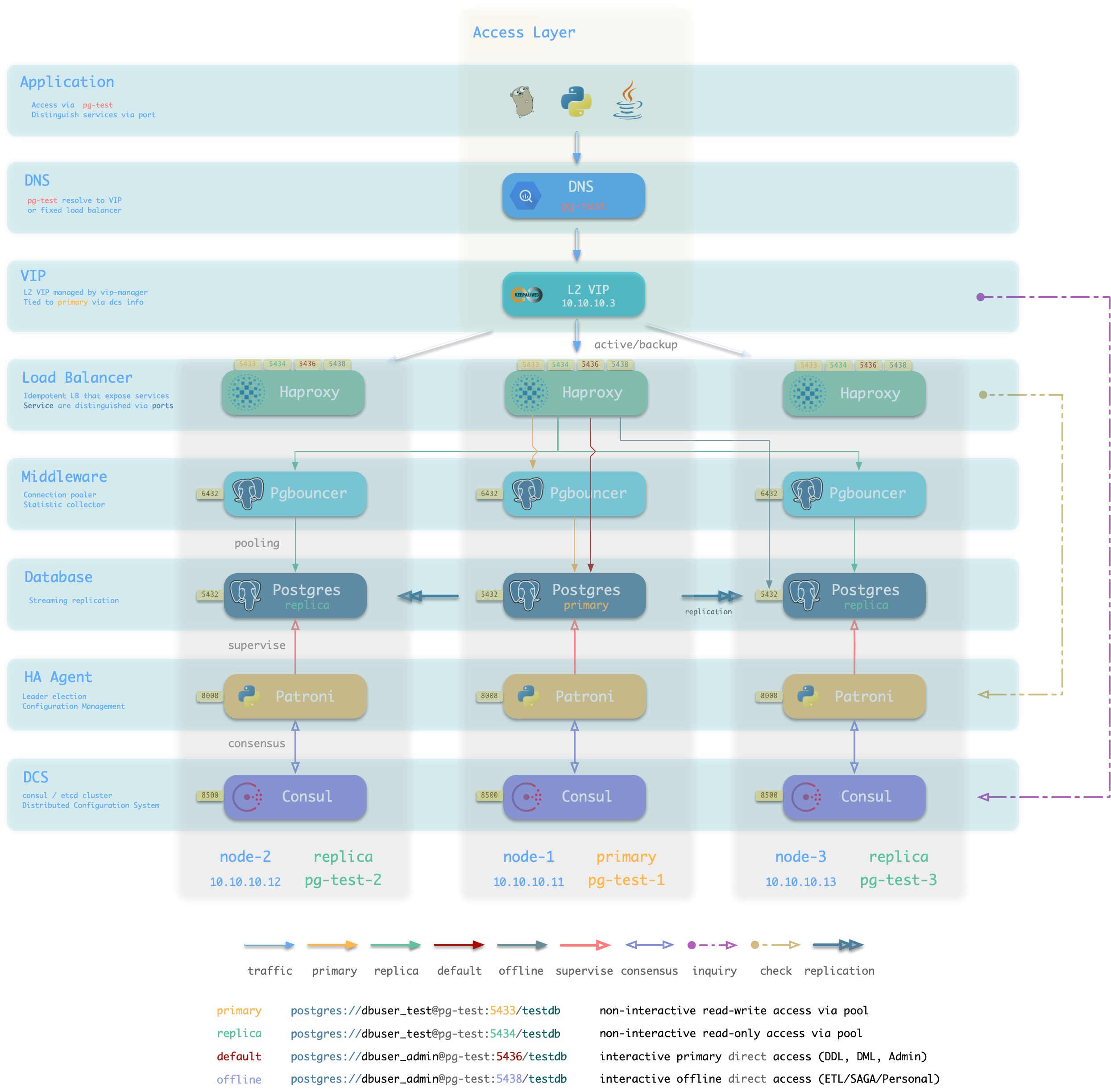
方案简介
Pigsty沙箱使用的标准接入方案,采用单个域名绑定至单个L2 VIP,VIP指向集群中的HAProxy。
集群中的Haproxy采用Node Port的方式统一对外暴露 服务。每个Haproxy都是幂等的实例,提供完整的负载均衡与服务分发功能。而Haproxy本身的可用性则通过L2 VIP来保证。
每个集群都分配有一个L2 VIP,固定绑定至集群主库。当主库发生切换时,该L2 VIP也会随之漂移至新的主库上。这是通过vip-manager实现的:vip-manager会查询Consul获取集群当前主库信息,然后在主库上监听VIP地址。
集群的L2 VIP有与之对应的域名。域名固定解析至该L2 VIP,在生命周期中不发生变化。
方案优越性
-
无单点,高可用
-
VIP固定绑定至主库,可以灵活访问
方案局限性
方案示意
L4 VIP + Haproxy
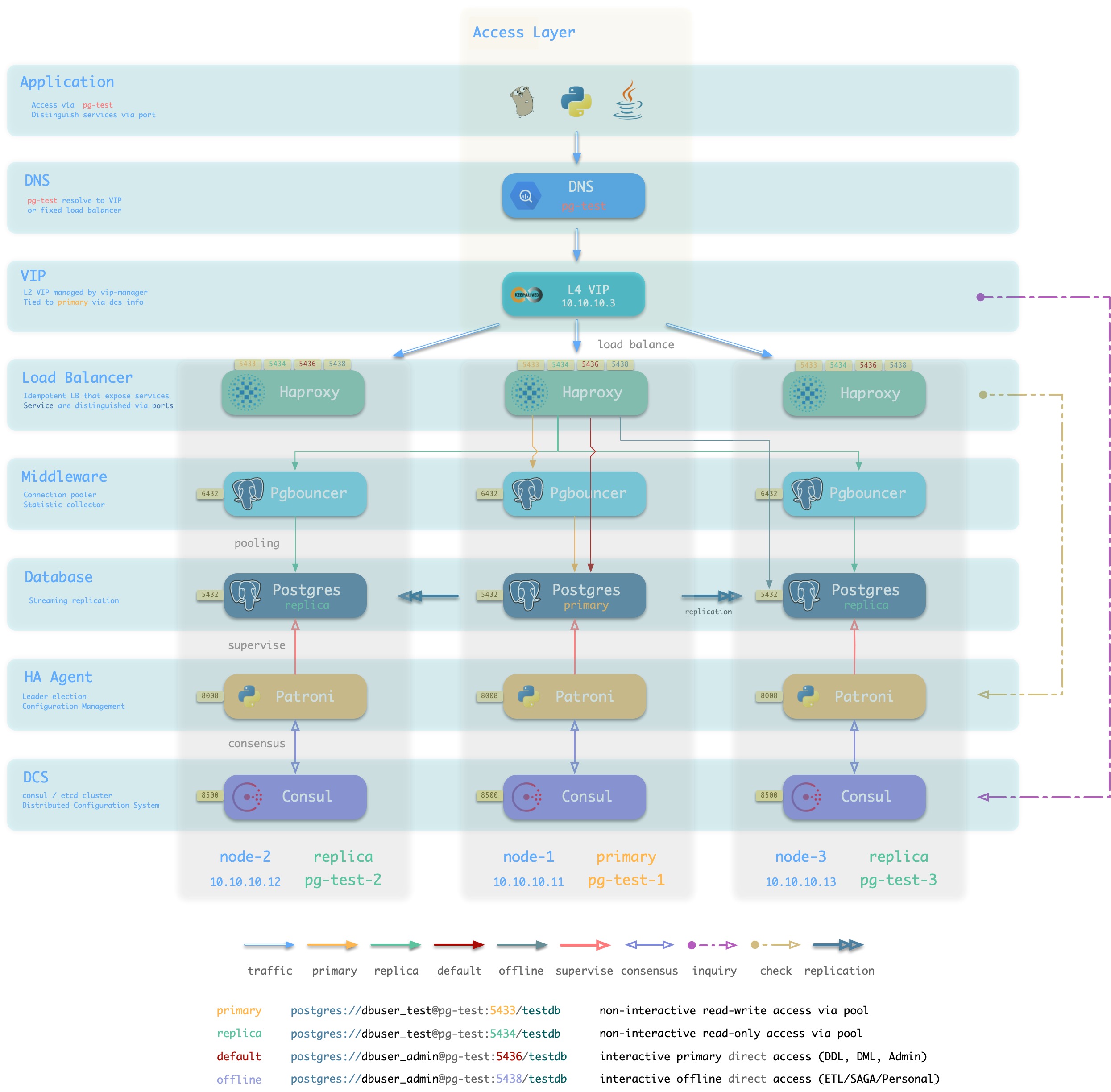
方案简介
接入方案1/2的另一种变体,通过L4 VIP确保Haproxy的高可用
方案优越性
- 无单点,高可用
- 可以同时使用所有的Haproxy实例,均匀承载流量。
- 所有候选主库不需要位于同一二层网络。
- 可以操作单一VIP完成流量切换(如果同时使用了多个Haproxy,不需要逐个调整)
方案局限性
- 多两跳,较为浪费,如果有条件可以直接使用方案4: L4 VIP直接接入。
- Client IP地址丢失,部分HBA策略无法正常生效
方案示意
L4 VIP
方案简介
大规模高性能生产环境建议使用 L4 VIP接入(FullNAT,DPVS)
方案优越性
- 性能好,吞吐量大
- 可以通过
toa模块获取正确的客户端IP地址,HBA可以完整生效。
方案局限性
- 仍然多一条。
- 需要依赖外部基础设施,部署复杂。
- 未启用
toa内核模块时,仍然会丢失客户端IP地址。
- 没有Haproxy屏蔽主从差异,集群中的每个节点不再“幂等”。
方案示意

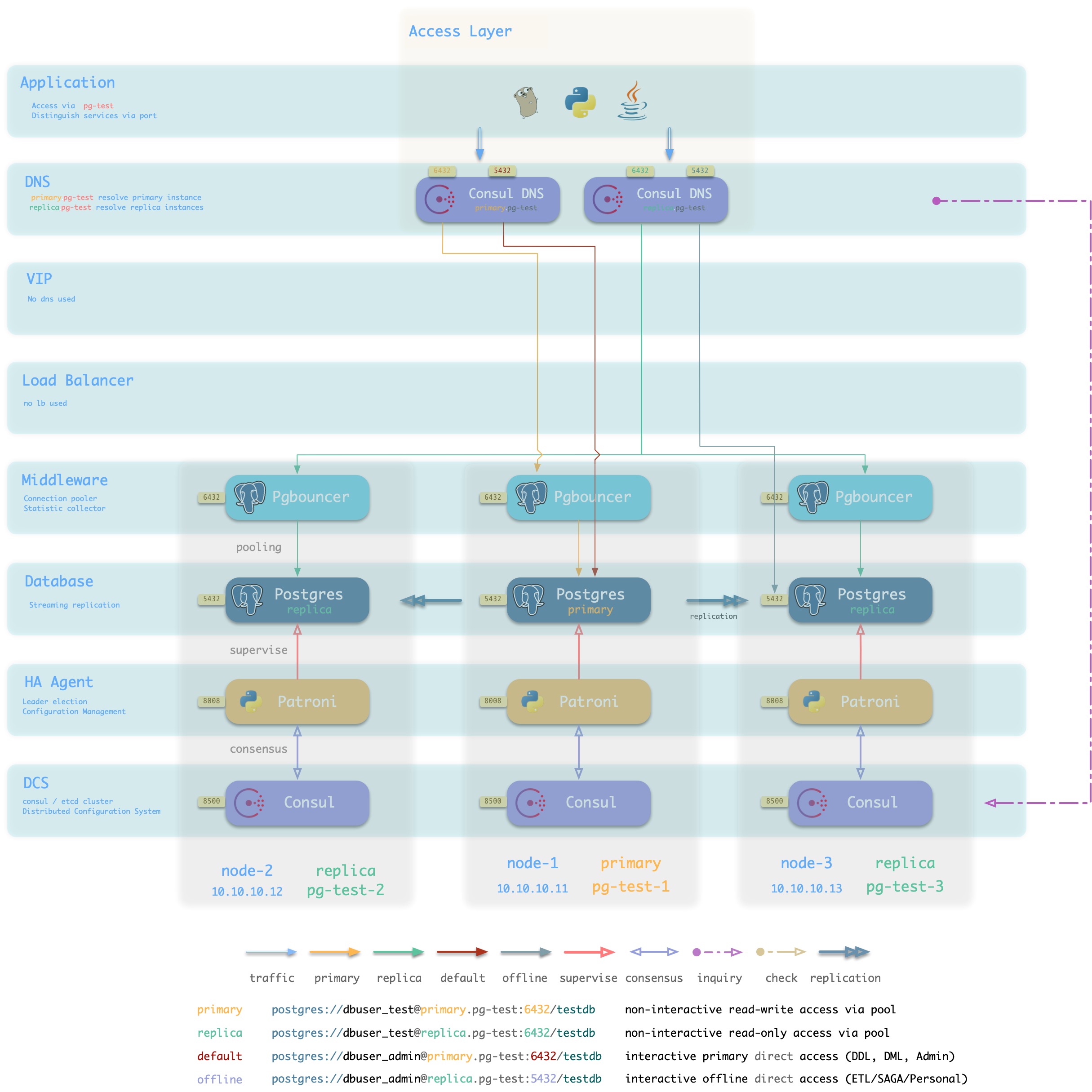
Consul DNS
方案简介
L2 VIP并非总是可用,特别是所有候选主库必须位于同一二层网络的要求可能不一定能满足。
在这种情况下,可以使用DNS解析代替L2 VIP,进行
方案优越性
方案局限性
- 依赖Consul DNS
- 用户需要合理配置DNS缓存策略
方案示意
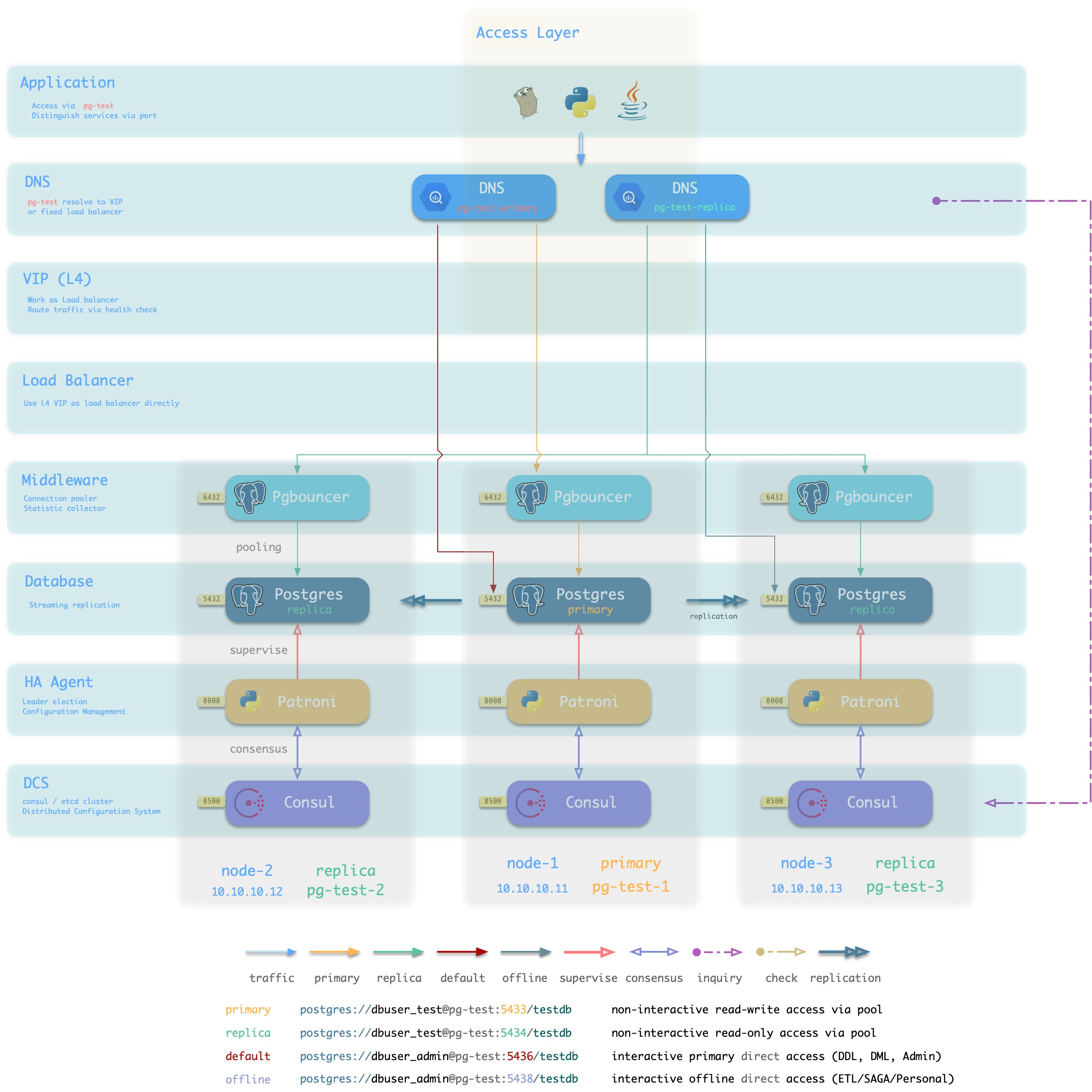
Static DNS
方案简介
传统静态DNS接入方式
方案优越性
方案局限性
方案示意
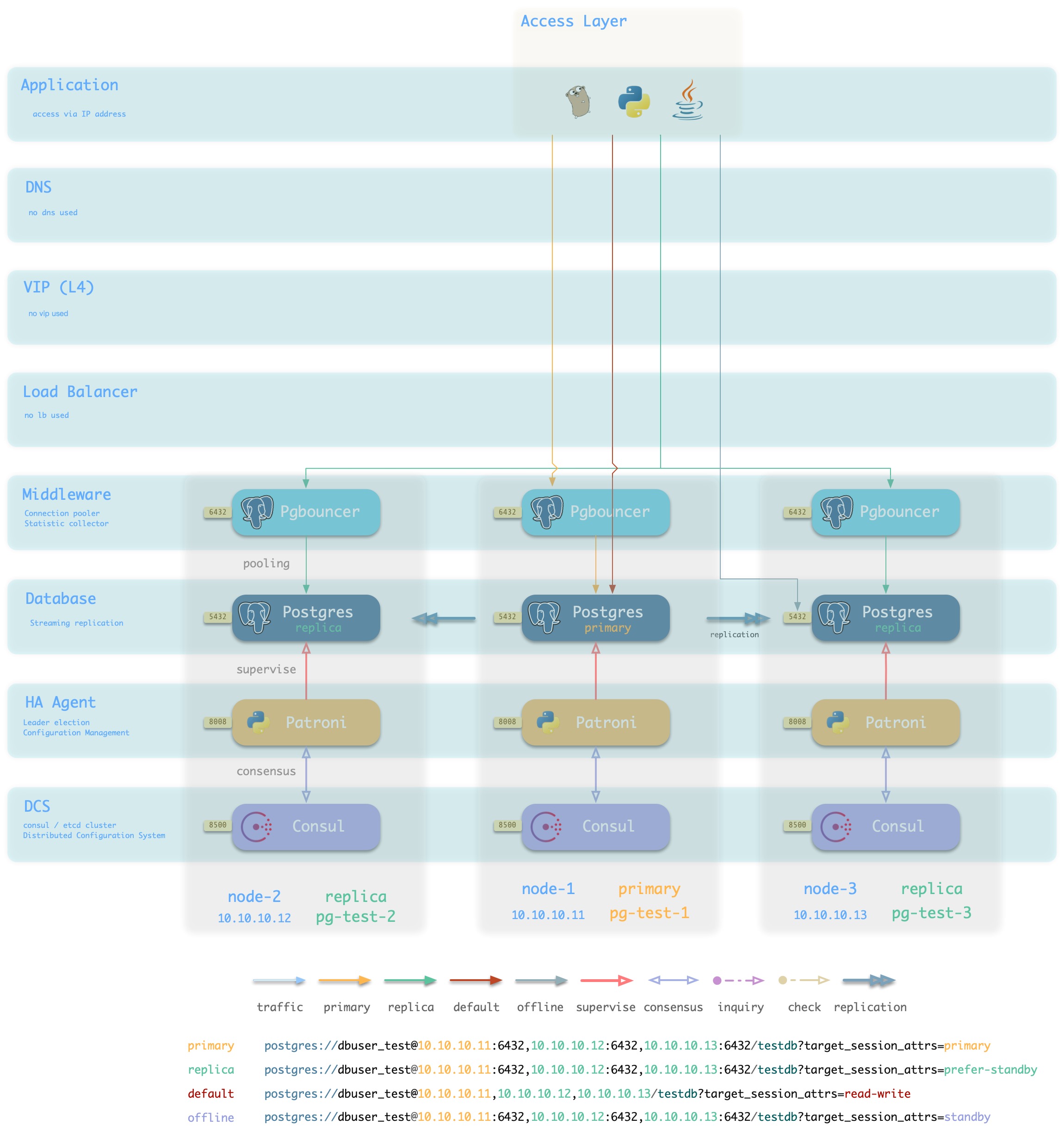
IP
方案简介
采用智能客户端直连数据库IP接入
方案优越性
- 直连数据库/连接池,少一条
- 不依赖额外组件进行主从区分,降低系统复杂性。
方案局限性
方案示意
2 - 数据库服务
如何在Pigsty中定义新的服务
服务(Service),是数据库集群对外提供功能的形式。通常来说,一个数据库集群至少应当提供两种服务:
- 读写服务(primary) :用户可以写入数据库
- 只读服务(replica) :用户可以访问只读副本
此外,根据具体的业务场景,可能还会有其他的服务:
- 离线从库服务(offline):不承接线上只读流量的专用从库,用于ETL与个人用户查询。
- 同步从库服务(standby) :采用同步提交,没有复制延迟的只读服务。
- 延迟从库服务(delayed) : 允许业务访问固定时间间隔之前的旧数据。
- 默认直连服务(default) : 允许(管理)用户绕过连接池直接管理数据库的服务
默认服务
Pigsty默认对外提供四种服务:primary, replica, default, offline
| 服务 |
端口 |
用途 |
说明 |
| primary |
5433 |
生产读写 |
通过连接池连接至集群主库 |
| replica |
5434 |
生产只读 |
通过连接池连接至集群从库 |
| default |
5436 |
管理 |
直接连接至集群主库 |
| offline |
5438 |
ETL/个人用户 |
直接连接至集群可用的离线实例 |
| 服务 |
端口 |
说明 |
样例 |
| primary |
5433 |
只有生产用户可以连接 |
postgres://test@pg-test:5433/test |
| replica |
5434 |
只有生产用户可以连接 |
postgres://test@pg-test:5434/test |
| default |
5436 |
管理员与DML执行者可以连接 |
postgres://dbuser_admin@pg-test:5436/test |
| offline |
5438 |
ETL/STATS 个人用户可以连接 |
postgres://dbuser_stats@pg-test-tt:5438/test
postgres://dbp_vonng@pg-test:5438/test |
Primary服务
Primary服务服务于线上生产读写访问,它将集群的5433端口,映射为 主库连接池(默认6432) 端口。
Primary服务选择集群中的所有实例作为其成员,但只有健康检查/primary为真者,才能实际承接流量。
在集群中有且仅有一个实例是主库,只有其健康检查为真。
- name: primary # service name {{ pg_cluster }}_primary
src_ip: "*"
src_port: 5433
dst_port: pgbouncer # 5433 route to pgbouncer
check_url: /primary # primary health check, success when instance is primary
selector: "[]" # select all instance as primary service candidate
Replica服务
Replica服务服务于线上生产只读访问,它将集群的5434端口,映射为 从库连接池(默认6432) 端口。
Replica服务选择集群中的所有实例作为其成员,但只有健康检查/read-only为真者,才能实际承接流量,该健康检查对所有可以承接只读流量的实例(包括主库)返回成功。所以集群中的任何成员都可以承载只读流量。
但默认情况下,只有从库承载只读请求,Replica服务定义了selector_backup,该选择器将集群的主库作为 备份实例 加入到Replica服务中。只要当Replica服务中所有其他实例,即所有从库宕机时,主库才会开始承接只读流量。
# replica service will route {ip|name}:5434 to replica pgbouncer (5434->6432 ro)
- name: replica # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5434
dst_port: pgbouncer
check_url: /read-only # read-only health check. (including primary)
selector: "[]" # select all instance as replica service candidate
selector_backup: "[? pg_role == `primary`]" # primary are used as backup server in replica service
Default服务
Default服务服务于线上主库直连,它将集群的5436端口,映射为主库Postgres端口(默认5432)。
Default服务针对交互式的读写访问,包括:执行管理命令,执行DDL变更,连接至主库执行DML,执行CDC。交互式的操作不应当通过连接池访问,因此Default服务将流量直接转发至Postgres,绕过了Pgbouncer。
Default服务与Primary服务类似,采用相同的配置选项。出于演示目显式填入了默认参数。
# default service will route {ip|name}:5436 to primary postgres (5436->5432 primary)
- name: default # service's actual name is {{ pg_cluster }}-{{ service.name }}
src_ip: "*" # service bind ip address, * for all, vip for cluster virtual ip address
src_port: 5436 # bind port, mandatory
dst_port: postgres # target port: postgres|pgbouncer|port_number , pgbouncer(6432) by default
check_method: http # health check method: only http is available for now
check_port: patroni # health check port: patroni|pg_exporter|port_number , patroni by default
check_url: /primary # health check url path, / as default
check_code: 200 # health check http code, 200 as default
selector: "[]" # instance selector
haproxy: # haproxy specific fields
maxconn: 3000 # default front-end connection
balance: roundrobin # load balance algorithm (roundrobin by default)
default_server_options: 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
Offline服务
Offline服务用于离线访问与个人查询。它将集群的5438端口,映射为离线实例Postgres端口(默认5432)。
Offline服务针对交互式的只读访问,包括:ETL,离线大型分析查询,个人用户查询。交互式的操作不应当通过连接池访问,因此Default服务将流量直接转发至离线实例的Postgres,绕过了Pgbouncer。
离线实例指的是 pg_role == offline 或带有pg_offline_query标记的实例。离线实例外的其他其他从库将作为Offline的备份实例,这样当Offline实例宕机时,Offline服务仍然可以从其他从库获取服务。
# offline service will route {ip|name}:5438 to offline postgres (5438->5432 offline)
- name: offline # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5438
dst_port: postgres
check_url: /replica # offline MUST be a replica
selector: "[? pg_role == `offline` || pg_offline_query ]" # instances with pg_role == 'offline' or instance marked with 'pg_offline_query == true'
selector_backup: "[? pg_role == `replica` && !pg_offline_query]" # replica are used as backup server in offline service
服务定义
由服务定义对象构成的数组,定义了每一个数据库集群中对外暴露的服务。每一个集群都可以定义多个服务,每个服务包含任意数量的集群成员,服务通过端口进行区分。
服务通过 pg_services 与 pg_services_extra 进行定义。前者用于定义整个环境中通用的服务,后者用于定义集群特定的额外服务。两者都是由服务定义组成的数组,Pigsty默认服务的定义如下所示:
# primary service will route {ip|name}:5433 to primary pgbouncer (5433->6432 rw)
- name: primary # service name {{ pg_cluster }}_primary
src_ip: "*"
src_port: 5433
dst_port: pgbouncer # 5433 route to pgbouncer
check_url: /primary # primary health check, success when instance is primary
selector: "[]" # select all instance as primary service candidate
# replica service will route {ip|name}:5434 to replica pgbouncer (5434->6432 ro)
- name: replica # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5434
dst_port: pgbouncer
check_url: /read-only # read-only health check. (including primary)
selector: "[]" # select all instance as replica service candidate
selector_backup: "[? pg_role == `primary`]" # primary are used as backup server in replica service
# default service will route {ip|name}:5436 to primary postgres (5436->5432 primary)
- name: default # service's actual name is {{ pg_cluster }}-{{ service.name }}
src_ip: "*" # service bind ip address, * for all, vip for cluster virtual ip address
src_port: 5436 # bind port, mandatory
dst_port: postgres # target port: postgres|pgbouncer|port_number , pgbouncer(6432) by default
check_method: http # health check method: only http is available for now
check_port: patroni # health check port: patroni|pg_exporter|port_number , patroni by default
check_url: /primary # health check url path, / as default
check_code: 200 # health check http code, 200 as default
selector: "[]" # instance selector
haproxy: # haproxy specific fields
maxconn: 3000 # default front-end connection
balance: roundrobin # load balance algorithm (roundrobin by default)
default_server_options: 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
# offline service will route {ip|name}:5438 to offline postgres (5438->5432 offline)
- name: offline # service name {{ pg_cluster }}_replica
src_ip: "*"
src_port: 5438
dst_port: postgres
check_url: /replica # offline MUST be a replica
selector: "[? pg_role == `offline` || pg_offline_query ]" # instances with pg_role == 'offline' or instance marked with 'pg_offline_query == true'
selector_backup: "[? pg_role == `replica` && !pg_offline_query]" # replica are used as backup server in offline service
必选项目
-
名称(service.name):
服务名称,服务的完整名称以数据库集群名为前缀,以service.name为后缀,通过-连接。例如在pg-test集群中name=primary的服务,其完整服务名称为pg-test-primary。
-
端口(service.port):
在Pigsty中,服务默认采用NodePort的形式对外暴露,因此暴露端口为必选项。但如果使用外部负载均衡服务接入方案,您也可以通过其他的方式区分服务。
-
选择器(service.selector):
选择器指定了服务的实例成员,采用JMESPath的形式,从所有集群实例成员中筛选变量。默认的[]选择器会选取所有的集群成员。
可选项目
-
备份选择器(service.selector):
可选的 备份选择器service.selector_backup会选择或标记用于服务备份的实例列表,即集群中所有其他成员失效时,备份实例才接管服务。例如可以将primary实例加入replica服务的备选集中,当所有从库失效后主库依然可以承载集群的只读流量。
-
源端IP(service.src_ip) :
表示服务对外使用的IP地址,默认为*,即本机所有IP地址。使用vip则会使用vip_address变量取值,或者也可以填入网卡支持的特定IP地址。
-
宿端口(service.dst_port):
服务的流量将指向目标实例上的哪个端口?postgres 会指向数据库监听的端口,pgbouncer会指向连接池所监听的端口,也可以填入固定的端口号。
-
健康检查方式(service.check_method):
服务如何检查实例的健康状态?目前仅支持HTTP
-
健康检查端口(service.check_port):
服务检查实例的哪个端口获取实例的健康状态? patroni会从Patroni(默认8008)获取,pg_exporter会从PG Exporter(默认9630)获取,用户也可以填入自定义的端口号。
-
健康检查路径(service.check_url):
服务执行HTTP检查时,使用的URL PATH。默认会使用/作为健康检查,PG Exporter与Patroni提供了多样的健康检查方式,可以用于主从流量区分。例如,/primary仅会对主库返回成功,/replica仅会对从库返回成功。/read-only则会对任何支持只读的实例(包括主库)返回成功。
-
健康检查代码(service.check_code):
HTTP健康检查所期待的代码,默认为200
-
Haproxy特定配置(service.haproxy) :
关于服务供应软件(HAproxy)的专有配置项
3 - 高可用
介绍可用性的概念,以及Pigsty在高可用上的实践
Pigsty创建的数据库集群是分布式、高可用的数据库集群。
从效果上讲,只要集群中有任意实例存活,集群就可以对外提供完整的读写服务与只读服务。
数据库集群中的每个数据库实例在使用上都是幂等的,任意实例都可以通过内建负载均衡组件提供完整的读写服务。
数据库集群可以自动进行故障检测与主从切换,普通故障能在几秒到几十秒内自愈,且期间只读流量不受影响。
高可用
两个核心场景:Switchover,Failover
四个核心问题:故障检测,Fencing,选主,流量切换
关于高可用的核心场景演练,请参考 高可用演练 一节。
基于Patroni的高可用方案
基于 Patroni 的高可用方案部署简单,不需要使用特殊硬件,具有大量实际生产使用案例背书。
Pigsty的高可用方案基于Patroni,vip-manager,haproxy
Patroni基于DCS(etcd/consul/zookeeper)达成选主共识。
Patroni的故障检测采用心跳包保活,DCS租约机制实现。主库持有租约,秦失其鹿,则天下共逐之。
Patroni的Fencing基于Linux内核模块watchdog。
Patroni提供了主从健康检查,便于与外部负载均衡器相集成。
基于Haproxy与VIP的接入层方案
Pigsty沙箱默认使用基于L2 VIP与Haproxy的接入层方案。Pigsty提供多种可选的 数据库接入 方式。
Haproxy幂等地部署在集群的每个实例上,任何一个或多个Haproxy实例都可以作为集群的负载均衡器。
Haproxy采用类似Node Port的方式对外暴露服务,默认情况下,5433端口提供集群的读写服务,而5434端口提供集群的只读服务。
Haproxy本身的高可用性可通过以下几种方式达成:
- 使用智能客户端,利用Consul提供的DNS或服务发现机制连接至数据库。
- 使用智能客户端,利用Multi-Host特性填入集群中的所有实例。
- 使用绑定在Haproxy前的VIP(2层或4层)
- 使用外部负载均衡器保证
- 使用DNS轮询解析至多个Haproxy,客户端会在建连失败后重新执行DNS解析并重试。
Patroni在故障时的行为表现
| 场景 |
位置 |
Patroni的动作 |
| PG Down |
replica |
尝试重新拉起PG |
| Patroni Down |
replica |
PG随之关闭(维护模式下不变) |
| Patroni Crash |
replica |
PG不会随Patroni一并关闭 |
| DCS Network Partition |
replica |
无事 |
| Promote |
replica |
将PG降为从库并重新挂至主库。 |
| PG Down |
primary |
尝试重启PG
超过master_start_timeout后执行Failover |
| Patroni Down |
primary |
关闭PG并触发Failover |
| Patroni Crash |
primary |
触发Failover,可能触发脑裂。
可通过watchdog fencing避免。 |
| DCS Network Partition |
primary |
主库降级为从库,触发Failover |
| DCS Down |
DCS |
主库降级为从库,集群中没有主库,不可写入。 |
| 同步模式下无可用备选 |
|
临时切换为异步复制。
恢复为同步复制前不会Failover |
合理配置Patroni可以应对绝大多数故障。不过DCS Down这种场景(Consul/Etcd宕机或网络不可达)会导致所有生产数据库集群不可写入,需要特别关注。必须确保DCS的可用性高于数据库的可用性。
Known Issue
请尽量确保服务器的时间同步服务先于Patroni启动。
4 - 目录结构
介绍Pigsty默认设置的目录结构
以下参数与Pigsty目录结构相关
概览
#------------------------------------------------------------------------------
# Create Directory
#------------------------------------------------------------------------------
# this assumes that
# /pg is shortcut for postgres home
# {{ pg_fs_main }} contains the main data (MUST ALREADY MOUNTED)
# {{ pg_fs_bkup }} contains archive and backup data (MUST ALREADY MOUNTED)
# cluster-version is the default parent folder for pgdata (e.g pg-test-12)
#------------------------------------------------------------------------------
# default variable:
# pg_fs_main = /export fast ssd
# pg_fs_bkup = /var/backups cheap hdd
#
# /pg -> /export/postgres/pg-test-12
# /pg/data -> /export/postgres/pg-test-12/data
#------------------------------------------------------------------------------
- name: Create postgresql directories
tags: pg_dir
become: yes
block:
- name: Make sure main and backup dir exists
file: path={{ item }} state=directory owner=root mode=0777
with_items:
- "{{ pg_fs_main }}"
- "{{ pg_fs_bkup }}"
# pg_cluster_dir: "{{ pg_fs_main }}/postgres/{{ pg_cluster }}-{{ pg_version }}"
- name: Create postgres directory structure
file: path={{ item }} state=directory owner={{ pg_dbsu }} group=postgres mode=0700
with_items:
- "{{ pg_fs_main }}/postgres"
- "{{ pg_cluster_dir }}"
- "{{ pg_cluster_dir }}/bin"
- "{{ pg_cluster_dir }}/log"
- "{{ pg_cluster_dir }}/tmp"
- "{{ pg_cluster_dir }}/conf"
- "{{ pg_cluster_dir }}/data"
- "{{ pg_cluster_dir }}/meta"
- "{{ pg_cluster_dir }}/stat"
- "{{ pg_cluster_dir }}/change"
- "{{ pg_backup_dir }}/postgres"
- "{{ pg_backup_dir }}/arcwal"
- "{{ pg_backup_dir }}/backup"
- "{{ pg_backup_dir }}/remote"
PG二进制目录结构
在RedHat/CentOS上,默认的Postgres发行版安装位置为
/usr/pgsql-${pg_version}/
安装剧本会自动创建指向当前安装版本的软连接,例如,如果安装了13版本的Postgres,则有:
/usr/pgsql -> /usr/pgsql-13
因此,默认的pg_bin_dir为/usr/pgsql/bin/,该路径会在/etc/profile.d/pgsql.sh中添加至所有用户的PATH环境变量中。
PG数据目录结构
Pigsty假设用于部署数据库实例的单个节点上至少有一块主数据盘(pg_fs_main),以及一块可选的备份数据盘(pg_fs_bkup)。通常主数据盘是高性能SSD,而备份盘是大容量廉价HDD。
#------------------------------------------------------------------------------
# Create Directory
#------------------------------------------------------------------------------
# this assumes that
# /pg is shortcut for postgres home
# {{ pg_fs_main }} contains the main data (MUST ALREADY MOUNTED)
# {{ pg_fs_bkup }} contains archive and backup data (MAYBE ALREADY MOUNTED)
# {{ pg_cluster }}-{{ pg_version }} is the default parent folder
# for pgdata (e.g pg-test-12)
#------------------------------------------------------------------------------
# default variable:
# pg_fs_main = /export fast ssd
# pg_fs_bkup = /var/backups cheap hdd
#
# /pg -> /export/postgres/pg-test-12
# /pg/data -> /export/postgres/pg-test-12/data
PG数据库集簇目录结构
# basic
{{ pg_fs_main }} /export # contains all business data (pg,consul,etc..)
{{ pg_dir_main }} /export/postgres # contains postgres main data
{{ pg_cluster_dir }} /export/postgres/pg-test-13 # contains cluster `pg-test` data (of version 13)
/export/postgres/pg-test-13/bin # binary scripts
/export/postgres/pg-test-13/log # misc logs
/export/postgres/pg-test-13/tmp # tmp, sql files, records
/export/postgres/pg-test-13/conf # configurations
/export/postgres/pg-test-13/data # main data directory
/export/postgres/pg-test-13/meta # identity information
/export/postgres/pg-test-13/stat # stats information
/export/postgres/pg-test-13/change # changing records
{{ pg_fs_bkup }} /var/backups # contains all backup data (pg,consul,etc..)
{{ pg_dir_bkup }} /var/backups/postgres # contains postgres backup data
{{ pg_backup_dir }} /var/backups/postgres/pg-test-13 # contains cluster `pg-test` backup (of version 13)
/var/backups/postgres/pg-test-13/backup # base backup
/var/backups/postgres/pg-test-13/arcwal # WAL archive
/var/backups/postgres/pg-test-13/remote # mount NFS/S3 remote resources here
# links
/pg -> /export/postgres/pg-test-12 # pg root link
/pg/data -> /export/postgres/pg-test-12/data # real data dir
/pg/backup -> /var/backups/postgres/pg-test-13/backup # base backup
/pg/arcwal -> /var/backups/postgres/pg-test-13/arcwal # WAL archive
/pg/remote -> /var/backups/postgres/pg-test-13/remote # mount NFS/S3 remote resources here
Pgbouncer配置文件结构
Pgbouncer使用Postgres用户运行,配置文件位于/etc/pgbouncer。配置文件包括:
pgbouncer.ini,主配置文件userlist.txt:列出连接池中的用户pgb_hba.conf:列出连接池用户的访问权限database.txt:列出连接池中的数据库
5 - 访问控制
介绍Pigsty中的访问控制模型
PostgreSQL提供了两类访问控制机制:认证(Authentication) 与 权限(Privileges)
Pigsty带有基本的访问控制模型,足以覆盖绝大多数应用场景。
用户体系
Pigsty的默认权限系统包含四个默认用户与四类默认角色 。
用户可以通过修改 pg_default_roles 来修改默认用户的名字,但默认角色的名字不建议新用户自行修改。
默认角色
Pigsty带有四个默认角色:
- 只读角色(
dbrole_readonly):只读
- 读写角色(
dbrole_readwrite):读写,继承dbrole_readonly
- 管理角色(
dbrole_admin):�执行DDL变更,继承dbrole_readwrite
- 离线角色(
dbrole_offline):只读,用于执行慢查询/ETL/交互查询,仅允许在特定实例上访问。
默认用户
Pigsty带有四个默认用户:
- 超级用户(
postgres),数据库的拥有者与创建者,与操作系统用户一致
- 复制用户(
replicator),用于主从复制的用户。
- 监控用户(
dbuser_monitor),用于监控数据库指标的用户。
- 管理员(
dbuser_admin),执行日常管理操作与数据库变更。(通常供DBA使用)
| name |
attr |
roles |
desc |
| dbrole_readonly |
Cannot login |
|
role for global readonly access |
| dbrole_readwrite |
Cannot login |
dbrole_readonly |
role for global read-write access |
| dbrole_offline |
Cannot login |
|
role for restricted read-only access (offline instance) |
| dbrole_admin |
Cannot login
Bypass RLS |
pg_monitor
pg_signal_backend
dbrole_readwrite |
role for object creation |
| postgres |
Superuser
Create role
Create DB
Replication
Bypass RLS |
|
system superuser |
| replicator |
Replication
Bypass RLS |
pg_monitor
dbrole_readonly |
system replicator |
| dbuser_monitor |
16 connections |
pg_monitor
dbrole_readonly |
system monitor user |
| dbuser_admin |
Bypass RLS
Superuser |
dbrole_admin |
system admin user |
相关配置
以下是8个默认用户/角色的相关变量
默认用户有专用的用户名与密码配置选项,会覆盖 pg_default_roles中的选项。因此无需在其中为默认用户配置密码。
出于安全考虑,不建议为DBSU配置密码,故pg_dbsu没有专门的密码配置项。如有需要,用户可以在pg_default_roles中为超级用户指定密码。
# - system roles - #
pg_replication_username: replicator # system replication user
pg_replication_password: DBUser.Replicator # system replication password
pg_monitor_username: dbuser_monitor # system monitor user
pg_monitor_password: DBUser.Monitor # system monitor password
pg_admin_username: dbuser_admin # system admin user
pg_admin_password: DBUser.Admin # system admin password
# - default roles - #
# chekc http://pigsty.cc/zh/docs/concepts/provision/acl/ for more detail
pg_default_roles:
# common production readonly user
- name: dbrole_readonly # production read-only roles
login: false
comment: role for global readonly access
# common production read-write user
- name: dbrole_readwrite # production read-write roles
login: false
roles: [dbrole_readonly] # read-write includes read-only access
comment: role for global read-write access
# offline have same privileges as readonly, but with limited hba access on offline instance only
# for the purpose of running slow queries, interactive queries and perform ETL tasks
- name: dbrole_offline
login: false
comment: role for restricted read-only access (offline instance)
# admin have the privileges to issue DDL changes
- name: dbrole_admin
login: false
bypassrls: true
comment: role for object creation
roles: [dbrole_readwrite,pg_monitor,pg_signal_backend]
# dbsu, name is designated by `pg_dbsu`. It's not recommend to set password for dbsu
- name: postgres
superuser: true
comment: system superuser
# default replication user, name is designated by `pg_replication_username`, and password is set by `pg_replication_password`
- name: replicator
replication: true
roles: [pg_monitor, dbrole_readonly]
comment: system replicator
# default replication user, name is designated by `pg_monitor_username`, and password is set by `pg_monitor_password`
- name: dbuser_monitor
connlimit: 16
comment: system monitor user
roles: [pg_monitor, dbrole_readonly]
# default admin user, name is designated by `pg_admin_username`, and password is set by `pg_admin_password`
- name: dbuser_admin
bypassrls: true
comment: system admin user
roles: [dbrole_admin]
# default stats user, for ETL and slow queries
- name: dbuser_stats
password: DBUser.Stats
comment: business offline user for offline queries and ETL
roles: [dbrole_offline]
Pgbouncer用户
Pgbouncer的操作系统用户将与数据库超级用户保持一致,默认都使用postgres。
Pigsty默认会使用Postgres管理用户作为Pgbouncer的管理用户,使用Postgres的监控用户同时作为Pgbouncer的监控用户。
Pgbouncer的用户权限通过/etc/pgbouncer/pgb_hba.conf进行控制。
Pgbounce的用户列表通过/etc/pgbouncer/userlist.txt文件进行控制。
定义用户时,只有显式添加pgbouncer: true 的用户,才会被加入到Pgbouncer的用户列表中。
用户的定义
Pigsty中的用户可以通过以下两个参数进行声明,两者使用同样的形式:
用户的创建
Pigsty的用户可以通过 pgsql-createuser.yml 剧本完成创建
权限模型
默认情况下,角色拥有的权限如下所示:
GRANT USAGE ON SCHEMAS TO dbrole_readonly
GRANT SELECT ON TABLES TO dbrole_readonly
GRANT SELECT ON SEQUENCES TO dbrole_readonly
GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly
GRANT USAGE ON SCHEMAS TO dbrole_offline
GRANT SELECT ON TABLES TO dbrole_offline
GRANT SELECT ON SEQUENCES TO dbrole_offline
GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly
GRANT INSERT, UPDATE, DELETE ON TABLES TO dbrole_readwrite
GRANT USAGE, UPDATE ON SEQUENCES TO dbrole_readwrite
GRANT TRUNCATE, REFERENCES, TRIGGER ON TABLES TO dbrole_admin
GRANT CREATE ON SCHEMAS TO dbrole_admin
GRANT USAGE ON TYPES TO dbrole_admin
其他业务用户默认都应当属于四种默认角色之一:只读,读写,管理员,离线访问。
| Owner |
Schema |
Type |
Access privileges |
| username |
|
function |
=X/postgres |
|
|
|
postgres=X/postgres |
|
|
|
dbrole_readonly=X/postgres |
|
|
|
dbrole_offline=X/postgres |
| username |
|
schema |
postgres=UC/postgres |
|
|
|
dbrole_readonly=U/postgres |
|
|
|
dbrole_offline=U/postgres |
|
|
|
dbrole_admin=C/postgres |
| username |
|
sequence |
postgres=rwU/postgres |
|
|
|
dbrole_readonly=r/postgres |
|
|
|
dbrole_readwrite=wU/postgres |
|
|
|
dbrole_offline=r/postgres |
| username |
|
table |
postgres=arwdDxt/postgres |
|
|
|
dbrole_readonly=r/postgres |
|
|
|
dbrole_readwrite=awd/postgres |
|
|
|
dbrole_offline=r/postgres |
|
|
|
dbrole_admin=Dxt/postgres |
所有用户都可以访问所有模式,只读用户可以读取所有表,读写用户可以对所有表进行DML操作,管理员可以执行DDL变更操作。离线用户与只读用户类似,但只允许访问pg_role == 'offline' 或带有 pg_offline_query = true 的实例。
数据库权限
数据库有三种权限:CONNECT, CREATE, TEMP,以及特殊的属主OWNERSHIP。数据库的定义由参数 pg_database 控制。一个完整的数据库定义如下所示:
pg_databases:
- name: meta # name is the only required field for a database
owner: postgres # optional, database owner
template: template1 # optional, template1 by default
encoding: UTF8 # optional, UTF8 by default
locale: C # optional, C by default
allowconn: true # optional, true by default, false disable connect at all
revokeconn: false # optional, false by default, true revoke connect from public # (only default user and owner have connect privilege on database)
tablespace: pg_default # optional, 'pg_default' is the default tablespace
connlimit: -1 # optional, connection limit, -1 or none disable limit (default)
extensions: # optional, extension name and where to create
- {name: postgis, schema: public}
parameters: # optional, extra parameters with ALTER DATABASE
enable_partitionwise_join: true
pgbouncer: true # optional, add this database to pgbouncer list? true by default
comment: pigsty meta database # optional, comment string for database
默认情况下,如果数据库没有配置属主,那么数据库超级用户dbsu将会作为数据库的默认OWNER,否则将为指定用户。
默认情况下,所有用户都具有对新创建数据库的CONNECT 权限,如果希望回收该权限,设置 revokeconn == true,则该权限会被回收。只有默认用户(dbsu|admin|monitor|replicator)与数据库的属主才会被显式赋予CONNECT权限。同时,admin|owner将会具有CONNECT权限的GRANT OPTION,可以将CONNECT权限转授他人。
如果希望实现不同数据库之间的访问隔离,可以为每一个数据库创建一个相应的业务用户作为owner,并全部设置revokeconn选项。这种配置对于多租户实例尤为实用。
创建新对象
默认情况下,出于安全考虑,Pigsty会撤销PUBLIC用户在数据库下CREATE新模式的权限,同时也会撤销PUBLIC用户在public模式下创建新关系的权限。数据库超级用户与管理员不受此限制,他们总是可以在任何地方执行DDL变更。
Pigsty非常不建议使用业务用户执行DDL变更,因为PostgreSQL的ALTER DEFAULT PRIVILEGE仅针对“由特定用户创建的对象”生效,默认情况下超级用户postgres和dbuser_admin创建的对象拥有默认的权限配置,如果用户希望授予业务用户dbrole_admin,请在使用该业务管理员执行DDL变更时首先执行:
SET ROLE dbrole_admin; -- dbrole_admin 创建的对象具有正确的默认权限
在数据库中创建对象的权限与用户是否为数据库属主无关,这只取决于创建该用户时是否为该用户赋予管理员权限。
pg_users:
- {name: test1, password: xxx , groups: [dbrole_readwrite]} # 不能创建Schema与对象
- {name: test2, password: xxx , groups: [dbrole_admin]} # 可以创建Schema与对象
认证模型
HBA是Host Based Authentication的缩写,可以将其视作IP黑白名单。
HBA配置方式
在Pigsty中,所有实例的HBA都由配置文件生成而来,最终生成的HBA规则取决于实例的角色(pg_role)
Pigsty的HBA由下列变量控制:
pg_hba_rules: 环境统一的HBA规则pg_hba_rules_extra: 特定于实例或集群的HBA规则pgbouncer_hba_rules: 链接池使用的HBA规则pgbouncer_hba_rules_extra: 特定于实例或集群的链接池HBA规则
每个变量都是由下列样式的规则组成的数组:
- title: allow intranet admin password access
role: common
rules:
- host all +dbrole_admin 10.0.0.0/8 md5
- host all +dbrole_admin 172.16.0.0/12 md5
- host all +dbrole_admin 192.168.0.0/16 md5
基于角色的HBA
role = common的HBA规则组会安装到所有的实例上,而其他的取值,例如(role : primary)则只会安装至pg_role = primary的实例上。因此用户可以通过角色体系定义灵活的HBA规则。
作为一个特例,role: offline 的HBA规则,除了会安装至pg_role == 'offline'的实例,也会安装至pg_offline_query == true的实例上。
默认配置
在默认配置下,主库与从库会使用以下的HBA规则:
- 超级用户通过本地操作系统认证访问
- 其他用户可以从本地用密码访问
- 复制用户可以从局域网段通过密码访问
- 监控用户可以通过本地访问
- 所有人都可以在元节点上使用密码访问
- 管理员可以从局域网通过密码访问
- 所有人都可以从内网通过密码访问
- 读写用户(生产业务账号)可以通过本地(链接池)访问
(部分访问控制转交链接池处理)
- 在从库上:只读用户(个人)可以从本地(链接池)访问。
(意味主库上拒绝只读用户连接)
pg_role == 'offline' 或带有pg_offline_query == true的实例上,会添加允许dbrole_offline分组用户访问的HBA规则。
#==============================================================#
# Default HBA
#==============================================================#
# allow local su with ident"
local all postgres ident
local replication postgres ident
# allow local user password access
local all all md5
# allow local/intranet replication with password
local replication replicator md5
host replication replicator 127.0.0.1/32 md5
host all replicator 10.0.0.0/8 md5
host all replicator 172.16.0.0/12 md5
host all replicator 192.168.0.0/16 md5
host replication replicator 10.0.0.0/8 md5
host replication replicator 172.16.0.0/12 md5
host replication replicator 192.168.0.0/16 md5
# allow local role monitor with password
local all dbuser_monitor md5
host all dbuser_monitor 127.0.0.1/32 md5
#==============================================================#
# Extra HBA
#==============================================================#
# add extra hba rules here
#==============================================================#
# primary HBA
#==============================================================#
#==============================================================#
# special HBA for instance marked with 'pg_offline_query = true'
#==============================================================#
#==============================================================#
# Common HBA
#==============================================================#
# allow meta node password access
host all all 10.10.10.10/32 md5
# allow intranet admin password access
host all +dbrole_admin 10.0.0.0/8 md5
host all +dbrole_admin 172.16.0.0/12 md5
host all +dbrole_admin 192.168.0.0/16 md5
# allow intranet password access
host all all 10.0.0.0/8 md5
host all all 172.16.0.0/12 md5
host all all 192.168.0.0/16 md5
# allow local read/write (local production user via pgbouncer)
local all +dbrole_readonly md5
host all +dbrole_readonly 127.0.0.1/32 md5
#==============================================================#
# Ad Hoc HBA
#===========================================================