After configuring Pigsty, you can do some interesting explorations and experiments with it.
This the multi-page printable view of this section. Click here to print.
Tasks
database access, HA drills, some of the tasks that can be explored in Pigsty
- 1: Migration based on logical replication
- 2: HA Drill
- 3: How to optmize slow queries with pigsty
- 4: App Example
1 - Migration based on logical replication
How to perform a smooth migration based on logical replication
本文基于Pigsty沙箱中的实例,介绍基于逻辑复制进行主从切换与数据库迁移的原理,细节与注意事项。
逻辑复制相关基础知识可参考 Postgres逻辑复制详解 一文。
0 逻辑复制迁移
逻辑复制通常可用于跨大版本跨操作系统在线升级PostgreSQL,例如从PG 10到PG 13,从Windows到Linux。
0.1 逻辑迁移的优点
相比原地pg_upgrade升级与pg_dump升级,逻辑复制的好处有:
- 在线:迁移可以在线进行,不需要或者只需要极小的停机窗口。
- 灵活:目标库的结构可以与源库不同,例如普通表改为分区表,加列等。可以跨越大版本使用。
- 安全:相比物理复制,目标库是可写的,因此在最终切换前,可以随意进行测试并重建。
- 快速:停机窗口很短,可以控制在秒级到分钟级。
0.2 逻辑迁移的局限性
逻辑复制的局限性主要在于设置相对繁琐,初始时刻拷贝数据较物理复制更慢,对于单实例多DB的情况需要迁移多次。大对象与序列号需要在迁移时手动同步。
-
不能复制DDL变更
-
不能复制序列号(Sequence)
-
如果逻辑从库上某张被外键引用的表被Truncate,但因为引用该表的表不在订阅集中(所以无法在不truncate该表的情况下继续,但在订阅集之外的表上执行truncate违反语义),那么就会出现冲突。
-
大对象无法复制。
-
只支持普通表的复制,包括分区表。不支持视图,物化视图,外部表。
总体来说都,属于可以解决或可以容忍的问题。
0.3 逻辑迁移的基本流程
整体上讲,基于逻辑复制的迁移遵循以下步骤:
其中准备工作与存量迁移部分耗时较长,但不需要停机,不会对生产业务产生影响。
切换时刻需要短暂的停机窗口,采用自动化的脚本可以将停机时间控制在秒级到分钟级。
下面将基于Pigsty沙箱介绍这些步骤涉及到的具体细节。
1 准备工作
1.1 准备源宿集群
在进行迁移之前,首先要确定迁移的源端集群与目标集群配置正确。
Pigsty标准沙箱由四个节点与两套数据库集群构成。
两套数据库集群pg-meta与pg-test将分别作为逻辑复制的源端(SRC)与宿端(DST)。
本例将pg-meta-1作为发布者,pg-test-1作为订阅者,将pgbench相关表从pg-meta迁移至pg-test。
1.1.1 用户
迁移通常需要在原宿两端拥有两个用户,分别用于管理与复制。
CREATE USER dbuser_admin SUPERUSER; -- 超级用户用于创建发布与订阅
CREATE USER replicator REPLICATION BYPASSRLS; -- 复制用户用于订阅变更
1.1.2 HBA规则
同时,还需要配置相应的HBA规则,允许复制用户在原宿集群间相互访问。
此外,迁移通常会从中控机发起,应当允许管理用户从中控机访问原/宿集群。
因为创建订阅需要超级用户权限,建议为管理用户(永久或临时)配置SUPERUSER权限。
1.1.3 配置项
必选的配置项是wal_level,您必须在源端将wal_level配置为logical,方能启用逻辑复制。
其他一些关于复制的相关参数也需要合理配置,但除了wal_level外的参数默认值都不会影响逻辑复制正常工作,均为可选。
推荐在源端与宿端使用相同的配置项,下面是在64核机器上,一些相关配置的参考值:
wal_level: logical # MANDATORY!
max_worker_processes: 64 # default 8 -> 64, set to CPU CORE 64
max_parallel_workers: 32 # default 8 -> 32, limit by max_worker_processes
max_parallel_maintenance_workers: 16 # default 2 -> 16, limit by parallel worker
max_parallel_workers_per_gather: 0 # default 2 -> 0, disable parallel query on OLTP instance
# max_parallel_workers_per_gather: 16 # default 2 -> 16, enable parallel query on OLAP instance
max_wal_senders: 24 # 10 -> 24
max_replication_slots: 16 # 10 -> 16
max_logical_replication_workers: 8 # 4 -> 8, 6 sync worker + 1~2 apply worker
max_sync_workers_per_subscription: 6 # 2 -> 6, 6 sync worker
对于数据库来说,通常还需要关注数据库的 编码(encoding)与 本地化 (locale)配置项是否正确,通常建议统一使用C.UTF8。
1.1.4 连接信息
为了执行管理命令,您需要通过连接串访问原/宿集群的主库。
建议不要在连接串中使用明文密码,密码可以通过~/.pgpass,~/.pg_service,环境变量等方式管理,下面使用时将不会列出密码。
PGSRC='postgres://dbuser_admin@10.10.10.10/meta' # 源端发布者 (SU)
PGDST='postgres://dbuser_admin@10.10.10.11/test' # 宿端订阅者 (SU)
建议在中控机/元节点上执行迁移命令,并在操作过程中保持上面两个变量生效。
1.2 确定迁移对象
相比于物理复制,逻辑复制允许用户对复制的内容与过程施加更为精细的控制。您可以选择数据库内容的一个子集进行复制。不过在这个例子中,我们将进行整库复制。
在本例中,我们采用pgbench提供的用例作为迁移标的。因此可以在源端集群使用pgbench初始化相关表项。
pgbench -is64 ${PGSRC}
此外,考虑到测试的覆盖范围,我们还将创建一张额外的测试数据表(用于测试Sequence的迁移)
psql ${PGSRC} -qAXtw <<-EOF
DROP TABLE IF EXISTS pgbench_extras;
CREATE TABLE IF NOT EXISTS pgbench_extras
(id BIGSERIAL PRIMARY KEY,v TIMESTAMP NOT NULL UNIQUE);
EOF
要注意,只有 基本表 (包括分区表)可以参与逻辑复制,其他类型的对象,包括 视图,物化视图,外部表,索引,序列号都无法加入到逻辑复制中。使用以下查询,可以列出当前数据库中可以加入逻辑复制的表的完全限定名。
SELECT quote_ident(nspname) || '.' || quote_ident(relname) AS name
FROM pg_class c JOIN pg_namespace n ON c.relnamespace = n.oid
WHERE relkind = 'r' AND nspname NOT IN ('pg_catalog', 'information_schema', 'monitor', 'repack', 'pg_toast')
在准备阶段,您需要筛选出希望进行复制的表。在存量迁移中将这些表的结构定义同步至宿集群中,并建立在这些表上的逻辑复制。
1.3 修复复制标识
并不是所有的表都可以直接纳入逻辑复制中并正常工作。在进行迁移前,您需要对所有待迁移的表进行检查,确认它们都已经正确配置了复制标识。
| 复制身份模式\表上的约束 | 主键(p) | 非空唯一索引(u) | 两者皆无(n) |
|---|---|---|---|
| default | 有效 | x | x |
| index | x | 有效 | x |
| full | 低效 | 低效 | 低效 |
| nothing | x | x | x |
-
如果表上有主键,则会默认使用
REPLICA IDENTITY default,这是最好的,不用进行任何修改。 -
如果表上没有主键,有条件的话请创建一个,没有条件的话,一个建立在非空列集上的唯一索引也可以起到同样的作用。在这种情况下需要显式的为表配置
REPLICA IDENTITY USING <tbl_unique_key_idx_name>。 -
如果表上既没有主键,也没有唯一索引,那么您可以为表配置
REPLICA IDENTITY FULL,将完整的一行作为复制标识。使用
FULL身份标识的性能非常差,发布侧和订阅侧的删改操作都会导致顺序扫表,建议只将其作为保底手段使用。另一种选择是为表配置
REPLICA IDENTITY NOTHING,这样任何在发布端对此表进行UPDATE|DELETE操作都会直接报错中止。
使用以下查询,可以列出所有表的完全限定名,复制标识配置,以及表上是否有主键或唯一索引,
SELECT quote_ident(nspname) || '.' || quote_ident(relname) AS name, con.ri AS keys,
CASE relreplident WHEN 'd' THEN 'default' WHEN 'n' THEN 'nothing' WHEN 'f' THEN 'full' WHEN 'i' THEN 'index' END AS identity
FROM pg_class c JOIN pg_namespace n ON c.relnamespace = n.oid, LATERAL (SELECT array_agg(contype) AS ri FROM pg_constraint WHERE conrelid = c.oid) con
WHERE relkind = 'r' AND nspname NOT IN ('pg_catalog', 'information_schema', 'monitor', 'repack', 'pg_toast')
ORDER BY 2,3;
以1.2的测试场景为例:
name | keys | identity
-------------------------+-------+----------
public.spatial_ref_sys | {c,p} | default
public.pgbench_accounts | {p} | default
public.pgbench_branches | {p} | default
public.pgbench_tellers | {p} | default
public.pgbench_extras | {p,u} | default
public.pgbench_history | NULL | default
如果表上只有唯一索引,例如您需要检查该唯一索引是否满足要求:所有列都为非空,not deferrable,not partial,如果满足,则可以使用以下命令将表的复制身份修改为index模式。
-- 一个例子:即使pgbench_extras上有主键,但也可以使用唯一索引作为身份标识
ALTER TABLE pgbench_extras REPLICA IDENTITY USING INDEX pgbench_extras_v_key;
如果表上没有主键,也没有唯一约束。如上面的pgbench_history表,那就需要通过以下命令将其复制身份设置为FULL|NOTHING。
ALTER TABLE pgbench_history REPLICA IDENTITY FULL;
完成修复后,所有表都应当具有合适的复制身份:
name | keys | identity
-------------------------+-------+----------
public.spatial_ref_sys | {c,p} | default
public.pgbench_accounts | {p} | default
public.pgbench_branches | {p} | default
public.pgbench_tellers | {p} | default
public.pgbench_extras | {p,u} | index
public.pgbench_history | NULL | full
2 存量迁移
2.1 同步数据库模式
2.1.1 转储
使用以下命令转储所有对象定义,并复制到宿端应用。
pg_dump ${PGSRC} --schema-only -n public | psql ${PGDST}
可以通过pg_dump的-n,-t参数进行灵活控制,只转储所需的对象。例如,如果只需要public模式下pgbench的相关表,则可以通过以下命令转储:
pg_dump ${PGSRC} --schema-only -n public -t 'pgbench_*' | psql ${PGDST}
2.1.2 校验
同步完成后,通常需要进行模式校验。
- 所有目标表及其索引、序列号是否已经建立
- 函数、类型、模式、用户、权限是否均符合预期?
数据库模式需要根据用户自己的需求进行同步与校验,没有什么通用的方式。
2.2 在源端创建发布
源端集群主库作为发布者,需要创建发布,将所需的表加入到发布集中。
2.2.1 创建发布的方式
创建发布的语法如下所示:
CREATE PUBLICATION name
[ FOR TABLE [ ONLY ] table_name [ * ] [, ...]
| FOR ALL TABLES ]
[ WITH ( publication_parameter [= value] [, ... ] ) ]
针对所有表创建发布(需要超级用户权限):
CREATE PUBLICATION "pg_meta_pub" FOR ALL TABLES;
注意无论是发布还是订阅,名称都建议遵循PostgreSQL对象标识符命名规则([a-z][0-9a-z_]+),特别是不要在名称中使用-。以免不必要的麻烦,例如创建订阅同名的复制槽因命名不规范而失败。
如果需要控制订阅的事件类型(不常见),可以通过参数publish指定,默认为insert, update, delete, truncate。
如果源端上有分区表,有一个参数可以用于控制其复制行为。把分区表当成一张表(使用分区根表的复制标识),还是当成多张子表(使用子表上的复制标识)来处理。启用这个选项可以把分区表在逻辑上看成一张表(分区根表),而不是一系列的分区子表,所以订阅端只需要存在一张分区根表的同名表即可正常复制,这是13版本引入的新选项。该选项默认为false,也就是说逻辑复制分区表时,源端的每一个分区都必须在订阅端存在。
额外的参数可以通过以下的形式传入:
CREATE PUBLICATION "pg_meta_pub" FOR ALL TABLES
WITH(publish = 'insert', publish_via_partition_root = true);
2.2.2 发布的内容
如果不希望发布所有的表,则可以在发布中具体指定所需的表名称。
例如在这个例子中spatial_ref_sys是一张postgis扩展使用的常量表,并不需要迁移,我们可以将其排除。利用以下SQL,可以直接在数据库中拼接出创建发布的SQL命令:
SELECT E'CREATE PUBLICATION pg_meta_pub FOR TABLE\n' ||
string_agg(quote_ident(nspname) || '.' || quote_ident(relname), E',\n') || ';' AS sql
FROM pg_class c JOIN pg_namespace n ON c.relnamespace = n.oid
WHERE relkind = 'r' AND nspname NOT IN ('pg_catalog', 'information_schema', 'monitor', 'repack', 'pg_toast')
AND relname ~ 'pgbench'; -- 只复制表名形如 pgbench* 的表
\gexec -- 在psql中执行上面命令生成的SQL语句
在这个例子中,实际生成并执行的命令如下:
psql ${PGSRC} -Xtw <<-EOF
CREATE PUBLICATION pg_meta_pub FOR TABLE
public.pgbench_accounts,
public.pgbench_branches,
public.pgbench_tellers,
public.pgbench_history,
public.pgbench_extras;
EOF
2.2.3 确认发布状态
建立完发布后,可以从 pg_publication 视图看到所创建的发布。
$ psql ${PGSRC} -Xxwc 'table pg_publication;'
-[ RECORD 1 ]+------------
oid | 24679
pubname | pg_meta_pub
pubowner | 10
puballtables | f
pubinsert | t
pubupdate | t
pubdelete | t
pubtruncate | t
pubviaroot | f
可以从pg_publication_tables确认纳入到发布中的表有哪些。
$ psql ${PGSRC} -Xwc 'table pg_publication_tables;'
pubname | schemaname | tablename
-------------+------------+------------------
pg_meta_pub | public | pgbench_history
pg_meta_pub | public | pgbench_tellers
pg_meta_pub | public | pgbench_accounts
pg_meta_pub | public | pgbench_branches
pg_meta_pub | public | pgbench_extras
确认无误后,发布端的工作完成。接下来要在宿端集群主库上创建订阅,订阅源端集群主库上的这个发布。
2.3 在宿端创建订阅
宿端集群主库作为订阅者,需要创建订阅,从发布者上订阅所需的变更。
2.3.1 创建订阅
创建订阅需要SUPERUSER权限,创建订阅的语法如下所示:
CREATE SUBSCRIPTION subscription_name
CONNECTION 'conninfo'
PUBLICATION publication_name [, ...]
[ WITH ( subscription_parameter [= value] [, ... ] ) ]
创建订阅必须使用CONNECTION子句指定发布者的连接信息,通过PUBLICATION子句指定发布名称。这里使用replicator用户连接发布者,该用户的密码已经写入宿端实例下~/.pgpass,因此这里可以在连接串中省去。
创建订阅还有一些其他的参数,通常只有手动管理复制槽时才需要修改这些参数:
copy_data,默认为true,当复制开始时,是否要复制全量数据。create_slot,默认为true,该订阅是否会在发布实例上创建复制槽。enabled,默认为true,是否立即开始订阅。connect,默认为true,是否连接至订阅实例,如果不连接,上面几个选项都会被重置为false。
这里,创建订阅的实际命令为:
psql ${PGDST} -Xtw <<-EOF
CREATE SUBSCRIPTION "pg_test_sub"
CONNECTION 'host=10.10.10.10 user=replicator dbname=meta'
PUBLICATION "pg_meta_pub";
EOF
2.3.2 订阅状态确认
成功创建订阅后,可以从 pg_subscription 视图看到所创建的发布。
$ psql ${PGDST} -Xxwc 'TABLE pg_subscription;'
-[ RECORD 1 ]---+---------------------------------------------
oid | 20759
subdbid | 19351
subname | pg_test_sub
subowner | 16390
subenabled | t
subconninfo | host=10.10.10.10 user=replicator dbname=meta
subslotname | pg_test_sub
subsynccommit | off
subpublications | {pg_meta_pub}
可以从pg_subscription_rel中确认哪些表被纳入到订阅的范围,及其复制状态。
$ psql ${PGDST} -Xwc 'table pg_subscription_rel;'
srsubid | srrelid | srsubstate | srsublsn
---------+---------+------------+------------
20759 | 20742 | r | 0/B0BC1FB8
20759 | 20734 | r | 0/B0BC20B0
20759 | 20737 | r | 0/B0BC20B0
20759 | 20745 | r | 0/B0BC20B0
20759 | 20731 | r | 0/B0BC20B0
2.4 等待逻辑复制同步
创建订阅后,首先必须监控 发布端与订阅端两侧的数据库日志,确保没有错误产生。
2.4.1 逻辑复制状态机
如果一切正常,逻辑复制会自动开始,针对每张订阅中的表执行复制状态机逻辑,如下图所示。
当所有的表都完成复制,进入r(ready)状态时,逻辑复制的存量同步阶段便完成了,发布端与订阅端整体进入同步状态。
stateDiagram-v2
[*] --> init : 表被加入到订阅集中
init --> data : 开始同步表的初始快照
data --> sync : 存量数据同步完成
sync --> ready : 同步期间的增量变更应用完毕,进入就绪状态
当创建或刷新订阅时,表会被加入到 订阅集 中,每一张订阅集中的表都会在pg_subscription_rel视图中有一条对应纪录,展示这张表当前的复制状态。刚加入订阅集的表初始状态为i,即initialize,初始状态。
如果订阅的copy_data选项为真(默认情况),且工作进程池中有空闲的Worker,PostgreSQL会为这张表分配一个同步工作进程,同步这张表上的存量数据,此时表的状态进入d,即拷贝数据中。对表做数据同步类似于对数据库集群进行basebackup,Sync Worker会在发布端创建临时的复制槽,获取表上的快照并通过COPY完成基础数据同步。
当表上的基础数据拷贝完成后,表会进入sync模式,即数据同步,同步进程会追赶同步过程中发生的增量变更。当追赶完成时,同步进程会将这张表标记为r(ready)状态,转交逻辑复制主Apply进程管理变更,表示这张表已经处于正常复制中。
2.4.2 同步进度跟踪
数据同步(d)阶段可能需要花费一些时间,取决于网卡,网络,磁盘,表的大小与分布,逻辑复制的同步worker数量等因素。
作为参考,1TB的数据库,20张表,包含有250GB的大表,双万兆网卡,在6个数据同步worker的负责下大约需要6~8小时完成复制。
在数据同步过程中,每个表同步任务都会源端库上创建临时的复制槽。请确保逻辑复制初始同步期间不要给源端主库施加过大的不必要写入压力,以免WAL撑爆磁盘。
发布侧的 pg_stat_replication,pg_replication_slots,订阅端的pg_stat_subscription,pg_subscription_rel提供了逻辑复制状态的相关信息,需要关注。
psql ${PGDST} -Xxw <<-'EOF'
SELECT subname, json_object_agg(srsubstate, cnt) FROM
pg_subscription s JOIN
(SELECT srsubid, srsubstate, count(*) AS cnt FROM pg_subscription_rel
GROUP BY srsubid, srsubstate) sr
ON s.oid = sr.srsubid GROUP BY subname;
EOF
可以使用以下SQL确认订阅中表的状态,如果所有表的状态都显示为r,则表示逻辑复制已经成功建立,订阅端可以用于切换。
subname | json_object_agg
-------------+-----------------
pg_test_sub | { "r" : 5 }
当然,最好的方式始终是通过监控系统来跟踪复制状态。
3 切换时刻
3.1 准备工作
一个良好的工程实践是,在搞事情之前,在源端宿端都执行几次存盘操作,避免后续操作因被内存刷盘拖慢。
也可以执行分析命令更新统计信息,便于后续快速对比校验数据完整性。
psql ${PGSRC} -Xxwc 'CHECKPOINT;ANALYZE;CHECKPOINT;'
psql ${PGSRC} -Xxwc 'CHECKPOINT;ANALYZE;CHECKPOINT;'
在此之后的操作,都处于服务不可用状态,因此尽可能快地进行。通常情况下在分钟级内完成较为合适。
3.2 停止源端写入流量
3.2.1 选择合适的停止方式
暂停源端写入有多种方式,请根据实际业务场景选择与组合:
- 告知业务方停止流量
- 停止解析源端主库域名
- 停止或暂停负载均衡器(Haproxy | VIP)的流量转发
- 停止或暂停连接池Pgbouncer
- 停止或暂停Postgres实例
- 修改数据库主库的参数,设置默认事务模式为只读。
- 修改数据库主库的HBA规则,拒绝业务访问。
通常建议使用修改HBA,修改连接池,修改负载均衡器的方式停止主库的写入流量。
请注意,无论使用何种方式,建议保持PostgreSQL存活,并且管理用户和复制用户仍然可以连接到源端主库。
3.2.2 确认源端写入流量停止
当源端主库停止接受写入后,首先执行确认逻辑,通过观察pg_stat_replication,确认逻辑订阅者已经与发布者保持同步。
psql ${PGSRC} -Xxw <<-EOF
SELECT application_name AS name,
pg_current_wal_lsn() AS lsn,
pg_current_wal_lsn() - replay_lsn AS lag
FROM pg_stat_replication;
EOF
-[ RECORD 1 ]-----
name | pg_test_sub
lsn | 0/B0C24918
lag | 0
重复执行上述命令,如果lsn字段保持不变,lag始终为0,就说明主库的写入流量已经正确停止,且逻辑从库上已经没有复制延迟,可以用于切换。
3.2.3 建立反向逻辑复制(可选)
如果要求迁移失败后业务可以随时回滚,可以在停止源端写入流量后,设置反向的逻辑复制,将后续订阅端(新主库)的变更反向同步至原来的发布端(旧主库)。不过此过程需要重新同步数据,耗时太久。通常情况下,只有在数据非常重要,且数据量不大或停机窗口足够长的情况下才适用于此方法。
首先停止宿端现有的逻辑订阅。必须停止现有逻辑复制才能继续后面的步骤,否则会形成循环复制。
停止源端写入流量后,继续维持逻辑复制没有意义,因此可以停止宿端的订阅。但建议保留该订阅,只是禁用它,以备迁移失败回滚。
psql ${PGDST} -qAXtwc 'ALTER SUBSCRIPTION pg_test_sub DISABLE;'
然后依照上述流程重新建立 反向的逻辑复制,这里只给出命令:
# 在宿端创建发布:pg_test_pub
psql ${PGDST} -Xtw <<-EOF
CREATE PUBLICATION pg_test_pub FOR TABLE
public.pgbench_accounts,
public.pgbench_branches,
public.pgbench_tellers,
public.pgbench_history,
public.pgbench_extras;
TABLE pg_publication;
EOF
# 在源端创建订阅
psql ${PGSRC} -Xtw <<-EOF
CREATE SUBSCRIPTION "pg_meta_sub"
CONNECTION 'host=10.10.10.11 user=replicator dbname=test'
PUBLICATION "pg_test_pub";
TABLE pg_subscription;
EOF
# 清空源端所有相关表(危险),等待/或者不等待同步完成
psql ${PGSRC} -Xtw <<-EOF
TRUNCATE TABLE
public.pgbench_accounts,
public.pgbench_branches,
public.pgbench_tellers,
public.pgbench_history,
public.pgbench_extras;
TABLE pg_publication;
EOF
3.3 同步序列号与其他对象
逻辑复制不复制序列号(Sequence),因此基于逻辑复制做Failover时,必须在切换前手工同步序列号的值。
3.3.1 从源端同步序列号值
如果您的序列号都是从表上的SERIAL列定义自动创建的,而且宿端库也单纯只从源端订阅,那么同步序列号比较简单。从订阅端找出所有需要同步的序列号:
PGSRC='postgres://dbuser_admin@10.10.10.10/meta' # 源端发布者 (SU)
PGDST='postgres://dbuser_admin@10.10.10.11/test' # 宿端订阅者 (SU)
-- 查询订阅端,生成的用于同步SEQUENCE的shell命令
psql ${PGDST} -qAXtw <<-'EOF'
SELECT 'pg_dump ${PGSRC} -a ' ||
string_agg('-t ' || quote_ident(schemaname) || '.' || quote_ident(sequencename), ' ') ||
' | grep setval | psql -qAXtw ${PGDST}'
FROM pg_sequences;
EOF
在本例中,只有pgbench_extras.id上有一个对应的SEQUENCE pgbench_extras_id_seq。这里生成的同步语句为
pg_dump ${PGSRC} -a -t public.pgbench_extras_id_seq | grep setval | psql -qAXtw ${PGDST}
比较复杂的情况,需要您手工生成这条命令,通过-t依次指定需要转储的序列号。
3.3.2 基于业务数据设置序列号值
另一种管理序列号的方式是直接根据表中的数据设置序列号的值,而无需从源端同步。
例如,表pgbench_extras.id的最大值为100,那么将订阅端端pgbench_extras_id_seq直接设置为一个足够大的值,例如100+10000 = 10100,就可以保证迁移后使用该序列号分配的新id不会与已有数据冲突。
采用这种方式,可以直接在故障切换前进行序列号的设置,减少迁移切换所需的停机时间。但这样可能会导致业务数据序列号分配出现空洞,对于一些边界条件与特殊的序列号使用场景需要特别小心。例如:序列号从未被使用过,序列号的增长步长为负数,采用函数发号器调用Sequence等。
直接设置序列号的命令如下所示:
psql ${PGDST} -qAXtw <<-'EOF'
SELECT pg_catalog.setval('public.pgbench_extras_id_seq', (SELECT max(id) + 1000 FROM pgbench_extras));
EOF
3.3.3 其他对象的同步
某些无法被逻辑复制处理的对象,也需要在这里一并进行同步。
例如:刷新物化视图,手工迁移大对象等。但这些功能很少有人会用到,所以在此不详细展开。
3.4 校验数据一致性
如果逻辑复制工作正常,通常不用校验数据,您可以在第二步中间执行多次对比校验以增强对逻辑复制的信心。
在停机窗口期间,建议只进行简单基本的数据校验,例如,比较表中的行数,主键的最大最小值是否一致。
以下函数用于执行这一校验
function compare_relation(){
local relname=$1
local identity=${2-'id'}
psql ${3-${PGSRC}} -AXtwc "SELECT count(*) AS cnt, max($identity) AS max, min($identity) AS min FROM ${relname};"
psql ${4-${PGDST}} -AXtwc "SELECT count(*) AS cnt, max($identity) AS max, min($identity) AS min FROM ${relname};"
}
compare_relation pgbench_accounts aid
compare_relation pgbench_branches bid
compare_relation pgbench_history tid
compare_relation pgbench_tellers tid
function compare_relation() {
local src_url=${1}
local dst_url=${2}
local relname=${3}
res1=$(psql "${src_url}" -AXtwc "SELECT count(*) AS cnt FROM ${relname};")
res2=$(psql "${dst_url}" -AXtwc "SELECT count(*) AS cnt FROM ${relname};")
if [[ "${res1}" == "${res2}" ]]; then
echo -e "[ok] ${relname}\t\t\t${res1}\t${res2}"
else
echo -e "[xx] ${relname}\t\t\t${res1}\t${res2}"
fi
}
function compare_all() {
local src_url=${1}
local dst_url=${2}
tables=$(psql ${src_url} -AXtwc "SELECT quote_ident(nspname) || '.' || quote_ident(relname) AS name FROM pg_class c JOIN pg_namespace n ON c.relnamespace = n.oid WHERE relkind = 'r' AND nspname NOT IN ('pg_catalog', 'information_schema', 'monitor', 'repack', 'pg_toast')")
for tbl in $tables; do
result=$(compare_relation "${src_url}" "${dst_url}" ${tbl})
echo ${result}
done
}
compare_all ${PGSRC} ${PGDST}
同时,也可以过一遍3.3中同步的序列号,确认其配置是否相同。
psql ${PGSRC} -qwXtc "SELECT schemaname || '.' || sequencename AS name, last_value AS v FROM pg_sequences;"
psql ${PGDST} -qwXtc "SELECT schemaname || '.' || sequencename AS name, last_value AS v FROM pg_sequences;"
其他在3.3.3中手工同步的对象请按需自行校验。如果需要进行其他业务侧的校验,也在这里进行。但停机窗口时间宝贵,花费在这里的时间越长,服务不可用时间也越久。
校验完成后,就可以进行最终的流量切换了。
3.5 流量切换与善后
完成数据校验后就可以进行流量切换。
流量切换的方式取决于您所使用的访问方式,通常与3.2中停流量的方式对偶。例如:
- 修改应用端连接串,并应用生效
- 将源端主库域名解析至新主库
- 将负载均衡器(Haproxy | VIP)的流量转发至新主库
- 将原主库上Pgbouncer连接池的流量转发至新主库
通过监控系统或其他方式,确认写入流量已经正确应用订阅端的新主库后,基于逻辑复制的迁移就完成了。
不要忘记一些善后清理工作,停用并删除订阅端的订阅,删除发布端的发布。
同时,应当继续确保原主库拒绝新的写入,以免有未清理干净的流量因为配置失误错漏仍然向旧主库访问。
# 删除订阅侧的 订阅
psql ${PGDST} -qAXtw <<-'EOF'
ALTER SUBSCRIPTION pg_test_sub DISABLE;
DROP SUBSCRIPTION pg_test_sub;
EOF
# 删除发布侧的 发布
psql ${PGSRC} -qAXtw <<-'EOF'
DROP PUBLICATION pg_meta_sub;
EOF
至此,基于逻辑复制的完整迁移结束。
2 - HA Drill
Be prepared for failures!
Simulate several common failures in production environments to test the self-healing capabilities of Pigsty’s highly available database cluster.
Patroni Quick Start
patronictl is the patroni cli tool, aliased as pt
alias pt='patronictl -c /pg/bin/patroni.yml'
alias pt-up='sudo systemctl start patroni' # launch patroni
alias pt-dw='sudo systemctl stop patroni' # stop patroni
alias pt-st='systemctl status patroni' # report patroni status
alias pt-ps='ps aux | grep patroni' # show patroni processes
alias pt-log='tail -f /pg/log/patroni.log' # watch patroni logs
Patroni commands requires dbsu (which is postgres by default )
$ pt --help
Usage: patronictl [OPTIONS] COMMAND [ARGS]...
Options:
-c, --config-file TEXT Configuration file
-d, --dcs TEXT Use this DCS
-k, --insecure Allow connections to SSL sites without certs
--help Show this message and exit.
Commands:
configure Create configuration file
dsn Generate a dsn for the provided member,...
edit-config Edit cluster configuration
failover Failover to a replica
flush Discard scheduled events
history Show the history of failovers/switchovers
list List the Patroni members for a given Patroni
pause Disable auto failover
query Query a Patroni PostgreSQL member
reinit Reinitialize cluster member
reload Reload cluster member configuration
remove Remove cluster from DCS
restart Restart cluster member
resume Resume auto failover
scaffold Create a structure for the cluster in DCS
show-config Show cluster configuration
switchover Switchover to a replica
topology Prints ASCII topology for given cluster
version Output version of patronictl command or a...
场景一:Switchover
Switch是主动切换集群领导者
$ pt switchover
Master [pg-test-3]: pg-test-3
Candidate ['pg-test-1', 'pg-test-2'] []: pg-test-1
When should the switchover take place (e.g. 2020-10-23T17:06 ) [now]: now
Current cluster topology
+ Cluster: pg-test (6886641621295638555) -----+----+-----------+-----------------+
| Member | Host | Role | State | TL | Lag in MB | Tags |
+-----------+-------------+---------+---------+----+-----------+-----------------+
| pg-test-1 | 10.10.10.11 | Replica | running | 2 | 0 | clonefrom: true |
| pg-test-2 | 10.10.10.12 | Replica | running | 2 | 0 | clonefrom: true |
| pg-test-3 | 10.10.10.13 | Leader | running | 2 | | clonefrom: true |
+-----------+-------------+---------+---------+----+-----------+-----------------+
Are you sure you want to switchover cluster pg-test, demoting current master pg-test-3? [y/N]: y
2020-10-23 16:06:11.76252 Successfully switched over to "pg-test-1"
场景二:Failover
# run as postgres @ any member of cluster `pg-test`
$ pt failover
Candidate ['pg-test-2', 'pg-test-3'] []: pg-test-3
Current cluster topology
+ Cluster: pg-test (6886641621295638555) -----+----+-----------+-----------------+
| Member | Host | Role | State | TL | Lag in MB | Tags |
+-----------+-------------+---------+---------+----+-----------+-----------------+
| pg-test-1 | 10.10.10.11 | Leader | running | 1 | | clonefrom: true |
| pg-test-2 | 10.10.10.12 | Replica | running | 1 | 0 | clonefrom: true |
| pg-test-3 | 10.10.10.13 | Replica | running | 1 | 0 | clonefrom: true |
+-----------+-------------+---------+---------+----+-----------+-----------------+
Are you sure you want to failover cluster pg-test, demoting current master pg-test-1? [y/N]: y
+ Cluster: pg-test (6886641621295638555) -----+----+-----------+-----------------+
| Member | Host | Role | State | TL | Lag in MB | Tags |
+-----------+-------------+---------+---------+----+-----------+-----------------+
| pg-test-1 | 10.10.10.11 | Replica | running | 2 | 0 | clonefrom: true |
| pg-test-2 | 10.10.10.12 | Replica | running | 2 | 0 | clonefrom: true |
| pg-test-3 | 10.10.10.13 | Leader | running | 2 | | clonefrom: true |
+-----------+-------------+---------+---------+----+-----------+-----------------+
场景三:从库Patroni/Postgres宕机
场景四:主库Patroni/Postgres宕机
场景五:DCS不可用
场景六:维护模式
问题探讨
关键问题:DCS的SLA如何保障?
==在自动切换模式下,如果DCS挂了,当前主库会在retry_timeout 后Demote成从库,导致所有集群不可写==。
作为分布式共识数据库,Consul/Etcd是相当稳健的,但仍必须确保DCS的SLA高于DB的SLA。
解决方法:配置一个足够大的retry_timeout,并通过几种以下方式从管理上解决此问题。
- SLA确保DCS一年的不可用时间短于该时长
- 运维人员能确保在
retry_timeout之内解决DCS Service Down的问题。 - DBA能确保在
retry_timeout之内将关闭集群的自动切换功能(打开维护模式)。
可以优化的点? 添加绕开DCS的P2P检测,如果主库意识到自己所处的分区仍为Major分区,不触发操作。
关键问题:HA策略,RPO优先或RTO优先?
可用性与一致性谁优先?例如,普通库RTO优先,金融支付类RPO优先。
普通库允许紧急故障切换时丢失极少量数据(阈值可配置,例如最近1M写入)
与钱相关的库不允许丢数据,相应地在故障切换时需要更多更审慎的检查或人工介入。
关键问题:Fencing机制,是否允许关机?
在正常情况下,Patroni会在发生Leader Change时先执行Primary Fencing,通过杀掉PG进程的方式进行。
但在某些极端情况下,比如vm暂停,软件Bug,或者极高负载,有可能没法成功完成这一点。那么就需要通过重启机器的方式一了百了。是否可以接受?在极端环境下会有怎样的表现?
关键操作:选主之后
选主之后要记得存盘。手工做一次Checkpoint确保万无一失。
关键问题:流量切换怎样做,2层,4层,7层
- 2层:VIP漂移
- 4层:Haproxy分发
- 7层:DNS域名解析
关键问题:一主一从的特殊场景
- 2层:VIP漂移
- 4层:Haproxy分发
- 7层:DNS域名解析
HA Procedure
Failure Detection
https://patroni.readthedocs.io/en/latest/SETTINGS.html#dynamic-configuration-settings
Fencing
Configure Watchdog
https://patroni.readthedocs.io/en/latest/watchdog.html
Bad Cases
Traffic Routing
DNS
VIP
HAproxy
Pgbouncer

3 - How to optmize slow queries with pigsty
A typical example of optimizing slow queries
下面以Pigsty自带的沙箱环境为例,介绍一个使用Pigsty监控系统处理慢查询的过程。
慢查询:模拟
因为没有实际的业务系统,这里我们以一种简单快捷的方式模拟系统中的慢查询。即pgbench自带的tpc-c。
在主库上执行以下命令
ALTER TABLE pgbench_accounts DROP CONSTRAINT pgbench_accounts_pkey ;
该命令会移除 pgbench_accounts 表上的主键,导致相关查询变慢,系统瞬间雪崩过载。
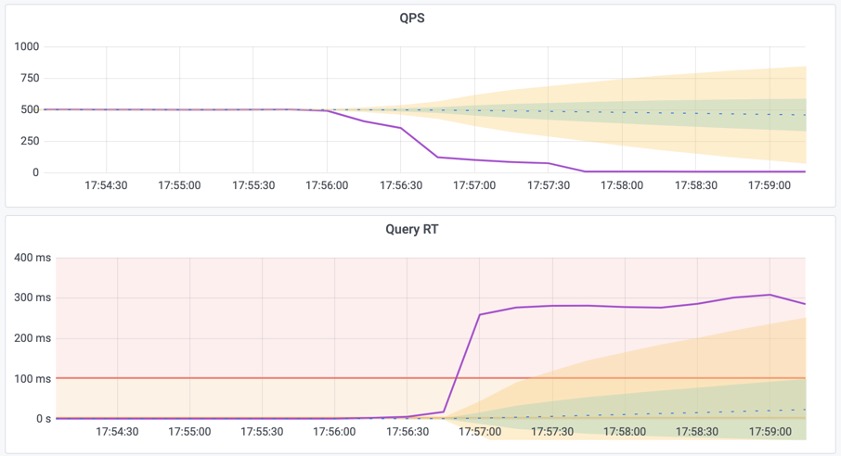
图1:单个从库实例的QPS从500下降至7,Query RT下降至300ms

图2:系统负载达到200%,触发机器负载过大,与查询响应时间过长的报警规则。
慢查询:定位
首先,使用PG Cluster面板定位慢查询所在的具体实例,这里以 pg-test-2为例
然后,使用PG Query面板定位具体的慢查询:编号为 -6041100154778468427
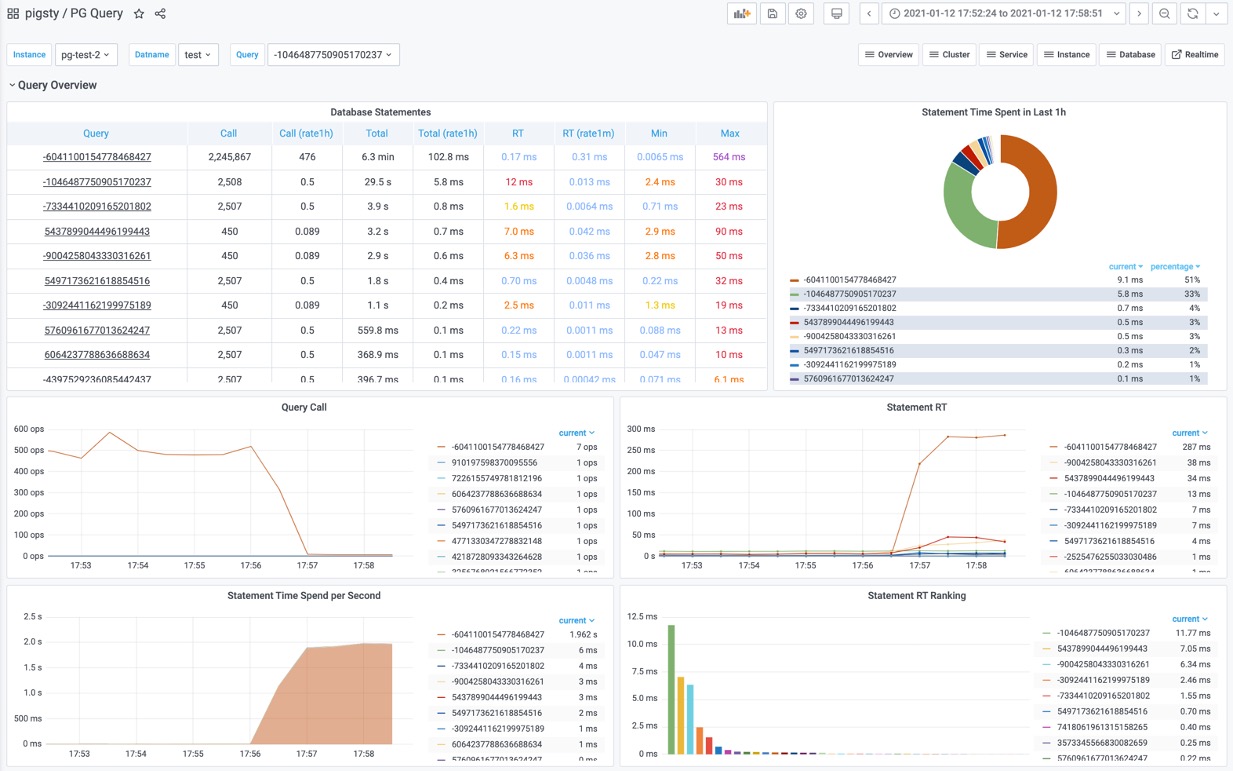
图3:从查询总览中发现异常慢查询
该查询表现出:
- 响应时间显著上升: 17us 升至 280ms
- QPS 显著下降: 从500下降到 7
- 花费在该查询上的时间占比显著增加
可以确定,就是这个查询变慢了!
接下来,利用PG Stat Statements面板或PG Query Detail,根据查询ID定位慢查询的具体语句。

图4:定位的查询是
SELECT abalance FROM pgbench_accounts WHERE aid = $1
慢查询:猜想
接下来,我们需要推断慢查询产生的原因。
SELECT abalance FROM pgbench_accounts WHERE aid = $1
该查询以 aid 作为过滤条件查询 pgbench_accounts 表,如此简单的查询变慢,大概率是这张表上的索引出了问题。
用屁股想都知道是索引少了,因为就是我们自己删掉的嘛!
分析查询后提出猜想: 该查询变慢是pgbench_accounts表上aid列缺少索引
下一步,查阅 PG Table Detail 面板,检查 pgbench_accounts 表上的访问,来验证我们的猜想

图5:
pgbench_accounts表上的访问情况
通过观察,我们发现表上的索引扫描归零,与此同时顺序扫描却有相应增长。这印证了我们的猜想!
慢查询:解决
确定了问题根源后,我们将着手解决。
尝试在 pgbench_accounts 表上为 aid 列添加索引,看看能否解决这个问题。
加上索引后,神奇的事情发生了。

图6:可以看到,查询的响应时间与QPS已经恢复正常。
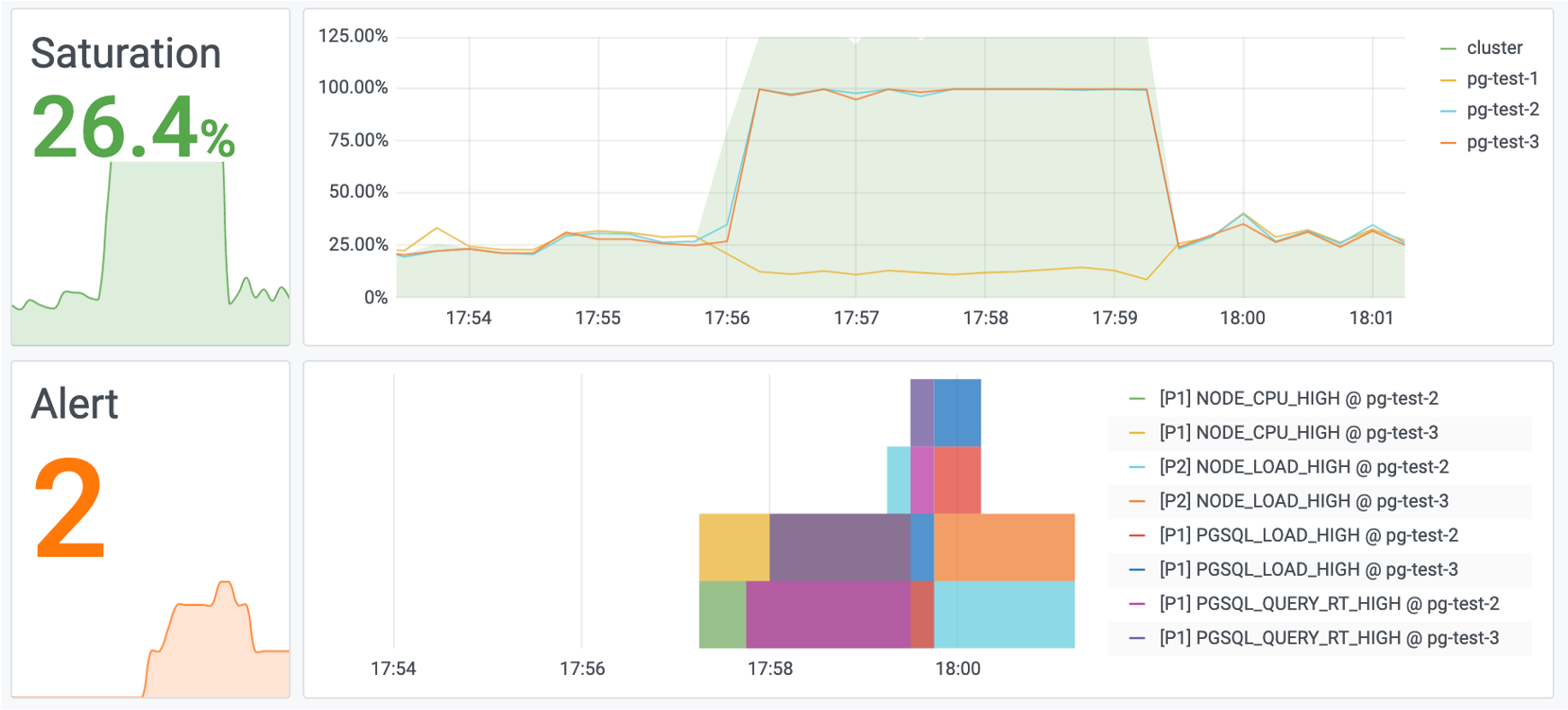
图7:系统的负载也恢复正常
慢查询:样例
通过这篇教程,您已经掌握了慢查询优化的一般方法论。
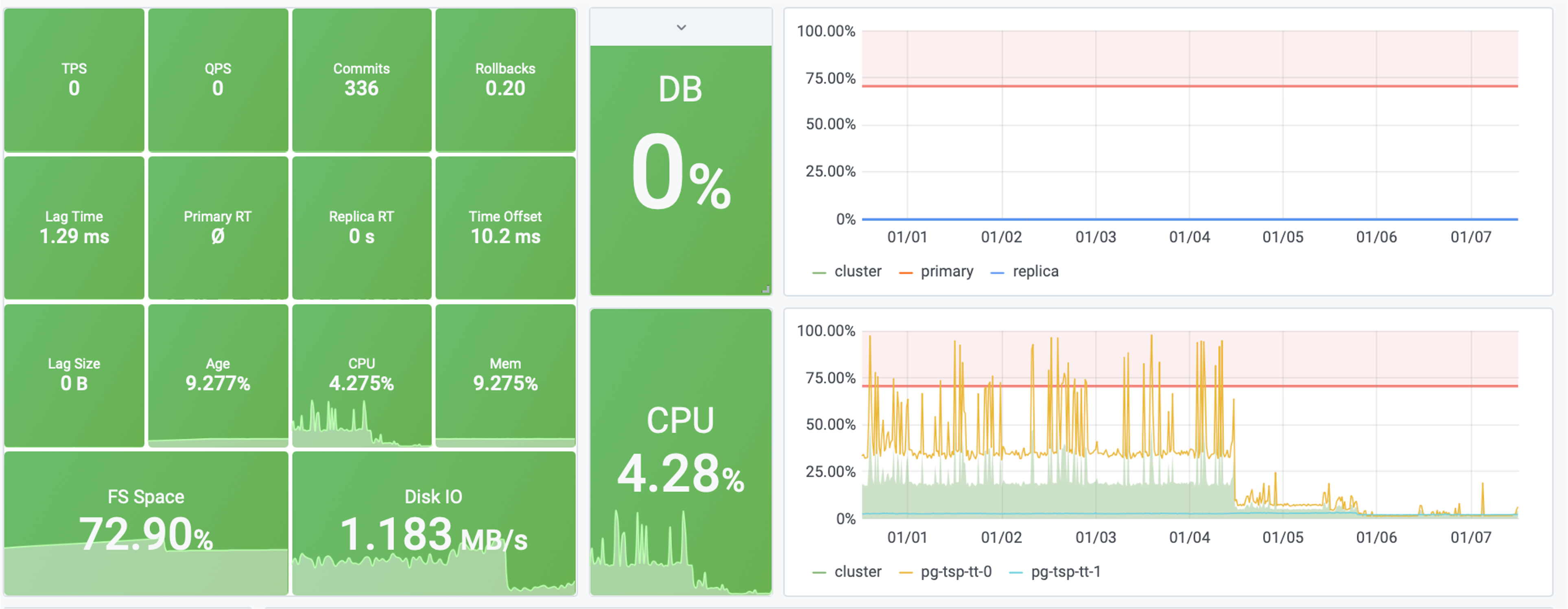
图8:一个慢查询优化的实际例子,将系统的饱和度从40%降到了4%
4 - App Example
Example application based on pigsty
If you have a database and don’t know what to do with it, check out another open source project by the author: Vonng/isd
You can directly reuse the monitoring system Grafana to interactively access sub-hourly weather data from nearly 30,000 surface weather stations over the past 120 years.
ISD – Intergrated Surface Data
All the tools you need to download, parse, process, and visualize NOAA ISD datasets are included here. It gives you access to sub-hourly weather data from nearly 30,000 surface weather stations over the last 120 years. And experience the power of PostgreSQL for data analysis and processing!
SYNOPSIS
Download, Parse, Visualize Intergrated Suface Dataset.
Including 30000 meteorology station, sub-hourly observation records, from 1900-2020.
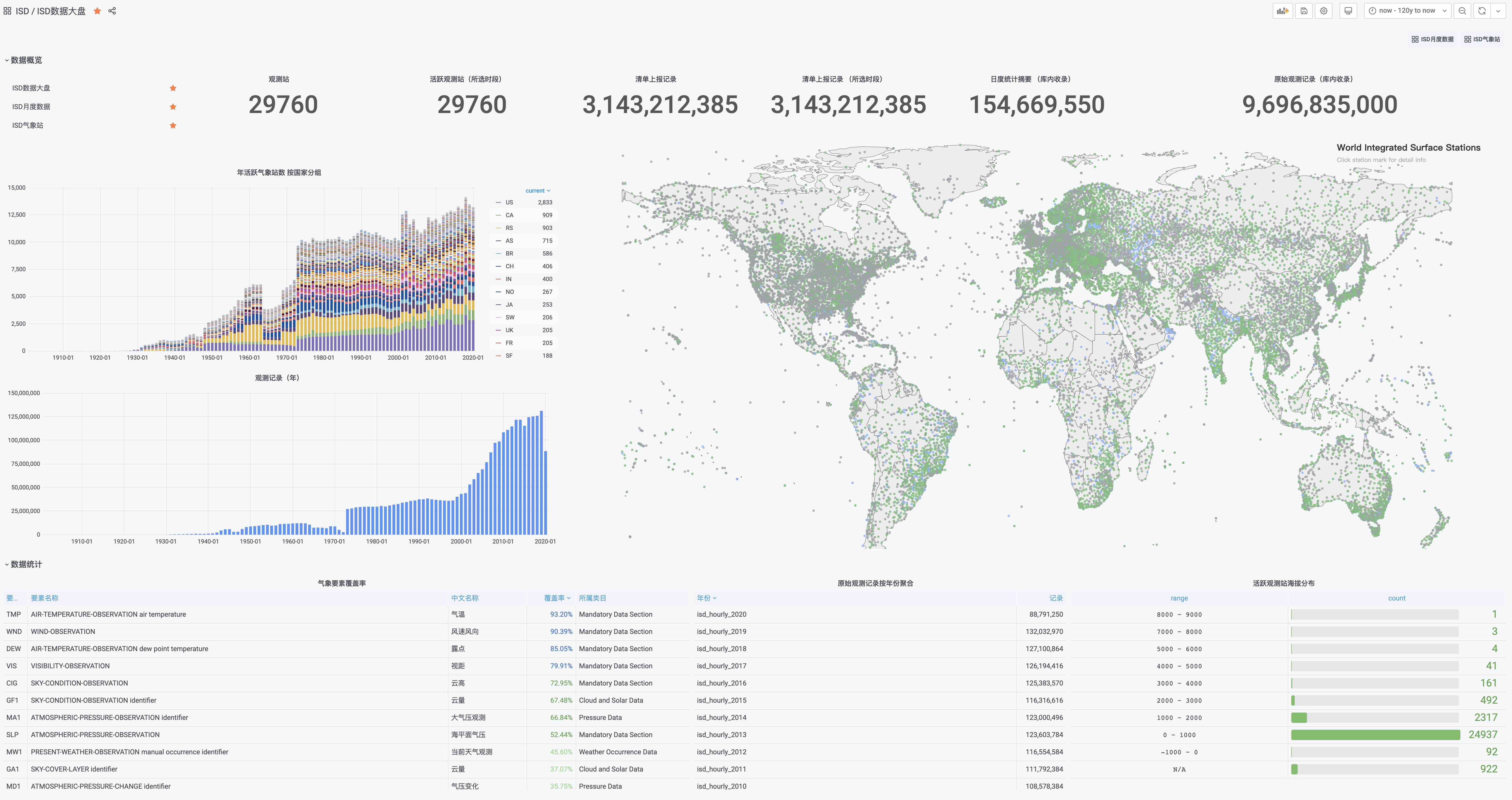
Quick Started
-
Clone repo
git clone https://github.com/Vonng/isd && cd isd -
Prepare a postgres database
Connect via something like
isdorpostgres://user:pass@host/dbname)# skip this if you already have a viable database PGURL=postgres psql ${PGURL} -c 'CREATE DATABASE isd;' # database connection string, something like `isd` or `postgres://user:pass@host/dbname` PGURL='isd' psql ${PGURL} -AXtwc 'CREATE EXTENSION postgis;' # create tables, partitions, functions psql ${PGURL} -AXtwf 'sql/schema.sql' -
Download data
- ISD Station: Station metadata, id, name, location, country, etc…
- ISD History: Station observation records: observation count per month
- ISD Hourly: Yearly archived station (sub-)hourly observation records
- ISD Daily: Yearly archvied station daily aggregated summary
git clone https://github.com/Vonng/isd && cd isd bin/get-isd-station.sh # download isd station from noaa (proxy makes it faster) bin/get-isd-history.sh # download isd history observation from noaa bin/get-isd-hourly.sh <year> # download isd hourly data (yearly tarball 1901-2020) bin/get-isd-daily.sh <year> # download isd daily data (yearly tarball 1929-2020) -
Build Parser
There are two ISD dataset parsers written in Golang :
isdhfor isd hourly dataset andisddfor isd daily dataset.make isdhandmake isddwill build it and copy to bin. These parsers are required for loading data into database.You can download pre-compiled binary to bin/ dir to skip this phase.
-
Load data
Metadata includes
world_fences,china_fences,isd_elements,isd_mwcode,isd_station,isd_history. These are gzipped csv file lies indata/meta/.world_fences,china_fences,isd_elements,isd_mwcodeare constant dict table. Butisd_stationandisd_historyare frequently updated. You’ll have to download it from noaa before loading it.# load metadata: fences, dicts, station, history,... bin/load-meta.sh # load a year's daily data to database bin/load-isd-daily <year> # load a year's hourly data to database bin/laod-isd-hourly <year>Note that the original
isd_dailydataset has some un-cleansed data, refer caveat for detail.
Data
Dataset
| 数据集 | 样本 | 文档 | 备注 |
|---|---|---|---|
| ISD Hourly | isd-hourly-sample.csv | isd-hourly-document.pdf | (Sub-) Hour oberservation records |
| ISD Daily | isd-daily-sample.csv | isd-daily-format.txt | Daily summary |
| ISD Monthly | N/A | isd-gsom-document.pdf | Not used, gen from daily |
| ISD Yearly | N/A | isd-gsoy-document.pdf | Not used, gen from monthly |
Hourly Data: Oringinal tarball size 105GB, Table size 1TB (+600GB Indexes).
Daily Data: Oringinal tarball size 3.2GB, table size 24 GB
It is recommended to have 2TB storage for a full installation, and at least 40GB for daily data only installation.
Schema
Data schema definition
Station
CREATE TABLE public.isd_station
(
station VARCHAR(12) PRIMARY KEY,
usaf VARCHAR(6) GENERATED ALWAYS AS (substring(station, 1, 6)) STORED,
wban VARCHAR(5) GENERATED ALWAYS AS (substring(station, 7, 5)) STORED,
name VARCHAR(32),
country VARCHAR(2),
province VARCHAR(2),
icao VARCHAR(4),
location GEOMETRY(POINT),
longitude NUMERIC GENERATED ALWAYS AS (Round(ST_X(location)::NUMERIC, 6)) STORED,
latitude NUMERIC GENERATED ALWAYS AS (Round(ST_Y(location)::NUMERIC, 6)) STORED,
elevation NUMERIC,
period daterange,
begin_date DATE GENERATED ALWAYS AS (lower(period)) STORED,
end_date DATE GENERATED ALWAYS AS (upper(period)) STORED
);
Hourly Data
CREATE TABLE public.isd_hourly
(
station VARCHAR(11) NOT NULL,
ts TIMESTAMP NOT NULL,
temp NUMERIC(3, 1),
dewp NUMERIC(3, 1),
slp NUMERIC(5, 1),
stp NUMERIC(5, 1),
vis NUMERIC(6),
wd_angle NUMERIC(3),
wd_speed NUMERIC(4, 1),
wd_gust NUMERIC(4, 1),
wd_code VARCHAR(1),
cld_height NUMERIC(5),
cld_code VARCHAR(2),
sndp NUMERIC(5, 1),
prcp NUMERIC(5, 1),
prcp_hour NUMERIC(2),
prcp_code VARCHAR(1),
mw_code VARCHAR(2),
aw_code VARCHAR(2),
pw_code VARCHAR(1),
pw_hour NUMERIC(2),
data JSONB
) PARTITION BY RANGE (ts);
Daily Data
CREATE TABLE public.isd_daily
(
station VARCHAR(12) NOT NULL,
ts DATE NOT NULL,
temp_mean NUMERIC(3, 1),
temp_min NUMERIC(3, 1),
temp_max NUMERIC(3, 1),
dewp_mean NUMERIC(3, 1),
slp_mean NUMERIC(5, 1),
stp_mean NUMERIC(5, 1),
vis_mean NUMERIC(6),
wdsp_mean NUMERIC(4, 1),
wdsp_max NUMERIC(4, 1),
gust NUMERIC(4, 1),
prcp_mean NUMERIC(5, 1),
prcp NUMERIC(5, 1),
sndp NuMERIC(5, 1),
is_foggy BOOLEAN,
is_rainy BOOLEAN,
is_snowy BOOLEAN,
is_hail BOOLEAN,
is_thunder BOOLEAN,
is_tornado BOOLEAN,
temp_count SMALLINT,
dewp_count SMALLINT,
slp_count SMALLINT,
stp_count SMALLINT,
wdsp_count SMALLINT,
visib_count SMALLINT,
temp_min_f BOOLEAN,
temp_max_f BOOLEAN,
prcp_flag CHAR,
PRIMARY KEY (ts, station)
) PARTITION BY RANGE (ts);
Update
ISD Daily and ISD hourly dataset will rolling update each day. Run following scripts to load latest data into database.
# download, clean, reload latest hourly dataset
bin/get-isd-daily.sh
bin/load-isd-daily.sh
# download, clean, reload latest daily dataset
bin/get-isd-daily.sh
bin/load-isd-daily.sh
# recalculate latest partition of monthly and yearly
bin/refresh-latest.sh
Parser
There are two parser: isdd and isdh, which takes noaa original yearly tarball as input, generate CSV as output (which could be directly consume by PostgreSQL Copy command).
NAME
isdh -- Intergrated Surface Dataset Hourly Parser
SYNOPSIS
isdh [-i <input|stdin>] [-o <output|st>] -p -d -c -v
DESCRIPTION
The isdh program takes isd hourly (yearly tarball file) as input.
And generate csv format as output
OPTIONS
-i <input> input file, stdin by default
-o <output> output file, stdout by default
-p <profpath> pprof file path (disable by default)
-v verbose progress report
-d de-duplicate rows (raw, ts-first, hour-first)
-c add comma separated extra columns
UI
ISD Station
ISD Monthly