高可用
Pigsty创建的数据库集群是分布式、高可用的数据库集群。
从效果上讲,只要集群中有任意实例存活,集群就可以对外提供完整的读写服务与只读服务。
数据库集群中的每个数据库实例在使用上都是幂等的,任意实例都可以通过内建负载均衡组件提供完整的读写服务。
数据库集群可以自动进行故障检测与主从切换,普通故障能在几秒到几十秒内自愈,且期间只读流量不受影响。
高可用
两个核心场景:Switchover,Failover
四个核心问题:故障检测,Fencing,选主,流量切换
关于高可用的核心场景演练,请参考 高可用演练 一节。
基于Patroni的高可用方案
基于 Patroni 的高可用方案部署简单,不需要使用特殊硬件,具有大量实际生产使用案例背书。
Pigsty的高可用方案基于Patroni,vip-manager,haproxy
Patroni基于DCS(etcd/consul/zookeeper)达成选主共识。
Patroni的故障检测采用心跳包保活,DCS租约机制实现。主库持有租约,秦失其鹿,则天下共逐之。
Patroni的Fencing基于Linux内核模块watchdog。
Patroni提供了主从健康检查,便于与外部负载均衡器相集成。
基于Haproxy与VIP的接入层方案
Pigsty沙箱默认使用基于L2 VIP与Haproxy的接入层方案。Pigsty提供多种可选的 数据库接入 方式。
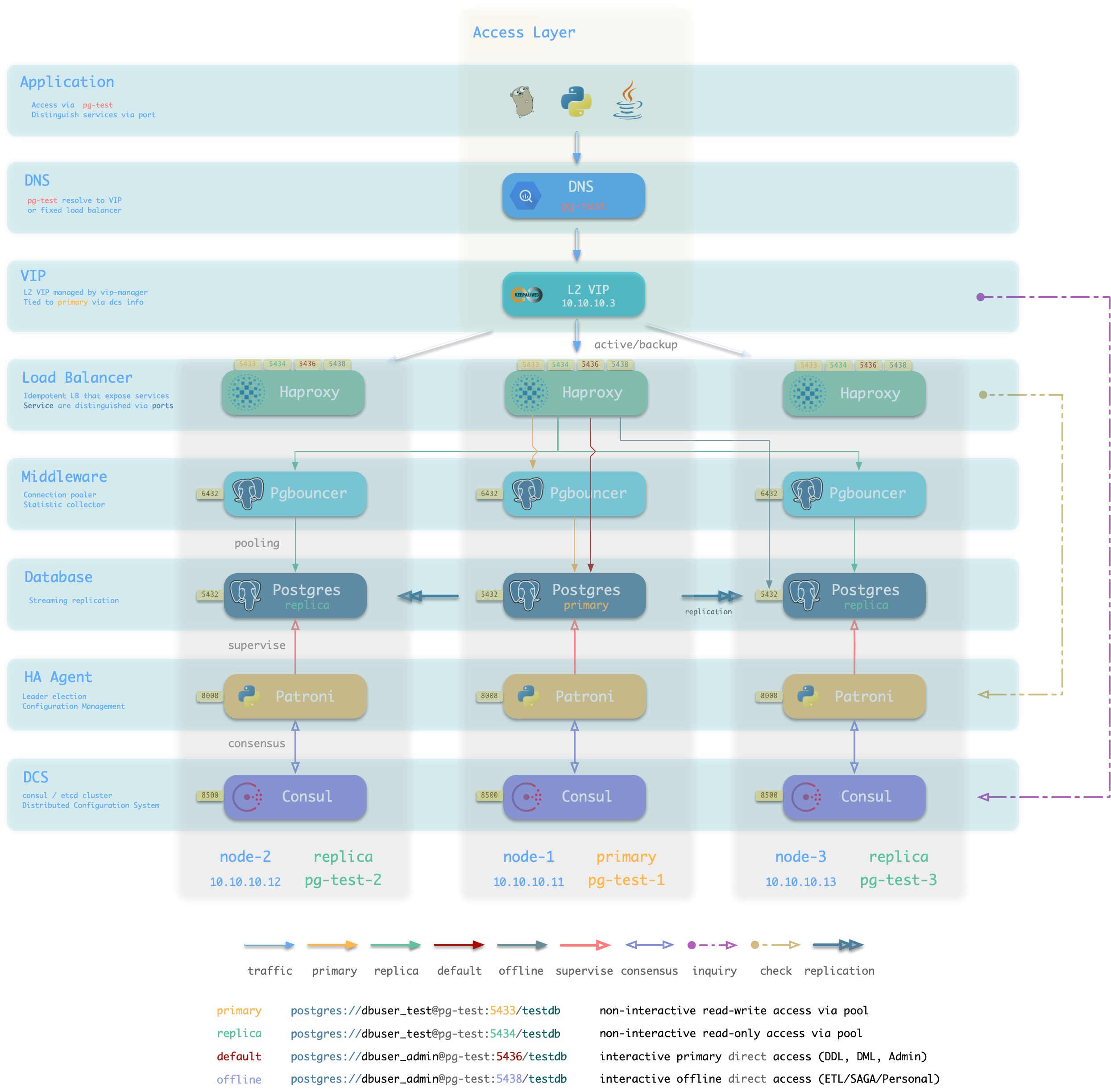
Haproxy幂等地部署在集群的每个实例上,任何一个或多个Haproxy实例都可以作为集群的负载均衡器。
Haproxy采用类似Node Port的方式对外暴露服务,默认情况下,5433端口提供集群的读写服务,而5434端口提供集群的只读服务。
Haproxy本身的高可用性可通过以下几种方式达成:
- 使用智能客户端,利用Consul提供的DNS或服务发现机制连接至数据库。
- 使用智能客户端,利用Multi-Host特性填入集群中的所有实例。
- 使用绑定在Haproxy前的VIP(2层或4层)
- 使用外部负载均衡器保证
- 使用DNS轮询解析至多个Haproxy,客户端会在建连失败后重新执行DNS解析并重试。
Patroni在故障时的行为表现
| 场景 | 位置 | Patroni的动作 |
|---|---|---|
| PG Down | replica | 尝试重新拉起PG |
| Patroni Down | replica | PG随之关闭(维护模式下不变) |
| Patroni Crash | replica | PG不会随Patroni一并关闭 |
| DCS Network Partition | replica | 无事 |
| Promote | replica | 将PG降为从库并重新挂至主库。 |
| PG Down | primary | 尝试重启PG 超过 master_start_timeout后执行Failover |
| Patroni Down | primary | 关闭PG并触发Failover |
| Patroni Crash | primary | 触发Failover,可能触发脑裂。 可通过watchdog fencing避免。 |
| DCS Network Partition | primary | 主库降级为从库,触发Failover |
| DCS Down | DCS | 主库降级为从库,集群中没有主库,不可写入。 |
| 同步模式下无可用备选 | 临时切换为异步复制。 恢复为同步复制前不会Failover |
合理配置Patroni可以应对绝大多数故障。不过DCS Down这种场景(Consul/Etcd宕机或网络不可达)会导致所有生产数据库集群不可写入,需要特别关注。必须确保DCS的可用性高于数据库的可用性。
Known Issue
请尽量确保服务器的时间同步服务先于Patroni启动。