数据库集群管理概念与实体命名规范
数据库集群管理概念与实体命名规范
名之则可言也,言之则可行也。
概念及其命名是非常重要的东西,命名风格体现了工程师对系统架构的认知。定义不清的概念将导致沟通困惑,随意设定的名称将产生意想不到的额外负担。因此需要审慎地设计。
TL;DR
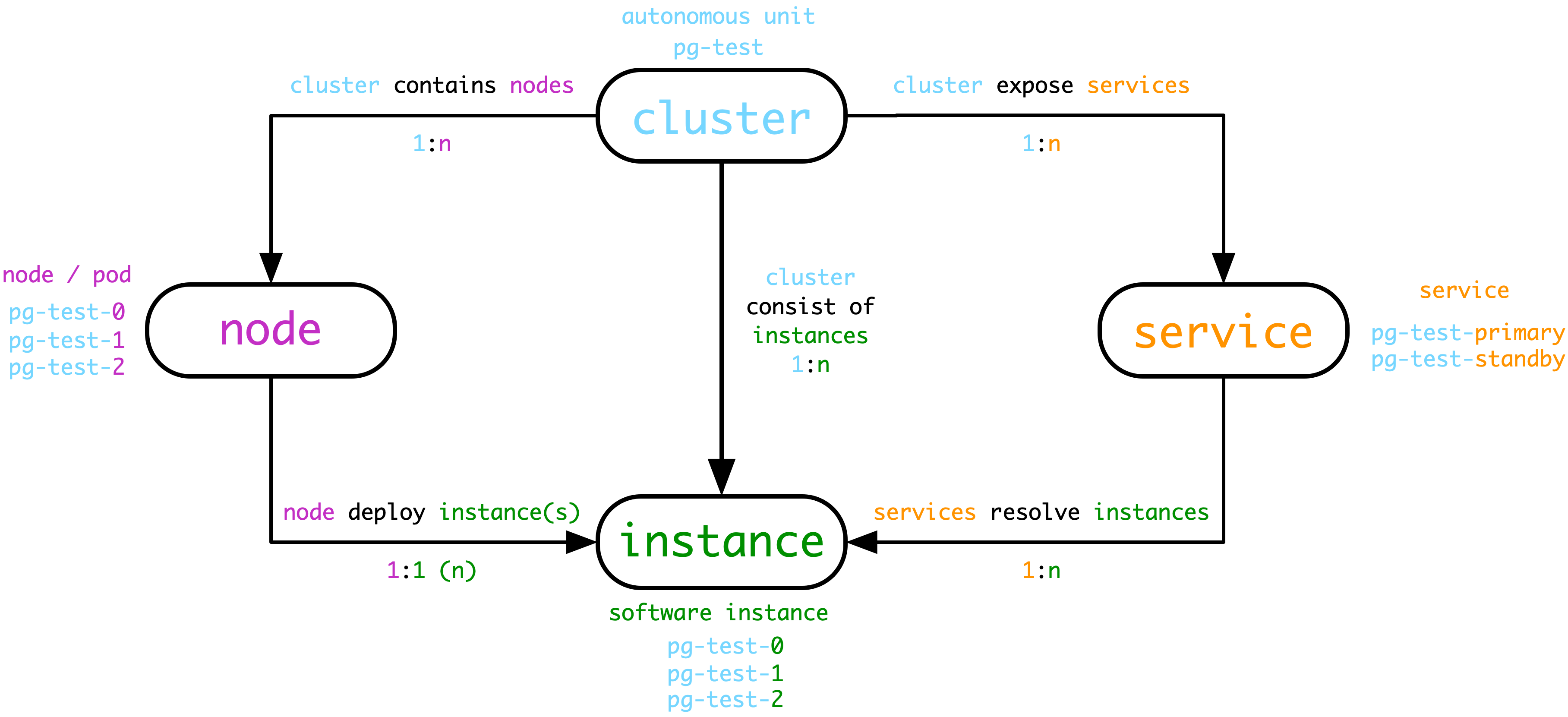
- **集群(Cluster)**是基本自治单元,由用户指定唯一标识,表达业务含义,作为顶层命名空间。
- 集群在硬件层面上包含一系列的节点(Node),即物理机,虚机(或Pod),可以通过IP唯一标识。
- 集群在软件层面上包含一系列的实例(Instance),即软件服务器,可以通过IP:Port唯一标识。
- 集群在服务层面上包含一系列的服务(Service),即可访问的域名与端点,可以通过域名唯一标识。
- Cluster命名可以使用任意满足DNS域名规范的名称,但不能带点([a-zA-Z0-9-]+)。
- Node/Pod命名采用Cluster名称前缀,后接
-连接一个从0开始分配的序号,(与k8s保持一致) - 实例命名通常与Node保持一致,即
${cluster}-${seq}的方式,这种方式隐含着节点与实例1:1部署的假设。如果这个假设不成立,则可以采用独立于节点的序号,但保持同样的命名规则。 - Service命名采用Cluster名称前缀,后接
-连接服务具体内容,如primary,standby
以上图为例,用于测试的数据库集群名为“pg-test”,该集群由一主两从三个数据库服务器实例组成,部署在集群所属的三个节点上。pg-test集群集群对外提供两种服务,读写服务pg-test-primary与只读副本服务pg-test-standby。
基本概念
在Postgres集群管理中,有如下概念:
集群(Cluster)
集群是基本的自治业务单元,这意味着集群能够作为一个整体组织对外提供服务。类似于k8s中Deployment的概念。注意这里的集群是软件层面的概念,不要与PG Cluster(数据库集簇,即包含多个PG Database实例的单个PG Server Instance)或Node Cluster(机器集群)混淆。
集群是管理的基本单位之一,是用于统合各类资源的组织单位。例如一个PG集群可能包括:
- 三个物理机器节点
- 一个主库实例,对外提供数据库读写服务。
- 两个从库实例,对外提供数据库只读副本服务。
- 两个对外暴露的服务:读写服务,只读副本服务。
每个集群都有用户根据业务需求定义的唯一标识符,本例中定义了一个名为pg-test的数据库集群。
节点(Node)
节点是对硬件资源的一种抽象,通常指代一台工作机器,无论是物理机(bare metal)还是虚拟机(vm),或者是k8s中的Pod。这里注意k8s中Node是硬件资源的抽象,但在实际管理使用上,是k8s中的Pod而不是Node更类似于这里Node概念。总之,节点的关键要素是:
- 节点是硬件资源的抽象,可以运行一系列的软件服务
- 节点可以使用IP地址作为唯一标识符
尽管可以使用lan_ip地址作为节点唯一标识符,但为了便于管理,节点应当拥有一个人类可读的充满意义的名称作为节点的Hostname,作为另一个常用的节点唯一标识。
服务(Service)
服务是对软件服务(例如Postgres,Redis)的一种命名抽象(named abastraction)。服务可以有各种各样的实现,但其的关键要素在于:
- 可以寻址访问的服务名称,用于对外提供接入,例如:
- 一个DNS域名(
pg-test-primary) - 一个Nginx/Haproxy Endpoint
- 一个DNS域名(
- 服务流量路由解析与负载均衡机制,用于决定哪个实例负责处理请求,例如:
- DNS L7:DNS解析记录
- HTTP Proxy:Nginx/Ingress L7:Nginx Upstream配置
- TCP Proxy:Haproxy L4:Haproxy Backend配置
- Kubernetes:Ingress:Pod Selector 选择器。
同一个数据集簇中通常包括主库与从库,两者分别提供读写服务(primary)和只读副本服务(standby)。
实例(Instance)
实例指带一个具体的数据库服务器,它可以是单个进程,也可能是共享命运的一组进程,也可以是一个Pod中几个紧密关联的容器。实例的关键要素在于:
- 可以通过IP:Port唯一标识
- 具有处理请求的能力
例如,我们可以把一个Postgres进程,为之服务的独占Pgbouncer连接池,PgExporter监控组件,高可用组件,管理Agent看作一个提供服务的整体,视为一个数据库实例。
实例隶属于集群,每个实例在集群范围内都有着自己的唯一标识用于区分。
实例由服务负责解析,实例提供被寻址的能力,而Service将请求流量解析到具体的实例组上。
命名规则
一个对象可以有很多组 标签(Tag) 与 元数据(Metadata/Annotation) ,但通常只能有一个名字。
管理数据库和软件,其实与管理子女或者宠物类似,都是需要花心思去照顾的。而起名字就是其中非常重要的一项工作。肆意的名字(例如 XÆA-12,NULL,史珍香)很可能会引入不必要的麻烦(额外复杂度),而设计得当的名字则可能会有意想不到的效果。
总的来说,对象起名应当遵循一些原则:
-
简洁直白,人类可读:名字是给人看的,因此要好记,便于使用。
-
体现功能,反映特征:名字需要反映对象的关键特征
-
独一无二,唯一标识:名字在命名空间内,自己的类目下应当是独一无二,可以惟一标识寻址的。
-
不要把太多无关的东西塞到名字里去:在名字中嵌入很多重要元数据是一个很有吸引力的想法,但维护起来会非常痛苦,例如反例:
pg:user:profile:10.11.12.13:5432:replica:13。
集群命名
集群名称,其实类似于命名空间的作用。所有隶属本集群的资源,都会使用该命名空间。
集群命名的形式,建议采用符合DNS标准 RFC1034 的命名规则,以免给后续改造埋坑。例如哪一天想要搬到云上去,发现以前用的名字不支持,那就要再改一遍名,成本巨大。
我认为更好的方式是采用更为严格的限制:集群的名称不应该包括点(dot)。应当仅使用小写字母,数字,以及减号连字符(hyphen)-。这样,集群中的所有对象都可以使用这个名称作为前缀,用于各种各样的地方,而不用担心打破某些约束。即集群命名规则为:
cluster_name := [a-z][a-z0-9-]*
之所以强调不要在集群名称中用点,是因为以前很流行一种命名方式,例如com.foo.bar。即由点分割的层次结构命名法。这种命名方式虽然简洁名快,但有一个问题,就是用户给出的名字里可能有任意多的层次,数量不可控。如果集群需要与外部系统交互,而外部系统对于命名有一些约束,那么这样的名字就会带来麻烦。一个最直观的例子是K8s中的Pod,Pod的命名规则中不允许出现.。
集群命名的内涵,建议采用-分隔的两段式,三段式名称,例如:
<集群类型>-<业务>-<业务线>
比如:pg-test-tt就表示tt 业务线下的test集群,类型为pg。pg-user-fin表示fin业务线下的user服务。当然,采集多段命名最好还是保持段数固定。
节点命名
节点命名建议采用与k8s Pod一致的命名规则,即
<cluster_name>-<seq>
Node的名称会在集群资源分配阶段确定下来,每个节点都会分配到一个序号${seq},从0开始的自增整型。这个与k8s中StatefulSet的命名规则保持一致,因此能够做到云上云下一致管理。
例如,集群pg-test有三个节点,那么这三个节点就可以命名为:
pg-test-0, pg-test-1和pg-test2。
节点的命名,在整个集群的生命周期中保持不变,便于监控与管理。
实例命名
对于数据库来说,通常都会采用独占式部署方式,一个实例占用整个机器节点。PG实例与Node是一一对应的关系,因此可以简单地采用Node的标识符作为Instance的标识符。例如,节点pg-test-1上的PG实例名即为:pg-test-1,以此类推。
采用独占部署的方式有很大优势,一个节点即一个实例,这样能最小化管理复杂度。混部的需求通常来自资源利用率的压力,但虚拟机或者云平台可以有效解决这种问题。通过vm或pod的抽象,即使是每个redis(1核1G)实例也可以有一个独占的节点环境。
作为一种约定,每个集群中的0号节点(Pod),会作为默认主库。因为它是初始化时第一个分配的节点。
服务命名
通常来说,数据库对外提供两种基础服务:primary 读写服务,与standby只读副本服务。
那么服务就可以采用一种简单的命名规则:
<cluster_name>-<service_name>
例如这里pg-test集群就包含两个服务:读写服务pg-test-primary与只读副本服务pg-test-standby。
还有一种流行的实例/节点命名规则:<cluster_name>-<service_role>-<sequence>,即把数据库的主从身份嵌入到实例名称中。这种命名方式有好处也有坏处。好处是管理的时候一眼就能看出来哪一个实例/节点是主库,哪些是从库。缺点是一但发生Failover,实例与节点的名称必须进行调整才能维持一执性,这就带来的额外的维护工作。此外,服务与节点实例是相对独立的概念,这种Embedding命名方式扭曲了这一关系,将实例唯一隶属至服务。但复杂的场景下这一假设可能并不满足。例如,集群可能有几种不同的服务划分方式,而不同的划分方式之间很可能会出现重叠。
- 可读从库(解析至包含主库在内的所有实例)
- 同步从库(解析至采用同步提交的备库)
- 延迟从库,备份实例(解析至特定具体实例)
因此,不要把服务角色嵌入实例名称,而是在服务中维护目标实例列表。
小结
命名属于相当经验性的知识,很少有地方会专门会讲这件事。这种“细节”其实往往能体现出命名者的一些经验水平来。
标识对象不仅仅可以通过ID和名称,还可以通过标签(Label)和选择器(Selector)。实际上这一种做法会更具有通用性和灵活性,本系列下一篇文章(也许)将会介绍数据库对象的标签设计与管理。