Observability
对于系统管理来说,最重要到问题之一就是可观测性(Observability)。
那么,什么是可观测性呢?对于这样的问题,列举定义是枯燥乏味的,让我们直接以Postgres本身为例。
这张图显示了Postgres本身提供的可观测性。PostgreSQL 提供了丰富的观测接口,包括系统目录,统计视图,辅助函数。 这些都是我们可以观测的对象。

原图地址:https://pgstats.dev/
我可以很荣幸地宣称,这里列出的信息全部被Pigsty所收录。并且通过精心的设计,将晦涩的指标数据,转换成了人类可以轻松理解的洞察。
可观测性
经典的监控模型中,有三类重要信息:
指标
下面让我们以一个最经典的例子来深入探索可观测性: pg_stat_statements ,这是Postgres官方提供的统计插件,可以暴露出数据库中执行的每一类查询的详细统计指标。与图中Query Planning和Execution相对应
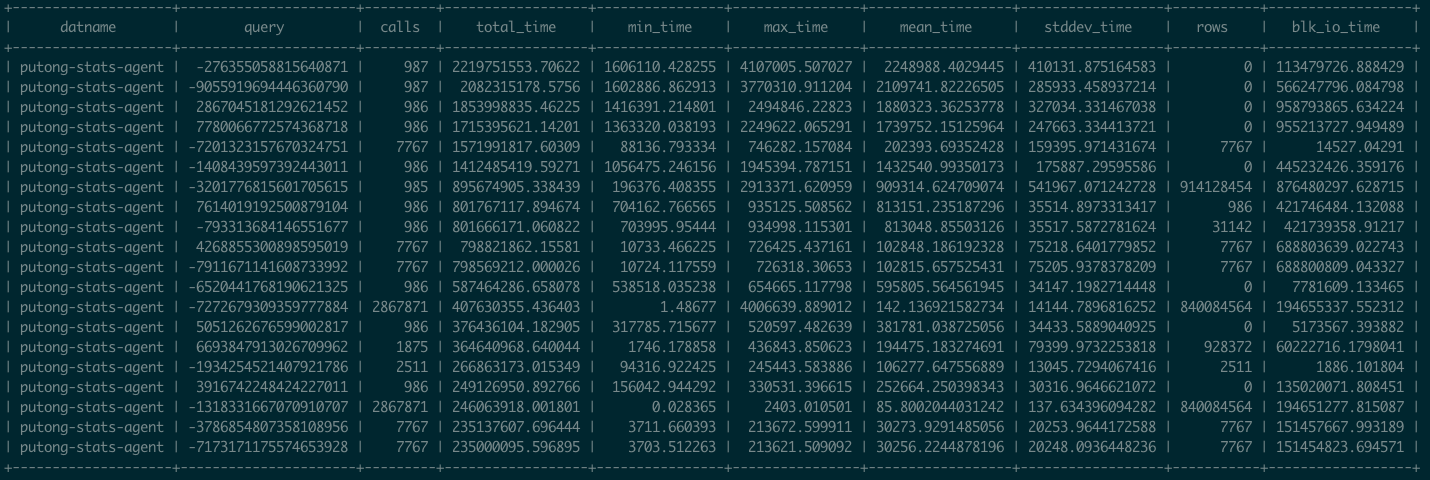
这里我们可以看到,pg_stat_statements 提供的原始指标数据以表格的形式呈现。譬如这里,每个查询都分配有一个查询ID,紧接着是调用次数,总耗时,最大、最小、平均单次耗时,响应时间都标准差,每次调用平均返回的行数,用于块IO的时间等等,(如果是PG13,还有更为细化的计划时间、执行时间、产生的WAL记录数量等新指标)。
直接观测这种数据表,很容易让人摸不着头脑,看不到重点。我们需要的是,将这种可观测性转换为洞察,也就是以直观图表的方式呈现。
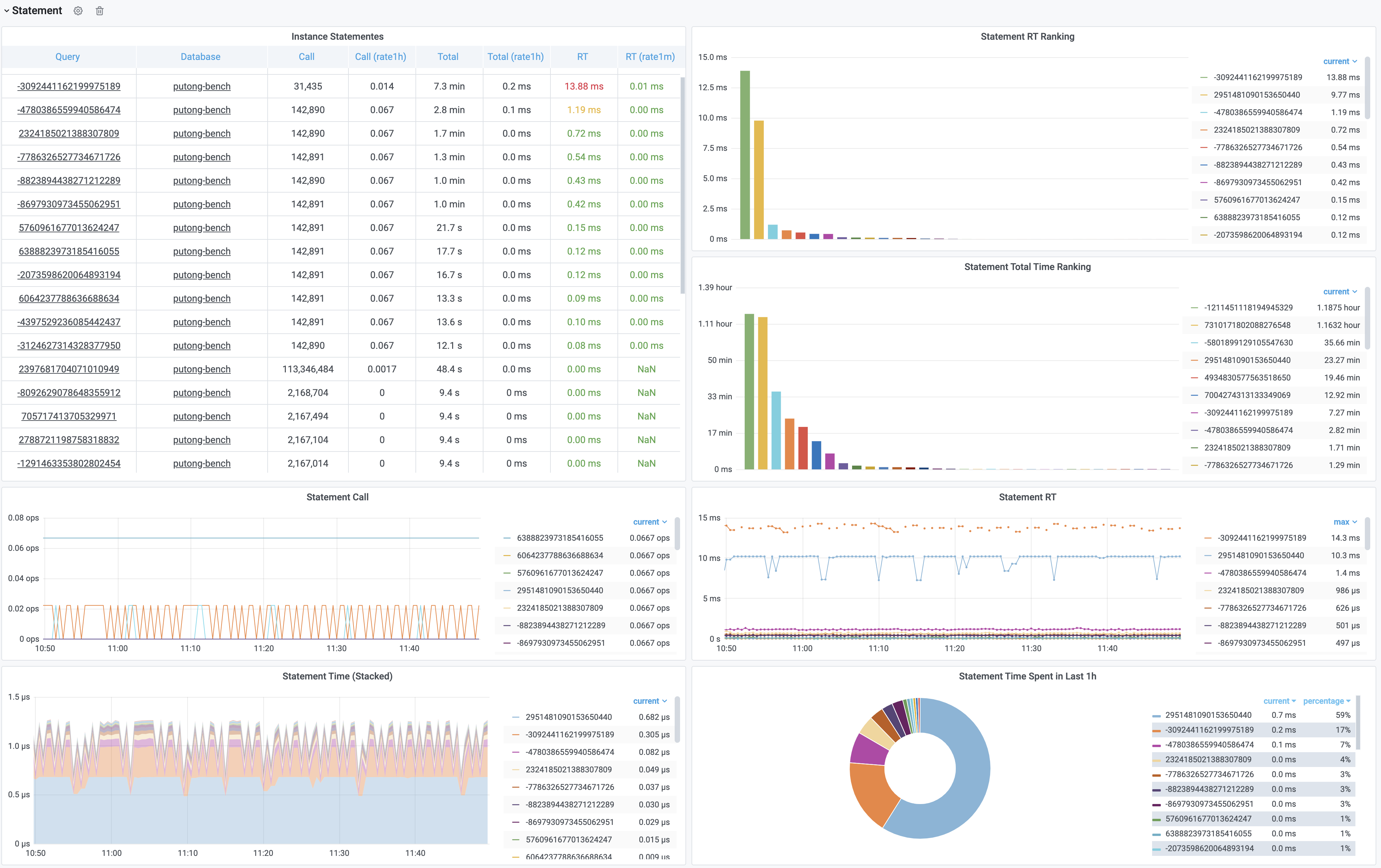
这里的表格数据经过一系列的加工处理,最终呈现为若干监控面板。最基本的加工处理譬如:对表格中的原始数据进行标红上色,这样慢查询就可以一览无余,但这也不过是雕虫小技。
更重要的是,原始的数据视图只能呈现当前时刻的快照,而通过Pigsty,你可以回溯任意时刻或任意时间段。获取更深刻的性能洞察。
比如下图是集群视角下的慢查询,我们可以看到整个集群中所有查询的概览,包括每一类查询的QPS与RT,平均响应时间排名,以及耗费的总时间占比。当我们对某一类具体查询感兴趣时,就可以点击查询ID跳转到查询详情页中,如右图所示。这里会显示查询的语句,以及一些核心指标。
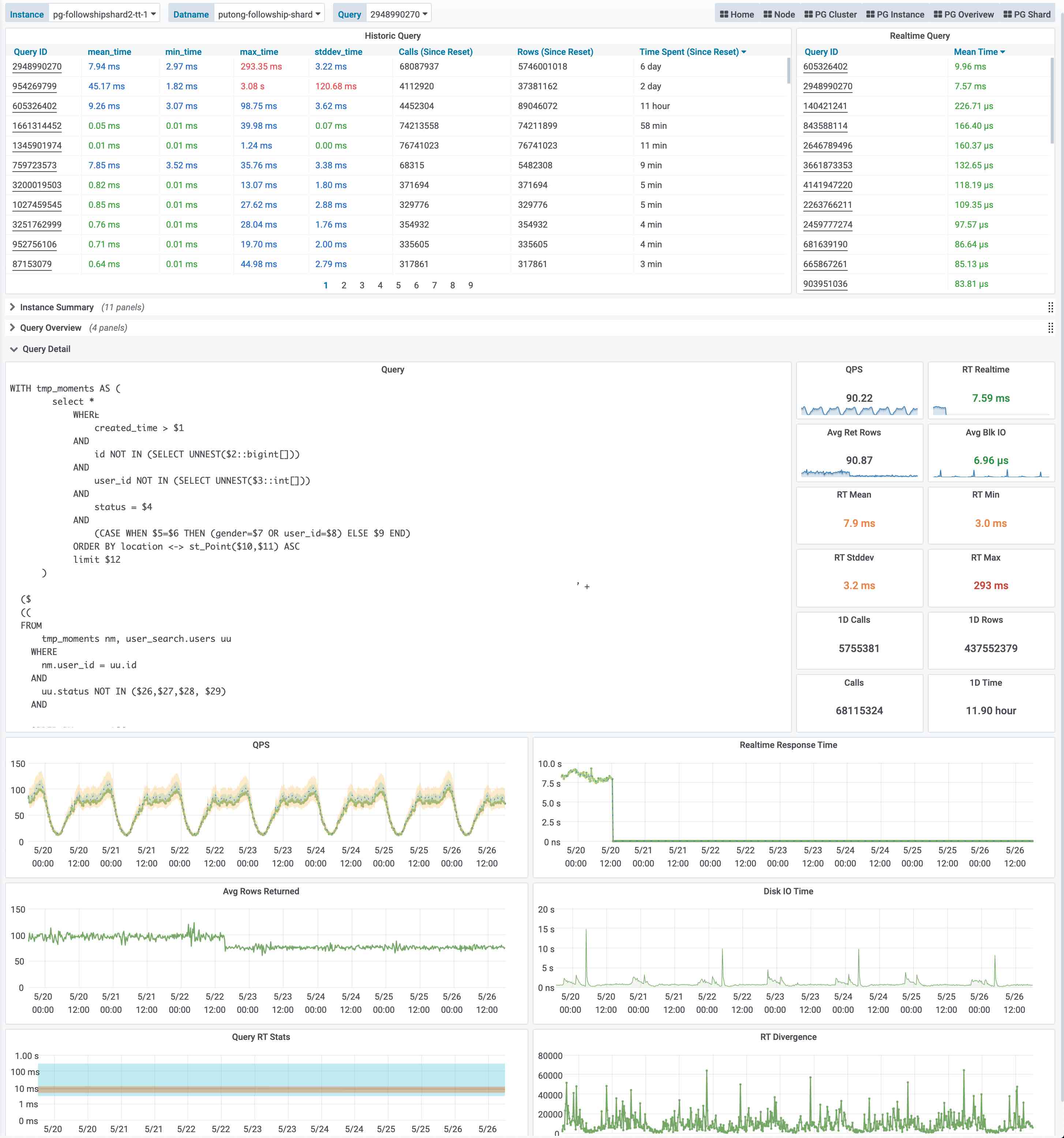
这个图是实际生产环境中的一次慢查询优化记录,我们可以从右侧中间的Realtime Response Time 面板中看到一个突变,该查询的平均响应时间从七八秒突降到了七八毫秒。我们定位到了这个慢查询并添加了适当的索引,那么优化的效果就立刻在图表上以直观的形式展现出来。
这就是Pigsty需要解决的核心问题,From observability to insight。
而下面这些玲琅满目的面板,就是Pigsty成就的一瞥:


目录
Catalog是什么?Catalog是数据库的元数据字典。
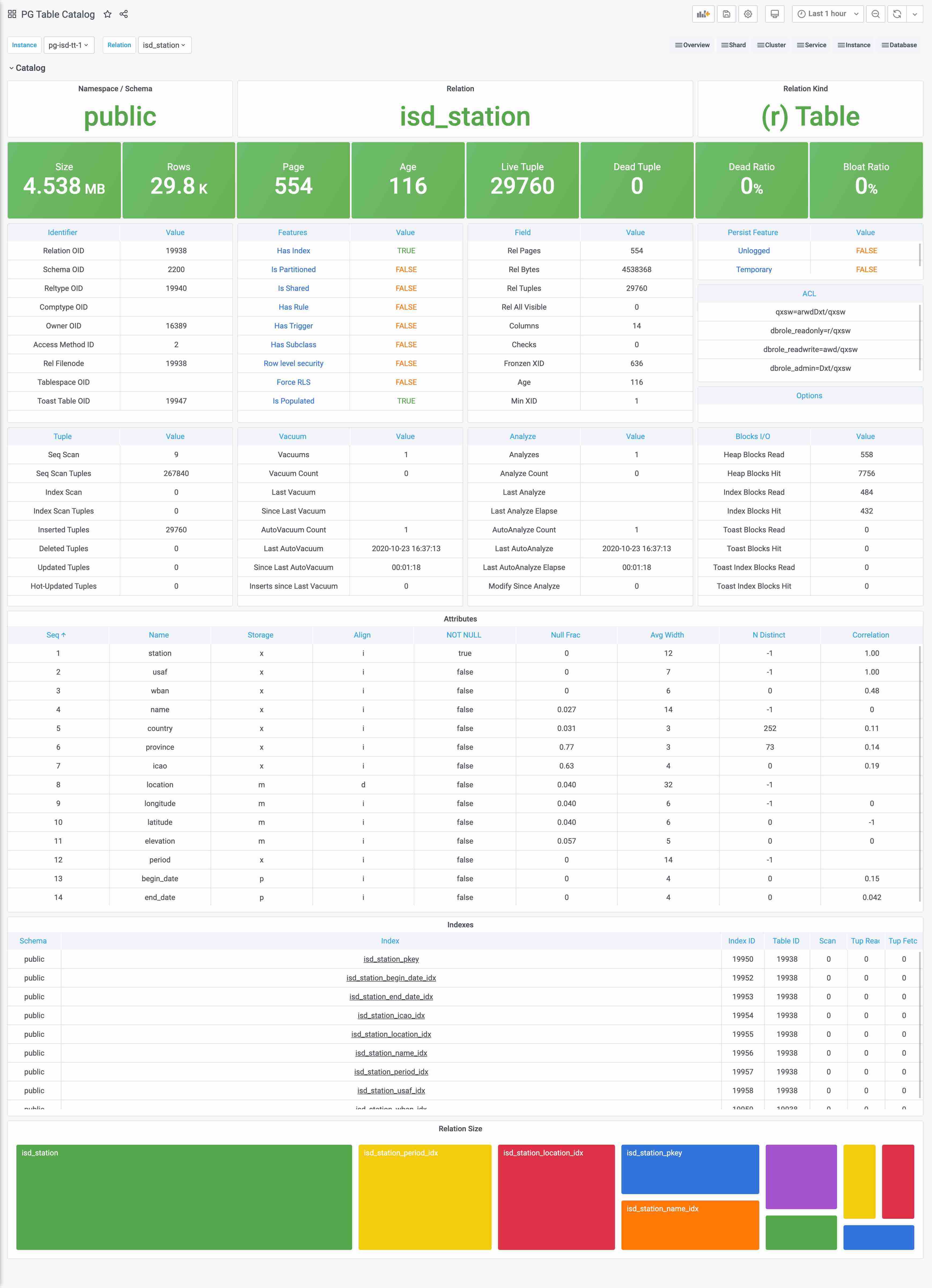
Catalog与Metrics比较相似但又不完全相同,边界比较模糊。最简单的例子,一个表的页面数量和元组数量,应该算Catalog还是算Metrics呢?
跳过这种概念游戏,实践上Catalog和Metrics主要的区别是,Catalog里的信息通常是不怎么变化的,比如表的定义之类的,如果也像Metrics这样比如几秒抓一次,显然是一种浪费。所以我们会将这一类偏静态的信息划归Catalog。
Catalog主要由定时任务负责抓取,而不由Prometheus采集。
日志
除了Catalog,还有一类与监控系统有关的数据是Log。如果说Metrics是对数据库系统的被动观测,那么Log就是数据库系统主动汇报的信息。
Pigsty集成了pgbadger,这是一个非常强大的日志摘要工具,可以实时聚合并生成PG的日志摘要。
同时,通过mtail这样的工具,我们还可以从日志中提取重要的监控指标,最简单的例子就是每秒各错误等级的日志条数。如果说整个监控系统只能保留一个指标,也许这个指标就是最有用的那个指标了。
接下来呢?
只有指标并不够,我们还需要将这些信息组织起来,才能构建出体系来。
阅读下一节:实际挑战 来了解实际的生产环境中的监控系统可能面临怎样的问题与挑战。