Hierarchy
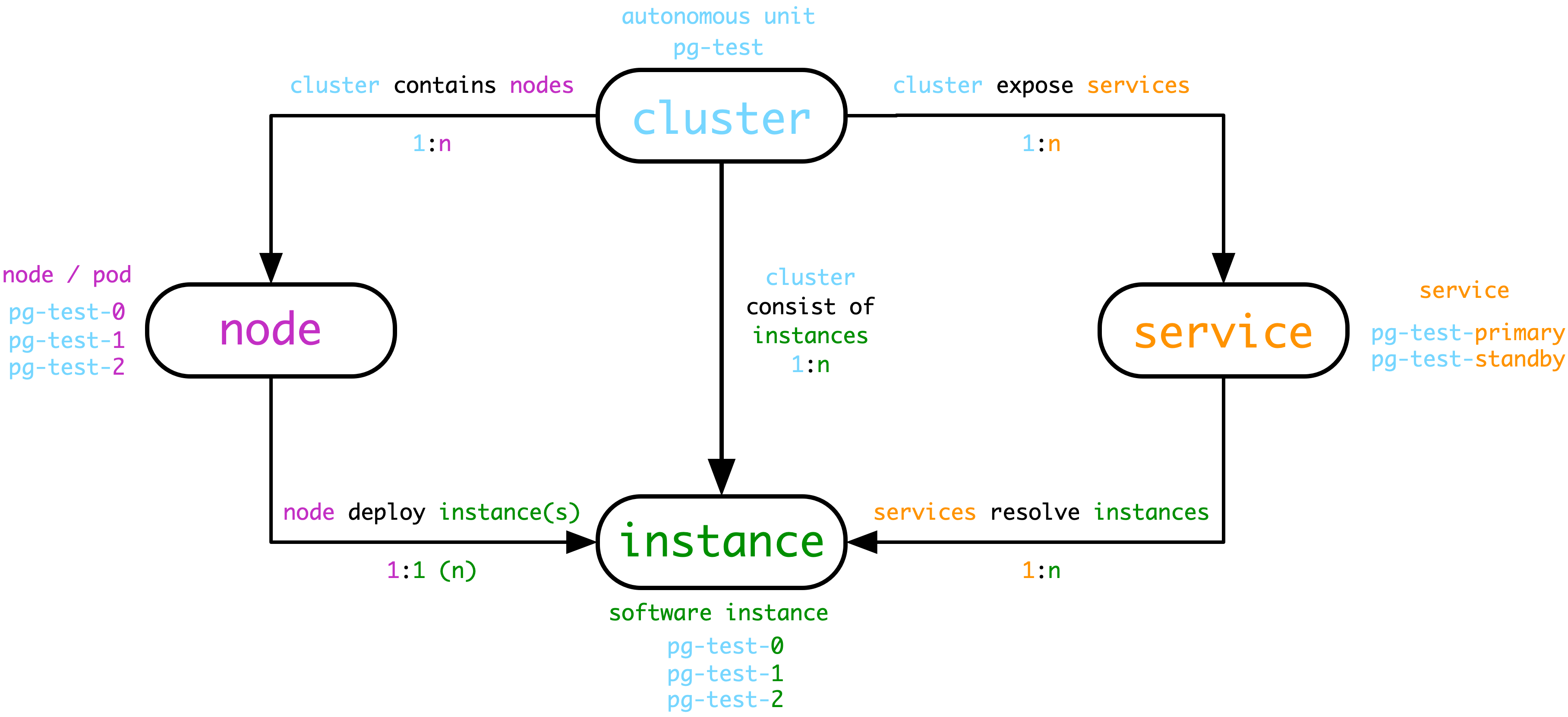
As in Naming Principle, objects in Pigsty are divided into multiple levels: clusters, services, instances, and nodes.
Monitoring system hierarchy
Pigsty’s monitoring system has more layers. In addition to the two most common layers, Instance and Cluster, there are other layers of organization throughout the system. From the top down, there are 7 levels: **Overview, Slice, Cluster, Service, Instance, Database, Object. **

Figure : Pigsty’s monitoring panel is divided into 7 logical hierarchies and 5 implementation hierarchies
Logical levels
Databases in production environments are often organized in clusters, which are the basic business service units and the most important level of monitoring.
A cluster is a set of database instances associated by master-slave replication, and instance is the most basic level of monitoring.
Whereas multiple database clusters together form a real-world production environment, the Overview level of monitoring provides an overall description of the entire environment.
Multiple database clusters serving the same business in a horizontally split pattern are called Shards, and monitoring at the shard level is useful for locating data distribution, skew, and other issues.
Service is the layer sandwiched between the cluster and the instance, and the service is usually closely associated with resources such as DNS, domain names, VIPs, NodePort, etc.
Database is a sub-instance level object where a database cluster/instance may have multiple databases existing at the same time, and database level monitoring is concerned with activity within a single database.
Object are entities within a database, including tables, indexes, sequence numbers, functions, queries, connection pools, etc. Object-level monitoring focuses on the statistical metrics of these objects, which are closely related to the business.
Hierarchical Streamlining
As a streamlining, just as the OSI 7-layer model for networking was reduced in practice to a five-layer model for TCP/IP, these seven layers were also reduced to five layers bounded by Clusters and Instances: Overview , Clusters , Services , Instance , Databases .
This makes the final hierarchy very concise: all information above the cluster level is the Overview level, all monitoring below the instance level is counted as the Database level, and sandwiched between the Cluster and Instance is the Service level.
Naming Rules
After the hierarchy, the most important issue is naming.
-
there needs to be a way to identify and refer to the components within the different layers of the system.
-
the naming convention should reasonably reflect the hierarchical relationship of the entities in the system
-
the naming scheme should be automatically generated according to the rules, so that it can run maintenance-free and automatically when the cluster is scaled up and down and Failover.
Once we have clarified the hierarchy of the system, we can proceed to name each entity in the system.
For the basic naming rules followed by Pigsty, please refer to Naming Principles section.
Pigsty uses an independent name management mechanism and the naming of entities is self-contained.
If you need to interface with external systems, you can use this naming system directly, or adopt your own naming system by transferring the adaptation.
Cluster Naming
Pigsty’s cluster names are specified by the user and satisfy the regular expression of [a-z0-9][a-z0-9-]*, in the form of pg-test, pg-meta.
node naming
Pigsty’s nodes are subordinate to clusters. pigsty’s node names consist of two parts: [cluster name](#cluster naming) and node number, and are concatenated with -.
The form is ${pg_cluster}-${pg_seq}, e.g. pg-meta-1, pg-test-2.
Formally, node numbers are natural numbers of reasonable length (including 0), unique within the cluster, and each node has its own number.
Instance numbers can be explicitly specified and assigned by the user, usually using an assignment starting from 0 or 1, once assigned, they do not change again for the lifetime of the cluster.
Instance Naming
Pigsty’s instance is subordinate to the cluster and is deployed in an exclusive node style.
Since there is a one-to-one correspondence between instances and nodes, the instance name remains the same as the node life.
Service Naming
Pigsty’s Service is subordinate to the cluster. pigsty’s service name consists of two parts: [cluster name](#cluster naming) and Role, and is concatenated with -.
The form is ${pg_cluster}-${pg_role}, e.g. pg-meta-primary, pg-test-replica.
The options available for pg_role include: primary|replica|offline|delayed.
primary is a special role that each cluster must and can only define one instance of pg_role = primary as the primary library.
The other roles are largely user-defined, with replica|offline|delayed being a Pigsty predefined role.
What next?
After delineating the monitoring hierarchy, you need to [assign identity] to the monitoring object (../identity) to be able to manage them.