关系膨胀:监控与处理
前言
PostgreSQL使用了MVCC作为主要并发控制技术,它有很多好处,但也会带来一些其他的影响,例如关系膨胀。关系(表与索引)膨胀会对数据库性能产生负面影响,并浪费磁盘空间。为了使PostgreSQL始终保持在最佳性能,有必要及时对膨胀的关系进行垃圾回收,并定期重建过度膨胀的关系。
在实际操作中,垃圾回收并没有那么简单,这里有一系列的问题:
- 关系膨胀的原因?
- 关系膨胀的度量?
- 关系膨胀的监控?
- 关系膨胀的处理?
本文将详细说明这些问题。
关系膨胀概述
假设某个关系实际占用存储100G,但其中有很多空间被死元组,碎片,空闲区域浪费,如果将其压实为一个新的关系,占用空间变为60G,那么就可以近似认为该关系的膨胀率是 (100 - 60) / 100 = 40%。
普通的VACUUM不能解决表膨胀的问题,死元组本身能够被并发VACUUM机制回收,但它产生的碎片,留下的空洞却不可以。比如,即使删除了许多死元组,也无法减小表的大小。久而久之,关系文件被大量空洞填满,浪费了大量的磁盘空间。
VACUUM FULL命令可以回收这些空间,它将旧表文件中的活元组复制到新表中,通过重写整张表的方式将表压实。但在实际生产中,因为该操作会持有表上的AccessExclusiveLock,阻塞业务正常访问,因此在不间断服务的情况下并不适用,pg_repack是一个实用的第三方插件,能够在线上业务正常进行的同时进行无锁的VACUUM FULL。
不幸的是,关于什么时候需要进行VACUUM FULL处理膨胀并没有一个最佳实践。DBA需要针对自己的业务场景制定清理策略。但无论采用何种策略,实施这些策略的机制都是类似的:
- 监控,检测,衡量关系的膨胀程度
- 依据关系的膨胀程度,时机等因素,处理关系膨胀。
这里有几个关键的问题,首先是,如何定义关系的膨胀率?
关系膨胀的度量
衡量关系膨胀的程度,首先需要定义一个指标:膨胀率(bloat rate)。
膨胀率的计算思想是:通过统计信息估算出目标表如果处于 紧实(Compact) 状态所占用的空间,而实际使用空间超出该紧实空间部分的占比,就是膨胀率。因此膨胀率可以被定义为 1 - (活元组占用字节总数 / 关系占用字节总数)。
例如,某个表实际占用存储100G,但其中有很多空间被死元组,碎片,空闲区域浪费,如果将其压实为一张新表,占用空间变为60G,那么膨胀率就是 1 - 60/100 = 40%。
关系的大小获取较为简单,可以直接从系统目录中获取。所以问题的关键在于,活元组的字节总数这一数据如何获取。
膨胀率的精确计算
PostgreSQL自带了pgstattuple模块,可用于精确计算表的膨胀率。譬如这里的tuple_percent字段就是元组实际字节占关系总大小的百分比,用1减去该值即为膨胀率。
vonng@[local]:5432/bench# select *,
1.0 - tuple_len::numeric / table_len as bloat
from pgstattuple('pgbench_accounts');
┌─[ RECORD 1 ]───────┬────────────────────────┐
│ table_len │ 136642560 │
│ tuple_count │ 1000000 │
│ tuple_len │ 121000000 │
│ tuple_percent │ 88.55 │
│ dead_tuple_count │ 16418 │
│ dead_tuple_len │ 1986578 │
│ dead_tuple_percent │ 1.45 │
│ free_space │ 1674768 │
│ free_percent │ 1.23 │
│ bloat │ 0.11447794889088729017 │
└────────────────────┴────────────────────────┘
pgstattuple对于精确地判断表与索引的膨胀情况非常有用,具体细节可以参考官方文档:https://www.postgresql.org/docs/current/static/pgstattuple.html。
此外,PostgreSQL还提供了两个自带的扩展,pg_freespacemap与pageinspect,前者可以用于检视每个页面中的空闲空间大小,后者则可以精确地展示关系中每个数据页内物理存储的内容。如果希望检视关系的内部状态,这两个插件非常实用,详细使用方法可以参考官方文档:
https://www.postgresql.org/docs/current/static/pgfreespacemap.html
https://www.postgresql.org/docs/current/static/pageinspect.html
不过在绝大多数情况下,我们并不会太在意膨胀率的精确度。在实际生产中对膨胀率的要求并不高:第一位有效数字是准确的,就差不多够用了。另一方面,要想精确地知道活元组占用的字节总数,需要对整个关系执行一遍扫描,这会对线上系统的IO产生压力。如果希望对所有表的膨胀率进行监控,也不适合使用这种方式。
例如一个200G的关系,使用pgstattuple插件执行精确的膨胀率估算大致需要5分钟时间。在9.5及后续版本,pgstattuple插件还提供了pgstattuple_approx函数,以精度换速度。但即使使用估算,也需要秒级的时间。
监控膨胀率,最重要的要求是速度快,影响小。因此当我们需要对很多数据库的很多表同时进行监控时,需要对膨胀率进行快速估算,避免对业务产生影响。
膨胀率的估算
PostgreSQL为每个关系都维护了很多的统计信息,利用统计信息,可以快速高效地估算数据库中所有表的膨胀率。估算膨胀率需要使用表与列上的统计信息,直接使用的统计指标有三个:
- 元组的平均宽度
avgwidth:从列级统计数据计算而来,用于估计紧实状态占用的空间。 - 元组数:
pg_class.reltuples:用于估计紧实状态占用的空间 - 页面数:
pg_class.relpages:用于测算实际使用的空间
而计算公式也很简单:
1 - (reltuples * avgwidth) / (block_size - pageheader) / relpages
这里block_size是页面大小,默认为8182,pageheader是首部占用的大小,默认为24字节。页面大小减去首部大小就是可以用于元组存储的实际空间,因此(reltuples * avgwidth)给出了元组的估计总大小,而除以前者后,就可以得到预计需要多少个页面才能紧实地存下所有的元组。最后,期待使用的页面数量,除以实际使用的页面数量,就是利用率,而1减去利用率,就是膨胀率。
难点
这里的关键,在于如何使用统计信息估算元组的平均长度,而为了实现这一点,我们需要克服三个困难:
- 当元组中存在空值时,首部会带有空值位图。
- 首部与数据部分存在Padding,需要考虑边界对齐。
- 一些字段类型也存在对齐要求
但好在,膨胀率本身就是一种估算,只要大致正确即可。
计算元组的平均长度
为了理解估算的过程,首先需要理解PostgreSQL中数据页面与元组的的内部布局。
首先来看元组的平均长度,PG中元组的布局如下图所示。
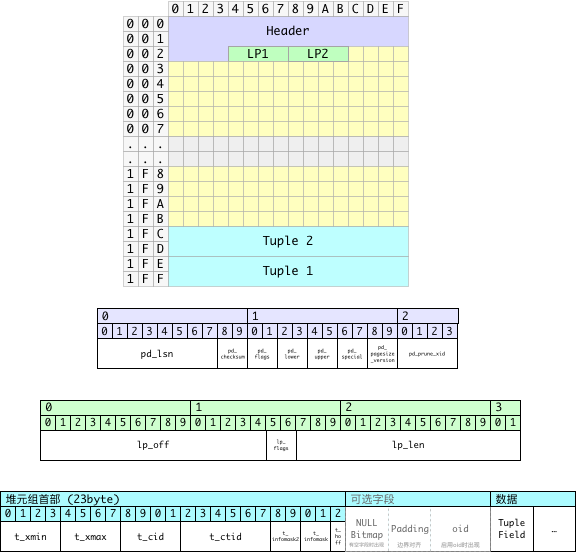
一条元组占用的空间可以分为三个部分:
- 定长的行指针(4字节,严格来说这不算元组的一部分,但它与元组一一对应)
- 变长的首部
- 固定长度部分23字节
- 当元组中存在空值时,会出现空值位图,每个字段占一位,故其长度为字段数除以8。
- 在空值位图后需要填充至
MAXALIGN,通常为8。 - 如果表启用了
WITH OIDS选项,元组还会有一个4字节的OID,但这里我们不考虑该情况。
- 数据部分
因此,一条元组(包括相应的行指针)的平均长度可以这样计算:
avg_size_tuple = 4 + avg_size_hdr + avg_size_data
关键在于求出首部的平均长度与数据部分的平均长度。
计算首部的平均长度
首部平均长度主要的变数在于空值位图与填充对齐。为了估算元组首部的平均长度,我们需要知道几个参数:
- 不带空值位图的首部平均长度(带有填充):
normhdr - 带有空值位图的首部平均长度(带有填充):
nullhdr - 带有空值的元组比例:
nullfrac
而估算首部平均长度的公式,也非常简单:
avg_size_hdr = nullhdr * nullfrac + normhdr * (1 - nullfrac)
因为不带空值位图的首部,其长度是23字节,对齐至8字节的边界,长度为24字节,上式可以改为:
avg_size_hdr = nullhdr * nullfrac + 24 * (1 - nullfrac)
计算某值被补齐至8字节边界的长度,可以使用以下公式进行高效计算:
padding = lambda x : x + 7 >> 3 << 3
计算数据部分的平均长度
数据部分的平均长度主要取决于每个字段的平均宽度与空值率,加上末尾的对齐。
以下SQL可以利用统计信息算出所有表的平均元组数据部分宽度。
SELECT schemaname, tablename, sum((1 - null_frac) * avg_width)
FROM pg_stats GROUP BY (schemaname, tablename);
例如,以下SQL能够从pg_stats系统统计视图中获取app.apple表上一条元组的平均长度。
SELECT
count(*), -- 字段数目
ceil(count(*) / 8.0), -- 空值位图占用的字节数
max(null_frac), -- 最大空值率
sum((1 - null_frac) * avg_width) -- 数据部分的平均宽度
FROM pg_stats
where schemaname = 'app' and tablename = 'apple';
-[ RECORD 1 ]-----------
count | 47
ceil | 6
max | 1
sum | 1733.76873471724
整合
将上面三节的逻辑整合,得到以下的存储过程,给定一个表,返回其膨胀率。
CREATE OR REPLACE FUNCTION public.pg_table_bloat(relation regclass)
RETURNS double precision
LANGUAGE plpgsql
AS $function$
DECLARE
_schemaname text;
tuples BIGINT := 0;
pages INTEGER := 0;
nullheader INTEGER:= 0;
nullfrac FLOAT := 0;
datawidth INTEGER :=0;
avgtuplelen FLOAT :=24;
BEGIN
SELECT
relnamespace :: RegNamespace,
reltuples,
relpages
into _schemaname, tuples, pages
FROM pg_class
Where oid = relation;
SELECT
23 + ceil(count(*) >> 3),
max(null_frac),
ceil(sum((1 - null_frac) * avg_width))
into nullheader, nullfrac, datawidth
FROM pg_stats
where schemaname = _schemaname and tablename = relation :: text;
SELECT (datawidth + 8 - (CASE WHEN datawidth%8=0 THEN 8 ELSE datawidth%8 END)) -- avg data len
+ (1 - nullfrac) * 24 + nullfrac * (nullheader + 8 - (CASE WHEN nullheader%8=0 THEN 8 ELSE nullheader%8 END))
INTO avgtuplelen;
raise notice '% %', nullfrac, datawidth;
RETURN 1 - (ceil(tuples * avgtuplelen / 8168)) / pages;
END;
$function$
批量计算
对于监控而言,我们关注的往往不仅仅是一张表,而是库中所有的表。因此,可以将上面的膨胀率计算逻辑重写为批量计算的查询,并定义为视图便于使用:
DROP VIEW IF EXISTS monitor.pg_bloat_indexes CASCADE;
CREATE OR REPLACE VIEW monitor.pg_bloat_indexes AS
WITH btree_index_atts AS (
SELECT
pg_namespace.nspname,
indexclass.relname AS index_name,
indexclass.reltuples,
indexclass.relpages,
pg_index.indrelid,
pg_index.indexrelid,
indexclass.relam,
tableclass.relname AS tablename,
(regexp_split_to_table((pg_index.indkey) :: TEXT, ' ' :: TEXT)) :: SMALLINT AS attnum,
pg_index.indexrelid AS index_oid
FROM ((((pg_index
JOIN pg_class indexclass ON ((pg_index.indexrelid = indexclass.oid)))
JOIN pg_class tableclass ON ((pg_index.indrelid = tableclass.oid)))
JOIN pg_namespace ON ((pg_namespace.oid = indexclass.relnamespace)))
JOIN pg_am ON ((indexclass.relam = pg_am.oid)))
WHERE ((pg_am.amname = 'btree' :: NAME) AND (indexclass.relpages > 0))
), index_item_sizes AS (
SELECT
ind_atts.nspname,
ind_atts.index_name,
ind_atts.reltuples,
ind_atts.relpages,
ind_atts.relam,
ind_atts.indrelid AS table_oid,
ind_atts.index_oid,
(current_setting('block_size' :: TEXT)) :: NUMERIC AS bs,
8 AS maxalign,
24 AS pagehdr,
CASE
WHEN (max(COALESCE(pg_stats.null_frac, (0) :: REAL)) = (0) :: FLOAT)
THEN 2
ELSE 6
END AS index_tuple_hdr,
sum((((1) :: FLOAT - COALESCE(pg_stats.null_frac, (0) :: REAL)) *
(COALESCE(pg_stats.avg_width, 1024)) :: FLOAT)) AS nulldatawidth
FROM ((pg_attribute
JOIN btree_index_atts ind_atts
ON (((pg_attribute.attrelid = ind_atts.indexrelid) AND (pg_attribute.attnum = ind_atts.attnum))))
JOIN pg_stats ON (((pg_stats.schemaname = ind_atts.nspname) AND (((pg_stats.tablename = ind_atts.tablename) AND
((pg_stats.attname) :: TEXT =
pg_get_indexdef(pg_attribute.attrelid,
(pg_attribute.attnum) :: INTEGER,
TRUE))) OR
((pg_stats.tablename = ind_atts.index_name) AND
(pg_stats.attname = pg_attribute.attname))))))
WHERE (pg_attribute.attnum > 0)
GROUP BY ind_atts.nspname, ind_atts.index_name, ind_atts.reltuples, ind_atts.relpages, ind_atts.relam,
ind_atts.indrelid, ind_atts.index_oid, (current_setting('block_size' :: TEXT)) :: NUMERIC, 8 :: INTEGER
), index_aligned_est AS (
SELECT
index_item_sizes.maxalign,
index_item_sizes.bs,
index_item_sizes.nspname,
index_item_sizes.index_name,
index_item_sizes.reltuples,
index_item_sizes.relpages,
index_item_sizes.relam,
index_item_sizes.table_oid,
index_item_sizes.index_oid,
COALESCE(ceil((((index_item_sizes.reltuples * ((((((((6 + index_item_sizes.maxalign) -
CASE
WHEN ((index_item_sizes.index_tuple_hdr %
index_item_sizes.maxalign) = 0)
THEN index_item_sizes.maxalign
ELSE (index_item_sizes.index_tuple_hdr %
index_item_sizes.maxalign)
END)) :: FLOAT + index_item_sizes.nulldatawidth)
+ (index_item_sizes.maxalign) :: FLOAT) - (
CASE
WHEN (((index_item_sizes.nulldatawidth) :: INTEGER %
index_item_sizes.maxalign) = 0)
THEN index_item_sizes.maxalign
ELSE ((index_item_sizes.nulldatawidth) :: INTEGER %
index_item_sizes.maxalign)
END) :: FLOAT)) :: NUMERIC) :: FLOAT) /
((index_item_sizes.bs - (index_item_sizes.pagehdr) :: NUMERIC)) :: FLOAT) +
(1) :: FLOAT)), (0) :: FLOAT) AS expected
FROM index_item_sizes
), raw_bloat AS (
SELECT
current_database() AS dbname,
index_aligned_est.nspname,
pg_class.relname AS table_name,
index_aligned_est.index_name,
(index_aligned_est.bs * ((index_aligned_est.relpages) :: BIGINT) :: NUMERIC) AS totalbytes,
index_aligned_est.expected,
CASE
WHEN ((index_aligned_est.relpages) :: FLOAT <= index_aligned_est.expected)
THEN (0) :: NUMERIC
ELSE (index_aligned_est.bs *
((((index_aligned_est.relpages) :: FLOAT - index_aligned_est.expected)) :: BIGINT) :: NUMERIC)
END AS wastedbytes,
CASE
WHEN ((index_aligned_est.relpages) :: FLOAT <= index_aligned_est.expected)
THEN (0) :: NUMERIC
ELSE (((index_aligned_est.bs * ((((index_aligned_est.relpages) :: FLOAT -
index_aligned_est.expected)) :: BIGINT) :: NUMERIC) * (100) :: NUMERIC) /
(index_aligned_est.bs * ((index_aligned_est.relpages) :: BIGINT) :: NUMERIC))
END AS realbloat,
pg_relation_size((index_aligned_est.table_oid) :: REGCLASS) AS table_bytes,
stat.idx_scan AS index_scans
FROM ((index_aligned_est
JOIN pg_class ON ((pg_class.oid = index_aligned_est.table_oid)))
JOIN pg_stat_user_indexes stat ON ((index_aligned_est.index_oid = stat.indexrelid)))
), format_bloat AS (
SELECT
raw_bloat.dbname AS database_name,
raw_bloat.nspname AS schema_name,
raw_bloat.table_name,
raw_bloat.index_name,
round(
raw_bloat.realbloat) AS bloat_pct,
round((raw_bloat.wastedbytes / (((1024) :: FLOAT ^
(2) :: FLOAT)) :: NUMERIC)) AS bloat_mb,
round((raw_bloat.totalbytes / (((1024) :: FLOAT ^ (2) :: FLOAT)) :: NUMERIC),
3) AS index_mb,
round(
((raw_bloat.table_bytes) :: NUMERIC / (((1024) :: FLOAT ^ (2) :: FLOAT)) :: NUMERIC),
3) AS table_mb,
raw_bloat.index_scans
FROM raw_bloat
)
SELECT
format_bloat.database_name as datname,
format_bloat.schema_name as nspname,
format_bloat.table_name as relname,
format_bloat.index_name as idxname,
format_bloat.index_scans as idx_scans,
format_bloat.bloat_pct as bloat_pct,
format_bloat.table_mb,
format_bloat.index_mb - format_bloat.bloat_mb as actual_mb,
format_bloat.bloat_mb,
format_bloat.index_mb as total_mb
FROM format_bloat
ORDER BY format_bloat.bloat_mb DESC;
COMMENT ON VIEW monitor.pg_bloat_indexes IS 'index bloat monitor';
虽然看上去很长,但查询该视图获取全库(3TB)所有表的膨胀率,计算只需要50ms。而且只需要访问统计数据,不需要访问关系本体,占用实例的IO。
表膨胀的处理
如果只是玩具数据库,或者业务允许每天有很长的停机维护时间,那么简单地在数据库中执行VACUUM FULL就可以了。但VACUUM FULL需要表上的排它读写锁,但对于需要不间断运行的数据库,我们就需要用到pg_repack来处理表的膨胀。
- 主页:http://reorg.github.io/pg_repack/
pg_repack已经包含在了PostgreSQL官方的yum源中,因此可以直接通过yum install pg_repack安装。
yum install pg_repack10
pg_repack的使用
与大多数PostgreSQL客户端程序一样,pg_repack也通过类似的参数连接至PostgreSQL服务器。
在使用pg_repack之前,需要在待重整的数据库中创建pg_repack扩展
CREATE EXTENSION pg_repack
然后就可以正常使用了,几种典型的用法:
# 完全清理整个数据库,开5个并发任务,超时等待10秒
pg_repack -d <database> -j 5 -T 10
# 清理mydb中一张特定的表mytable,超时等待10秒
pg_repack mydb -t public.mytable -T 10
# 清理某个特定的索引 myschema.myindex,注意必须使用带模式的全名
pg_repack mydb -i myschema.myindex
详细的用法可以参考官方文档。
pg_repack的策略
通常,如果业务存在峰谷周期,则可以选在业务低谷器进行整理。pg_repack执行比较快,但很吃资源。在高峰期执行可能会影响整个数据库的性能表现,也有可能会导致复制滞后。
例如,可以利用上面两节提供的膨胀率监控视图,每天挑选膨胀最为严重的若干张表和若干索引进行自动重整。
#--------------------------------------------------------------#
# Name: repack_tables
# Desc: repack table via fullname
# Arg1: database_name
# Argv: list of table full name
# Deps: psql
#--------------------------------------------------------------#
# repack single table
function repack_tables(){
local db=$1
shift
log_info "repack ${db} tables begin"
log_info "repack table list: $@"
for relname in $@
do
old_size=$(psql ${db} -Atqc "SELECT pg_size_pretty(pg_relation_size('${relname}'));")
# kill_queries ${db}
log_info "repack table ${relname} begin, old size: ${old_size}"
pg_repack ${db} -T 10 -t ${relname}
new_size=$(psql ${db} -Atqc "SELECT pg_size_pretty(pg_relation_size('${relname}'));")
log_info "repack table ${relname} done , new size: ${old_size} -> ${new_size}"
done
log_info "repack ${db} tables done"
}
#--------------------------------------------------------------#
# Name: get_bloat_tables
# Desc: find bloat tables in given database match some condition
# Arg1: database_name
# Echo: list of full table name
# Deps: psql, monitor.pg_bloat_tables
#--------------------------------------------------------------#
function get_bloat_tables(){
echo $(psql ${1} -Atq <<-'EOF'
WITH bloat_tables AS (
SELECT
nspname || '.' || relname as relname,
actual_mb,
bloat_pct
FROM monitor.pg_bloat_tables
WHERE nspname NOT IN ('dba', 'monitor', 'trash')
ORDER BY 2 DESC,3 DESC
)
-- 64 small + 16 medium + 4 large
(SELECT relname FROM bloat_tables WHERE actual_mb < 256 AND bloat_pct > 40 ORDER BY bloat_pct DESC LIMIT 64) UNION
(SELECT relname FROM bloat_tables WHERE actual_mb BETWEEN 256 AND 1024 AND bloat_pct > 30 ORDER BY bloat_pct DESC LIMIT 16) UNION
(SELECT relname FROM bloat_tables WHERE actual_mb BETWEEN 1024 AND 4096 AND bloat_pct > 20 ORDER BY bloat_pct DESC LIMIT 4);
EOF
)
}
这里,设置了三条规则:
- 从小于256MB,且膨胀率超过40%的小表中,选出TOP64
- 从256MB到1GB之间,且膨胀率超过40%的中表中,选出TOP16
- 从1GB到4GB之间,且膨胀率超过20%的大表中,选出TOP4
选出这些表,每天凌晨低谷自动进行重整。超过4GB的表手工处理。
但何时进行重整,还是取决于具体的业务模式。
pg_repack的原理
pg_repack的原理相当简单,它会为待重建的表创建一份副本。首先取一份全量快照,将所有活元组写入新表,并通过触发器将所有针对原表的变更同步至新表,最后通过重命名,使用新的紧实副本替换老表。而对于索引,则是通过PostgreSQL的CREATE(DROP) INDEX CONCURRENTLY完成的。
重整表
- 创建一张与原表模式相同,但不带索引的空表。
- 创建一张与原始表对应的日志表,用于记录
pg_repack工作期间该表上发生的变更。 - 为原始表添加一个行触发器,在相应日志表中记录所有
INSERT,DELETE,UPDATE操作。 - 将老表中的数据复制到新的空表中。
- 在新表上创建同样的索引
- 将日志表中的增量变更应用到新表上
- 通过重命名的方式切换新旧表
- 将旧的,已经被重命名掉的表
DROP掉。
重整索引
- 使用
CREATE INDEX CONCURRENTLY在原表上创建新索引,保持与旧索引相同的定义。 Analyze新索引,并将旧索引设置为无效,在数据目录中将新旧索引交换。- 删除旧索引。
pg_repack的注意事项
-
重整开始之前,最好取消掉所有正在进行的
Vacuum任务。 -
对索引做重整之前,最好能手动清理掉可能正在使用该索引的查询
-
如果出现异常的情况(譬如中途强制退出),有可能会留下未清理的垃圾,需要手工清理。可能包括:
- 临时表与临时索引建立在与原表/索引同一个schema内
- 临时表的名称为:
${schema_name}.table_${table_oid} - 临时索引的名称为:
${schema_name}.index_${table_oid}} - 原始表上可能会残留相关的触发器,需要手动清理。
-
重整特别大的表时,需要预留至少与该表及其索引相同大小的磁盘空间,需要特别小心,手动检查。
-
当完成重整,进行重命名替换时,会产生巨量的WAL,有可能会导致复制延迟,而且无法取消。