PgSQL变更数据捕获
在实际生产中,我们经常需要把数据库的状态同步到其他地方去,例如同步到数据仓库进行分析,同步到消息队列供下游消费,同步到缓存以加速查询。总的来说,搬运状态有两大类方法:ETL与CDC。
前驱知识
CDC与ETL
数据库在本质上是一个状态集合,任何对数据库的变更(增删改)本质上都是对状态的修改。
在实际生产中,我们经常需要把数据库的状态同步到其他地方去,例如同步到数据仓库进行分析,同步到消息队列供下游消费,同步到缓存以加速查询。总的来说,搬运状态有两大类方法:ETL与CDC。
-
ETL(ExtractTransformLoad)着眼于状态本身,用定时批量轮询的方式拉取状态本身。
-
CDC(ChangeDataCapture)则着眼于变更,以流式的方式持续收集状态变化事件(变更)。
ETL大家都耳熟能详,每天批量跑ETL任务,从生产OLTP数据库 拉取(E) , 转换(T) 格式, 导入(L) 数仓,在此不赘述。相比ETL而言,CDC算是个新鲜玩意,随着流计算的崛起也越来越多地进入人们的视线。
变更数据捕获(change data capture, CDC)是一种观察写入数据库的所有数据变更,并将其提取并转换为可以复制到其他系统中的形式的过程。 CDC很有意思,特别是当变更能在被写入数据库后立刻用于后续的流处理时。
例如用户可以捕获数据库中的变更,并不断将相同的变更应用至搜索索引(e.g elasticsearch)。如果变更日志以相同的顺序应用,则可以预期的是,搜索索引中的数据与数据库中的数据是匹配的。同理,这些变更也可以应用于后台刷新缓存(redis),送往消息队列(Kafka),导入数据仓库(EventSourcing,存储不可变的事实事件记录而不是每天取快照),收集统计数据与监控(Prometheus),等等等等。在这种意义下,外部索引,缓存,数仓都成为了PostgreSQL在逻辑上的从库,这些衍生数据系统都成为了变更流的消费者,而PostgreSQL成为了整个数据系统的主库。在这种架构下,应用只需要操心怎样把数据写入数据库,剩下的事情交给CDC即可。系统设计可以得到极大地简化:所有的数据组件都能够自动与主库在逻辑上保证(最终)一致。用户不用再为如何保证多个异构数据系统之间数据同步而焦头烂额了。
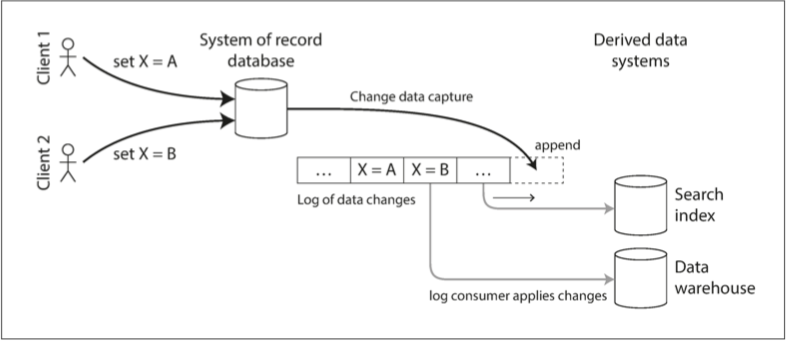
实际上PostgreSQL自10.0版本以来提供的逻辑复制(logical replication)功能,实质上就是一个CDC应用:从主库上提取变更事件流:INSERT, UPDATE, DELETE, TRUNCATE,并在另一个PostgreSQL主库实例上重放。如果这些增删改事件能够被解析出来,它们就可以用于任何感兴趣的消费者,而不仅仅局限于另一个PostgreSQL实例。
逻辑复制
想在传统关系型数据库上实施CDC并不容易,关系型数据库本身的预写式日志WAL 实际上就是数据库中变更事件的记录。因此从数据库中捕获变更,基本上可以认为等价于消费数据库产生的WAL日志/复制日志。(当然也有其他的变更捕获方式,例如在表上建立触发器,当变更发生时将变更记录写入另一张变更日志表,客户端不断tail这张日志表,当然也有一定的局限性)。
大多数数据库的复制日志的问题在于,它们一直被当做数据库的内部实现细节,而不是公开的API。客户端应该通过其数据模型和查询语言来查询数据库,而不是解析复制日志并尝试从中提取数据。许多数据库根本没有记录在案的获取变更日志的方式。因此捕获数据库中所有的变更然后将其复制到其他状态存储(搜索索引,缓存,数据仓库)中是相当困难的。
此外,仅有 数据库变更日志仍然是不够的。如果你拥有 全量 变更日志,当然可以通过重放日志来重建数据库的完整状态。但是在许多情况下保留全量历史WAL日志并不是可行的选择(例如磁盘空间与重放耗时的限制)。 例如,构建新的全文索引需要整个数据库的完整副本 —— 仅仅应用最新的变更日志是不够的,因为这样会丢失最近没有更新过的项目。因此如果你不能保留完整的历史日志,那么你至少需要包留一个一致的数据库快照,并保留从该快照开始的变更日志。
因此实施CDC,数据库至少需要提供以下功能:
-
获取数据库的变更日志(WAL),并解码成逻辑上的事件(对表的增删改而不是数据库的内部表示)
-
获取数据库的"一致性快照",从而订阅者可以从任意一个一致性状态开始订阅而不是数据库创建伊始。
-
保存消费者偏移量,以便跟踪订阅者的消费进度,及时清理回收不用的变更日志以免撑爆磁盘。
我们会发现,PostgreSQL在实现逻辑复制的同时,已经提供了一切CDC所需要的基础设施。
- 逻辑解码(Logical Decoding),用于从WAL日志中解析逻辑变更事件
- 复制协议(Replication Protocol):提供了消费者实时订阅(甚至同步订阅)数据库变更的机制
- 快照导出(export snapshot):允许导出数据库的一致性快照(
pg_export_snapshot) - 复制槽(Replication Slot),用于保存消费者偏移量,跟踪订阅者进度。
因此,在PostgreSQL上实施CDC最为直观优雅的方式,就是按照PostgreSQL的复制协议编写一个"逻辑从库" ,从数据库中实时地,流式地接受逻辑解码后的变更事件,完成自己定义的处理逻辑,并及时向数据库汇报自己的消息消费进度。就像使用Kafka一样。在这里CDC客户端可以将自己伪装成一个PostgreSQL的从库,从而不断地实时从PostgreSQL主库中接收逻辑解码后的变更内容。同时CDC客户端还可以通过PostgreSQL提供的复制槽(Replication Slot)机制来保存自己的消费者偏移量,即消费进度,实现类似消息队列一至少次的保证,保证不错过变更数据。(客户端自己记录消费者偏移量跳过重复记录,即可实现"恰好一次 “的保证 )
逻辑解码
在开始进一步的讨论之前,让我们先来看一看期待的输出结果到底是什么样子。
PostgreSQL的变更事件以二进制内部表示形式保存在预写式日志(WAL)中,使用其自带的pg_waldump工具可以解析出来一些人类可读的信息:
rmgr: Btree len (rec/tot): 64/ 64, tx: 1342, lsn: 2D/AAFFC9F0, prev 2D/AAFFC810, desc: INSERT_LEAF off 126, blkref #0: rel 1663/3101882/3105398 blk 4
rmgr: Heap len (rec/tot): 485/ 485, tx: 1342, lsn: 2D/AAFFCA30, prev 2D/AAFFC9F0, desc: INSERT off 10, blkref #0: rel 1663/3101882/3105391 blk 139
WAL日志里包含了完整权威的变更事件记录,但这种记录格式过于底层。用户并不会对磁盘上某个数据页里的二进制变更(文件A页面B偏移量C追加写入二进制数据D)感兴趣,他们感兴趣的是某张表中增删改了哪些行哪些字段。逻辑解码就是将物理变更记录翻译为用户期望的逻辑变更事件的机制(例如表A上的增删改事件)。
例如用户可能期望的是,能够解码出等价的SQL语句
INSERT INTO public.test (id, data) VALUES (14, 'hoho');
或者最为通用的JSON结构(这里以JSON格式记录了一条UPDATE事件)
{
"change": [
{
"kind": "update",
"schema": "public",
"table": "test",
"columnnames": ["id", "data" ],
"columntypes": [ "integer", "text" ],
"columnvalues": [ 1, "hoho"],
"oldkeys": { "keynames": [ "id"],
"keytypes": ["integer" ],
"keyvalues": [1]
}
}
]
}
当然也可以是更为紧凑高效严格的Protobuf格式,更为灵活的Avro格式,抑或是任何用户感兴趣的格式。
逻辑解码 所要解决的问题,就是将数据库内部二进制表示的变更事件,解码(Decoding)成为用户感兴趣的格式。之所以需要这样一个过程,是因为数据库内部表示是非常紧凑的,想要解读原始的二进制WAL日志,不仅仅需要WAL结构相关的知识,还需要系统目录(System Catalog),即元数据。没有元数据就无从得知用户可能感兴趣的模式名,表名,列名,只能解析出来的一系列数据库自己才能看懂的oid。
关于流复制协议,复制槽,事务快照等概念与功能,这里就不展开了,让我们进入动手环节。
快速开始
假设我们有一张用户表,我们希望捕获任何发生在它上面的变更,假设数据库发生了如下变更操作
下面会重复用到这几条命令
DROP TABLE IF EXISTS users;
CREATE TABLE users(id SERIAL PRIMARY KEY, name TEXT);
INSERT INTO users VALUES (100, 'Vonng');
INSERT INTO users VALUES (101, 'Xiao Wang');
DELETE FROM users WHERE id = 100;
UPDATE users SET name = 'Lao Wang' WHERE id = 101;
最终数据库的状态是:只有一条(101, 'Lao Wang')的记录。无论是曾经有一个名为Vonng的用户存在过的痕迹,抑或是隔壁老王也曾年轻过的事实,都随着对数据库的删改而烟消云散。我们希望这些事实不应随风而逝,需要被记录下来。
操作流程
通常来说,订阅变更需要以下几步操作:
- 选择一个一致性的数据库快照,作为订阅变更的起点。(创建一个复制槽)
- (数据库发生了一些变更)
- 读取这些变更,更新自己的的消费进度。
那么, 让我们先从最简单的办法开始,从PostgreSQL自带的的SQL接口开始
SQL接口
逻辑复制槽的增删查API:
TABLE pg_replication_slots; -- 查
pg_create_logical_replication_slot(slot_name name, plugin name) -- 增
pg_drop_replication_slot(slot_name name) -- 删
从逻辑复制槽中获取最新的变更数据:
pg_logical_slot_get_changes(slot_name name, ...) -- 消费掉
pg_logical_slot_peek_changes(slot_name name, ...) -- 只查看不消费
在正式开始前,还需要对数据库参数做一些修改,修改wal_level = logical,这样在WAL日志中的信息才能足够用于逻辑解码。
-- 创建一个复制槽test_slot,使用系统自带的测试解码插件test_decoding,解码插件会在后面介绍
SELECT * FROM pg_create_logical_replication_slot('test_slot', 'test_decoding');
-- 重放上面的建表与增删改操作
-- DROP TABLE | CREATE TABLE | INSERT 1 | INSERT 1 | DELETE 1 | UPDATE 1
-- 读取复制槽test_slot中未消费的最新的变更事件流
SELECT * FROM pg_logical_slot_get_changes('test_slot', NULL, NULL);
lsn | xid | data
-----------+-----+--------------------------------------------------------------------
0/167C7E8 | 569 | BEGIN 569
0/169F6F8 | 569 | COMMIT 569
0/169F6F8 | 570 | BEGIN 570
0/169F6F8 | 570 | table public.users: INSERT: id[integer]:100 name[text]:'Vonng'
0/169F810 | 570 | COMMIT 570
0/169F810 | 571 | BEGIN 571
0/169F810 | 571 | table public.users: INSERT: id[integer]:101 name[text]:'Xiao Wang'
0/169F8C8 | 571 | COMMIT 571
0/169F8C8 | 572 | BEGIN 572
0/169F8C8 | 572 | table public.users: DELETE: id[integer]:100
0/169F938 | 572 | COMMIT 572
0/169F970 | 573 | BEGIN 573
0/169F970 | 573 | table public.users: UPDATE: id[integer]:101 name[text]:'Lao Wang'
0/169F9F0 | 573 | COMMIT 573
-- 清理掉创建的复制槽
SELECT pg_drop_replication_slot('test_slot');
这里,我们可以看到一系列被触发的事件,其中每个事务的开始与提交都会触发一个事件。因为目前逻辑解码机制不支持DDL变更,因此CREATE TABLE与DROP TABLE并没有出现在事件流中,只能看到空荡荡的BEGIN+COMMIT。另一点需要注意的是,只有成功提交的事务才会产生逻辑解码变更事件。也就是说用户不用担心收到并处理了很多行变更消息之后,最后发现事务回滚了,还需要担心怎么通知消费者去会跟变更。
通过SQL接口,用户已经能够拉取最新的变更了。这也就意味着任何有着PostgreSQL驱动的语言都可以通过这种方式从数据库中捕获最新的变更。当然这种方式实话说还是略过于土鳖。更好的方式是利用PostgreSQL的复制协议直接从数据库中订阅变更数据流。当然相比使用SQL接口,这也需要更多的工作。
使用客户端接收变更
在编写自己的CDC客户端之前,让我们先来试用一下官方自带的CDC客户端样例——pg_recvlogical。与pg_receivewal类似,不过它接收的是逻辑解码后的变更,下面是一个具体的例子:
# 启动一个CDC客户端,连接数据库postgres,创建名为test_slot的槽,使用test_decoding解码插件,标准输出
pg_recvlogical \
-d postgres \
--create-slot --if-not-exists --slot=test_slot \
--plugin=test_decoding \
--start -f -
# 开启另一个会话,重放上面的建表与增删改操作
# DROP TABLE | CREATE TABLE | INSERT 1 | INSERT 1 | DELETE 1 | UPDATE 1
# pg_recvlogical输出结果
BEGIN 585
COMMIT 585
BEGIN 586
table public.users: INSERT: id[integer]:100 name[text]:'Vonng'
COMMIT 586
BEGIN 587
table public.users: INSERT: id[integer]:101 name[text]:'Xiao Wang'
COMMIT 587
BEGIN 588
table public.users: DELETE: id[integer]:100
COMMIT 588
BEGIN 589
table public.users: UPDATE: id[integer]:101 name[text]:'Lao Wang'
COMMIT 589
# 清理:删除创建的复制槽
pg_recvlogical -d postgres --drop-slot --slot=test_slot
上面的例子中,主要的变更事件包括事务的开始与结束,以及数据行的增删改。这里默认的test_decoding插件的输出格式为:
BEGIN {事务标识}
table {模式名}.{表名} {命令INSERT|UPDATE|DELETE} {列名}[{类型}]:{取值} ...
COMMIT {事务标识}
实际上,PostgreSQL的逻辑解码是这样工作的,每当特定的事件发生(表的Truncate,行级别的增删改,事务开始与提交),PostgreSQL都会调用一系列的钩子函数。所谓的逻辑解码输出插件(Logical Decoding Output Plugin),就是这样一组回调函数的集合。它们接受二进制内部表示的变更事件作为输入,查阅一些系统目录,将二进制数据翻译成为用户感兴趣的结果。
逻辑解码输出插件
除了PostgreSQL自带的"用于测试"的逻辑解码插件:test_decoding 之外,还有很多现成的输出插件,例如:
- JSON格式输出插件:
wal2json - SQL格式输出插件:
decoder_raw - Protobuf输出插件:
decoderbufs
当然还有PostgreSQL自带逻辑复制所使用的解码插件:pgoutput,其消息格式文档地址。
安装这些插件非常简单,有一些插件(例如wal2json)可以直接从官方二进制源轻松安装。
yum install wal2json11
apt install postgresql-11-wal2json
或者如果没有二进制包,也可以自己下载编译。只需要确保pg_config已经在你的PATH中,然后执行make & sudo make install两板斧即可。以输出SQL格式的decoder_raw插件为例:
git clone https://github.com/michaelpq/pg_plugins && cd pg_plugins/decoder_raw
make && sudo make install
使用wal2json接收同样的变更
pg_recvlogical -d postgres --drop-slot --slot=test_slot
pg_recvlogical -d postgres --create-slot --if-not-exists --slot=test_slot \
--plugin=wal2json --start -f -
结果为:
{"change":[]}
{"change":[{"kind":"insert","schema":"public","table":"users","columnnames":["id","name"],"columntypes":["integer","text"],"columnvalues":[100,"Vonng"]}]}
{"change":[{"kind":"insert","schema":"public","table":"users","columnnames":["id","name"],"columntypes":["integer","text"],"columnvalues":[101,"Xiao Wang"]}]}
{"change":[{"kind":"delete","schema":"public","table":"users","oldkeys":{"keynames":["id"],"keytypes":["integer"],"keyvalues":[100]}}]}
{"change":[{"kind":"update","schema":"public","table":"users","columnnames":["id","name"],"columntypes":["integer","text"],"columnvalues":[101,"Lao Wang"],"oldkeys":{"keynames":["id"],"keytypes":["integer"],"keyvalues":[101]}}]}
而使用decoder_raw获取SQL格式的输出
pg_recvlogical -d postgres --drop-slot --slot=test_slot
pg_recvlogical -d postgres --create-slot --if-not-exists --slot=test_slot \
--plugin=decoder_raw --start -f -
结果为:
INSERT INTO public.users (id, name) VALUES (100, 'Vonng');
INSERT INTO public.users (id, name) VALUES (101, 'Xiao Wang');
DELETE FROM public.users WHERE id = 100;
UPDATE public.users SET id = 101, name = 'Lao Wang' WHERE id = 101;
decoder_raw可以用于抽取SQL形式表示的状态变更,将这些抽取得到的SQL语句在同样的基础状态上重放,即可得到相同的结果。PostgreSQL就是使用这样的机制实现逻辑复制的。
一个典型的应用场景就是数据库不停机迁移。在传统不停机迁移模式(双写,改读,改写)中,第三步改写完成后是无法快速回滚的,因为写入流量在切换至新主库后如果发现有问题想立刻回滚,老主库上会丢失一些数据。这时候就可以使用decoder_raw提取主库上的最新变更,并通过一行简单的Bash命令,将新主库上的变更实时同步到旧主库。保证迁移过程中任何时刻都可以快速回滚至老主库。
pg_recvlogical -d <new_master_url> --slot=test_slot --plugin=decoder_raw --start -f - |
psql <old_master_url>
另一个有趣的场景是UNDO LOG。PostgreSQL的故障恢复是基于REDO LOG的,通过重放WAL会到历史上的任意时间点。在数据库模式不发生变化的情况下,如果只是单纯的表内容增删改出现了失误,完全可以利用类似decoder_raw的方式反向生成UNDO日志。提高此类故障恢复的速度。
最后,输出插件可以将变更事件格式化为各种各样的形式。解码输出为Redis的kv操作,或者仅仅抽取一些关键字段用于更新统计数据或者构建外部索引,有着很大的想象空间。
编写自定义的逻辑解码输出插件并不复杂,可以参阅这篇官方文档。毕竟逻辑解码输出插件本质上只是一个拼字符串的回调函数集合。在官方样例的基础上稍作修改,即可轻松实现一个你自己的逻辑解码输出插件。
CDC客户端
PostgreSQL自带了一个名为pg_recvlogical的客户端应用,可以将逻辑变更的事件流写至标准输出。但并不是所有的消费者都可以或者愿意使用Unix Pipe来完成所有工作的。此外,根据端到端原则,使用pg_recvlogical将变更数据流落盘并不意味着消费者已经拿到并确认了该消息,只有消费者自己亲自向数据库确认才可以做到这一点。
编写PostgreSQL的CDC客户端程序,本质上是实现了一个"猴版”数据库从库。客户端向数据库建立一条复制连接(Replication Connection) ,将自己伪装成一个从库:从主库获取解码后的变更消息流,并周期性地向主库汇报自己的消费进度(落盘进度,刷盘进度,应用进度)。
复制连接
复制连接,顾名思义就是用于复制(Replication) 的特殊连接。当与PostgreSQL服务器建立连接时,如果连接参数中提供了replication=database|on|yes|1,就会建立一条复制连接,而不是普通连接。复制连接可以执行一些特殊的命令,例如IDENTIFY_SYSTEM, TIMELINE_HISTORY, CREATE_REPLICATION_SLOT, START_REPLICATION, BASE_BACKUP, 在逻辑复制的情况下,还可以执行一些简单的SQL查询。具体细节可以参考PostgreSQL官方文档中前后端协议一章:https://www.postgresql.org/docs/current/protocol-replication.html
譬如,下面这条命令就会建立一条复制连接:
$ psql 'postgres://localhost:5432/postgres?replication=on&application_name=mocker'
从系统视图pg_stat_replication可以看到主库识别到了一个新的"从库”
vonng=# table pg_stat_replication ;
-[ RECORD 1 ]----+-----------------------------
pid | 7218
usesysid | 10
usename | vonng
application_name | mocker
client_addr | ::1
client_hostname |
client_port | 53420
编写自定义逻辑
无论是JDBC还是Go语言的PostgreSQL驱动,都提供了相应的基础设施,用于处理复制连接。
这里让我们用Go语言编写一个简单的CDC客户端,样例使用了jackc/pgx,一个很不错的Go语言编写的PostgreSQL驱动。这里的代码只是作为概念演示,因此忽略掉了错误处理,非常Naive。将下面的代码保存为main.go,执行go run main.go即可执行。
默认的三个参数分别为数据库连接串,逻辑解码输出插件的名称,以及复制槽的名称。默认值为:
dsn := "postgres://localhost:5432/postgres?application_name=cdc"
plugin := "test_decoding"
slot := "test_slot"
go run main.go postgres:///postgres?application_name=cdc test_decoding test_slot
代码如下所示:
package main
import (
"log"
"os"
"time"
"context"
"github.com/jackc/pgx"
)
type Subscriber struct {
URL string
Slot string
Plugin string
Conn *pgx.ReplicationConn
LSN uint64
}
// Connect 会建立到服务器的复制连接,区别在于自动添加了replication=on|1|yes|dbname参数
func (s *Subscriber) Connect() {
connConfig, _ := pgx.ParseURI(s.URL)
s.Conn, _ = pgx.ReplicationConnect(connConfig)
}
// ReportProgress 会向主库汇报写盘,刷盘,应用的进度坐标(消费者偏移量)
func (s *Subscriber) ReportProgress() {
status, _ := pgx.NewStandbyStatus(s.LSN)
s.Conn.SendStandbyStatus(status)
}
// CreateReplicationSlot 会创建逻辑复制槽,并使用给定的解码插件
func (s *Subscriber) CreateReplicationSlot() {
if consistPoint, snapshotName, err := s.Conn.CreateReplicationSlotEx(s.Slot, s.Plugin); err != nil {
log.Fatalf("fail to create replication slot: %s", err.Error())
} else {
log.Printf("create replication slot %s with plugin %s : consist snapshot: %s, snapshot name: %s",
s.Slot, s.Plugin, consistPoint, snapshotName)
s.LSN, _ = pgx.ParseLSN(consistPoint)
}
}
// StartReplication 会启动逻辑复制(服务器会开始发送事件消息)
func (s *Subscriber) StartReplication() {
if err := s.Conn.StartReplication(s.Slot, 0, -1); err != nil {
log.Fatalf("fail to start replication on slot %s : %s", s.Slot, err.Error())
}
}
// DropReplicationSlot 会使用临时普通连接删除复制槽(如果存在),注意如果复制连接正在使用这个槽是没法删的。
func (s *Subscriber) DropReplicationSlot() {
connConfig, _ := pgx.ParseURI(s.URL)
conn, _ := pgx.Connect(connConfig)
var slotExists bool
conn.QueryRow(`SELECT EXISTS(SELECT 1 FROM pg_replication_slots WHERE slot_name = $1)`, s.Slot).Scan(&slotExists)
if slotExists {
if s.Conn != nil {
s.Conn.Close()
}
conn.Exec("SELECT pg_drop_replication_slot($1)", s.Slot)
log.Printf("drop replication slot %s", s.Slot)
}
}
// Subscribe 开始订阅变更事件,主消息循环
func (s *Subscriber) Subscribe() {
var message *pgx.ReplicationMessage
for {
// 等待一条消息, 消息有可能是真的消息,也可能只是心跳包
message, _ = s.Conn.WaitForReplicationMessage(context.Background())
if message.WalMessage != nil {
DoSomething(message.WalMessage) // 如果是真的消息就消费它
if message.WalMessage.WalStart > s.LSN { // 消费完后更新消费进度,并向主库汇报
s.LSN = message.WalMessage.WalStart + uint64(len(message.WalMessage.WalData))
s.ReportProgress()
}
}
// 如果是心跳包消息,按照协议,需要检查服务器是否要求回送进度。
if message.ServerHeartbeat != nil && message.ServerHeartbeat.ReplyRequested == 1 {
s.ReportProgress() // 如果服务器心跳包要求回送进度,则汇报进度
}
}
}
// 实际消费消息的函数,这里只是把消息打印出来,也可以写入Redis,写入Kafka,更新统计信息,发送邮件等
func DoSomething(message *pgx.WalMessage) {
log.Printf("[LSN] %s [Payload] %s",
pgx.FormatLSN(message.WalStart), string(message.WalData))
}
// 如果使用JSON解码插件,这里是用于Decode的Schema
type Payload struct {
Change []struct {
Kind string `json:"kind"`
Schema string `json:"schema"`
Table string `json:"table"`
ColumnNames []string `json:"columnnames"`
ColumnTypes []string `json:"columntypes"`
ColumnValues []interface{} `json:"columnvalues"`
OldKeys struct {
KeyNames []string `json:"keynames"`
KeyTypes []string `json:"keytypes"`
KeyValues []interface{} `json:"keyvalues"`
} `json:"oldkeys"`
} `json:"change"`
}
func main() {
dsn := "postgres://localhost:5432/postgres?application_name=cdc"
plugin := "test_decoding"
slot := "test_slot"
if len(os.Args) > 1 {
dsn = os.Args[1]
}
if len(os.Args) > 2 {
plugin = os.Args[2]
}
if len(os.Args) > 3 {
slot = os.Args[3]
}
subscriber := &Subscriber{
URL: dsn,
Slot: slot,
Plugin: plugin,
} // 创建新的CDC客户端
subscriber.DropReplicationSlot() // 如果存在,清理掉遗留的Slot
subscriber.Connect() // 建立复制连接
defer subscriber.DropReplicationSlot() // 程序中止前清理掉复制槽
subscriber.CreateReplicationSlot() // 创建复制槽
subscriber.StartReplication() // 开始接收变更流
go func() {
for {
time.Sleep(5 * time.Second)
subscriber.ReportProgress()
}
}() // 协程2每5秒地向主库汇报进度
subscriber.Subscribe() // 主消息循环
}
在另一个数据库会话中再次执行上面的变更,可以看到客户端及时地接收到了变更的内容。这里客户端只是简单地将其打印了出来,实际生产中,客户端可以完成任何工作,比如写入Kafka,写入Redis,写入磁盘日志,或者只是更新内存中的统计数据并暴露给监控系统。甚至,还可以通过配置同步提交,确保所有系统中的变更能够时刻保证严格同步(当然相比默认的异步模式比较影响性能就是了)。
对于PostgreSQL主库而言,这看起来就像是另一个从库。
postgres=# table pg_stat_replication; -- 查看当前从库
-[ RECORD 1 ]----+------------------------------
pid | 14082
usesysid | 10
usename | vonng
application_name | cdc
client_addr | 10.1.1.95
client_hostname |
client_port | 56609
backend_start | 2019-05-19 13:14:34.606014+08
backend_xmin |
state | streaming
sent_lsn | 2D/AB269AB8 -- 服务端已经发送的消息坐标
write_lsn | 2D/AB269AB8 -- 客户端已经执行完写入的消息坐标
flush_lsn | 2D/AB269AB8 -- 客户端已经刷盘的消息坐标(不会丢失)
replay_lsn | 2D/AB269AB8 -- 客户端已经应用的消息坐标(已经生效)
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
postgres=# table pg_replication_slots; -- 查看当前复制槽
-[ RECORD 1 ]-------+------------
slot_name | test
plugin | decoder_raw
slot_type | logical
datoid | 13382
database | postgres
temporary | f
active | t
active_pid | 14082
xmin |
catalog_xmin | 1371
restart_lsn | 2D/AB269A80 -- 下次客户端重连时将从这里开始重放
confirmed_flush_lsn | 2D/AB269AB8 -- 客户端确认完成的消息进度
局限性
想要在生产环境中使用CDC,还需要考虑一些其他的问题。略有遗憾的是,在PostgreSQL CDC的天空上,还飘着两朵小乌云。
完备性
就目前而言,PostgreSQL的逻辑解码只提供了以下几个钩子:
LogicalDecodeStartupCB startup_cb;
LogicalDecodeBeginCB begin_cb;
LogicalDecodeChangeCB change_cb;
LogicalDecodeTruncateCB truncate_cb;
LogicalDecodeCommitCB commit_cb;
LogicalDecodeMessageCB message_cb;
LogicalDecodeFilterByOriginCB filter_by_origin_cb;
LogicalDecodeShutdownCB shutdown_cb;
其中比较重要,也是必须提供的是三个回调函数:begin:事务开始,change:行级别增删改事件,commit:事务提交 。遗憾的是,并不是所有的事件都有相应的钩子,例如数据库的模式变更,Sequence的取值变化,以及特殊的大对象操作。
通常来说,这并不是一个大问题,因为用户感兴趣的往往只是表记录而不是表结构的增删改。而且,如果使用诸如JSON,Avro等灵活格式作为解码目标格式,即使表结构发生变化,也不会有什么大问题。
但是尝试从目前的变更事件流生成完备的UNDO Log是不可能的,因为目前模式的变更DDL并不会记录在逻辑解码的输出中。好消息是未来会有越来越多的钩子与支持,因此这个问题是可解的。
同步提交
需要注意的一点是,有一些输出插件会无视Begin与Commit消息。这两条消息本身也是数据库变更日志的一部分,如果输出插件忽略了这些消息,那么CDC客户端在汇报消费进度时就可能会出现偏差(落后一条消息的偏移量)。在一些边界条件下可能会触发一些问题:例如写入极少的数据库启用同步提交时,主库迟迟等不到从库确认最后的Commit消息而卡住)
故障切换
理想很美好,现实很骨感。当一切正常时,CDC工作流工作的很好。但当数据库出现故障,或者出现故障转移时,事情就变得比较棘手了。
恰好一次保证
另外一个使用PostgreSQL CDC的问题是消息队列中经典的恰好一次问题。
PostgreSQL的逻辑复制实际上提供的是至少一次保证,因为消费者偏移量的值会在检查点的时候保存。如果PostgreSQL主库宕机,那么重新发送变更事件的起点,不一定恰好等于上次订阅者已经消费的位置。因此有可能会发送重复的消息。
解决方法是:逻辑复制的消费者也需要记录自己的消费者偏移量,以便跳过重复的消息,实现真正的恰好一次 消息传达保证。这并不是一个真正的问题,只是任何试图自行实现CDC客户端的人都应当注意这一点。
Failover Slot
对目前PostgreSQL的CDC来说,Failover Slot是最大的难点与痛点。逻辑复制依赖复制槽,因为复制槽持有着消费者的状态,记录着消费者的消费进度,因而数据库不会将消费者还没处理的消息清理掉。
但以目前的实现而言,复制槽只能用在主库上,且复制槽本身并不会被复制到从库上。因此当主库进行Failover时,消费者偏移量就会丢失。如果在新的主库承接任何写入之前没有重新建好逻辑复制槽,就有可能会丢失一些数据。对于非常严格的场景,使用这个功能时仍然需要谨慎。
这个问题计划将于下一个大版本(13)解决,Failover Slot的Patch计划于版本13(2020)年合入主线版本。
在那之前,如果希望在生产中使用CDC,那么务必要针对故障切换进行充分地测试。例如使用CDC的情况下,Failover的操作就需要有所变更:核心思想是运维与DBA必须手工完成复制槽的复制工作。在Failover前可以在原主库上启用同步提交,暂停写入流量并在新主库上使用脚本复制复制原主库的槽,并在新主库上创建同样的复制槽,从而手工完成复制槽的Failover。对于紧急故障切换,即原主库无法访问,需要立即切换的情况,也可以在事后使用PITR重新将缺失的变更恢复出来。
小结一下:CDC的功能机制已经达到了生产应用的要求,但可靠性的机制还略有欠缺,这个问题可以等待下一个主线版本,或通过审慎地手工操作解决,当然激进的用户也可以自行拉取该补丁提前尝鲜。