Alert Rules
Alerts are critical to daily fault response and to improve system availability.
Missed alarms lead to reduced availability and false alarms lead to reduced sensitivity, necessitating a prudent design of alarm rules.
- Reasonable definition of alarm levels and the corresponding processing flow
- Reasonable definition of alarm indicators, removal of duplicate alarm items, and supplementation of missing alarm items
- Scientific configuration of alarm thresholds based on historical monitoring data to reduce the false alarm rate.
- Reasonable sparse special case rules to eliminate false alarms caused by maintenance work, ETL, and offline query.
Alert taxonomy
**By Urgency **
-
P0: FATAL: Incidents that have significant off-site impact and require urgent intervention to handle. For example, main library down, replication outage. (Serious incident)
-
P1: ERROR: Incidents with minor off-site impact, or incidents with redundant processing, requiring response processing at the minute level. (Incident)
-
P2: WARNING: imminent impact, let loose may worsen at the hourly level, response is required at the hourly level. (Incident of concern)
-
P3: NOTICE: Needs attention, will not have an immediate impact, but needs to be responded to within the day level. (Deviation phenomena)
By Level
- DBA will only pay special attention to CPU and disk alarms, and the rest is the responsibility of operation and maintenance.
- Database level: Alarms of database itself, DBA focus on. This is generated by PG, PGB, and Exporter’s own monitoring metrics.
- Application level: Application alarms are the responsibility of the business side itself, but DBA will set alarms for business metrics such as QPS, TPS, Rollback, Seasonality, etc.
By Metric Type
- Errors: PG Down, PGB Down, Exporter Down, Stream Replication Outage, Single Set Cluster Multi-Master
- Traffic: QPS, TPS, Rollback, Seasonality
- Latency: Average Response Time, Replication Latency
- Saturation: Connection Stacking, Number of Idle Transactions, CPU, Disk, Age (Transaction Number), Buffers
Alarm Visualization
Pigsty uses bar graphs to present alarm information. The horizontal axis represents the time period and a color bar represents the alarm event. Only alarms that are in the Firing state are displayed in the alarm chart.
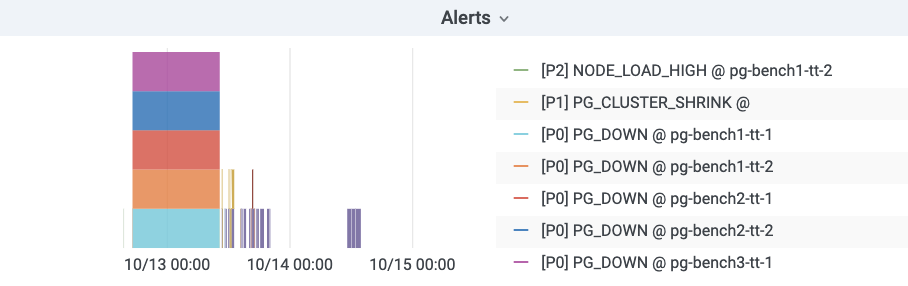
Alarm rules in detail
Alarm rules can be roughly divided into four categories by type: error, delay, saturation, and flow. Among them.
- Errors: mainly concerned with the survivability (Aliveness) of each component, as well as network outages, brain fractures and other abnormalities, the level is usually higher (P0|P1).
- Latency: mainly concerned with query response time, replication latency, slow queries, and long transactions.
- Saturation: mainly focus on CPU, disk (these two belong to system monitoring but very important for DB so incorporate), connection pool queue, number of database back-end connections, age (essentially the saturation of available thing numbers), SSD life, etc.
- Traffic: QPS, TPS, Rollback (traffic is usually related to business metrics belongs to business monitoring, but incorporated because it is important for DB), seasonality of QPS, burst of TPS.
Error Alarm
Postgres instance downtime distinguishes between master and slave, master library downtime triggers P0 alarm, slave library downtime triggers P1 alarm. Both require immediate intervention, but slave libraries usually have multiple instances and can be downgraded to query on the master library, which has a higher processing margin, so slave library downtime is designated as P1.
# primary|master instance down for 1m triggers a P0 alert
- alert: PG_PRIMARY_DOWN
expr: pg_up{instance=~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Postgres Primary Instance Down: {{$labels.instance}}"
description: "pg_up = {{ $value }} {{$labels.instance}}"
# standby|slave instance down for 1m triggers a P1 alert
- alert: PG_STANDBY_DOWN
expr: pg_up{instance!~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres Standby Instance Down: {{$labels.instance}}"
description: "pg_up = {{ $value }} {{$labels.instance}}"
Pgbouncer实例因为与Postgres实例一一对应,其存活性报警规则与Postgres统一。
# primary pgbouncer down for 1m triggers a P0 alert
- alert: PGB_PRIMARY_DOWN
expr: pgbouncer_up{instance=~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Pgbouncer Primary Instance Down: {{$labels.instance}}"
description: "pgbouncer_up = {{ $value }} {{$labels.instance}}"
# standby pgbouncer down for 1m triggers a P1 alert
- alert: PGB_STANDBY_DOWN
expr: pgbouncer_up{instance!~'.*master.*'}
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Pgbouncer Standby Instance Down: {{$labels.instance}}"
description: "pgbouncer_up = {{ $value }} {{$labels.instance}}"
Prometheus Exporter的存活性定级为P1,虽然Exporter宕机本身并不影响数据库服务,但这通常预示着一些不好的情况,而且监控数据的缺失也会产生某些相应的报警。Exporter的存活性是通过Prometheus自己的up指标检测的,需要注意某些单实例多DB的特例。
# exporter down for 1m triggers a P1 alert
- alert: PG_EXPORTER_DOWN
expr: up{port=~"(9185|9127)"} == 0
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Exporter Down: {{$labels.instance}} {{$labels.port}}"
description: "port = {{$labels.port}}, {{$labels.instance}}"
所有存活性检测的持续时间阈值设定为1分钟,对15s的默认采集周期而言是四个样本点。常规的重启操作通常不会触发存活性报警。
延迟报警
与复制延迟有关的报警有三个:复制中断,复制延迟高,复制延迟异常,分别定级为P1, P2, P3
-
其中复制中断是一种错误,使用指标:
pg_repl_state_count{state="streaming"}进行判断,当前streaming状态的从库如果数量发生负向变动,则触发break报警。walsender会决定复制的状态,从库直接断开会产生此现象,缓冲区出现积压时会从streaming进入catchup状态也会触发此报警。此外,采用-Xs手工制作备份结束时也会产生此报警,此报警会在10分钟后自动Resolve。复制中断会导致客户端读到陈旧的数据,具有一定的场外影响,定级为P1。 -
复制延迟可以使用延迟时间或者延迟字节数判定。以延迟字节数为权威指标。常规状态下,复制延迟时间在百毫秒量级,复制延迟字节在百KB量级均属于正常。目前采用的是5s,15s的时间报警阈值。根据历史经验数据,这里采用了时间8秒与字节32MB的阈值,大致报警频率为每天个位数个。延迟时间更符合直觉,所以采用8s的P2报警,但并不是所有的从库都能有效取到该指标所以使用32MB的字节阈值触发P3报警补漏。
-
特例:
antispam,stats,coredb均经常出现复制延迟。
# replication break for 1m triggers a P0 alert. auto-resolved after 10 minutes.
- alert: PG_REPLICATION_BREAK
expr: pg_repl_state_count{state="streaming"} - (pg_repl_state_count{state="streaming"} OFFSET 10m) < 0
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Postgres Streaming Replication Break: {{$labels.instance}}"
description: "delta = {{ $value }} {{$labels.instance}}"
# replication lag greater than 8 second for 3m triggers a P1 alert
- alert: PG_REPLICATION_LAG
expr: pg_repl_replay_lag{application_name="walreceiver"} > 8
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres Replication Lagged: {{$labels.instance}}"
description: "lag = {{ $value }} seconds, {{$labels.instance}}"
# replication diff greater than 32MB for 5m triggers a P3 alert
- alert: PG_REPLICATOIN_DIFF
expr: pg_repl_lsn{application_name="walreceiver"} - pg_repl_replay_lsn{application_name="walreceiver"} > 33554432
for: 5m
labels:
team: DBA
urgency: P3
annotations:
summary: "P3 Postgres Replication Diff Deviant: {{$labels.instance}}"
description: "delta = {{ $value }} {{$labels.instance}}"
饱和度报警
饱和度指标主要资源,包含很多系统级监控的指标。主要包括:CPU,磁盘(这两个属于系统监控但对于DB非常重要所以纳入),连接池排队,数据库后端连接数,年龄(本质是可用事物号的饱和度),SSD寿命等。
堆积检测
堆积主要包含两类指标,一方面是PG本身的后端连接数与活跃连接数,另一方面是连接池的排队情况。
PGB排队是决定性的指标,它代表用户端可感知的阻塞已经出现,因此,配置排队超过15持续1分钟触发P0报警。
# more than 8 client waiting in queue for 1 min triggers a P0 alert
- alert: PGB_QUEUING
expr: sum(pgbouncer_pool_waiting_clients{datname!="pgbouncer"}) by (instance,datname) > 8
for: 1m
labels:
team: DBA
urgency: P0
annotations:
summary: "P0 Pgbouncer {{ $value }} Clients Wait in Queue: {{$labels.instance}}"
description: "waiting clients = {{ $value }} {{$labels.instance}}"
后端连接数是一个重要的报警指标,如果后端连接持续达到最大连接数,往往也意味着雪崩。连接池的排队连接数也能反映这种情况,但不能覆盖应用直连数据库的情况。后端连接数的主要问题是它与连接池关系密切,连接池在短暂堵塞后会迅速打满后端连接,但堵塞恢复后这些连接必须在默认约10min的Timeout后才被释放。因此收到短暂堆积的影响较大。同时外晚上1点备份时也会出现这种情况,容易产生误报。
注意后端连接数与后端活跃连接数不同,目前报警使用的是活跃连接数。后端活跃连接数通常在0~1,一些慢库在十几左右,离线库可能会达到20~30。但后端连接/进程数(不管活跃不活跃),通常均值可达50。后端连接数更为直观准确。
对于后端连接数,这里使用两个等级的报警:超过90持续3分钟P1,以及超过80持续10分钟P2,考虑到通常数据库最大连接数为100。这样做可以以尽可能低的误报率检测到雪崩堆积。
# num of backend exceed 90 for 3m
- alert: PG_BACKEND_HIGH
expr: sum(pg_db_numbackends) by (node) > 90
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres Backend Number High: {{$labels.instance}}"
description: "numbackend = {{ $value }} {{$labels.instance}}"
# num of backend exceed 80 for 10m (avoid pgbouncer jam false alert)
- alert: PG_BACKEND_WARN
expr: sum(pg_db_numbackends) by (node) > 80
for: 10m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres Backend Number Warn: {{$labels.instance}}"
description: "numbackend = {{ $value }} {{$labels.instance}}"
空闲事务
目前监控使用IDEL In Xact的绝对数量作为报警条件,其实 Idle In Xact的最长持续时间可能会更有意义。因为这种现象其实已经被后端连接数覆盖了。长时间的空闲是我们真正关注的,因此这里使用所有空闲事务中最高的闲置时长作为报警指标。设置3分钟为P2报警阈值。经常出现IDLE的非Offline库有:moderation, location, stats,sms, device, moderationdevice
# max idle xact duration exceed 3m
- alert: PG_IDLE_XACT
expr: pg_activity_max_duration{instance!~".*offline.*", state=~"^idle in transaction.*"} > 180
for: 3m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres Long Idle Transaction: {{$labels.instance}}"
description: "duration = {{ $value }} {{$labels.instance}}"
资源报警
CPU, 磁盘,AGE
默认清理年龄为2亿,超过10Y报P1,既留下了充分的余量,又不至于让人忽视。
# age wrap around (progress in half 10Y) triggers a P1 alert
- alert: PG_XID_WRAP
expr: pg_database_age{} > 1000000000
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres XID Wrap Around: {{$labels.instance}}"
description: "age = {{ $value }} {{$labels.instance}}"
磁盘和CPU由运维配置,不变
流量
因为各个业务的负载情况不一,为流量指标设置绝对值是相对困难的。这里只对TPS和Rollback设置绝对值指标。而且较为宽松。
Rollback OPS超过4则发出P3警告,TPS超过24000发P2,超过30000发P1
# more than 30k TPS lasts for 1m triggers a P1 (pgbouncer bottleneck)
- alert: PG_TPS_HIGH
expr: rate(pg_db_xact_total{}[1m]) > 30000
for: 1m
labels:
team: DBA
urgency: P1
annotations:
summary: "P1 Postgres TPS High: {{$labels.instance}} {{$labels.datname}}"
description: "TPS = {{ $value }} {{$labels.instance}}"
# more than 24k TPS lasts for 3m triggers a P2
- alert: PG_TPS_WARN
expr: rate(pg_db_xact_total{}[1m]) > 24000
for: 3m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres TPS Warning: {{$labels.instance}} {{$labels.datname}}"
description: "TPS = {{ $value }} {{$labels.instance}}"
# more than 4 rollback per seconds lasts for 5m
- alert: PG_ROLLBACK_WARN
expr: rate(pg_db_xact_rollback{}[1m]) > 4
for: 5m
labels:
team: DBA
urgency: P2
annotations:
summary: "P2 Postgres Rollback Warning: {{$labels.instance}}"
description: "rollback per sec = {{ $value }} {{$labels.instance}}"
QPS的指标与业务高度相关,因此不适合配置绝对值,可以为QPS突增配置一个报警项
短时间(和10分钟)前比突增30%会触发一个P2警报,同时避免小QPS下的突发流量,设置一个绝对阈值10k
# QPS > 10000 and have a 30% inc for 3m triggers P2 alert
- alert: PG_QPS_BURST
expr: sum by(datname,instance)(rate(pgbouncer_stat_total_query_count{datname!="pgbouncer"}[1m]))/sum by(datname,instance) (rate(pgbouncer_stat_total_query_count{datname!="pgbouncer"}[1m] offset 10m)) > 1.3 and sum by(datname,instance) (rate(pgbouncer_stat_total_query_count{datname!="pgbouncer"}[1m])) > 10000
for: 3m
labels:
team: DBA
urgency: P1
annotations:
summary: "P2 Pgbouncer QPS Burst 30% and exceed 10000: {{$labels.instance}}"
description: "qps = {{ $value }} {{$labels.instance}}"
Prometheus报警规则
完整的报警规则详见:参考-报警规则