概念
在使用Pigsty时需要了解的一些信息
Pigsty在逻辑上由两部分组成:监控系统 与 供给方案
Pigsty监控系统负责监控PostgreSQL数据库集群,Pigsty供给方案负责创建PostgreSQL数据库集群。
Pigsty的监控系统与供给方案可以独立使用,例如,用户可以在不使用Pigsty供给方案的情况下,使用Pigsty监控系统监控已有的其他PostgreSQL数据库集群,譬如阿里云的MyBase for PostgreSQL所托管的PostgreSQL,但这样做需要对Pigsty的模型有较深的理解,建议初学者使用Pigsty沙箱 进行探索与实验。下面的介绍都将基于Pigsty沙箱进行。
监控系统
You can’t manage what you don’t measure.
监控系统提供了对系统状态的度量,是运维管理工作的基石。Pigsty提供最好的开源PostgreSQL监控系统。
Pigsty的监控系统在物理上分为两个部分:
- 服务端:部署于元节点上,包括时序数据库Prometheus,监控仪表盘Grafana,报警管理Altermanager,服务发现Consul等服务。
- 客户端:部署于数据库节点上,包括NodeExporter, PgExporter, Haproxy。被动接受Prometheus拉取,上。
Pigsty监控系统的核心概念如下:
- 命名规则与监控层级
- 身份管理与服务发现
- 可观测性与指标采集
- 指标聚合与报警规则
- 视觉呈现与监控面板
供给方案
授人以鱼,不如授人以渔
供给方案(Provisioning Solution),指的是向用户交付数据库服务与监控系统的系统。供给方案不是数据库,而是数据库工厂,用户向供给系统提交一份配置,供给系统便会按照用户所需的规格在环境中创建出所需的数据库集群来,这类似于通过向Kubernetes提交YAML文件来创建系统所需的各类资源。
Pigsty的供给方案在部署上分为两个部分:
- 基础设施(Infra) :部署于元节点上,包括上述监控组件,以及DNS,NTP,DCS,本地源等关键服务。
- 数据库集群(PgSQL):部署于数据库节点上,以集群为单位对外提供业务服务。
Pigsty的供给方案的部署对象分为两种:
- 元节点(Meta):部署基础设施,监控系统,执行控制逻辑,每个Pigsty部署至少需要一个元节点,可复用为普通节点。
- 普通节点(Node):用于部署数据库集群/实例,Pigsty采用节点与数据库实例一一对应的独占式部署。
Pigsty供给方案的相关概念如下:
- 基础设施
- 数据库集群
- 元节点
- 普通节点
- 系统架构
- 沙箱环境
- 高可用
- 代码定义的基础设施
- 访问控制模型
- 文件目录结构
- Ansible
1 - 系统模型
介绍Pigsty的系统模型
Pigsty在逻辑上由两部分组成:监控系统 与 供给方案
基础设施(Infra) 与 数据库集群(PgSQL)。每一套 Pigsty 部署(Deployment),都包含有一套基础设施,与多套数据库集群。
Pigsty需要部署在机器节点上,节点分为两类:元节点(Meta Node) 用于部署基础设施,普通节点 用于部署数据库集群。元节点也可以复用为普通节点,用于数据库部署。
下图以Pigsty自带沙箱环境为例,介绍Pigsty的系统模型。
基础设施
Pigsty包含有生产环境数据库管理与使用所需的完整基础设施组件,包括:
- Nginx:Pigsty Web界面入口,服务代理,本地Yum源服务器
- Consul:高可用依赖的DCS服务,服务发现,DNS
- Grafana:监控系统,可视化仪表盘
- Prometheus:监控组件,时序指标收集与存储
- Altermanager:报警组件
- NTP Server:时间服务器
- DNS Server:域名解析服务器
- CA:公私钥基础设施。
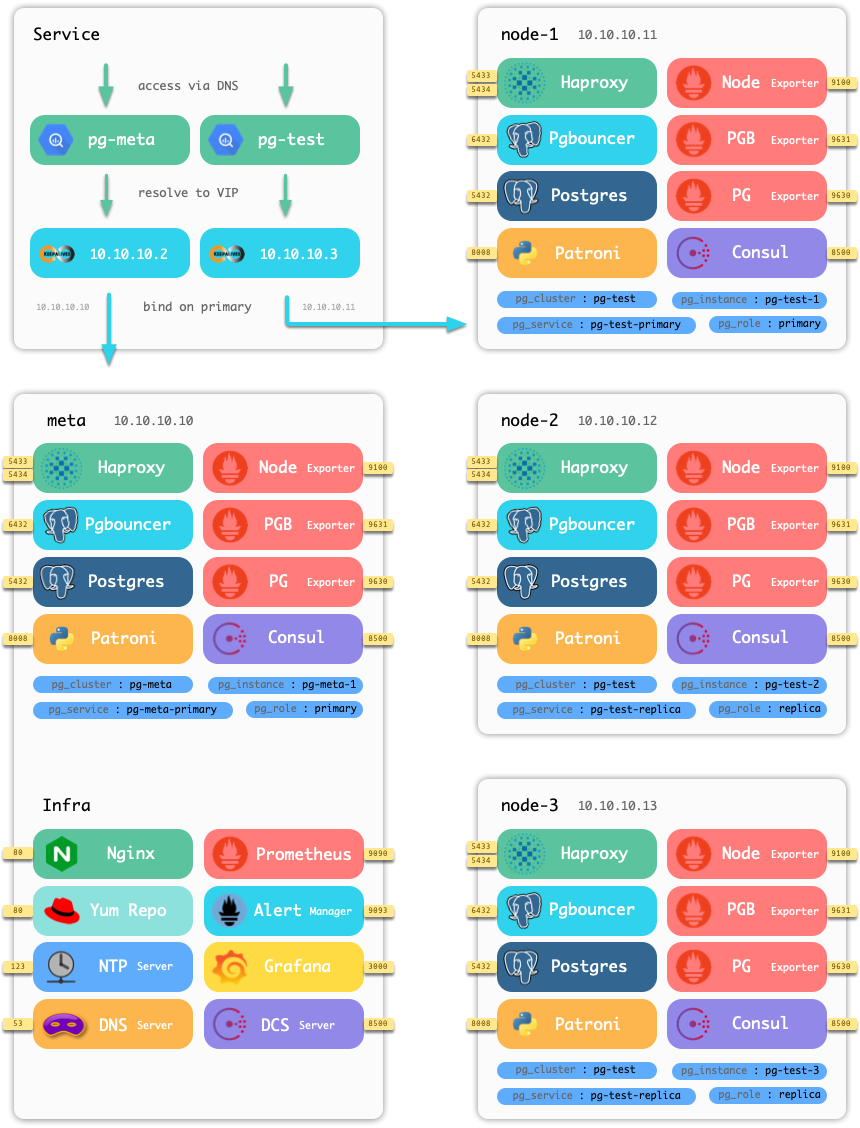
除DCS外,基础设施默认以幂等的方式部署在一个或多个元节点上。
元节点(Meta Node) 是Pigsty中的特殊机器,用于发起管理,执行控制,部署监控。
数据库集群
Pigsty是数据库供给方案,可以按需创建高可用数据库集群。
每个“数据库实例”在使用上是幂等的,采用类似NodePort的方式对外暴露服务。默认情况下,访问任意实例的5433端口即可访问主库,访问任意实例的5434端口即可访问从库。用户也可以灵活地同时使用不同的方式访问数据库。
每个数据库集群是一个自组织的业务服务单元,由至少一个数据库实例组成。
Pigsty创建的数据库集群是分布式、高可用的数据库集群。只要集群中有任意实例存活,集群就可以对外提供完整的读写服务与只读服务。
Pigsty可以自动进行故障切换,业务方只读流量不受影响;读写流量的影响视具体配置与负载,通常在几秒到几十秒的范围。
Pigsty通过声明式的配置定义数据库集群,通过幂等的Ansible Playbook根据配置创建数据库集群。
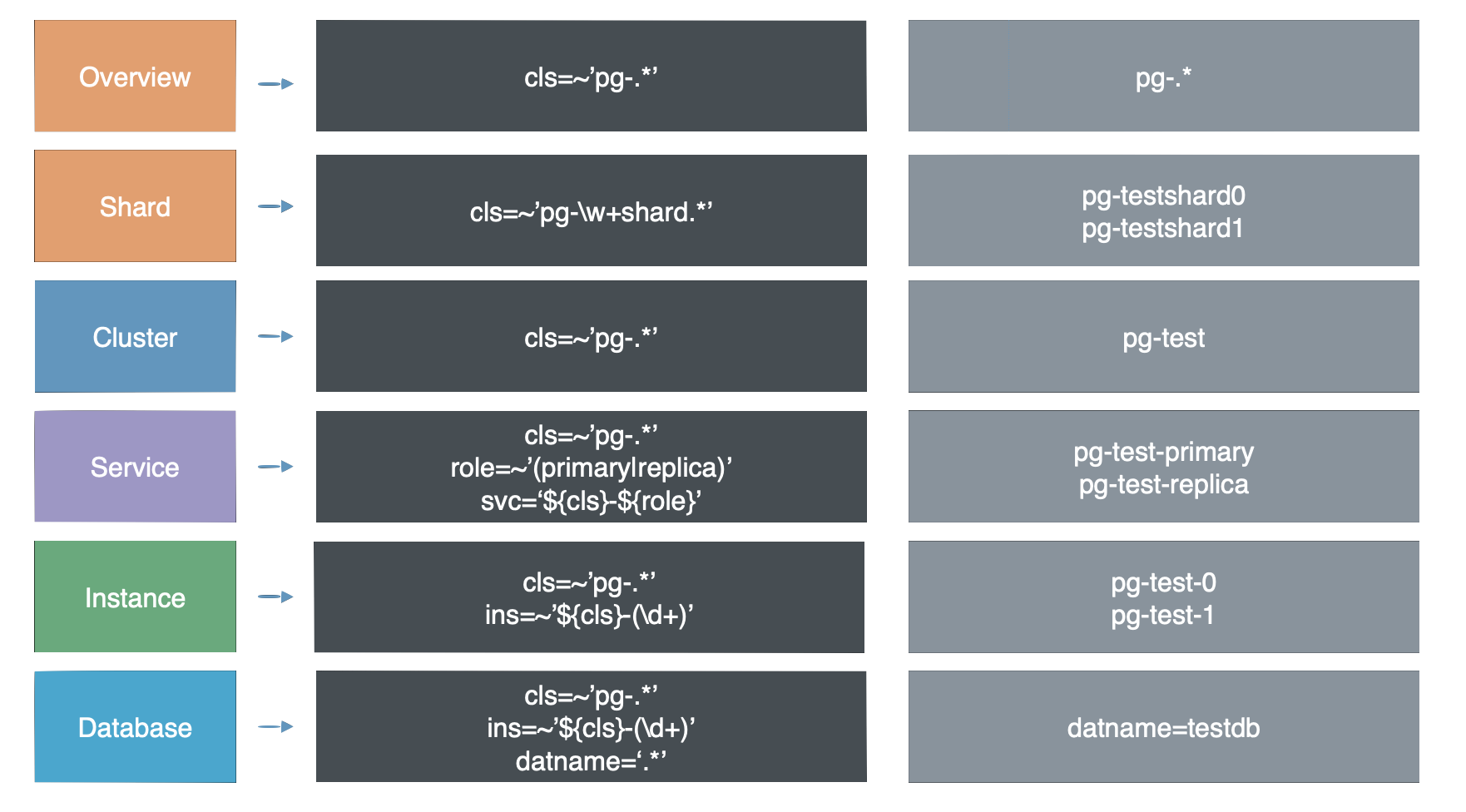
命名规则
生产环境的数据库往往是以集群为单位组织的。集群是一个由主从复制所关联的一组数据库实例所构成的,它是基本的业务服务单元。集群由多个实例组成,而多套数据库集群共同组成一个现实世界中的生产环境。
除了实例与集群这两个最为Trivial层次,整个系统中还有着其他层次的组织。自顶向下可以分为7个层级:概览,分片,集群,服务,实例,数据库,对象。
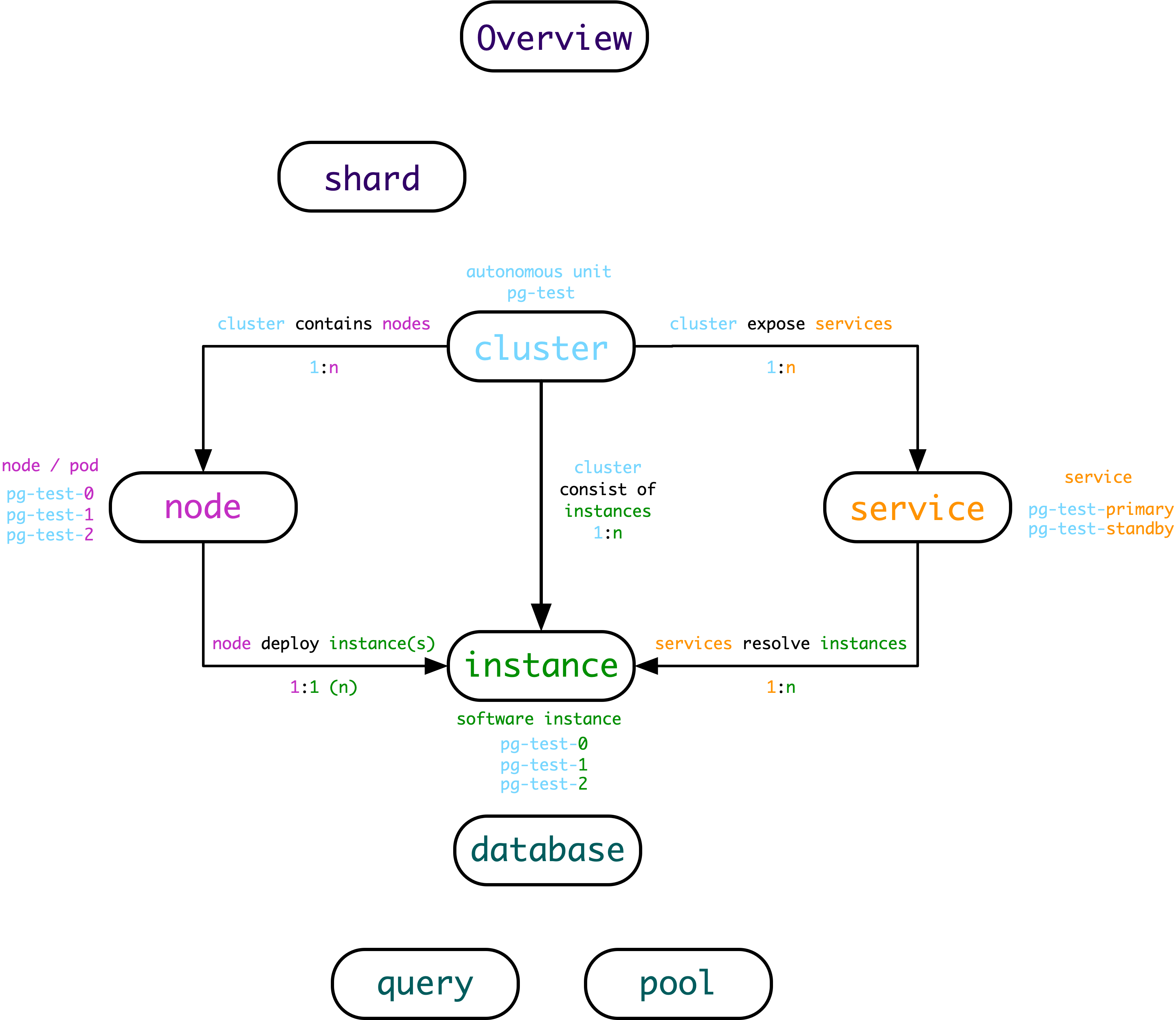
夹在集群与实例中间的层次—— Service。
在实例层级以下,还可以再分出两个层次来,分别是Database和Object。Object即亚数据库对象,包括:表、索引,函数,序列号,查询、连接池等。
从集群层次向上看,则会有两个更高的层次——Shard与Overview。
作为一种精简,正如网络的OSI 7层模型在实际中被简化为TCP/IP五层模型一样,这七个层次也以集群 和 实例为界,简化为五个层次:Overview,Cluster,Service,Instance,Database 。
这样,最终的层次划分也变得十分简洁:所有集群层次以上的信息,都是Overview层次,所有实例内部的信息都算Database层次,夹在两者中间的,就是Service层次。

命名问题
分完层次后,剩下的问题实际上就是命名问题,或者说身份管理的问题。
-
我们需要一种方式来标识、引用系统中不同层次内的各个组件,
-
这种命名方式,应当合理地反映出系统中各个实体的层次关系
-
这种命名方式,应当可以按照规则自动生成,只有这样,才可以在集群扩容缩容,Failover时做到免维护自动化运行,
当我们理清了系统中存在的层次后,就可以着手为系统中的每个实体起名。请参考下一节:命名规则
2 - 实际挑战
真实世界中的问题与挑战
聊完了可观测性的问题,接下来让我们说一说 生产环境集群的问题。比起玩具数据库,生产环境有着更严苛的要求与更复杂的问题。
很多开源或者商业监控系统,都没有很好的解决这些痛点、痒点、需求点。这也是我开发Pigsty的初衷 ,为了解决这些生产环境中的实际问题而开发的,
生产环境,比起本地测试,或者玩具数据库有什么区别呢? 总结了三个主要特点:多集群,多层次,多变更
多集群
第一个问题,多集群。而最实际等问题就是,生产环境的数据库往往都是以一个个的集群为单位组织起来的。
集群是什么,集群是一个由主从复制所关联的一组数据库实例所构成的,它是基本的业务服务单元。比如这里下图就展示了某一个业务集群pg-core-tt的复制拓扑,这里的9个实例共同组成一个集群。
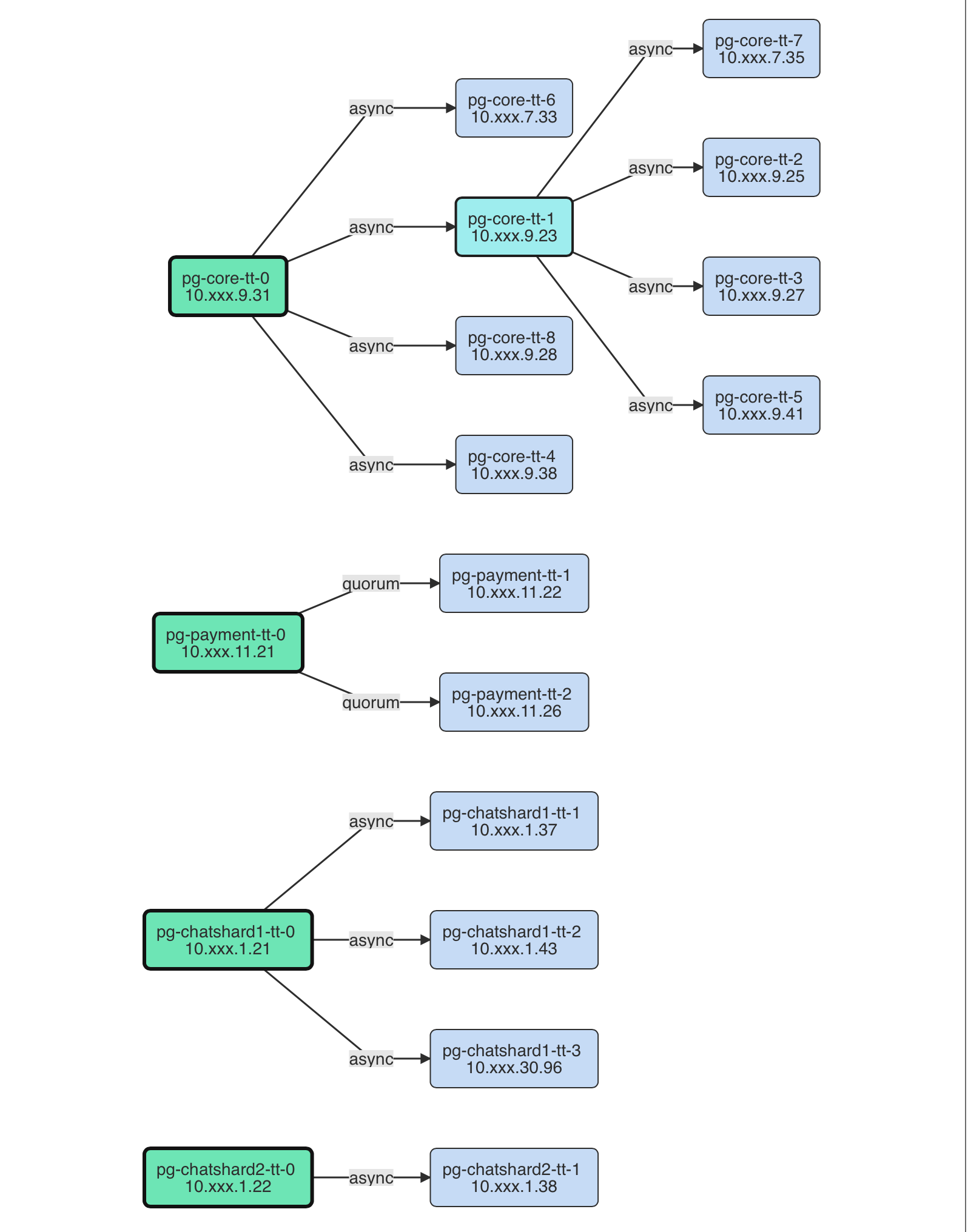
集群由多个实例组成,而多套数据库集群共同组成一个现实世界中的生产环境。很多监控系统往往只关注单个数据库实例的监控,那么问题就来了:如果我有一套数据库,那么部署一套监控系统是Fair Enough的。但如果我有一百套,一千套呢?用户不会说我真的会去部署一千套监控系统,而是希望有一套监控系统能直接把这一千套数据库监控起来。
多层次
生产环境的第二个特点是多层次,Hierarchy是计算机系统里永恒的话题。
但除了实例与集群这两个最为Trivial层次,整个系统中还有着其他层次的组织。这里概括一下自顶向下可以分为7个层级:概览,分片,集群,服务,实例,数据库,对象。
我们先来看夹在集群与实例中间的层次—— Service。
接下来,让我们先向下看,在实例层级以下,还可以再分出两个层次来,分别是DB和Object。
然后,我们从集群层次向上看,则会有两个更高的层次——Shard与Overview。
最后,就像网络的OSI 7层模型在实际中被简化为TCP/IP五层模型一样,这七个层次也以集群 和 实例为界,简化为五个层次:Overview,Cluster,Service,Instance,Database
而且定义也简单了很多,所有集群层次以上的信息,都是Overview,所有实例内部的信息都算Database,夹在两者中间的,就是Service。
多变更
生产环境的第三个特点,是多变更。世界上唯一不变的就是变化本身。
第三个特点,也是最后一个。是变动频繁,这里频繁也许要打个引号。但真实世界的生产数据库必然不会是一成不变的,无论是扩容,缩容,还是Failover或Switchover,都会引起集群状态的变化。
我们会有各式各样的变更:
- 集群故障切换,手工切换
- 增加/移除实例
- 增加/移除数据库
- 修改复制拓扑,级联复制,同步复制,延迟复制,日志传输复制
- 将数据库水平拆分为分片库
- 将物理机数据库迁移至Kubernetes
- ……
如果任何集群变动都需要手工维护监控系统,是很容易出错的,最好的系统就是不需要维护的系统。我们希望所有这些集群状态变化都能被自动感知,无需手工维护。
这就需要用到服务发现
小结
为了解决实际生产环境中面临的问题与挑战,我们首先要理清监控对象的 层次关系
3 - 命名规则
介绍Pigsty默认采用的实体命名规则
名之必可言也,言之必可行也。
概念及其命名是非常重要的东西,命名风格体现了工程师对系统架构的认知。定义不清的概念将导致沟通困惑,随意设定的名称将产生意想不到的额外负担。因此需要审慎地设计。
TL;DR
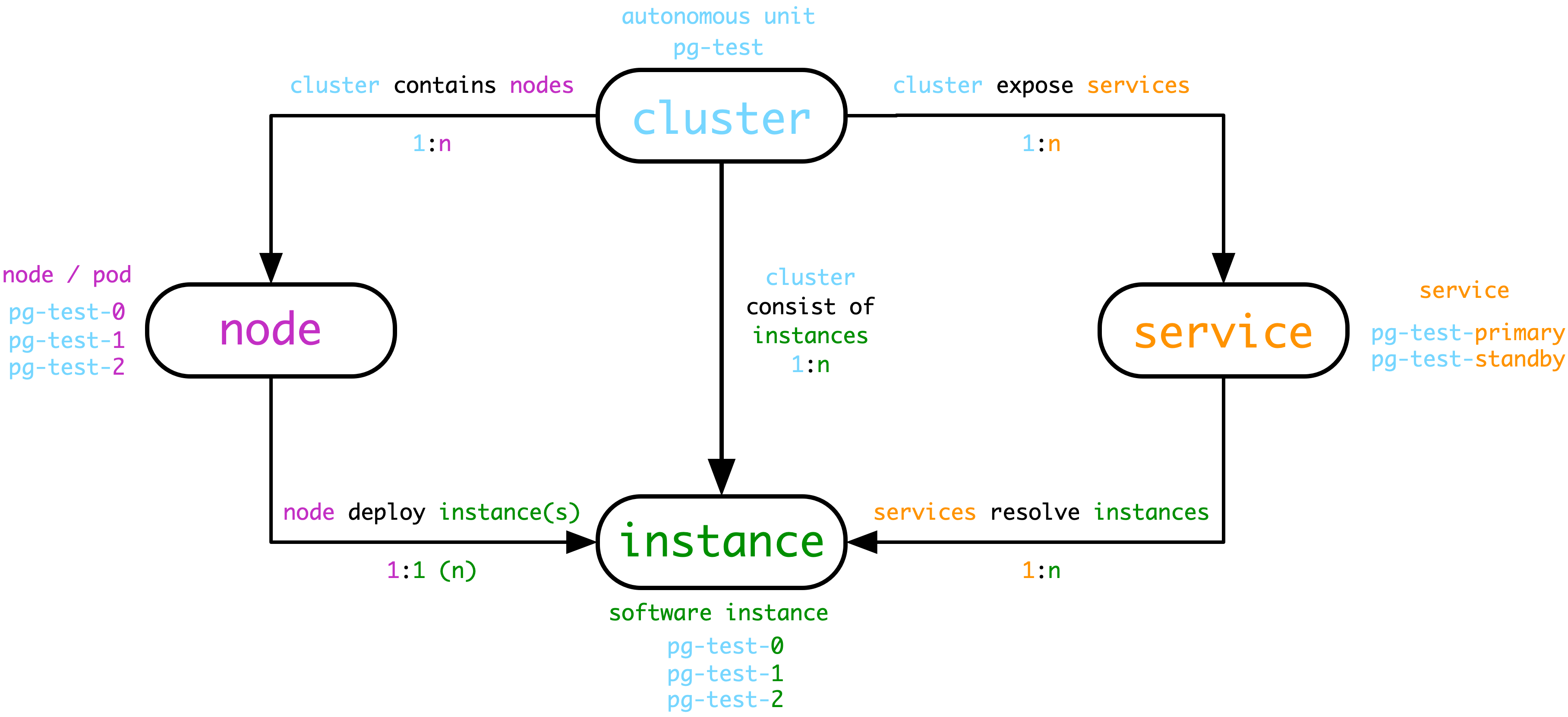
- 集群(Cluster) 是基本自治单元,由用户指定唯一标识,表达业务含义,作为顶层命名空间。
- 集群在硬件层面上包含一系列的节点(Node),即物理机,虚机(或Pod),可以通过IP唯一标识。
- 集群在软件层面上包含一系列的实例(Instance),即软件服务器,可以通过IP:Port唯一标识。
- 集群在服务层面上包含一系列的服务(Service),即可访问的域名与端点,可以通过域名唯一标识。
- Cluster命名可以使用任意满足DNS域名规范的名称,但不能带点([a-zA-Z0-9-]+)。
- Node/Pod命名采用Cluster名称前缀,后接
-连接一个从0开始分配的序号,(与k8s保持一致)
- 实例命名通常与Node保持一致,即
${cluster}-${seq}的方式,这种方式隐含着节点与实例1:1部署的假设。如果这个假设不成立,则可以采用独立于节点的序号,但保持同样的命名规则。
- Service命名采用Cluster名称前缀,后接
-连接服务具体内容,如primary, standby
以上图为例,用于测试的数据库集群名为“pg-test”,该集群由一主两从三个数据库服务器实例组成,部署在集群所属的三个节点上。pg-test集群集群对外提供两种服务,读写服务pg-test-primary与只读副本服务pg-test-standby。
集群管理基本概念
在Postgres集群管理中,有如下概念:
集群(Cluster)
集群是基本的自治业务单元,这意味着集群能够作为一个整体组织对外提供服务。类似于k8s中Deployment的概念。注意这里的集群是软件层面的概念,不要与PG Cluster(数据库集簇,即包含多个PG Database实例的单个PG Server Instance)或Node Cluster(机器集群)混淆。
集群是管理的基本单位之一,是用于统合各类资源的组织单位。例如一个PG集群可能包括:
- 三个物理机器节点
- 一个主库实例,对外提供数据库读写服务。
- 两个从库实例,对外提供数据库只读副本服务。
- 两个对外暴露的服务:读写服务,只读副本服务。
每个集群都有用户根据业务需求定义的唯一标识符,本例中定义了一个名为pg-test的数据库集群。
节点(Node)
节点是对硬件资源的一种抽象,通常指代一台工作机器,无论是物理机(bare metal)还是虚拟机(vm),或者是k8s中的Pod。这里注意k8s中Node是硬件资源的抽象,但在实际管理使用上,是k8s中的Pod而不是Node更类似于这里Node概念。总之,节点的关键要素是:
- 节点是硬件资源的抽象,可以运行一系列的软件服务
- 节点可以使用IP地址作为唯一标识符
尽管可以使用lan_ip地址作为节点唯一标识符,但为了便于管理,节点应当拥有一个人类可读的充满意义的名称作为节点的Hostname,作为另一个常用的节点唯一标识。
服务(Service)
服务是对软件服务(例如Postgres,Redis)的一种命名抽象(named abastraction)。服务可以有各种各样的实现,但其的关键要素在于:
- 可以寻址访问的服务名称,用于对外提供接入,例如:
- 一个DNS域名(
pg-test-primary)
- 一个Nginx/Haproxy Endpoint
- 服务流量路由解析与负载均衡机制,用于决定哪个实例负责处理请求,例如:
- DNS L7:DNS解析记录
- HTTP Proxy:Nginx/Ingress L7:Nginx Upstream配置
- TCP Proxy:Haproxy L4:Haproxy Backend配置
- Kubernetes:Ingress:Pod Selector 选择器。
同一个数据集簇中通常包括主库与从库,两者分别提供读写服务(primary)和只读副本服务(standby)。
实例(Instance)
实例指带一个具体的数据库服务器,它可以是单个进程,也可能是共享命运的一组进程,也可以是一个Pod中几个紧密关联的容器。实例的关键要素在于:
- 可以通过IP:Port唯一标识
- 具有处理请求的能力
例如,我们可以把一个Postgres进程,为之服务的独占Pgbouncer连接池,PgExporter监控组件,高可用组件,管理Agent看作一个提供服务的整体,视为一个数据库实例。
实例隶属于集群,每个实例在集群范围内都有着自己的唯一标识用于区分。
实例由服务负责解析,实例提供被寻址的能力,而Service将请求流量解析到具体的实例组上。
命名规则
一个对象可以有很多组**标签(Tag)**与元数据(Metadata/Annotation),但通常只能有一个名字。
管理数据库和软件,其实与管理子女或者宠物类似,都是需要花心思去照顾的。而起名字就是其中非常重要的一项工作。肆意的名字(例如 XÆA-12,NULL,史珍香)很可能会引入不必要的麻烦(额外复杂度),而设计得当的名字则可能会有意想不到的效果。
总的来说,对象起名应当遵循一些原则:
-
简洁直白,人类可读:名字是给人看的,因此要好记,便于使用。
-
体现功能,反映特征:名字需要反映对象的关键特征
-
独一无二,唯一标识:名字在命名空间内,自己的类目下应当是独一无二,可以惟一标识寻址的。
-
不要把太多无关的东西塞到名字里去:在名字中嵌入很多重要元数据是一个很有吸引力的想法,但维护起来会非常痛苦,例如反例:pg:user:profile:10.11.12.13:5432:replica:13。
集群命名
集群名称,其实类似于命名空间的作用。所有隶属本集群的资源,都会使用该命名空间。
集群命名的形式,建议采用符合DNS标准 RFC1034 的命名规则,以免给后续改造埋坑。例如哪一天想要搬到云上去,发现以前用的名字不支持,那就要再改一遍名,成本巨大。
我认为更好的方式是采用更为严格的限制:集群的名称不应该包括点(dot)。应当仅使用小写字母,数字,以及减号连字符(hyphen)-。这样,集群中的所有对象都可以使用这个名称作为前缀,用于各种各样的地方,而不用担心打破某些约束。即集群命名规则为:
cluster_name := [a-z][a-z0-9-]*
之所以强调不要在集群名称中用点,是因为以前很流行一种命名方式,例如com.foo.bar。即由点分割的层次结构命名法。这种命名方式虽然简洁名快,但有一个问题,就是用户给出的名字里可能有任意多的层次,数量不可控。如果集群需要与外部系统交互,而外部系统对于命名有一些约束,那么这样的名字就会带来麻烦。一个最直观的例子是K8s中的Pod,Pod的命名规则中不允许出现.。
集群命名的内涵,建议采用-分隔的两段式,三段式名称,例如:
<集群类型>-<业务>-<业务线>
比如:pg-test-tt就表示tt 业务线下的test集群,类型为pg。pg-user-fin表示fin业务线下的user服务。
节点命名
节点命名建议采用与k8s Pod一致的命名规则,即
<cluster_name>-<seq>
Node的名称会在集群资源分配阶段确定下来,每个节点都会分配到一个序号${seq},从0开始的自增整型。这个与k8s中StatefulSet的命名规则保持一致,因此能够做到云上云下一致管理。
例如,集群pg-test有三个节点,那么这三个节点就可以命名为:
pg-test-1, pg-test-2和pg-test-3。
节点的命名,在整个集群的生命周期中保持不变,便于监控与管理。
实例命名
对于数据库来说,通常都会采用独占式部署方式,一个实例占用整个机器节点。PG实例与Node是一一对应的关系,因此可以简单地采用Node的标识符作为Instance的标识符。例如,节点pg-test-1上的PG实例名即为:pg-test-1,以此类推。
采用独占部署的方式有很大优势,一个节点即一个实例,这样能最小化管理复杂度。混部的需求通常来自资源利用率的压力,但虚拟机或者云平台可以有效解决这种问题。通过vm或pod的抽象,即使是每个redis(1核1G)实例也可以有一个独占的节点环境。
作为一种约定,每个集群中的0号节点(Pod),会作为默认主库。因为它是初始化时第一个分配的节点。
服务命名
通常来说,数据库对外提供两种基础服务:primary 读写服务,与standby只读副本服务。
那么服务就可以采用一种简单的命名规则:
<cluster_name>-<service_name>
例如这里pg-test集群就包含两个服务:读写服务pg-test-primary与只读副本服务pg-test-standby。
一种流行的实例/节点命名规则:<cluster_name>-<service_role>-<sequence>,即把数据库的主从身份嵌入到实例名称中。这种命名方式有好处也有坏处。好处是管理的时候一眼就能看出来哪一个实例/节点是主库,哪些是从库。缺点是一但发生Failover,实例与节点的名称必须进行调整才能维持一执性,这就带来的额外的维护工作。此外,服务与节点实例是相对独立的概念,这种Embedding命名方式扭曲了这一关系,将实例唯一隶属至服务。但复杂的场景下这一假设可能并不满足。例如,集群可能有几种不同的服务划分方式,而不同的划分方式之间很可能会出现重叠。
- 可读从库(解析至包含主库在内的所有实例)
- 同步从库(解析至采用同步提交的备库)
- 延迟从库,备份实例(解析至特定具体实例)
因此,不要把服务角色嵌入实例名称,而是在服务中维护目标实例列表。
毕竟,名字不是全能的,不要把太多非必要的信息嵌入到对象名称中。
小结
命名属于相当经验性的知识,很少有地方会专门会讲这件事。这种“细节”其实往往能体现出命名者的一些经验水平来。
标识对象不仅仅可以通过ID和名称,还可以通过标签(Label)和选择器(Selector)。实际上这一种做法会更具有通用性和灵活性。
当我们为系统中的实体起名后,还需要通过一种方式将名称与实体关联起来。这就涉及到了 服务发现
4.1 - 可观测性
从原始信息到全局洞察
对于系统管理来说,最重要到问题之一就是可观测性(Observability)。
那么,什么是可观测性呢?对于这样的问题,列举定义是枯燥乏味的,让我们直接以Postgres本身为例。
这张图显示了Postgres本身提供的可观测性。PostgreSQL 提供了丰富的观测接口,包括系统目录,统计视图,辅助函数。 这些都是我们可以观测的对象。

原图地址:https://pgstats.dev/
我可以很荣幸地宣称,这里列出的信息全部被Pigsty所收录。并且通过精心的设计,将晦涩的指标数据,转换成了人类可以轻松理解的洞察。
可观测性
经典的监控模型中,有三类重要信息:
- 指标(Metrics),
- 日志(Log)
- 目录(Catalog),(其实是Trace,但数据库没有trace信息,这里用Catalog替代)
指标
下面让我们以一个最经典的例子来深入探索可观测性: pg_stat_statements ,这是Postgres官方提供的统计插件,可以暴露出数据库中执行的每一类查询的详细统计指标。与图中Query Planning和Execution相对应
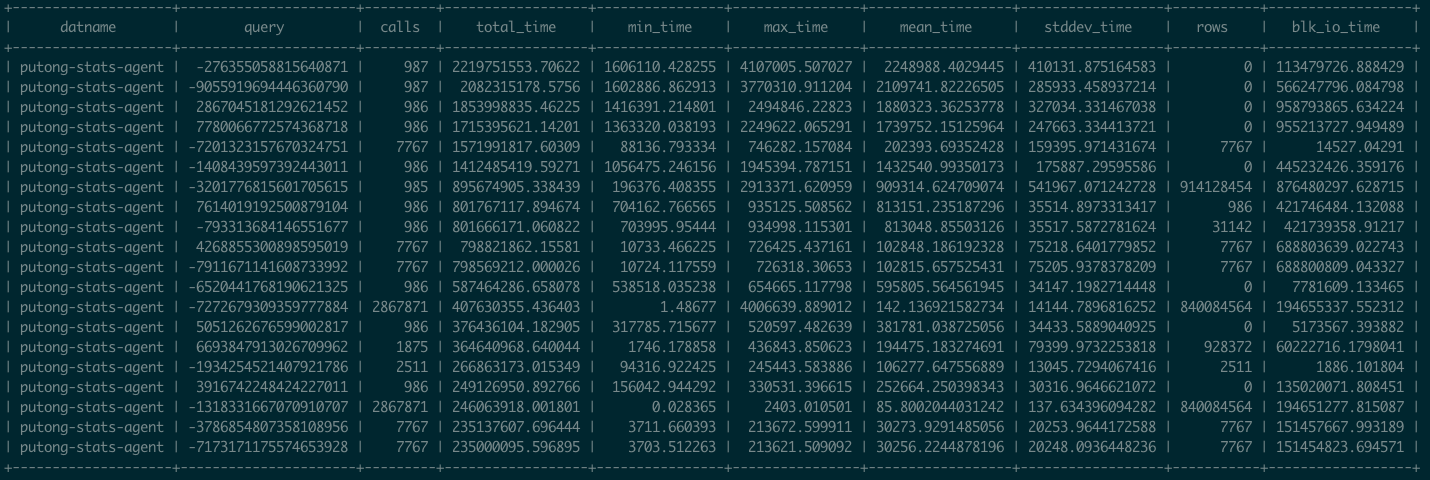
这里我们可以看到,pg_stat_statements 提供的原始指标数据以表格的形式呈现。譬如这里,每个查询都分配有一个查询ID,紧接着是调用次数,总耗时,最大、最小、平均单次耗时,响应时间都标准差,每次调用平均返回的行数,用于块IO的时间等等,(如果是PG13,还有更为细化的计划时间、执行时间、产生的WAL记录数量等新指标)。
直接观测这种数据表,很容易让人摸不着头脑,看不到重点。我们需要的是,将这种可观测性转换为洞察,也就是以直观图表的方式呈现。
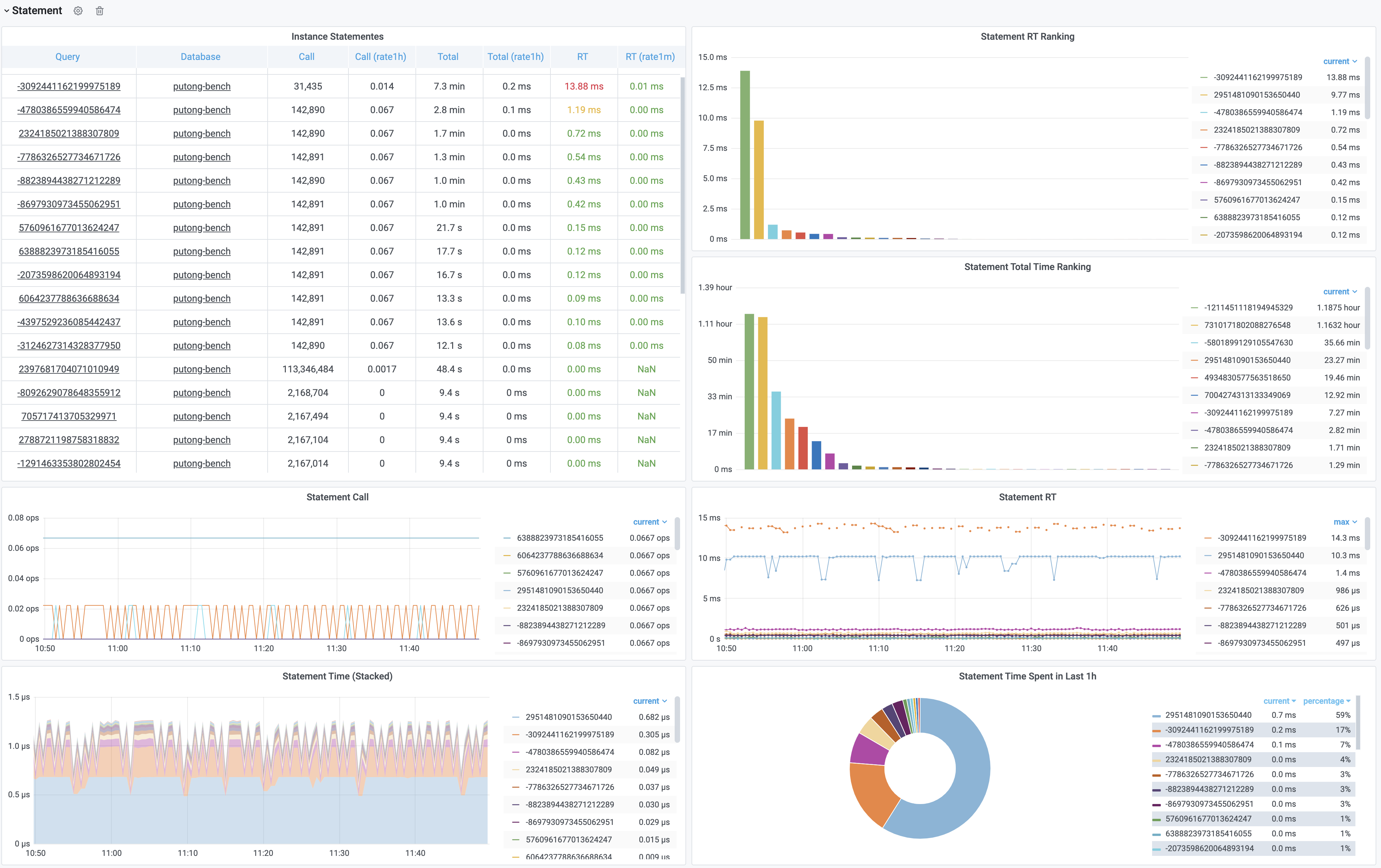
这里的表格数据经过一系列的加工处理,最终呈现为若干监控面板。最基本的加工处理譬如:对表格中的原始数据进行标红上色,这样慢查询就可以一览无余,但这也不过是雕虫小技。
更重要的是,原始的数据视图只能呈现当前时刻的快照,而通过Pigsty,你可以回溯任意时刻或任意时间段。获取更深刻的性能洞察。
比如下图是集群视角下的慢查询,我们可以看到整个集群中所有查询的概览,包括每一类查询的QPS与RT,平均响应时间排名,以及耗费的总时间占比。当我们对某一类具体查询感兴趣时,就可以点击查询ID跳转到查询详情页中,如右图所示。这里会显示查询的语句,以及一些核心指标。
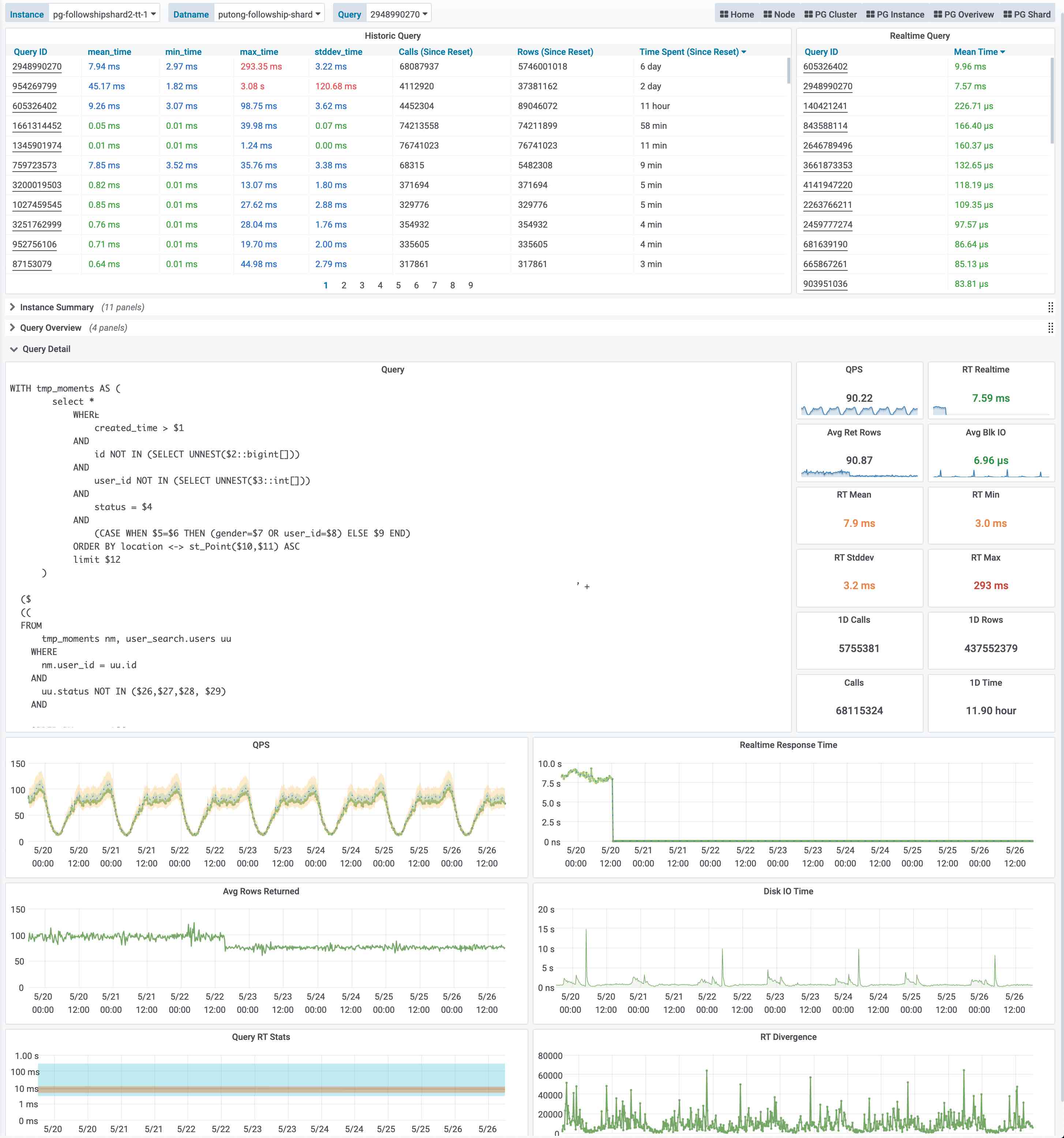
这个图是实际生产环境中的一次慢查询优化记录,我们可以从右侧中间的Realtime Response Time 面板中看到一个突变,该查询的平均响应时间从七八秒突降到了七八毫秒。我们定位到了这个慢查询并添加了适当的索引,那么优化的效果就立刻在图表上以直观的形式展现出来。
这就是Pigsty需要解决的核心问题,From observability to insight。
而下面这些玲琅满目的面板,就是Pigsty成就的一瞥:


目录
Catalog是什么?Catalog是数据库的元数据字典。
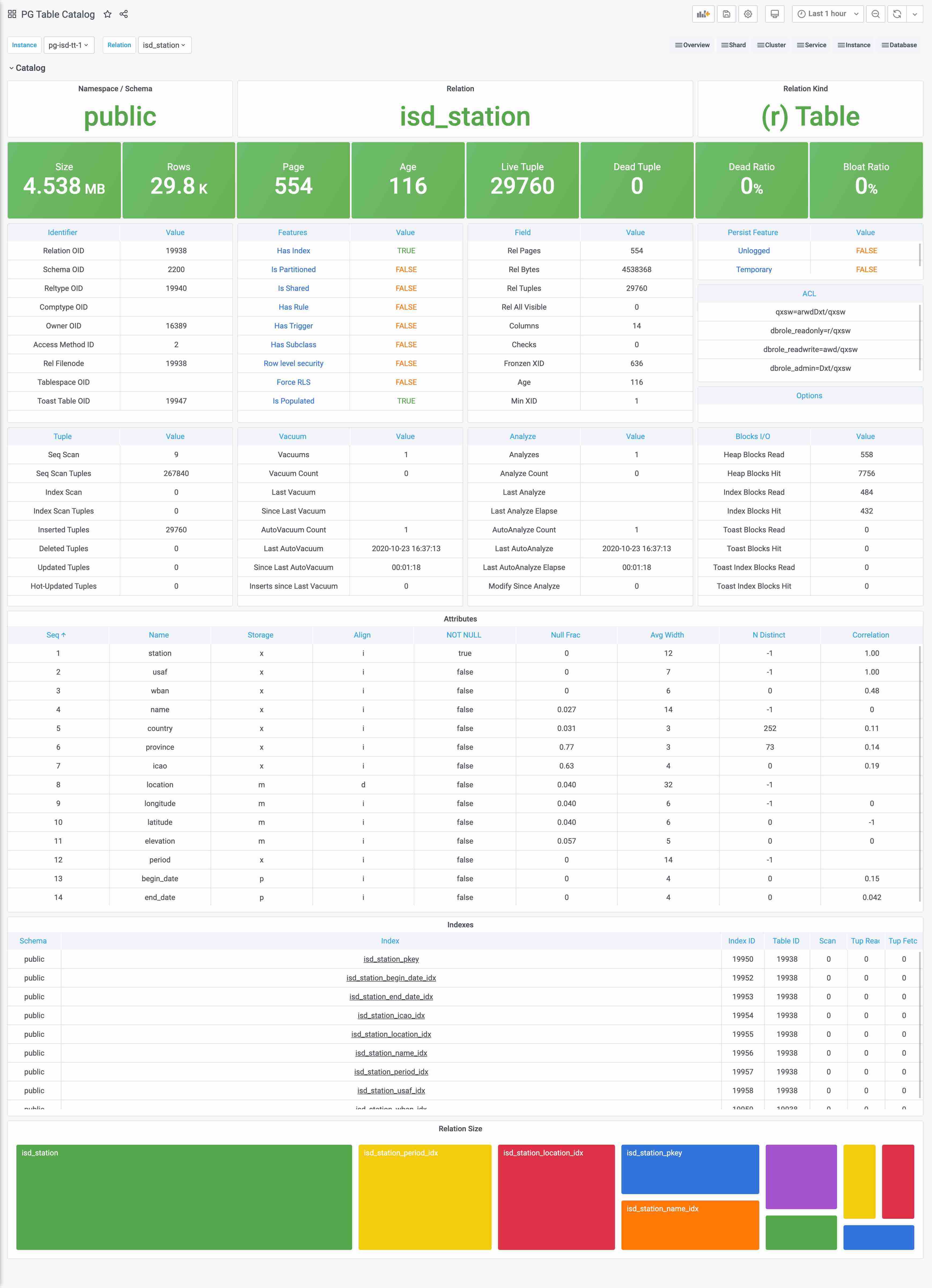
Catalog与Metrics比较相似但又不完全相同,边界比较模糊。最简单的例子,一个表的页面数量和元组数量,应该算Catalog还是算Metrics呢?
跳过这种概念游戏,实践上Catalog和Metrics主要的区别是,Catalog里的信息通常是不怎么变化的,比如表的定义之类的,如果也像Metrics这样比如几秒抓一次,显然是一种浪费。所以我们会将这一类偏静态的信息划归Catalog。
Catalog主要由定时任务负责抓取,而不由Prometheus采集。
日志
除了Catalog,还有一类与监控系统有关的数据是Log。如果说Metrics是对数据库系统的被动观测,那么Log就是数据库系统主动汇报的信息。
Pigsty集成了pgbadger,这是一个非常强大的日志摘要工具,可以实时聚合并生成PG的日志摘要。
同时,通过mtail这样的工具,我们还可以从日志中提取重要的监控指标,最简单的例子就是每秒各错误等级的日志条数。如果说整个监控系统只能保留一个指标,也许这个指标就是最有用的那个指标了。
接下来呢?
只有指标并不够,我们还需要将这些信息组织起来,才能构建出体系来。
阅读下一节:实际挑战 来了解实际的生产环境中的监控系统可能面临怎样的问题与挑战。
4.2 - 监控层级
介绍Pigsty中涉及的层次关系
生产环境的数据库往往是以集群为单位组织的。集群是一个由主从复制所关联的一组数据库实例所构成的,它是基本的业务服务单元。集群由多个实例组成,而多套数据库集群共同组成一个现实世界中的生产环境。
除了实例与集群这两个最为Trivial层次,整个系统中还有着其他层次的组织。自顶向下可以分为7个层级:概览,分片,集群,服务,实例,数据库,对象。
夹在集群与实例中间的层次—— Service。
在实例层级以下,还可以再分出两个层次来,分别是Database和Object。Object即亚数据库对象,包括:表、索引,函数,序列号,查询、连接池等。
从集群层次向上看,则会有两个更高的层次——Shard与Overview。
作为一种精简,正如网络的OSI 7层模型在实际中被简化为TCP/IP五层模型一样,这七个层次也以集群 和 实例为界,简化为五个层次:Overview,Cluster,Service,Instance,Database 。
这样,最终的层次划分也变得十分简洁:所有集群层次以上的信息,都是Overview层次,所有实例内部的信息都算Database层次,夹在两者中间的,就是Service层次。
命名问题
分完层次后,剩下的问题实际上就是命名问题,或者说身份管理的问题。
-
我们需要一种方式来标识、引用系统中不同层次内的各个组件,
-
这种命名方式,应当合理地反映出系统中各个实体的层次关系
-
这种命名方式,应当可以按照规则自动生成,只有这样,才可以在集群扩容缩容,Failover时做到免维护自动化运行,
当我们理清了系统中存在的层次后,就可以着手为系统中的每个实体起名。请参考下一节:命名规则
4.3 - 服务发现
Pigsty是如何自动发现并管理数据库实例的
所有的服务都有身份,例如,所属的集群,集群内的唯一标识,在集群中扮演的角色。等等。
身份管理
当我们为系统设计好命名规则与模式后,第二个问题,就是如何将身份赋予/关联数据库实例。
数据库本身并不知道自己为谁而服务。属于哪个业务,是集群中的几号实例。因此在生产环境大规模集群管理中,我们必须为数据库实例赋予身份。
身份赋予可以有多种形式,例如人肉死记硬背也是一种身份赋予,管理员在脑海中记住了10.20.30.40 IP地址上的数据库实例是用于支付的,而另一台上的数据库实例则用于订单。
更好的方式是通过配置文件,或者更进一步,服务发现的方式来管理集群成员的身份。将身份信息注册到监控系统中是系统自动运行的重要环节,这一步与Kubernetes往etcd中写元数据类似。
Pigsty提供两种身份管理的方式:基于服务发现(Consul/etcd),与基于配置文件。
参考配置:prometheus_sd_method
Prometheus使用的服务发现机制,默认为consul,可选项:
consul:基于Consul进行服务发现static:基于本地配置文件进行服务发现
Pigsty建议使用consul服务发现,当服务器发生Failover时,监控系统会自动更正目标实例所注册的身份。
基于Consul的服务发现
Pigsty内置了基于DCS的配置管理与自动服务发现,用户可以直观地察看系统中的所有节点与服务信息,以及健康状态。Pigsty中的所有服务都会自动注册至DCS中,因此创建、销毁、修改数据库集群时,元数据会自动修正,监控系统能够自动发现监控目标,无需手动维护配置。
目前仅支持Consul作为DCS,用户亦可通过Consul提供的DNS与服务发现机制,实现基于DNS的自动流量切换。后续会提供etcd的完整支持,但下面的介绍都将基于consul进行。
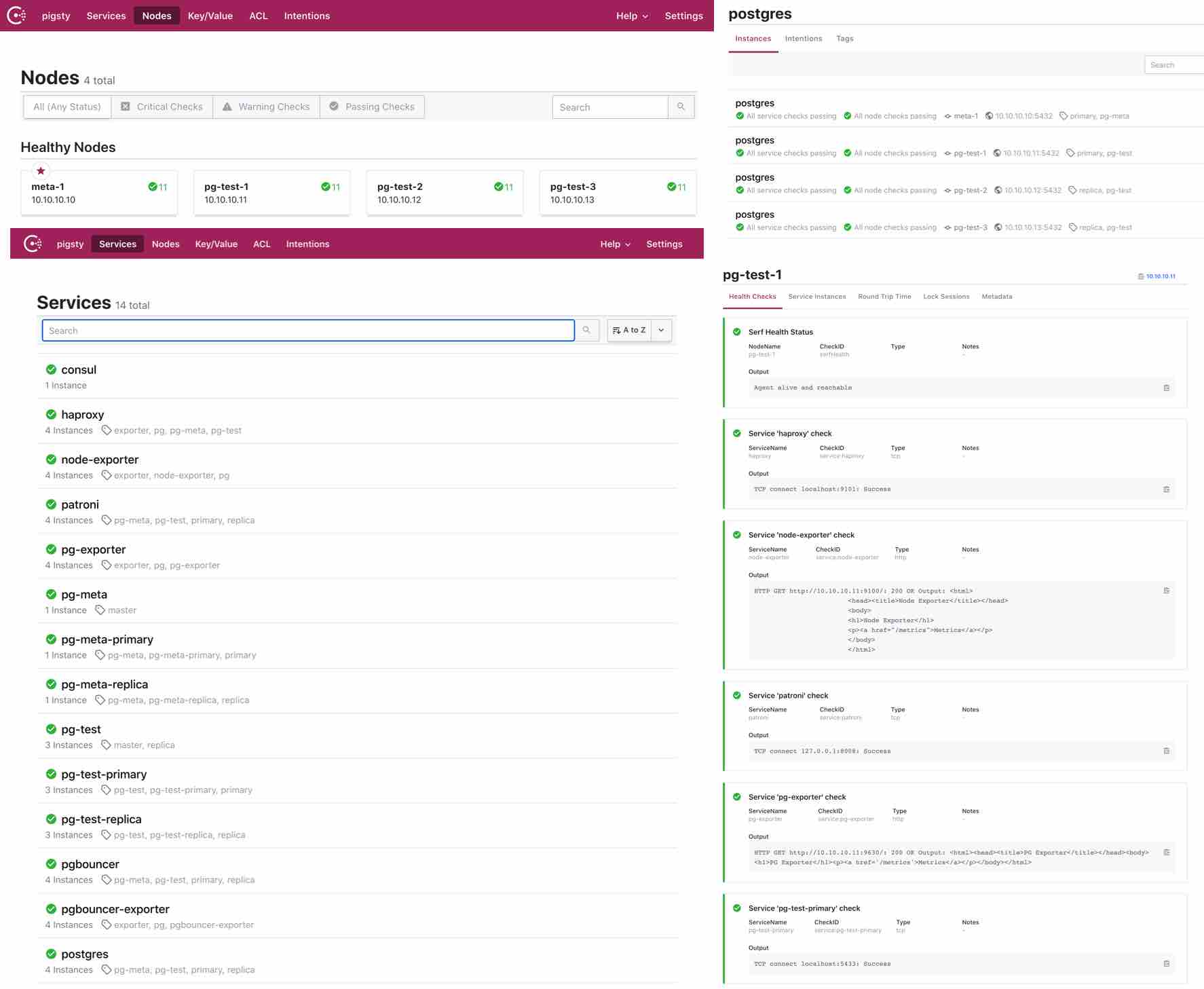
注册
在每个节点上,都运行有 consul agent。服务通过JSON配置文件的方式,由consul agent注册至DCS中。
JSON配置文件的默认位置是/etc/consul.d/,采用svc-<service>.json的命名规则,以postgres为例:
{
"service": {
"name": "postgres",
"port": {{ pg_port }},
"tags": [
"{{ pg_role }}",
"{{ pg_cluster }}"
],
"meta": {
"type": "postgres",
"role": "{{ pg_role }}",
"seq": "{{ pg_seq }}",
"instance": "{{ pg_instance }}",
"service": "{{ pg_service }}",
"cluster": "{{ pg_cluster }}",
"version": "{{ pg_version }}"
},
"check": {
"tcp": "127.0.0.1:{{ pg_port }}",
"interval": "15s",
"timeout": "1s"
}
}
}
查询
您可以通过Consul提供的DNS服务,或者直接调用Consul API实现服务发现。注册到Consul中的服务
使用DNS API查阅consul服务的方式请参阅Consul文档。
发现
Prometheus会自动通过consul_sd_configs发现环境中的监控对象。同时带有pg和exporter标签的服务会自动被识别为抓取对象:
- job_name: pg
# https://prometheus.io/docs/prometheus/latest/configuration/configuration/#consul_sd_config
consul_sd_configs:
- server: localhost:8500
refresh_interval: 5s
tags:
- pg
- exporter
被Prometheus发现的服务
Prometheus会自动通过consul_sd_configs发现环境中的监控对象。同时带有pg和exporter标签的服务会自动被识别为抓取对象:
- job_name: pg
# https://prometheus.io/docs/prometheus/latest/configuration/configuration/#consul_sd_config
consul_sd_configs:
- server: localhost:8500
refresh_interval: 5s
tags:
- pg
- exporter
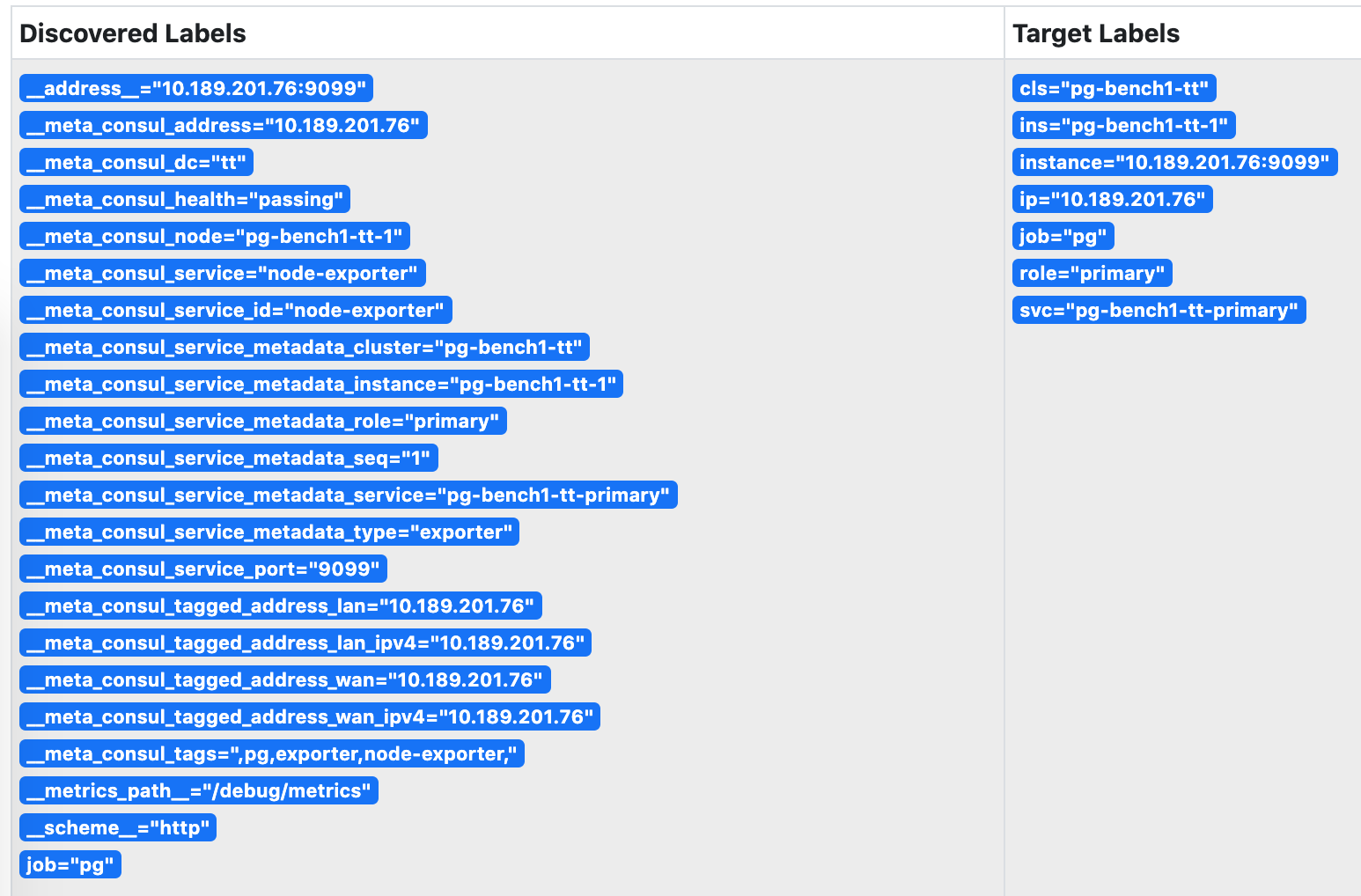
维护
有时候,因为数据库主从发生切换,导致注册的角色与数据库实例的实际角色出现偏差。这时候需要通过反熵过程处理这种异常。
基于Patroni的故障切换可以正常地通过回调逻辑修正注册的角色,但人工完成的角色切换则需要人工介入处理。
使用以下脚本可以自动检测并修复数据库的服务注册。建议在数据库实例上配置Crontab,定期检测并修正服务。
/pg/bin/pg-register $(pg-role)
基于静态文件的服务发现
static服务发现依赖/etc/prometheus/targets/*.yml中的配置进行服务发现。采用这种方式的优势是不依赖Consul。
当Pigsty监控系统与外部管控方案集成时,这种模式对原系统的侵入性较小。
但是缺点是,当集群内发生主从切换时,您需要自行维护实例角色信息。
手动维护时,可以根据以下命令从配置文件生成Prometheus所需的监控对象配置文件并载入生效。
./infra.yml --tags=prometheus_targtes,prometheus_reload
Pigsty默认生成的静态监控对象文件示例如下:
#==============================================================#
# File : targets/all.yml
# Ctime : 2021-02-18
# Mtime : 2021-02-18
# Desc : Prometheus Static Monitoring Targets Definition
# Path : /etc/prometheus/targets/all.yml
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
#======> pg-meta-1 [primary]
- labels: {cls: pg-meta, ins: pg-meta-1, ip: 10.10.10.10, role: primary, svc: pg-meta-primary}
targets: [10.10.10.10:9630, 10.10.10.10:9100, 10.10.10.10:9631, 10.10.10.10:9101]
#======> pg-test-1 [primary]
- labels: {cls: pg-test, ins: pg-test-1, ip: 10.10.10.11, role: primary, svc: pg-test-primary}
targets: [10.10.10.11:9630, 10.10.10.11:9100, 10.10.10.11:9631, 10.10.10.11:9101]
#======> pg-test-2 [replica]
- labels: {cls: pg-test, ins: pg-test-2, ip: 10.10.10.12, role: replica, svc: pg-test-replica}
targets: [10.10.10.12:9630, 10.10.10.12:9100, 10.10.10.12:9631, 10.10.10.12:9101]
#======> pg-test-3 [replica]
- labels: {cls: pg-test, ins: pg-test-3, ip: 10.10.10.13, role: replica, svc: pg-test-replica}
targets: [10.10.10.13:9630, 10.10.10.13:9100, 10.10.10.13:9631, 10.10.10.13:9101]
接下来
将数据库服务注册至DCS后,我们为每个实例赋予了身份信息,因此可以将监控指标与实例的身份关联起来。
阅读下一节 监控指标 了解Pigsty提供的监控指标,以及这些指标是如何通过标签组织起来的。
4.4 - 监控指标
监控指标的数量,层次,衍生规则,
指标来源
Pigsty的监控数据,主要有四个来源: 数据库本身,中间件,操作系统,负载均衡器。通过相应的exporter对外暴露。
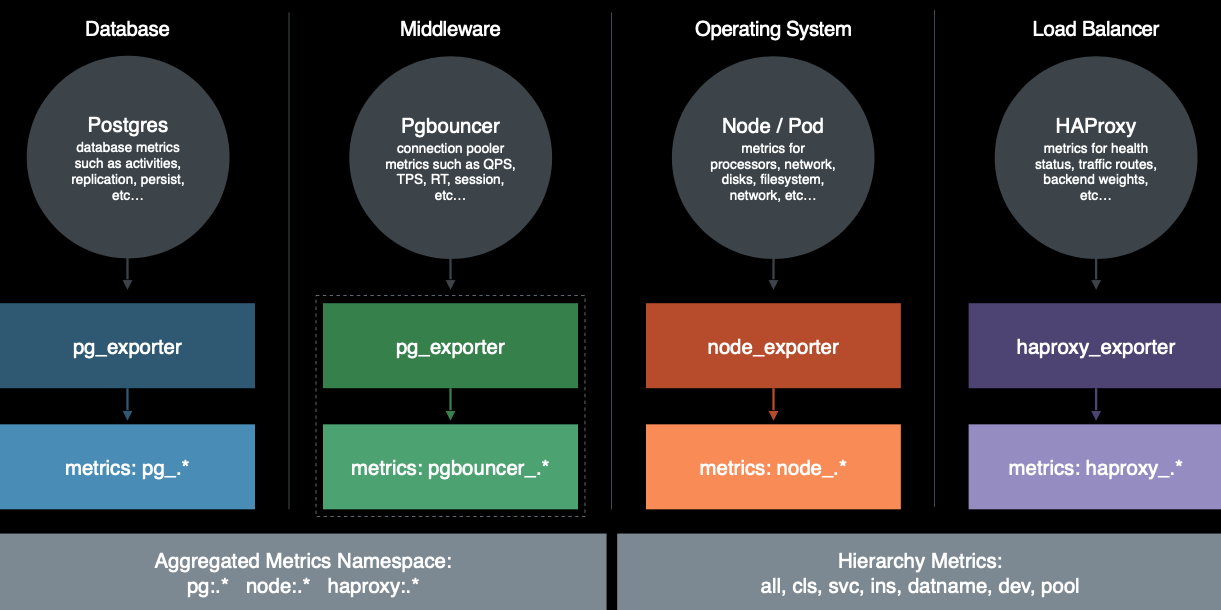
完整来源包括:
- PostgreSQL本身的监控指标
- PostgreSQL日志中的统计指标
- PostgreSQL系统目录信息
- Pgbouncer连接池中间价的指标
- PgExporter指标
- 数据库工作节点Node的指标
- 负载均衡器Haproxy指标
- DCS(Consul)工作指标
- 监控系统自身工作指标:Grafana,Prometheus,Nginx
- Blackbox探活指标
关于全部可用的指标清单,请查阅 参考-指标清单 一节
指标数量
那么,Pigsty总共包含了多少指标呢? 这里是一副各个指标来源占比的饼图。我们可以看到,右侧蓝绿黄对应的部分是数据库及数据库相关组件所暴露的指标,而左下方红橙色部分则对应着机器节点相关指标。左上方紫色部分则是负载均衡器的相关指标。
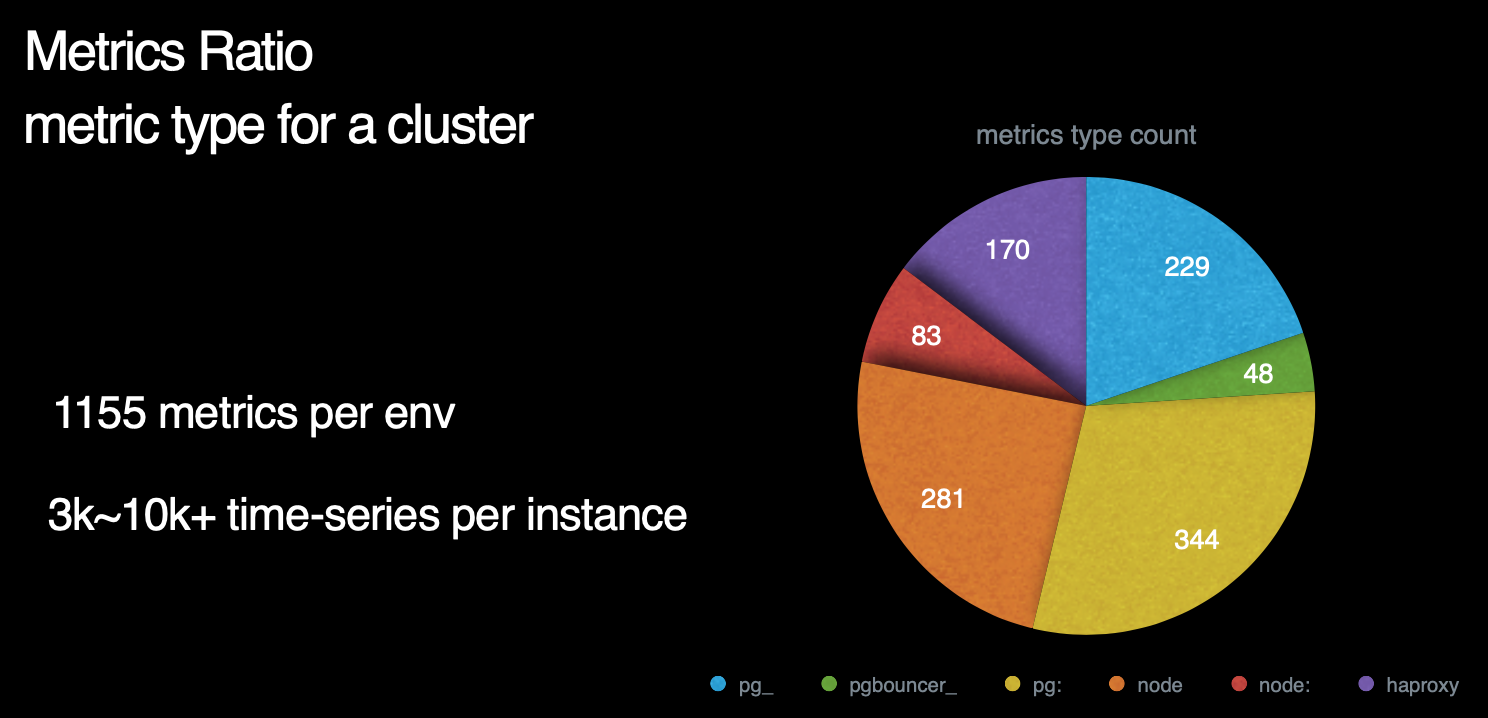
数据库指标中,与postgres本身有关的原始指标约230个,与中间件有关的原始指标约50个,基于这些原始指标,Pigsty又通过层次聚合与预计算,精心设计出约350个与DB相关的衍生指标。
因此,对于每个数据库集群来说,单纯针对数据库及其附件的监控指标就有621个。而机器原始指标281个,衍生指标83个一共364个。加上负载均衡器的170个指标,我们总共有接近1200类指标。
注意,这里我们必须辨析一下指标(metric)与时间序列( Time-series)的区别。
这里我们使用的量词是 类 而不是个 。 因为一个指标可能对应多个时间序列。例如一个数据库中有20张表,那么 pg_table_index_scan 这样的指标就会对应有20个对应的时间序列。
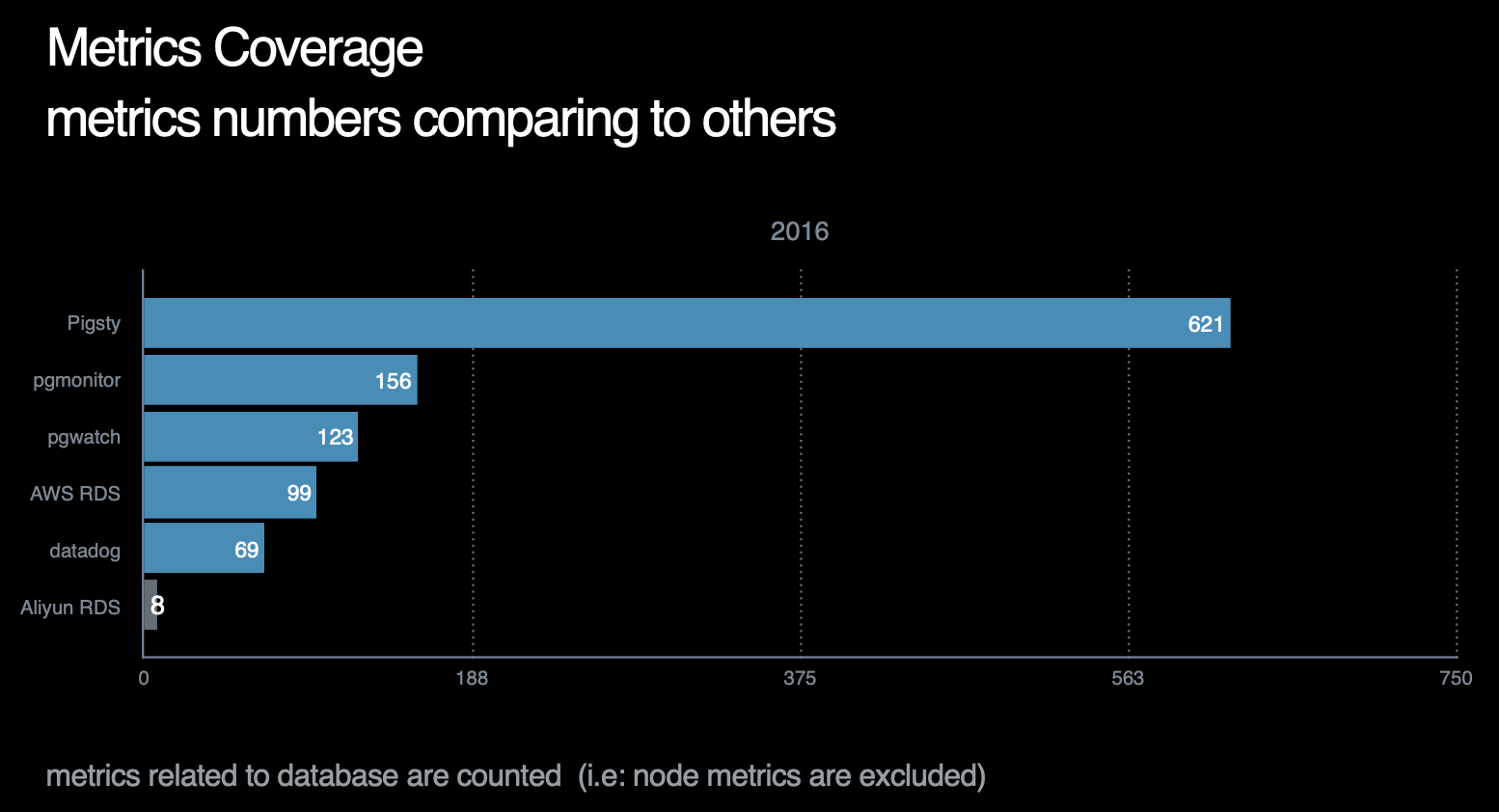
截止至2021年,Pigsty的指标覆盖率在所有作者已知的开源/商业监控系统中一骑绝尘,详情请参考横向对比。
指标层次
所有的这些指标,还会进行进一步的加工处理。
例如按照不同的层次进行聚合,形成一系列的衍生指标。
从原始监控时间序列数据,到最终的成品图表,中间还有着若干道加工工序。
这里以TPS指标的衍生流程为例。
原始数据是从Pgbouncer抓取得到的事务计数器,集群中有四个实例,而每个实例上又有两个数据库,所以一个实例总共有8个DB层次的TPS指标。
而下面的图表,则是整个集群内每个实例的QPS横向对比,因此在这里,我们使用预定义的规则,首先对原始事务计数器求导获取8个DB层面的TPS指标,然后将8个DB层次的时间序列聚合为4个实例层次的TPS指标,最后再将这四个实例级别的TPS指标聚合为集群层次的TPS指标。
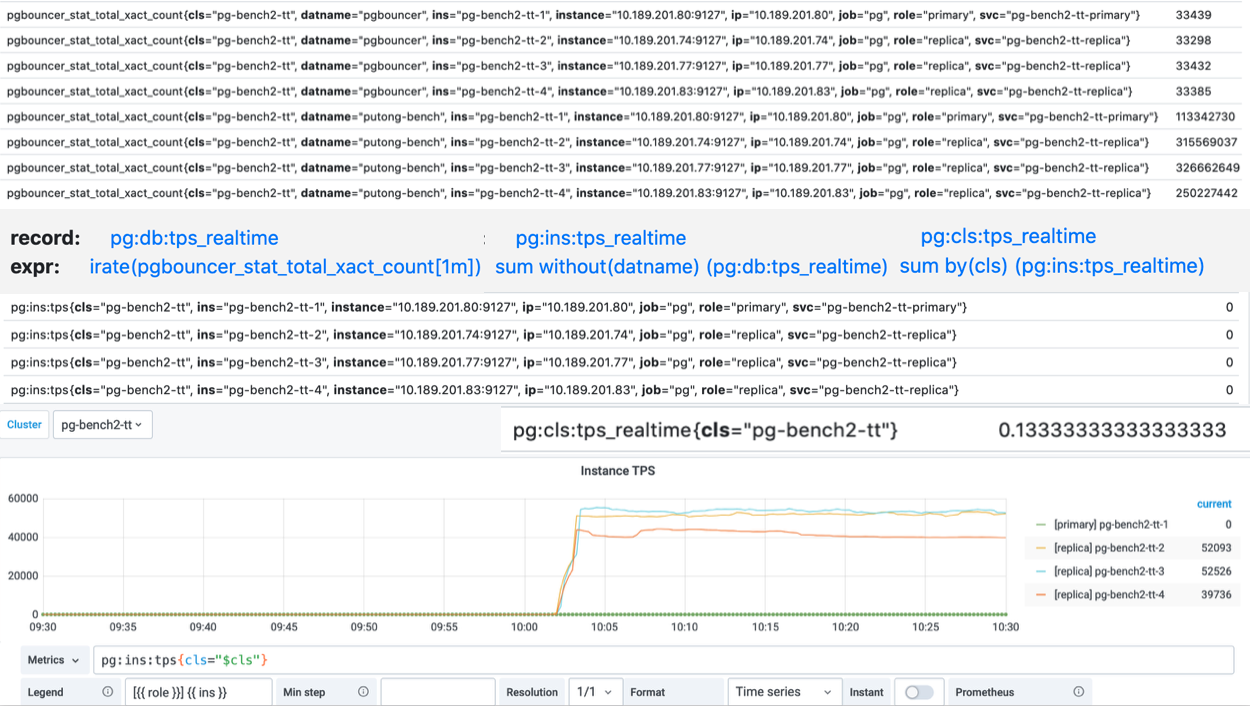
Pigsty共定义了360类衍生聚合指标,后续还会不断增加。衍生指标定义规则详见 参考-衍生指标
小结
了解了Pigsty指标后,不妨了解一下Pigsty的报警系统是如何将这些指标数据用于实际生产用途的。
4.5 - 报警规则
介绍附带的数据库报警规则,以及如何定制报警规则
报警对于日常故障响应,提高系统可用性至关重要。
漏报会导致可用性降低,误报会导致敏感性下降,有必要对报警规则进行审慎的设计。
- 合理定义报警级别,以及相应的处理流程
- 合理定义报警指标,去除重复报警项,补充缺失报警项
- 根据历史监控数据科学配置报警阈值,减少误报率。
- 合理疏理特例规则,消除维护工作,ETL,离线查询导致的误报。
报警分类学
按紧急程度分类
-
P0:FATAL:产生重大场外影响的事故,需要紧急介入处理。例如主库宕机,复制中断。(严重事故)
-
P1:ERROR:场外影响轻微,或有冗余处理的事故,需要在分钟级别内进行响应处理。(事故)
-
P2:WARNING:即将产生影响,放任可能在小时级别内恶化,需在小时级别进行响应。(关注事件)
-
P3:NOTICE:需要关注,不会有即时的影响,但需要在天级别内进行响应。(偏差现象)
按报警层次分类
- 系统级:操作系统,硬件资源的报警。DBA只会特别关注CPU与磁盘报警,其他由运维负责。
- 数据库级:数据库本身的报警,DBA重点关注。由PG,PGB,Exporter本身的监控指标产生。
- 应用级:应用报警由业务方自己负责,但DBA会为QPS,TPS,Rollback,Seasonality等业务指标设置报警
按指标类型分类
- 错误:PG Down, PGB Down, Exporter Down, 流复制中断,单集簇多主
- 流量:QPS,TPS,Rollback,Seasonaility
- 延迟: 平均响应时间,复制延迟
- 饱和度:连接堆积,闲事务数,CPU,磁盘,年龄(事务号),缓冲区
报警可视化
报警规则详解
报警规则按类型可粗略分为四类:错误,延迟,饱和度,流量。其中:
- 错误:主要关注各个组件的存活性(Aliveness),以及网络中断,脑裂等异常情况,级别通常较高(P0|P1)。
- 延迟:主要关注查询响应时间,复制延迟,慢查询,长事务。
- 饱和度:主要关注CPU,磁盘(这两个属于系统监控但对于DB非常重要所以纳入),连接池排队,数据库后端连接数,年龄(本质是可用事物号的饱和度),SSD寿命等。
- 流量:QPS,TPS,Rollback(流量通常与业务指标有关属于业务监控范畴,但因为对于DB很重要所以纳入),QPS的季节性,TPS的突增。
错误报警
Postgres实例宕机区分主从,主库宕机触发P0报警,从库宕机触发P1报警。两者都需要立即介入,但从库通常有多个实例,且可以降级到主库上查询,有着更高的处理余量,所以从库宕机定为P1。
# primary|master instance down for 1m triggers a P0 alert
- alert: PG_PRIMARY_DOWN
expr: pg_up{instance=~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Postgres Primary Instance Down: {{$labels.instance}}"
description: "pg_up = {{ $value }} {{$labels.instance}}"
# standby|slave instance down for 1m triggers a P1 alert
- alert: PG_STANDBY_DOWN
expr: pg_up{instance!~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres Standby Instance Down: {{$labels.instance}}"
description: "pg_up = {{ $value }} {{$labels.instance}}"
Pgbouncer实例因为与Postgres实例一一对应,其存活性报警规则与Postgres统一。
# primary pgbouncer down for 1m triggers a P0 alert
- alert: PGB_PRIMARY_DOWN
expr: pgbouncer_up{instance=~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Pgbouncer Primary Instance Down: {{$labels.instance}}"
description: "pgbouncer_up = {{ $value }} {{$labels.instance}}"
# standby pgbouncer down for 1m triggers a P1 alert
- alert: PGB_STANDBY_DOWN
expr: pgbouncer_up{instance!~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Pgbouncer Standby Instance Down: {{$labels.instance}}"
description: "pgbouncer_up = {{ $value }} {{$labels.instance}}"
Prometheus Exporter的存活性定级为P1,虽然Exporter宕机本身并不影响数据库服务,但这通常预示着一些不好的情况,而且监控数据的缺失也会产生某些相应的报警。Exporter的存活性是通过Prometheus自己的up指标检测的,需要注意某些单实例多DB的特例。
# exporter down for 1m triggers a P1 alert
- alert: PG_EXPORTER_DOWN
expr: up{port=~"(9185|9127)"} == 0
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Exporter Down: {{$labels.instance}} {{$labels.port}}"
description: "port = {{$labels.port}}, {{$labels.instance}}"
所有存活性检测的持续时间阈值设定为1分钟,对15s的默认采集周期而言是四个样本点。常规的重启操作通常不会触发存活性报警。
延迟报警
与复制延迟有关的报警有三个:复制中断,复制延迟高,复制延迟异常,分别定级为P1, P2, P3
-
其中复制中断是一种错误,使用指标:pg_repl_state_count{state="streaming"}进行判断,当前streaming状态的从库如果数量发生负向变动,则触发break报警。walsender会决定复制的状态,从库直接断开会产生此现象,缓冲区出现积压时会从streaming进入catchup状态也会触发此报警。此外,采用-Xs手工制作备份结束时也会产生此报警,此报警会在10分钟后自动Resolve。复制中断会导致客户端读到陈旧的数据,具有一定的场外影响,定级为P1。
-
复制延迟可以使用延迟时间或者延迟字节数判定。以延迟字节数为权威指标。常规状态下,复制延迟时间在百毫秒量级,复制延迟字节在百KB量级均属于正常。目前采用的是5s,15s的时间报警阈值。根据历史经验数据,这里采用了时间8秒与字节32MB的阈值,大致报警频率为每天个位数个。延迟时间更符合直觉,所以采用8s的P2报警,但并不是所有的从库都能有效取到该指标所以使用32MB的字节阈值触发P3报警补漏。
-
特例:antispam,stats,coredb均经常出现复制延迟。
# replication break for 1m triggers a P0 alert. auto-resolved after 10 minutes.
- alert: PG_REPLICATION_BREAK
expr: pg_repl_state_count{state="streaming"} - (pg_repl_state_count{state="streaming"} OFFSET 10m) < 0
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Postgres Streaming Replication Break: {{$labels.instance}}"
description: "delta = {{ $value }} {{$labels.instance}}"
# replication lag greater than 8 second for 3m triggers a P1 alert
- alert: PG_REPLICATION_LAG
expr: pg_repl_replay_lag{application_name="walreceiver"} > 8
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres Replication Lagged: {{$labels.instance}}"
description: "lag = {{ $value }} seconds, {{$labels.instance}}"
# replication diff greater than 32MB for 5m triggers a P3 alert
- alert: PG_REPLICATOIN_DIFF
expr: pg_repl_lsn{application_name="walreceiver"} - pg_repl_replay_lsn{application_name="walreceiver"} > 33554432
for: 5m
labels:
team: DBA
urgency: P3
annotations:
summary: "P3 Postgres Replication Diff Deviant: {{$labels.instance}}"
description: "delta = {{ $value }} {{$labels.instance}}"
饱和度报警
饱和度指标主要资源,包含很多系统级监控的指标。主要包括:CPU,磁盘(这两个属于系统监控但对于DB非常重要所以纳入),连接池排队,数据库后端连接数,年龄(本质是可用事物号的饱和度),SSD寿命等。
堆积检测
堆积主要包含两类指标,一方面是PG本身的后端连接数与活跃连接数,另一方面是连接池的排队情况。
PGB排队是决定性的指标,它代表用户端可感知的阻塞已经出现,因此,配置排队超过15持续1分钟触发P0报警。
# more than 8 client waiting in queue for 1 min triggers a P0 alert
- alert: PGB_QUEUING
expr: sum(pgbouncer_pool_waiting_clients{datname!="pgbouncer"}) by (instance,datname) > 8
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Pgbouncer {{ $value }} Clients Wait in Queue: {{$labels.instance}}"
description: "waiting clients = {{ $value }} {{$labels.instance}}"
后端连接数是一个重要的报警指标,如果后端连接持续达到最大连接数,往往也意味着雪崩。连接池的排队连接数也能反映这种情况,但不能覆盖应用直连数据库的情况。后端连接数的主要问题是它与连接池关系密切,连接池在短暂堵塞后会迅速打满后端连接,但堵塞恢复后这些连接必须在默认约10min的Timeout后才被释放。因此收到短暂堆积的影响较大。同时外晚上1点备份时也会出现这种情况,容易产生误报。
注意后端连接数与后端活跃连接数不同,目前报警使用的是活跃连接数。后端活跃连接数通常在0~1,一些慢库在十几左右,离线库可能会达到20~30。但后端连接/进程数(不管活跃不活跃),通常均值可达50。后端连接数更为直观准确。
对于后端连接数,这里使用两个等级的报警:超过90持续3分钟P1,以及超过80持续10分钟P2,考虑到通常数据库最大连接数为100。这样做可以以尽可能低的误报率检测到雪崩堆积。
# num of backend exceed 90 for 3m
- alert: PG_BACKEND_HIGH
expr: sum(pg_db_numbackends) by (node) > 90
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres Backend Number High: {{$labels.instance}}"
description: "numbackend = {{ $value }} {{$labels.instance}}"
# num of backend exceed 80 for 10m (avoid pgbouncer jam false alert)
- alert: PG_BACKEND_WARN
expr: sum(pg_db_numbackends) by (node) > 80
for: 10m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres Backend Number Warn: {{$labels.instance}}"
description: "numbackend = {{ $value }} {{$labels.instance}}"
空闲事务
目前监控使用IDEL In Xact的绝对数量作为报警条件,其实 Idle In Xact的最长持续时间可能会更有意义。因为这种现象其实已经被后端连接数覆盖了。长时间的空闲是我们真正关注的,因此这里使用所有空闲事务中最高的闲置时长作为报警指标。设置3分钟为P2报警阈值。经常出现IDLE的非Offline库有:moderation, location, stats,sms, device, moderationdevice
# max idle xact duration exceed 3m
- alert: PG_IDLE_XACT
expr: pg_activity_max_duration{instance!~".*offline.*", state=~"^idle in transaction.*"} > 180
for: 3m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres Long Idle Transaction: {{$labels.instance}}"
description: "duration = {{ $value }} {{$labels.instance}}"
资源报警
CPU, 磁盘,AGE
默认清理年龄为2亿,超过10Y报P1,既留下了充分的余量,又不至于让人忽视。
# age wrap around (progress in half 10Y) triggers a P1 alert
- alert: PG_XID_WRAP
expr: pg_database_age{} > 1000000000
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres XID Wrap Around: {{$labels.instance}}"
description: "age = {{ $value }} {{$labels.instance}}"
磁盘和CPU由运维配置,不变
流量
因为各个业务的负载情况不一,为流量指标设置绝对值是相对困难的。这里只对TPS和Rollback设置绝对值指标。而且较为宽松。
Rollback OPS超过4则发出P3警告,TPS超过24000发P2,超过30000发P1
# more than 30k TPS lasts for 1m triggers a P1 (pgbouncer bottleneck)
- alert: PG_TPS_HIGH
expr: rate(pg_db_xact_total{}[1m]) > 30000
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres TPS High: {{$labels.instance}} {{$labels.datname}}"
description: "TPS = {{ $value }} {{$labels.instance}}"
# more than 24k TPS lasts for 3m triggers a P2
- alert: PG_TPS_WARN
expr: rate(pg_db_xact_total{}[1m]) > 24000
for: 3m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres TPS Warning: {{$labels.instance}} {{$labels.datname}}"
description: "TPS = {{ $value }} {{$labels.instance}}"
# more than 4 rollback per seconds lasts for 5m
- alert: PG_ROLLBACK_WARN
expr: rate(pg_db_xact_rollback{}[1m]) > 4
for: 5m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres Rollback Warning: {{$labels.instance}}"
description: "rollback per sec = {{ $value }} {{$labels.instance}}"
QPS的指标与业务高度相关,因此不适合配置绝对值,可以为QPS突增配置一个报警项
短时间(和10分钟)前比突增30%会触发一个P2警报,同时避免小QPS下的突发流量,设置一个绝对阈值10k
# QPS > 10000 and have a 30% inc for 3m triggers P2 alert
- alert: PG_QPS_BURST
expr: sum by(datname,instance)(rate(pgbouncer_stat_total_query_count{datname!="pgbouncer"}[1m]))/sum by(datname,instance) (rate(pgbouncer_stat_total_query_count{datname!="pgbouncer"}[1m] offset 10m)) > 1.3 and sum by(datname,instance) (rate(pgbouncer_stat_total_query_count{datname!="pgbouncer"}[1m])) > 10000
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P2 Pgbouncer QPS Burst 30% and exceed 10000: {{$labels.instance}}"
description: "qps = {{ $value }} {{$labels.instance}}"
Prometheus报警规则
完整的报警规则详见:参考-报警规则
5.1 - 系统架构
介绍Pigsty的系统架构
Pigsty的监控系统部分完全基于开源组件构建,核心组件包括:
示例
以Pigsty附带的四节点沙箱环境为例,Pigsty中涉及的主要组件如下所示。
从数据库集群的逻辑角度来看:
5.2 - 供给方案
介绍供给方案的概念,用途
所谓供给方案(Provisioning Solution),指的是一套向用户交付数据库服务与监控系统的系统。
供给方案不是数据库,而是数据库工厂:
用户向供给系统提交一份配置,供给系统便会按照用户所需的规格在环境中创建出所需的数据库集群来。
这比较类似于向Kubernetes提交YAML文件,创建所需的各类资源。
定义数据库集群
例如,以下配置信息声明了一套名为pg-test的PostgreSQL数据库集群。
#-----------------------------
# cluster: pg-test
#-----------------------------
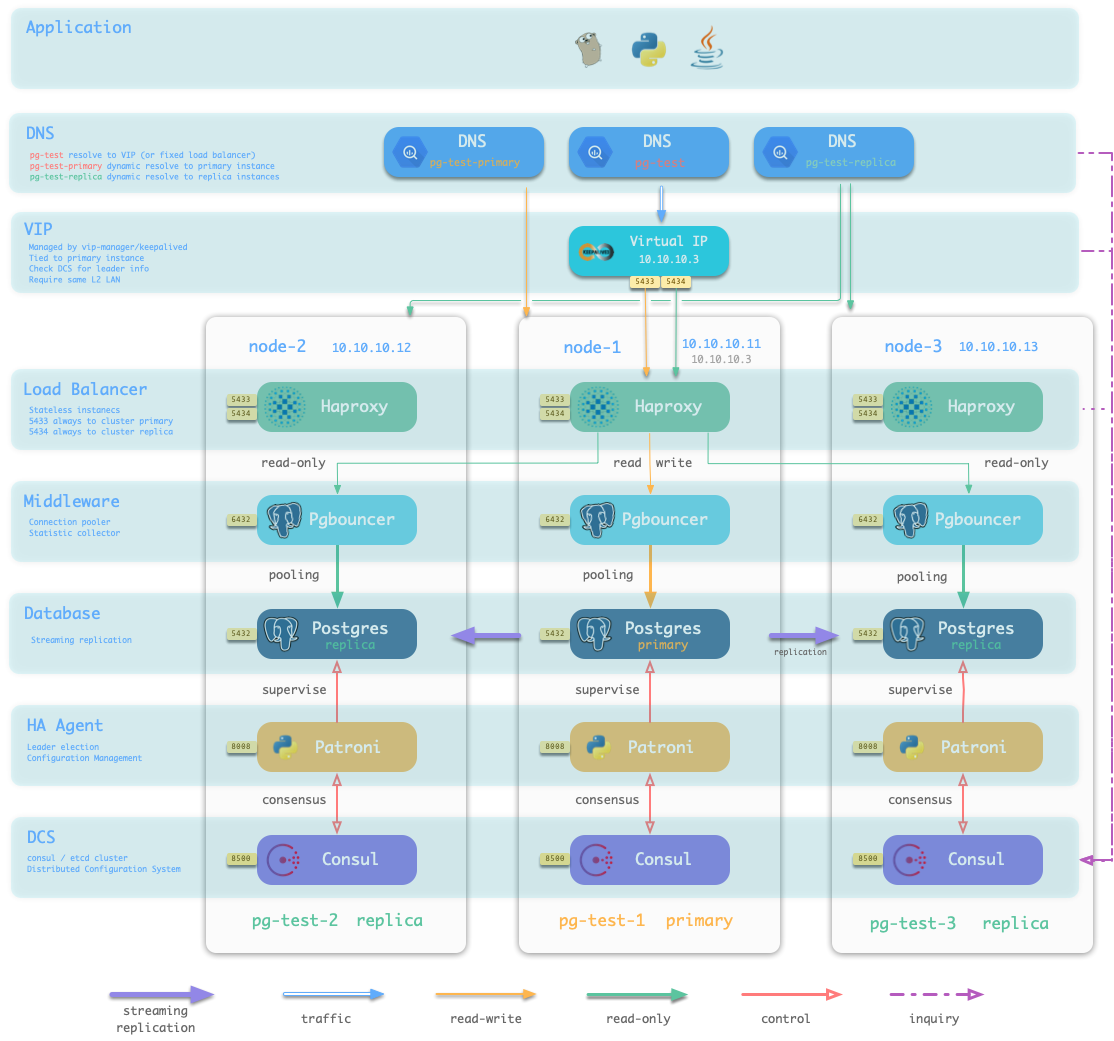
pg-test: # define cluster named 'pg-test'
# - cluster members - #
hosts:
10.10.10.11: {pg_seq: 1, pg_role: replica, ansible_host: node-1}
10.10.10.12: {pg_seq: 2, pg_role: primary, ansible_host: node-2}
10.10.10.13: {pg_seq: 3, pg_role: replica, ansible_host: node-3}
# - cluster configs - #
vars:
# basic settings
pg_cluster: pg-test # define actual cluster name
pg_version: 13 # define installed pgsql version
node_tune: tiny # tune node into oltp|olap|crit|tiny mode
pg_conf: tiny.yml # tune pgsql into oltp/olap/crit/tiny mode
pg_users:
- username: test
password: test
comment: default test user
groups: [ dbrole_readwrite ] # dborole_admin|dbrole_readwrite|dbrole_readonly
pg_databases: # create a business database 'test'
- name: test
extensions: [{name: postgis}] # create extra extension postgis
parameters: # overwrite database meta's default search_path
search_path: public,monitor
pg_default_database: test # default database will be used as primary monitor target
# proxy settings
vip_enabled: true # enable/disable vip (require members in same LAN)
vip_address: 10.10.10.3 # virtual ip address
vip_cidrmask: 8 # cidr network mask length
vip_interface: eth1 # interface to add virtual ip
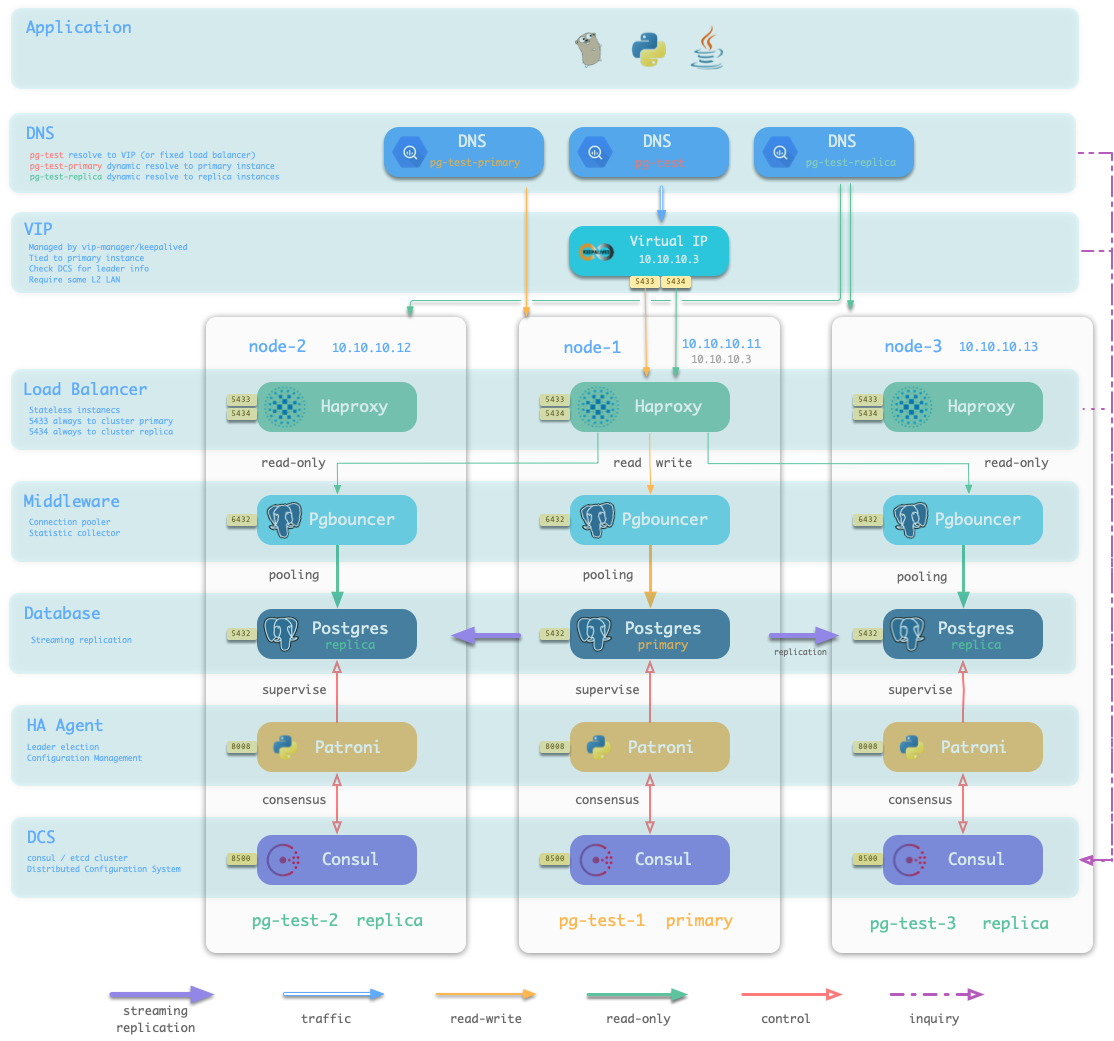
当我们执行 数据库供给 脚本 ./pgsql.yml 时,供给系统会根据清单中的定义,在10.10.10.11,10.10.10.12,10.10.10.13这三台机器上生成一主两从的PostgreSQL集群pg-test。并创建名为test的用户与数据库。同时,Pigsty还会根据要求,声明一个10.10.10.3的VIP绑定在集群的主库上面。结构如下图所示。
定义基础设施
您能够定义的不仅仅是数据库集群,还包括了整个基础设施。
Pigsty通过130+个变量实现了对数据库运行时环境的完整表述。
详细的可配置项,请参考 配置指南
供给方案的职责
供给方案通常只负责集群的创建。一旦集群创建完毕,日常的管理应当由管控平台负责。
尽管如此,Pigsty目前不包含管控平台部分,因此也提供了简单的资源回收销毁脚本,并亦可用于资源的更新与管理。但须知此并非供给方案的本职工作。
5.3 - 高可用
介绍可用性的概念,以及Pigsty在高可用上的实践
可用性的概念
人们对于一个东西是否可靠,都有一个直观的想法。人们对可靠软件的典型期望包括:
- 应用程序表现出用户所期望的功能。
- 允许用户犯错,允许用户以出乎意料的方式使用软件。
- 在预期的负载和数据量下,性能满足要求。
- 系统能防止未经授权的访问和滥用。
如果所有这些在一起意味着“正确工作”,那么可以把可靠性粗略理解为“即使出现问题,也能继续正确工作”。
造成错误的原因叫做故障(fault),能预料并应对故障的系统特性可称为容错(fault-tolerant)或韧性(resilient)。“容错”一词可能会产生误导,因为它暗示着系统可以容忍所有可能的错误,但在实际中这是不可能的。比方说,如果整个地球(及其上的所有服务器)都被黑洞吞噬了,想要容忍这种错误,需要把网络托管到太空中——这种预算能不能批准就祝你好运了。所以在讨论容错时,只有谈论特定类型的错误才有意义。
注意故障(fault)不同于失效(failure)【2】。故障通常定义为系统的一部分状态偏离其标准,而失效则是系统作为一个整体停止向用户提供服务。故障的概率不可能降到零,因此最好设计容错机制以防因故障而导致失效。本书中我们将介绍几种用不可靠的部件构建可靠系统的技术。
反直觉的是,在这类容错系统中,通过故意触发来提高故障率是有意义的,例如:在没有警告的情况下随机地杀死单个进程。许多高危漏洞实际上是由糟糕的错误处理导致的【3】,因此我们可以通过故意引发故障来确保容错机制不断运行并接受考验,从而提高故障自然发生时系统能正确处理的信心。Netflix公司的Chaos Monkey【4】就是这种方法的一个例子。
尽管比起阻止错误(prevent error),我们通常更倾向于容忍错误。但也有预防胜于治疗的情况(比如不存在治疗方法时)。安全问题就属于这种情况。例如,如果攻击者破坏了系统,并获取了敏感数据,这种事是撤销不了的。但本书主要讨论的是可以恢复的故障种类,正如下面几节所述。
硬件故障
当想到系统失效的原因时,硬件故障(hardware faults)总会第一个进入脑海。硬盘崩溃、内存出错、机房断电、有人拔错网线……任何与大型数据中心打过交道的人都会告诉你:一旦你拥有很多机器,这些事情总会发生!
据报道称,硬盘的 平均无故障时间(MTTF mean time to failure) 约为10到50年【5】【6】。因此从数学期望上讲,在拥有10000个磁盘的存储集群上,平均每天会有1个磁盘出故障。
为了减少系统的故障率,第一反应通常都是增加单个硬件的冗余度,例如:磁盘可以组建RAID,服务器可能有双路电源和热插拔CPU,数据中心可能有电池和柴油发电机作为后备电源,某个组件挂掉时冗余组件可以立刻接管。这种方法虽然不能完全防止由硬件问题导致的系统失效,但它简单易懂,通常也足以让机器不间断运行很多年。
直到最近,硬件冗余对于大多数应用来说已经足够了,它使单台机器完全失效变得相当罕见。只要你能快速地把备份恢复到新机器上,故障停机时间对大多数应用而言都算不上灾难性的。只有少量高可用性至关重要的应用才会要求有多套硬件冗余。
但是随着数据量和应用计算需求的增加,越来越多的应用开始大量使用机器,这会相应地增加硬件故障率。此外在一些云平台(如亚马逊网络服务(AWS, Amazon Web Services))中,虚拟机实例不可用却没有任何警告也是很常见的【7】,因为云平台的设计就是优先考虑灵活性(flexibility)和弹性(elasticity)[^i],而不是单机可靠性。
如果在硬件冗余的基础上进一步引入软件容错机制,那么系统在容忍整个(单台)机器故障的道路上就更进一步了。这样的系统也有运维上的便利,例如:如果需要重启机器(例如应用操作系统安全补丁),单服务器系统就需要计划停机。而允许机器失效的系统则可以一次修复一个节点,无需整个系统停机。
软件错误
我们通常认为硬件故障是随机的、相互独立的:一台机器的磁盘失效并不意味着另一台机器的磁盘也会失效。大量硬件组件不可能同时发生故障,除非它们存在比较弱的相关性(同样的原因导致关联性错误,例如服务器机架的温度)。
另一类错误是内部的系统性错误(systematic error)【7】。这类错误难以预料,而且因为是跨节点相关的,所以比起不相关的硬件故障往往可能造成更多的系统失效【5】。例子包括:
- 接受特定的错误输入,便导致所有应用服务器实例崩溃的BUG。例如2012年6月30日的闰秒,由于Linux内核中的一个错误,许多应用同时挂掉了。
- 失控进程会用尽一些共享资源,包括CPU时间、内存、磁盘空间或网络带宽。
- 系统依赖的服务变慢,没有响应,或者开始返回错误的响应。
- 级联故障,一个组件中的小故障触发另一个组件中的故障,进而触发更多的故障【10】。
导致这类软件故障的BUG通常会潜伏很长时间,直到被异常情况触发为止。这种情况意味着软件对其环境做出了某种假设——虽然这种假设通常来说是正确的,但由于某种原因最后不再成立了【11】。
虽然软件中的系统性故障没有速效药,但我们还是有很多小办法,例如:仔细考虑系统中的假设和交互;彻底的测试;进程隔离;允许进程崩溃并重启;测量、监控并分析生产环境中的系统行为。如果系统能够提供一些保证(例如在一个消息队列中,进入与发出的消息数量相等),那么系统就可以在运行时不断自检,并在出现差异(discrepancy) 时报警【12】。
人为错误
设计并构建了软件系统的工程师是人类,维持系统运行的运维也是人类。即使他们怀有最大的善意,人类也是不可靠的。举个例子,一项关于大型互联网服务的研究发现,运维配置错误是导致服务中断的首要原因,而硬件故障(服务器或网络)仅导致了10-25%的服务中断【13】。
尽管人类不可靠,但怎么做才能让系统变得可靠?最好的系统会组合使用以下几种办法:
- 以最小化犯错机会的方式设计系统。例如,精心设计的抽象、API和管理后台使做对事情更容易,搞砸事情更困难。但如果接口限制太多,人们就会忽略它们的好处而想办法绕开。很难正确把握这种微妙的平衡。
- 将人们最容易犯错的地方与可能导致失效的地方解耦(decouple)。特别是提供一个功能齐全的非生产环境沙箱(sandbox),使人们可以在不影响真实用户的情况下,使用真实数据安全地探索和实验。
- 在各个层次进行彻底的测试【3】,从单元测试、全系统集成测试到手动测试。自动化测试易于理解,已经被广泛使用,特别适合用来覆盖正常情况中少见的边缘场景(corner case)。
- 允许从人为错误中简单快速地恢复,以最大限度地减少失效情况带来的影响。 例如,快速回滚配置变更,分批发布新代码(以便任何意外错误只影响一小部分用户),并提供数据重算工具(以备旧的计算出错)。
- 配置详细和明确的监控,比如性能指标和错误率。 在其他工程学科中这指的是遥测(telemetry)。 (一旦火箭离开了地面,遥测技术对于跟踪发生的事情和理解失败是至关重要的。)监控可以向我们发出预警信号,并允许我们检查是否有任何地方违反了假设和约束。当出现问题时,指标数据对于问题诊断是非常宝贵的。
- 良好的管理实践与充分的培训——一个复杂而重要的方面,但超出了本书的范围。
可靠性有多重要?
可靠性不仅仅是针对核电站和空中交通管制软件而言,我们也期望更多平凡的应用能可靠地运行。商务应用中的错误会导致生产力损失(也许数据报告不完整还会有法律风险),而电商网站的中断则可能会导致收入和声誉的巨大损失。
即使在“非关键”应用中,我们也对用户负有责任。试想一位家长把所有的照片和孩子的视频储存在你的照片应用里【15】。如果数据库突然损坏,他们会感觉如何?他们可能会知道如何从备份恢复吗?
在某些情况下,我们可能会选择牺牲可靠性来降低开发成本(例如为未经证实的市场开发产品原型)或运营成本(例如利润率极低的服务),但我们偷工减料时,应该清楚意识到自己在做什么。
一、意义
- 显著提高系统整体可用性,提高RTO与RPO水平。
- 极大提高运维灵活性与可演化性,可以通过主动切换进行滚动升级,灰度停机维护。
- 极大提高系统可维护性,自动维护域名,服务,角色,机器,监控等系统间的一致性。显著减少运维工作量,降低管理成本
二、目标
当我们在说高可用时,究竟在说什么?Several nines ?
说到底,对于传统单领导者数据库来说,核心问题是就是故障切换,是领导权力交接的问题。
目标层次
- L0,手工操作,完全通过DBA人工介入,手工操作完成故障切换(十几分钟到小时级)
- L1,辅助操作,有一系列手工脚本,完成选主,拓扑切换,流量切换等操作(几分钟)
- L2,半自动化,自动检测,人工决策,自动操作。(1分钟)
- L3,全自动化:自动检测,自动决策,自动操作。(10s)
关键指标
- 允许进行日常Failover与Switchover操作,不允许出现脑裂。
- 无需客户端介入,提供代理切换机制,基于流复制,不依赖特殊硬件。
- 域名解析,VIP流量切换,服务发现,监控适配都需要与自动故障切换对接,做到自动化。
- 支持PG 10~12版本与CentOS 7,不会给云原生改造埋坑。
交付方式
- 沙盒模型,展示期待的部署架构与状态
- 调整方案,说明如何将现有环境调整至理想状态。
三、效果
场景演示
集群状况介绍
- 主库URL:
postgres://dbuser_test:dbuser_test@testdb:5555/testdb
- 从库URL:
postgres://dbuser_test:dbuser_test@testdb:5556/testdb
HA的两个核心场景:
故障切换的四个核心问题:
- 故障检测(Lease, TTL,Patroni向DCS获取Leader Key)
- Fencing(Patroni demote,kill PG进程,或通过Watchdog直接重启)
- 拓扑调整(通过DCS选主,其他从库从DCS获取新主库信息,修改自身复制源并重启生效)
- 流量切换(监听选主事件,通知网络层修改解析)
Patroni原理:故障检测
- 基于DCS判定
- 心跳包保活
- Leader Key Lease
- 秦失其鹿,天下共逐之。
Patroni原理:Fencing
Patroni原理:选主
- The king is dead, long live the king
- 先入关者王
流量切换原理
搭建环境
https://github.com/Vonng/pigsty
五、细节,问题,与风险
场景演示
- Switchover�
- Standby Down
- Patroni Down
- Postgres Down
- Accidentally Promote
- Primary Down
- Failover
- DCS Down
- DCS Service Down
- DCS Primary Client Down
- DCS Standby Client Down
- Fencing And corner cases
- Standby Cluster
- Sync Standby
- Takeover existing cluster
问题探讨
关键问题:DCS的SLA如何保障?
==在自动切换模式下,如果DCS挂了,当前主库会在retry_timeout 后Demote成从库,导致所有集群不可写==。
作为分布式共识数据库,Consul/Etcd是相当稳健的,但仍必须确保DCS的SLA高于DB的SLA。
解决方法:配置一个足够大的retry_timeout,并通过几种以下方式从管理上解决此问题。
- SLA确保DCS一年的不可用时间短于该时长
- 运维人员能确保在
retry_timeout之内解决DCS Service Down的问题。
- DBA能确保在
retry_timeout之内将关闭集群的自动切换功能(打开维护模式)。
可以优化的点? 添加绕开DCS的P2P检测,如果主库意识到自己所处的分区仍为Major分区,不触发操作。
具体来说,当节点与DCS失联,节点应当首先执行自己的P2P检测协议,判断是不是DCS本身的故障,如果是DCS本身的故障,则应当拒绝角色切换,或者直接进入维护模式,保持现状。
关键问题:HA策略,RPO优先或RTO优先?
可用性与一致性谁优先?例如,普通库RTO优先,金融支付类RPO优先。
普通库允许紧急故障切换时丢失极少量数据(阈值可配置,例如最近1M写入)
与钱相关的库不允许丢数据,相应地在故障切换时需要更多更审慎的检查或人工介入。
关键问题:Fencing机制,是否允许关机?
在正常情况下,Patroni会在发生Leader Change时先执行Primary Fencing,通过杀掉PG进程的方式进行。
但在某些极端情况下,比如vm暂停,软件Bug,或者极高负载,有可能没法成功完成这一点。那么就需要通过重启机器的方式一了百了。是否可以接受?在极端环境下会有怎样的表现?
关键操作:选主之后
选主之后要记得存盘。手工做一次Checkpoint确保万无一失。
关键问题:流量切换怎样做,2层,4层,7层
- 2层:VIP漂移
- 4层:Haproxy分发
- 7层:DNS域名解析
关键问题:一主一从的特殊场景
- 2层:VIP漂移
- 4层:Haproxy分发
- 7层:DNS域名解析
切换流程细节
主动切换流程
假设集群包括一台主库P,n台从库S,所有从库直接挂载在主库上。
- 检测:主动切换不需要检测故障
- 选主:人工从集群中选择复制延迟最低的从库,将其作为候选主库(C)andidate。
- 拓扑调整
- 修改主库P配置,使得C成为同步从库,使切换RTO = 0。
- 重定向其他从库,将其
primary_conninfo指向C,作为级连从库,滚动重启生效。
- 流量切换:需要快速自动化执行以下步骤
- Fencing P,停止当前主库P,视流量来源决定手段狠辣程度
- PAUSE Pgbouncer连接池
- 修改P的HBA文件并Reload
- 停止Postgres服务。
- 确认无法写入
- Promote C:提升候选主库C为新主库
- 移除standby.signal 或 recovery.conf。执行promote
- 如果Promote失败,重启P完成回滚。
- 如果Promote成功,执行以下任务:
- 自动生成候选主库C的新角色域名:
.primary.
- 调整集群主库域名/VIP解析:
primary. ,指向C
- 调整集群从库域名/VIP解析:
standby.,摘除C(一主一从除外)
- 根据新的角色域名重置监控(修改Consul Node名称并重启)
- Rewind P:(可选)将旧主库Rewind后作为新从库
- 运行
pg_rewind,如果成功则继续,如果失败则直接重做从库。
- 修改
recovery.conf(12-)|postgresql.auto.conf(12),将其primary_conninfo指向C
- 自动生成P的新角色域名:
< max(standby_sequence) + 1>.standby.
- 集群从库域名/VIP解析变更:
standby.,向S中添加P,承接读流量
- 根据角色域名重置监控
自动切换流程
自动切换的核心区别在于主库不可用。如果主库可用,那么完全同主动切换一样即可。
自动切换相比之下要多了两个问题,即检测与选主的问题,同时拓扑调整也因为主库不可用而有所区别。
- 检测
(网络不可达,端口拒绝连接,进程消失,无法写入,多个从库上的WAL Receiver断开)
- 实现:检测可以使用主动/定时脚本,也可以直接访问
pg_exporter,或者由Agent定期向DCS汇报。
- 触发:主动式检测触发,或监听DCS事件。触发结果可以是调用中控机上的HA脚本进行集中式调整,也可以由Agent进行本机操作。
- 选主
- Fencing P:同手动切换,因为自动切换中主库不可用,无法修改同步提交配置,因此存在RPO > 0 的可能性。
- 遍历所有可达从库,找出LSN最大者,选定为C,最小化RPO。
- 流量切换:需要快速自动化执行以下步骤
- Promote C:提升候选主库C为新主库
- 移除standby.signal 或 recovery.conf。执行promote
- 自动生成候选主库C的新角色域名:
.primary.
- 调整集群主库域名/VIP解析:
primary. ,指向C
- 调整集群从库域名/VIP解析:
standby.,摘除C(一主一从除外)
- 根据新的角色域名重置监控(修改Consul Node名称并重启)
- 拓扑调整
- 重定向其他从库,将其
primary_conninfo指向C,作为级连从库,滚动重启生效,并追赶新主库C。
- 如果使用一主一从,之前C仍然承接读流量,则拓扑调整完成后将C摘除。
- 修复旧主库P(如果是一主一从配置且读写负载单台C撑不住,则需要立刻进行,否则这一步不紧急)
- 修复有以下两种方式:Rewind,Remake
- Rewind P:(可选)将旧主库Rewind后作为新从库(如果只有一主一从则是必选)
- 运行
pg_rewind,如果成功则继续,如果失败则直接重做从库。
- 修改
recovery.conf(12-)|postgresql.auto.conf(12),将其primary_conninfo指向C
- 自动生成P的新角色域名:
< max(standby_sequence) + 1>.standby.
- 集群从库域名/VIP解析变更:
standby.,向S中添加P,承接读流量
- 根据角色域名重置监控
- Remake P:
- 以新角色域名
< max(standby_sequence) + 1>.standby.向集群添加新从库。