Challenge
聊完了可观测性的问题,接下来让我们说一说 生产环境集群的问题。比起玩具数据库,生产环境有着更严苛的要求与更复杂的问题。
很多开源或者商业监控系统,都没有很好的解决这些痛点、痒点、需求点。这也是我开发Pigsty的初衷 ,为了解决这些生产环境中的实际问题而开发的,
生产环境,比起本地测试,或者玩具数据库有什么区别呢? 总结了三个主要特点:多集群,多层次,多变更
Multi-Clusters
第一个问题,多集群。而最实际等问题就是,生产环境的数据库往往都是以一个个的集群为单位组织起来的。
集群是什么,集群是一个由主从复制所关联的一组数据库实例所构成的,它是基本的业务服务单元。比如这里下图就展示了某一个业务集群pg-core-tt的复制拓扑,这里的9个实例共同组成一个集群。
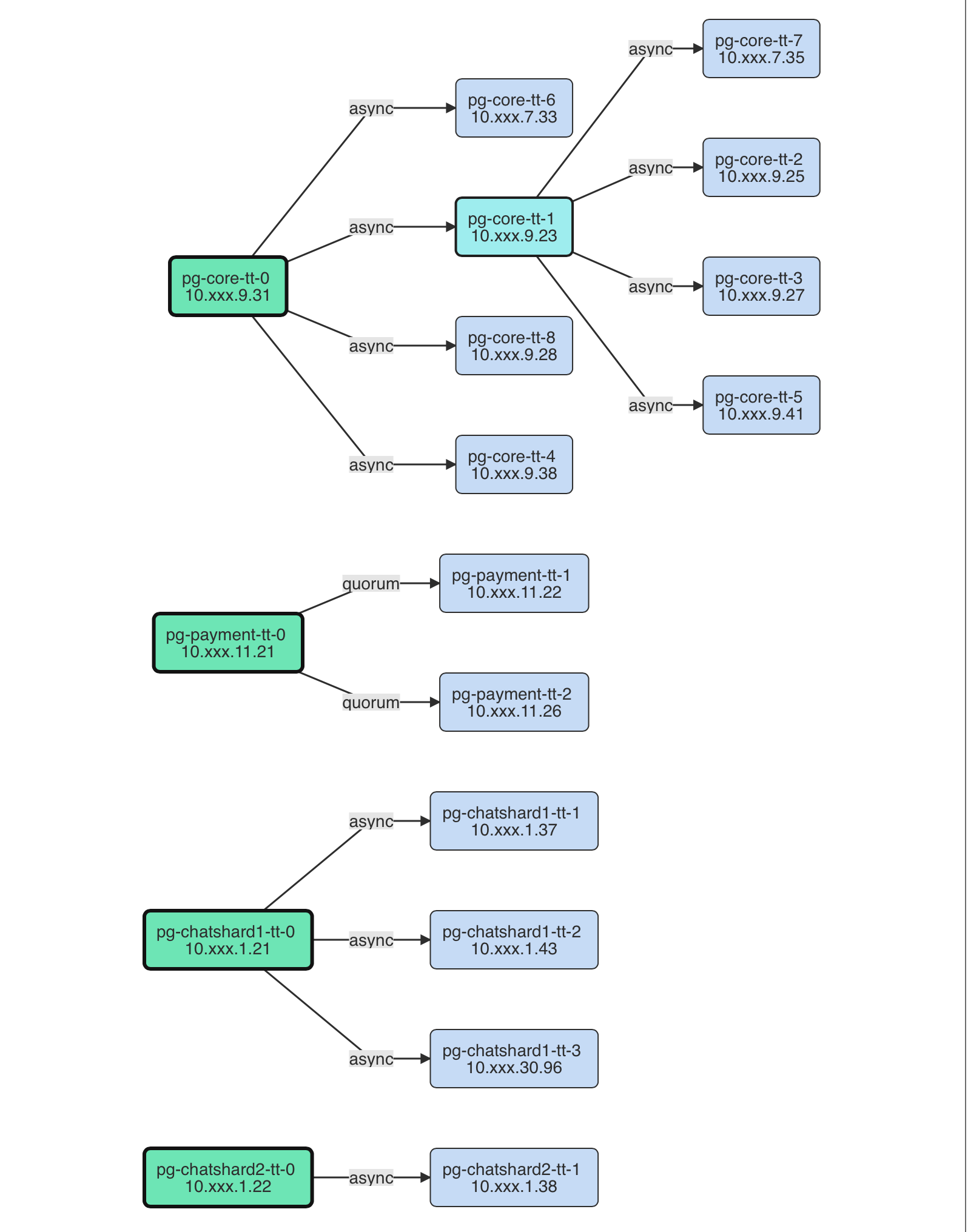
集群由多个实例组成,而多套数据库集群共同组成一个现实世界中的生产环境。很多监控系统往往只关注单个数据库实例的监控,那么问题就来了:如果我有一套数据库,那么部署一套监控系统是Fair Enough的。但如果我有一百套,一千套呢?用户不会说我真的会去部署一千套监控系统,而是希望有一套监控系统能直接把这一千套数据库监控起来。
Hierarchy
生产环境的第二个特点是多层次,Hierarchy是计算机系统里永恒的话题。
但除了实例与集群这两个最为Trivial层次,整个系统中还有着其他层次的组织。这里概括一下自顶向下可以分为7个层级:概览,分片,集群,服务,实例,数据库,对象。

我们先来看夹在集群与实例中间的层次—— Service。
接下来,让我们先向下看,在实例层级以下,还可以再分出两个层次来,分别是DB和Object。
然后,我们从集群层次向上看,则会有两个更高的层次——Shard与Overview。
最后,就像网络的OSI 7层模型在实际中被简化为TCP/IP五层模型一样,这七个层次也以集群 和 实例为界,简化为五个层次:Overview,Cluster,Service,Instance,Database
而且定义也简单了很多,所有集群层次以上的信息,都是Overview,所有实例内部的信息都算Database,夹在两者中间的,就是Service。
Changes
生产环境的第三个特点,是多变更。世界上唯一不变的就是变化本身。
第三个特点,也是最后一个。是变动频繁,这里频繁也许要打个引号。但真实世界的生产数据库必然不会是一成不变的,无论是扩容,缩容,还是Failover或Switchover,都会引起集群状态的变化。
我们会有各式各样的变更:
- 集群故障切换,手工切换
- 增加/移除实例
- 增加/移除数据库
- 修改复制拓扑,级联复制,同步复制,延迟复制,日志传输复制
- 将数据库水平拆分为分片库
- 将物理机数据库迁移至Kubernetes
- ……
如果任何集群变动都需要手工维护监控系统,是很容易出错的,最好的系统就是不需要维护的系统。我们希望所有这些集群状态变化都能被自动感知,无需手工维护。
这就需要用到服务发现
Summary
为了解决实际生产环境中面临的问题与挑战,我们首先要理清监控对象的 层次关系