故障档案:pg_dump导致的连接池污染
PostgreSQL很棒,但这并不意味着它是Bug-Free的。这一次在线上环境中,我又遇到了一个很有趣的Case:由pg_dump导致的线上故障。这是一个非常微妙的Bug,由Pgbouncer,search_path,以及特殊的pg_dump操作所触发。
背景知识
连接污染
在PostgreSQL中,每条数据库连接对应一个后端进程,会持有一些临时资源(状态),在连接结束时会被销毁,包括:
- 本会话中修改过的参数。
RESET ALL; - 准备好的语句。
DEALLOCATE ALL - 打开的游标。
CLOSE ALL; - 监听的消息信道。
UNLISTEN * - 执行计划的缓存。
DISCARD PLANS; - 预分配的序列号值及其缓存。
DISCARD SEQUENCES; - 临时表。
DISCARD TEMP
Web应用会频繁建立大量的数据库连接,故在实际应用中通常都会使用连接池,复用连接,以减小连接创建与销毁的开销。除了使用各种语言/驱动内置的连接池外,Pgbouncer是最常用的第三方中间件连接池。Pgbouncer提供了一种Transaction Pooling的模式,即:每当客户端事务开始时,连接池会为客户端连接分配一个服务端连接,当事务结束时,服务端连接会被放回到池中。
事务池化模式也存在一些问题,例如连接污染。当某个客户端修改了连接的状态,并将该连接放回池中,其他的应用遍可能受到非预期的影响。如下图所示:
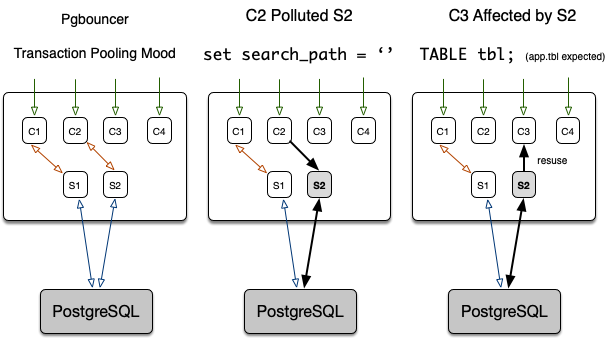
假设有四条客户端连接(前端连接)C1、C2、C3、C4,和两条服务器连接(后端连接)S1,S2。数据库默认搜索路径被配置为:app,$user,public,应用知道该假设,并使用SELECT * FROM tbl;的方式,来默认访问模式app下的表app.tbl。现在假设客户端C2在使用了服务器连接S2的过程中,执行了set search_path = ''清空了连接S2上的搜索路径。当S2被另一个客户端C3复用时,C3执行SELECT * FROM tbl时就会因为search_path中找不到对应的表而报错。
当客户端对于连接的假设被打破时,很容易出现各种错误。
故障排查
线上应用突然大量报错触发熔断,错误内容为大量的对象(表,函数)找不到。
第一直觉就是连接池被污染了:某个连接在修改完search_path之后将连接放回池中,当这个后端连接被其他前端连接复用时,就会出现找不到对象的情况。
连接至相应的Pool中,发现确实存在连接的search_path被污染的情况,某些连接的search_path被置空了,因此使用这些连接的应用就找不到对象了。
psql -p6432 somedb
# show search_path; \watch 0.1
在Pgbouncer中使用管理员账户执行RECONNECT命令,强制重连所有连接,search_path重置为默认值,问题解决。
reconnect somedb
不过问题就来了,究竟是什么应用修改了search_path呢?如果问题来源没有排查清楚,难免以后会重犯。有几种可能:业务代码修改,应用的驱动Bug,人工操作,或者连接池本身的Bug。嫌疑最大的当然是手工操作,有人如果使用生产账号用psql连到连接池,手工修改了search_path,然后退出,这个连接就会被放回到生产池中,导致污染。
首先检查数据库日志,发现报错的日志记录全都来自同一条服务器连接5c06218b.2ca6c,即只有一条连接被污染。找到这条连接开始持续报错的临界时刻:
cat postgresql-Tue.csv | grep 5c06218b.2ca6c
2018-12-04 14:44:42.766 CST,"xxx","xxx-xxx",182892,"127.0.0.1:60114",5c06218b.2ca6c,36,"SELECT",2018-12-04 14:41:15 CST,24/0,0,LOG,00000,"duration: 1067.392 ms statement: SELECT xxxx FROM x",,,,,,,,,"app - xx.xx.xx.xx:23962"
2018-12-04 14:45:03.857 CST,"xxx","xxx-xxx",182892,"127.0.0.1:60114",5c06218b.2ca6c,37,"SELECT",2018-12-04 14:41:15 CST,24/368400961,0,ERROR,42883,"function upsert_xxxxxx(xxx) does not exist",,"No function matches the given name and argument types. You might need to add explicit type casts.",,,,"select upsert_phone_plan('965+6628',1,0,0,0,1,0,'2018-12-03 19:00:00'::timestamp)",8,,"app - 10.191.160.49:46382"
这里5c06218b.2ca6c是该连接的唯一标识符,而后面的数字36,37则是该连接所产生日志的行号。一些操作并不会记录在日志中,但这里幸运的是,正常和出错的两条日志时间相差只有21秒,可以比较精确地定位故障时间点。
通过扫描所有白名单机器上该时刻的命令操作记录,精准定位到了一条执行记录:
pg_dump --host master.xxxx --port 6432 -d somedb -t sometable
嗯?pg_dump不是官方自带的工具吗,难道会修改search_path?不过直觉告诉我,还真不是没可能。例如我想起了一个有趣的行为,因为schema本质上是一个命名空间,因此位于不同schema内的对象可以有相同的名字。在老版本在使用-t转储特定表时,如果提供的表名参数不带schema前缀,pg_dump默认会默认转储所有同名的表。
查阅pg_dump的源码,发现还真有这种操作,以10.5版本为例,发现在setup_connection的时候,确实修改了search_path。
// src/bin/pg_dump/pg_dump.c line 287
int main(int argc, char **argv);
// src/bin/pg_dump/pg_dump.c line 681 main
setup_connection(fout, dumpencoding, dumpsnapshot, use_role);
// src/bin/pg_dump/pg_dump.c line 1006 setup_connection
PQclear(ExecuteSqlQueryForSingleRow(AH, ALWAYS_SECURE_SEARCH_PATH_SQL));
// include/server/fe_utils/connect.h
#define ALWAYS_SECURE_SEARCH_PATH_SQL \
"SELECT pg_catalog.set_config('search_path', '', false)"
Bug复现
接下来就是复现该BUG了。但比较奇怪的是,在使用PostgreSQL11的时候并没能复现出该Bug来,于是我看了一下肇事司机的全部历史记录,还原了其心路历程(发现pg_dump和服务器版本不匹配,来回折腾),使用不同版本的pg_dump终于复现了该BUG。
使用一个现成的数据库,名为data进行测试,版本为11.1。使用的Pgbouncer配置如下,为了便于调试,连接池的大小已经改小,只允许两条服务端连接。
[databases]
postgres = host=127.0.0.1
[pgbouncer]
logfile = /Users/vonng/pgb/pgbouncer.log
pidfile = /Users/vonng/pgb/pgbouncer.pid
listen_addr = *
listen_port = 6432
auth_type = trust
admin_users = postgres
stats_users = stats, postgres
auth_file = /Users/vonng/pgb/userlist.txt
pool_mode = transaction
server_reset_query =
max_client_conn = 50000
default_pool_size = 2
reserve_pool_size = 0
reserve_pool_timeout = 5
log_connections = 1
log_disconnections = 1
application_name_add_host = 1
ignore_startup_parameters = extra_float_digits
启动连接池,检查search_path,正常的默认配置。
$ psql postgres://vonng:123456@:6432/data -c 'show search_path;'
search_path
-----------------------
app, "$user", public
使用10.5版本的pg_dump,从6432端口发起Dump
/usr/local/Cellar/postgresql/10.5/bin/pg_dump \
postgres://vonng:123456@:6432/data \
-t geo.pois -f /dev/null
pg_dump: server version: 11.1; pg_dump version: 10.5
pg_dump: aborting because of server version mismatch
虽然Dump失败,但再次检查所有连接的search_path时,就会发现池里的连接已经被污染了,一条连接的search_path已经被修改为空
$ psql postgres://vonng:123456@:6432/data -c 'show search_path;'
search_path
-------------
(1 row)
解决方案
同时配置pgbouncer的server_reset_query以及server_reset_query_always参数,可以彻底解决此问题。
server_reset_query = DISCARD ALL
server_reset_query_always = 1
在TransactionPooling模式下,server_reset_query默认是不执行的,因此需要通过配置server_reset_query_always=1使每次事务执行完后强制执行DISCARD ALL清空连接的所有状态。不过,这样的配置是有代价的,DISCARD ALL实质上执行了以下操作:
SET SESSION AUTHORIZATION DEFAULT;
RESET ALL;
DEALLOCATE ALL;
CLOSE ALL;
UNLISTEN *;
SELECT pg_advisory_unlock_all();
DISCARD PLANS;
DISCARD SEQUENCES;
DISCARD TEMP;
如果每个事务后面都要多执行这些语句,确实会带来一些额外的性能开销。
当然,也有其他的方法,譬如从管理上解决,杜绝使用pg_dump访问6432端口的可能,将数据库账号使用专门的加密配置中心管理。或者要求业务方使用带schema限定名的name访问数据库对象。但都可能产生漏网之鱼,不如强制配置来的直接。