PostgreSQL数据页面损坏修复
PostgreSQL是一个很可靠的数据库,但是再可靠的数据库,如果碰上了不可靠的硬件,恐怕也得抓瞎。本文介绍了在PostgreSQL中,应对数据页面损坏的方法。
最初的问题
线上有一套统计库跑离线任务,业务方反馈跑SQL的时候碰上一个错误:
ERROR: invalid page in block 18858877 of relation base/16400/275852
看到这样的错误信息,第一直觉就是硬件错误导致的关系数据文件损坏,第一步要检查定位具体问题。
这里,16400是数据库的oid,而275852则是数据表的relfilenode,通常等于OID。
somedb=# select 275852::RegClass;
regclass
---------------------
dailyuseractivities
-- 如果relfilenode与oid不一致,则使用以下查询
somedb=# select relname from pg_class where pg_relation_filenode(oid) = '275852';
relname
---------------------
dailyuseractivities
(1 row)
定位到出问题的表之后,检查出问题的页面,这里错误提示区块号为18858877的页面出现问题。
somedb=# select * from dailyuseractivities where ctid = '(18858877,1)';
ERROR: invalid page in block 18858877 of relation base/16400/275852
-- 打印详细错误位置
somedb=# \errverbose
ERROR: XX001: invalid page in block 18858877 of relation base/16400/275852
LOCATION: ReadBuffer_common, bufmgr.c:917
通过检查,发现该页面无法访问,但该页面前后两个页面都可以正常访问。使用errverbose可以打印出错误所在的源码位置。搜索PostgreSQL源码,发现这个错误信息只在一处位置出现:https://github.com/postgres/postgres/blob/master/src/backend/storage/buffer/bufmgr.c。可以看到,错误发生在页面从磁盘加载到内存共享缓冲区时。PostgreSQL认为这是一个无效的页面,因此报错并中止事务。
/* check for garbage data */
if (!PageIsVerified((Page) bufBlock, blockNum))
{
if (mode == RBM_ZERO_ON_ERROR || zero_damaged_pages)
{
ereport(WARNING,
(errcode(ERRCODE_DATA_CORRUPTED),
errmsg("invalid page in block %u of relation %s; zeroing out page",
blockNum,
relpath(smgr->smgr_rnode, forkNum))));
MemSet((char *) bufBlock, 0, BLCKSZ);
}
else
ereport(ERROR,
(errcode(ERRCODE_DATA_CORRUPTED),
errmsg("invalid page in block %u of relation %s",
blockNum,
relpath(smgr->smgr_rnode, forkNum))));
}
进一步检查PageIsVerified函数的逻辑:
/* 这里的检查并不能保证页面首部是正确的,只是说它看上去足够正常
* 允许其加载至缓冲池中。后续实际使用该页面时仍然可能会出错,这也
* 是我们提供校验和选项的原因。*/
if ((p->pd_flags & ~PD_VALID_FLAG_BITS) == 0 &&
p->pd_lower <= p->pd_upper &&
p->pd_upper <= p->pd_special &&
p->pd_special <= BLCKSZ &&
p->pd_special == MAXALIGN(p->pd_special))
header_sane = true;
if (header_sane && !checksum_failure)
return true;
接下来就要具体定位问题了,那么第一步,首先要找到问题页面在磁盘上的位置。这其实是两个子问题:在哪个文件里,以及在文件里的偏移量地址。这里,关系文件的relfilenode是275852,在PostgreSQL中,每个关系文件都会被默认切割为1GB大小的段文件,并用relfilenode, relfilenode.1, relfilenode.2, …这样的规则依此命名。
因此,我们可以计算一下,第18858877个页面,每个页面8KB,一个段文件1GB。偏移量为18858877 * 2^13 = 154491920384。
154491920384 / (1024^3) = 143
154491920384 % (1024^3) = 946839552 = 0x386FA000
由此可得,问题页面位于第143个段内,偏移量0x386FA000处。
落实到具体文件,也就是${PGDATA}/base/16400/275852.143。
hexdump 275852.143 | grep -w10 386fa00
386f9fe0 003b 0000 0100 0000 0100 0000 4b00 07c8
386f9ff0 9b3d 5ed9 1f40 eb85 b851 44de 0040 0000
386fa000 0000 0000 0000 0000 0000 0000 0000 0000
*
386fb000 62df 3d7e 0000 0000 0452 0000 011f c37d
386fb010 0040 0003 0b02 0018 18f6 0000 d66a 0068
使用二进制编辑器打开并定位至相应偏移量,发现该页面的内容已经被抹零,没有抢救价值了。好在线上的数据库至少都是一主一从配置,如果是因为主库上的坏块导致的页面损坏,从库上应该还有原来的数据。在从库上果然能找到对应的数据:
386f9fe0:3b00 0000 0001 0000 0001 0000 004b c807 ;............K..
386f9ff0:3d9b d95e 401f 85eb 51b8 de44 4000 0000 =..^@...Q..D@...
386fa000:e3bd 0100 70c8 864a 0000 0400 f801 0002 ....p..J........
386fa010:0020 0420 0000 0000 c09f 7a00 809f 7a00 . . ......z...z.
386fa020:409f 7a00 009f 7a00 c09e 7a00 809e 7a00 @.z...z...z...z.
386fa030:409e 7a00 009e 7a00 c09d 7a00 809d 7a00 @.z...z...z...z.
当然,如果页面是正常的,在从库上执行读取操作就不会报错。因此可以直接通过CTID过滤把损坏的数据找回来。
到现在为止,数据虽然找回来,可以松一口气了。但主库上的坏块问题仍然需要处理,这个就比较简单了,直接重建该表,并从从库抽取最新的数据即可。有各种各样的方法,VACUUM FULL,pg_repack,或者手工重建拷贝数据。
不过,我注意到在判定页面有效性的代码中出现了一个从来没见过的参数zero_damaged_pages,查阅文档才发现,这是一个开发者调试用参数,可以允许PostgreSQL忽略损坏的数据页,将其视为全零的空页面。用WARNING替代ERROR。这引发了我的兴趣。毕竟有时候,对于一些粗放的统计业务,跑了几个小时的SQL因为一两条脏数据中断,恐怕要比错漏那么几条记录更令人抓狂。这个参数可不可以满足这样的需求呢?
zero_damaged_pages(boolean)PostgreSQL在检测到损坏的页面首部时通常会报告一个错误,并中止当前事务。将参数
zero_damaged_pages配置为on,会使系统取而代之报告一个WARNING,并将内存中的页面抹为全零。然而该操作会摧毁数据,也就是说损坏页面上的行全都会丢失。不过,这样做确实能允许你略过错误并从未损坏的页面中获取表中未受损的行。当出现软件或硬件导致的数据损坏时,该选项可用于恢复数据。通常情况下只有当您放弃从受损的页面中恢复数据时,才应当使用该选项。抹零的页面并不会强制刷回磁盘,因此建议在重新关闭该选项之前重建受损的表或索引。本选项默认是关闭的,且只有超级用户才能修改。
毕竟,当重建表之后,原来的坏块就被释放掉了。如果硬件本身没有提供坏块识别与筛除的功能,那么这就是一个定时炸弹,很可能将来又会坑到自己。不幸的是,这台机器上的数据库有14TB,用的16TB的SSD,暂时没有同类型的机器了。只能先苟一下,因此需要研究一下,这个参数能不能让查询在遇到坏页时自动跳过。
苟且的办法
如下,在本机搭建一个测试集群,配置一主一从。尝试复现该问题,并确定
# tear down
pg_ctl -D /pg/d1 stop
pg_ctl -D /pg/d2 stop
rm -rf /pg/d1 /pg/d2
# master @ port5432
pg_ctl -D /pg/d1 init
pg_ctl -D /pg/d1 start
psql postgres -c "CREATE USER replication replication;"
# slave @ port5433
pg_basebackup -Xs -Pv -R -D /pg/d2 -Ureplication
pg_ctl -D /pg/d2 start -o"-p5433"
连接至主库,创建样例表并插入555条数据,约占据三个页面。
-- psql postgres
DROP TABLE IF EXISTS test;
CREATE TABLE test(id varchar(8) PRIMARY KEY);
ANALYZE test;
-- 注意,插入数据之后一定要执行checkpoint确保落盘
INSERT INTO test SELECT generate_series(1,555)::TEXT;
CHECKPOINT;
现在,让我们模拟出现坏块的情况,首先找出主库中test表的对应文件。
SELECT pg_relation_filepath(oid) FROM pg_class WHERE relname = 'test';
base/12630/16385
$ hexdump /pg/d1/base/12630/16385 | head -n 20
0000000 00 00 00 00 d0 22 02 03 00 00 00 00 a0 03 c0 03
0000010 00 20 04 20 00 00 00 00 e0 9f 34 00 c0 9f 34 00
0000020 a0 9f 34 00 80 9f 34 00 60 9f 34 00 40 9f 34 00
0000030 20 9f 34 00 00 9f 34 00 e0 9e 34 00 c0 9e 36 00
0000040 a0 9e 36 00 80 9e 36 00 60 9e 36 00 40 9e 36 00
0000050 20 9e 36 00 00 9e 36 00 e0 9d 36 00 c0 9d 36 00
0000060 a0 9d 36 00 80 9d 36 00 60 9d 36 00 40 9d 36 00
0000070 20 9d 36 00 00 9d 36 00 e0 9c 36 00 c0 9c 36 00
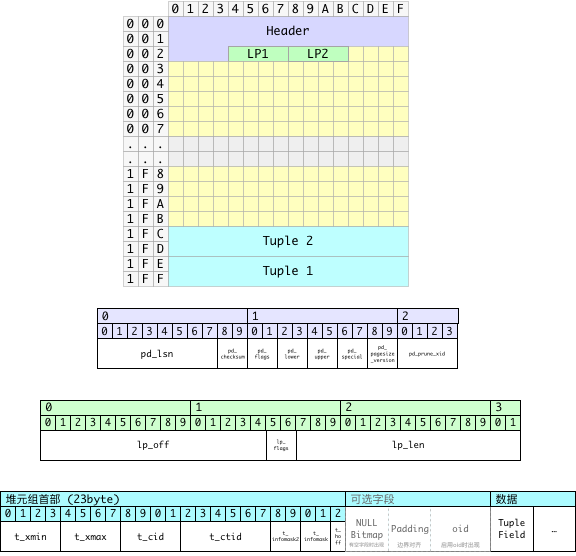
上面已经给出了PostgreSQL判断页面是否“正常”的逻辑,这里我们就修改一下数据页面,让页面变得“不正常”。页面的第12~16字节,也就是这里第一行的最后四个字节a0 03 c0 03,是页面内空闲空间上下界的指针。这里按小端序解释的意思就是本页面内,空闲空间从0x03A0开始,到0x03C0结束。符合逻辑的空闲空间范围当然需要满足上界小于等于下界。这里我们将上界0x03A0修改为0x03D0,超出下界0x03C0,也就是将第一行的倒数第四个字节由A0修改为D0。
# vim打开后使用 :%!xxd 编辑二进制
# 编辑完成后使用 :%!xxd -r转换回二进制,再用:wq保存
vi /pg/d1/base/12630/16385
# 查看修改后的结果。
$ hexdump /pg/d1/base/12630/16385 | head -n 2
0000000 00 00 00 00 48 22 02 03 00 00 00 00 d0 03 c0 03
0000010 00 20 04 20 00 00 00 00 e0 9f 34 00 c0 9f 34 00
这里,虽然磁盘上的页面已经被修改,但页面已经缓存到了内存中的共享缓冲池里。因此从主库上仍然可以正常看到页面1中的结果。接下来重启主库,清空其Buffer。不幸的是,当关闭数据库或执行检查点时,内存中的页面会刷写会磁盘中,覆盖我们之前编辑的结果。因此,首先关闭数据库,重新执行编辑后再启动。
pg_ctl -D /pg/d1 stop
vi /pg/d1/base/12630/16385
pg_ctl -D /pg/d1 start
psql postgres -c 'select * from test;'
ERROR: invalid page in block 0 of relation base/12630/16385
psql postgres -c "select * from test where id = '10';"
ERROR: invalid page in block 0 of relation base/12630/16385
psql postgres -c "select * from test where ctid = '(0,1)';"
ERROR: invalid page in block 0 of relation base/12630/16385
$ psql postgres -c "select * from test where ctid = '(1,1)';"
id
-----
227
可以看到,修改后的0号页面无法被数据库识别出来,但未受影响的页面1仍然可以正常访问。
虽然主库上的查询因为页面损坏无法访问了,这时候在从库上执行类似的查询,都可以正常返回结果
$ psql -p5433 postgres -c 'select * from test limit 2;'
id
----
1
2
$ psql -p5433 postgres -c "select * from test where id = '10';"
id
----
10
$ psql -p5433 postgres -c "select * from test where ctid = '(0,1)';"
id
----
1
(1 row)
接下来,让我们打开zero_damaged_pages参数,现在在主库上的查询不报错了。取而代之的是一个警告,页面0中的数据蒸发掉了,返回的结果从第1页开始。
postgres=# set zero_damaged_pages = on ;
SET
postgres=# select * from test;
WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
id
-----
227
228
229
230
231
第0页确实已经被加载到内存缓冲池里了,而且页面里的数据被抹成了0。
create extension pg_buffercache ;
postgres=# select relblocknumber,isdirty,usagecount from pg_buffercache where relfilenode = 16385;
relblocknumber | isdirty | usagecount
----------------+---------+------------
0 | f | 5
1 | f | 3
2 | f | 2
zero_damaged_pages参数需要在实例级别进行配置:
# 确保该选项默认打开,并重启生效
psql postgres -c 'ALTER SYSTEM set zero_damaged_pages = on;'
pg_ctl -D /pg/d1 restart
psql postgres -c 'show zero_damaged_pages;'
zero_damaged_pages
--------------------
on
这里,通过配置zero_damaged_pages,能够让主库即使遇到坏块,也能继续应付一下。
垃圾页面被加载到内存并抹零之后,如果执行检查点,这个全零的页面是否又会被重新刷回磁盘覆盖原来的数据呢?这一点很重要,因为脏数据也是数据,起码有抢救的价值。为了一时的方便产生永久性无法挽回的损失,那肯定也是无法接受的。
psql postgres -c 'checkpoint;'
hexdump /pg/d1/base/12630/16385 | head -n 2
0000000 00 00 00 00 48 22 02 03 00 00 00 00 d0 03 c0 03
0000010 00 20 04 20 00 00 00 00 e0 9f 34 00 c0 9f 34 00
可以看到,无论是检查点还是重启,这个内存中的全零页面并不会强制替代磁盘上的损坏页面,留下了抢救的希望,又能保证线上的查询可以苟一下。甚好,甚好。这也符合文档中的描述:“抹零的页面并不会强制刷回磁盘”。
微妙的问题
就当我觉得实验完成,可以安心的把这个开关打开先对付一下时。突然又想起了一个微妙的事情,主库和从库上读到的数据是不一样的,这就很尴尬了。
psql -p5432 postgres -Atqc 'select * from test limit 2;'
2018-11-29 22:31:20.777 CST [24175] WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
227
228
psql -p5433 postgres -Atqc 'select * from test limit 2;'
1
2
更尴尬的是,在主库上是看不到第0页中的元组的,也就是说主库认为第0页中的记录都不存在,因此,即使表上存在主键约束,仍然可以插入同一个主键的记录:
# 表中已经有主键 id = 1的记录了,但是主库抹零了看不到!
psql postgres -c "INSERT INTO test VALUES(1);"
INSERT 0 1
# 从从库上查询,夭寿了!主键出现重复了!
psql postgres -p5433 -c "SELECT * FROM test;"
id
-----
1
2
3
...
555
1
# id列真的是主键……
$ psql postgres -p5433 -c "\d test;"
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+----------------------+-----------+----------+---------
id | character varying(8) | | not null |
Indexes:
"test_pkey" PRIMARY KEY, btree (id)
如果把这个从库Promote成新的主库,这个问题在从库上依然存在:一条主键能返回两条记录!真是夭寿啊……。
此外,还有一个有趣的问题,VACUUM会如何处理这样的零页面呢?
# 对表进行清理
psql postgres -c 'VACUUM VERBOSE;'
INFO: vacuuming "public.test"
2018-11-29 22:18:05.212 CST [23572] WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
2018-11-29 22:18:05.212 CST [23572] WARNING: relation "test" page 0 is uninitialized --- fixing
WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
WARNING: relation "test" page 0 is uninitialized --- fixing
INFO: index "test_pkey" now contains 329 row versions in 5 pages
DETAIL: 0 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
VACUUM把这个页面“修好了”?但杯具的是,VACUUM自作主张修好了脏数据页,并不一定是一件好事…。因为当VACUUM完成修复时,这个页面就被视作一个普通的页面了,就会在CHECKPOINT时被刷写回磁盘中……,从而覆盖了原始的脏数据。如果这种修复并不是你想要的结果,那么数据就有可能会丢失。
总结
- 复制,备份是应对硬件损坏的最佳办法。
- 当出现数据页面损坏时,可以找到对应的物理页面,进行比较,尝试修复。
- 当页面损坏导致查询无法进行时,参数
zero_damaged_pages可以临时用于跳过错误。 - 参数
zero_damaged_pages极其危险 - 打开抹零时,损坏页面会被加载至内存缓冲池中并抹零,且在检查点时不会覆盖磁盘原页面。
- 内存中被抹零的页面会被VACUUM尝试修复,修复后的页面会被检查点刷回磁盘,覆盖原页面。
- 抹零页面内的内容对数据库不可见,因此可能会出现违反约束的情况出现。