Naming Rules
You can refer to those you can name. You can take action on those you can refer
Concepts and their naming are very important things, and the naming style reflects the engineer’s knowledge of the system architecture. Ill-defined concepts will lead to confusion in communication, and arbitrarily set names will create unexpected additional burden. Therefore it needs to be designed judiciously. This article introduces the relevant entities in Pigsty and the principles followed for their naming.
Conclusion
In Pigsty, the core four types of entities are: Cluster, Service, Instance, Node
- Cluster is the basic autonomous unit, which is assigned **uniquely by the user to express the business meaning and serve as the top-level namespace.
- Clusters contain a series of Nodes at the hardware level, i.e., physical machines, virtual machines (or Pods) that can be uniquely identified by IP.
- The cluster contains a series of Instance at the software level, i.e., software servers, which can be uniquely identified by IP:Port.
- The cluster contains a series of Services at the service level, i.e., accessible domains and endpoints that can be uniquely identified by domains.
- Cluster naming can use any name that satisfies the DNS domain name specification, not with a dot (
[a-zA-Z0-9-]+). - Node naming uses the cluster name as a prefix, followed by
-and then an integer ordinal number (recommended to be assigned starting from 0, consistent with k8s) - Because Pigsty uses exclusive deployment, nodes correspond to instances one by one. Then the instance naming can be consistent with the node naming, i.e.
${cluster}-${seq}way. - Service naming also uses the cluster name as the prefix, followed by
-to connect the service specifics, such asprimary,replica,offline,delayed, etc.
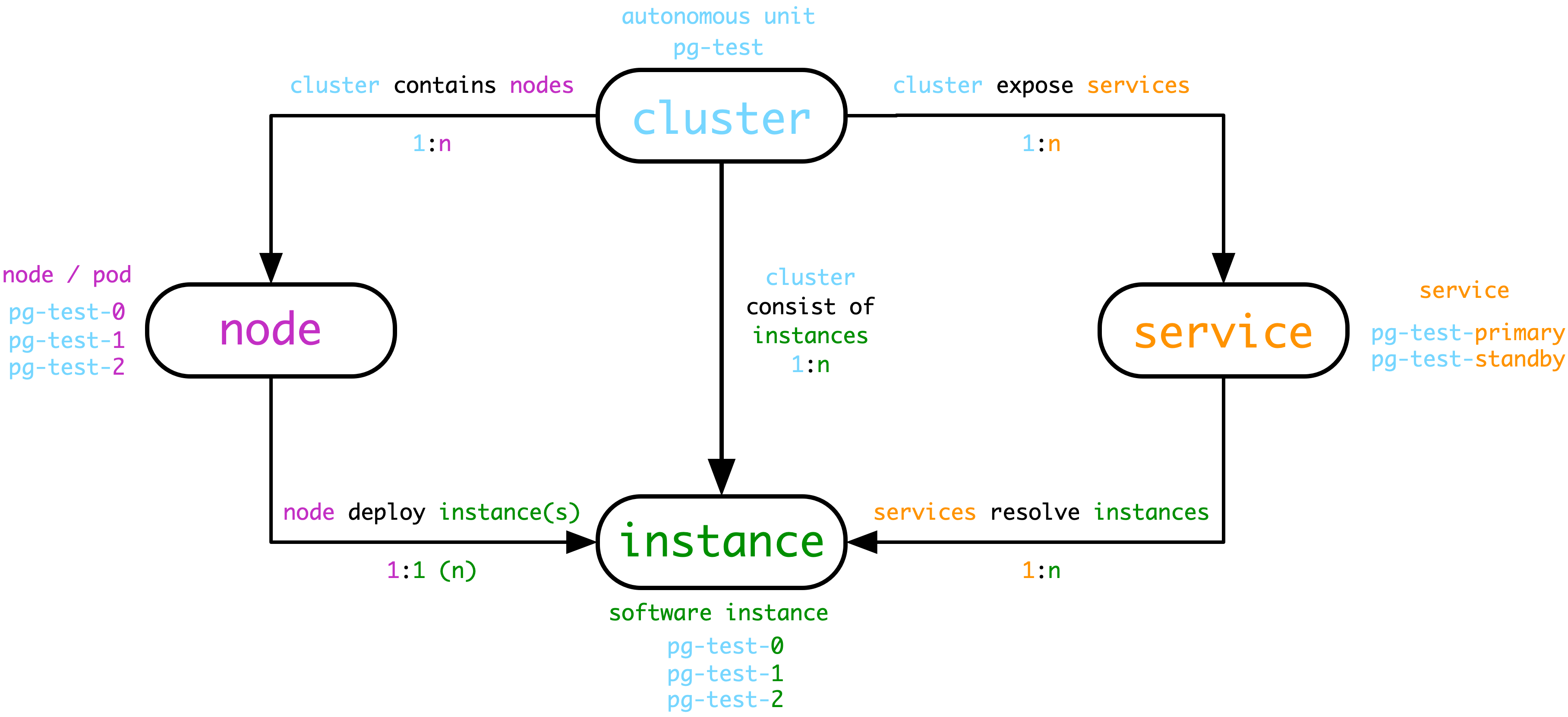
In the above figure, for example, the database cluster used for testing is named ``pg-test'', which consists of three database server instances, one master and two slaves, deployed on the three nodes belonging to the cluster. The pg-testcluster cluster provides two services to the outside world, the read-write servicepg-test-primaryand the read-only copy servicepg-test-replica`.
Entities
In Postgres cluster management, there are the following entity concepts.
Cluster (Cluster)
A cluster is the basic autonomous business unit, which means that the cluster can be organized as a whole to provide services to the outside world. Similar to the concept of Deployment in k8s. Note that Cluster here is a software level concept, not to be confused with PG Cluster (Database Set Cluster, i.e. a data directory containing multiple PG Databases with a single PG instance) or Node Cluster (Machine Cluster).
A cluster is one of the basic units of management, an organizational unit used to unify various resources. For example, a PG cluster may include.
- Three physical machine nodes
- One master instance, which provides database read and write services to the external world.
- Two slave instances, which provide read-only copies of the database to the public.
- Two externally exposed services: read-write service, read-only copy service.
Each cluster has a unique identifier defined by the user according to the business requirements. In this example, a database cluster named pg-test is defined.
Nodes (Node)
Node is an abstraction of a hardware resource, usually referring to a working machine, either a physical machine (bare metal) or a virtual machine (vm), or a Pod in k8s. note here that Node in k8s is an abstraction of a hardware resource, but in terms of actual management use, it is the Pod in k8s rather than the Node that is more similar to the Node concept here. In short, the key elements of a Node are.
- Node is an abstraction of a hardware resource that can run a range of software services
- Nodes can use IP addresses as unique identifiers
Although the lan_ip address can be used as the node unique identifier, for ease of management, the node should have a human-readable meaning-filled name as the node’s Hostname, as another common node unique identifier.
Service
A service is a named abstraction of a software service (e.g. Postgres, Redis). Services can be implemented in a variety of ways, but their key elements are.
- an addressable and accessible service name for providing access to the outside world, for example.
- A DNS domain name (
pg-test-primary) - An Nginx/Haproxy Endpoint
- A DNS domain name (
- ** Service traffic routing resolution and load balancing mechanism** for deciding which instance is responsible for handling requests, e.g.
- DNS L7: DNS resolution records
- HTTP Proxy: Nginx/Ingress L7: Nginx Upstream configuration
- TCP Proxy: Haproxy L4: Haproxy Backend configuration
- Kubernetes: Ingress: Pod Selector Selector.
The same dataset cluster usually includes a master and a slave, both of which provide read and write services (primary) and read-only copy services (replica), respectively.
Instance
An instance refers to a specific database server**, which can be a single process, a group of processes sharing a common fate, or several closely related containers within a Pod. The key elements of an instance are.
- Can be uniquely identified by IP:Port
- Has the ability to process requests
For example, we can consider a Postgres process, the exclusive Pgbouncer connection pool that serves it, the PgExporter monitoring component, the high availability component, and the management Agent as a whole that provides services as a single database instance.
Instances are part of a cluster, and each instance has its own unique identifier to distinguish it within the cluster.
The instances are resolved by the Service, which provides the ability to be addressed, and the Service resolves the request traffic to a specific set of instances.
Naming Rules
An object can have many groups of Tags and Metadata/Annotation, but can usually have only one Name.
Managing databases and software is similar to managing pets in that it takes care of them. And naming is one of those very important tasks. Unbridled names (e.g. XÆA-12, NULL, Shi Zhenxiang) are likely to introduce unnecessary hassles (extra complexity), while properly designed names may have unexpected and surprising effects.
In general, object naming should follow some principles.
-
Simple and straightforward, human readable: the name is for people, so it should be memorable and easy to use.
-
Reflect the function, reflect the characteristics: the name needs to reflect the key features of the object
-
Unique, uniquely identifiable: the name should be unique in the namespace, under its own class, and can uniquely identify addressable.
-
Don’t cram too much extraneous stuff into the name: embedding a lot of important metadata in the name is an attractive idea, but can be very painful to maintain, e.g. counter example:
pg:user:profile:10.11.12.13:5432:replica:13.
Cluster naming
The cluster name, in fact, is similar to the role of a namespace. All resources that are part of this cluster use this namespace.
For the form of cluster naming, it is recommended to use naming rules that conform to the DNS standard RFC1034 so as not to bury a hole for subsequent transformation. For example, if you want to move to the cloud one day and find that the name you used before is not supported, you will have to change the name again, which is costly.
I think a better approach would be to adopt a stricter restriction: cluster names should not include dots (dot). Only lowercase letters, numbers, and minus hyphens (hyphen)- should be used. This way, all objects in the cluster can use this name as a prefix for a wide variety of places without worrying about breaking certain constraints. That is, the cluster naming rule is
cluster_name := [a-z][a-z0-9-]*
The reason for emphasizing not to use dots in cluster names is that a naming convention used to be popular, such as com.foo.bar. That is, the hierarchical naming method split by points. Although this naming style is concise and quick, there is a problem that there may be arbitrarily many levels in the name given by the user, and the number is not controllable. Such names can cause trouble if the cluster needs to interact with an external system that has some constraints on naming. One of the most intuitive examples is Pod in K8s, where Pod naming rules do not allow . .
Connotation of cluster naming, -separated two-paragraph, three-paragraph names are recommended, e.g.
<cluster type>-<business>-<business line
For example: pg-test-tt would indicate a test cluster under the tt line of business, type pg. pg-user-fin indicates user service under the fin line of business.
Node naming
The recommended naming convention for nodes is the same as for k8s Pods, i.e.
<cluster_name>-<seq>
Node names are determined during the cluster resource allocation phase, and each node is assigned a serial number ${seq}, a self-incrementing integer starting at 0. This is consistent with the naming rules of StatefulSet in k8s, so it can be managed consistently on and off the cloud.
For example, the cluster pg-test has three nodes, so these three nodes can be named as
pg-test-1, pg-test-2 and pg-test-3.
The nodes are named in such a way that they remain the same throughout the life of the cluster for easy monitoring and management.
Instance naming
For databases, exclusive deployment is usually used, where one instance occupies the entire machine node. pg instances are in one-to-one correspondence with Nodes, so you can simply use the identifier of the Node as the identifier of the Instance. For example, the name of the PG instance on node pg-test-1 is: pg-test-1, and so on.
There is a great advantage in using exclusive deployment, where one node is one instance, which minimizes the management complexity. The need to mix parts usually comes from the pressure of resource utilization, but virtual machines or cloud platforms can effectively solve this problem. With vm or pod abstraction, even each redis (1 core 1G) instance can have an exclusive node environment.
As a convention, node 0 (Pod), in each cluster, will be used as the default primary library. This is because it is the first node allocated at initialization.
Service naming
Generally speaking, the database provides two basic services externally: primary read-write service, and replica read-only copy service.
Then the services can be named using a simple naming rule: ``primary`''
<cluster_name>-<service_name>
For example, here the pg-test cluster contains two services: the read-write service pg-test-primary and the read-only replica service pg-test-replica.
A popular instance/node naming rule: <cluster_name>-<service_role>-<sequence>, where the master-slave identity of the database is embedded in the instance name. This naming convention has both advantages and disadvantages. The advantage is that you can tell at a glance which instance/node is the master and which is the slave when managing it. The disadvantage is that once Failover occurs, the names of instances and nodes must be adjusted to maintain persistence, which creates additional maintenance work. In addition, service and node instances are relatively independent concepts, and this Embedding nomenclature distorts this relationship by uniquely affiliating instances to services. However, this assumption may not be satisfied in complex scenarios. For example, a cluster may have several different ways of dividing services, and there is likely to be overlap between the different divisions.
- Readable slave (resolves to all instances including the master)
- Synchronous slave (resolves to a backup library that uses synchronous commits)
- Deferred slave, backup instances (resolves to a specific specific instance)
So instead of embedding the service role in the instance name, maintain a list of target instances in the service. After all, names are not all-powerful, so don’t embed too much non-essential information into the object names.