PostGIS高效解决行政区划归属查询
在应用开发中,很多时候我们需要解决这样一个问题:根据用户的经纬度坐标,定位用户的行政区划。
我们收集到的是诸如28°00'00"N 100°00'00.000"E这样的经纬度坐标,但实际感兴趣的是这个点所属的行政区划:(中华人民共和国,云南省,迪庆藏族自治州,香格里拉市)。这种将地理坐标映射到某条记录的操作就称为地理编码(GeoEncode)。高效实现地理编码是一个很有趣的问题。
本文介绍了该问题的解决与优化方案:能在确保正确性的前提下,能用几兆的空间,110μs的执行时间完成一次地理编码。
0x01 正确至上
正确性是第一位的。我们不希望出现用户明明身处A地,却被划分到B地的尴尬情况。然而一个尴尬的现实是,很多地理编码服务的实现粗糙到令人无法直视,Vornoi方法就是一个典型的例子。
假设我们有一系列的坐标点,那么这些坐标点之间两两连线的中垂线就对整个坐标平面做了一个Vornoi划分。每一个细胞的中心点就是细胞核,而元胞内的任意一点到该细胞核的距离是最近的(与其他细胞核相比)。
当我们没有行政区划的边界数据,但有行政区划中心点的数据时,这也是一种能凑合管用办法。找到距离用户最近的某级行政区域中心,然后认为用户就位于该行政区域中心。这个功能实现起来非常简单。
不过,这种方法对于边界情况的处理很差:
最近邻搜索—Vornoi方法
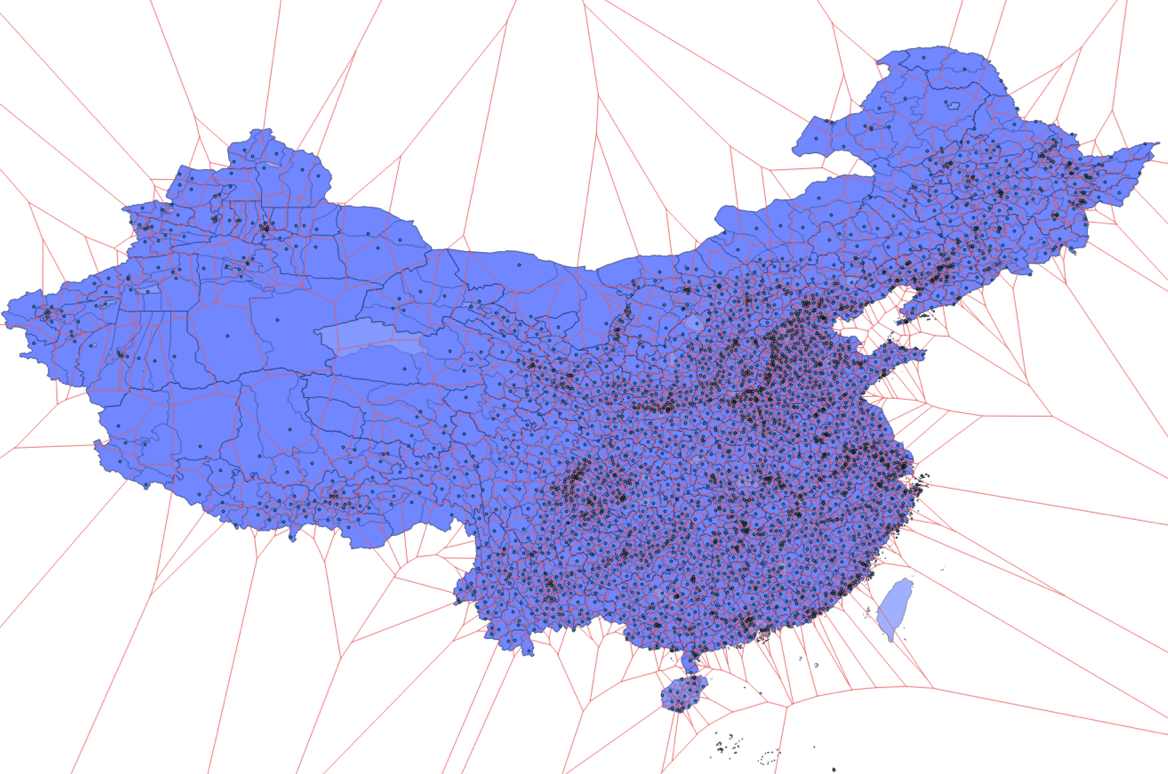
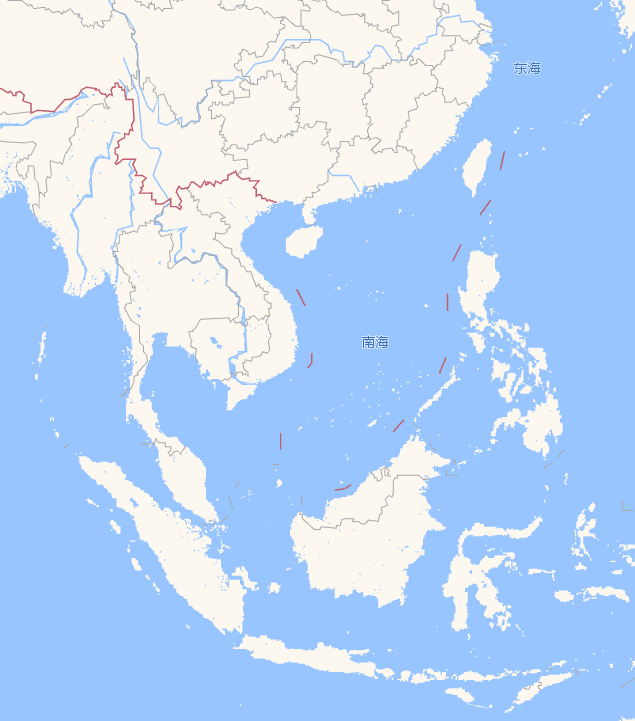
现实总是与理想情况相距甚远。也许对于国内而言,这种错误影响也许并不大。但涉及到国际主权边界时,这种粗糙的实现很可能会给自己带来不必要的麻烦:
还有一种思路,和编程中的“查表法”类似,预先计算好所有经纬度到行政区划的映射,使用时只要用经纬度坐标查表就好了。当然无论经度还是维度,都是一个连续的标量,理论上精度必然是有限的。
GeoHash就是这样一种方案:它将经度与维度交叉编码为单一字符串,字符串越长精度越高,每一个字符串都对应一个经纬度围成的“矩形”,只要精度足够,理论上是可以这么做的。当然,这种方案难以做到真正意义上的正确,存储开销也极为浪费。好处是实现很简单。只要有数据,一个KV服务就可以轻松搞定。
相比之下,基于地理边界多边形的解决方案在保证绝对正确的前提下,能在一毫秒内完成这种地理编码功能,而且可能只需要几兆的空间。唯一的难点可能在于如何获取数据上。
0x02 数据为王
地理编码属于典型的数据密集型应用,数据的质量直接决定了最终服务的效果。要想真正做好服务,优质数据必不可少。好在行政区划与地理边界数据也不算什么保密信息,有一些地方提供了公开获取的方式:
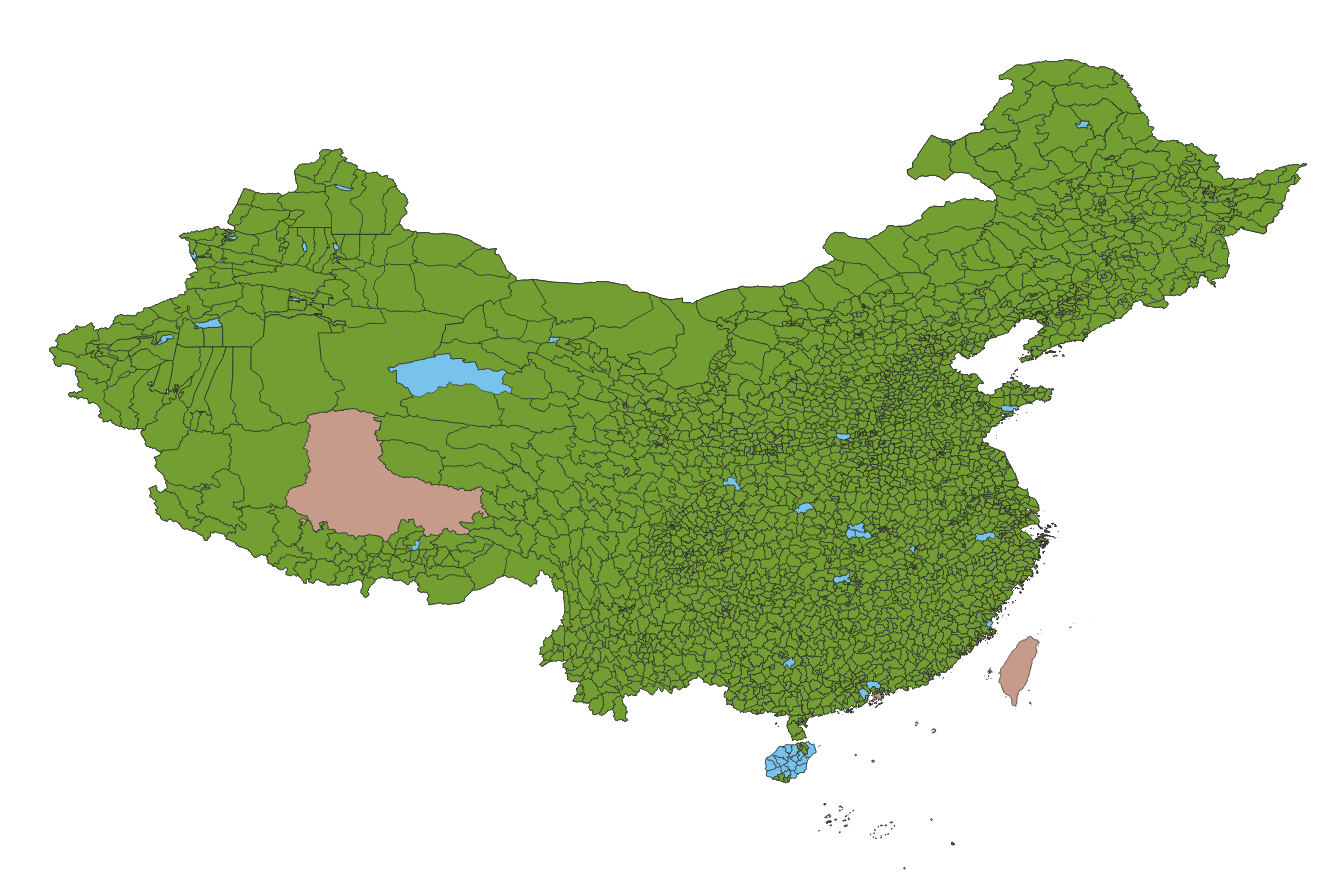
民政部信息查询平台与高德地图两者都提供了精确到县级区划的地理边界数据:
-
高德的数据更新更及时,形式简单,边界精度较高(点数多),但不够权威,有不少错漏之处。
-
民政部平台数据相对更加权威,而且采用的是拓扑编码,严格避免了边界重叠的问题,使用无偏的WGS84坐标,但边界精度较低(点数目较少)。
除了地理围栏数据之外,另一份重要的数据是行政区划代码数据。国家统计局使用的12位城乡统计用行政区划代码编制还是很科学的,具有层次包含关系,尤其适合作为行政区划的唯一标示。但问题是稍显过时,最新的版本是2016年8月发布的,2018年7月后可能会发布一份更新的数据。
笔者整理了一份连接国际统计局行政区划与高德区划边界的数据:https://github.com/Vonng/adcode
民政部的数据可以直接在该网站中打开浏览器的调试工具,从接口返回数据中直接获取。
0x03 牛刀小试
假设我们已经有一张表了,全国行政区划与地理围栏表:adcode_fences
create table adcode_fences
(
code bigint,
parent bigint,
name varchar(64),
level varchar(16),
rank integer,
adcode integer,
post_code varchar(8),
area_code varchar(4),
ur_code varchar(4),
municipality boolean,
virtual boolean,
dummy boolean,
longitude double precision,
latitude double precision,
center geometry,
province varchar(64),
city varchar(64),
county varchar(64),
town varchar(64),
village varchar(64),
fence geometry
);

索引
为了高效执行空间查询,首先需要在表示地理边界的fence列上创建GIST索引。
中国县级行政区划的记录数据并不多(约3000条),但使用索引仍然能带来几十倍的性能提升。因为这个优化太基础太Trivial了,就不单独拎出来说了。(一百多毫秒到几毫秒)
CREATE INDEX ON adcode_fences USING GIST(fence);
查询
PostGIS提供了ST_Contains与ST_Within两个函数,用于判断多边形与点之间的包含关系,例如以下SQL就会找出表中所有包含该点(116,40)的行政区划:
SELECT
code,
name
FROM adcode_fences
WHERE ST_Contains(fence, ST_Point(116, 40))
ORDER BY rank;
结果是:
100000000000 中华人民共和国
110000000000 北京市
110100000000 市辖区
110109000000 门头沟区
再比如(100,28)的坐标点:
SELECT json_object_agg(level,name)
FROM adcode_fences WHERE ST_Contains(fence, ST_Point(100, 28));
{
"country": "中华人民共和国",
"city": "迪庆藏族自治州",
"county": "香格里拉市",
"province": "云南省"
}
相当不可思议,数据就位之后,借力于PostgreSQL与PostGIS,实现这一功能所需的代码少的惊人:一行SQL。
在笔者的笔记本上,该查询执行用时6毫秒。6ms的平均查询时间,换算为48核机器上的QPS差不多就是6400。在我们以前的生产环境代码中基本上就是这么做的,但因为还有其他国家的数据,以及单核主频没有我的机器高,因此一次查询的平均执行时间可能在12毫秒左右。
看上去几毫秒似乎已经很快了,但还是没有达到我们生产环境的性能要求(1毫秒)。对于真实世界的生产业务而言,性能很重要,十倍的性能提升意味着省十倍的机器。还能不能再给力点?实际上通过简单的优化就可以达到百倍的性能提升。
0x04 性能优化
针对数据特性优化
导致上述查询慢的一个重要原因是不必要的相交判断。行政区划是有层级关系的,如果一个用户位于县级行政区划中,那么他一定位于该县级区划所处的省级区划中。因此,知道了最低级的行政区划,其高级区划归属已经自然而然地确定了;那么与省界,国界做相交判断就是没有必要的。 实际上这可能是效果最明显的优化,单是中国地理边界与点做相交判断可能就需要几毫秒。
区域切分
R树索引的原理,能为我们带来优化的启发。R树是基于**AABB(Axis Aligned Bounding Box)**的索引。因此越是饱满的凸多边形,索引的效果就越好。而对于拥有遥远飞地的行政区划,效果则可能恶化的很厉害。因此,将区域切分为均匀饱满的小块,能有效提高查询的性能。
最基本的优化,就是将所有的ST_MultiPolygon拆分为ST_Polygon,并指向同一个行政区划。更进一步,可以将长得比较畸形的行政区划切分为形状饱满的小块(典型的比如甘肃这种)。当然,这样的代价就是让所有行政区划与地理围栏从一对一变成了一对多的关系。需要拆出一张单独的表。
实际操作中,如果已经有了县级行政区划的数据,通常只要将带有飞地的MultiPolygon拆为单独的几个Polygon,就已经能有很好的表现了。而县一级的行政区划通常边界也比较饱满,进一步拆分效果相当有限。
精确度
正确性是第一位的,然而有的时候我们宁愿牺牲一些准确性,换来性能的大幅提升。例如高德与民政部的数据对比,显然民政部要粗糙的多,但对于糙猛快的互联网场景,低精度的数据反而可能是更合适的。
| 高德 | 民政部 |
|---|---|
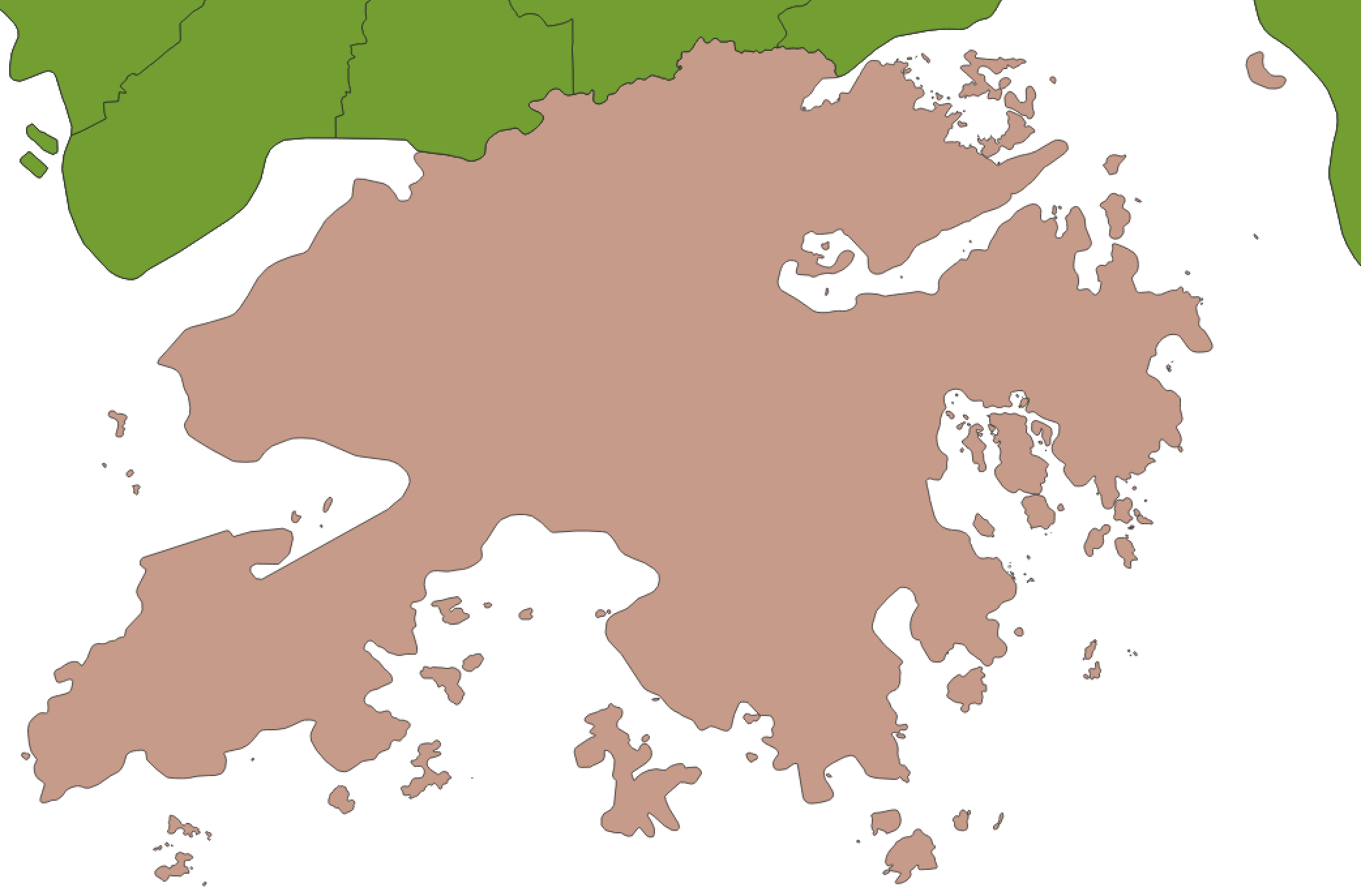 |
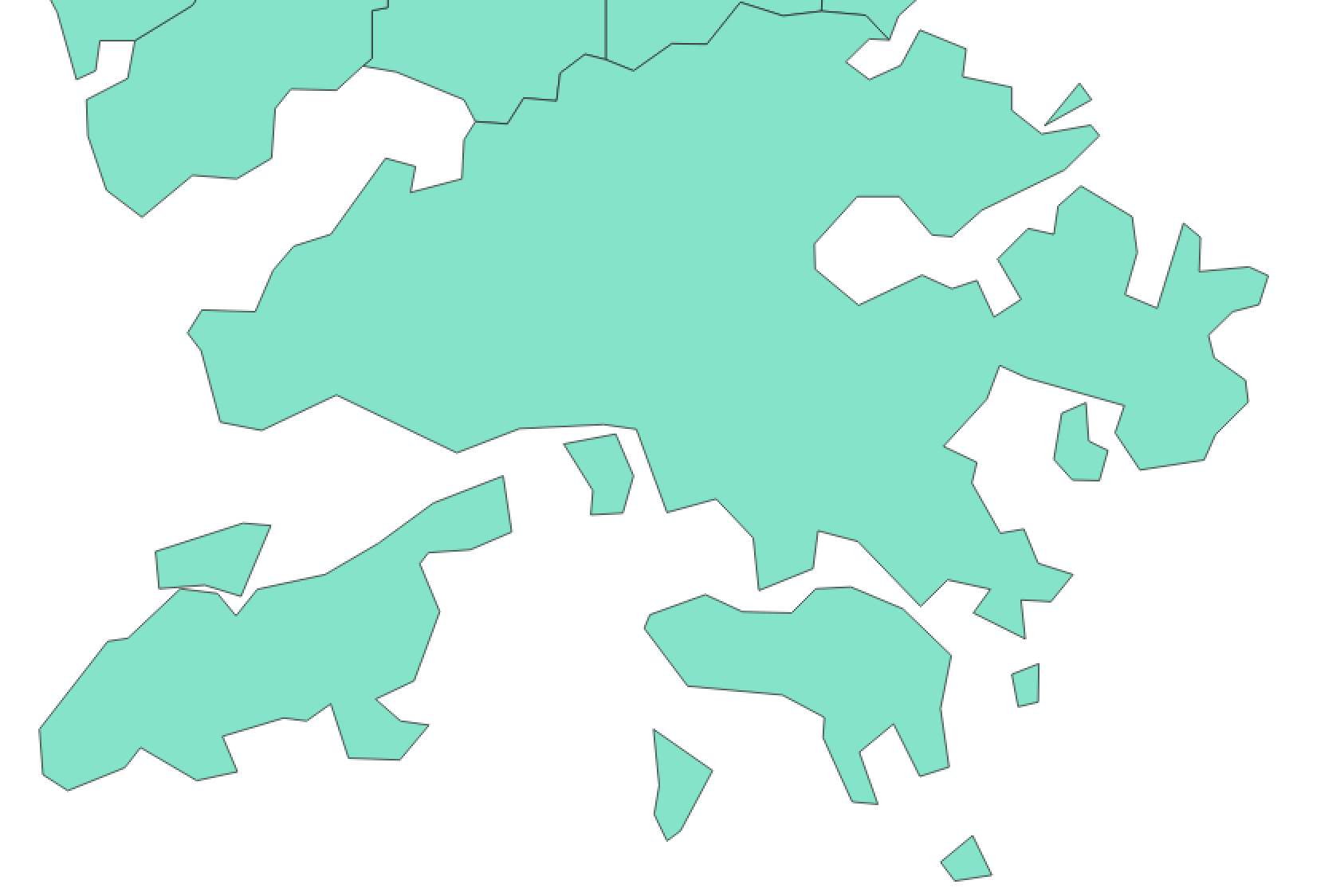 |
高德的全国行政区划数据约100M左右,而民政部的数据约为10M(以原始拓扑数据表示则为4M)。但实际使用中效果差别不大,因此推荐使用民政部的数据。
主键设计
行政区划有内在的层次关系,国家包含省,省包含城市,城市包含区县,区县包含乡镇,乡镇包含村庄街道。我国的行政区划代码就很好的体现了这种层次关系,十二位的城乡区划代码包含了很丰富的信息:
- 第1~2位,为省级代码;
- 第3~4 位,为地级代码;
- 第5~6位,为县级代码;
- 第7~9位,为乡级代码;
- 第10~12位,为村级代码。
因此这种12位的行政区划代码是很适合作为行政区划表的主键的。此外,当需要国际化支持时,这套区划代码体系还可以通过在前面添加国家代码来扩展(相应地中国行政区划对应地就是高位国家代码为0的特殊情况)。
另一方面,地理围栏表与行政区划表由一对一变为多对一,那么地理围栏表就不再适合用行政区划代码作为主键了。可能自增列是一个更合适的选择。
规范化与反规范化
数据模型设计的一个重要权衡就是规范化与反规范化。将地理围栏表从行政区划表中拆出来是一种规范化,而反规范化也可以用于优化:既然行政区划存在层次关系,那么在子行政区划中保留所有的祖先行政区划信息(或仅仅是代码与名称)是很合理的反规范化操作。这样,通过区划代码主键一次查询就可以取出所有的层次信息。
回溯支持
有时候我们想回溯到历史上某个特定时刻,查询该时刻的行政区划状态。
举个例子,行政区划变更并不会影响该区划内现有公民的身份证号码,只会影响新出生公民的身份证号。因此有时候用公民身份证号前6位去查现在的行政区划表可能一无所获,需要回溯到该公民出生的历史时间才能查询到正确的结果。可以参考PostgreSQL MVCC的实现方式,为行政区划表添加一对PostgreSQL提供的tstzrange类型字段,标识行政区划记录版本的有效时间段,并在查询时指明时间点作为筛选条件。PostgreSQL可以支持在范围类型与空间类型上建立联合GIST索引,提供高效查询支持。
不过,时序数据获取难度是很大的。而且一般这个需求也并不常见。所以这里就不展开了。
0x05 设计实现
既然已经将地理编码的功能从区划代码表拆分出来,本题对adcode中的结构就不甚关注了。我们只需要知道凭借code字段能从该表中快速查出我们感兴趣的东西,比如一连串的行政区划层次,行政区划的人口,面积,等级,行政中心等等。
create table adcode
(
code bigint PRIMARY KEY ,
parent bigint references adcode(code),
name text,
rank integer,
path text[],
…… <other attrs>
);
相比之下,fences表才是我们需要关注的对象,因为这是性能损耗的关键路径。
CREATE TABLE fences (
id BIGSERIAL PRIMARY KEY,
fence geometry(POLYGON),
code BIGINT
);
CREATE INDEX ON fences USING GiST(fence);
CREATE INDEX ON fences USING Btree(code);
CLUSTER TABLE fences USING fences_fence_idx;
不使用行政区划代码code作为主键,给予了我们更多的灵活性与优化空间。任何时候需要修正地理编码的逻辑时,只修改fences中的数据即可。你甚至可以添加冗余字段与条件索引,将不同来源的数据,不同等级的行政区划,相互重叠的地理围栏放在同一张表中,灵活地执行自定义的编码逻辑。
说句题外话:如果您能确保自己的数据不会重叠,则可以考虑使用PostgreSQL提供的Exclude约束确保数据完整性:
CREATE TABLE fences (
id BIGSERIAL PRIMARY KEY,
fence geometry(POLYGON),
code BIGINT,
EXCLUDE USING gist(fence WITH &&)
-- no need to create gist index for fence anymore
);
性能测试
那么优化完之后的性能表现又如何?让我们随机生成一些坐标点,检验一下性能。
\set x random(75,125)
\set y random(20,50)
SELECT code FROM fences2 WHERE ST_Contains(fence,ST_Point(:x,:y));
在笔者的机器上,现在一次查询只要0.1ms了,单进程9k TPS,折算为48核机器约为350kTPS
$ pgbench adcode -T 5 -f run.sql
number of clients: 1
number of threads: 1
duration: 5 s
number of transactions actually processed: 45710
latency average = 0.109 ms
tps = 9135.632484 (including connections establishing)
tps = 9143.947723 (excluding connections establishing)
当然拿到code之后还是需要去行政区划表里查一次,但一次索引扫描的开销是很小的。
总的来说,与优化之前的实现相比,性能提升了60倍。落实在生产环境中,可能就意味着省了百来万的成本。