Pigsty 0.9 新功能介绍
v0.9 Highlight
Pigsty v0.9 已经于5月4日发布。v0.9是1.0GA前最后一个大版本,引入了一些有趣的新功能。
- 部署简化:一键安装模式
- 日志收集:基于Loki实时查阅分析数据库日志
- 命令行工具:Pigsty CLI,使用Go编写的趁手好用的命令行工具。
- Pigsty GUI:提供图形化的配置文件编辑生成功能(Beta)
- 飞升模式:集成默认PostgreSQL实例,Bootstrap,Datalet
- 界面改版:适配Grafana 7.5.4新特性,重制若干Dashboard。
易用性优化:一键安装
尽管Pigsty已经在封包,交付流程上进行了大量优化,不少用户仍然反馈安装遇到困难。所以在v0.9中,Pigsty针对安装部署又进行了再次改进。
总而言之,目前只要在装有全新CentOS 7.8的机器上使用root依次执行以下命令,即可完成单节点Pigsty的部署。
# 用免密ssh&sudo的用户执行,标准就是能成功执行: ssh 127.0.0.1 'sudo ls'
/bin/bash -c "$(curl -fsSL https://pigsty.cc/install)" # 下载源码
cd ~/pigsty # 进入源码目录
make pkg # 下载离线包(可选)
bin/ipconfig <ip_address> # 配置IP地址
make meta # 开始初始化
一键安装可能有些言过其实,但你确实可以把这几行命令粘成一条一键执行……
这里有一个产品思路上的变化,Pigsty将默认的演示环境从4节点改为了单节点。原来的四节点沙箱,能够很好对演示监控系统相关功能,演示集群管理、创建、扩缩容、高可用故障切换等。3个嫌少5个太多4个刚刚好。标准的4节点沙箱至少需要4核6G内存,尽管一台树莓派就够了,但还是有使用门槛:一个是大家的笔记本配置不一定都像我的那么好,不一定能在本机跑起来,再者就是一台虚拟机还是会省事很多。
所以单节点作为Pigsty的默认配置,有助于降低使用试用的门槛。正所谓门槛低一分,用户多十分。最后为了避免跑命令都有人不会,我还特意录了一个教学视频,完整的演示了如何在一台新弄的云虚拟机上部署Pigsty。
B站地址:https://www.bilibili.com/video/BV1nK4y1P7E1
日志收集
监控系统收集的是指标(Metrics),但系统的可观测性还有另一个重要的部分就是日志。日志的重要性无需多提,系统出现问题时,如何最快的看到日志,搜索到关键信息十分重要。
传统上做日志收集分析通常是用ELK全家桶,不巧的是我个人很讨厌Java生态的东西。而且这玩意明显太重了,对于我来说,能以最快的速度在正确的日志上,正确的时间段走grep搜索就足够了。所以我选择了Loki,这个是Grafana官方出品的日志收集组件,它最大的特色就是采用与Promtheus一致的查询语法。
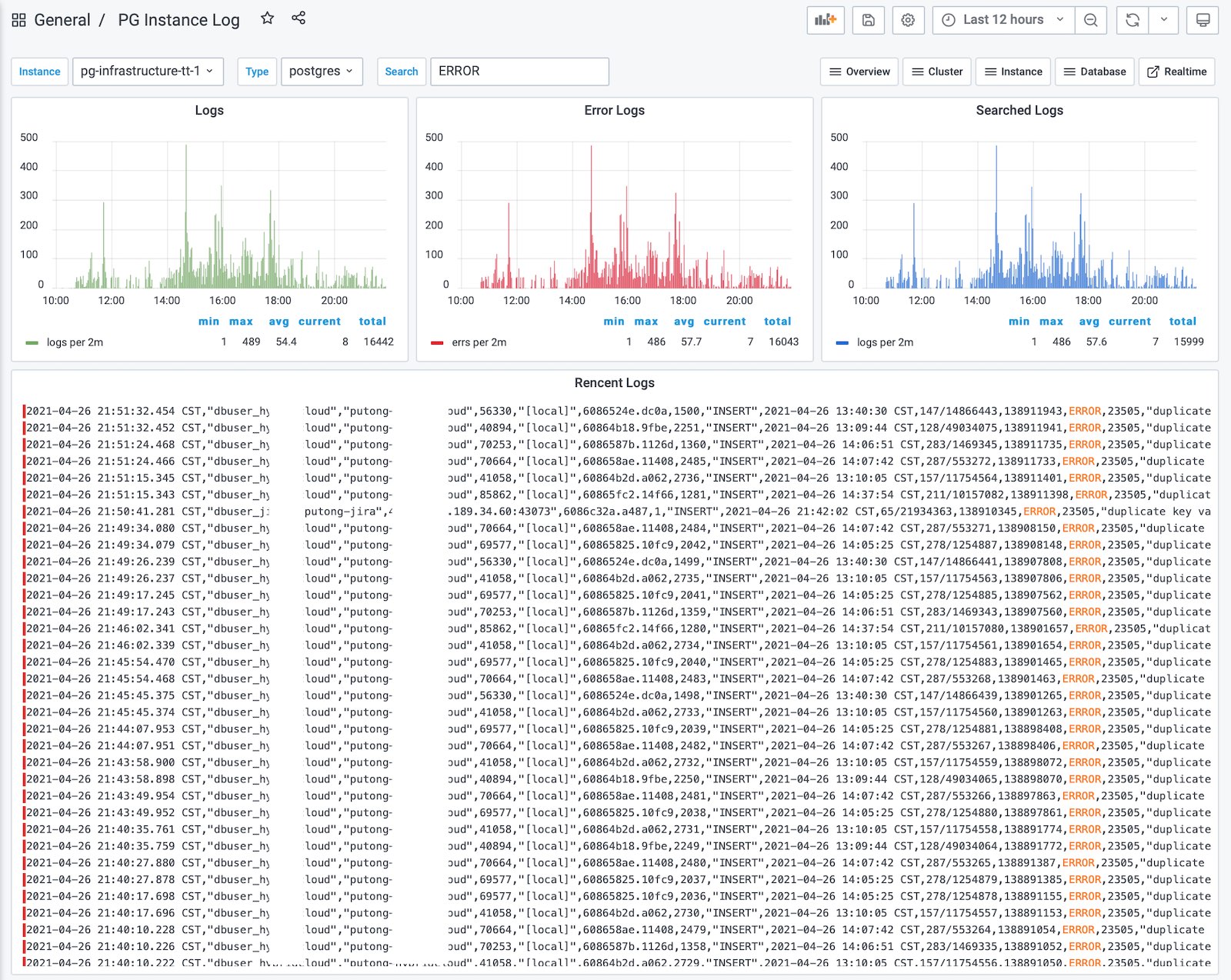
例如在Pigsty v0.9中新增的PG Instance Log Dashboard,就提供了一个简单但无比实用的功能。通过ins选择数据库实例,通过job选择日志类型(postgres|pgbouncer|patroni),然后在搜索框中填入(可选)的关键词。即可完成日志查询。

错误日志会自动按等级区分颜色并高亮搜索关键词。上方的Logs | Error Logs | Search Logs 面板分别显示了指定实例在指定时间段内的(所有,错误,搜索匹配)日志分布直方图。您可以在这里拉选快速定位出现错误(或包含指定关键词)的日志项,在几秒钟精确定位到任意一条错误日志。
此外,我们还可以通过LogQL,采用类似Prometheus的语法定义日志衍生指标。比如每分钟错误日志数就会是一个极其有用的监控报警指标。使用LogQL也可以迅速对日志进行分析,并通过相同的Label与Prometheus中其他的丰富监控指标进行Join。
Loki在设计上就是个大规模并行Grep,尽管没有索引,但是速度还是惊人的快。而且对于日志的压缩比相当高,很省空间。总的来说我相当满意。使用Loki与Promtail收集Postgres相关日志还是比较Tricky的,特别是CSV日志,用正则表达式去解析确实是比较蛋疼的一件事:
^(?P<ts>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{3} \w+),"?(?P<user>[^"]*?)?"?,"?(?P<datname>[^"]*?)?"?,(?P<pid>\d+)?,"?(?P<conn>[^"]+)?"?,(?P<session_id>\w+\.\w+)?,(?P<line_num>\d+)?,"?(?P<cmdtag>[^"]*?)?"?,(?P<session_start>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2} \w+)?,(?P<vxid>[^"]*?)?,(?P<txid>\d+)?,(?P<level>\w+)?,(?P<code>\w{5})?,.*$
另外值得注意的就是,为了正确收集处理Patroni的日志,Pigsty v0.9针对Patroni的日志时间戳进行了修改,移除了畸形的毫秒时间戳并添加了时区,主要是Python默认的时间戳格式无法被Go标准库正确识别,这是一个我没想到的坑。所以为了收集查阅Patroni日志,Pigsty v0.8之间的用户也许需要重新调整一下Patroni的配置并移除已有Log。
最后 Pigsty v0.9 为了避免系统被垃圾日志淹没,对日志参数进行了精细的优化。特别是把健康检查,监控导致的垃圾信息都消除掉了,真是一件大好事啊。主要是修改了Consul Health Check Method 和 Haproxy的健康检查Method,使用旧版本的同志们重新执行 monitor & service 两个任务即可应用此变更。
命令行工具
Pigsty先前都是通过Ansible Playbook来完成各种部署任务。直接调用Ansible Playbook尽管可以执行非常精细的控制,但也需要对系统有一定的熟悉与了解才行。尽管ansible是个非常简单的傻瓜式部署工具,但它也是有使用门槛的。有没有办法消除这个门槛,让Pigsty用户根本不用知道什么是Ansible?当然也有办法,只要写一个命令行工具,在Ansible的原语外面再包装一层就好了。例如
pigsty infra init #--> ./infra.yml # 执行基础设施初始化
pigsty pgsql init -l pg-test #--> ./pgsql.yml -l pg-test # 初始化pg-test集群
当然如果只是一个命令翻译层,就没什么好说的了。Pigsty CLI还提供了很实用的信息查询功能。最后要达到的理想状态就是Pigsty CLI一个二进制往服务器上一丢,然后无论是下载安装,配置ssh sudo,查阅基础设施与数据库集群配置,巡检数据库状态, 执行Play,快捷ssh与psql至数据库,SQL发布,备份恢复,所有的东西都做到里面去。
关于Pigsty CLI本身,我一直在犹豫是用Python写还是用Go写。
Python的好处是写起来确实很快,能Hotfix,而且纯文本体积很小,坏处是一堆依赖不太好处理;比如解析yaml需要安装PyYAML,连接PG需要安装psycopg2,跑个webserver还要安装框架,有的包不一定有。
Go的好处是没有任何依赖,但是编译出来十几MB太大了,而且用Go解析YAML真的是一个粪活,Python几十行搞定的功能我要写千把行代码。但没有依赖这个特性确实太香了。我分别写了Go和Python两个版本,但最后还是决定用Go来做这个工具。
说起来Go 1.16有一个很棒的新功能 embed,可以直接把静态资源嵌入到二进制程序中。一个Web程序就是一个清清爽爽的二进制。这也是我使用Go的一个重要原因:开发Pigsty GUI
图形用户界面
Pigsty GUI
Pigsty CLI中还集成了一个Web UI。提供了一个配置文件编辑与跑脚本的API,并嵌入了一个图形界面。只要在Pigsty源码目录中执行 pigsty serve 就会启动它(不过目前还在Beta,且这个GUI开不开源还没定)。就我个人而言,还是比较习惯命令行,但图形界面确实是降低门槛的好东西。比如这个配置编辑的功能就很不错
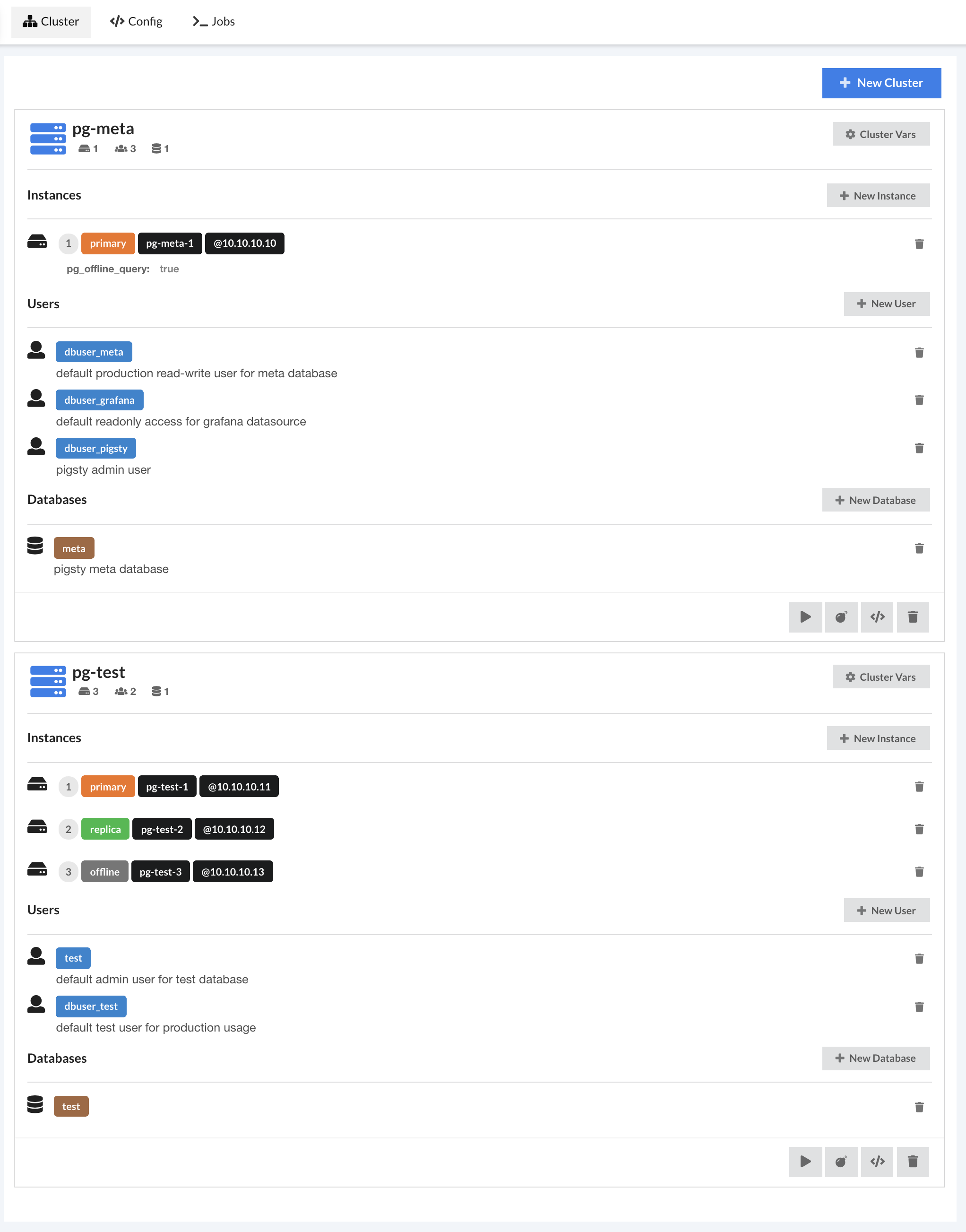
这个GUI还会调用CLI中封装好的命令,执行各种任务(集群、实例初始化、销毁、扩缩容等),并实时返回日志信息。
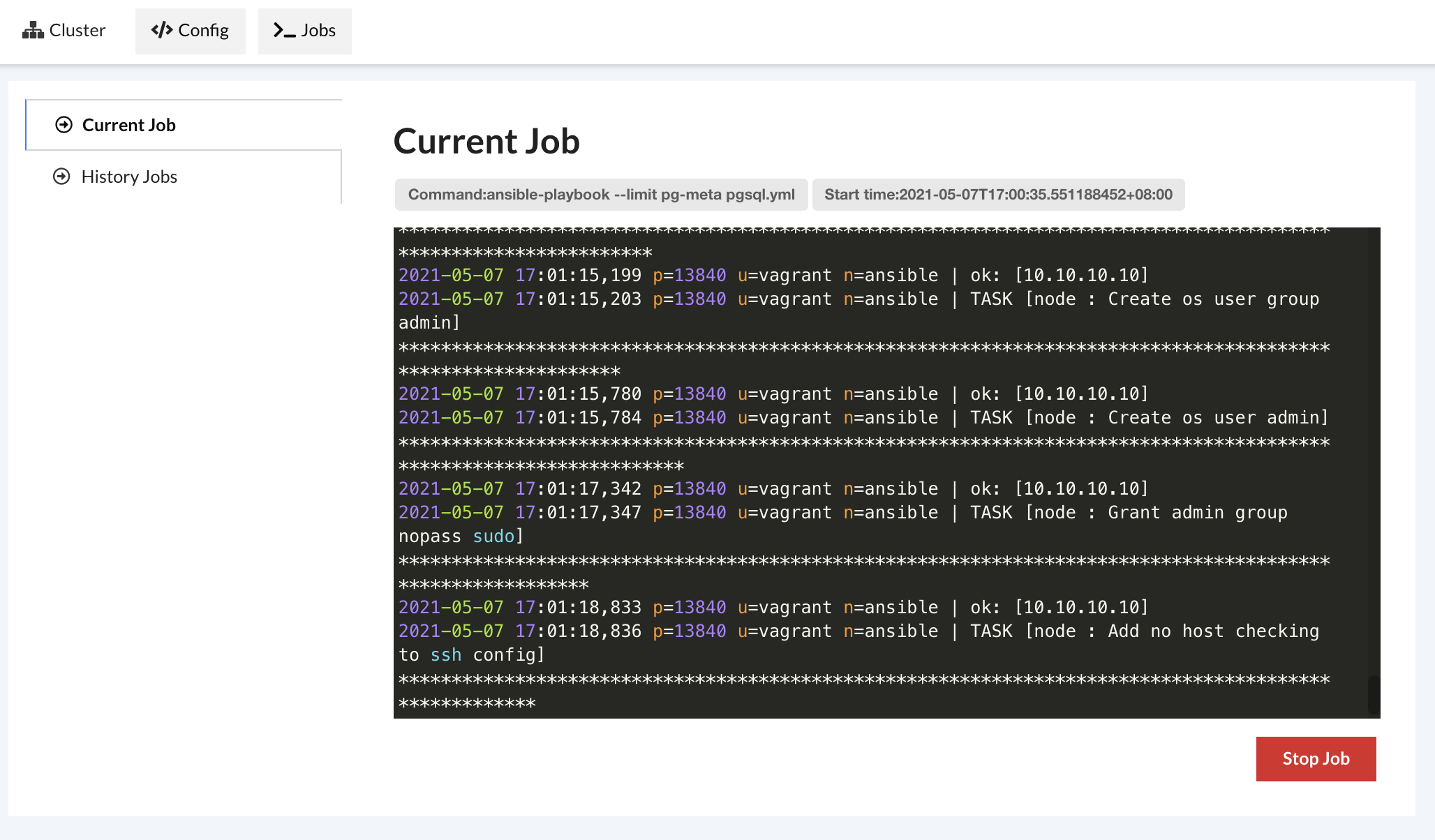
也可以查阅先前执行的Job
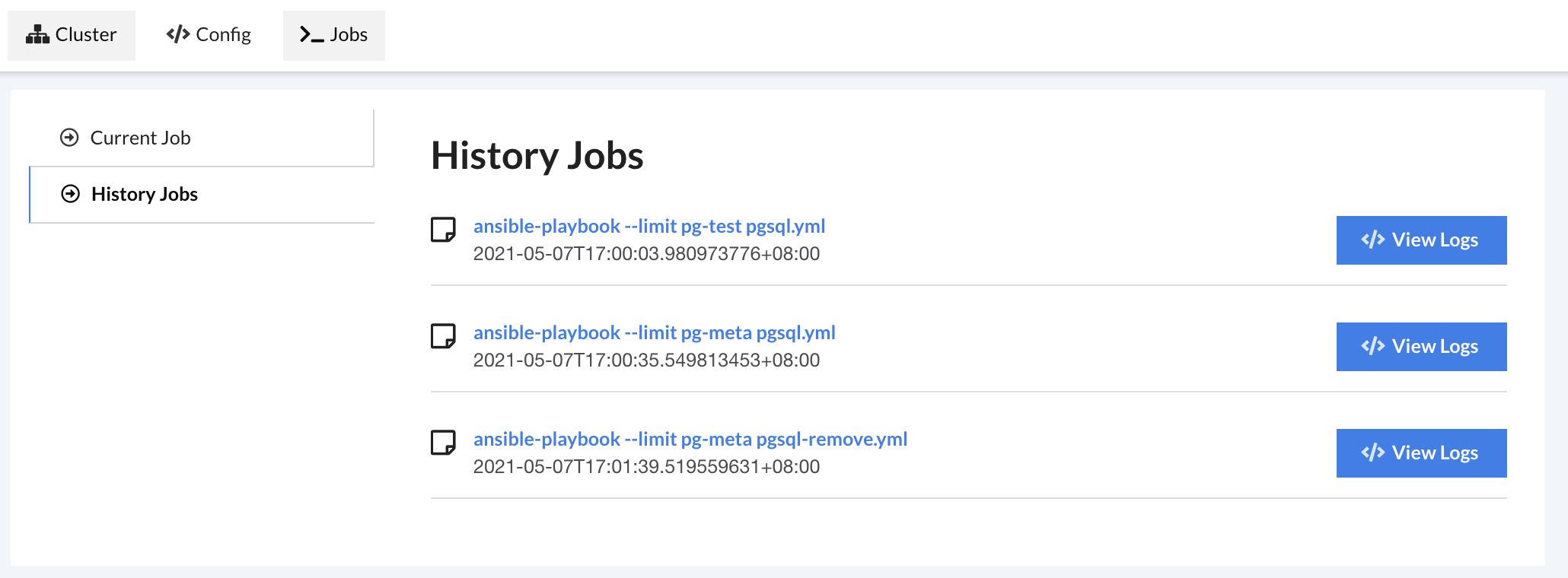
为了安(tou)全(lan),我把Job做成了Singleton,一次只能通过UI运行一个Job,就是跑一个Playbook。
Pigsty监控系统的UI
此外,Pigsty监控系统的图形界面也有了一些改进。一些Panel改用Grafana新提供的Pie Chart和Time Series重新绘制,一些用户反馈的的Bug也得到了修复。开源版中新增加了非常实用的PG Instance Log Dashboard。同时原有的 PG Service Dashboard 彻底重制,更多的是反映 Haproxy 中对外”暴露“ 的Service以及Proxy的状态,而不再是展现根据人为划分的Role聚合的服务级指标。
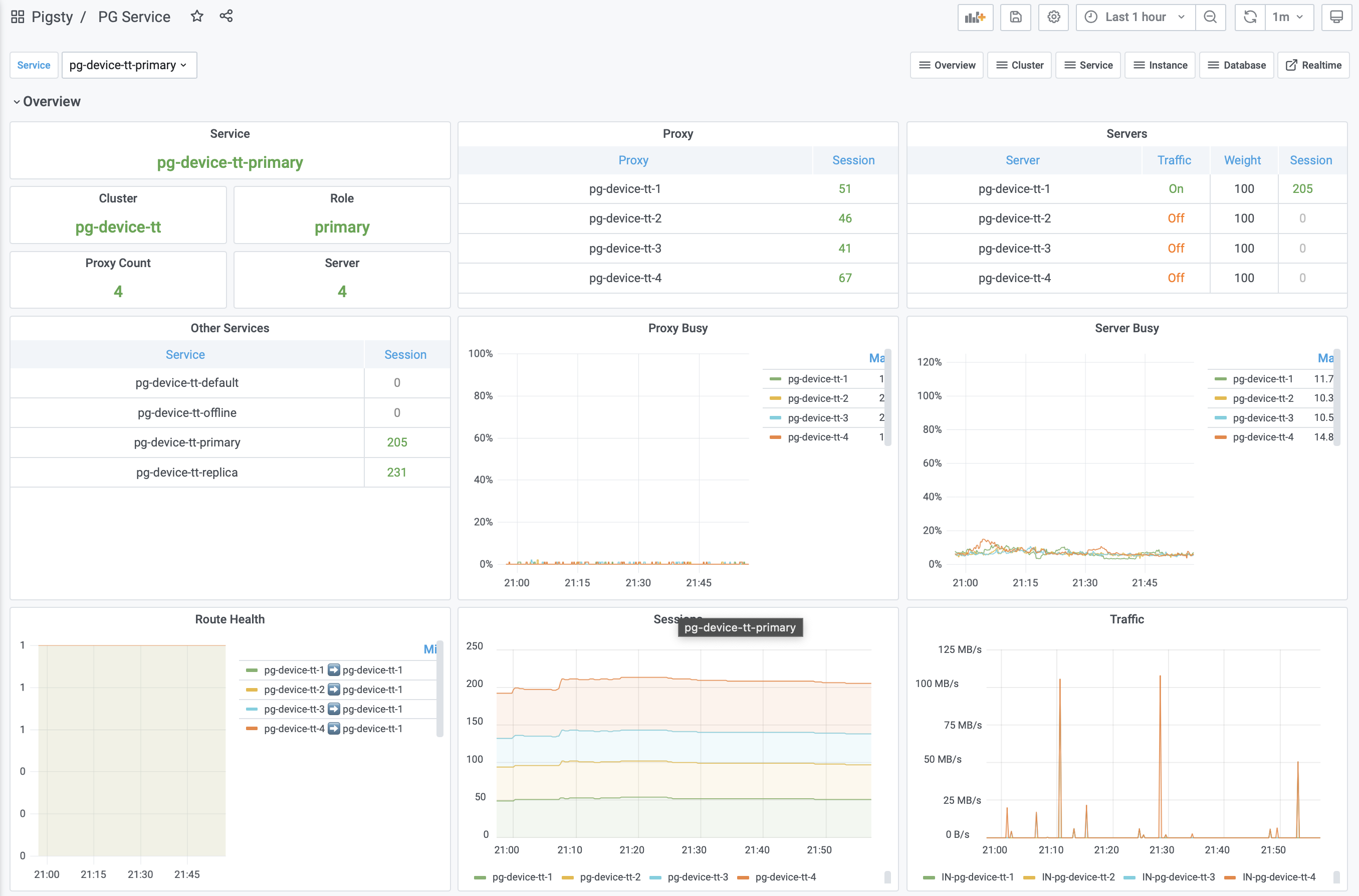
新 PG Service Dashboard
原来的Dashboard适配Grafana 7.5.4 后,显示效果有了一些改善。
说句题外话,如果你觉的Demo中监控系统界面太单调,很可能是因为你的实例太少了,Pigsty的UI是针对大规模集群(几百+实例)设计的。如果实例太少,又没什么活动,就会显得空荡荡的。
关于监控系统,等到六月份Grafana 8.0 出来后,可能在界面上会有显著调整。但我现在并不确定这个变更是否应该引入到1.0 GA中。
飞升
默认配置文件中部署在元节点上的数据库集群pg-meta, 本来纯粹是一个空的演示数据库。在以前这个数据库实例本身并不属于元节点或基础设施的一部分,纯粹是出于元节点“废物利用”的目的加上的,用来配合pg-test集群测试一些数据库迁移的案例。但是现在我决定让它成为一个必选项而不是可选项,在执行infra初始化的时候一并完成这个pgsql数据库实例的创建。
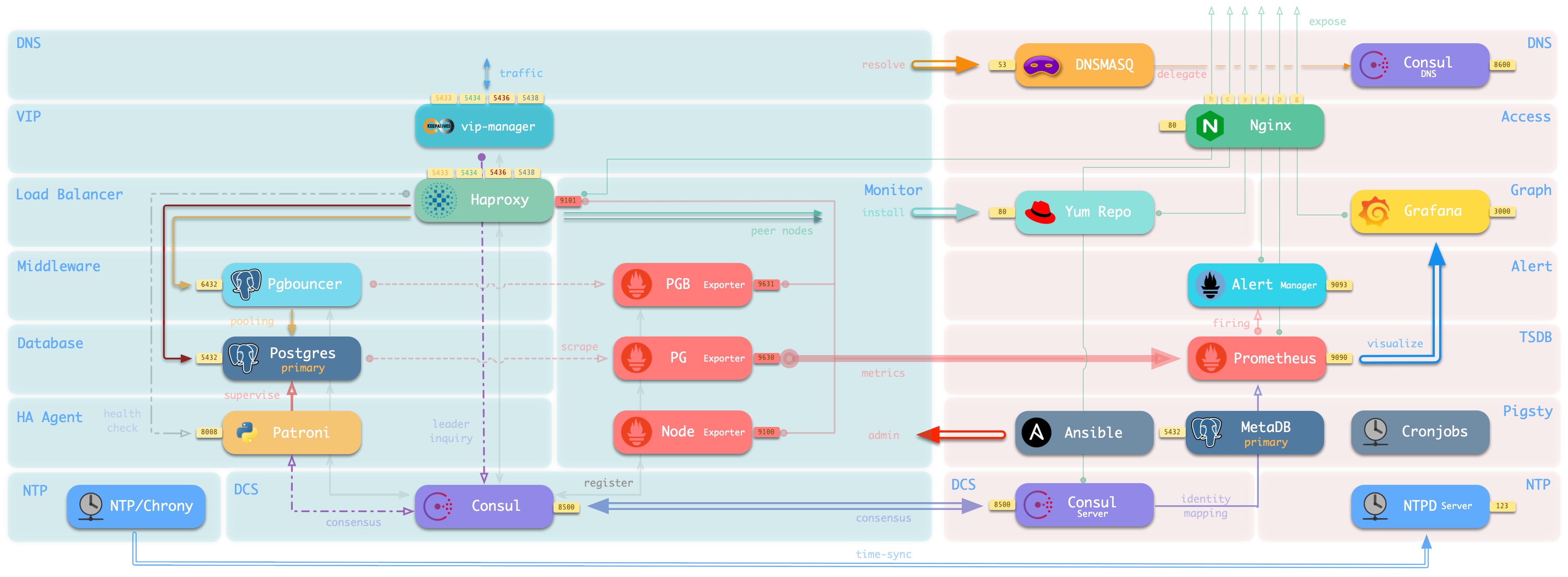
这样做有两个考量,第一个是正确性验证。作为一个数据库部署方案,如果这套系统可以在元节点上部署基础设施时一并部署一套数据库,那么我们当然对它能在普通数据库节点上成功完成数据库集群部署更有信心。第二个是一个默认可用的PostgreSQL确实可以做非常非常多的事情:例如,自我管理。
CMDB
理想情况下,大规模生产集群应该使用CMDB进行管理。简单的说,就是把 pigsty.yml 文件拆分成一系列的数据库表。然后通过数据库DML来完成配置修改,执行脚本时通过查询来获取最新的配置。
不过这里就是一个先有鸡还是先有蛋的问题。为了使用CMDB管理集群,你先要部署一套DB。而没有CMDB,你就没法(使用基于CMDB的供给方案)部署这套DB。除非说你的CMDB不是Postgres,而是etcd,consul这样的分布式配置存储元数据库。
我确实认真考虑过用Consul或Etcd作为CMDB的可能性,例如,如果后面我想做Kubernetes的Operator,使用ETCD作为CMDB就是很自然的想法,特别是服务注册机制可以实时反馈每个实例每个服务的状态,可以省掉很多开发工作。但从另一方面讲,Pigsty的许多计划中的高级特性又确实需要一个Postgres来承载。所以最后我还是决定使用Postgres本身作为Pigsty的CMDB,即元节点上的那套数据库 pg-meta。这也是为什么我会在 Pigsty v0.9中将 pg-meta 作为基础设施的一部分。
快捷方式make upgrade (实际上是调用bin/upgrade 这个脚本)可以将当前的 pigsty.yml 配置文件解析为meta 数据库中的一系列表。然后将pigsty.yml 本身替换为一个从数据库中查询配置的动态Inventory脚本。这样就完成了一次“飞升”,从配置文件管理升级为CMDB管理。
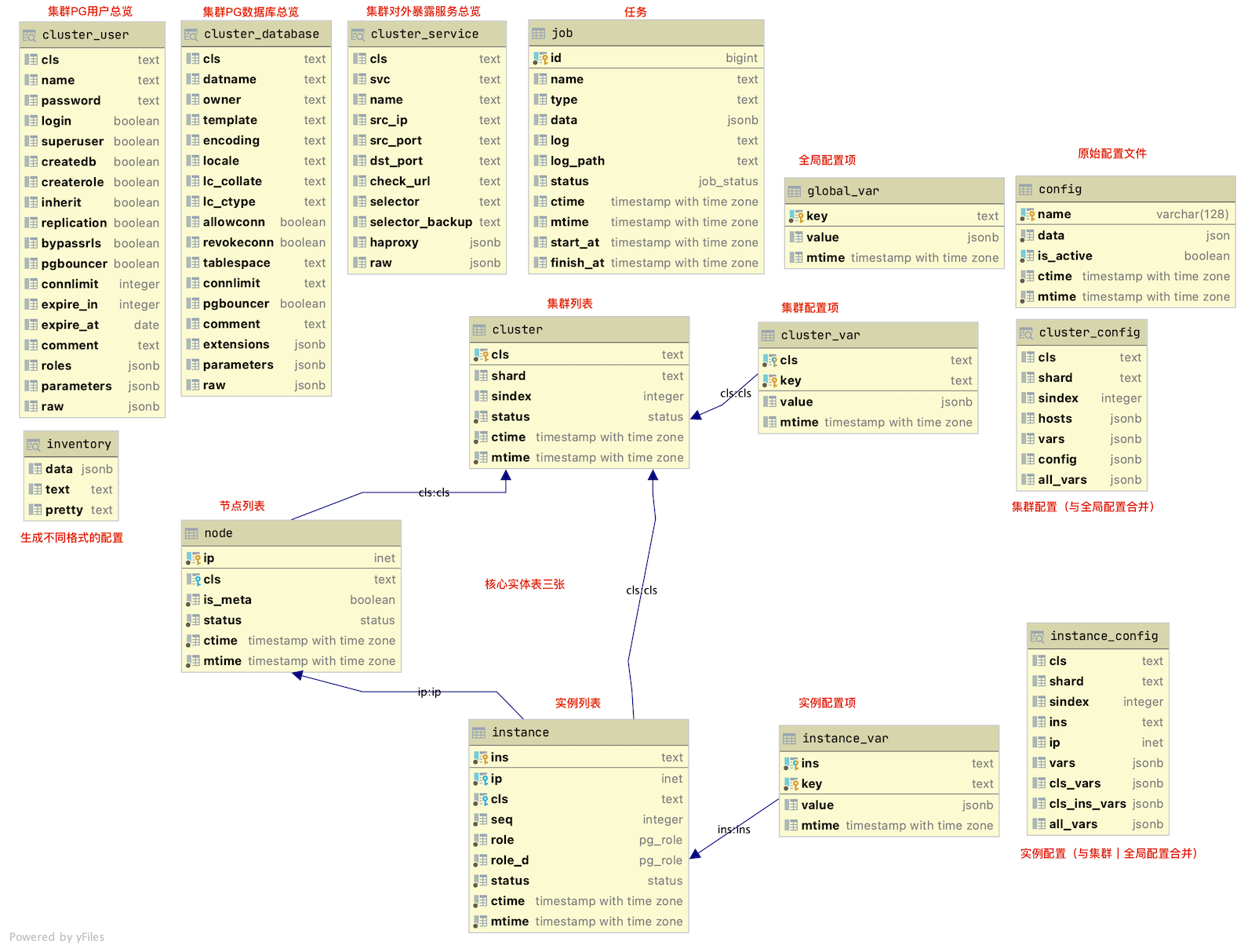
PostgreSQL非常强大,我编写了一系列存储过程封装了配置文件的增删改查。将Pigsty CMDB功能做成了一个自包含的数据库应用。所以任何后端实现只需要简单的转发这些函数调用即可,甚至有一些现成的应用(PostGraphile,PRest,postgREST)可以直接根据数据库模式生成CRUD API。所以基于数据库的后端CURD实现我就不着急弄了。
这些表将作为Pigsty后续高级特性的基石,它们构成了一个自治应用的核心部分。这个应用也可以作为一个范例,演示一个典型的应用是如何使用Pigsty中的数据库的。
分析
pg-meta的存在不仅仅可以服务于Pigsty自我管理这种简单的应用场景,还可以做的更多。如果梳理一下Pigsty现在的形态就会发现:它现在可以一键拉起一个生产级PostgreSQL实例,同时还有一个Grafana。有了这两个东西,Pigsty变成了什么?它变成了一个开箱即用的数据分析IDE!
分析是数据产业的核心,是数据这种电子石油的炼化厂。SQL基本上是数据分析的事实标准,而PostgreSQL的数据分析功能绝对是所有关系型数据库中最先进的(之一,谦虚一下)。
分析的结果需要呈现,而Grafana提供了快速高效的可视化功能支持。用一个时髦的名词讲,Grafana是一个Low code数据产品开发平台。如果觉得Grafana的可视化功能不够丰富,还可以在Grafana中使用echarts。我之前有一个讲座专门介绍了如何使用这三者配合做出相当实用的数据可视化应用来。

参考视频: 使用PostgreSQL Grafana Echarts进行敏捷数据可视化 | https://www.bilibili.com/video/BV1Gh411o7FG
很多应用(特别是数据分析,内部数据报表展示)其实并不一定需要(数据消费端的)后端 ,Grafana + PostgreSQL可以一条龙式地解决很多此类需求。一个典型的例子就是在Apple时我曾经用两周时间,基于Grafana和PostgreSQL做出了一个与现有Trace系统类似功能的产品,除了界面丑了点,基本覆盖了核心功能,用半个人月实现了几个人年的功能。这背后隐藏的是一种敏捷方法论:抓主要矛盾,找出系统的不可替代点(用数据库写SQL分析,数据库可视化),然后把所有其他杂活全都用现有开源轮子解决掉。
Datalet
Pigsty在某种程度上就是这种方法论的体现,现在你有一个开箱即用的数据库+可视化平台。数据研发人员不需要关心什么前端后端接口,只需要把数据灌入数据库再用SQL查出来,最后在Grafana上画出来。添加一些交互导航,一个五脏俱全的数据应用就出炉了。所以说数据应用的分发是不是就可以浓缩成一个标准化的模式:database schema + grafana dashboards [+ data generator] ?
这里的Story是,也许可以把这种典型数据应用做成一种通用的 “Datalet”,把一个特定的数据功能点做成一个自包含的”数据小应用“,例如手机号身份证查询,漫游轨迹查询,行政区划查询,旅游照片打卡,实时疫情数据等等。而Pigsty则成为这种Datalet的标准Runtime。
上面那些应用其实我都做过,当然Talk is cheap,所以这里特别准备了一个典型Non-Trivial的例子:ISD数据分析案例,便是基于Pigsty开发的。这个应用拉取美国NOAA官方的全球地面气象站观测数据。便是采用的这种结构。任何用户完全可以在Pigsty环境中几分钟完这个应用的部署。
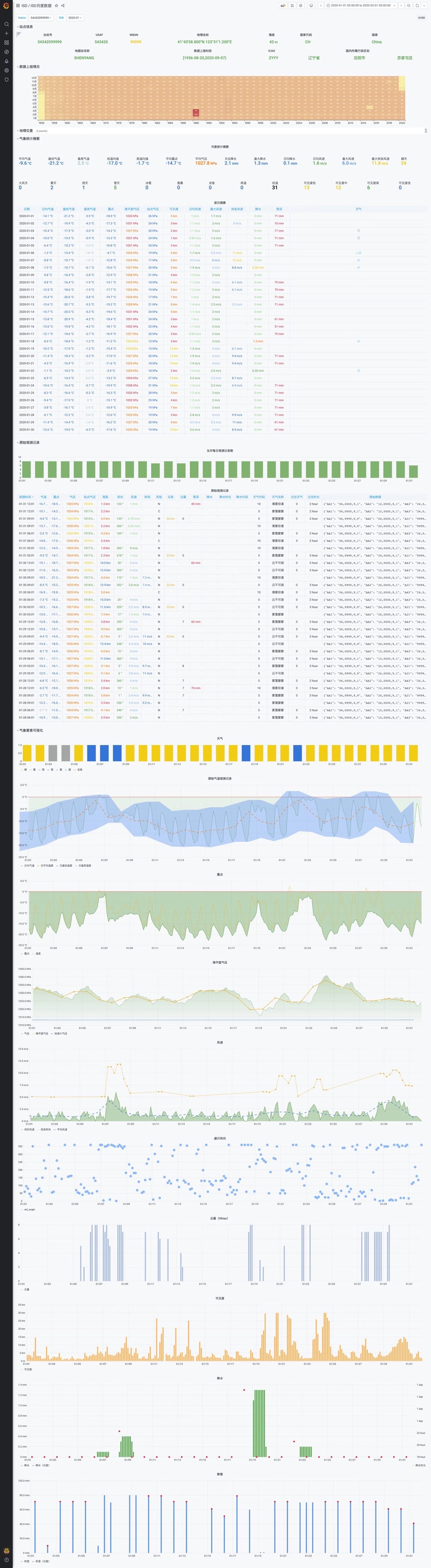
另外从某种意义上来说,Pigsty的监控系统也是这样一个典型的 数据应用,只不过它的主要数据源是Prometheus而不是Postgres罢了。数据库实例越多,活动越丰富,情况越复杂,数据也就越丰富,就越能展现出Pigsty监控系统的能力来。
绕的太远了,让我重新总结一下,这里的这个功能点之所以叫做”飞升“,就是它 Enable 了一种可能性,让Pigsty不再是一个 监控系统,一个管控软件,而且还是一个开箱即用的数据分析集成开发部署环境。尽管目前只有一个自我管理的应用,和一个演示用的气象站查询应用,但这里的Potential是无穷的。
展望未来
Pigsty 1.0 版本 大致将于 今年6~7月份释出。主要计划的更新包括:
- Pigsty CLI 与 GUI 的完善,提供对 数据库动态 Inventory的支持
- 进一步简化安装流程,最好能集成到 Pigsty CLI中。
- 修改
pg_exporter,提供单实例多DB的 DB内对象监控支持,支持PG14(如果需要)。 - 彻底消除监控系统中的
role与svc标签,涉及到不少监控面板的重制,报警规则调整等。 - 如果可能,基于Grafana 8.0 重新调整监控系统的界面。
- 以ISD为例,做出几个基于Pigsty的典型 “Datalet”
尽管Pigsty仍然处于早期阶段,但我相信它具有极大的Potential,能成为一个Gaming Changing的东西。因此也需要好好规划思考一下后续的打法。Pigsty以后的发展,大致有三个方向:
- 做最顶尖最专业的 开源PostgreSQL 监控系统
- 做门槛最低最好用的 开源PostgreSQL 供给方案
- 做开箱即用的数据分析一条龙解决方案
当然我自己精力也有限,怎么加点还是需要审慎考虑的,毕竟一个人运营一个开源项目还是蛮吃力的。
Pigsty从最开始的 Idea (https://github.com/Vonng/pg/tree/master/test) 到现在已经快两年了。经过了近两年时间的打磨润色,已经基本成为了成熟的产品。但我一般喜欢做完了再说,所以1.0GA之前不会大张旗鼓的去宣传。但令人欣喜的是,已经有不少用户使用了起来。其中还有一些很给力的用户:互联网公司,部队,银行消费金融……,管理的PostgreSQL集群规模放在全国也绝对是排得上号的。可以说正是正是这些用户们的支持,才让我相信这是 the right thing,真正有动力继续去把这个事情推下去。