1 - 可观测性
对于系统管理来说,最重要到问题之一就是可观测性(Observability)。
那么,什么是可观测性呢?对于这样的问题,列举定义是枯燥乏味的,让我们直接以Postgres本身为例。
这张图显示了Postgres本身提供的可观测性。PostgreSQL 提供了丰富的观测接口,包括系统目录,统计视图,辅助函数。 这些都是我们可以观测的对象。

原图地址:https://pgstats.dev/
我可以很荣幸地宣称,这里列出的信息全部被Pigsty所收录。并且通过精心的设计,将晦涩的指标数据,转换成了人类可以轻松理解的洞察。
可观测性
经典的监控模型中,有三类重要信息:
指标
下面让我们以一个最经典的例子来深入探索可观测性: pg_stat_statements ,这是Postgres官方提供的统计插件,可以暴露出数据库中执行的每一类查询的详细统计指标。与图中Query Planning和Execution相对应
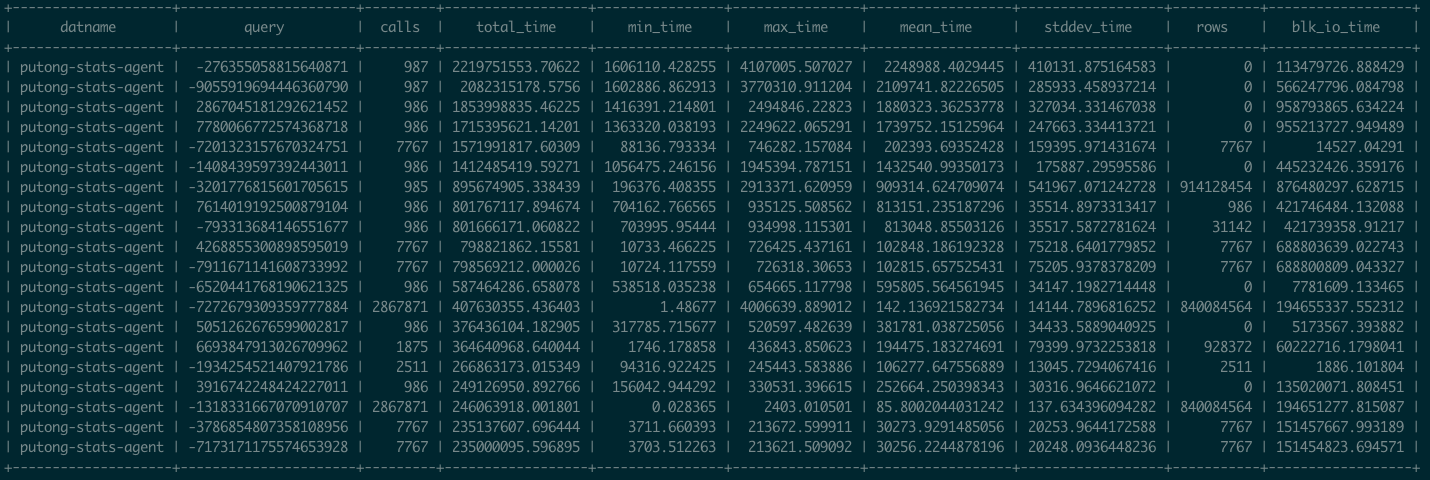
这里我们可以看到,pg_stat_statements 提供的原始指标数据以表格的形式呈现。譬如这里,每个查询都分配有一个查询ID,紧接着是调用次数,总耗时,最大、最小、平均单次耗时,响应时间都标准差,每次调用平均返回的行数,用于块IO的时间等等,(如果是PG13,还有更为细化的计划时间、执行时间、产生的WAL记录数量等新指标)。
直接观测这种数据表,很容易让人摸不着头脑,看不到重点。我们需要的是,将这种可观测性转换为洞察,也就是以直观图表的方式呈现。
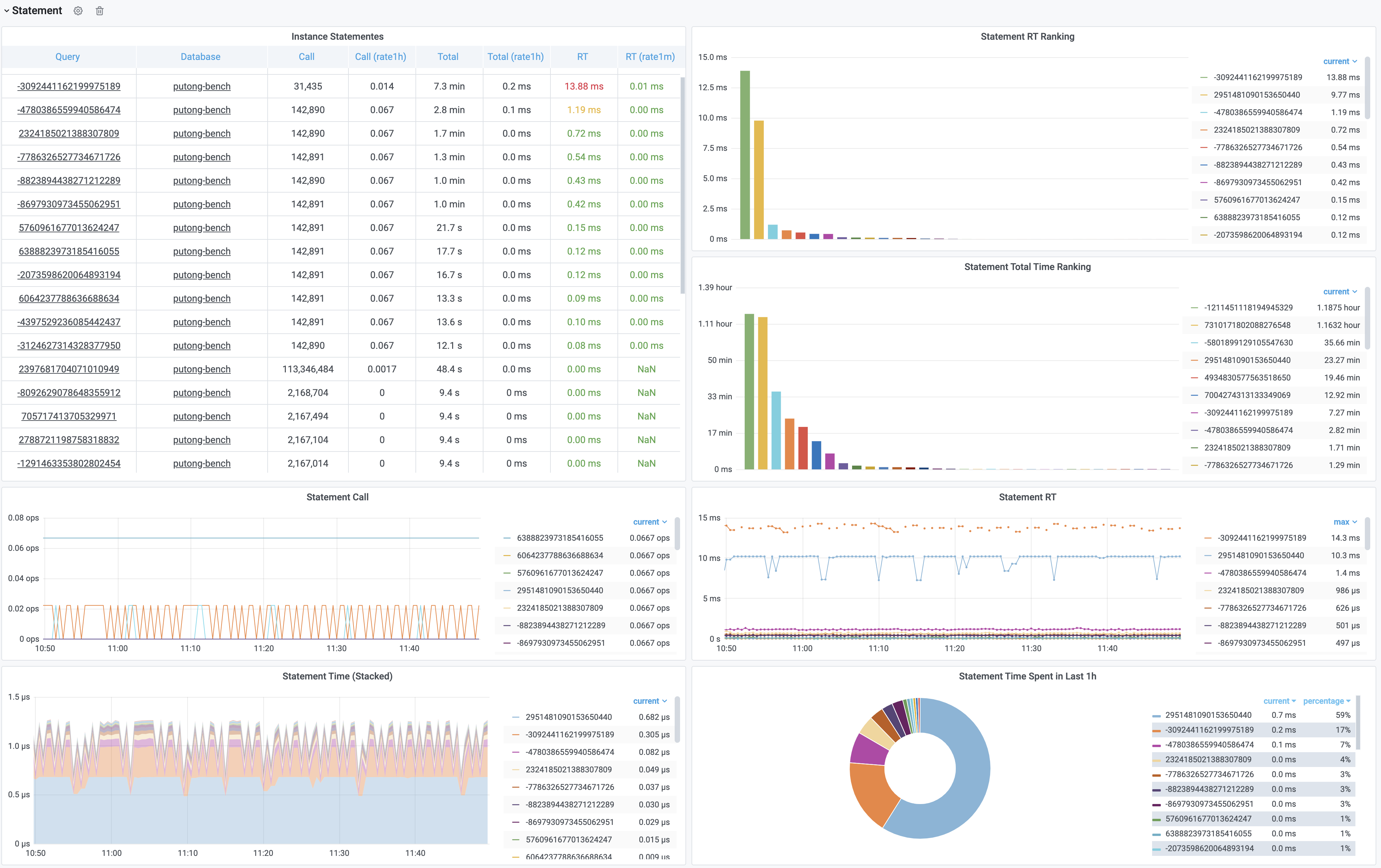
这里的表格数据经过一系列的加工处理,最终呈现为若干监控面板。最基本的加工处理譬如:对表格中的原始数据进行标红上色,这样慢查询就可以一览无余,但这也不过是雕虫小技。
更重要的是,原始的数据视图只能呈现当前时刻的快照,而通过Pigsty,你可以回溯任意时刻或任意时间段。获取更深刻的性能洞察。
比如下图是集群视角下的慢查询,我们可以看到整个集群中所有查询的概览,包括每一类查询的QPS与RT,平均响应时间排名,以及耗费的总时间占比。当我们对某一类具体查询感兴趣时,就可以点击查询ID跳转到查询详情页中,如右图所示。这里会显示查询的语句,以及一些核心指标。
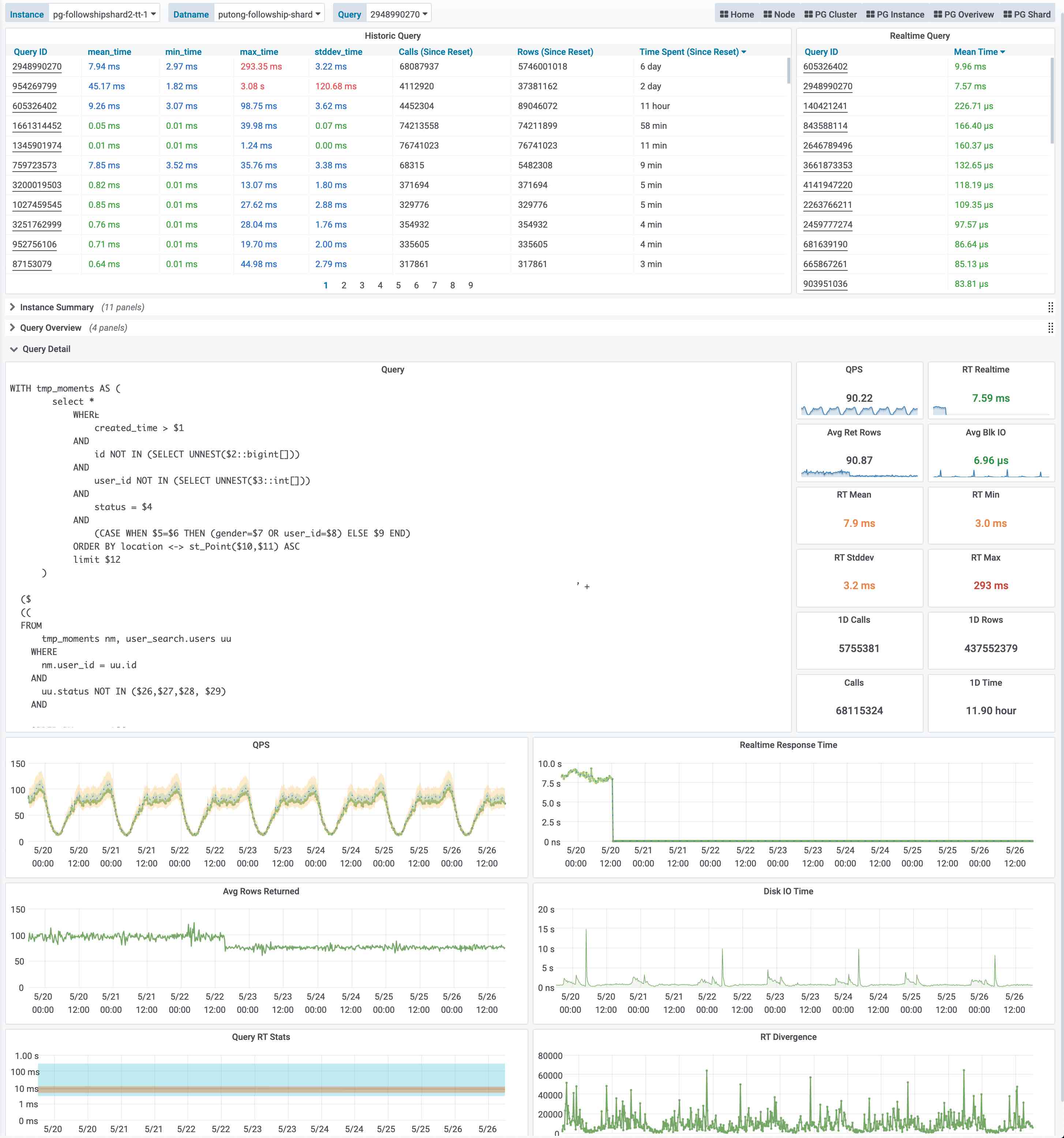
这个图是实际生产环境中的一次慢查询优化记录,我们可以从右侧中间的Realtime Response Time 面板中看到一个突变,该查询的平均响应时间从七八秒突降到了七八毫秒。我们定位到了这个慢查询并添加了适当的索引,那么优化的效果就立刻在图表上以直观的形式展现出来。
这就是Pigsty需要解决的核心问题,From observability to insight。
而下面这些玲琅满目的面板,就是Pigsty成就的一瞥:


目录
Catalog是什么?Catalog是数据库的元数据字典。
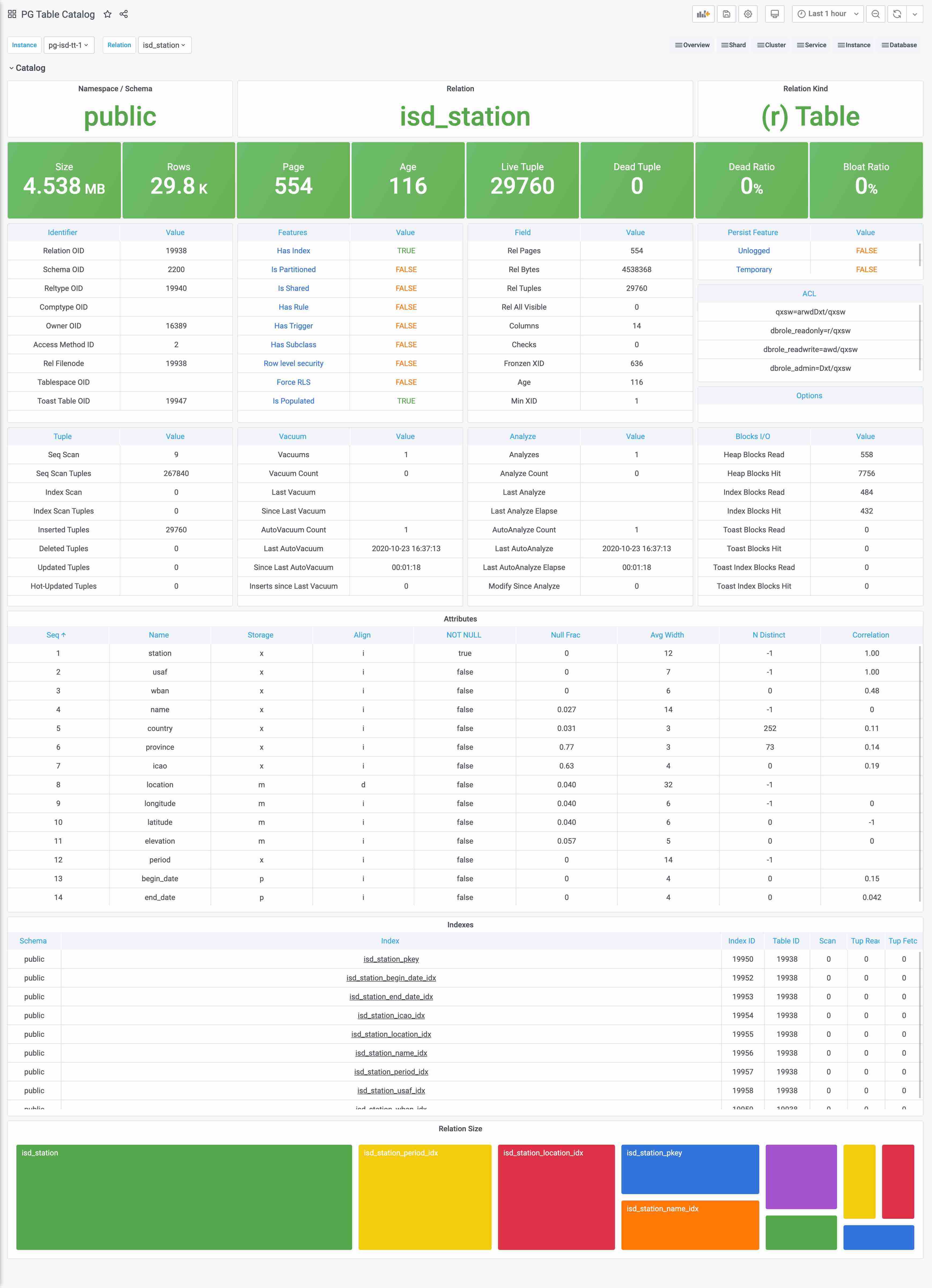
Catalog与Metrics比较相似但又不完全相同,边界比较模糊。最简单的例子,一个表的页面数量和元组数量,应该算Catalog还是算Metrics呢?
跳过这种概念游戏,实践上Catalog和Metrics主要的区别是,Catalog里的信息通常是不怎么变化的,比如表的定义之类的,如果也像Metrics这样比如几秒抓一次,显然是一种浪费。所以我们会将这一类偏静态的信息划归Catalog。
Catalog主要由定时任务负责抓取,而不由Prometheus采集。
日志
除了Catalog,还有一类与监控系统有关的数据是Log。如果说Metrics是对数据库系统的被动观测,那么Log就是数据库系统主动汇报的信息。
Pigsty集成了pgbadger,这是一个非常强大的日志摘要工具,可以实时聚合并生成PG的日志摘要。
同时,通过mtail这样的工具,我们还可以从日志中提取重要的监控指标,最简单的例子就是每秒各错误等级的日志条数。如果说整个监控系统只能保留一个指标,也许这个指标就是最有用的那个指标了。
接下来呢?
只有指标并不够,我们还需要将这些信息组织起来,才能构建出体系来。
阅读下一节:实际挑战 来了解实际的生产环境中的监控系统可能面临怎样的问题与挑战。
2 - 监控层级
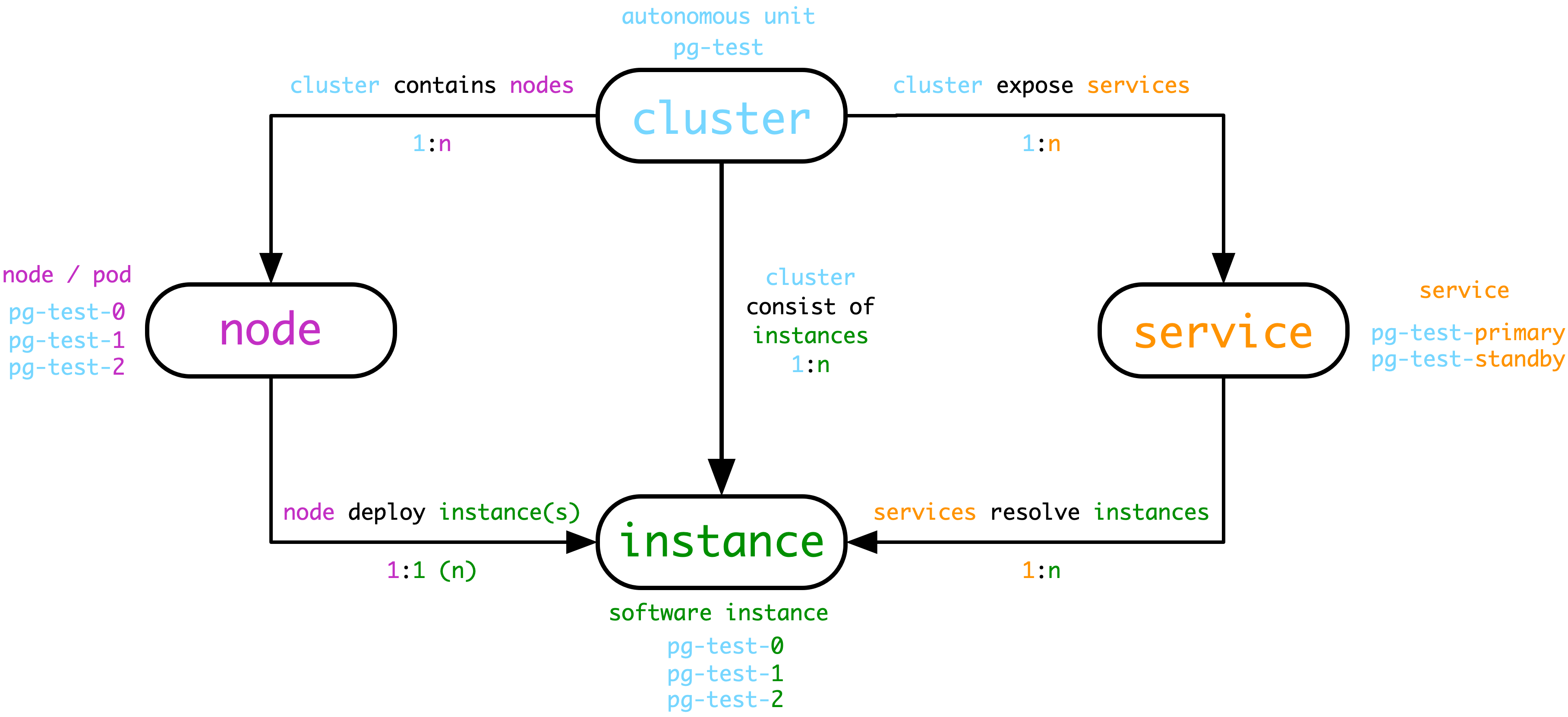
生产环境的数据库往往是以集群为单位组织的。集群是一个由主从复制所关联的一组数据库实例所构成的,它是基本的业务服务单元。集群由多个实例组成,而多套数据库集群共同组成一个现实世界中的生产环境。
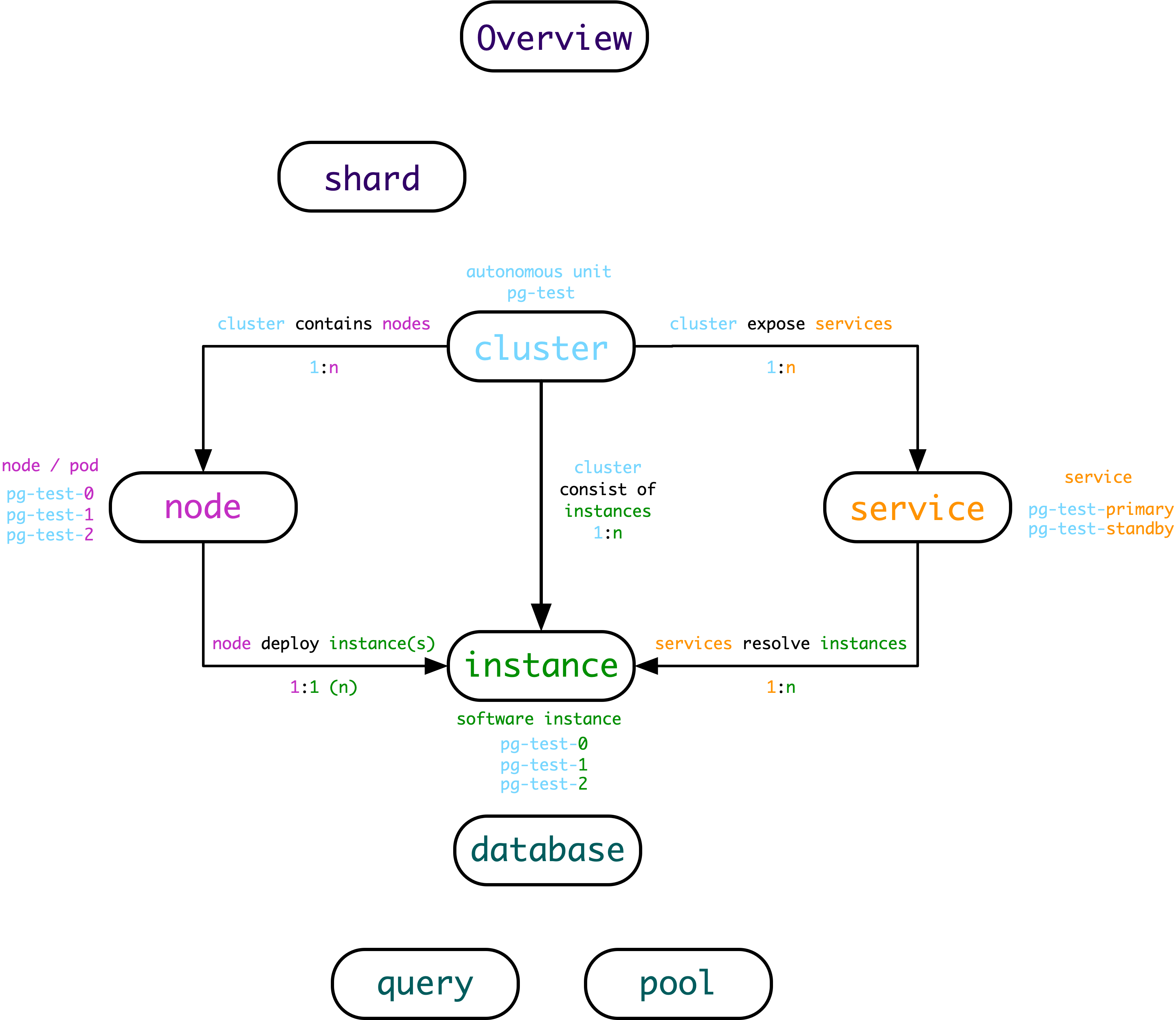
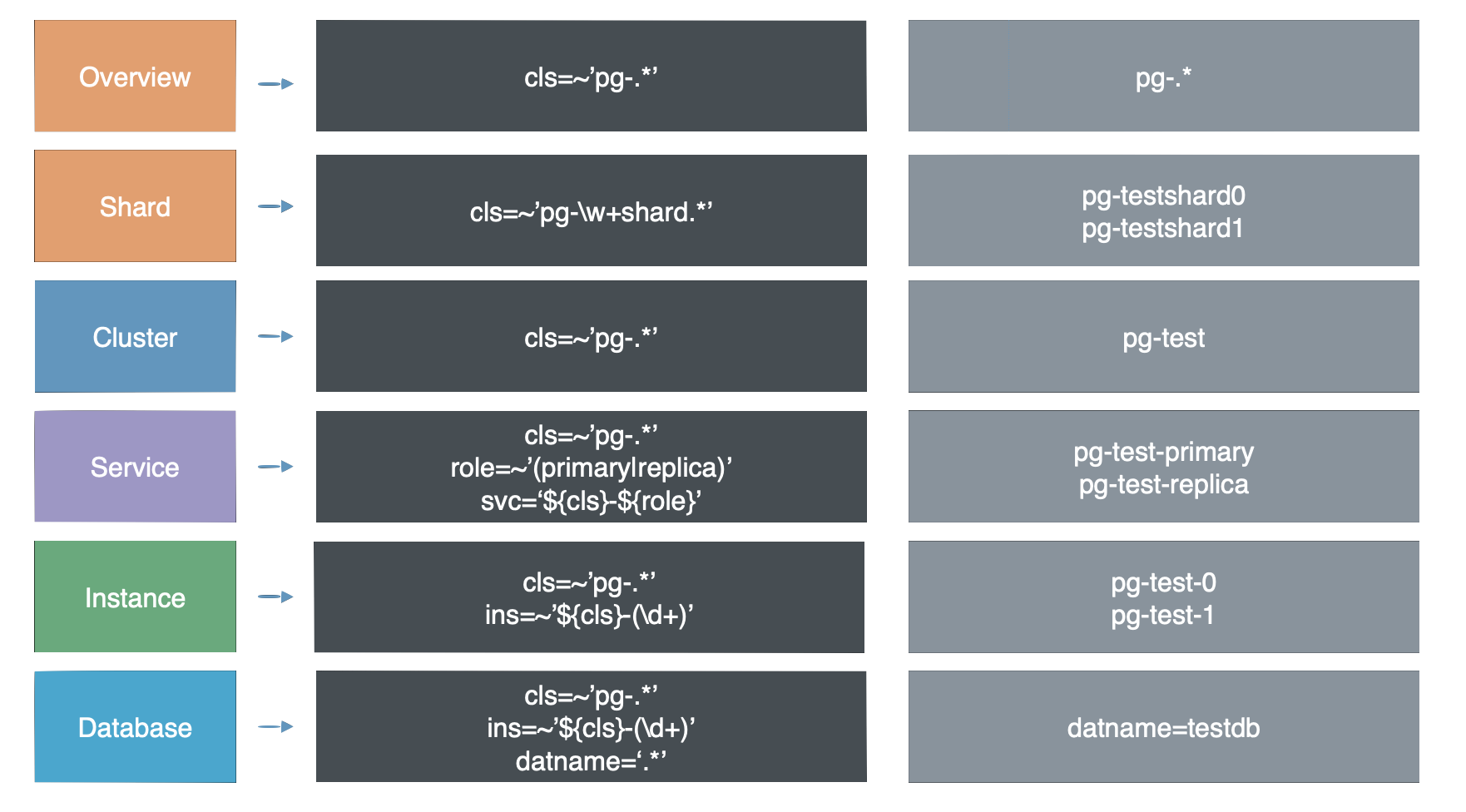
除了实例与集群这两个最为Trivial层次,整个系统中还有着其他层次的组织。自顶向下可以分为7个层级:概览,分片,集群,服务,实例,数据库,对象。
夹在集群与实例中间的层次—— Service。
在实例层级以下,还可以再分出两个层次来,分别是Database和Object。Object即亚数据库对象,包括:表、索引,函数,序列号,查询、连接池等。
从集群层次向上看,则会有两个更高的层次——Shard与Overview。
作为一种精简,正如网络的OSI 7层模型在实际中被简化为TCP/IP五层模型一样,这七个层次也以集群 和 实例为界,简化为五个层次:Overview,Cluster,Service,Instance,Database 。
这样,最终的层次划分也变得十分简洁:所有集群层次以上的信息,都是Overview层次,所有实例内部的信息都算Database层次,夹在两者中间的,就是Service层次。

命名问题
分完层次后,剩下的问题实际上就是命名问题,或者说身份管理的问题。
-
我们需要一种方式来标识、引用系统中不同层次内的各个组件,
-
这种命名方式,应当合理地反映出系统中各个实体的层次关系
-
这种命名方式,应当可以按照规则自动生成,只有这样,才可以在集群扩容缩容,Failover时做到免维护自动化运行,
当我们理清了系统中存在的层次后,就可以着手为系统中的每个实体起名。请参考下一节:命名规则
3 - 服务发现
所有的服务都有身份,例如,所属的集群,集群内的唯一标识,在集群中扮演的角色。等等。
身份管理
当我们为系统设计好命名规则与模式后,第二个问题,就是如何将身份赋予/关联数据库实例。
数据库本身并不知道自己为谁而服务。属于哪个业务,是集群中的几号实例。因此在生产环境大规模集群管理中,我们必须为数据库实例赋予身份。
身份赋予可以有多种形式,例如人肉死记硬背也是一种身份赋予,管理员在脑海中记住了10.20.30.40 IP地址上的数据库实例是用于支付的,而另一台上的数据库实例则用于订单。
更好的方式是通过配置文件,或者更进一步,服务发现的方式来管理集群成员的身份。将身份信息注册到监控系统中是系统自动运行的重要环节,这一步与Kubernetes往etcd中写元数据类似。
Pigsty提供两种身份管理的方式:基于服务发现(Consul/etcd),与基于配置文件。
参考配置:prometheus_sd_method
Prometheus使用的服务发现机制,默认为consul,可选项:
consul:基于Consul进行服务发现static:基于本地配置文件进行服务发现
Pigsty建议使用consul服务发现,当服务器发生Failover时,监控系统会自动更正目标实例所注册的身份。
基于Consul的服务发现
Pigsty内置了基于DCS的配置管理与自动服务发现,用户可以直观地察看系统中的所有节点与服务信息,以及健康状态。Pigsty中的所有服务都会自动注册至DCS中,因此创建、销毁、修改数据库集群时,元数据会自动修正,监控系统能够自动发现监控目标,无需手动维护配置。
目前仅支持Consul作为DCS,用户亦可通过Consul提供的DNS与服务发现机制,实现基于DNS的自动流量切换。后续会提供etcd的完整支持,但下面的介绍都将基于consul进行。
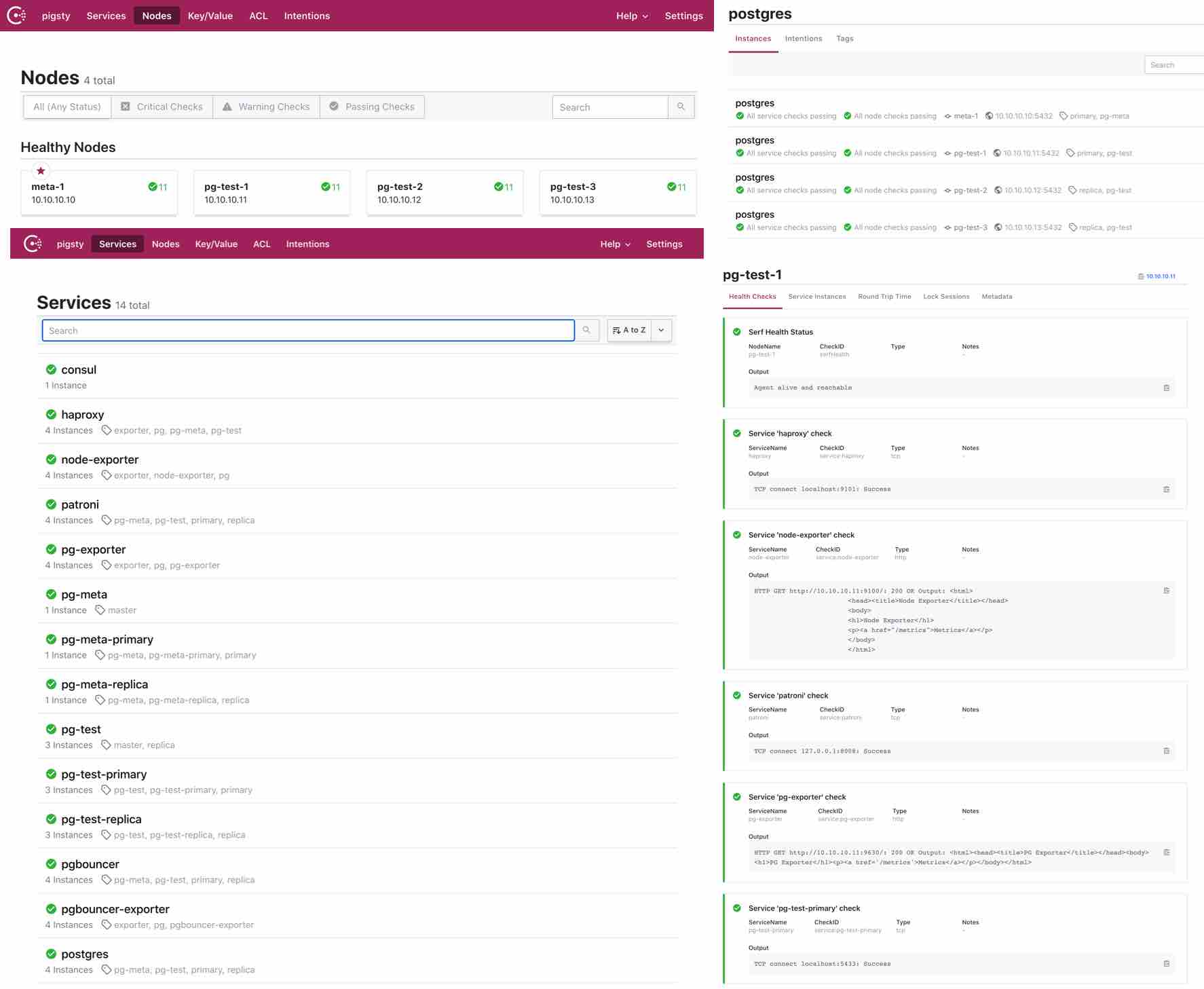
注册
在每个节点上,都运行有 consul agent。服务通过JSON配置文件的方式,由consul agent注册至DCS中。
JSON配置文件的默认位置是/etc/consul.d/,采用svc-<service>.json的命名规则,以postgres为例:
{
"service": {
"name": "postgres",
"port": {{ pg_port }},
"tags": [
"{{ pg_role }}",
"{{ pg_cluster }}"
],
"meta": {
"type": "postgres",
"role": "{{ pg_role }}",
"seq": "{{ pg_seq }}",
"instance": "{{ pg_instance }}",
"service": "{{ pg_service }}",
"cluster": "{{ pg_cluster }}",
"version": "{{ pg_version }}"
},
"check": {
"tcp": "127.0.0.1:{{ pg_port }}",
"interval": "15s",
"timeout": "1s"
}
}
}
查询
您可以通过Consul提供的DNS服务,或者直接调用Consul API实现服务发现。注册到Consul中的服务
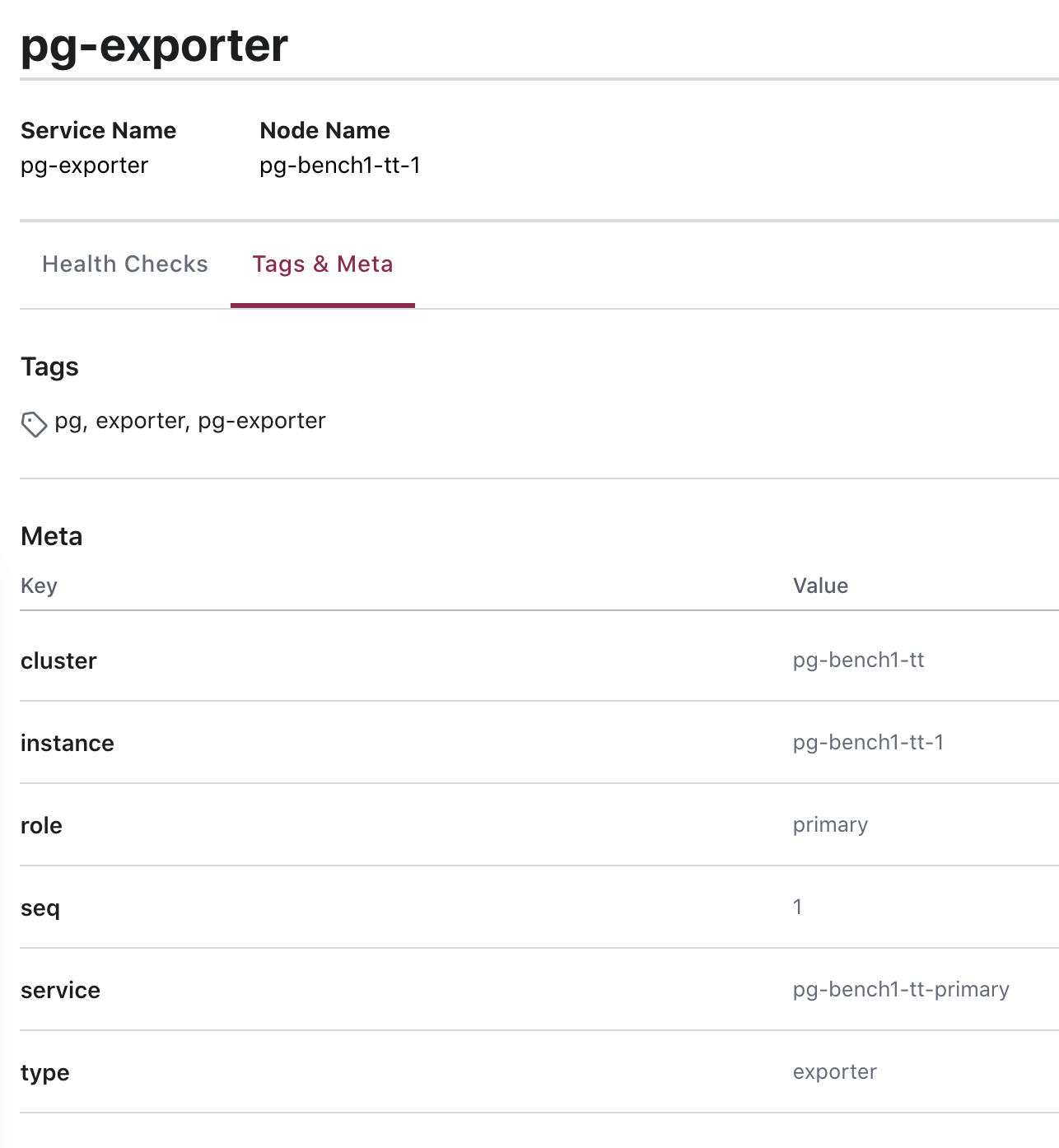
使用DNS API查阅consul服务的方式请参阅Consul文档。
发现
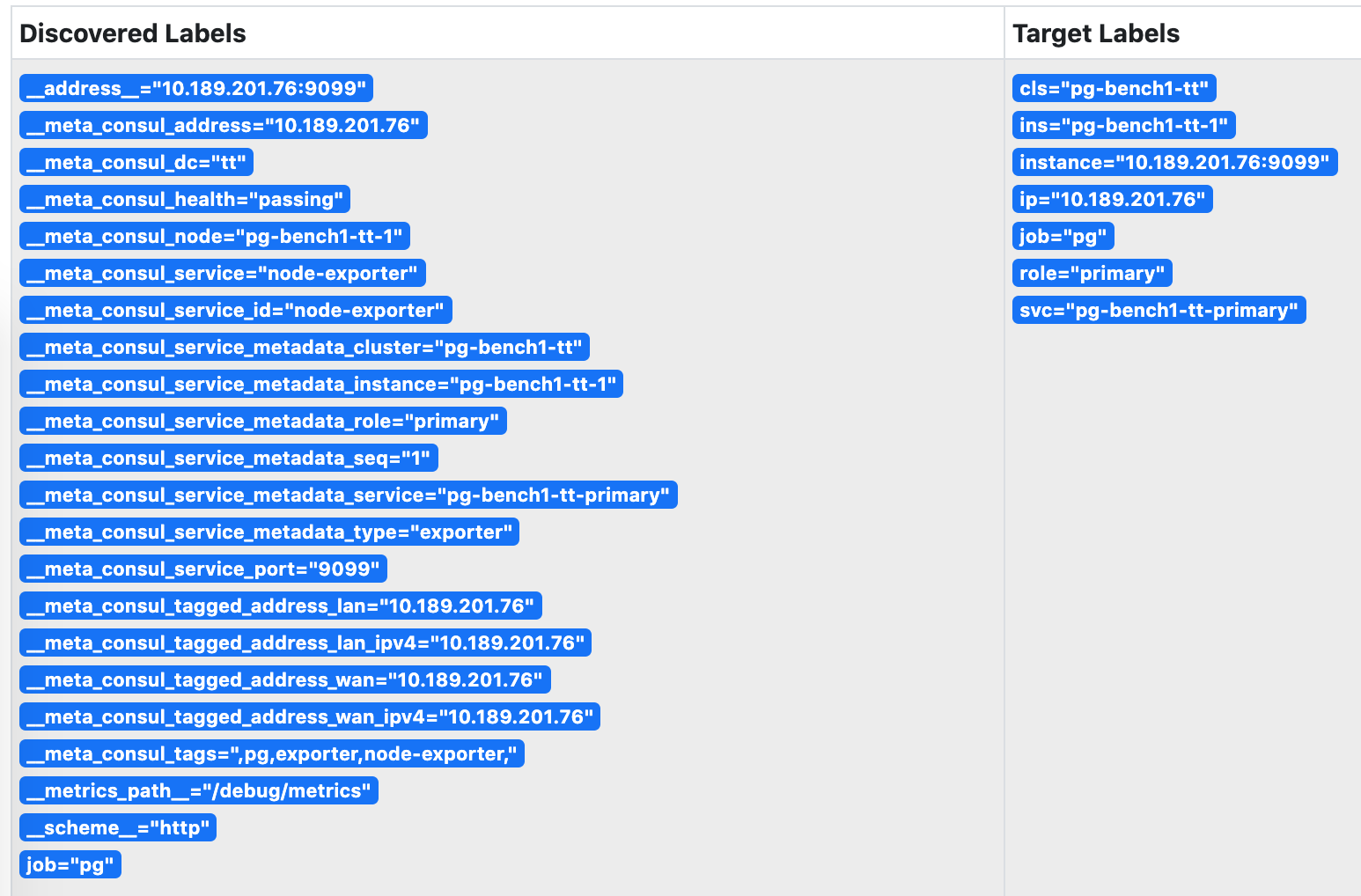
Prometheus会自动通过consul_sd_configs发现环境中的监控对象。同时带有pg和exporter标签的服务会自动被识别为抓取对象:
- job_name: pg
# https://prometheus.io/docs/prometheus/latest/configuration/configuration/#consul_sd_config
consul_sd_configs:
- server: localhost:8500
refresh_interval: 5s
tags:
- pg
- exporter
被Prometheus发现的服务
Prometheus会自动通过consul_sd_configs发现环境中的监控对象。同时带有pg和exporter标签的服务会自动被识别为抓取对象:
- job_name: pg
# https://prometheus.io/docs/prometheus/latest/configuration/configuration/#consul_sd_config
consul_sd_configs:
- server: localhost:8500
refresh_interval: 5s
tags:
- pg
- exporter
维护
有时候,因为数据库主从发生切换,导致注册的角色与数据库实例的实际角色出现偏差。这时候需要通过反熵过程处理这种异常。
基于Patroni的故障切换可以正常地通过回调逻辑修正注册的角色,但人工完成的角色切换则需要人工介入处理。
使用以下脚本可以自动检测并修复数据库的服务注册。建议在数据库实例上配置Crontab,定期检测并修正服务。
/pg/bin/pg-register $(pg-role)
基于静态文件的服务发现
static服务发现依赖/etc/prometheus/targets/*.yml中的配置进行服务发现。采用这种方式的优势是不依赖Consul。
当Pigsty监控系统与外部管控方案集成时,这种模式对原系统的侵入性较小。
但是缺点是,当集群内发生主从切换时,您需要自行维护实例角色信息。
手动维护时,可以根据以下命令从配置文件生成Prometheus所需的监控对象配置文件并载入生效。
./infra.yml --tags=prometheus_targtes,prometheus_reload
Pigsty默认生成的静态监控对象文件示例如下:
#==============================================================#
# File : targets/all.yml
# Ctime : 2021-02-18
# Mtime : 2021-02-18
# Desc : Prometheus Static Monitoring Targets Definition
# Path : /etc/prometheus/targets/all.yml
# Copyright (C) 2018-2021 Ruohang Feng
#==============================================================#
#======> pg-meta-1 [primary]
- labels: {cls: pg-meta, ins: pg-meta-1, ip: 10.10.10.10, role: primary, svc: pg-meta-primary}
targets: [10.10.10.10:9630, 10.10.10.10:9100, 10.10.10.10:9631, 10.10.10.10:9101]
#======> pg-test-1 [primary]
- labels: {cls: pg-test, ins: pg-test-1, ip: 10.10.10.11, role: primary, svc: pg-test-primary}
targets: [10.10.10.11:9630, 10.10.10.11:9100, 10.10.10.11:9631, 10.10.10.11:9101]
#======> pg-test-2 [replica]
- labels: {cls: pg-test, ins: pg-test-2, ip: 10.10.10.12, role: replica, svc: pg-test-replica}
targets: [10.10.10.12:9630, 10.10.10.12:9100, 10.10.10.12:9631, 10.10.10.12:9101]
#======> pg-test-3 [replica]
- labels: {cls: pg-test, ins: pg-test-3, ip: 10.10.10.13, role: replica, svc: pg-test-replica}
targets: [10.10.10.13:9630, 10.10.10.13:9100, 10.10.10.13:9631, 10.10.10.13:9101]
接下来
将数据库服务注册至DCS后,我们为每个实例赋予了身份信息,因此可以将监控指标与实例的身份关联起来。
阅读下一节 监控指标 了解Pigsty提供的监控指标,以及这些指标是如何通过标签组织起来的。
4 - 监控指标
指标来源
Pigsty的监控数据,主要有四个来源: 数据库本身,中间件,操作系统,负载均衡器。通过相应的exporter对外暴露。
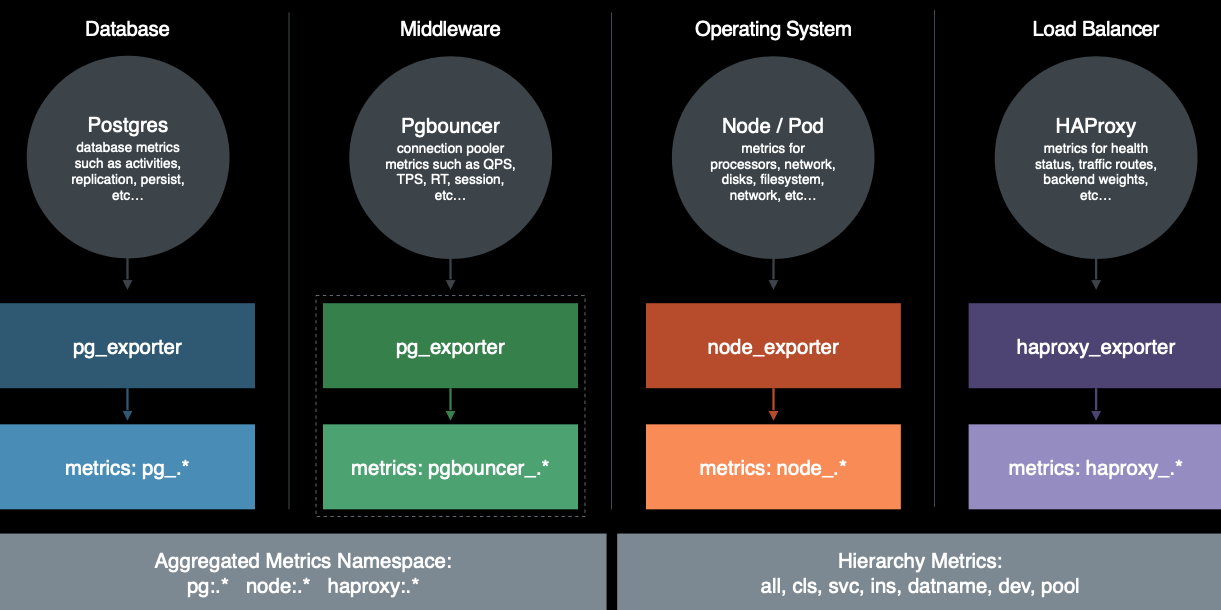
完整来源包括:
- PostgreSQL本身的监控指标
- PostgreSQL日志中的统计指标
- PostgreSQL系统目录信息
- Pgbouncer连接池中间价的指标
- PgExporter指标
- 数据库工作节点Node的指标
- 负载均衡器Haproxy指标
- DCS(Consul)工作指标
- 监控系统自身工作指标:Grafana,Prometheus,Nginx
- Blackbox探活指标
关于全部可用的指标清单,请查阅 参考-指标清单 一节
指标数量
那么,Pigsty总共包含了多少指标呢? 这里是一副各个指标来源占比的饼图。我们可以看到,右侧蓝绿黄对应的部分是数据库及数据库相关组件所暴露的指标,而左下方红橙色部分则对应着机器节点相关指标。左上方紫色部分则是负载均衡器的相关指标。
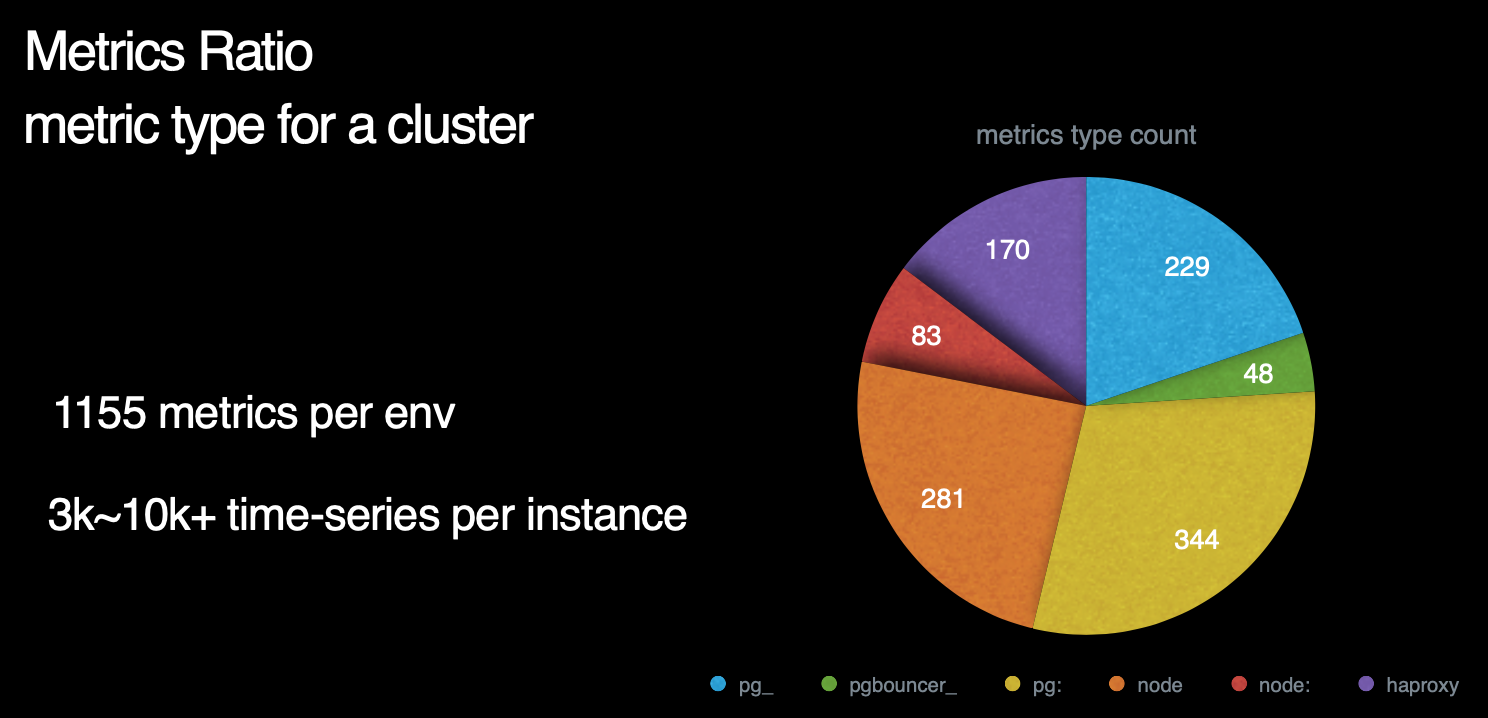
数据库指标中,与postgres本身有关的原始指标约230个,与中间件有关的原始指标约50个,基于这些原始指标,Pigsty又通过层次聚合与预计算,精心设计出约350个与DB相关的衍生指标。 因此,对于每个数据库集群来说,单纯针对数据库及其附件的监控指标就有621个。而机器原始指标281个,衍生指标83个一共364个。加上负载均衡器的170个指标,我们总共有接近1200类指标。
注意,这里我们必须辨析一下指标(metric)与时间序列( Time-series)的区别。
这里我们使用的量词是 类 而不是个 。 因为一个指标可能对应多个时间序列。例如一个数据库中有20张表,那么 pg_table_index_scan 这样的指标就会对应有20个对应的时间序列。
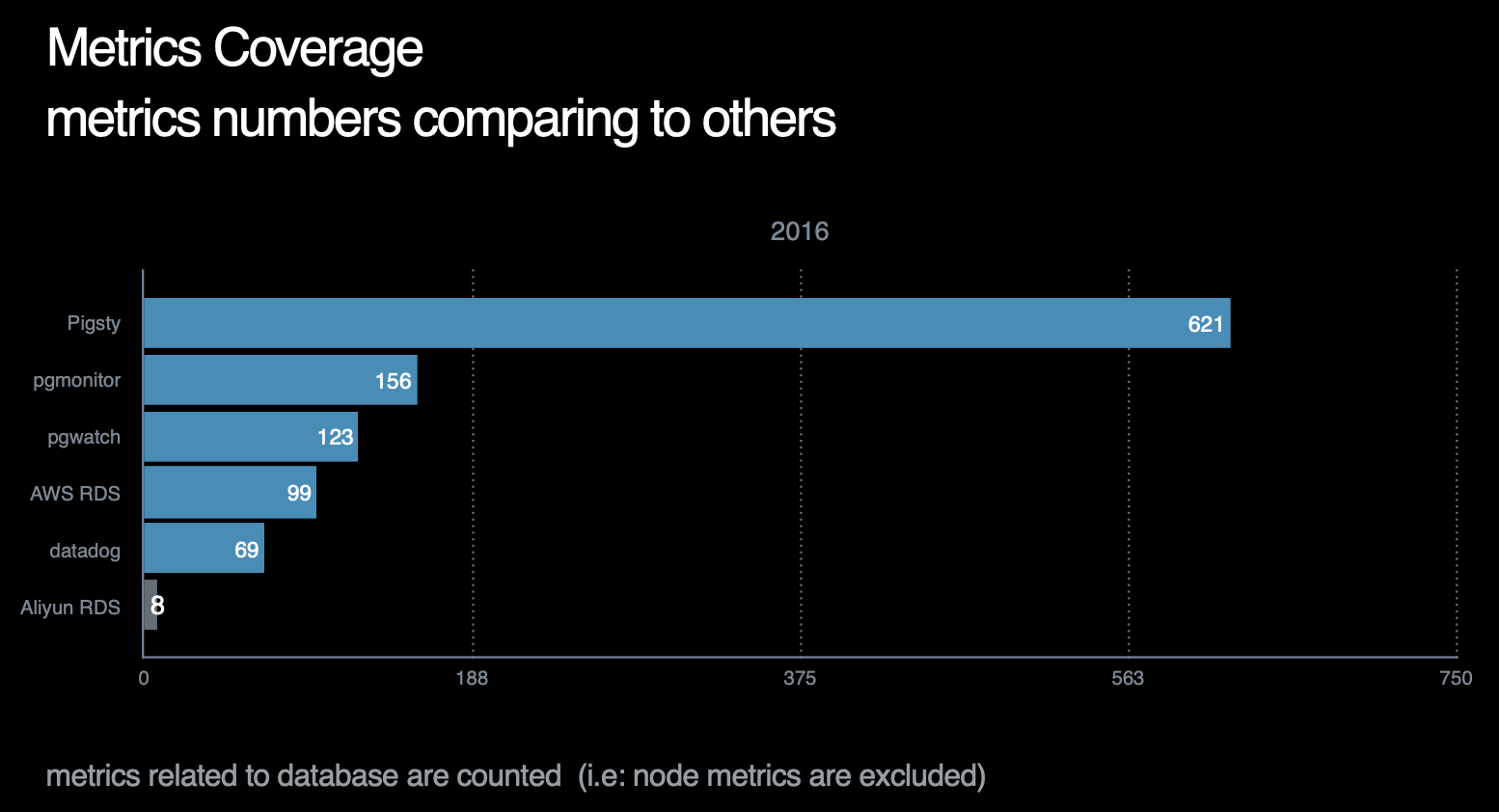
截止至2021年,Pigsty的指标覆盖率在所有作者已知的开源/商业监控系统中一骑绝尘,详情请参考横向对比。
指标层次
所有的这些指标,还会进行进一步的加工处理。
例如按照不同的层次进行聚合,形成一系列的衍生指标。
从原始监控时间序列数据,到最终的成品图表,中间还有着若干道加工工序。
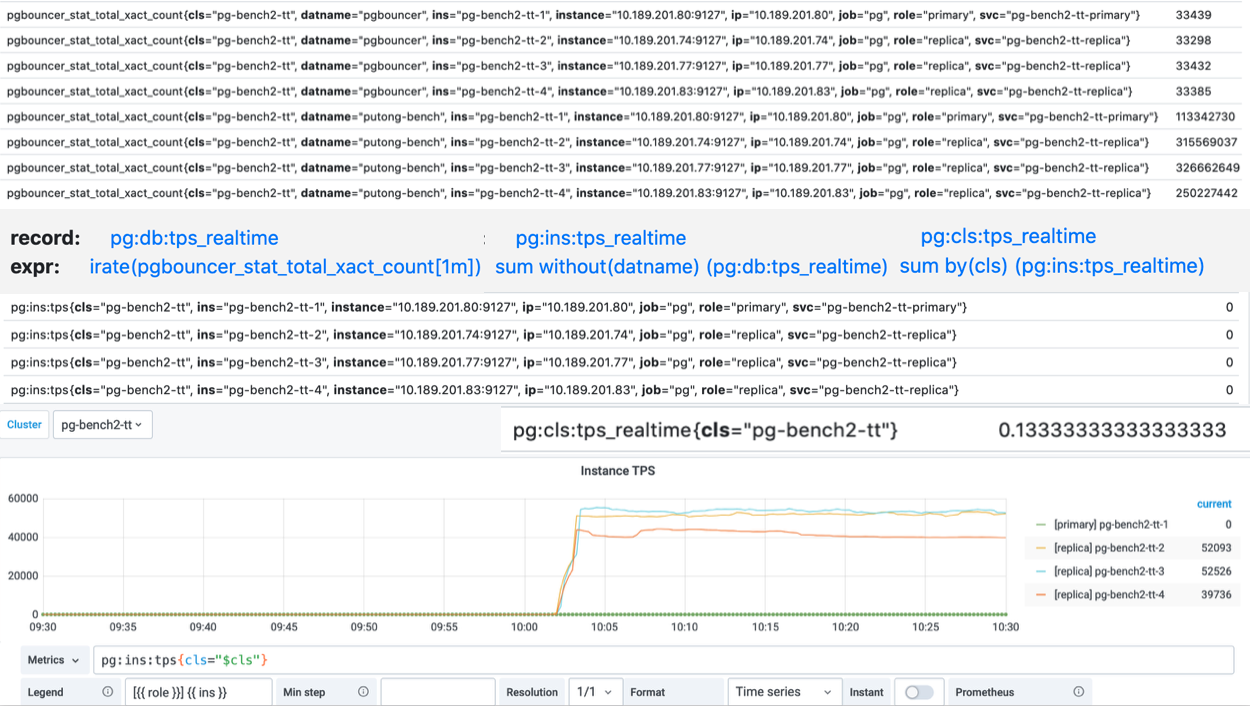
这里以TPS指标的衍生流程为例。
原始数据是从Pgbouncer抓取得到的事务计数器,集群中有四个实例,而每个实例上又有两个数据库,所以一个实例总共有8个DB层次的TPS指标。
而下面的图表,则是整个集群内每个实例的QPS横向对比,因此在这里,我们使用预定义的规则,首先对原始事务计数器求导获取8个DB层面的TPS指标,然后将8个DB层次的时间序列聚合为4个实例层次的TPS指标,最后再将这四个实例级别的TPS指标聚合为集群层次的TPS指标。
Pigsty共定义了360类衍生聚合指标,后续还会不断增加。衍生指标定义规则详见 参考-衍生指标
小结
了解了Pigsty指标后,不妨了解一下Pigsty的报警系统是如何将这些指标数据用于实际生产用途的。
5 - 报警规则
报警对于日常故障响应,提高系统可用性至关重要。
漏报会导致可用性降低,误报会导致敏感性下降,有必要对报警规则进行审慎的设计。
- 合理定义报警级别,以及相应的处理流程
- 合理定义报警指标,去除重复报警项,补充缺失报警项
- 根据历史监控数据科学配置报警阈值,减少误报率。
- 合理疏理特例规则,消除维护工作,ETL,离线查询导致的误报。
报警分类学
按紧急程度分类
-
P0:FATAL:产生重大场外影响的事故,需要紧急介入处理。例如主库宕机,复制中断。(严重事故)
-
P1:ERROR:场外影响轻微,或有冗余处理的事故,需要在分钟级别内进行响应处理。(事故)
-
P2:WARNING:即将产生影响,放任可能在小时级别内恶化,需在小时级别进行响应。(关注事件)
-
P3:NOTICE:需要关注,不会有即时的影响,但需要在天级别内进行响应。(偏差现象)
按报警层次分类
- 系统级:操作系统,硬件资源的报警。DBA只会特别关注CPU与磁盘报警,其他由运维负责。
- 数据库级:数据库本身的报警,DBA重点关注。由PG,PGB,Exporter本身的监控指标产生。
- 应用级:应用报警由业务方自己负责,但DBA会为QPS,TPS,Rollback,Seasonality等业务指标设置报警
按指标类型分类
- 错误:PG Down, PGB Down, Exporter Down, 流复制中断,单集簇多主
- 流量:QPS,TPS,Rollback,Seasonaility
- 延迟: 平均响应时间,复制延迟
- 饱和度:连接堆积,闲事务数,CPU,磁盘,年龄(事务号),缓冲区
报警可视化
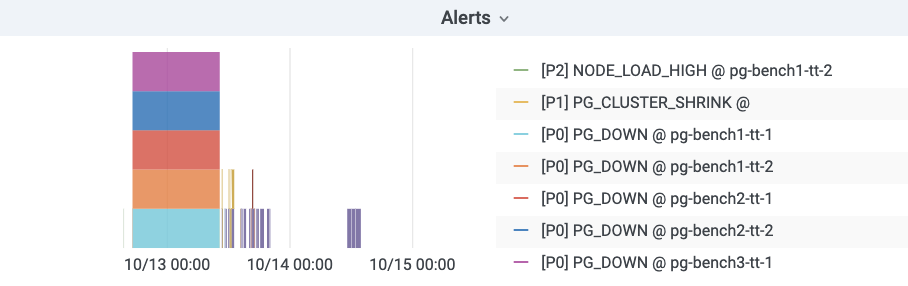
报警规则详解
报警规则按类型可粗略分为四类:错误,延迟,饱和度,流量。其中:
- 错误:主要关注各个组件的存活性(Aliveness),以及网络中断,脑裂等异常情况,级别通常较高(P0|P1)。
- 延迟:主要关注查询响应时间,复制延迟,慢查询,长事务。
- 饱和度:主要关注CPU,磁盘(这两个属于系统监控但对于DB非常重要所以纳入),连接池排队,数据库后端连接数,年龄(本质是可用事物号的饱和度),SSD寿命等。
- 流量:QPS,TPS,Rollback(流量通常与业务指标有关属于业务监控范畴,但因为对于DB很重要所以纳入),QPS的季节性,TPS的突增。
错误报警
Postgres实例宕机区分主从,主库宕机触发P0报警,从库宕机触发P1报警。两者都需要立即介入,但从库通常有多个实例,且可以降级到主库上查询,有着更高的处理余量,所以从库宕机定为P1。
# primary|master instance down for 1m triggers a P0 alert
- alert: PG_PRIMARY_DOWN
expr: pg_up{instance=~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Postgres Primary Instance Down: {{$labels.instance}}"
description: "pg_up = {{ $value }} {{$labels.instance}}"
# standby|slave instance down for 1m triggers a P1 alert
- alert: PG_STANDBY_DOWN
expr: pg_up{instance!~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres Standby Instance Down: {{$labels.instance}}"
description: "pg_up = {{ $value }} {{$labels.instance}}"
Pgbouncer实例因为与Postgres实例一一对应,其存活性报警规则与Postgres统一。
# primary pgbouncer down for 1m triggers a P0 alert
- alert: PGB_PRIMARY_DOWN
expr: pgbouncer_up{instance=~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Pgbouncer Primary Instance Down: {{$labels.instance}}"
description: "pgbouncer_up = {{ $value }} {{$labels.instance}}"
# standby pgbouncer down for 1m triggers a P1 alert
- alert: PGB_STANDBY_DOWN
expr: pgbouncer_up{instance!~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Pgbouncer Standby Instance Down: {{$labels.instance}}"
description: "pgbouncer_up = {{ $value }} {{$labels.instance}}"
Prometheus Exporter的存活性定级为P1,虽然Exporter宕机本身并不影响数据库服务,但这通常预示着一些不好的情况,而且监控数据的缺失也会产生某些相应的报警。Exporter的存活性是通过Prometheus自己的up指标检测的,需要注意某些单实例多DB的特例。
# exporter down for 1m triggers a P1 alert
- alert: PG_EXPORTER_DOWN
expr: up{port=~"(9185|9127)"} == 0
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Exporter Down: {{$labels.instance}} {{$labels.port}}"
description: "port = {{$labels.port}}, {{$labels.instance}}"
所有存活性检测的持续时间阈值设定为1分钟,对15s的默认采集周期而言是四个样本点。常规的重启操作通常不会触发存活性报警。
延迟报警
与复制延迟有关的报警有三个:复制中断,复制延迟高,复制延迟异常,分别定级为P1, P2, P3
-
其中复制中断是一种错误,使用指标:
pg_repl_state_count{state="streaming"}进行判断,当前streaming状态的从库如果数量发生负向变动,则触发break报警。walsender会决定复制的状态,从库直接断开会产生此现象,缓冲区出现积压时会从streaming进入catchup状态也会触发此报警。此外,采用-Xs手工制作备份结束时也会产生此报警,此报警会在10分钟后自动Resolve。复制中断会导致客户端读到陈旧的数据,具有一定的场外影响,定级为P1。 -
复制延迟可以使用延迟时间或者延迟字节数判定。以延迟字节数为权威指标。常规状态下,复制延迟时间在百毫秒量级,复制延迟字节在百KB量级均属于正常。目前采用的是5s,15s的时间报警阈值。根据历史经验数据,这里采用了时间8秒与字节32MB的阈值,大致报警频率为每天个位数个。延迟时间更符合直觉,所以采用8s的P2报警,但并不是所有的从库都能有效取到该指标所以使用32MB的字节阈值触发P3报警补漏。
-
特例:
antispam,stats,coredb均经常出现复制延迟。
# replication break for 1m triggers a P0 alert. auto-resolved after 10 minutes.
- alert: PG_REPLICATION_BREAK
expr: pg_repl_state_count{state="streaming"} - (pg_repl_state_count{state="streaming"} OFFSET 10m) < 0
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Postgres Streaming Replication Break: {{$labels.instance}}"
description: "delta = {{ $value }} {{$labels.instance}}"
# replication lag greater than 8 second for 3m triggers a P1 alert
- alert: PG_REPLICATION_LAG
expr: pg_repl_replay_lag{application_name="walreceiver"} > 8
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres Replication Lagged: {{$labels.instance}}"
description: "lag = {{ $value }} seconds, {{$labels.instance}}"
# replication diff greater than 32MB for 5m triggers a P3 alert
- alert: PG_REPLICATOIN_DIFF
expr: pg_repl_lsn{application_name="walreceiver"} - pg_repl_replay_lsn{application_name="walreceiver"} > 33554432
for: 5m
labels:
team: DBA
urgency: P3
annotations:
summary: "P3 Postgres Replication Diff Deviant: {{$labels.instance}}"
description: "delta = {{ $value }} {{$labels.instance}}"
饱和度报警
饱和度指标主要资源,包含很多系统级监控的指标。主要包括:CPU,磁盘(这两个属于系统监控但对于DB非常重要所以纳入),连接池排队,数据库后端连接数,年龄(本质是可用事物号的饱和度),SSD寿命等。
堆积检测
堆积主要包含两类指标,一方面是PG本身的后端连接数与活跃连接数,另一方面是连接池的排队情况。
PGB排队是决定性的指标,它代表用户端可感知的阻塞已经出现,因此,配置排队超过15持续1分钟触发P0报警。
# more than 8 client waiting in queue for 1 min triggers a P0 alert
- alert: PGB_QUEUING
expr: sum(pgbouncer_pool_waiting_clients{datname!="pgbouncer"}) by (instance,datname) > 8
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Pgbouncer {{ $value }} Clients Wait in Queue: {{$labels.instance}}"
description: "waiting clients = {{ $value }} {{$labels.instance}}"
后端连接数是一个重要的报警指标,如果后端连接持续达到最大连接数,往往也意味着雪崩。连接池的排队连接数也能反映这种情况,但不能覆盖应用直连数据库的情况。后端连接数的主要问题是它与连接池关系密切,连接池在短暂堵塞后会迅速打满后端连接,但堵塞恢复后这些连接必须在默认约10min的Timeout后才被释放。因此收到短暂堆积的影响较大。同时外晚上1点备份时也会出现这种情况,容易产生误报。
注意后端连接数与后端活跃连接数不同,目前报警使用的是活跃连接数。后端活跃连接数通常在0~1,一些慢库在十几左右,离线库可能会达到20~30。但后端连接/进程数(不管活跃不活跃),通常均值可达50。后端连接数更为直观准确。
对于后端连接数,这里使用两个等级的报警:超过90持续3分钟P1,以及超过80持续10分钟P2,考虑到通常数据库最大连接数为100。这样做可以以尽可能低的误报率检测到雪崩堆积。
# num of backend exceed 90 for 3m
- alert: PG_BACKEND_HIGH
expr: sum(pg_db_numbackends) by (node) > 90
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres Backend Number High: {{$labels.instance}}"
description: "numbackend = {{ $value }} {{$labels.instance}}"
# num of backend exceed 80 for 10m (avoid pgbouncer jam false alert)
- alert: PG_BACKEND_WARN
expr: sum(pg_db_numbackends) by (node) > 80
for: 10m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres Backend Number Warn: {{$labels.instance}}"
description: "numbackend = {{ $value }} {{$labels.instance}}"
空闲事务
目前监控使用IDEL In Xact的绝对数量作为报警条件,其实 Idle In Xact的最长持续时间可能会更有意义。因为这种现象其实已经被后端连接数覆盖了。长时间的空闲是我们真正关注的,因此这里使用所有空闲事务中最高的闲置时长作为报警指标。设置3分钟为P2报警阈值。经常出现IDLE的非Offline库有:moderation, location, stats,sms, device, moderationdevice
# max idle xact duration exceed 3m
- alert: PG_IDLE_XACT
expr: pg_activity_max_duration{instance!~".*offline.*", state=~"^idle in transaction.*"} > 180
for: 3m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres Long Idle Transaction: {{$labels.instance}}"
description: "duration = {{ $value }} {{$labels.instance}}"
资源报警
CPU, 磁盘,AGE
默认清理年龄为2亿,超过10Y报P1,既留下了充分的余量,又不至于让人忽视。
# age wrap around (progress in half 10Y) triggers a P1 alert
- alert: PG_XID_WRAP
expr: pg_database_age{} > 1000000000
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres XID Wrap Around: {{$labels.instance}}"
description: "age = {{ $value }} {{$labels.instance}}"
磁盘和CPU由运维配置,不变
流量
因为各个业务的负载情况不一,为流量指标设置绝对值是相对困难的。这里只对TPS和Rollback设置绝对值指标。而且较为宽松。
Rollback OPS超过4则发出P3警告,TPS超过24000发P2,超过30000发P1
# more than 30k TPS lasts for 1m triggers a P1 (pgbouncer bottleneck)
- alert: PG_TPS_HIGH
expr: rate(pg_db_xact_total{}[1m]) > 30000
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres TPS High: {{$labels.instance}} {{$labels.datname}}"
description: "TPS = {{ $value }} {{$labels.instance}}"
# more than 24k TPS lasts for 3m triggers a P2
- alert: PG_TPS_WARN
expr: rate(pg_db_xact_total{}[1m]) > 24000
for: 3m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres TPS Warning: {{$labels.instance}} {{$labels.datname}}"
description: "TPS = {{ $value }} {{$labels.instance}}"
# more than 4 rollback per seconds lasts for 5m
- alert: PG_ROLLBACK_WARN
expr: rate(pg_db_xact_rollback{}[1m]) > 4
for: 5m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres Rollback Warning: {{$labels.instance}}"
description: "rollback per sec = {{ $value }} {{$labels.instance}}"
QPS的指标与业务高度相关,因此不适合配置绝对值,可以为QPS突增配置一个报警项
短时间(和10分钟)前比突增30%会触发一个P2警报,同时避免小QPS下的突发流量,设置一个绝对阈值10k
# QPS > 10000 and have a 30% inc for 3m triggers P2 alert
- alert: PG_QPS_BURST
expr: sum by(datname,instance)(rate(pgbouncer_stat_total_query_count{datname!="pgbouncer"}[1m]))/sum by(datname,instance) (rate(pgbouncer_stat_total_query_count{datname!="pgbouncer"}[1m] offset 10m)) > 1.3 and sum by(datname,instance) (rate(pgbouncer_stat_total_query_count{datname!="pgbouncer"}[1m])) > 10000
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P2 Pgbouncer QPS Burst 30% and exceed 10000: {{$labels.instance}}"
description: "qps = {{ $value }} {{$labels.instance}}"
Prometheus报警规则
完整的报警规则详见:参考-报警规则