HA
The database cluster created by Pigsty is a distributed, highly available database cluster.
Effectively, as long as any instance in the cluster survives, the cluster can provide complete read and write services and read-only services to the outside world.
Each database instance in the database cluster is idempotent in use, and any instance can provide complete read and write services through the built-in load balancing components.
Database clusters can automatically perform fault detection and master-slave switching, and common failures can self-heal within seconds to tens of seconds, and read-only traffic is not affected during this period.
High Availability
Two core scenarios: Switchover, Failover
Four core issues: Fault detection, Fencing, master selection, traffic switching
For a walkthrough of the core scenarios of high availability, please refer to [High Availability Walkthrough](… /… /… /tasks/ha-drill/) section.
Patroni-based high availability scenarios
The Patroni based high availability solution is simple to deploy, does not require the use of special hardware, and has a large number of real production use cases to back it up.
Pigsty’s high availability solution is based on Patroni, vip-manager, haproxy
Patroni is based on DCS (etcd/consul/zookeeper) to reach a master selection consensus.
Patroni’s failure detection uses heartbeat packet to keep alive, DCS lease mechanism to achieve. The main repository holds the lease, and if Qin loses its deer, the world will fight it.
Patroni’s Fencing is based on the Linux kernel module watchdog.
Patroni provides master-slave health checks for easy integration with external load balancers.
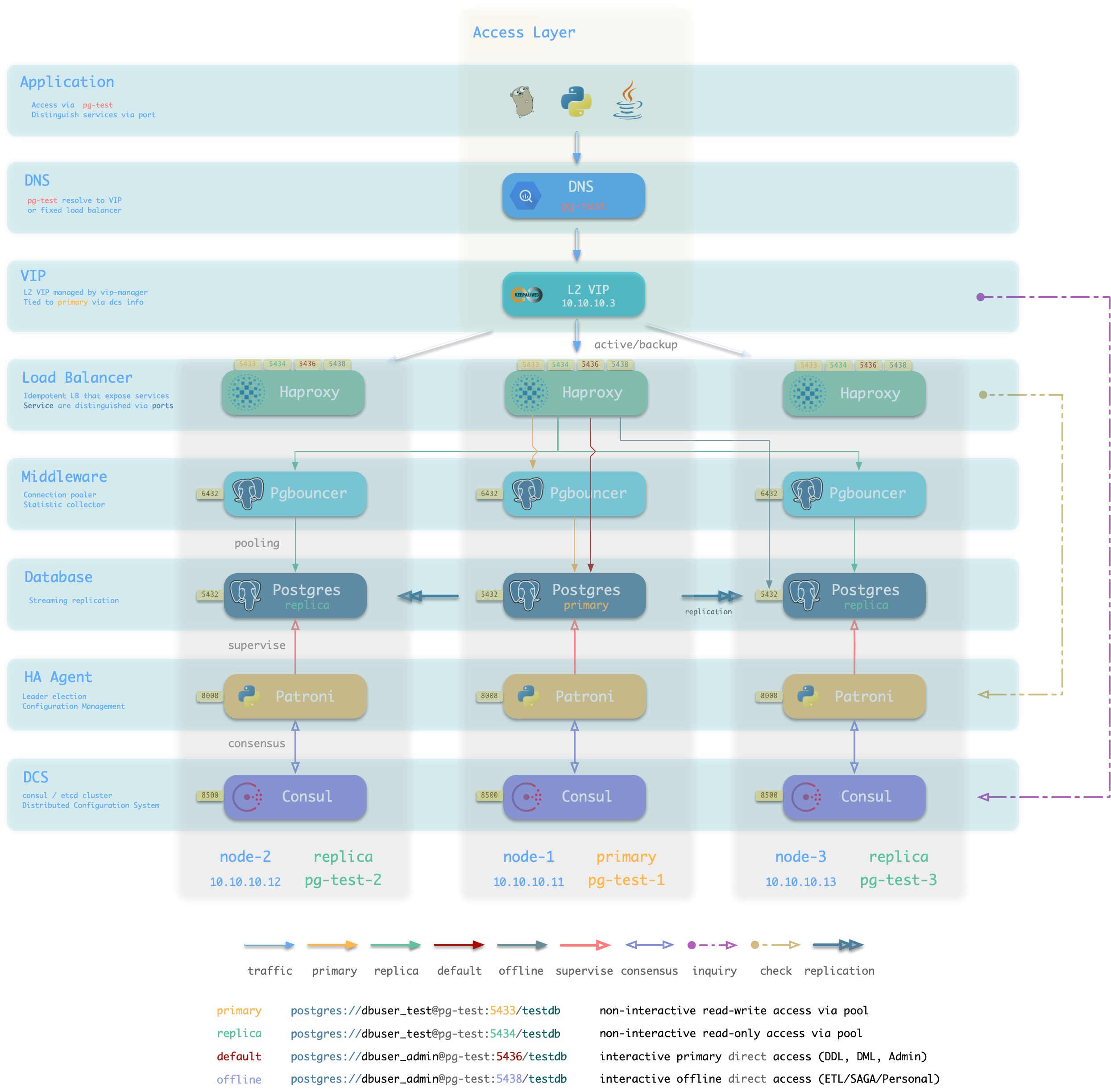
Haproxy and VIP based access layer solutions
Pigsty sandboxes use by default L2 VIP and Haproxy based access layer solutions, Pigsty provides several optional [database access](… /… /… /concept/provision/access/) methods.
{kind=link}
Haproxy idempotently is deployed on each instance of the cluster, and any one or more Haproxy instances can act as a load balancer for the cluster.
Haproxy uses a Node Port-like approach to expose its services to the public. By default, port 5433 provides read and write services to the cluster, while port 5434 provides read-only services to the cluster.
High availability of Haproxy itself can be achieved in several ways.
- Using a smart client that connects to the database using the DNS or service discovery mechanism provided by Consul.
- Using a smart client that uses the Multi-Host feature to populate all instances in the cluster.
- Use VIPs bound in front of Haproxy (Layer 2 or 4)
- Use external load balancers to guarantee
- Use DNS polling to resolve to multiple Haproxy, clients will re-execute DNS resolution and retry after a disconnect.
Patroni’s behavior in case of failure
| 场景 | 位置 | Patroni的动作 |
|---|---|---|
| PG Down | replica | 尝试重新拉起PG |
| Patroni Down | replica | PG随之关闭(维护模式下不变) |
| Patroni Crash | replica | PG不会随Patroni一并关闭 |
| DCS Network Partition | replica | 无事 |
| Promote | replica | 将PG降为从库并重新挂至主库。 |
| PG Down | primary | 尝试重启PG 超过 master_start_timeout后执行Failover |
| Patroni Down | primary | 关闭PG并触发Failover |
| Patroni Crash | primary | 触发Failover,可能触发脑裂。 可通过watchdog fencing避免。 |
| DCS Network Partition | primary | 主库降级为从库,触发Failover |
| DCS Down | DCS | 主库降级为从库,集群中没有主库,不可写入。 |
| 同步模式下无可用备选 | 临时切换为异步复制。 恢复为同步复制前不会Failover |
The proper configuration of Patroni can handle most failures. However, a scenario like DCS Down (Consul/Etcd down or network unreachable) will render all production database clusters unwritable and requires special attention. **Must ensure that DCS availability is higher than database availability. **
Known Issue
Please try to ensure that the server’s time synchronization service starts before Patroni.