PG慢查询诊断方法论
前言
You can’t optimize what you can’t measure
慢查询是在线业务数据库的大敌,如何诊断定位慢查询是DBA的必修课题。
本文介绍了使用监控系统 —— Pigsty诊断慢查询的一般方法论。
慢查询:危害
对于实际服务于在线业务事务处理的PostgreSQL数据库而言,慢查询的危害包括:
- 慢查询挤占数据库连接,导致普通查询无连接可用,堆积并导致数据库雪崩。
- 慢查询长时间锁住了主库已经清理掉的旧版本元组,导致流复制重放进程锁死,导致主从复制延迟。
- 查询越慢,查询间相互踩踏的几率越高,越容易产生死锁、锁等待,事务冲突等问题。
- 慢查询浪费系统资源,拉高系统水位。
因此,一个合格的DBA必须知道如何及时定位并处理慢查询。
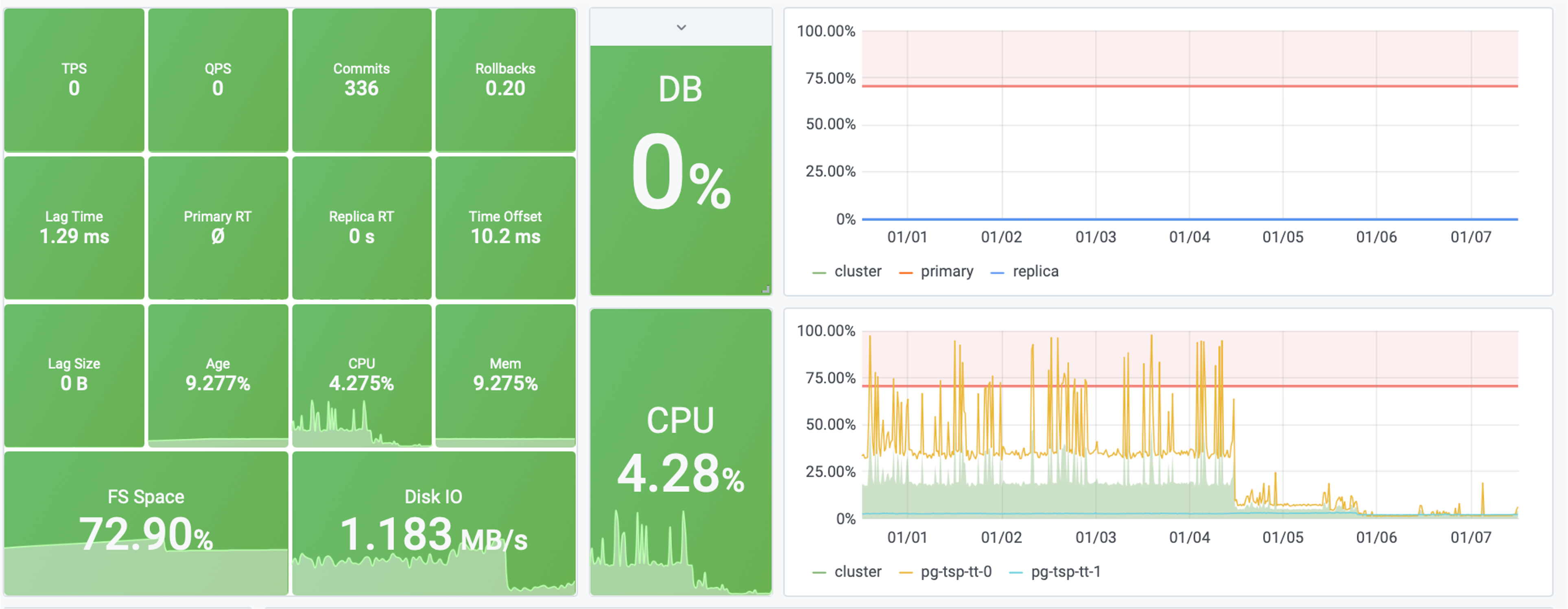
图:一个慢查询优化前后,系统的整体饱和度从40%降到了4%
慢查询诊断 —— 传统方法
传统上来说,在PostgreSQL有两种方式可以获得慢查询的相关信息,一个是通过官方的扩展插件pg_stat_statements,另一种是慢查询日志。
慢查询日志顾名思义,所有执行时间长于log_min_duration_statement参数的查询都会被记录到PG的日志中,对于定位慢查询,特别是对于分析特例、单次慢查询不可或缺。不过慢查询日志也有自己的局限性。在生产环境中出于性能考虑,通常只会记录时长超出某一阈值的查询,那么许多信息就无法从慢查询日志中获取了。当然值得一提的是,尽管开销很大,但全量查询日志仍然是慢查询分析的终极杀手锏。
更常用的慢查询诊断工具可能还是pg_stat_statements。这事是一个非常实用的扩展,它会收集数据库内运行查询的统计信息,在任何场景下都强烈建议启用该扩展。
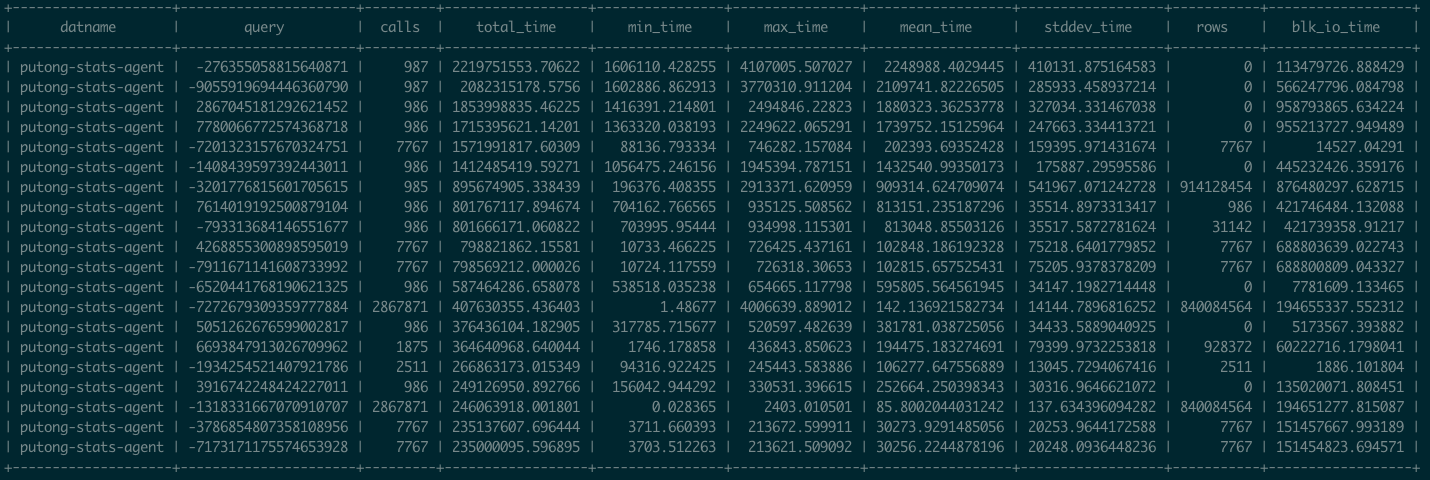
pg_stat_statements 提供的原始指标数据以系统视图表的形式呈现。系统中的每一类查询(即抽取变量后执行计划相同的查询)都分配有一个查询ID,紧接着是调用次数,总耗时,最大、最小、平均单次耗时,响应时间都标准差,每次调用平均返回的行数,用于块IO的时间这些指标类数据。
一种简单的方式当然是观察 mean_time/max_time这类指标,从系统的Catalog中,您的确可以知道某类查询有史以来平均的响应时间。对于定位慢查询来说,也许这样也算得上基本够用了。但是像这样的指标,只是系统在当前时刻的一个静态快照,所以能够回答的问题是有限的。譬如说,您想看一看某个查询在加上新索引之后的性能表现是不是有所改善,用这种方式可能就会非常繁琐。
pg_stat_statements需要在shared_preload_library中指定,并在数据库中通过CREATE EXTENSION pg_stat_statements显式创建。创建扩展后即可通过视图pg_stat_statements访问查询统计信息
慢查询的定义
多慢的查询算慢查询?
应该说这个问题取决于业务、以及实际的查询类型,并没有通用的标准。
作为一种经验阈值,频繁的CRUD点查,如果超过1ms,可列为慢查询。
对于偶发的单次特例查询而言,通常超过100ms或1s可以列为慢查询。
慢查询诊断 —— Pigsty
监控系统就可以更全面地回答关于慢查询的问题。监控系统中的数据是由无数历史快照组成的(如5秒一次快照采样)。因此用户可以回溯至任意时间点,考察不同时间段内查询平均响应时间的变化。
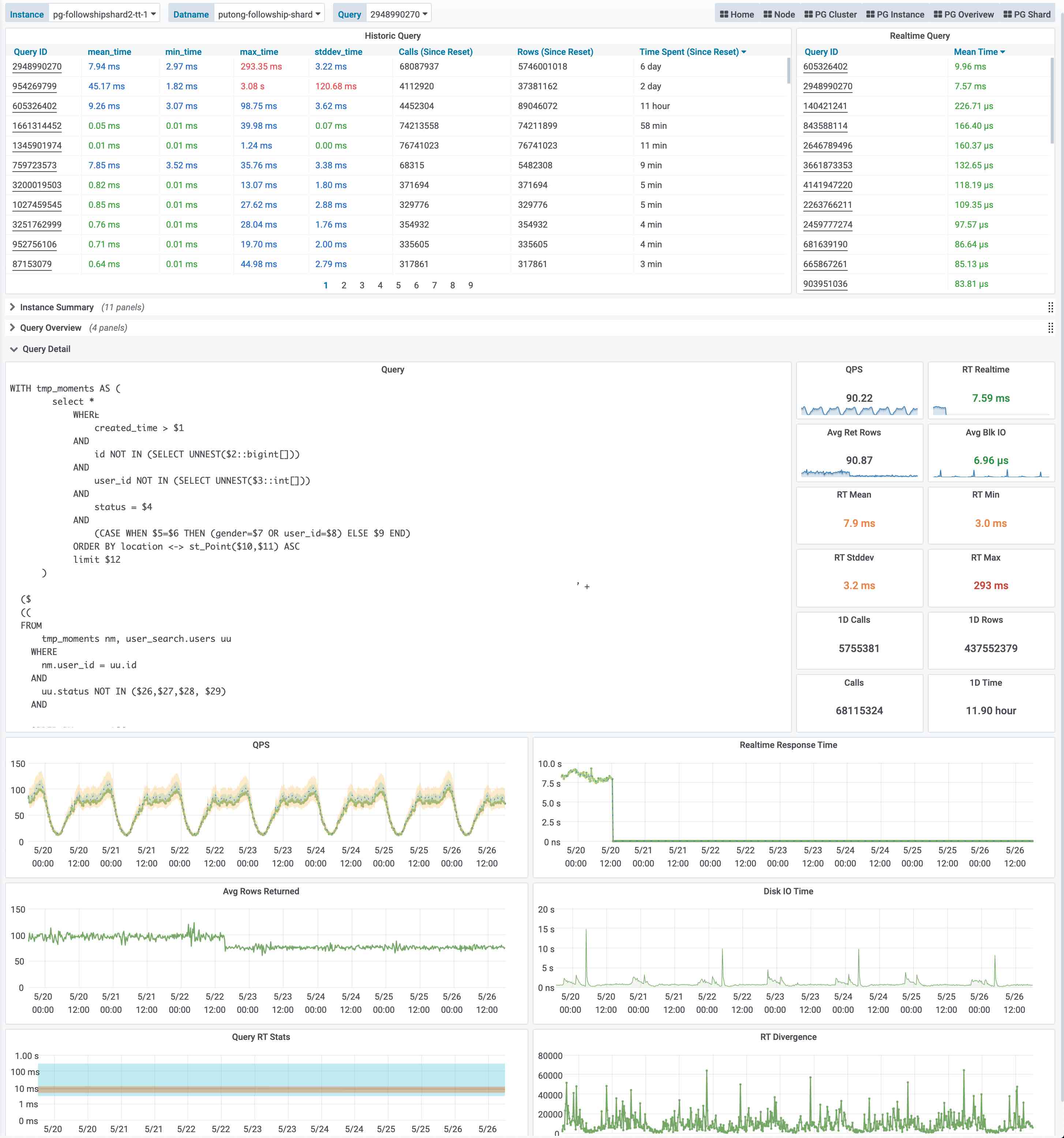
上图是Pigsty中 PG Query Detail提供的界面,这里展现出了单个查询的详细信息。
这是一个典型的慢查询,平均响应时间几秒钟。为它添加了一个索引后。从右中Query RT仪表盘的上可以看到,查询的平均响应世界从几秒降到了几毫秒。
用户可以利用监控系统提供的洞察迅速定位数据库中的慢查询,定位问题,提出猜想。更重要的是,用户可以即时地在不同层次审视表与查询的详细指标,应用解决方案并获取实时反馈,这对于紧急故障处理是非常有帮助的。
有时监控系统的用途不仅仅在于提供数据与反馈,它还可以作为一种安抚情绪的良药:设想一个慢查询把生产数据库打雪崩了,如果老板或客户没有一个地方可以透明地知道当前的处理状态,难免会焦急地催问,进一步影响问题解决的速度。监控系统也可以做作为精确管理的依据。您可以有理有据地用监控指标的变化和老板与客户吹牛逼。
一个模拟的慢查询案例
Talk is cheap, show me the code
假设用户已经拥有一个 Pigsty沙箱演示环境,下面将使用Pigsty沙箱,演示模拟的慢查询定位与处理流程。
慢查询:模拟
因为没有实际的业务系统,这里我们以一种简单快捷的方式模拟系统中的慢查询。即pgbench自带的类tpc-b场景。
通过make ri / make ro / make rw,在pg-test集群上初始化 pgbench 用例,并对集群施加读写负载
# 50TPS 写入负载
while true; do pgbench -nv -P1 -c20 --rate=50 -T10 postgres://test:test@pg-test:5433/test; done
# 1000TPS 只读负载
while true; do pgbench -nv -P1 -c40 --select-only --rate=1000 -T10 postgres://test:test@pg-test:5434/test; done
现在我们已经有了一个模拟运行中的业务系统,让我们通过简单粗暴的方式来模拟一个慢查询场景。在pg-test集群的主库上执行以下命令,删除表pgbench_accounts的主键:
ALTER TABLE pgbench_accounts DROP CONSTRAINT pgbench_accounts_pkey ;
该命令会移除 pgbench_accounts 表上的主键,导致相关查询从索引扫描变为顺序全表扫描,全部变为慢查询,访问PG Instance ➡️ Query ➡️ QPS,结果如下图所示:
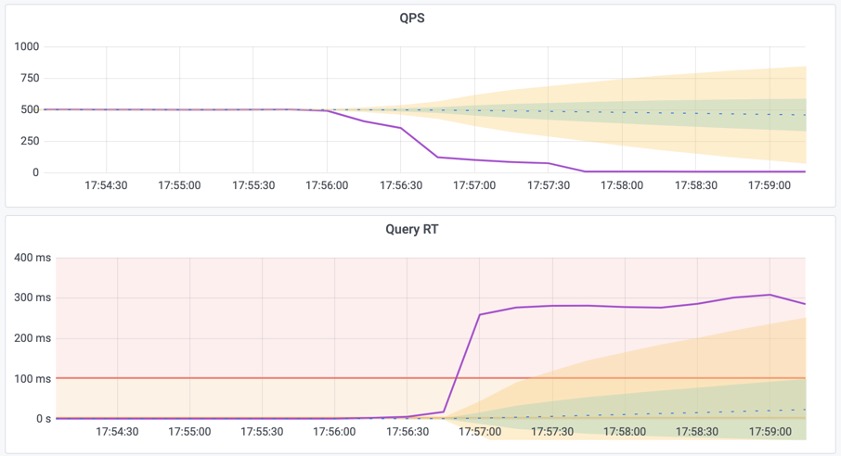
图1:平均查询响应时间从1ms飙升为300ms,单个从库实例的QPS从500下降至7。
与此同时,实例因为慢查询堆积,系统会在瞬间雪崩过载,访问PG Cluster首页,可以看到集群负载出现飙升。

图2:系统负载达到200%,触发机器负载过大,与查询响应时间过长的报警规则。
慢查询:定位
首先,使用PG Cluster面板定位慢查询所在的具体实例,这里以 pg-test-2 为例。
然后,使用PG Query面板定位具体的慢查询:编号为 -6041100154778468427
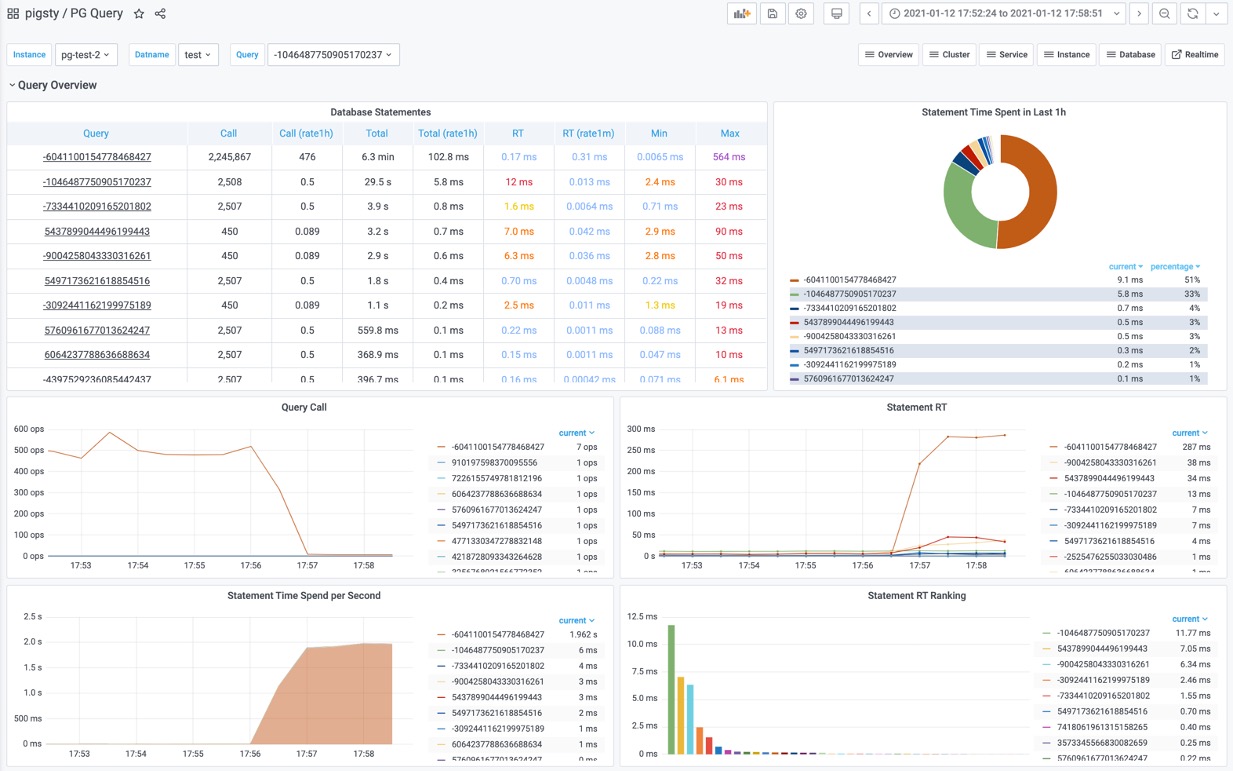
图3:从查询总览中发现异常慢查询
该查询表现出:
- 响应时间显著上升: 17us 升至 280ms
- QPS 显著下降: 从500下降到 7
- 花费在该查询上的时间占比显著增加
可以确定,就是这个查询变慢了!
接下来,利用PG Stat Statements面板或PG Query Detail,根据查询ID定位慢查询的具体语句。

图4:定位查询语句为
SELECT abalance FROM pgbench_accounts WHERE aid = $1
慢查询:猜想
获知慢查询语句后,接下来需要推断慢查询产生的原因。
SELECT abalance FROM pgbench_accounts WHERE aid = $1
该查询以 aid 作为过滤条件查询 pgbench_accounts 表,如此简单的查询变慢,大概率是这张表上的索引出了问题。 用屁股想都知道是索引少了,因为就是我们自己删掉的嘛!
分析查询后, 可以提出猜想: 该查询变慢是pgbench_accounts表上aid列缺少索引。
下一步,我们就要验证猜想。
第一步,使用PG Table Catalog,我们可以检视表的详情,例如表上建立的索引。
第二步,查阅 PG Table Detail 面板,检查 pgbench_accounts 表上的访问,来验证我们的猜想

图5:
pgbench_accounts表上的访问情况
通过观察,我们发现表上的索引扫描归零,与此同时顺序扫描却有相应增长。这印证了我们的猜想!
慢查询:方案
假设一旦成立,就可以着手提出方案,解决问题了。
解决慢查询通常有三种方式:修改表结构、修改查询、修改索引。
修改表结构与查询通常涉及到具体的业务知识和领域知识,需要具体问题具体分析。但修改索引通常来说不需要太多的具体业务知识。
这里的问题可以通过添加索引解决,pgbench_accounts 表上 aid 列缺少索引,那么我们尝试在 pgbench_accounts 表上为 aid 列添加索引,看看能否解决这个问题。
CREATE UNIQUE INDEX ON pgbench_accounts (aid);
加上索引后,神奇的事情发生了。

图6:可以看到,查询的响应时间与QPS已经恢复正常。
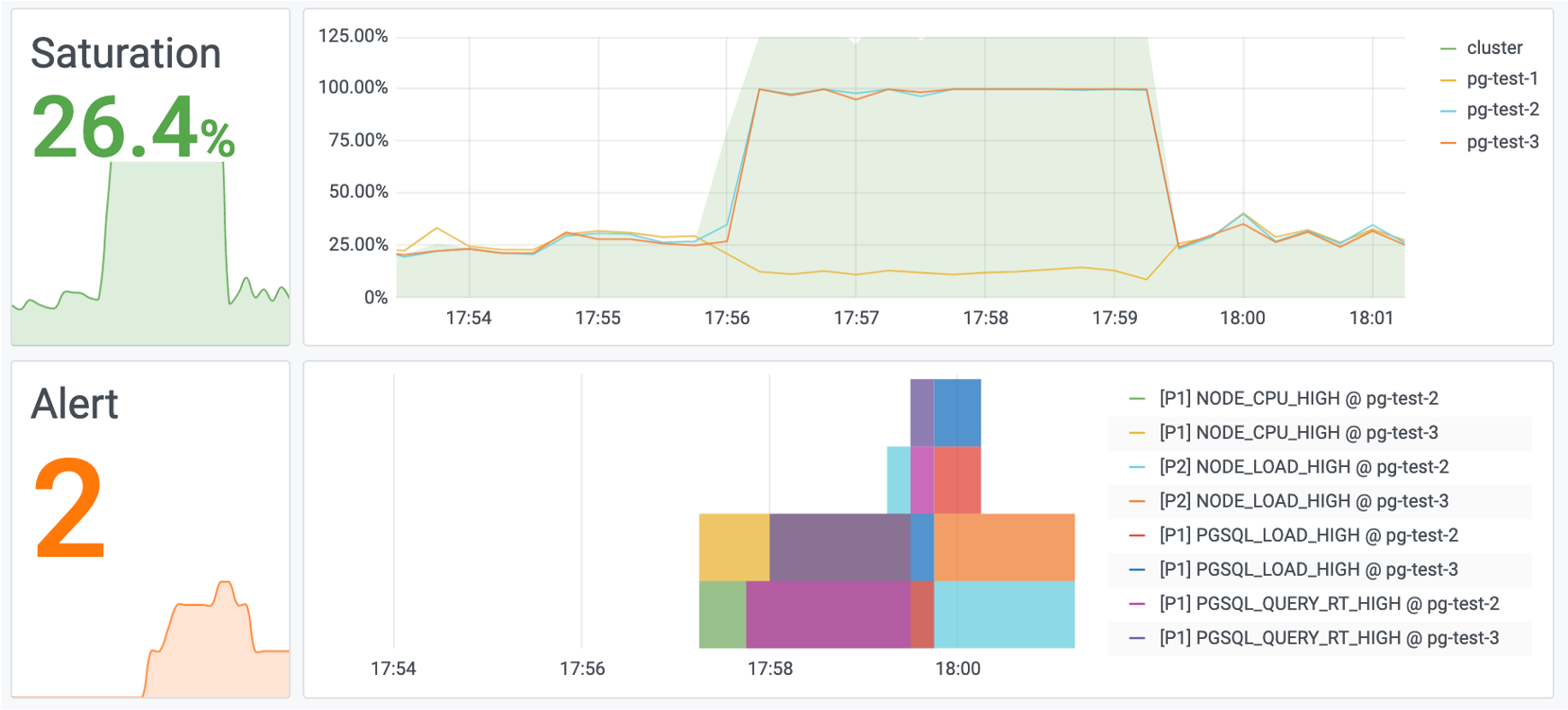
图7:系统的负载也恢复正常
慢查询:评估
作为慢查询处理的最后一步,我们通常需要对操作的过程进行记录,对效果进行评估。
有时候一个简单的优化可以产生戏剧性的效果。也许本来需要砸几十万加机器的问题,创建一个索引就解决了。
这种故事,就可以通过监控系统,用很生动直观的形式表达出来,赚取KPI与Credit。
图:一个慢查询优化前后,系统的整体饱和度从40%降到了4%
(相当于节省了X台机器,XX万元,老板看了心花怒放,下一任CTO就是你了!)
慢查询:小结
通过这篇教程,您已经掌握了慢查询优化的一般方法论。即:
-
定位问题
-
提出猜想
-
验证假设
-
制定方案
-
评估效果
监控系统在慢查询处理的整个生命周期中都能起到重要的效果。更能将运维与DBA的“经验”与“成果”,以可视化,可量化,可复制的方式表达出来。