系统模型
-
服务端
-
客户端
-
供给方案
- 基础设施
- 数据库集群
基础设施(Infra) 与 数据库集群(PgSQL)。每一套 Pigsty 部署(Deployment),都包含有一套基础设施,与多套数据库集群。
Pigsty需要部署在机器节点上,节点分为两类:元节点(Meta Node) 用于部署基础设施,普通节点 用于部署数据库集群。元节点也可以复用为普通节点,用于数据库部署。
下图以Pigsty自带沙箱环境为例,介绍Pigsty的系统模型。
基础设施
Pigsty包含有生产环境数据库管理与使用所需的完整基础设施组件,包括:
- Nginx:Pigsty Web界面入口,服务代理,本地Yum源服务器
- Consul:高可用依赖的DCS服务,服务发现,DNS
- Grafana:监控系统,可视化仪表盘
- Prometheus:监控组件,时序指标收集与存储
- Altermanager:报警组件
- NTP Server:时间服务器
- DNS Server:域名解析服务器
- CA:公私钥基础设施。
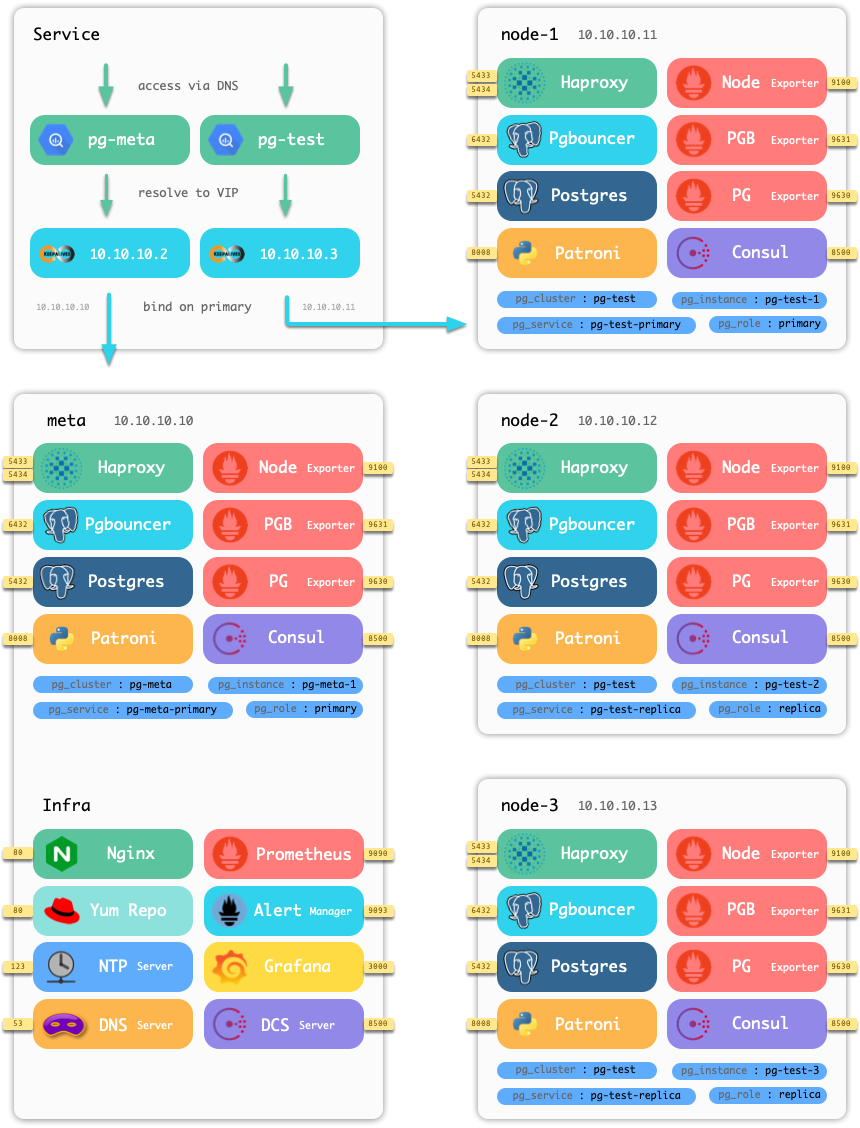
除DCS外,基础设施默认以幂等的方式部署在一个或多个元节点上。
元节点(Meta Node) 是Pigsty中的特殊机器,用于发起管理,执行控制,部署监控。
数据库集群
Pigsty是数据库供给方案,可以按需创建高可用数据库集群。
每个“数据库实例”在使用上是幂等的,采用类似NodePort的方式对外暴露服务。默认情况下,访问任意实例的5433端口即可访问主库,访问任意实例的5434端口即可访问从库。用户也可以灵活地同时使用不同的方式访问数据库。
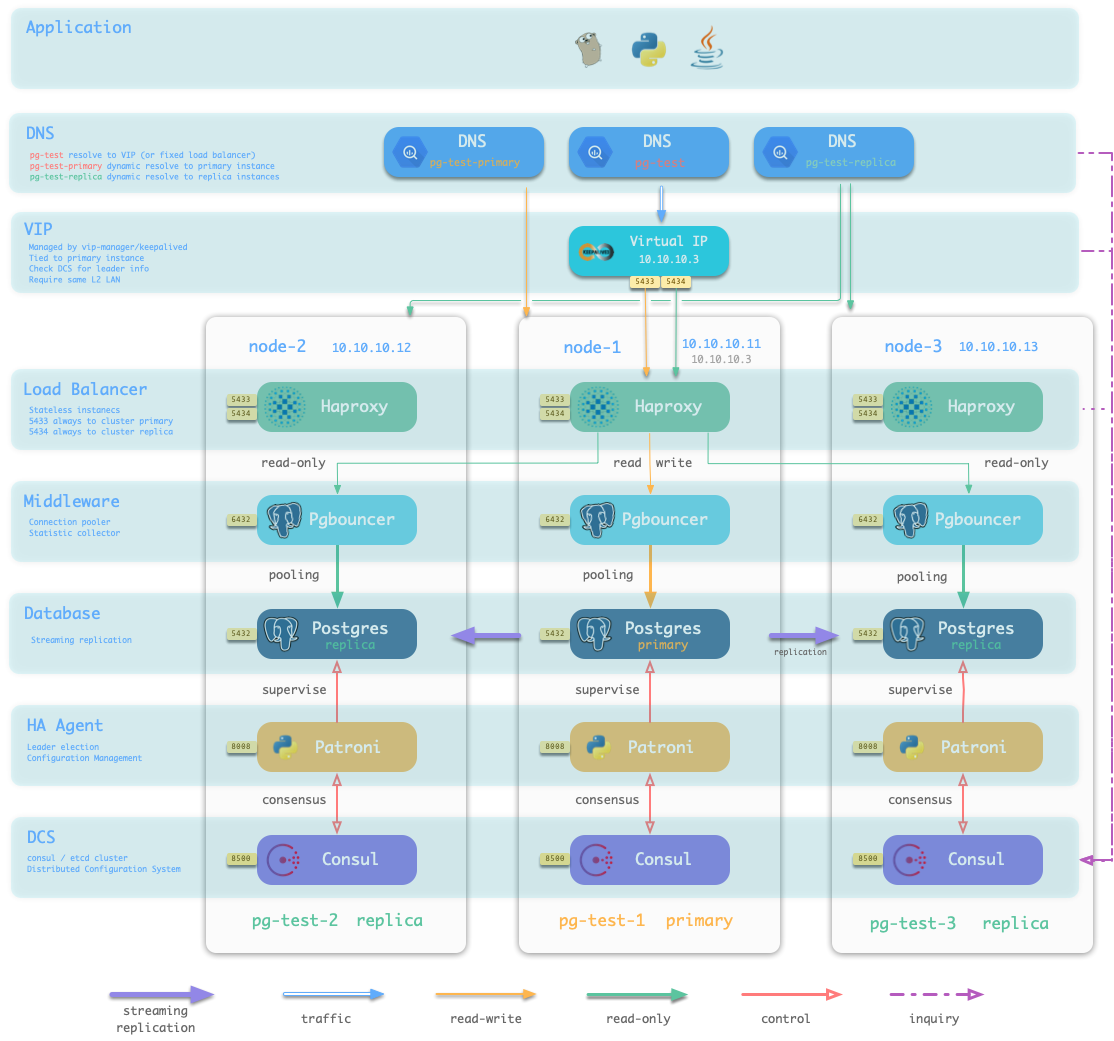
每个数据库集群是一个自组织的业务服务单元,由至少一个数据库实例组成。
Pigsty创建的数据库集群是分布式、高可用的数据库集群。只要集群中有任意实例存活,集群就可以对外提供完整的读写服务与只读服务。
Pigsty可以自动进行故障切换,业务方只读流量不受影响;读写流量的影响视具体配置与负载,通常在几秒到几十秒的范围。
Pigsty通过声明式的配置定义数据库集群,通过幂等的Ansible Playbook根据配置创建数据库集群。
命名规则
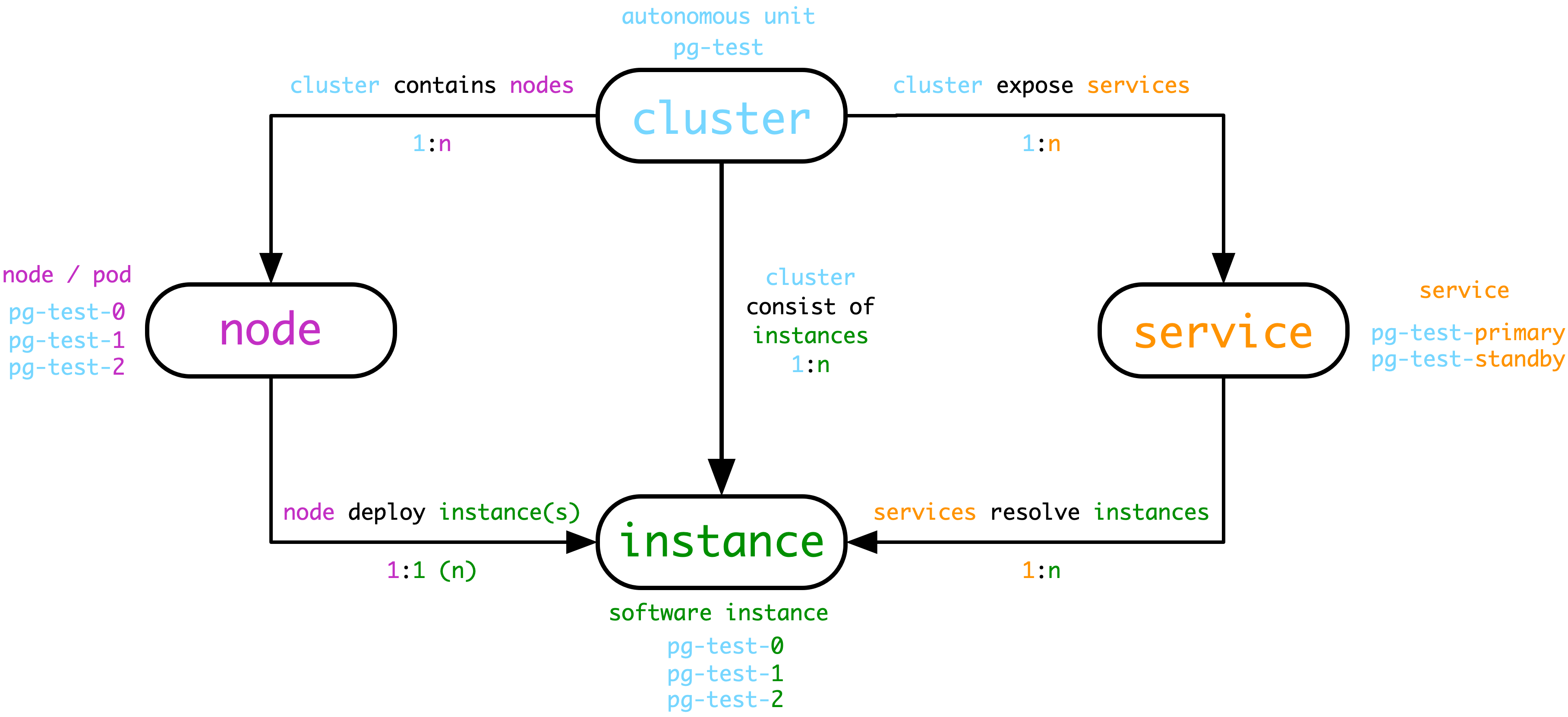
生产环境的数据库往往是以集群为单位组织的。集群是一个由主从复制所关联的一组数据库实例所构成的,它是基本的业务服务单元。集群由多个实例组成,而多套数据库集群共同组成一个现实世界中的生产环境。
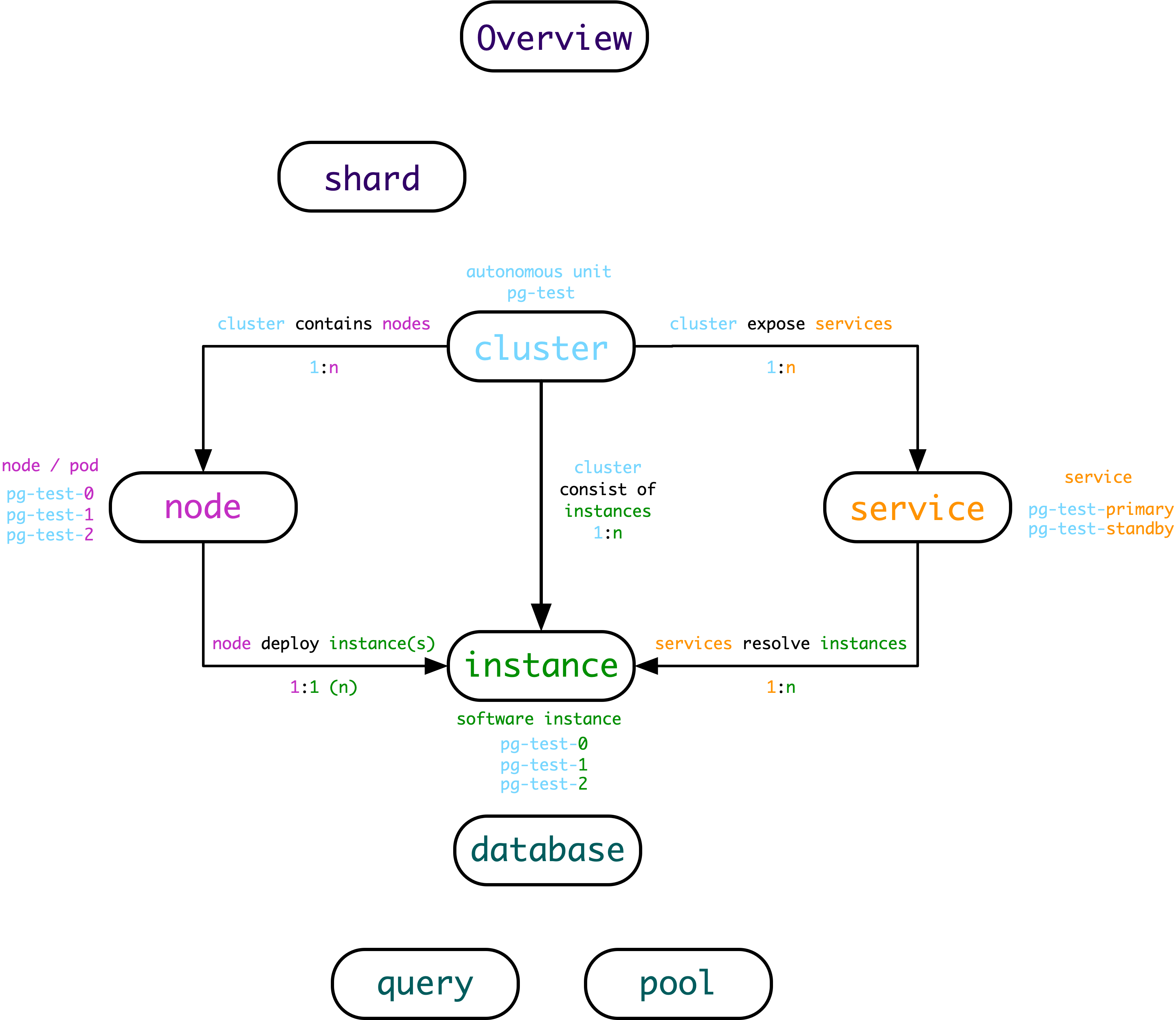
除了实例与集群这两个最为Trivial层次,整个系统中还有着其他层次的组织。自顶向下可以分为7个层级:概览,分片,集群,服务,实例,数据库,对象。
夹在集群与实例中间的层次—— Service。
在实例层级以下,还可以再分出两个层次来,分别是Database和Object。Object即亚数据库对象,包括:表、索引,函数,序列号,查询、连接池等。
从集群层次向上看,则会有两个更高的层次——Shard与Overview。
作为一种精简,正如网络的OSI 7层模型在实际中被简化为TCP/IP五层模型一样,这七个层次也以集群 和 实例为界,简化为五个层次:Overview,Cluster,Service,Instance,Database 。
这样,最终的层次划分也变得十分简洁:所有集群层次以上的信息,都是Overview层次,所有实例内部的信息都算Database层次,夹在两者中间的,就是Service层次。

命名问题
分完层次后,剩下的问题实际上就是命名问题,或者说身份管理的问题。
-
我们需要一种方式来标识、引用系统中不同层次内的各个组件,
-
这种命名方式,应当合理地反映出系统中各个实体的层次关系
-
这种命名方式,应当可以按照规则自动生成,只有这样,才可以在集群扩容缩容,Failover时做到免维护自动化运行,
当我们理清了系统中存在的层次后,就可以着手为系统中的每个实体起名。请参考下一节:命名规则