故障
- 故障档案:时间回溯导致的Patroni故障
- 故障档案:PG安装Extension导致无法连接
- 故障档案:pg_dump导致的连接池污染
- PostgreSQL数据页面损坏修复
- 故障档案:PostgreSQL事务号回卷
- 故障档案:序列号消耗过快导致整型溢出
- 故障档案:移除负载导致过载
故障档案:时间回溯导致的Patroni故障
【草稿】
机器因为故障重启,NTP服务在PG启动后修复了PG的时间,导致Patroni无法启动。
Patroni中的故障信息如下所示。
patroni 进程启动时间和pid时间不一致。就会认为:postgres is not running。
两个时间相差超过30秒。patroni就尿了。
还发现了Patroni里的一个BUG:https://github.com/zalando/patroni/issues/811
错误信息里两个时间戳打反了。
故障档案:PG安装Extension导致无法连接
今天遇到一个比较有趣的Case,客户报告说数据库连不上了。报这个错:
psql: FATAL: could not load library "/export/servers/pgsql/lib/pg_hint_plan.so": /export/servers/pgsql/lib/pg_hint_plan.so: undefined symbol: RINFO_IS_PUSHED_DOWN
当然,这种错误一眼就知道是插件没编译好,报符号找不到。因此数据库后端进程在启动时尝试加载pg_hint_plan插件时就GG了,报FATAL错误直接退出。
通常来说这个问题还是比较好解决的,这种额外的扩展通常都是在shared_preload_libraries中指定的,只要把这个扩展名称去掉就好了。
结果……
客户说是通过ALTER ROLE|DATABASE SET session_preload_libraries = pg_hint_plan的方式来启用扩展的。
这两条命令会在使用特定用户,或连接到特定数据库时覆盖系统默认参数,去加载pg_hint_plan插件。
ALTER DATABASE postgres SET session_preload_libraries = pg_hint_plan;
ALTER ROLE postgres SET session_preload_libraries = pg_hint_plan;
如果是这样的话,也是可以解决的,通常来说只要有其他的用户或者其他的数据库可以正常登陆,就可以通过ALTER TABLE语句把这两行配置给去掉。
但坏事就坏在,所有的用户和数据库都配了这个参数,以至于没有任何一条连接能连到数据库了。
这种情况下,数据库就成了植物人状态,postmaster还活着,但任何新创建的后端服务器进程都会因为扩展失效自杀……。即使dropdb这种外部自带的二进制命令也无法工作。
于是……
无法建立到数据库的连接,那么常规手段就都失效了……,只能Dirty hack了。
如果我们从二进制层面把用户和数据库级别的配置项给抹掉,那么就可以连接到数据库,把扩展给清理掉了。
DB与Role级别的配置存储在系统目录pg_db_role_setting中,这个表有着固定的OID = 2964,存储在数据目录下global/2964里。关闭数据库,使用二进制编辑器打开pg_db_role_setting对应的文件
# vim打开后使用 :%!xxd 编辑二进制
# 编辑完成后使用 :%!xxd -r转换回二进制,再用:wq保存
vi ${PGDATA}/global/2964

这里,将所有的pg_hint_plan字符串都替换成等长的^@二进制零字符即可。当然如果不在乎原来的配置,更省事的做法是直接把这个文件截断成零长文件。
重启数据库,终于又能连接上了。
复现
这个问题复现起来也非常简单,初始化一个新数据库实例
initdb -D /pg/test -U postgres && pg_ctl -D /pg/test start
然后执行以下语句,就可以体会这种酸爽了。
psql postgres postgres -c 'ALTER ROLE postgres SET session_preload_libraries = pg_hint_plan;'
教训……
- 安装扩展后,一定要先验证扩展本身可以正常工作,再启用扩展
- 凡事留一线,日后好相见:一个紧急备用的纯洁的su,或者一个无污染的可连接数据库,都不至于这么麻烦。
故障档案:pg_dump导致的连接池污染
PostgreSQL很棒,但这并不意味着它是Bug-Free的。这一次在线上环境中,我又遇到了一个很有趣的Case:由pg_dump导致的线上故障。这是一个非常微妙的Bug,由Pgbouncer,search_path,以及特殊的pg_dump操作所触发。
背景知识
连接污染
在PostgreSQL中,每条数据库连接对应一个后端进程,会持有一些临时资源(状态),在连接结束时会被销毁,包括:
- 本会话中修改过的参数。
RESET ALL; - 准备好的语句。
DEALLOCATE ALL - 打开的游标。
CLOSE ALL; - 监听的消息信道。
UNLISTEN * - 执行计划的缓存。
DISCARD PLANS; - 预分配的序列号值及其缓存。
DISCARD SEQUENCES; - 临时表。
DISCARD TEMP
Web应用会频繁建立大量的数据库连接,故在实际应用中通常都会使用连接池,复用连接,以减小连接创建与销毁的开销。除了使用各种语言/驱动内置的连接池外,Pgbouncer是最常用的第三方中间件连接池。Pgbouncer提供了一种Transaction Pooling的模式,即:每当客户端事务开始时,连接池会为客户端连接分配一个服务端连接,当事务结束时,服务端连接会被放回到池中。
事务池化模式也存在一些问题,例如连接污染。当某个客户端修改了连接的状态,并将该连接放回池中,其他的应用遍可能受到非预期的影响。如下图所示:
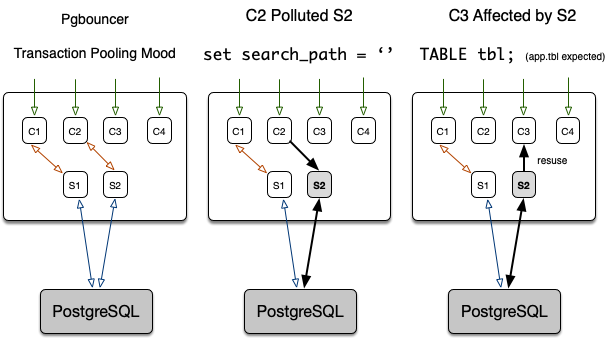
假设有四条客户端连接(前端连接)C1、C2、C3、C4,和两条服务器连接(后端连接)S1,S2。数据库默认搜索路径被配置为:app,$user,public,应用知道该假设,并使用SELECT * FROM tbl;的方式,来默认访问模式app下的表app.tbl。现在假设客户端C2在使用了服务器连接S2的过程中,执行了set search_path = ''清空了连接S2上的搜索路径。当S2被另一个客户端C3复用时,C3执行SELECT * FROM tbl时就会因为search_path中找不到对应的表而报错。
当客户端对于连接的假设被打破时,很容易出现各种错误。
故障排查
线上应用突然大量报错触发熔断,错误内容为大量的对象(表,函数)找不到。
第一直觉就是连接池被污染了:某个连接在修改完search_path之后将连接放回池中,当这个后端连接被其他前端连接复用时,就会出现找不到对象的情况。
连接至相应的Pool中,发现确实存在连接的search_path被污染的情况,某些连接的search_path被置空了,因此使用这些连接的应用就找不到对象了。
psql -p6432 somedb
# show search_path; \watch 0.1
在Pgbouncer中使用管理员账户执行RECONNECT命令,强制重连所有连接,search_path重置为默认值,问题解决。
reconnect somedb
不过问题就来了,究竟是什么应用修改了search_path呢?如果问题来源没有排查清楚,难免以后会重犯。有几种可能:业务代码修改,应用的驱动Bug,人工操作,或者连接池本身的Bug。嫌疑最大的当然是手工操作,有人如果使用生产账号用psql连到连接池,手工修改了search_path,然后退出,这个连接就会被放回到生产池中,导致污染。
首先检查数据库日志,发现报错的日志记录全都来自同一条服务器连接5c06218b.2ca6c,即只有一条连接被污染。找到这条连接开始持续报错的临界时刻:
cat postgresql-Tue.csv | grep 5c06218b.2ca6c
2018-12-04 14:44:42.766 CST,"xxx","xxx-xxx",182892,"127.0.0.1:60114",5c06218b.2ca6c,36,"SELECT",2018-12-04 14:41:15 CST,24/0,0,LOG,00000,"duration: 1067.392 ms statement: SELECT xxxx FROM x",,,,,,,,,"app - xx.xx.xx.xx:23962"
2018-12-04 14:45:03.857 CST,"xxx","xxx-xxx",182892,"127.0.0.1:60114",5c06218b.2ca6c,37,"SELECT",2018-12-04 14:41:15 CST,24/368400961,0,ERROR,42883,"function upsert_xxxxxx(xxx) does not exist",,"No function matches the given name and argument types. You might need to add explicit type casts.",,,,"select upsert_phone_plan('965+6628',1,0,0,0,1,0,'2018-12-03 19:00:00'::timestamp)",8,,"app - 10.191.160.49:46382"
这里5c06218b.2ca6c是该连接的唯一标识符,而后面的数字36,37则是该连接所产生日志的行号。一些操作并不会记录在日志中,但这里幸运的是,正常和出错的两条日志时间相差只有21秒,可以比较精确地定位故障时间点。
通过扫描所有白名单机器上该时刻的命令操作记录,精准定位到了一条执行记录:
pg_dump --host master.xxxx --port 6432 -d somedb -t sometable
嗯?pg_dump不是官方自带的工具吗,难道会修改search_path?不过直觉告诉我,还真不是没可能。例如我想起了一个有趣的行为,因为schema本质上是一个命名空间,因此位于不同schema内的对象可以有相同的名字。在老版本在使用-t转储特定表时,如果提供的表名参数不带schema前缀,pg_dump默认会默认转储所有同名的表。
查阅pg_dump的源码,发现还真有这种操作,以10.5版本为例,发现在setup_connection的时候,确实修改了search_path。
// src/bin/pg_dump/pg_dump.c line 287
int main(int argc, char **argv);
// src/bin/pg_dump/pg_dump.c line 681 main
setup_connection(fout, dumpencoding, dumpsnapshot, use_role);
// src/bin/pg_dump/pg_dump.c line 1006 setup_connection
PQclear(ExecuteSqlQueryForSingleRow(AH, ALWAYS_SECURE_SEARCH_PATH_SQL));
// include/server/fe_utils/connect.h
#define ALWAYS_SECURE_SEARCH_PATH_SQL \
"SELECT pg_catalog.set_config('search_path', '', false)"
Bug复现
接下来就是复现该BUG了。但比较奇怪的是,在使用PostgreSQL11的时候并没能复现出该Bug来,于是我看了一下肇事司机的全部历史记录,还原了其心路历程(发现pg_dump和服务器版本不匹配,来回折腾),使用不同版本的pg_dump终于复现了该BUG。
使用一个现成的数据库,名为data进行测试,版本为11.1。使用的Pgbouncer配置如下,为了便于调试,连接池的大小已经改小,只允许两条服务端连接。
[databases]
postgres = host=127.0.0.1
[pgbouncer]
logfile = /Users/vonng/pgb/pgbouncer.log
pidfile = /Users/vonng/pgb/pgbouncer.pid
listen_addr = *
listen_port = 6432
auth_type = trust
admin_users = postgres
stats_users = stats, postgres
auth_file = /Users/vonng/pgb/userlist.txt
pool_mode = transaction
server_reset_query =
max_client_conn = 50000
default_pool_size = 2
reserve_pool_size = 0
reserve_pool_timeout = 5
log_connections = 1
log_disconnections = 1
application_name_add_host = 1
ignore_startup_parameters = extra_float_digits
启动连接池,检查search_path,正常的默认配置。
$ psql postgres://vonng:123456@:6432/data -c 'show search_path;'
search_path
-----------------------
app, "$user", public
使用10.5版本的pg_dump,从6432端口发起Dump
/usr/local/Cellar/postgresql/10.5/bin/pg_dump \
postgres://vonng:123456@:6432/data \
-t geo.pois -f /dev/null
pg_dump: server version: 11.1; pg_dump version: 10.5
pg_dump: aborting because of server version mismatch
虽然Dump失败,但再次检查所有连接的search_path时,就会发现池里的连接已经被污染了,一条连接的search_path已经被修改为空
$ psql postgres://vonng:123456@:6432/data -c 'show search_path;'
search_path
-------------
(1 row)
解决方案
同时配置pgbouncer的server_reset_query以及server_reset_query_always参数,可以彻底解决此问题。
server_reset_query = DISCARD ALL
server_reset_query_always = 1
在TransactionPooling模式下,server_reset_query默认是不执行的,因此需要通过配置server_reset_query_always=1使每次事务执行完后强制执行DISCARD ALL清空连接的所有状态。不过,这样的配置是有代价的,DISCARD ALL实质上执行了以下操作:
SET SESSION AUTHORIZATION DEFAULT;
RESET ALL;
DEALLOCATE ALL;
CLOSE ALL;
UNLISTEN *;
SELECT pg_advisory_unlock_all();
DISCARD PLANS;
DISCARD SEQUENCES;
DISCARD TEMP;
如果每个事务后面都要多执行这些语句,确实会带来一些额外的性能开销。
当然,也有其他的方法,譬如从管理上解决,杜绝使用pg_dump访问6432端口的可能,将数据库账号使用专门的加密配置中心管理。或者要求业务方使用带schema限定名的name访问数据库对象。但都可能产生漏网之鱼,不如强制配置来的直接。
PostgreSQL数据页面损坏修复
PostgreSQL是一个很可靠的数据库,但是再可靠的数据库,如果碰上了不可靠的硬件,恐怕也得抓瞎。本文介绍了在PostgreSQL中,应对数据页面损坏的方法。
最初的问题
线上有一套统计库跑离线任务,业务方反馈跑SQL的时候碰上一个错误:
ERROR: invalid page in block 18858877 of relation base/16400/275852
看到这样的错误信息,第一直觉就是硬件错误导致的关系数据文件损坏,第一步要检查定位具体问题。
这里,16400是数据库的oid,而275852则是数据表的relfilenode,通常等于OID。
somedb=# select 275852::RegClass;
regclass
---------------------
dailyuseractivities
-- 如果relfilenode与oid不一致,则使用以下查询
somedb=# select relname from pg_class where pg_relation_filenode(oid) = '275852';
relname
---------------------
dailyuseractivities
(1 row)
定位到出问题的表之后,检查出问题的页面,这里错误提示区块号为18858877的页面出现问题。
somedb=# select * from dailyuseractivities where ctid = '(18858877,1)';
ERROR: invalid page in block 18858877 of relation base/16400/275852
-- 打印详细错误位置
somedb=# \errverbose
ERROR: XX001: invalid page in block 18858877 of relation base/16400/275852
LOCATION: ReadBuffer_common, bufmgr.c:917
通过检查,发现该页面无法访问,但该页面前后两个页面都可以正常访问。使用errverbose可以打印出错误所在的源码位置。搜索PostgreSQL源码,发现这个错误信息只在一处位置出现:https://github.com/postgres/postgres/blob/master/src/backend/storage/buffer/bufmgr.c。可以看到,错误发生在页面从磁盘加载到内存共享缓冲区时。PostgreSQL认为这是一个无效的页面,因此报错并中止事务。
/* check for garbage data */
if (!PageIsVerified((Page) bufBlock, blockNum))
{
if (mode == RBM_ZERO_ON_ERROR || zero_damaged_pages)
{
ereport(WARNING,
(errcode(ERRCODE_DATA_CORRUPTED),
errmsg("invalid page in block %u of relation %s; zeroing out page",
blockNum,
relpath(smgr->smgr_rnode, forkNum))));
MemSet((char *) bufBlock, 0, BLCKSZ);
}
else
ereport(ERROR,
(errcode(ERRCODE_DATA_CORRUPTED),
errmsg("invalid page in block %u of relation %s",
blockNum,
relpath(smgr->smgr_rnode, forkNum))));
}
进一步检查PageIsVerified函数的逻辑:
/* 这里的检查并不能保证页面首部是正确的,只是说它看上去足够正常
* 允许其加载至缓冲池中。后续实际使用该页面时仍然可能会出错,这也
* 是我们提供校验和选项的原因。*/
if ((p->pd_flags & ~PD_VALID_FLAG_BITS) == 0 &&
p->pd_lower <= p->pd_upper &&
p->pd_upper <= p->pd_special &&
p->pd_special <= BLCKSZ &&
p->pd_special == MAXALIGN(p->pd_special))
header_sane = true;
if (header_sane && !checksum_failure)
return true;
接下来就要具体定位问题了,那么第一步,首先要找到问题页面在磁盘上的位置。这其实是两个子问题:在哪个文件里,以及在文件里的偏移量地址。这里,关系文件的relfilenode是275852,在PostgreSQL中,每个关系文件都会被默认切割为1GB大小的段文件,并用relfilenode, relfilenode.1, relfilenode.2, …这样的规则依此命名。
因此,我们可以计算一下,第18858877个页面,每个页面8KB,一个段文件1GB。偏移量为18858877 * 2^13 = 154491920384。
154491920384 / (1024^3) = 143
154491920384 % (1024^3) = 946839552 = 0x386FA000
由此可得,问题页面位于第143个段内,偏移量0x386FA000处。
落实到具体文件,也就是${PGDATA}/base/16400/275852.143。
hexdump 275852.143 | grep -w10 386fa00
386f9fe0 003b 0000 0100 0000 0100 0000 4b00 07c8
386f9ff0 9b3d 5ed9 1f40 eb85 b851 44de 0040 0000
386fa000 0000 0000 0000 0000 0000 0000 0000 0000
*
386fb000 62df 3d7e 0000 0000 0452 0000 011f c37d
386fb010 0040 0003 0b02 0018 18f6 0000 d66a 0068
使用二进制编辑器打开并定位至相应偏移量,发现该页面的内容已经被抹零,没有抢救价值了。好在线上的数据库至少都是一主一从配置,如果是因为主库上的坏块导致的页面损坏,从库上应该还有原来的数据。在从库上果然能找到对应的数据:
386f9fe0:3b00 0000 0001 0000 0001 0000 004b c807 ;............K..
386f9ff0:3d9b d95e 401f 85eb 51b8 de44 4000 0000 =..^@...Q..D@...
386fa000:e3bd 0100 70c8 864a 0000 0400 f801 0002 ....p..J........
386fa010:0020 0420 0000 0000 c09f 7a00 809f 7a00 . . ......z...z.
386fa020:409f 7a00 009f 7a00 c09e 7a00 809e 7a00 @.z...z...z...z.
386fa030:409e 7a00 009e 7a00 c09d 7a00 809d 7a00 @.z...z...z...z.
当然,如果页面是正常的,在从库上执行读取操作就不会报错。因此可以直接通过CTID过滤把损坏的数据找回来。
到现在为止,数据虽然找回来,可以松一口气了。但主库上的坏块问题仍然需要处理,这个就比较简单了,直接重建该表,并从从库抽取最新的数据即可。有各种各样的方法,VACUUM FULL,pg_repack,或者手工重建拷贝数据。
不过,我注意到在判定页面有效性的代码中出现了一个从来没见过的参数zero_damaged_pages,查阅文档才发现,这是一个开发者调试用参数,可以允许PostgreSQL忽略损坏的数据页,将其视为全零的空页面。用WARNING替代ERROR。这引发了我的兴趣。毕竟有时候,对于一些粗放的统计业务,跑了几个小时的SQL因为一两条脏数据中断,恐怕要比错漏那么几条记录更令人抓狂。这个参数可不可以满足这样的需求呢?
zero_damaged_pages(boolean)PostgreSQL在检测到损坏的页面首部时通常会报告一个错误,并中止当前事务。将参数
zero_damaged_pages配置为on,会使系统取而代之报告一个WARNING,并将内存中的页面抹为全零。然而该操作会摧毁数据,也就是说损坏页面上的行全都会丢失。不过,这样做确实能允许你略过错误并从未损坏的页面中获取表中未受损的行。当出现软件或硬件导致的数据损坏时,该选项可用于恢复数据。通常情况下只有当您放弃从受损的页面中恢复数据时,才应当使用该选项。抹零的页面并不会强制刷回磁盘,因此建议在重新关闭该选项之前重建受损的表或索引。本选项默认是关闭的,且只有超级用户才能修改。
毕竟,当重建表之后,原来的坏块就被释放掉了。如果硬件本身没有提供坏块识别与筛除的功能,那么这就是一个定时炸弹,很可能将来又会坑到自己。不幸的是,这台机器上的数据库有14TB,用的16TB的SSD,暂时没有同类型的机器了。只能先苟一下,因此需要研究一下,这个参数能不能让查询在遇到坏页时自动跳过。
苟且的办法
如下,在本机搭建一个测试集群,配置一主一从。尝试复现该问题,并确定
# tear down
pg_ctl -D /pg/d1 stop
pg_ctl -D /pg/d2 stop
rm -rf /pg/d1 /pg/d2
# master @ port5432
pg_ctl -D /pg/d1 init
pg_ctl -D /pg/d1 start
psql postgres -c "CREATE USER replication replication;"
# slave @ port5433
pg_basebackup -Xs -Pv -R -D /pg/d2 -Ureplication
pg_ctl -D /pg/d2 start -o"-p5433"
连接至主库,创建样例表并插入555条数据,约占据三个页面。
-- psql postgres
DROP TABLE IF EXISTS test;
CREATE TABLE test(id varchar(8) PRIMARY KEY);
ANALYZE test;
-- 注意,插入数据之后一定要执行checkpoint确保落盘
INSERT INTO test SELECT generate_series(1,555)::TEXT;
CHECKPOINT;
现在,让我们模拟出现坏块的情况,首先找出主库中test表的对应文件。
SELECT pg_relation_filepath(oid) FROM pg_class WHERE relname = 'test';
base/12630/16385
$ hexdump /pg/d1/base/12630/16385 | head -n 20
0000000 00 00 00 00 d0 22 02 03 00 00 00 00 a0 03 c0 03
0000010 00 20 04 20 00 00 00 00 e0 9f 34 00 c0 9f 34 00
0000020 a0 9f 34 00 80 9f 34 00 60 9f 34 00 40 9f 34 00
0000030 20 9f 34 00 00 9f 34 00 e0 9e 34 00 c0 9e 36 00
0000040 a0 9e 36 00 80 9e 36 00 60 9e 36 00 40 9e 36 00
0000050 20 9e 36 00 00 9e 36 00 e0 9d 36 00 c0 9d 36 00
0000060 a0 9d 36 00 80 9d 36 00 60 9d 36 00 40 9d 36 00
0000070 20 9d 36 00 00 9d 36 00 e0 9c 36 00 c0 9c 36 00
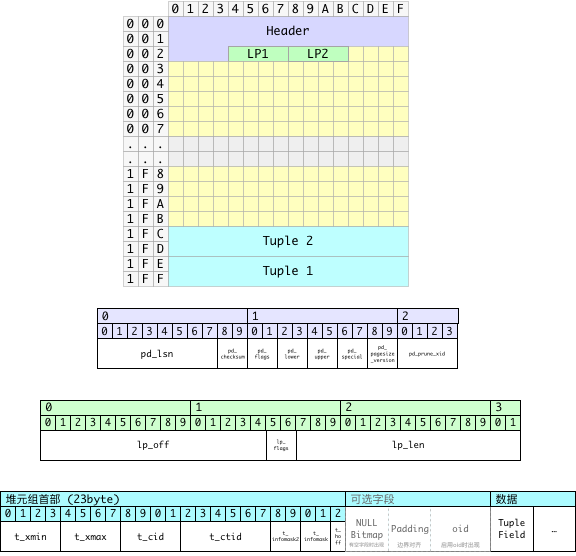
上面已经给出了PostgreSQL判断页面是否“正常”的逻辑,这里我们就修改一下数据页面,让页面变得“不正常”。页面的第12~16字节,也就是这里第一行的最后四个字节a0 03 c0 03,是页面内空闲空间上下界的指针。这里按小端序解释的意思就是本页面内,空闲空间从0x03A0开始,到0x03C0结束。符合逻辑的空闲空间范围当然需要满足上界小于等于下界。这里我们将上界0x03A0修改为0x03D0,超出下界0x03C0,也就是将第一行的倒数第四个字节由A0修改为D0。
# vim打开后使用 :%!xxd 编辑二进制
# 编辑完成后使用 :%!xxd -r转换回二进制,再用:wq保存
vi /pg/d1/base/12630/16385
# 查看修改后的结果。
$ hexdump /pg/d1/base/12630/16385 | head -n 2
0000000 00 00 00 00 48 22 02 03 00 00 00 00 d0 03 c0 03
0000010 00 20 04 20 00 00 00 00 e0 9f 34 00 c0 9f 34 00
这里,虽然磁盘上的页面已经被修改,但页面已经缓存到了内存中的共享缓冲池里。因此从主库上仍然可以正常看到页面1中的结果。接下来重启主库,清空其Buffer。不幸的是,当关闭数据库或执行检查点时,内存中的页面会刷写会磁盘中,覆盖我们之前编辑的结果。因此,首先关闭数据库,重新执行编辑后再启动。
pg_ctl -D /pg/d1 stop
vi /pg/d1/base/12630/16385
pg_ctl -D /pg/d1 start
psql postgres -c 'select * from test;'
ERROR: invalid page in block 0 of relation base/12630/16385
psql postgres -c "select * from test where id = '10';"
ERROR: invalid page in block 0 of relation base/12630/16385
psql postgres -c "select * from test where ctid = '(0,1)';"
ERROR: invalid page in block 0 of relation base/12630/16385
$ psql postgres -c "select * from test where ctid = '(1,1)';"
id
-----
227
可以看到,修改后的0号页面无法被数据库识别出来,但未受影响的页面1仍然可以正常访问。
虽然主库上的查询因为页面损坏无法访问了,这时候在从库上执行类似的查询,都可以正常返回结果
$ psql -p5433 postgres -c 'select * from test limit 2;'
id
----
1
2
$ psql -p5433 postgres -c "select * from test where id = '10';"
id
----
10
$ psql -p5433 postgres -c "select * from test where ctid = '(0,1)';"
id
----
1
(1 row)
接下来,让我们打开zero_damaged_pages参数,现在在主库上的查询不报错了。取而代之的是一个警告,页面0中的数据蒸发掉了,返回的结果从第1页开始。
postgres=# set zero_damaged_pages = on ;
SET
postgres=# select * from test;
WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
id
-----
227
228
229
230
231
第0页确实已经被加载到内存缓冲池里了,而且页面里的数据被抹成了0。
create extension pg_buffercache ;
postgres=# select relblocknumber,isdirty,usagecount from pg_buffercache where relfilenode = 16385;
relblocknumber | isdirty | usagecount
----------------+---------+------------
0 | f | 5
1 | f | 3
2 | f | 2
zero_damaged_pages参数需要在实例级别进行配置:
# 确保该选项默认打开,并重启生效
psql postgres -c 'ALTER SYSTEM set zero_damaged_pages = on;'
pg_ctl -D /pg/d1 restart
psql postgres -c 'show zero_damaged_pages;'
zero_damaged_pages
--------------------
on
这里,通过配置zero_damaged_pages,能够让主库即使遇到坏块,也能继续应付一下。
垃圾页面被加载到内存并抹零之后,如果执行检查点,这个全零的页面是否又会被重新刷回磁盘覆盖原来的数据呢?这一点很重要,因为脏数据也是数据,起码有抢救的价值。为了一时的方便产生永久性无法挽回的损失,那肯定也是无法接受的。
psql postgres -c 'checkpoint;'
hexdump /pg/d1/base/12630/16385 | head -n 2
0000000 00 00 00 00 48 22 02 03 00 00 00 00 d0 03 c0 03
0000010 00 20 04 20 00 00 00 00 e0 9f 34 00 c0 9f 34 00
可以看到,无论是检查点还是重启,这个内存中的全零页面并不会强制替代磁盘上的损坏页面,留下了抢救的希望,又能保证线上的查询可以苟一下。甚好,甚好。这也符合文档中的描述:“抹零的页面并不会强制刷回磁盘”。
微妙的问题
就当我觉得实验完成,可以安心的把这个开关打开先对付一下时。突然又想起了一个微妙的事情,主库和从库上读到的数据是不一样的,这就很尴尬了。
psql -p5432 postgres -Atqc 'select * from test limit 2;'
2018-11-29 22:31:20.777 CST [24175] WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
227
228
psql -p5433 postgres -Atqc 'select * from test limit 2;'
1
2
更尴尬的是,在主库上是看不到第0页中的元组的,也就是说主库认为第0页中的记录都不存在,因此,即使表上存在主键约束,仍然可以插入同一个主键的记录:
# 表中已经有主键 id = 1的记录了,但是主库抹零了看不到!
psql postgres -c "INSERT INTO test VALUES(1);"
INSERT 0 1
# 从从库上查询,夭寿了!主键出现重复了!
psql postgres -p5433 -c "SELECT * FROM test;"
id
-----
1
2
3
...
555
1
# id列真的是主键……
$ psql postgres -p5433 -c "\d test;"
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+----------------------+-----------+----------+---------
id | character varying(8) | | not null |
Indexes:
"test_pkey" PRIMARY KEY, btree (id)
如果把这个从库Promote成新的主库,这个问题在从库上依然存在:一条主键能返回两条记录!真是夭寿啊……。
此外,还有一个有趣的问题,VACUUM会如何处理这样的零页面呢?
# 对表进行清理
psql postgres -c 'VACUUM VERBOSE;'
INFO: vacuuming "public.test"
2018-11-29 22:18:05.212 CST [23572] WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
2018-11-29 22:18:05.212 CST [23572] WARNING: relation "test" page 0 is uninitialized --- fixing
WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
WARNING: relation "test" page 0 is uninitialized --- fixing
INFO: index "test_pkey" now contains 329 row versions in 5 pages
DETAIL: 0 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
VACUUM把这个页面“修好了”?但杯具的是,VACUUM自作主张修好了脏数据页,并不一定是一件好事…。因为当VACUUM完成修复时,这个页面就被视作一个普通的页面了,就会在CHECKPOINT时被刷写回磁盘中……,从而覆盖了原始的脏数据。如果这种修复并不是你想要的结果,那么数据就有可能会丢失。
总结
- 复制,备份是应对硬件损坏的最佳办法。
- 当出现数据页面损坏时,可以找到对应的物理页面,进行比较,尝试修复。
- 当页面损坏导致查询无法进行时,参数
zero_damaged_pages可以临时用于跳过错误。 - 参数
zero_damaged_pages极其危险 - 打开抹零时,损坏页面会被加载至内存缓冲池中并抹零,且在检查点时不会覆盖磁盘原页面。
- 内存中被抹零的页面会被VACUUM尝试修复,修复后的页面会被检查点刷回磁盘,覆盖原页面。
- 抹零页面内的内容对数据库不可见,因此可能会出现违反约束的情况出现。
故障档案:PostgreSQL事务号回卷
遇到一次磁盘坏块导致的事务回卷故障:
- 主库(PostgreSQL 9.3)磁盘坏块导致几张表上的VACUUM FREEZE执行失败。
- 无法回收老旧事务ID,导致整库事务ID濒临用尽,数据库进入自我保护状态不可用。
- 磁盘坏块导致手工VACUUM抢救不可行。
- 提升从库后,需要紧急VACUUM FREEZE才能继续服务,进一步延长了故障时间。
- 主库进入保护状态后提交日志(clog)没有及时复制到从库,从库产生存疑事务拒绝服务。
摘要
-
这是一个即将下线老旧库,疏于管理。坏块征兆在一周前就已经出现,没有及时跟进年龄。
-
通常AutoVacuum会保证很难出现这种故障,但一旦出现往往意味着祸不单行…让救火更加困难了……
背景
PostgreSQL实现了快照隔离(Snapshot Isolation),每个事务开始时都能获取数据库在该时刻的快照(也就是只能看到过去事务提交的结果,看不见后续事务提交的结果)。这一强大的功能是通过MVCC实现的,但也引入了额外复杂度,例如事务ID回卷问题。
事务ID(xid)是用于标识事务的32位无符号整型数值,递增分配,其中值0,1,2为保留值,溢出后回卷为3重新开始。事务ID之间的大小关系决定了事务的先后顺序。
/*
* TransactionIdPrecedes --- is id1 logically < id2?
*/
bool
TransactionIdPrecedes(TransactionId id1, TransactionId id2)
{
/*
* If either ID is a permanent XID then we can just do unsigned
* comparison. If both are normal, do a modulo-2^32 comparison.
*/
int32 diff;
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2))
return (id1 < id2);
diff = (int32) (id1 - id2);
return (diff < 0);
}
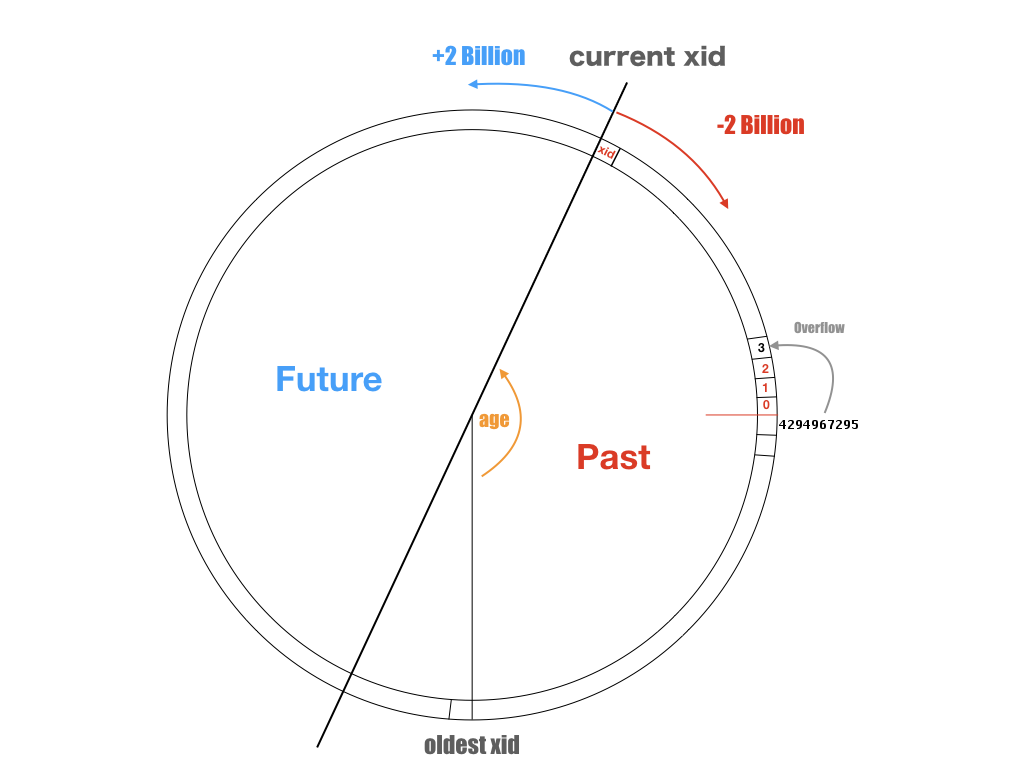
可以将xid的取值域视为一个整数环,但刨除0,1,2三个特殊值。0代表无效事务ID,1代表系统事务ID,2代表冻结事务ID。特殊的事务ID比任何普通事务ID小。而普通事务ID之间的比较可参见上图:它取决于两个事务ID的差值是否超出INT32_MAX。对任意一个事务ID,都有约21亿个位于过去的事务和21亿个位于未来的事务。
xid不仅仅存在于活跃的事务上,xid会影响所有的元组:事务会给自己影响的元组打上自己的xid作为记号。每个元组都会用(xmin, xmax)来标识自己的可见性,xmin 记录了最后写入(INSERT, UPDATE)该元组的事务ID,而xmax记录了删除或锁定该元组的事务ID。每个事务只能看见由先前事务提交(xmin < xid)且未被删除的元组(从而实现快照隔离)。
如果一个元组是由很久很久以前的事务产生的,那么在数据库的例行VACUUM FREEZE时,会找出当前活跃事务中最老的xid,将所有xmin < xid的元组的xmin标记为2,也就是冻结事务ID。这意味着这条元组跳出了这个比较环,比所有普通事务ID都要小,所以能被所有的事务看到。通过清理,数据库中最老的xid会不断追赶当前的xid,从而避免事务回卷。
数据库或表的年龄(age),定义为当前事务ID与数据库/表中存在最老的xid之差。最老的xid可能来自一个持续了几天的超长事务。也可能来自几天前老事务写入,但尚未被冻结的元组中。如果数据库的年龄超过了INT32_MAX,灾难性情况就发生了。过去的事务变成了未来的事务,过去事务写入的元组将变得不可见。
为了避免这种情况,需要避免超长事务与定期VACUUM FREEZE冻结老元组。如果单库在平均3万TPS的超高负载下,20亿个事务号一整天内就会用完。在这样的库上就无法执行一个超过一天的超长事务。而如果由于某种原因,自动清理工作无法继续进行,一天之内就可能遇到事务回卷。
9.4之后对FREEZE的机制进行了修改,FREEZE使用元组中单独的标记位来表示。
PostgreSQL应对事务回卷有自我保护机制。当临界事务号还剩一千万时,会进入紧急状态。
查询
查询当前所有表的年龄,SQL 语句如下:
SELECT c.oid::regclass as table_name,
greatest(age(c.relfrozenxid),age(t.relfrozenxid)) as age
FROM pg_class c
LEFT JOIN pg_class t ON c.reltoastrelid = t.oid
WHERE c.relkind IN ('r', 'm') order by 2 desc;
查询数据库的年龄,SQL语句如下:
SELECT *, age(datfrozenxid) FROM pg_database;
清理
执行VACUUM FREEZE可以冻结老旧事务的ID
set vacuum_cost_limit = 10000;
set vacuum_cost_delay = 0;
VACUUM FREEZE VERBOSE;
可以针对特定的表进行VACUUM FREEZE,抓主要矛盾。
问题
通常来说,PostgreSQL的AutoVacuum机制会自动执行FREEZE操作,冻结老旧事务的ID,从而降低数据库的年龄。因此一旦出现事务ID回卷故障,通常祸不单行,意味着vacuum机制可能被其他的故障挡住了。
目前遇到过三种触发事务ID回卷故障的情况
IDLE IN TRANSACTION
空闲事务会阻塞VACUUM FREEZE老旧元组。
解决方法很简单,干掉IDEL IN TRANSACTION的长事务然后执行VACUUM FREEZE即可。
存疑事务
clog损坏,或没有复制到从库,会导致相关表进入事务存疑状态,拒绝服务。
需要手工拷贝,或使用dd生成虚拟的clog来强行逃生。
磁盘/内存坏块
因为坏块导致的无法VACUUM比较尴尬。
需要通过二分法定位并跳过脏数据,或者干脆直接抢救从库。
注意事项
紧急抢救的时候,不要整库来,按照年龄大小降序挨个清理表会更快。
注意当主库进入事务回卷保护状态时,从库也会面临同样的问题。
解决方案
AutoVacuum参数配置
年龄监控
[未完待续]
故障档案:序列号消耗过快导致整型溢出
0x01 概览
-
故障表现:
- 某张使用自增列的表序列号涨至整型上限,无法写入。
- 发现表中的自增列存在大量空洞,很多序列号没有对应记录就被消耗掉了。
-
故障影响:非核心业务某表,10分钟左右无法写入。
-
故障原因:
- 内因:使用了INTEGER而不是BIGINT作为主键类型。
- 外因:业务方不了解
SEQUENCE的特性,执行大量违背约束的无效插入,浪费了大量序列号。
-
修复方案:
- 紧急操作:降级线上插入函数为直接返回,避免错误扩大。
- 应急方案:创建临时表,生成5000万个浪费空洞中的临时ID,修改插入函数,变为先检查再插入,并从该临时ID表中取ID。
- 解决方案:执行模式迁移,将所有相关表的主键与外键类型更新为Bigint。
原因分析
内因:类型使用不当
业务使用32位整型作为主键自增ID,而不是Bigint。
- 除非有特殊的理由,主键,自增列都应当使用BIGINT类型。
外因:不了解Sequence的特性
- 非要使用如果会频繁出现无效插入,或频繁使用UPSERT,需要关注Sequence的消耗问题。
- 可以考虑使用自定义发号函数(类Snowflake)
在PostgreSQL中,Sequence是一个比较特殊的类型。特别是,在事务中消耗的序列号不会回滚。因为序列号能被并发地获取,不存在逻辑上合理的回滚操作。
在生产中,我们就遇到了这样一种故障。有一张表直接使用了Serial作为主键:
CREATE TABLE sample(
id SERIAL PRIMARY KEY,
name TEXT UNIQUE,
value INTEGER
);
而插入的时候是这样的:
INSERT INTO sample(name, value) VALUES(?,?)
当然,实际上由于name列上的约束,如果插入了重复的name字段,事务就会报错中止并回滚。然而序列号已经被消耗掉了,即使事务回滚了,序列号也不会回滚。
vonng=# INSERT INTO sample(name, value) VALUES('Alice',1);
INSERT 0 1
vonng=# SELECT currval('sample_id_seq'::RegClass);
currval
---------
1
(1 row)
vonng=# INSERT INTO sample(name, value) VALUES('Alice',1);
ERROR: duplicate key value violates unique constraint "sample_name_key"
DETAIL: Key (name)=(Alice) already exists.
vonng=# SELECT currval('sample_id_seq'::RegClass);
currval
---------
2
(1 row)
vonng=# BEGIN;
BEGIN
vonng=# INSERT INTO sample(name, value) VALUES('Alice',1);
ERROR: duplicate key value violates unique constraint "sample_name_key"
DETAIL: Key (name)=(Alice) already exists.
vonng=# ROLLBACK;
ROLLBACK
vonng=# SELECT currval('sample_id_seq'::RegClass);
currval
---------
3
因此,当执行的插入有大量重复,即有大量的冲突时,可能会导致序列号消耗的非常快。出现大量空洞!
另一个需要注意的点在于,UPSERT操作也会消耗序列号!从表现上来看,这就意味着即使实际操作是UPDATE而不是INSERT,也会消耗一个序列号。
vonng=# INSERT INTO sample(name, value) VALUES('Alice',3) ON CONFLICT(name) DO UPDATE SET value = EXCLUDED.value;
INSERT 0 1
vonng=# SELECT currval('sample_id_seq'::RegClass);
currval
---------
4
(1 row)
vonng=# INSERT INTO sample(name, value) VALUES('Alice',4) ON CONFLICT(name) DO UPDATE SET value = EXCLUDED.value;
INSERT 0 1
vonng=# SELECT currval('sample_id_seq'::RegClass);
currval
---------
5
(1 row)
解决方案
线上所有查询与插入都使用存储过程。非核心业务,允许接受短暂的写入失效。首先降级插入函数,避免错误影响AppServer。因为该表存在大量依赖,无法直接修改其类型,需要一个临时解决方案。
检查发现ID列中存在大量空洞,每10000个序列号中实际只有1%被使用。因此使用下列函数生成临时ID表。
CREATE TABLE sample_temp_id(id INTEGER PRIMARY KEY);
-- 插入约5000w个临时ID,够用十几天了。
INSERT INTO sample_temp_id
SELECTT generate_series(2000000000,2100000000) as id EXCEPT SELECT id FROM sample;
-- 修改插入的存储过程,从临时表中Pop出ID。
DELETE FROM sample_temp_id WHERE id = (SELECT id FROM sample_temp_id FOR UPDATE LIMIT 1) RETURNING id;
修改插入存储过程,每次从临时ID表中取一个ID,显式插入表中。
经验与教训
故障档案:移除负载导致过载
最近发生了一起匪夷所思的故障,某数据库切走了一半的数据量和负载。
其他什么都没变,本来还好;压力减小,却在高峰期陷入濒死状态,完全不符合直觉。
但正如福尔摩斯所说,当你排除掉一切不可能之后,剩下的即使再离奇,也是事实。
一、摘要
某日凌晨4点,进行了核心库进行分库迁移,拆走一半的表和一半的查询负载,原库节点规模不变。
当日晚高峰核心库所有热备库(15台)出现连接堆积,压力暴涨,针对性地清理慢查询不再起效。
无差别持续杀查询,有立竿见影的救火效果(22:30后),且暂停后故障立刻重现(22:48),杀至高峰期结束。
匪夷所思的是,移走了表(数据量减半),移走了负载(TPS减半),其他什么都没变竟然会导致压力上升?
二、现象
CPU使用率的正常水位在25%,警戒水位在45%,极限水位在80%。故障期间所有从库飙升至极限水位。

PostgreSQL连接数发生暴涨,通常5~10个左右的数据库连接就足够撑起所有流量,连接池的最大连接数为100。

pgbouncer连接池平均响应时间平时在500μs左右,故障期间飙升至百毫秒级别。

故障期间,数据库TPS发生显著下滑。进行杀查询抢救后恢复,但处于剧烈抖动状态。

故障期间,两个函数的执行时间发生显著恶化,从几百微秒劣化至几十毫秒。

故障期间,复制延迟显著上升,开始出现GB级别的复制延迟,业务指标出现显著下滑。
开始杀查询后,大部分指标恢复,但一旦停止马上重新开始出现(22:48尝试性停止故障恢复)。
三、原因分析
【表因】:所有从库连接池被打满,连接被慢查询占据,快查询无法执行,发生连接堆积。
【主内因】:两个函数的并发数增大到30左右时,性能会发生急剧劣化,变为慢查询(500μs到100ms)。
【副内因】:后端与数据库没有合理的超时取消机制,断路器会放大故障。
【外因】:分库后,快查询比例下降,导致特定查询的相对比例上升,并发数增大至临界点。恶化为慢查询。
表因:连接打满
故障的表因是数据库连接池被打满,产生大量堆积连接。进而新连接无法建立,拒绝服务。
原理
数据库配置的最大连接数max_connections = 100,一个连接实质上就是一个数据库进程。机器能够负载的实际数据库进程数目与查询类型高度相关:如果全是在1ms内的快查询,几百上千个链接都是可以的(生产环境中的正常情况)。而如果全都是CPU和IO密集的慢查询,则最大支持的连接数可能只有(48 * 80% ≈ 38)个左右。
在生产环境中使用了连接池,正常情况下5~10个实际数据库连接就可以支撑起所有快查询。然而一旦有大量慢查询持续进入,长期占用了活跃连接,那么快查询就会排队等待发生堆积,连接池进而启动更多实际数据库的连接,而这些连接上的快查询很快就会执行完毕,最终仍然会被不断进入的慢查询占据。最终导致约100个实际数据库连接都在执行CPU/IO密集的慢查询(max_pool_size=100),CPU暴涨,进一步恶化情况。
证据
连接池活跃连接数

连接池排队连接数

数据库后端连接数
修复
持续地无差别杀掉所有数据库活跃连接,能起到很好的治标效果,且对业务指标影响很小。
但杀掉连接(pg_terminate_backend)会导致连接池重连,更好的做法是取消查询(pg_cancel_backend)
因为快查询走的快,卡在后端实际连接上执行的查询极大概率都是慢查询,这时候无差别取消所有查询命中的绝大多数都是慢查询。杀查询能将连接释放给快查询使用,让应用苟活下去,但必须持续不断的杀才有效果,因为用不了零点几秒,慢查询就会重新占据活跃连接。
使用psql执行以下SQL,每隔0.5秒取消所有活跃查询。
SELECT pg_cancel_backend(pid) FROM pg_stat_activity WHERE application_name != 'psql' \watch 0.5
解决方案:调整了连接池的后端最大连接数,进行快慢分离,强制所有批量任务与慢查询走离线从库。
主内因:并行恶化
故障的主内因是两个函数的执行时间在并行数增大时发生恶化。
原理
故障的直接导火索是这两个函数劣化为慢查询。经过单独的压力测试,这两个函数随着并行执行数增高,发生急剧的性能劣化,阈值点为约30个并发进程。(因为所有进程只执行同一个查询,所以可认为并行数等于并发数)
证据
图:故障期间函数平均执行时间出现明显飙升
图:在不同并行数下压测该函数能达到的最大QPS

修复
- 优化函数执行逻辑,将该函数的执行时间优化至原来的一半(最大QPS翻倍)。
- 新增五台从库,进一步降低单机负载。
副内因:没有超时
故障的副内因在于没有合理的超时取消机制,查询不会因为超时被取消,是发生堆积的必要条件。
原理
发生查询超时时,应用层的合理行为是
- 直接返回,报错。
- 进行若干次重试(在高峰期可以考虑直接返回错误)
查询等待超出合理范围的时间却不取消,就会导致连接堆积。抛弃返回结果并无法取消已经发出的查询,客户端需要主动Cancel Request。Go1.7后的标准实践是通过context包与database/sql提供的QueryContext/ExecContext进行超时控制。
数据库端和连接池端可以配置语句超时(statement_timeout),但实践表明这样的操作很容易误杀查询。
手动杀灭能够立竿见影地治标,但它本质上是一种人工超时取消机制。稳健的系统应当有自动化的超时取消机制,这需要在数据库、连接池、应用多个层次协同解决。
检视后端使用的驱动代码,发现pg.v3 pg.v5并没有真正意义上的查询超时机制,超时参数不过是为net.Conn加上的TCP超时(通常在分钟级别)。
修复
- 建议使用
github.com/jackc/pgx与github.com/go-pg/pg第六版驱动替代现有驱动 - 使用circuit-breaker会导致故障效应被放大,建议后端使用主动超时替代断路器。
- 建议在应用层面对连接的使用进行更精细的控制。
外因:分库迁移
分库导致了原库中的快慢查询比例发生变化,诱发了两个函数的劣化。
问题函数在迁移前后的全局调用次数占比由1/6 变为1/2,导致问题函数的并行数增大。
原理
- 迁走的函数全都是快查询,原本问题函数:普通函数的比例为1:5
- 迁移负载后,快查询迁走了大半。问题函数:普通函数超过1:1
- 问题函数的比例大幅升高,导致高峰期其并发数超出阈值点,出现劣化。
证据
通过分析分库迁移前后的数据库全量日志,回放查询流量进行压测,重现了现象,确认了问题原因。
| 指标 | 迁移前 | 迁移后 |
|---|---|---|
| 问题函数占比 | 1/6 | 5/9 |
| 最大QPS | 40k | 8k |
QPS/TPS是一个极具误导性的指标,只有在负载类型不变的清空下,比较QPS才有意义。当系统负载类型发生变化时,QPS的水位点也需要重新进行评估测试。
在本例中,在负载变化后,系统的最大QPS水位点已经发生了戏剧性的变化,因为问题函数并发劣化,最大QPS变为原来的五分之一。
修复
对问题函数进行了改写优化,提高了一倍的性能。
通过测试,确定了迁移后的系统水位值,并进行了相应的优化与容量调整。
四、经验与教训
在故障排查中,走了一些弯路。比如一开始认为是某个离线批量任务拖慢了查询(根据日志中观察到的前后相关性),也排查了API调用量突增,外部恶意访问,其他变更因素,未知线上操作等。虽然分库迁移被列入怀疑对象,但因为直觉上认为负载小了,系统的Capacity怎么可能会下降?就没有列为优先排查对象。现实马上就给我们上了一课:
当你排除掉一切不可能之后,剩下的即使再离奇,也是事实。