Metrics
Metrics lies in the core part of pigsty monitoring system.
指标形式
指标在形式上是可累加的,原子性的逻辑计量单元,可在时间段上进行更新与统计汇总。
指标通常以 带有维度标签的时间序列 的形式存在。举个例子,Pigsty沙箱中的pg:ins:qps_realtime指展示了所有实例的实时QPS。
pg:ins:qps_realtime{cls="pg-meta", ins="pg-meta-1", ip="10.10.10.10", role="primary"} 0
pg:ins:qps_realtime{cls="pg-test", ins="pg-test-1", ip="10.10.10.11", role="primary"} 327.6
pg:ins:qps_realtime{cls="pg-test", ins="pg-test-2", ip="10.10.10.12", role="replica"} 517.0
pg:ins:qps_realtime{cls="pg-test", ins="pg-test-3", ip="10.10.10.13", role="replica"} 0
用户可以对指标进行运算:求和、求导,聚合,等等。例如:
$ sum(pg:ins:qps_realtime) by (cls) -- 查询按集群聚合的 实时实例QPS
{cls="pg-meta"} 0
{cls="pg-test"} 844.6
$ avg(pg:ins:qps_realtime) by (cls) -- 查询每个集群中 所有实例的平均 实时实例QPS
{cls="pg-meta"} 0
{cls="pg-test"} 280
$ avg_over_time(pg:ins:qps_realtime[30m]) -- 过去30分钟内实例的平均QPS
pg:ins:qps_realtime{cls="pg-meta", ins="pg-meta-1", ip="10.10.10.10", role="primary"} 0
pg:ins:qps_realtime{cls="pg-test", ins="pg-test-1", ip="10.10.10.11", role="primary"} 130
pg:ins:qps_realtime{cls="pg-test", ins="pg-test-2", ip="10.10.10.12", role="replica"} 100
pg:ins:qps_realtime{cls="pg-test", ins="pg-test-3", ip="10.10.10.13", role="replica"} 0
指标模型
每一个指标(Metric),都是一类数据,通常会对应多个时间序列(time series)。同一个指标对应的不同时间序列通过维度进行区分。
指标 + 维度,可以具体定位一个时间序列。每一个时间序列都是由 (时间戳,取值)二元组构成的数组。
Pigsty采用Prometheus的指标模型,其逻辑概念可以用以下的SQL DDL表示。
-- 指标表,指标与时间序列构成1:n关系
CREATE TABLE metrics (
id INT PRIMARY KEY, -- 指标标识
name TEXT UNIQUE -- 指标名称,[...其他指标元数据,例如类型]
);
-- 时间序列表,每个时间序列都对应一个指标。
CREATE TABLE series (
id BIGINT PRIMARY KEY, -- 时间序列标识
metric_id INTEGER REFERENCES metrics (id), -- 时间序列所属的指标
dimension JSONB DEFAULT '{}' -- 时间序列带有的维度信息,采用键值对的形式表示
);
-- 时许数据表,保存最终的采样数据点。每个采样点都属于一个时间序列
CREATE TABLE series_data (
series_id BIGINT REFERENCES series(id), -- 时间序列标识
ts TIMESTAMP, -- 采样点时间戳
value FLOAT, -- 采样点指标值
PRIMARY KEY (series_id, ts) -- 每个采样点可以通过 所属时间序列 与 时间戳 唯一标识
);
这里我们以pg:ins:qps指标为例:
-- 样例指标数据
INSERT INTO metrics VALUES(1, 'pg:ins:qps'); -- 该指标名为 pg:ins:qps ,是一个 GAUGE。
INSERT INTO series VALUES -- 该指标包含有四个时间序列,通过维度标签区分
(1001, 1, '{"cls": "pg-meta", "ins": "pg-meta-1", "role": "primary", "other": "..."}'),
(1002, 1, '{"cls": "pg-test", "ins": "pg-test-1", "role": "primary", "other": "..."}'),
(1003, 1, '{"cls": "pg-test", "ins": "pg-test-2", "role": "replica", "other": "..."}'),
(1004, 1, '{"cls": "pg-test", "ins": "pg-test-3", "role": "replica", "other": "..."}');
INSERT INTO series_data VALUES -- 每个时间序列底层的采样点
(1001, now(), 1000), -- 实例 pg-meta-1 在当前时刻QPS为1000
(1002, now(), 1000), -- 实例 pg-test-1 在当前时刻QPS为1000
(1003, now(), 5000), -- 实例 pg-test-2 在当前时刻QPS为1000
(1004, now(), 5001); -- 实例 pg-test-3 在当前时刻QPS为5001
pg_up是一个指标,包含有4个时间序列。记录了整个环境中所有实例的存活状态。pg_up{ins": "pg-test-1", ...}是一个时间序列,记录了特定实例pg-test-1的存活状态
指标来源
Pigsty的监控数据主要有四种主要来源: 数据库,连接池,操作系统,负载均衡器。通过相应的exporter对外暴露。
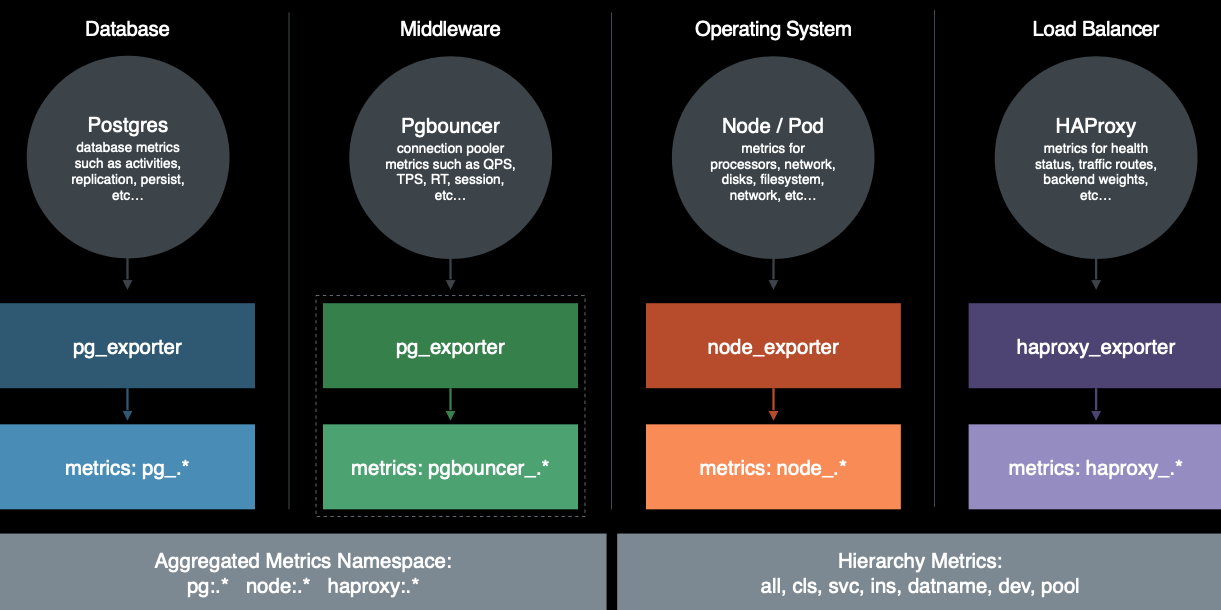
完整来源包括:
- PostgreSQL本身的监控指标
- PostgreSQL日志中的统计指标
- PostgreSQL系统目录信息
- Pgbouncer连接池中间价的指标
- PgExporter指标
- 数据库工作节点Node的指标
- 负载均衡器Haproxy指标
- DCS(Consul)工作指标
- 监控系统自身工作指标:Grafana,Prometheus,Nginx
- Blackbox探活指标
关于全部可用的指标清单,请查阅 参考-指标清单 一节
指标数量
那么,Pigsty总共包含了多少指标呢? 这里是一副各个指标来源占比的饼图。我们可以看到,右侧蓝绿黄对应的部分是数据库及数据库相关组件所暴露的指标,而左下方红橙色部分则对应着机器节点相关指标。左上方紫色部分则是负载均衡器的相关指标。
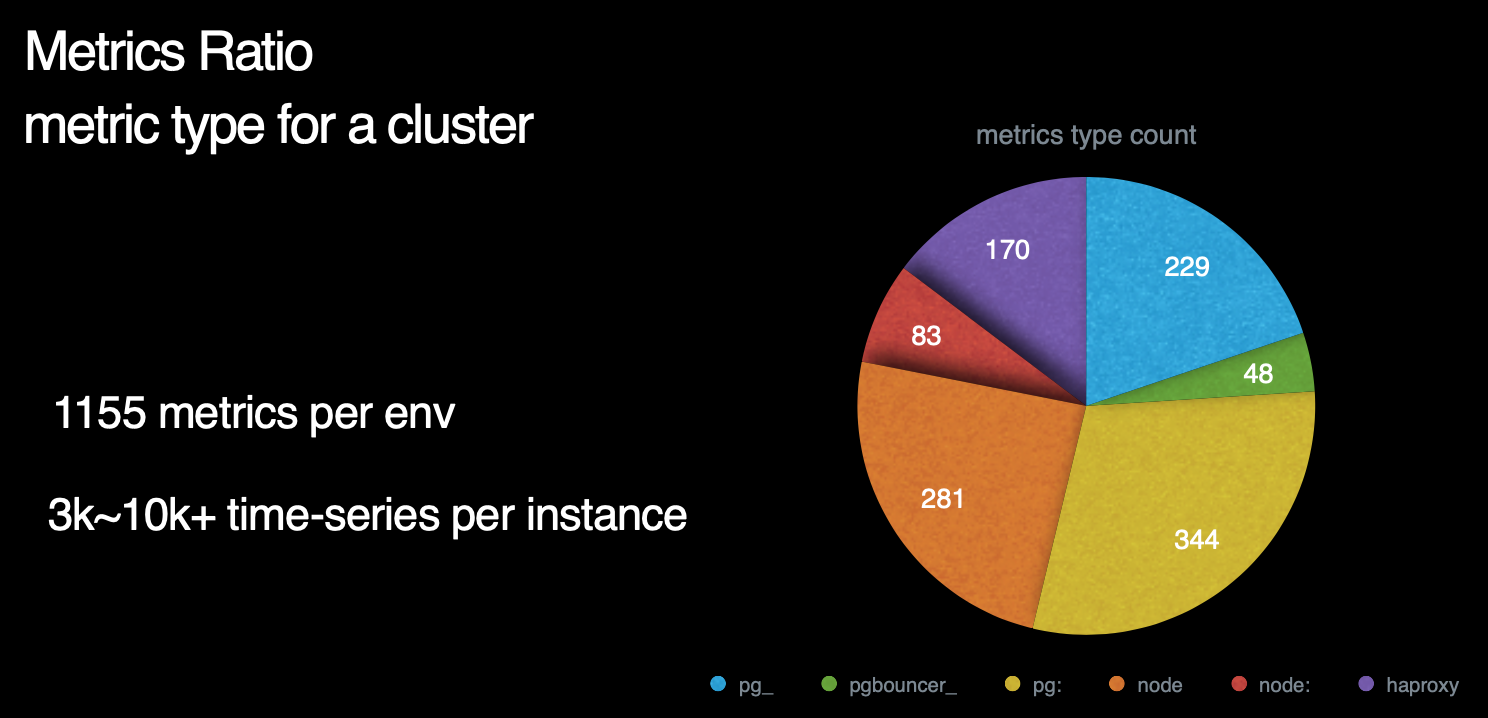
数据库指标中,与postgres本身有关的原始指标约230个,与中间件有关的原始指标约50个,基于这些原始指标,Pigsty又通过层次聚合与预计算,精心设计出约350个与DB相关的衍生指标。
因此,对于每个数据库集群来说,单纯针对数据库及其附件的监控指标就有621个。而机器原始指标281个,衍生指标83个一共364个。加上负载均衡器的170个指标,我们总共有接近1200类指标。
注意,这里我们必须辨析一下指标(metric)与时间序列( Time-series)的区别。
这里我们使用的量词是 类 而不是个 。 因为一个指标可能对应多个时间序列。例如一个数据库中有20张表,那么 pg_table_index_scan 这样的指标就会对应有20个对应的时间序列。
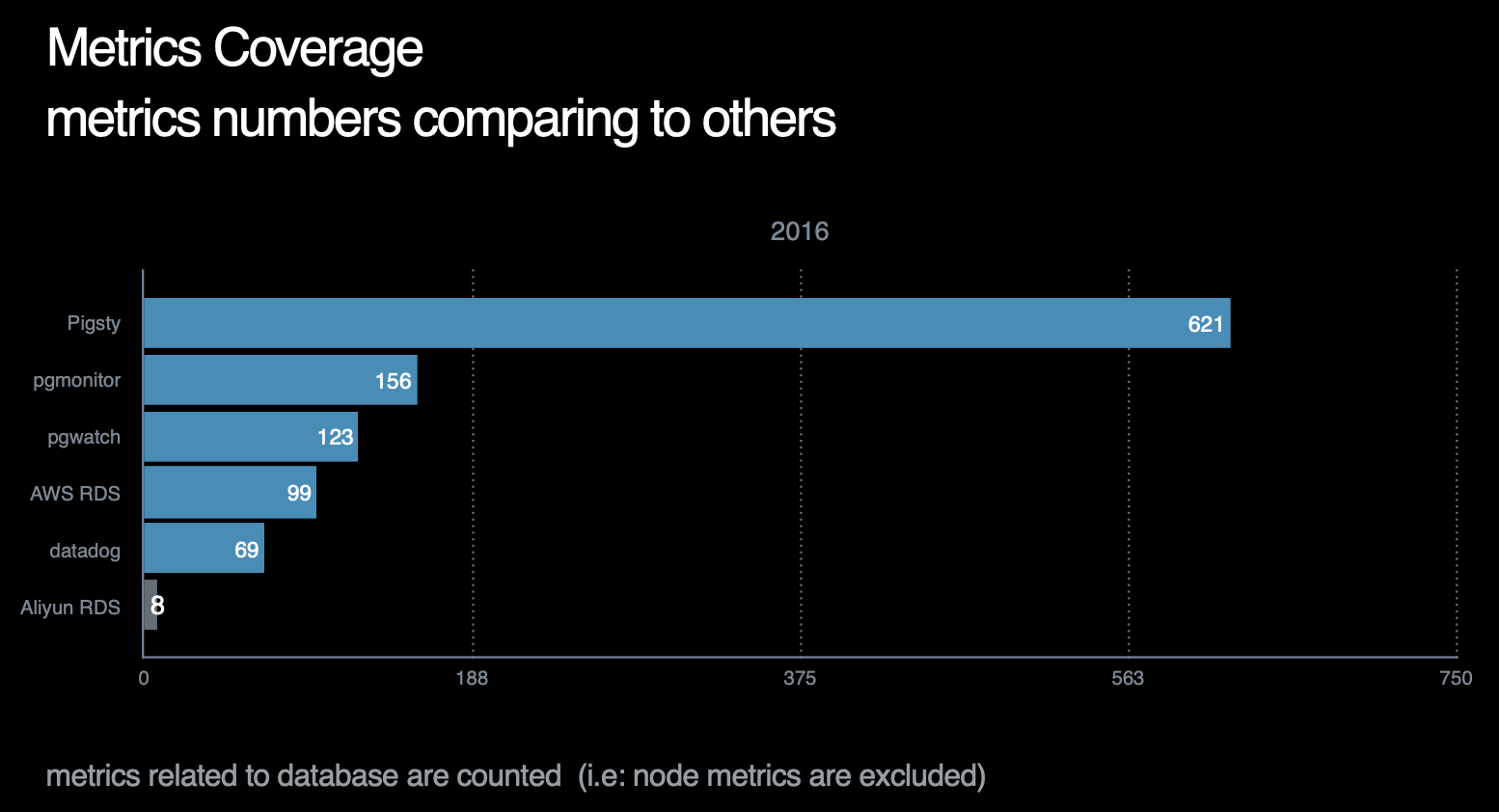
截止至2021年,Pigsty的指标覆盖率在所有作者已知的开源/商业监控系统中一骑绝尘,详情请参考横向对比。
指标层次
Pigsty还会基于现有指标进行加工处理,产出 衍生指标(Derived Metrics) 。
例如指标可以按照不同的层次进行聚合
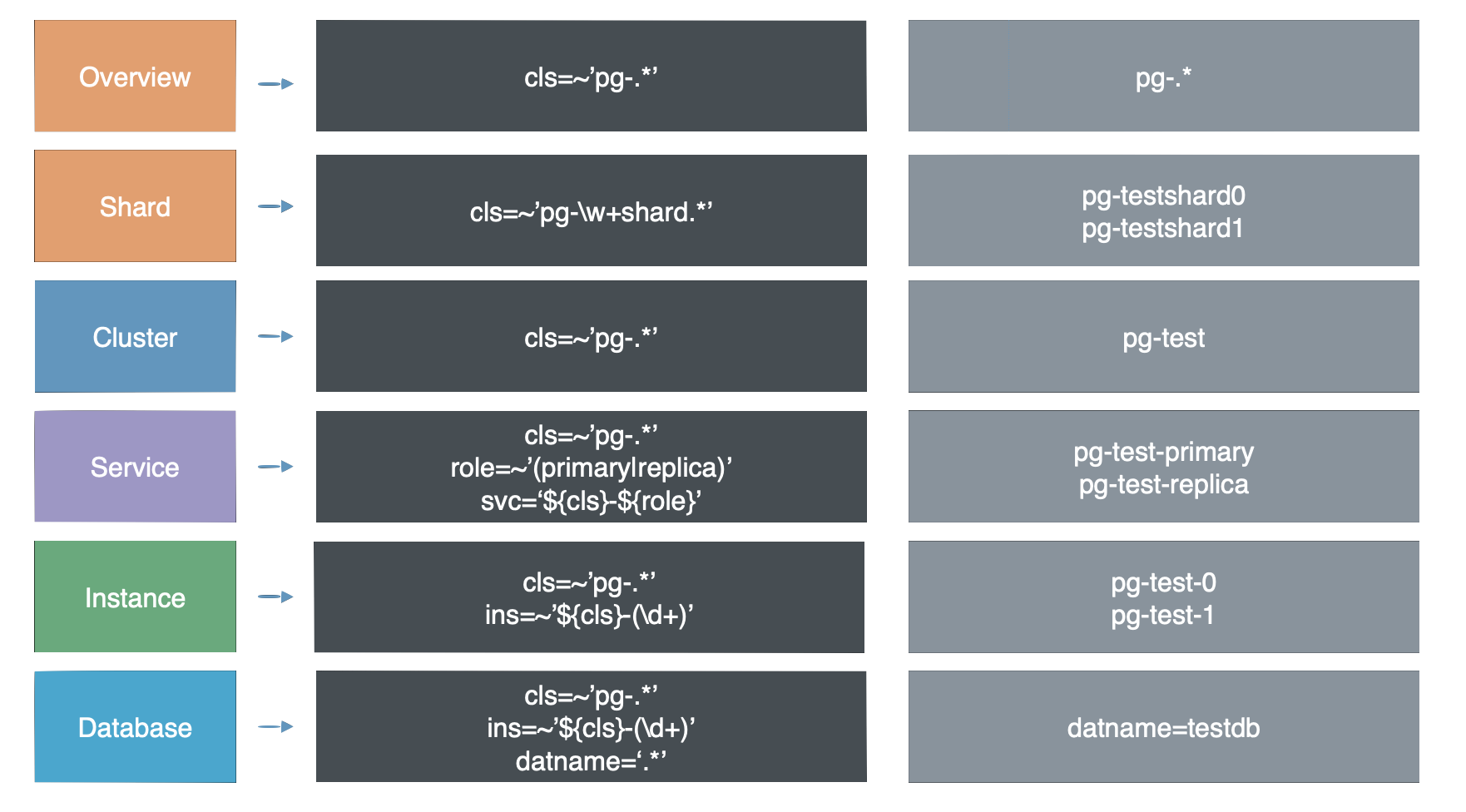
从原始监控时间序列数据,到最终的成品图表,中间还有着若干道加工工序。
这里以TPS指标的衍生流程为例。
原始数据是从Pgbouncer抓取得到的事务计数器,集群中有四个实例,而每个实例上又有两个数据库,所以一个实例总共有8个DB层次的TPS指标。
而下面的图表,则是整个集群内每个实例的QPS横向对比,因此在这里,我们使用预定义的规则,首先对原始事务计数器求导获取8个DB层面的TPS指标,然后将8个DB层次的时间序列聚合为4个实例层次的TPS指标,最后再将这四个实例级别的TPS指标聚合为集群层次的TPS指标。
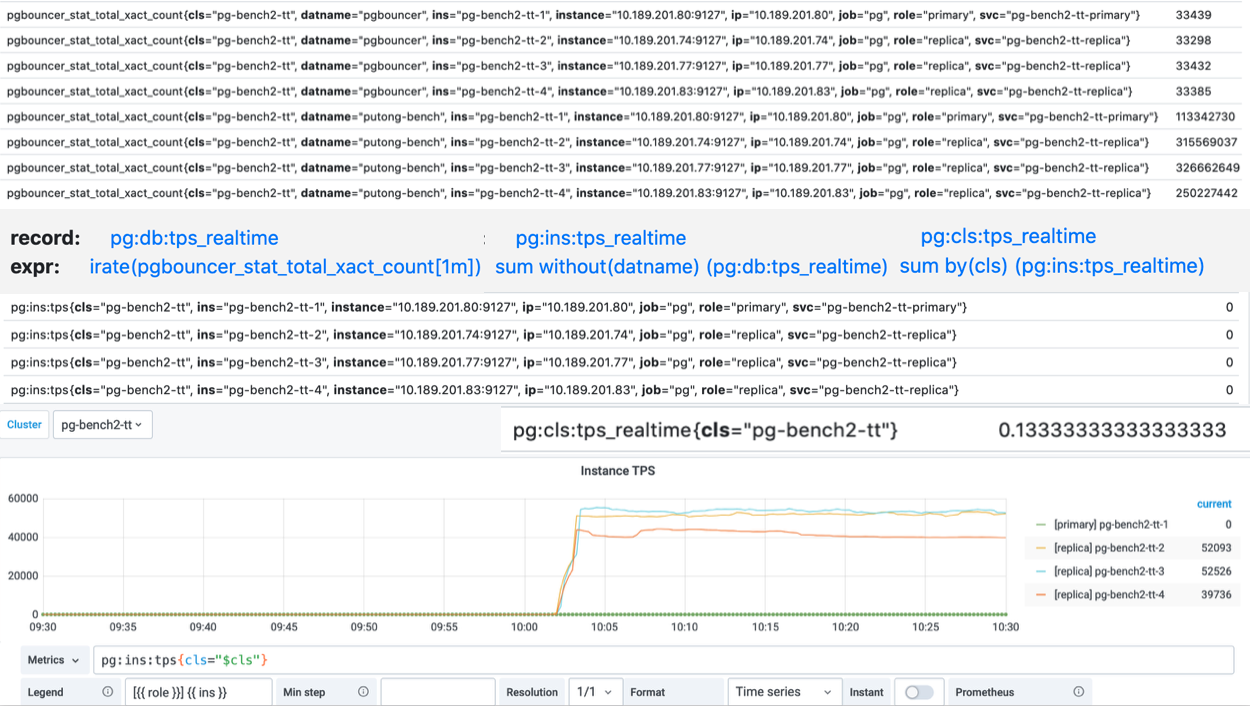
Pigsty共定义了360类衍生聚合指标,后续还会不断增加。衍生指标定义规则详见 参考-衍生指标
特殊指标
目录(Catalog) 是一种特殊的指标
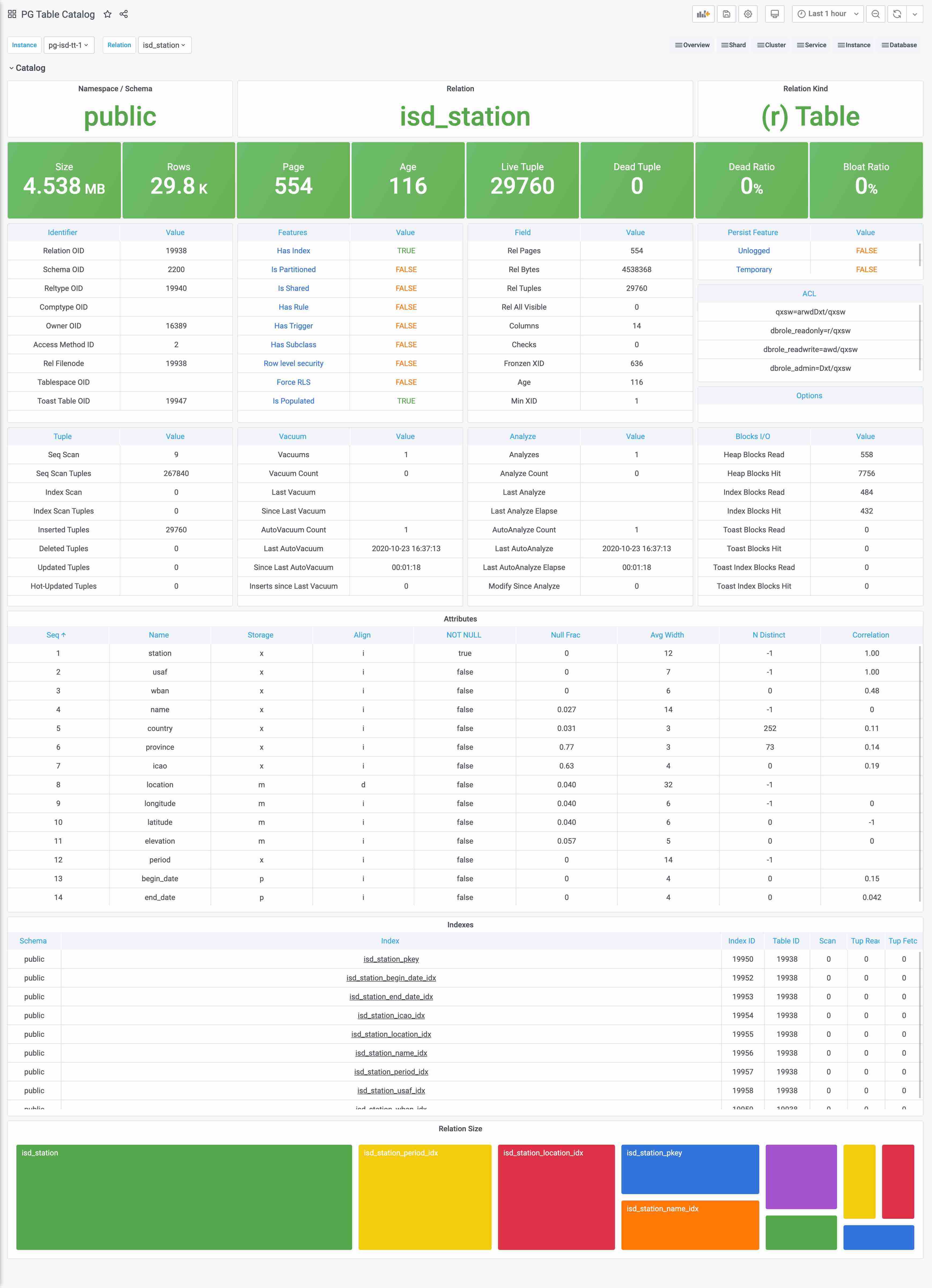
Catalog与Metrics比较相似但又不完全相同,边界比较模糊。最简单的例子,一个表的页面数量和元组数量,应该算Catalog还是算Metrics?
跳过这种概念游戏,实践上Catalog和Metrics主要的区别是,Catalog里的信息通常是不怎么变化的,比如表的定义之类的,如果也像Metrics这样比如几秒抓一次,显然是一种浪费。所以我们会将这一类偏静态的信息划归Catalog。
Catalog主要由定时任务(例如巡检)负责抓取,而不由Prometheus采集。一些特别重要的Catalog信息,例如pg_class中的一些信息,也会转换为指标被Prometheus所采集。
小结
了解了Pigsty指标后,不妨了解一下Pigsty的 报警系统 是如何将这些指标数据用于实际生产用途的。